

•
supervised learning은 input에 대해 정답이 주어짐.

•
정답이 주어지지 않고, input들의 상대적인 관계 정보만 주어짐.
◦
고양이는 비행기 보다 비슷하다.

•
Metric Learning은 두 input의 semantic distance function을 학습하는 것

•
Similar 하다는 것은 상당히 상대적임. 그 유사도를 수치적으로 표현하기는 쉽지 않음.


•
유사성에 대한 common sense가 있기 때문에 위와 같이 구분해 볼 수 있음.

•
Labeling 하지 않는 것은 Labeling 비용이 비싸기 때문.
◦
상대적인 데이터들은 수집이 쉽다. pair로 만들기도 쉬움.
◦
다만 이런 데이터는 noise가 있을 수 있음. 또한 추이적(transitivity) 관계가 성립하지 않을 수 있음.

•
metric learning도 supervised 이긴 함.

•
데이터셋이 multi modal로 들어올 수 있음.

•
살펴볼 주제들

•
ranking model은 item의 순서를 정렬해 줌.

•
point-wise는 점수를 갖고 결정 함.
•
pair-wise는 2개의 item 중에 어느 것이 더 선호 되는지를 결정 함.
•
list-wise는 정렬된 list를 줌.
◦
이거는 계산량이 exponential 하게 증가하기 때문에 approximate로 pair-wise를 사용 함.

•
ranking을 매기는 과정 자체에서 embedding이 나오는데, 그걸 이용하면 다른 task에 대해서도 generalize가 됨. —representation learning.
◦
비슷한 얼굴을 묶는 task를 통해 사람의 얼굴이 비슷하다는 것을 뉴럴 네트워크가 generalize 할 수 있게 됨.

•
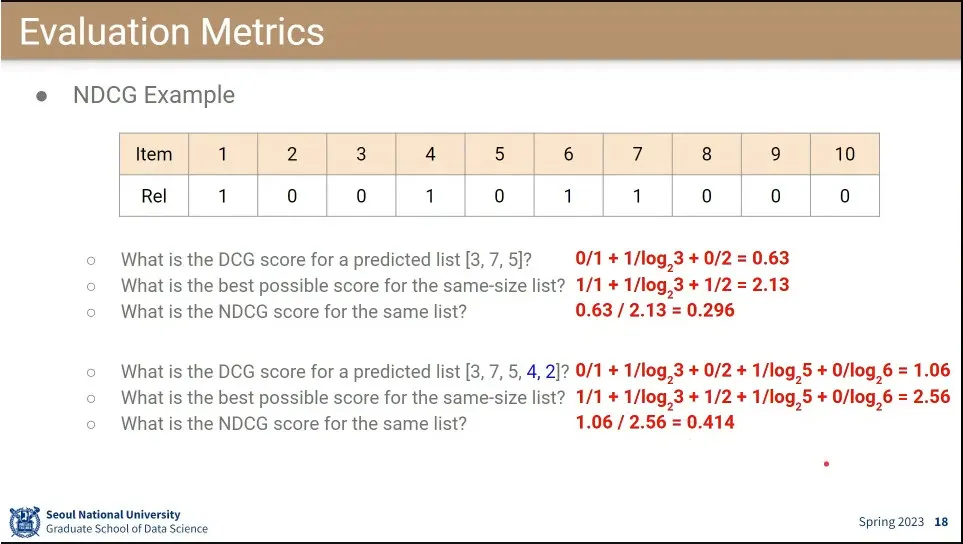
Normalized Discounted Cumulative Gain(NDCG)는 랭킹을 매기는 metric에서 많이 쓰임
◦
loss 함수는 1위를 맞출 때 점수를 많이 주고, 3등을 맞출 때 그보다 점수를 덜 주고 하는 식으로 높은 ranking에 더 높은 점수를 줌. —점수를 그냥 쓰는 경우와, 지수로 주어지는 경우가 있음.
◦
예측 점수를 가능한 최대 DCG로 나눠주기 때문에 점수는 0-1사이의 값이 나옴.
•
NDCG 계산 예
•
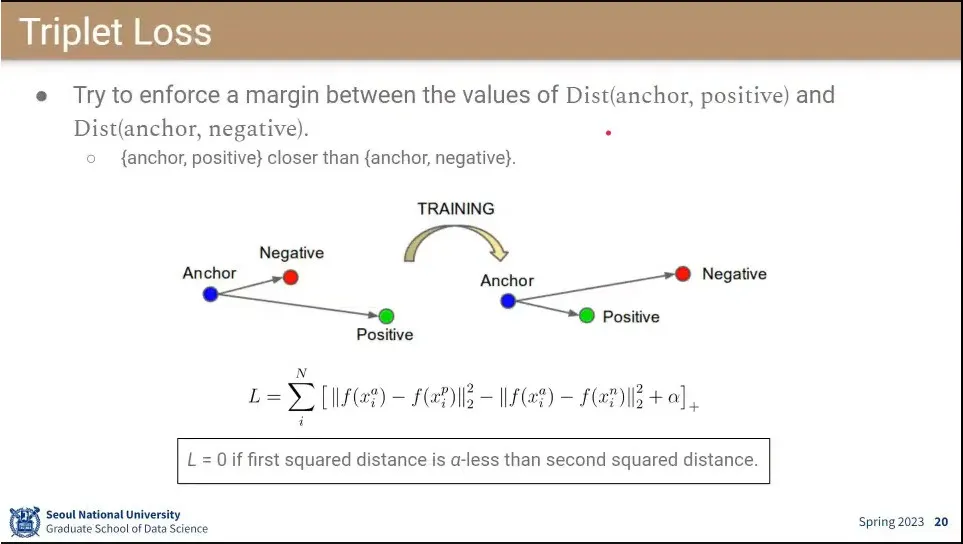
Triplet은 3개의 input(anchor, positive, negative)으로 이루어져서 triplet임.
◦
2010년대 많이 쓰였으나 현재는 다른 것을 더 많이 씀.
•
anchor-positive가 anchor-negative보다 높게 나와야 함.
◦
loss는 anchor와 positive의 값을 anchor와 negative의 값으로 뺀 결과를 최소화하도록 함. 마지막에 는 margin으로 positive와 negative의 간격을 이상 벌리도록 함.

•
positive 데이터는 많은데, negative 데이터는 수집이 어려움.
◦
그래서 positive가 아닌 것 중에 램덤으로 negative를 뽑아서 사용함.

•
문제는 그렇게 하면 너무 쉬워서 학습이 잘 안 됨.
◦
그래서 처음에는 easy triplet으로 학습 시키고 그 후에 hard triplet으로 학습을 시킴

•
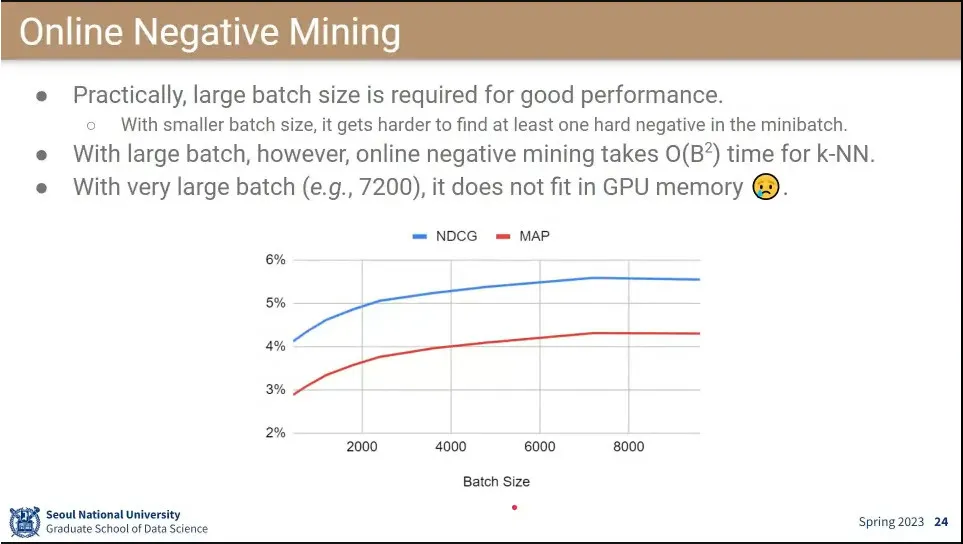
negative가 너무 쉬우면, mini-batch 단에서 현재 학습된 negative 보다 더 가까운 것을 찾아서 negative로 써서 학습 시킴. 그러면 좀 더 학습이 된다.
•
다만 negative mining을 하려면 batch size가 커야 됨.
◦
문제는 batch size가 아주 커지면 gpu에 안 올라감.

•
negative가 positive보다 가깝거나, positive 보다는 멀지만 보다는 안 멀거나, 아예 보다 먼 경우가 있는 경우
◦
positive와 사이에 존재하는 negative를 설정하는게 효과적이다. 이게 semi-hard negative mining
◦
positive 보다 가까운 negative를 주면 문제가 너무 어려워서 학습이 안 됨.
•
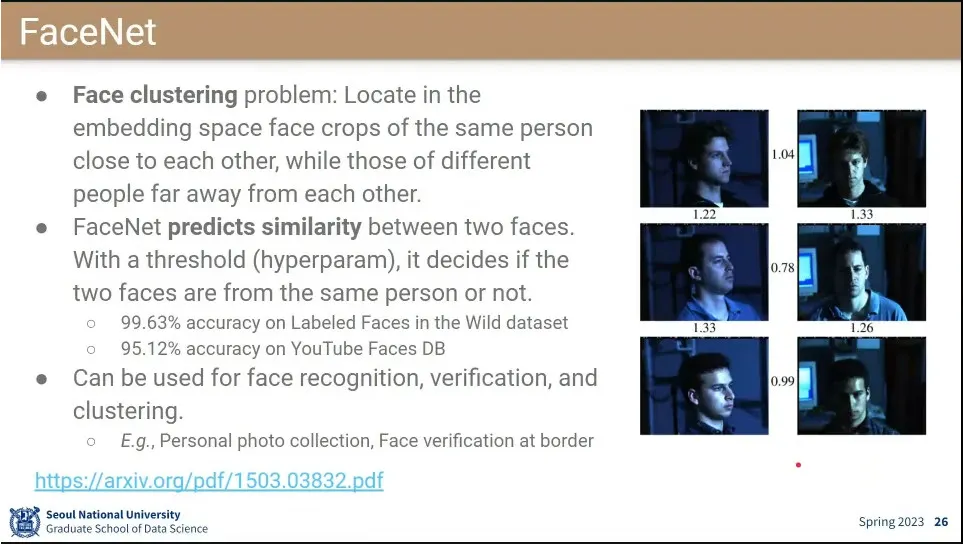
FaceNet이 처음으로 Triplet을 사용한 논문.
◦
15년에 나왔는데 그때 이미 성능이 높아서 현재 이미 널리 쓰이고 있음. 공항에서 쓰이고 있을 정도
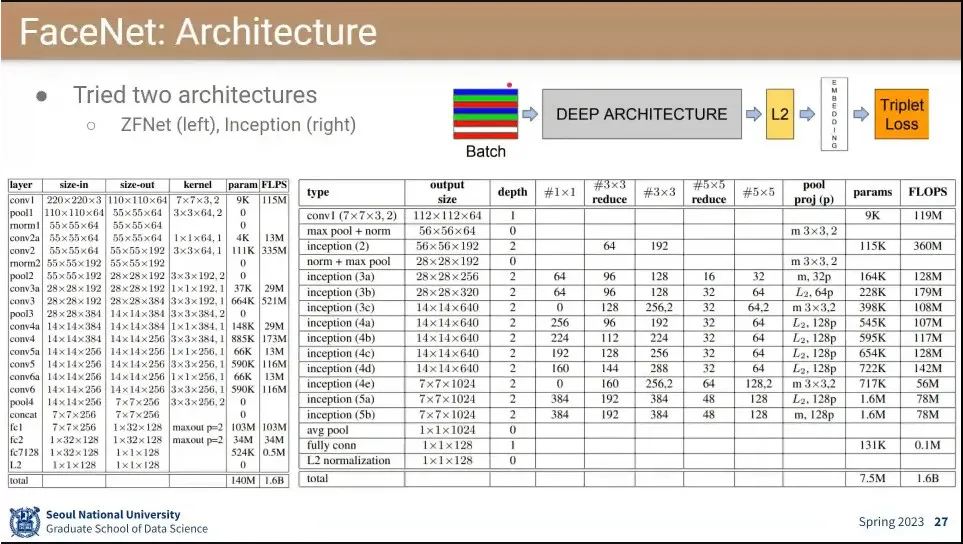
•
FaceNet의 아키텍쳐
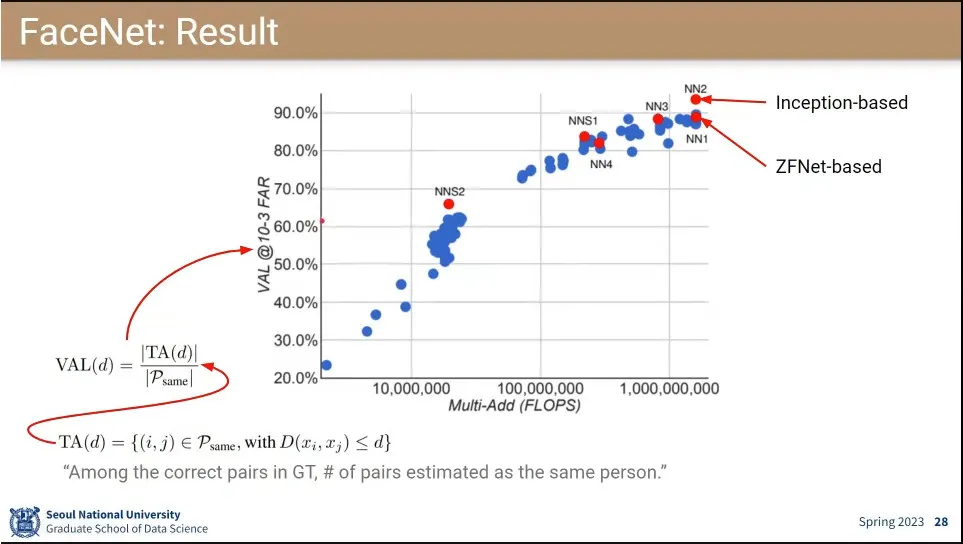
•
성능도 잘 나옴

•
FaceNet 예제
•
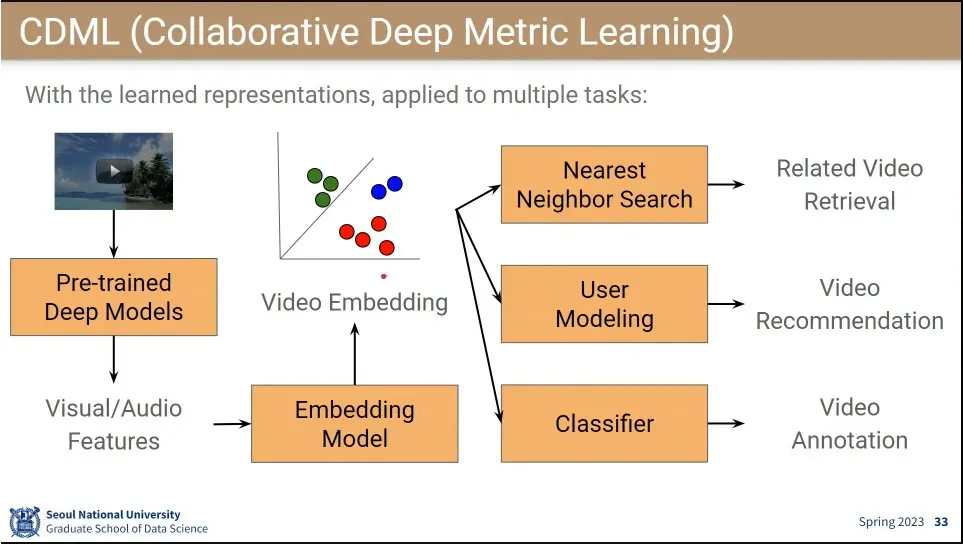
CDML은 영상에 like를 누른 사람들을 비슷한 그룹으로 모아서 그들에게 서로가 좋아한 것을 추천해 줌.
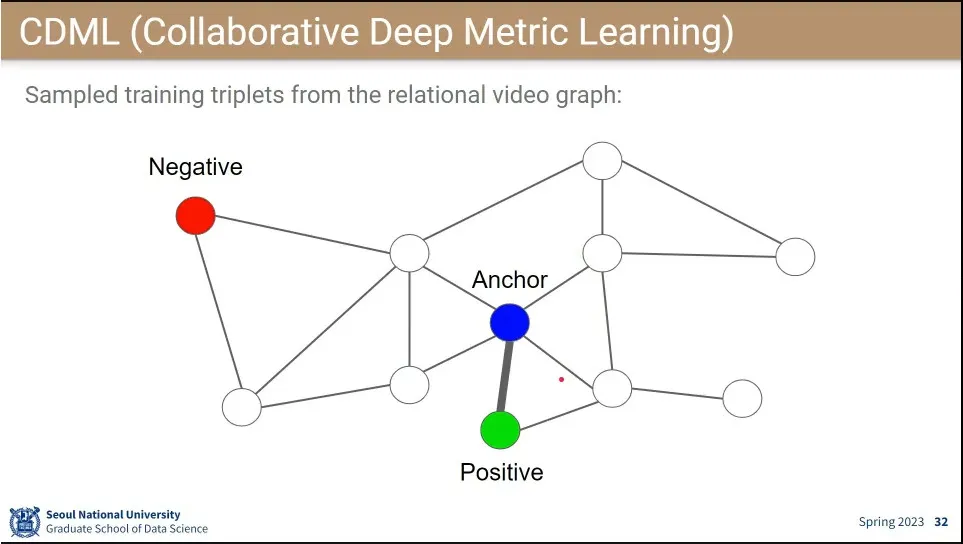
•
시청한 영상들을 graph로 표현한 뒤, achor와 연결된 것들을 positive로 연결하고, negative는 그렇지 않은 것 중에 무작위로 고름.
•
anchor와 positive는 가까이 두고 아닌 것들은 멀리 떨어뜨리는 triplet loss를 써 줌.
◦
그걸 이용하면 연관된 비디오, 비디오 추천, 분류도 할 수 있음.
•
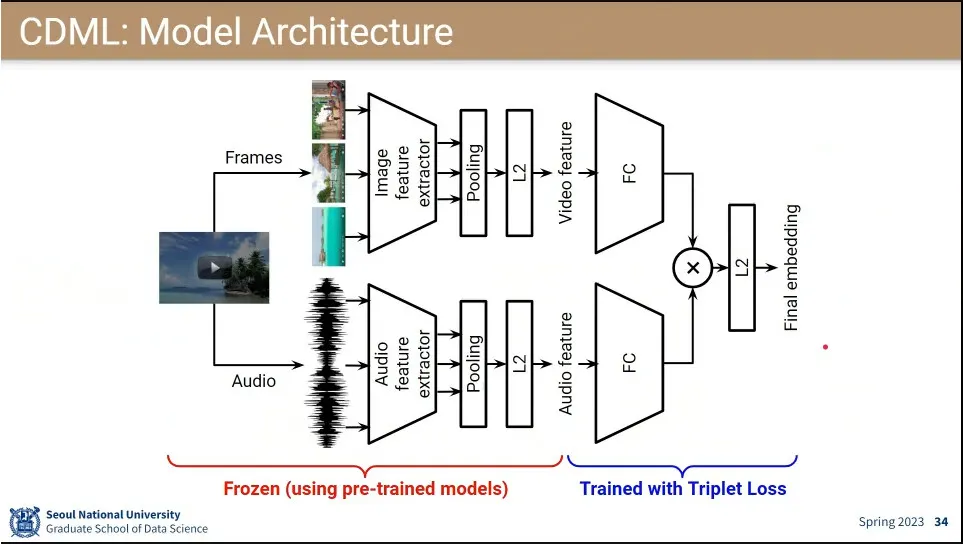
모델 아키텍쳐
◦
이미지와 오디오를 각각 학습 시켜서 fully-connected를 합친 후에 triplet loss를 줌.
◦
이때 fully-connected 이전은 freezing하고 역전파 시킴
•
사례

•
video 용량이 너무 커서 GPU에 넣을 수 없어서 CPU로 돌리면 시간이 너무 오래 걸림.
•
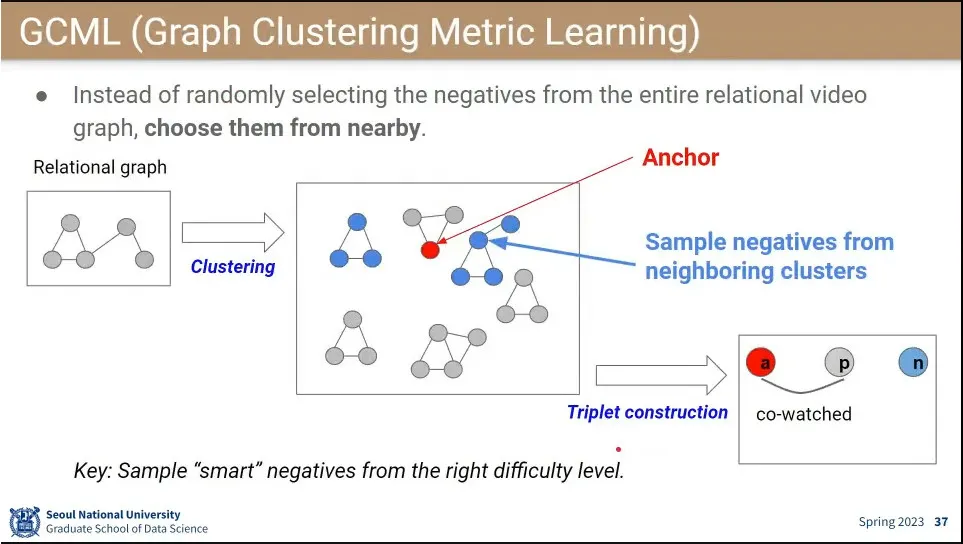
CDML을 개선해서 GCML을 만듦.
◦
negative를 랜덤으로 하지 않고, 모든 video를 clustering 해서 처리 함.
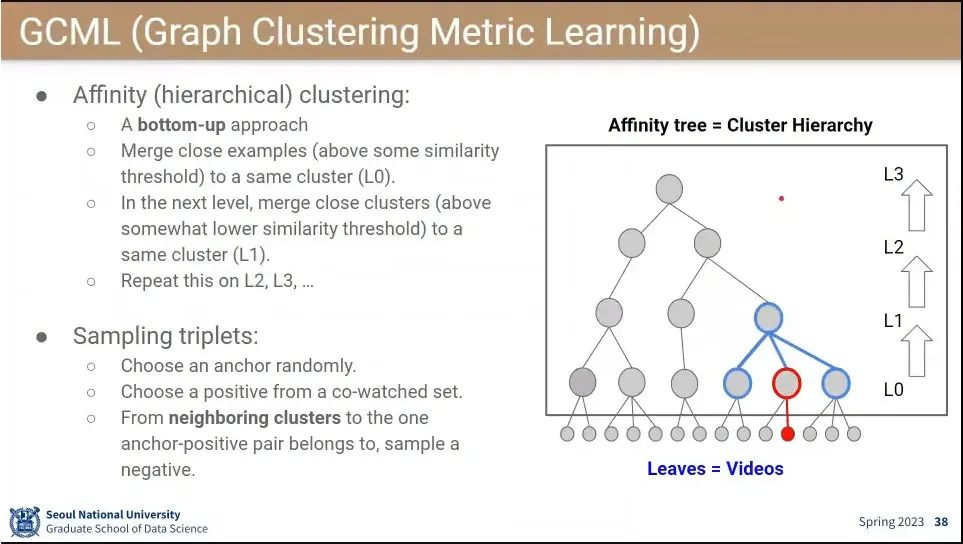
•
negative를 무작위로 고르지 않고, clustring으로 묶은 것에서 상위 단계에서 옆의 node(친척)을 negative로 잡아 줌.
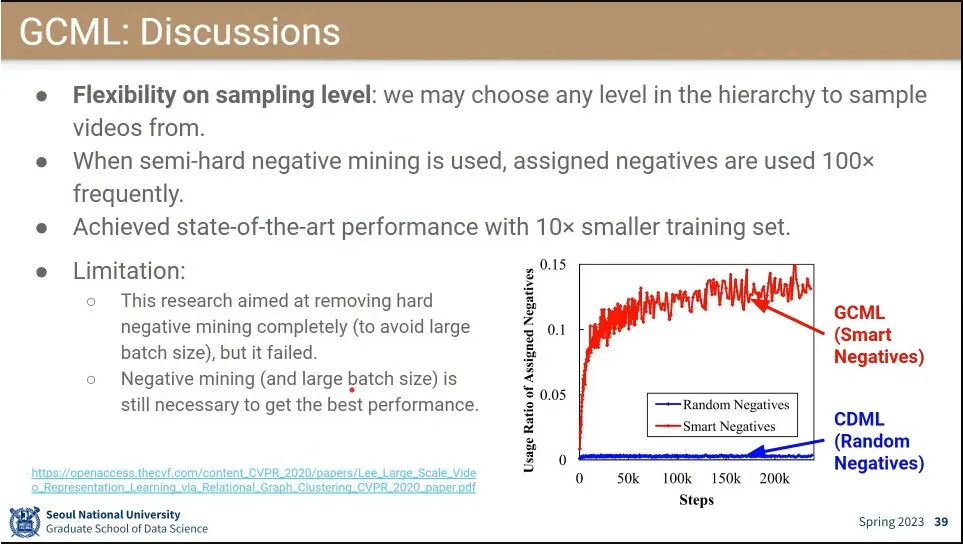
•
성과는 있었으나 의도했던 negative mining을 안하는 것은 못 함.

•
Contrastive Learning이 Triplet을 대체 함.
◦
triplet을 안 하고 2개만 쓰임. 2개가 비슷(similar)하면 0으로 만들고, 다르면(dissimilar) 1로 만드는 loss 씀
◦
similar일 떄는 그래프의 빨간색 loss, dissimilar일 때는 파란색 loss가 되도록 써서 합침.

•
similar한 경우에는 W를 줄여주고, dissimilar는 W를 증가시켜주는 방향으로 학습이 됨.

•
소프트맥스는 분모에 class들의 exponential을 씌운 합이 들어가는데, 이건 해당 클래스가 쓰이지 않는 상황에서도 분모에 남아서 영향을 줌.
◦
이게 class 수가 적을 때는 문제가 없는데, 요즘 처럼 class가 수백 만~수천 만이 되면서 계산할게 너무 많아짐.
•
‘zebra 같이 잘 안 쓰이는 데이터에 대한 계산도 매번 해야 되는가’는 의문
◦
softmax 분모의 negative를 다 쓰지 말고 sampling 해서 쓰자는 것이 아이디어. 어차피 대부분 0일 것이므로. 이때 positive인 것은 당연히 들어가야 하고 negative는 sampling 해서 사용.
•
이렇게 분모에 있는 것을 sampling 해서 쓰면 결국 contrastive learning이 된다.
◦
contrastive learning은 분자에는 positive 값이 들어가고, 분모에는 positive class가 포함된 것과 그 외의 것들을 넣어서, 분자를 키우고, 분모를 줄이는 식으로 학습하면 됨.
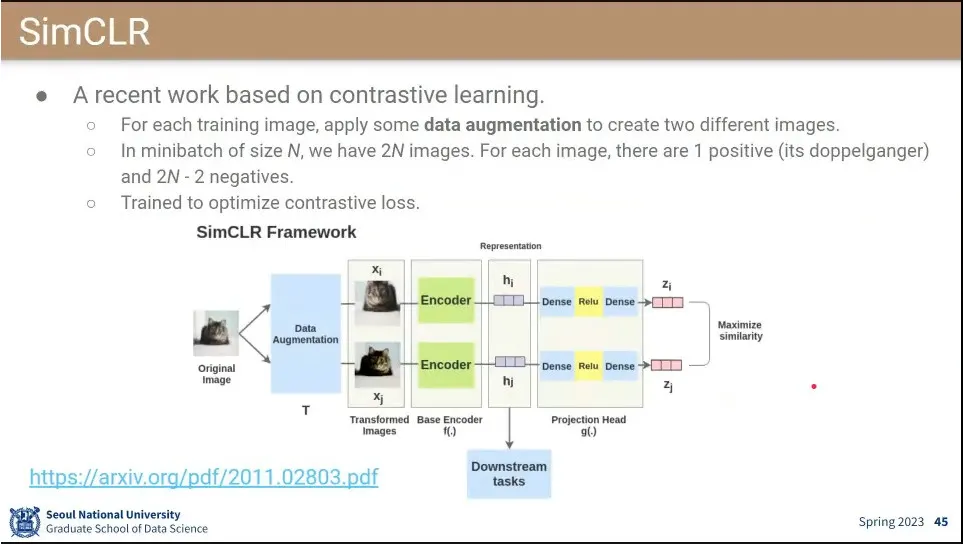
•
SimCLR이 contrastive learning을 기반으로 한 모델.
◦
positive를 수집하지 않고 Data Augmentation으로 만들어서 쓴다.
◦
일단 1차로 같은 encoder에 넣어서 embedding을 한 후에,
◦
그 후에 다시 몇 단계를 거쳐서 나온 2차 embedding 결과를 얻으면 그 둘의 similar를 계산하고 그 값을 maximize 한다.

•
분자를 positive로 두고, 분모에는 positive를 포함한 것을 두고, 분자를 키우고 분모를 줄이는게 결국 contrastive learning이 됨.
◦
분자에는 자기 자신 i와 pair인 j을 넣고, 분모에는 자기 자신 i을 제외한 나머지 것들 —이때 positive인 j도 포함됨— 을 넣어서 loss를 준다.

•
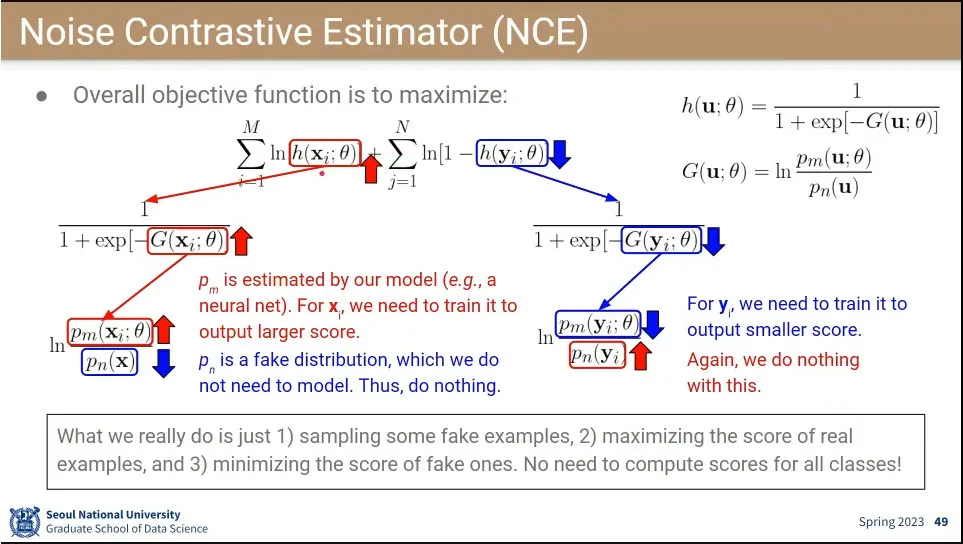
Noise Contrastive Estimator(NCE)는 softmax 대신에 binary classifier를 해보자는 접근
◦
2개의 input word가 어울릴 수 있느냐를 맞춤.
◦
실제 어울리는 두 단어와 fake로 만든 두 단어를 두고, 정말로 어울리는 단어인지 fake인지를 맞추는 것을 학습 함.

•
실제 분포와 가짜 분포를 만들고 진짜와 가짜를 다 섞은 후에 거기서 뽑은 데이터가 실제 분포에서 나온 것인지 가짜 분포에서 나오게 한 것인지를 맞추게 함.
◦
2개 중에 하나기 때문에 softmax를 안 쓰고 binary classfication으로 사용할 수 있게 함.
•
NCE의 loss 함수.
◦
진짜를 맞췄을 때가 앞의 값이 나오고, 가짜일 때는 뒤의 값이 나오는데, 둘다 logistic regression을 사용하는데,
◦
식을 따라가면 결국 분자에 존재하는 분포 를 최대화, 최소화 하는 것을 학습하게 됨.
