

•
이미지 1장에 대해 label 정의 되어 있는 것을 학습하는 것이 기본적인 방법

•
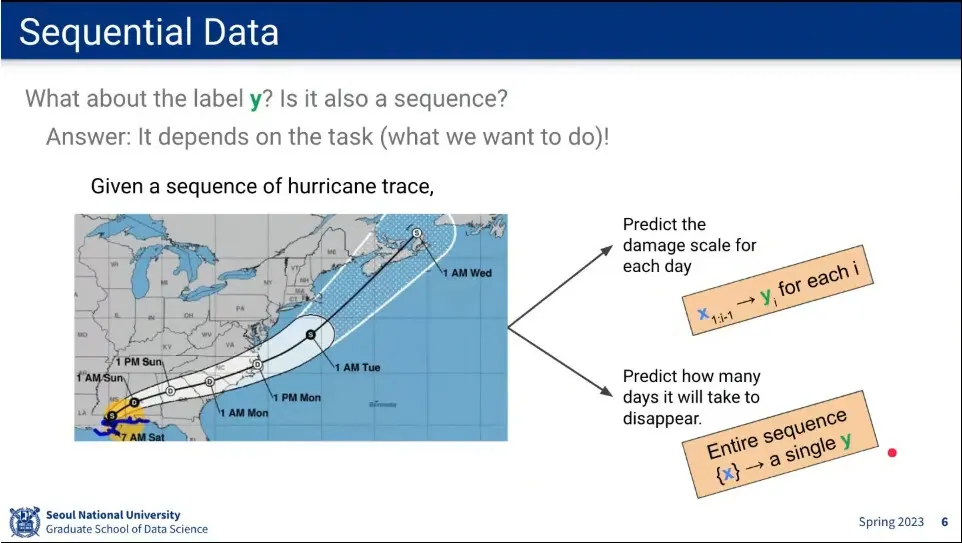
입력이 이미지 1장이 아니라 sequence 라면 어떻게 되어야 할까?


•
입력이 시퀀스라면 y도 시퀀스인가? → 문제에 따라 다름.
•
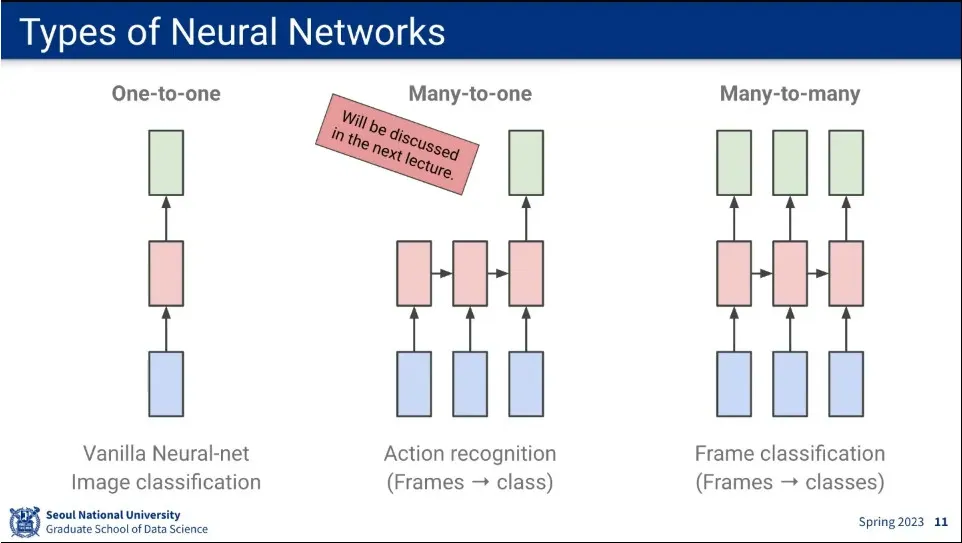
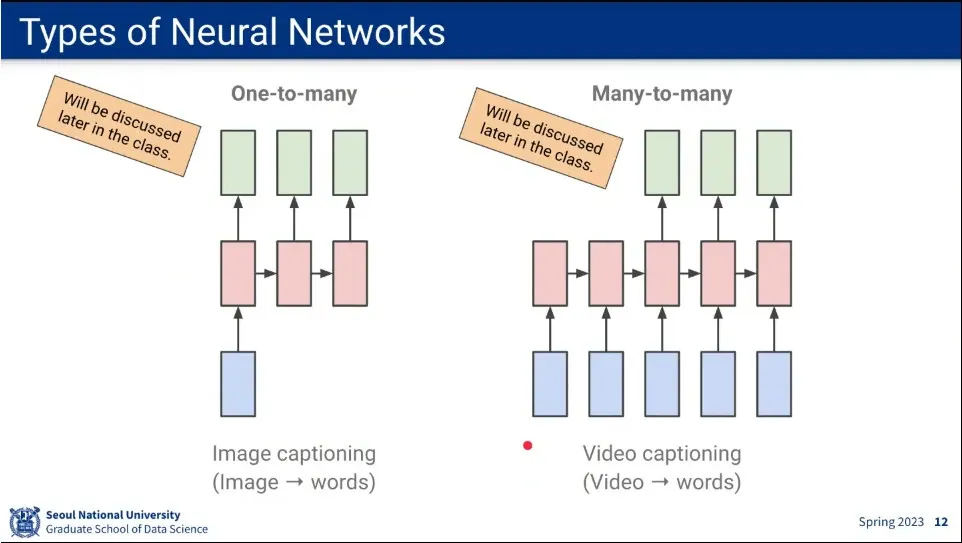
sequence는 위와 같이 분류 할 수 있음.
◦
one-to-one
◦
many-to-one
◦
many-to-many
◦
one-to-many
•
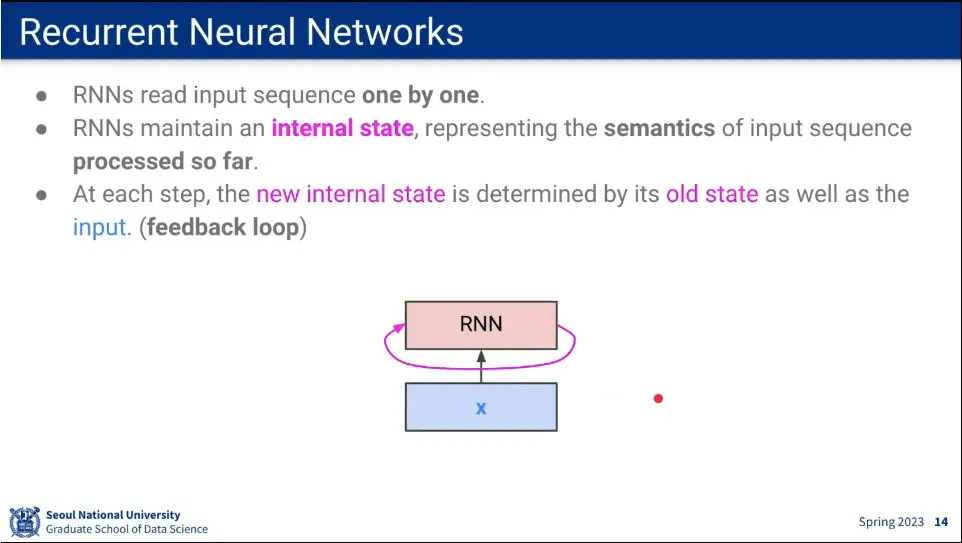
RNN은 internal state를 갖고 있고, 입력에 따라 internal state를 업데이트 함.

•
순환적인 과정을 펼쳐서 그리면 위와 같다.

•
recurrence formula는 점화식 형태다. 이전 state에 현재 input을 이용해서 현재 state를 구함.
•
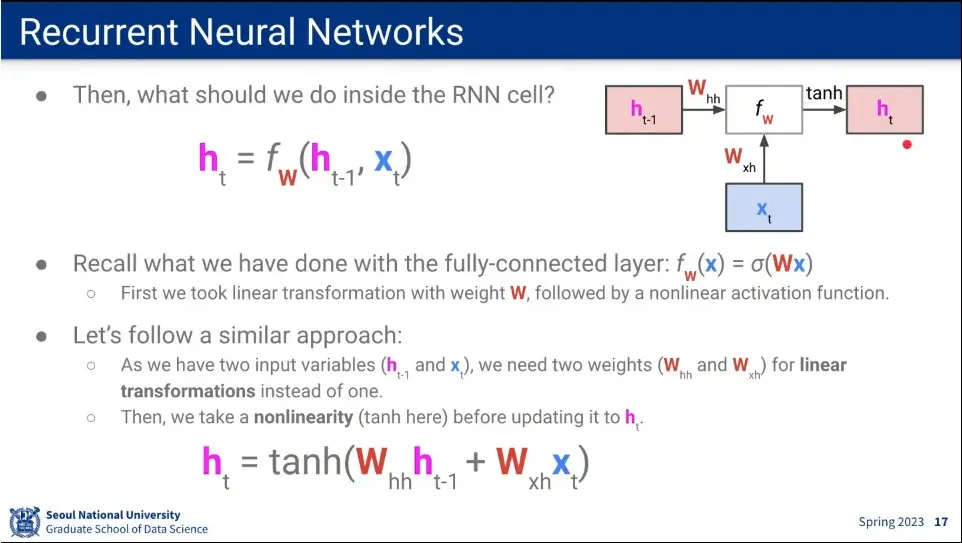
RNN 함수는 Fully-connected의 것을 참조하여 위와 같이 정의된다.
◦
가중치 를 이전 state에 곱해지는 가중치 와, 현재 input에 곱해지는 가중치 2개를 사용함.
◦
추가로 그렇게 곱해진 가중치를 activation function에 통과시켜 현재 state h를 구함.
•
RNN 처음 만든 사람들이 tanh를 썼기 때문에 tanh로 표기 함.
•
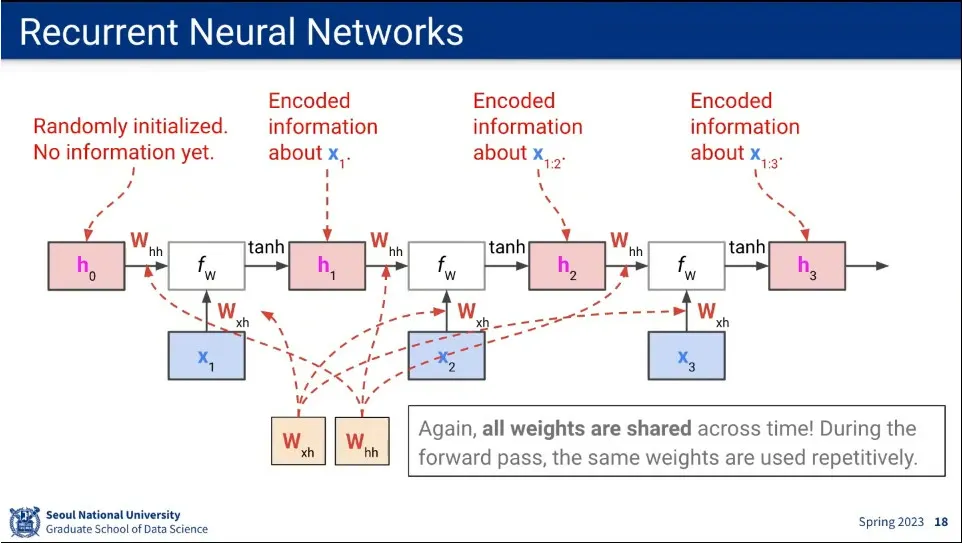
전체 과정을 펼쳐서 표현함.
◦
이때 어떤 input이 들어오든지 는 동일한 것을 사용한다.
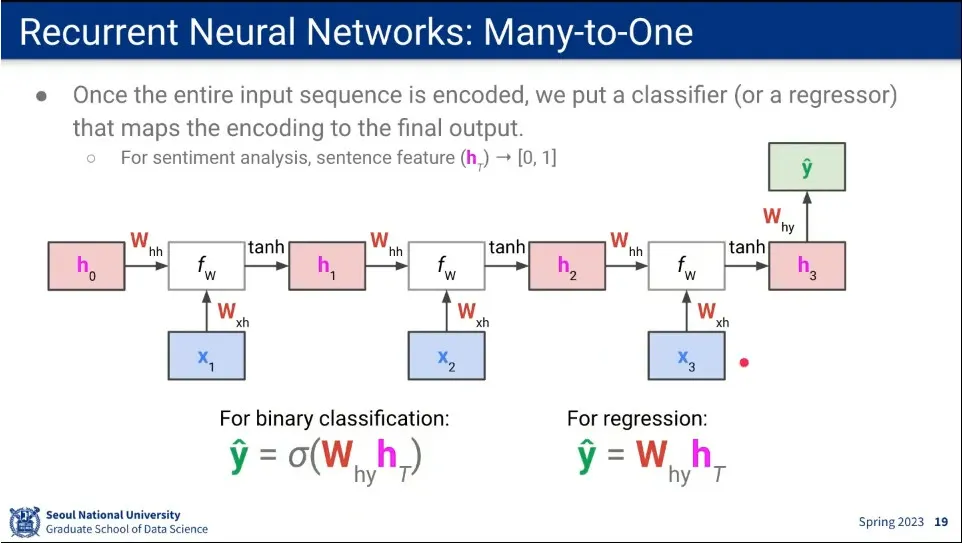
•
마지막에 분류 문제를 풀기 위해 를 하나 더 쓴다.
◦
총 3개의 가중치를 사용함.

•
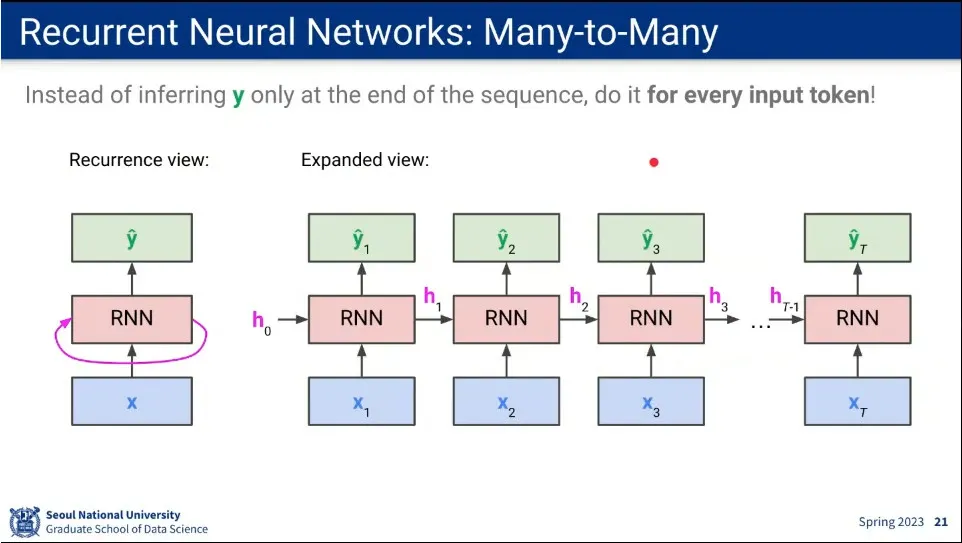
Many-to-Many의 예
◦
연속된 장면 속에서 sementic이 바뀌는 순간을 잡아내는 task
◦
영상 속에 광고를 집어 넣기 위한 용도로 사용 됨
•
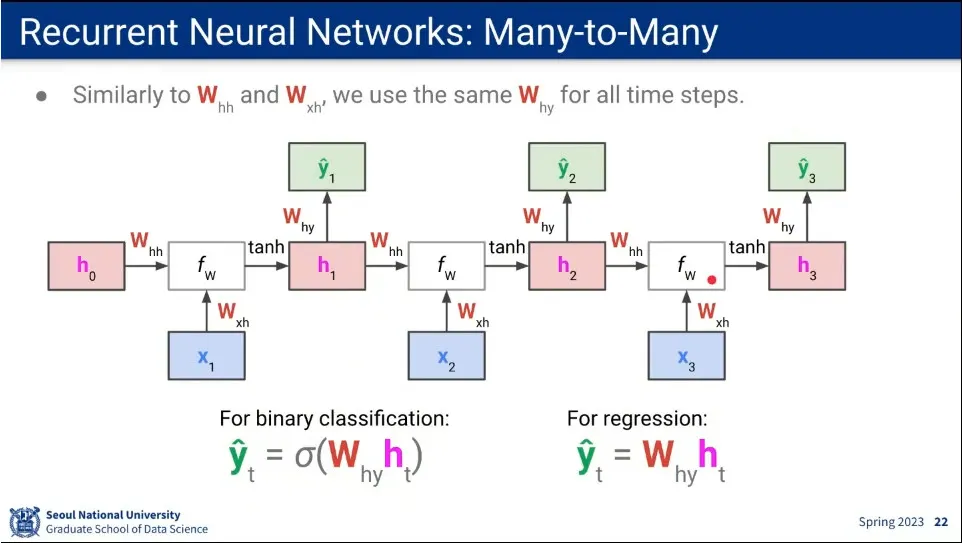
Many-to-Many의 흐름
◦
매번 를 구한다.
•
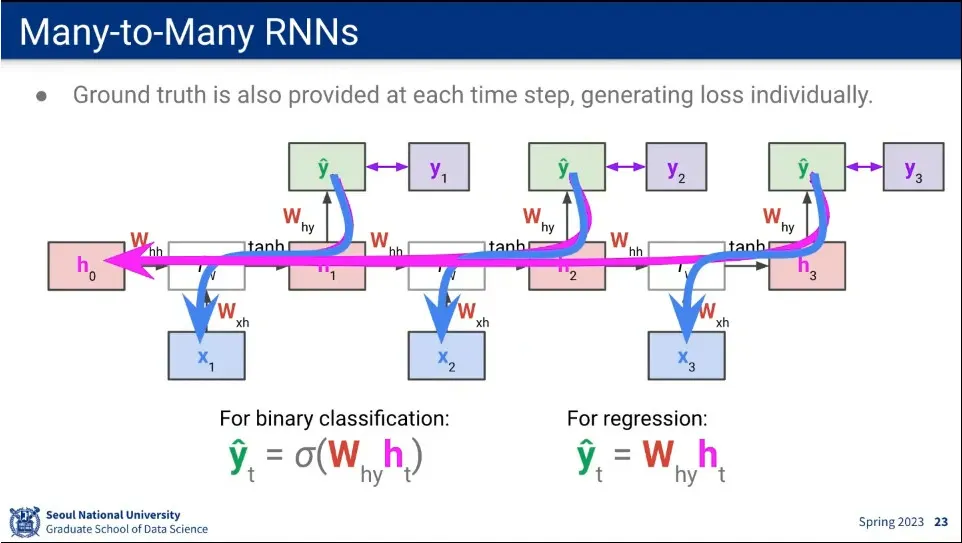
매번 를 구한다는 것을 제외하면 Many-to-One과 동일함
•
역전파는 매 예측()에 대해 적용 됨.
•
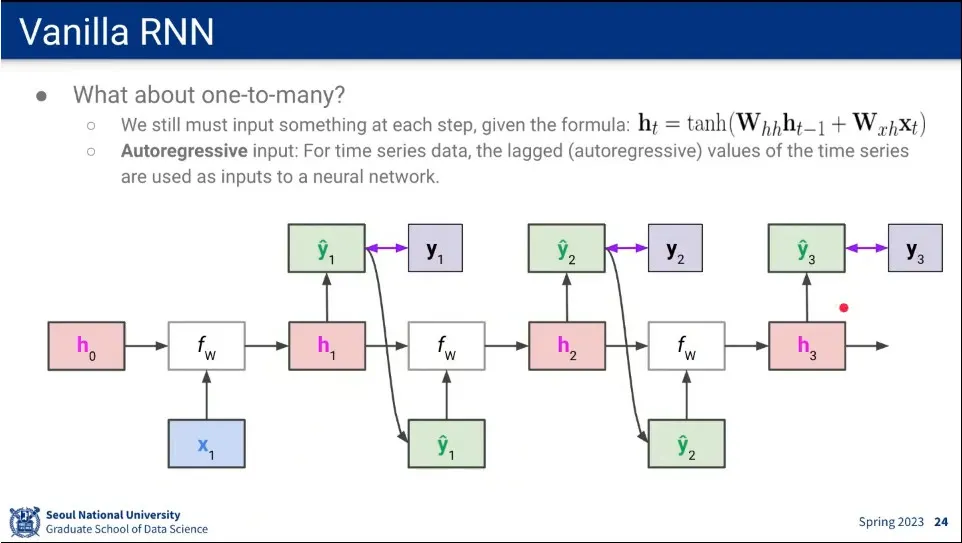
One-to-Many의 경우에는 output()을 다음 번 input으로 활용하는 식으로 한다.
•
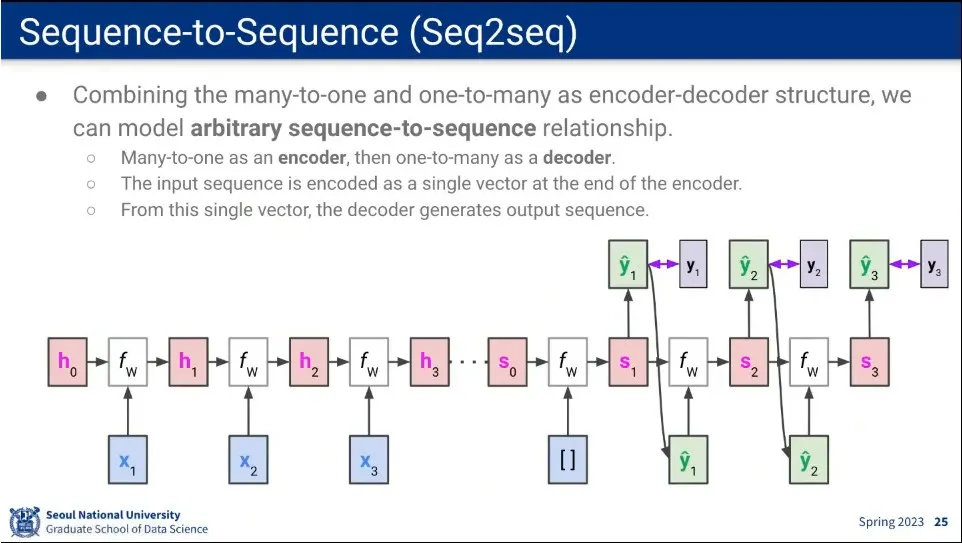
Many-to-One과 One-To-Many를 결합하면 Seq2Seq가 된다. 언어 번역이 대표적인 seq2seq
◦
이때 Many-to-One 부분을 encoder, One-To-Many 부분을 decoder라고 함.
•
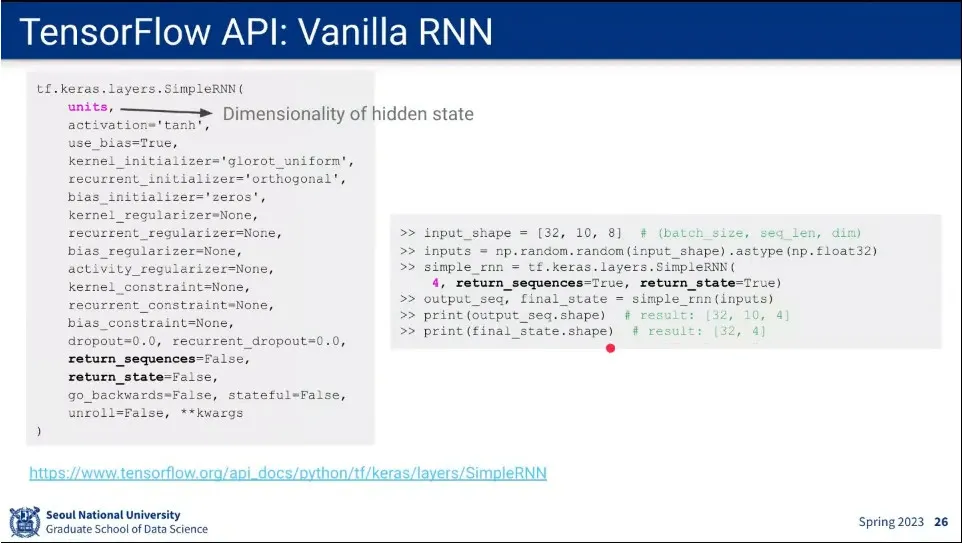
코드 예

•
RNN은 시퀀스의 길이에 관계 없이 사용할 수 있다는 장점이 있음.
◦
또한 모델의 크기가 input의 길이와 상관 없음.
•
다만 parallel하게 처리가 안되기 때문에 느리다는 단점이 있음.
◦
또한 vanishing gradient 문제가 발생할 가능성이 큼.
◦
시퀀스가 길어지면 (long-range) 처음 입력을 잃어버리는 문제가 발생

•
RNN도 여러 layer를 쌓아서 처리할 수도 있음.
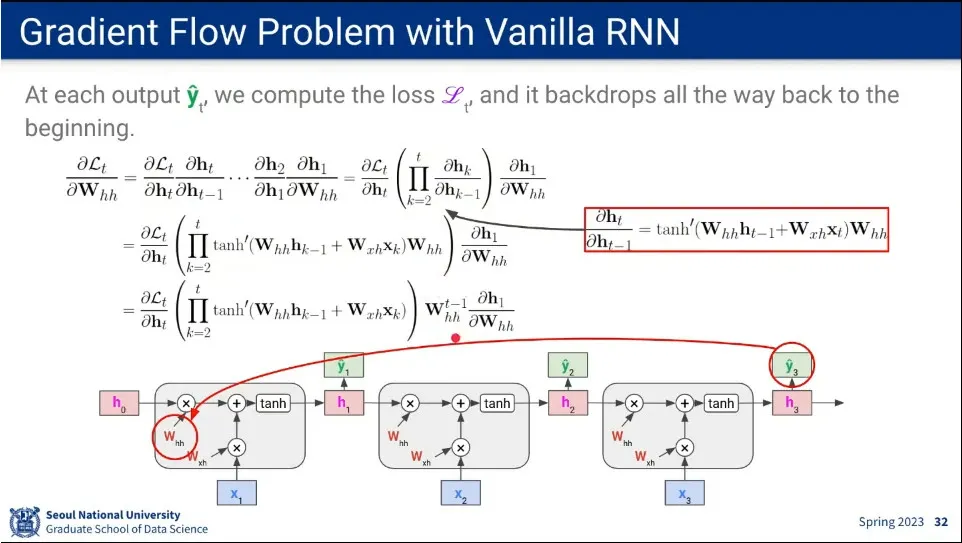
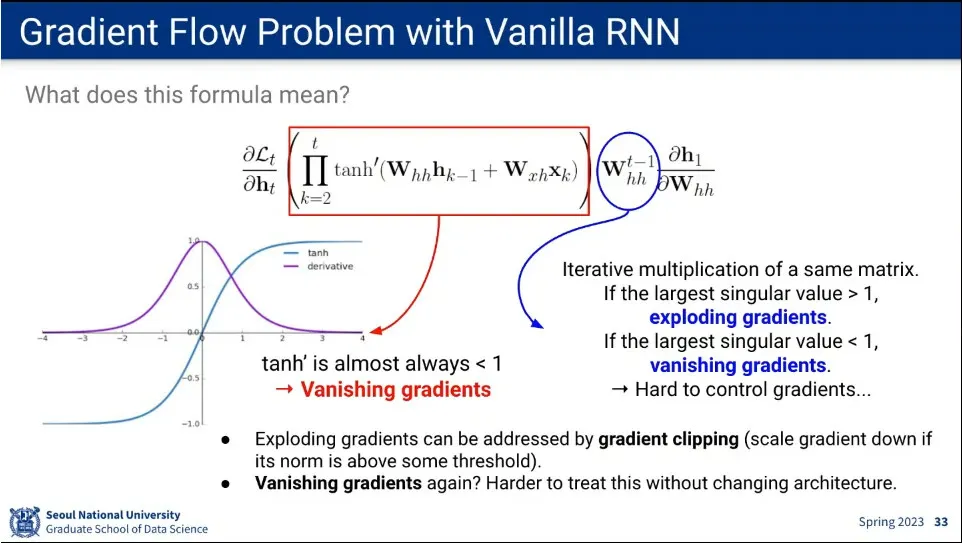
•
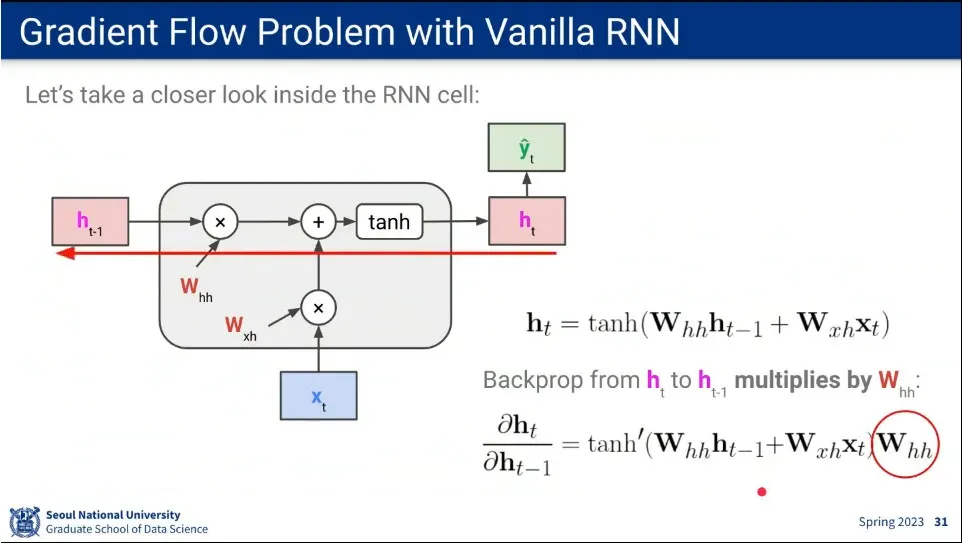
RNN의 gradient 흐름
◦
똑같은 파라미터를 쓰다 보니 시퀀스가 길어짐에 따라 vanishing gradient가 발생하게 됨. (또는 exploding gradients가 발생. 이 경우에는 clipping 해서 처리 가능)

•
LSTM을 설명하기 위한 notation 수정.
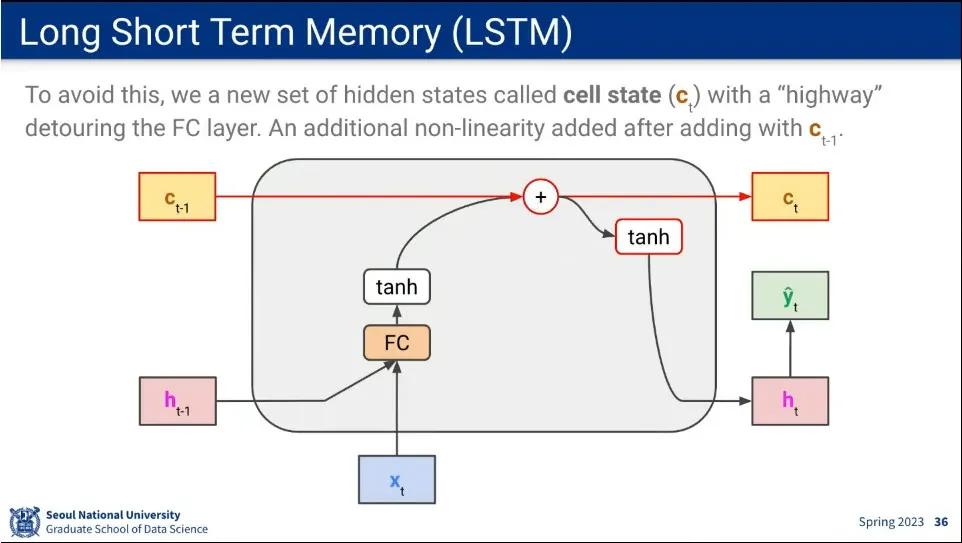
•
h가 vanishing gradient 발생하기 때문에 short term 메모리로 두고, 장기 정보를 저장할 수 있는 c state (cell state)를 따로 만들어서 long short term memory 구조를 만듦. 이게 바로 LSTM
◦
cell state는 fully-connected를 통과하지 않고, 기존 state에 값만 더해주고 넘어간다.
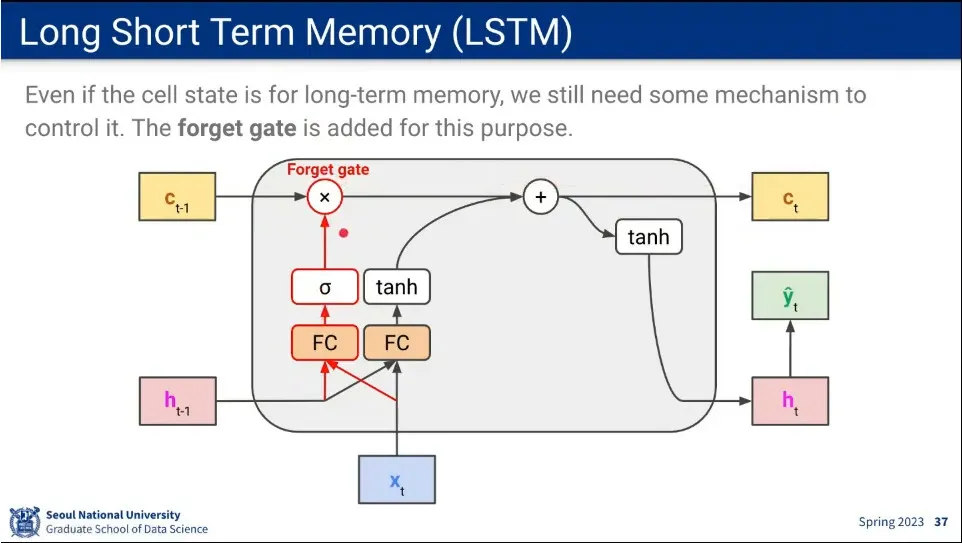
•
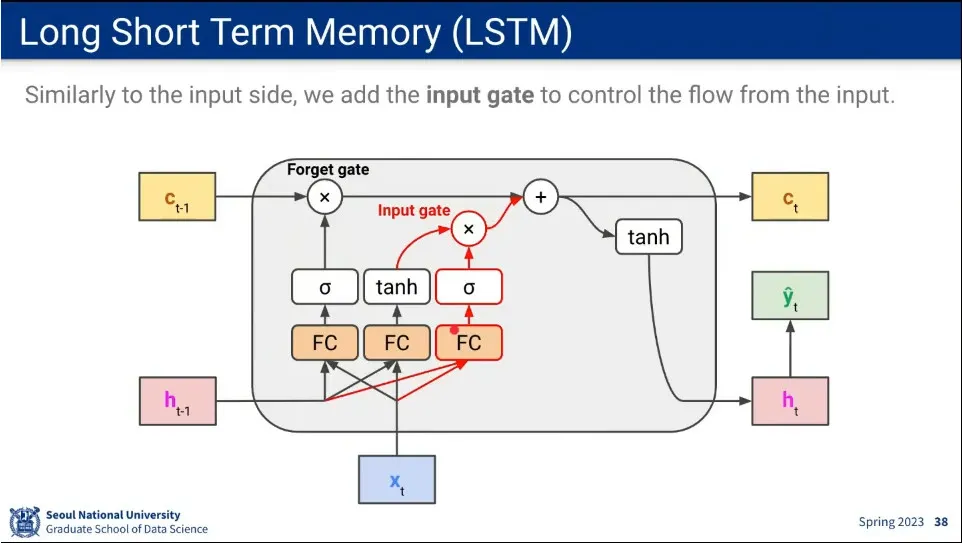
long term 메모리라고 마냥 더하기만 하기 보다는 제어를 하는게 좋기 때문에 forget gate를 추가해 줌.
◦
이것은 적절하게 이전 기억을 날려주는 역할을 하는데, 문장의 마침표를 발견하면 문장이 종료 되었으므로 이전 기억은 날리는 것이 그 예
•
새로 들어온 정보를 얼마나 반영할 것인가에 대해 input gate를 이용해서 처리 함.
•
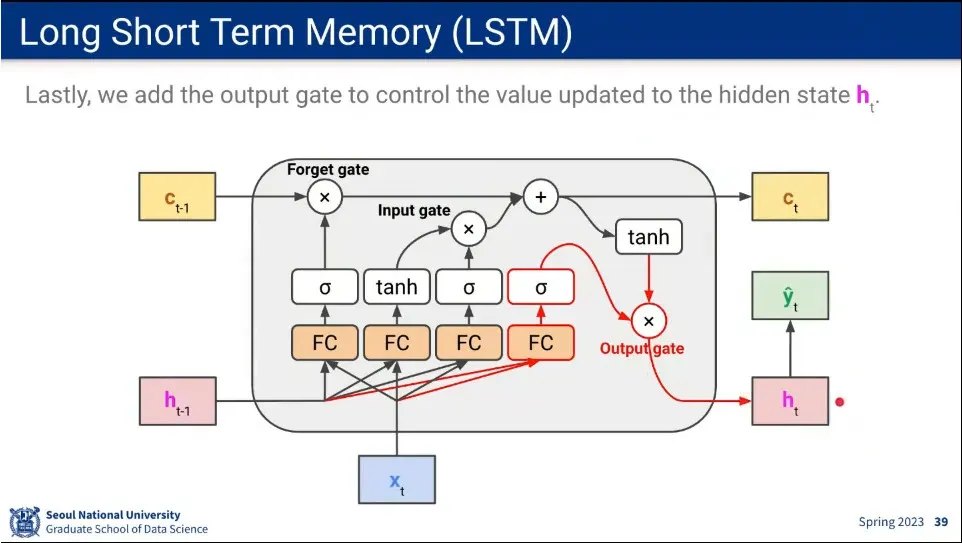
마지막으로 장기기억의 정보를 단기기억으로 가져올 수 있도록 하는게 output gate를 추가 함.

•
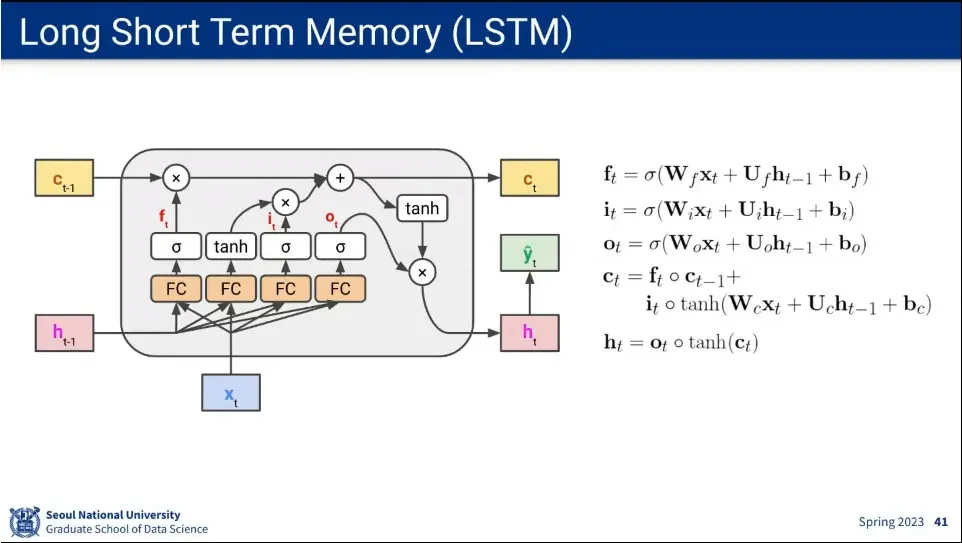
결과적으로 LSTM은 어떤 것을 장기기억으로 남길지, 어떤 정보를 받아 들일지, 어떤 정보를 단기 기억으로 가져올지를 배우게 됨.
•
각 gate에 반영되는 계산식

•
LSTM은 vanishing gradient를 완화시켜 줌.
•
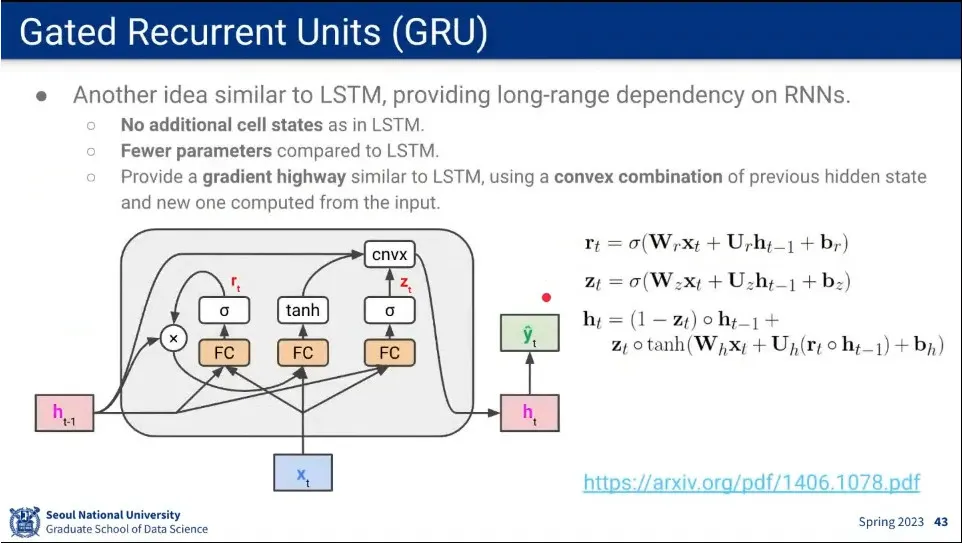
LSTM과 비슷한 개념으로 GRU라는 모델이 나옴.
◦
Cell State를 쓰지 않고 hidden state만 가지고 장기기억을 보존할 수 있도록 함.
◦
에서 로 갈 때 path를 여러개 만들고, fully-connected를 지나지 않는 경로가 장기기억을 보존하도록 함.
◦
파라미터를 덜 쓰기 때문에 계산 효율성이 좋다. 대신 성능은 조금 떨어짐.
•
코드

•
RNN을 쓰려면 LSTM을 써라
•
성능이 중요하면 GRU를 써라
•
그런데 요즘엔 Transformer를 주로 씀
