


Abstract
stereo rectification은 rectification을 수행하는 풍부한 전통적인 접근 때문에 ‘해결된’ 것으로 간주된다. 그러나 야생에 존재하는 자율주행과 로봇은 카메라가 wide-baseline 설정으로 정렬되어있을 때 진동과 구조적 스트레스를 포함한 다양한 환경적 요소에 노출되어 있기 때문에 지속적인 re-calibration이 필요하다. 기존의 rectification 방법은 이러한 도전적인 시나리오에서 특히 자동 화물 차량과 세미 트럭 같은 대형 차량에 대해 실패했다. 잘못된 rectification의 결과로 인해 stereo/multi-view 데이터를 사용하는 downstream 작업의 품질에 심각한 영향을 준다. 이 도전을 다루기 위해 우리는 높은 정확도와 실시간 속도로 작동하는 online rectification 접근을 제안한다. 우리는 cross-image attention으로 얻은 feature representation에서 구축된 stereo correlation volume을 활용하는 새로운 학습 기반 온라인 calibration 접근을 제안한다. 우리 모델은 proxy rectification 제약으로 vertical optical flow를 최소화하도록 학습하고 stereo 쌍 사이의 상대적인 회전을 예측한다. 이 방법은 실시간이고 offline calibration에 대해 사용될 때도 기존 방법을 능가하고 downstream stereo depth, post-rectification을 대체로 개선한다. 우리는 추가 연구를 촉진하기 위해 합성과 실험용 wide baseline 데이터셋 2개를 공개한다.
1. Introduction
wide baseline stereo 방법은 수 미터 떨어진 카메라를 사용하는 방법으로 100미터 이상의 장거리 깊이 측정을 가능케 하는 low-cost depth 센싱 방법으로 제안되었다. 자율주행 트럭, 대형 건설이나 농장 로봇이나 UAVs 등에서 활용되는 경우, 장착된 카메라는 큰 진동을 경험하고 offline calibration에서 크게 벗어난다. 따라서 online stereo calibration은 이러한 센서 시스템의 기능을 자율 의사결정 스택의 일부로 유지하는데 필수적이다. 특히 대형 장거리 차량의 경우, 온도와 스트레스 gradient 때문에 baseline 장착 구조물이 stretch되고 twist 될 수 있다. 제안 방법(그림 1 참조)에서 다루는 calibration 품질은 stereo depth 추정, 3D object detection, semantic segmentation과 SLAM 등 차량 주변 환경을 이해하는 목적의 downstream 작업에 필수적이다.

이미지가 2차원 공간에 존재하기 때문에 stereo co-planarity는 한 축의 시차를 0으로 만들고 matching 검색 공간을 1차원으로 축소시켜 효율적인 stereo matching과 stereo depth 추정을 가능하게 한다. 완벽한 stereo co-planarity을 달성하고 유지하기 어렵지만, stereo rectification은 image의 쌍을 공통 이미지 평면에 투영하여, 이미지간 해당하는 픽셀 사이에 vertical 시차가 없도록 하는 것을 목표로 한다.
기존 calibration과 rectification 방법은 일반적으로 hand-crafted와 학습 기반 feature를 사용하는 keypoint 추출과 description 방법에 의존한다. stereo rectification은 이런 전통적인 calibration 접근을 사용하여 해결될 수 있다. 한 연구 분야는 epipolar 기하학을 사용하여 rectification 제약을 공식화하고 Gradient descent와 Levenberg-Marquardt 같은 기존 최적화 기법에 의존하여 rectified stereo 쌍에 도달한다. 다른 접근은 feature 추출과 matching 기법, Fundamental Matrix 계산과 extrinsic 추정 개선에 중점을 둔다. 이런 방법 대부분은 비싼 최적화와 중간 단계 때문에 online 설정으로 배포하기에 계산적으로 허용되지 않는다. 이것들은 정확도를 타협하여 online으로 배포될 수 있지만 downstream 성능을 매우 떨어뜨린다. Dang et al 등은 3D reconstruction 같은 downstream 작업에 대한 빈곤한 extrinsic에서 에러를 전파를 광범위하게 분석했다.
이러한 제한으로 오늘날 정확한 stereo calibration 방법은 알려진 기하학적 패턴을 사용하여 설정의 intrinsic와 extrinsic를 결정하는 별도의 calibration 단계를 필요로 한다. 이러한 접근은 offline 설정에서 calibration을 필수로 하며, 센서가 사용 중일 때 겪는 환경적 영향을 무시한다. 이로인해 야생에서 추론하는 동안 downstream 작업에 대한 정확도와 성능이 크게 떨어진다.
우리는 주기적으로 센서를 re-rectify하여 빈곤한 calibration 품질을 해결하는 online rectification process를 제안한다. 이를 위해(To this end), correlation volume을 활용하여 두 카메라 사이의 상대적 포즈를 결정하는 online stereo pose 추정 모델을 제안한다. 우리는 transformer encoder를 사용하여 global context와 cross-view context에서 구축된 강력한 feature representation을 생성한다. 우리의 모델은 weak supervision과 self-supervised 방법으로 계산된 proxy rectification 제약을 사용하여 학습되었다. 우리는 vertical optical flow를 사용하여 vertical 시차의 각도를 해석하고 모델이 그것을 최소화하도록 학습한다. 게다가 우리의 새로운 self-supervised vertical flow 제약을 활용할 때 SIFT와 SuperGlue keypoint-offset 메트릭에서 40% 개선되는 것을 발견했다. 게다가 최신 stereo depth 추정 모델(DLNR, HITNet)에 대한 rectification 품질의 효과를 측정하여 이 방법을 검증한다. real-world Semi-Truck Highway 데이터셋과 KITTI 데이터셋에서 평가할 때 DLNR과 HITNet을 사용하는 depth 추정 downstream에서 MAE가 각각 63%와 51% 개선 되었다. 또한 real-world 캡쳐에서 드물게 발생하는 심각한 교란을 인공적으로 도입한 합성 Carla 데이터셋에서 이 방법의 효과성을 검증한다. 우리는 다음과 같은 기여를 한다.
•
우리는 실제와 합성 환경에서 각각 calibration 악화를 포착하는 Semi-truck Highway 운전 데이터셋과 Carla 데이터셋을 제공한다.
•
우리는 stereo correlation volume을 활용하여 stereo 쌍 사이의 상대적 pose를 추론하는 새로운 학습-기반 stereo calibration 모델을 제안한다.
•
우리는 self-supervised vertical optical flow 손실을 유도하여 높은 품질의 offline extrinsic없이 모델을 학습시킨다.
•
제안된 접근법은 keypoint-offset 메트릭과 실제 데이터에 대한 downstream stereo depth 추정에서 테스트된 모든 기존 방법을 능가하고 online 실시간 설정에서 배포가능하다.
2. Related Work
Traditional Stereo Rectification.
전통적인 stereo rectification 접근은 일반적으로 카메라의 extrinsic에 대한 prior 지식 없이 rectification homographies를 계산하는데 초점을 맞추었다. homographies는 rectification 제약의 공식에 대한 최적화를 통해 직접 계산된다. 계산 비용이 많이 들지만 Rehder et al. 등은 기존 rectification 품질을 개선하기 위한 전략으로 bundle adjustment를 목표로 했다. Hartley는 한 카메라의 epipole을 무한대으로 밀어내는 임의의 homography 행렬을 결정할 것을 제안했다. Gluchman et al은 rectification 후에 픽셀의 undersampling/oversampling을 최소화하는 최적화 전략을 제안했다. Frusiello et al.은 Sampson 에러라고도 불리는 reprojection error의 1차 근사를 최소화하여 rectification homographies를 최적화 했다. 몇몇 방법은 중간 extrinsic와 homogrphies를 더 단순한 변환으로 분해하여 개별적으로 최적화하는 방법을 조사했다.
또 다른 병렬 방향은 Fundamental Matrix 또는 extrinsic 계산을 개선하는 등 rectification에 앞서 수행되는 단계에 초점을 맞춘다. Georgiev et al.은 다양한 필터를 사용하여 잘못되거나 noisy 매칭를 제거하고, Zilly et al.은 Fundamental Matrix 계산을 테일러 급수 전개로 분해했다. 마지막으로 Dang et al은 wide baseline 시나리오에 대한 연속 online calibration을 탐구하고 빈곤한 calibration이 downstream 작업에 미치는 영향을 평가했다. 정확하지만 위의 모든 방법은 계산적으로 비싸므로 실시간 calibration으로 엄두도 낼 수 없다. 제안된 방법은 실시간이면서도 offline calibration 방법의 에러를 감소시킨다.
Learning-based Stereo Rectification.
최근에는 학습된 방법을 통해 rectification에서 에러를 우회하려는 시도가 있었다. Li et al.은 stereo 이미지에서 depth 추정을 위해 1차원 검색과 2차원 커널 기반 검색 전략을 제안했고, Luo et al은 중간 vertical correction 모듈을 도입하여 픽셀 단위 vertical correction을 제공하여 laparoscropic 이미지에서 stereo rectification을 다룬다. Ji et al은 view 합성 작업을 위해 rectification homographies를 예측하는 rectification network를 사용한다. Zhang et al.은 dedicated(전용) subnetwork에 의해 추정되고 downstream stereo matching에 사용되는 rectification homography의 4개 포인트 파라미터를 활용했다. Wang et al.은 학습된 feature 추출기를 사용하여 rectification에만 초점을 맞추었다. 이러한 모든 방법들은 직접적으로 rectification을 예측하는 대신 rectification에 대한 개선 접근을 제안한다. 우리는 이 작업에 도입된 데이터셋이 독립 작업으로서 rectification 방향의 연구를 촉진할 수 있기를 희망한다.
Learning-based Camera Pose Estimation.
Stereo rectification은 multi-view 이미지 사이의 상대적 pose 추정과도 접점이 있다. 두 겹치는 view가 주어지면 view 사이의 상대 회전과 평행 이동을 추정하도록 학습되고 결과적으로 두 view 사이의 extrinsic를 알 수 있다. PoseNet은 CNN을 사용하여 end-to-end 카메라 pose 추정을 시도한 가장 초기 시도 중 하나였다. PoseNet에 구축된 몇몇 작업은 평행 이동과 회전의 손실을 균형을 잡고 아키텍쳐 변형을 도입한다. 최근에 DirectionNet은 회전에 대한 연속 표현으로 quaternion을 최적화하는 방법을 탐구 했다. 다른 작업들은 coarse(거친) 초기화에서 포즈 추정을 개선하도록 flow를 통합한다. 이러한 방법들은 소스 이미지를 target 프레임으로 warp 하는 반면, 우리는 rectification 품질을 암시적으로 포착하는 vertical flow를 직접 최적화한다.
몇몇 접근은 기존 전통적인 접근에 학습된 컴포넌트를 통합하는 방법을 탐구한다. 예컨대 DSAC는 미분가능한 RANSAC 방법이다. 유사하게 Ling et al은 SuperGlue에서 feature 매칭과 descriptor가 주어지면 Fundamental Matrix를 추정하는 학습된 모델을 제안한다. Rockwell et al은 ViT를 사용하여 stereo 이미지 패치 사이의 cross attention 가중치를 추정한 다음에 마지막으로 Essential Matrix의 SVD 분해에서 얻어진 orthonormal 기저를 직접 추정하여 pose를 회귀한다. Roessle et al.은 SuperGlue에서 영감을 얻어 multi-view 이미지에 전반에 걸쳐 feature 대응 관계를 구축하는 graph 모델을 제안하며, 이어서 8-point 알고리즘을 사용한 coarse 포즈 추정과 bundle adjustment 단계를 추정을 개선한다. Arnold et al은 학습된 depth 추정 모델과 pose 추정에 대한 cost volume 기반 접근을 loop에 통합하여 2D-2D, 3D-3D 대응관계를 탐구한다. 이러한 기존 pose 추정 방법은 rectification 제약조건을 최적화하지 않지만 3D 포즈 또는 epipolar 제약을 최적화한다. 우리는 rectification에 pose 추정을 적용하면 빈곤한 결과를 얻는다는 것을 발견했다. 섹션 5 참조.
3. Flow-Guided Online Rectification
이 섹션에서 online rectification 모델과 flow-guided 학습 접근을 소개한다. Local feature 기반 pose 추정 방법은 고속도로 트럭 주행 시나리오에서 rolling-shutter 효과와 기계적 진동이 결합되어 빈곤하게 수행될 수 있다. 이 도전을 해결하기 위해 우리는 cross attentional 이미지 feature와 stereo cost volume을 활용하여 stereo 쌍에서 pose를 직접 예측하고 pose에 대해 최적화 한다. 게다가 real 데이터에 대해 우리는 강한 진동 때문에 고속도로 운전 시나리오에서 유지되지 않는 정적 offline calibration만 수행할 수 있다. 이를 위해 self-supervised vertical flow 손실에 의존하고 offline calibration을 semi-supervised rotation loss로 사용한다. 빈곤한 회전은 downstream task에 큰 영향을 미칠 수 있고, stereo baseline은 고정되므로 우리의 모델은 stereo 쌍에서 상대적 회전을 추정하도록 학습한다.
그림 2는 모델 아키텍쳐와 학습 프로세스를 보인다. 모델은 이미지의 쌍을 입력으로 받아 공유된 CNN을 통해 shift-equivariant feature를 추출한다. 추출된 feature는 이전 추정이나 identity로 설정된 prior pose 추정을 사용하여 rectified 된다. 이어서 positional embedding 단계와 transformer encoder로 구성된 feature enhancement 단계(그림 2.b)가 있다. transformer 인코더는 self-attention과 cross-attention을 사용하여 두 view에 걸친 global 정보를 포착한다. 다음으로 correlation volume(그림 2(c))을 활용하여 transformer 인코더에서 추출된 feature을 기반으로 matching을 수립한다. 이 volume은 feature map의 모든 픽셀에 대한 matching 분포를 나타낸다. correlation volume은 decoder에 의해 처리되어 noisy matching을 식별하고 단순화된 회전 추정을 예측하는 방법을 암시적으로 학습한다. 이것은 추가 처리를 거쳐 최종 상대적 회전 예측으로 이어진다. 이것이 주어지면 입력 이미지를 rectify하고 optical flow를 추정한다. 이 flow 추정을 사용하여 그림 2(e)의 vertical flow를 최소화한다.
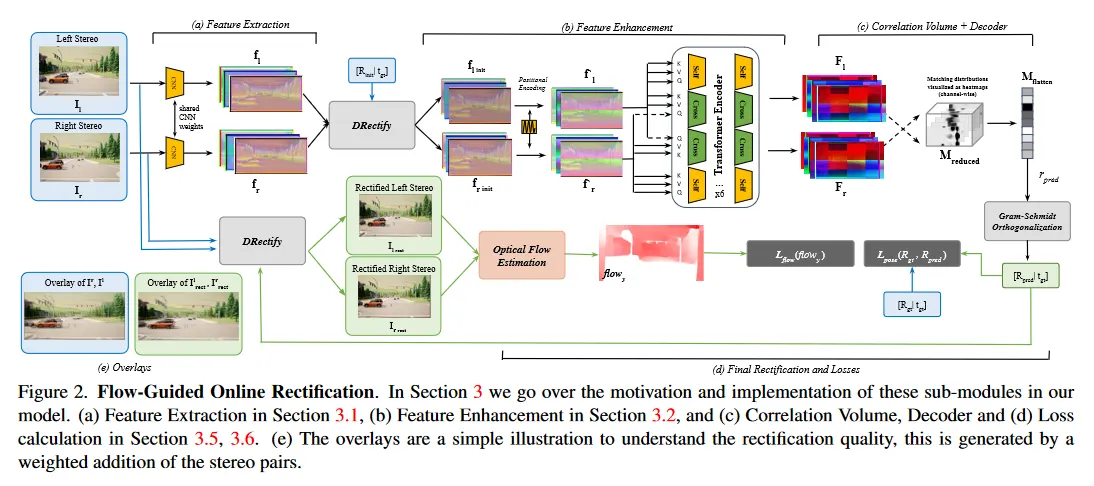
3.1. Feature Extraction
stereo 쌍 이 주어지면, weighted-shared CNN 백본을 사용하여 이미지를 인코딩한다. 백본은 3개의 residual convolution block으로 구성되며 feature map의 쌍 을 생성한다. 이 feature들은 convolution 연산이 본질적으로 local이라는 사실 때문에 globally 식별 가능한 feature를 포착하는데 한계가 있다. global representaion이 ambiguos(모호한) 매칭을 줄이는데 중요하지만, 저차원 feature는 이어지는 단계에서 계산과 메모리 이점을 제공한다. 제안된 방법은 실시간을 제공하면서 global feature를 추출한다.
3.2. Positional Feature Enhancement
우리는 transformer 모델에서 영감을 얻어 positional encoding, 구체적으로 2D sine과 cosine 인코딩(DETR과 같은)을 사용한다. positional encoding은 CNN feature map 에 직접 더해져서 matching시 feature 유사성 외에도 공간 정보의 추가 레이어를 추가한다. 이는 모델 match feature가 결국 이러한 feature의 공간적 매핑인 상대적 pose를 더 일관되게 추정하는데 도움이 된다.
우리는 다음을 인코딩한다.
여기서 . 이어서 feature enhancement transformer를 적용한다. encoder는 6개 self-attention block과 6개 cross-attention block과 feed-forward network으로 구성된다. self-attention phase에서 keys, queries, values는 동일한 feature map에서 오는 반면 cross-attention map은 2개 features에 걸쳐 추정되며, 특히 한 feature 집합에서 key-value 쌍을 유지하고 다른 feature map에서 query 한다. 또한 SWIN transformer를 사용하는 windowed 접근과 달리 전체 feature 맵에 걸쳐 attention map을 계산하여, fine-grained global matching을 강화한다.
여기서 는 transformer encoder이고 는 Key, Value, Query 입력에 해당한다. enhanced feature 은 섹션 3.4에서 설명하는 단계에 사용된다.
우리는 초기 rectification 단계인 후에 위에서 언급된 positional feature enhancement를 수행한다. 즉
여기서 은 identity(우리 실험에서 사용된)이거나 이전 추정에서의 rotation일 수 있다. 이어서 은 이 섹션에서 설명된 단계에 따라 에서 계산된다. 이를 통해 pose 변화를 어느 정도 표준화할 수 있으며, 더 나아가 섹션 3.5에서 설명한대로 에 적용된 보정으로 모델 예측을 공식화할 수 있다.
3.3. Differentiable Rectification
우리 모델에서 핵심 컴포넌트는 미분가능한 rectification 모듈 이다. 이를 통해 end-to-end 학습이 가능해지며 모델 pose 예측에서 rectified 이미지를 추론할 수 있다. 이는 다시 학습하는 동안 모델에 rectification 제약을 추가할 수 있게 해준다.
이 연산을 정의하기 위해 2개 이미지 와 센서 사이의 상대적 pose , intrinsic 를 가정하고 rectification rotation 를 사용하여 를 공통 이미지 plane에 투영하여 를 얻는 것을 목표로 한다. 이를 다음과 같이 나눈다.
Estimating Rectification Rotations.
상대적 pose 정보 가 주어지면 이 단계는 horizontal baseline 가정을 사용하여 각 이미지 에 대한 회전 을 계산하는 작업이 포함된다.
Rectifying Images.
에 대한 rectification 회전 이 주어지면, 이 회전을 사용하여 이미지를 reproject하고 미분가능한 grid-sampling을 사용하여 새로운 픽셀의 위치를 샘플링하여 를 생성한다.
이 두 단계에 대한 자세한 수학적 공식화는 보충 자료에 설명되어 있다.
3.4. Correlation Volume
correlation volume을 사용하여 enhanced feature map에 걸쳐 global feature matching을 허용한다. 우리는 두 feature 맵 을 를 따라 평탄화한 다음, 다음과 같이 correlation을 계산한다.
평탄화된 feature map에 걸쳐 계산된 이 correlation volume은 과 에 걸쳐 일치하는 항목을 암시적으로 나타낸다. 이 representation을 더욱 단순화하기 위해 의 마지막 2개 차원을 따라 softmax를 적용한다.
는 의 특정 위치와 의 모든 위치가 일치할 likelihood를 나타낸다. 다음과 같이 decoder에서 를 추가로 처리하여 모델이 reliable과 un-reliable 일치를 학습하도록 한다.
3.5. Decoder and Final Rectification
decoder 레이어는 6개의 3D convolution과 Average Pooling layer의 결합으로 구성된다. 그 결과 는 로 인코딩된 분포에서 가장 가능성 높은 매칭을 나타낸다. 그런 다음 를 평탄화하여 을 생성하고, 이를 최종 선형 레이어에서 전달하여 상대적 회전 를 예측한다. 우리의 모델이 회전 행렬의 요소를 직접 예측하도록 시도하기 때문에 연산자는 예측을 범위로 유지하여 안정적으로 만든다. 우리는 다음과 같이 한다.
Chen et al에서 광범위한 분석을 차용하여 회전 행렬의 와 열을 예측하는 것에 초점을 맞춘 6차원 표현을 사용하기로 선택한다. 이 단계 뒤에는 Gram-Schimidt orthogonalization가 이어진다. 와 열이 로 가정하면
다음으로 에서 와 열을 로 추출하고 다음을 찾는다.
이것은 입력 stereo 쌍 을 다음처럼 rectify하는데 사용될 수 있는 유효한 회전 행렬이다.
여기서 는 ground truth pose 정보에서 재사용된다.
3.6. Training
다음으로 우리 모델을 학습하는데 사용된 2개의 주요 loss 함수를 설명한다. 우리는 간편함을 위해 이전 섹션에서 표기를 그대로 사용한다. 완전한 loss 함수는 다음과 같다.
여기서 은 스칼라 가중치이다. 여기서 은 ground truth calibration 데이터에 대한 supervised pose loss이고 는 self-supervised vertical-flow loss이다.
Self-supervised Vertical Flow Loss.
rectified 이미지 쌍이 주어지면 KITTI에서 pre-trained 된 RAFT을 사용하여 x축과 y축에서 flow를 추론한다. 이 loss 함수는 self-supervised이고 모델이 stable/valid 회전 추정을 예측하는 경우 안정적이다. optical flow가 이미지에 걸쳐 밀집 대응 관계를 설정하는 간접적 방법이기 때문에, 이 flow를 활용하여 암시적으로 rectification 제약을 추가할 수 있다. rectification의 목표가 수직축을 따른 시차를 0으로 만드는 것이므로, vertical flow 컴포넌트에는 수직 시차 존재에 여부에 관한 정보가 포함된다. 따라서 우리의 loss 함수 컴포넌트는 다음과 같이 설계된다.
이고 은 이미지에서 픽셀의 전체 수이다. 흥미롭게도 이 loss 함수는 rectify vertical stereo 설정에도 적용 가능하다. 여기서 목표는 대신 를 최소화하는 것이다.
Rotation Loss.
우리는 또한 회전 행렬 의 ground truth 추정을 사용하여, 두 번째 supervised loss를 사용한다. 우리는 loss를 사용하여 다음을 산출한다.
loss는 학습의 초기 단계에서 핵심적인 역할을 한다. 모델이 가능한 회전 추정을 좁힐 수 있게 해주어 합리적으로 안정적인 회전 예측이 얻어질 때까지 위의 self-supervised flow loss가 지배적이 된다.
3.7. Implementation
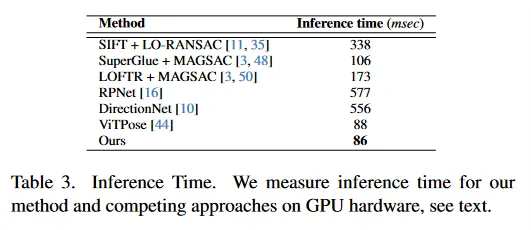
우리는 를 포함하여 우리의 모델을 PyTorch 프레임워크에서 구현한다. 모델은 데이터셋과 이미지 사이의 misalignment에 따라 80-140 epoch 동안 학습된다. 우리는 Adam Optimizer를 exponential decay와 결합된 의 학습률로 사용한다. 데이터에 brightness, contrast, color perturbation을 증강으로 적용하고, 왼쪽-오른쪽 stereo 쌍을 교체하는 추가적인 증강도 한다. 배치 크기 16으로 2개의 NVIDIA A40 GPU에서 학습했다. 입력 해상도는 1024x512 픽셀이고, 메인 모델이 하나의 GPU에서 학습되는 동안, 512x256 해상도의 이미지에 대해 추론을 실행하는 두 번째 GPU에서 flow 추정을 실행했다. 표 3의 모든 추론 시간 벤치마크는 배치 크기 1의 NVIDIA-A40 GPU에서 수행된다.
4. Stereo Rectification Datasets
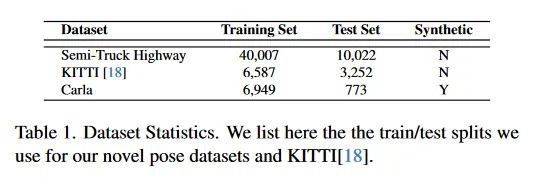
이어지는 섹션에서 방법을 학습하고 평가하는데 사용한 real-world와 합성 데이터셋을 설명한다. 두 데이터셋 모두 높은 scene 다양성과 연관된 작업의 난이도에 주목하라. 자세한 내용은 부록 참조. 그림 3은 데이터셋의 샘플을 리포트하고 표 1은 학습-테스트 분할을 나열한다. 두 데이터셋 모두 서로 다양한 시퀀스/레코딩에서 데이터의 샘플을 포함하므로 데이터셋의 모든 프레임이 고유한 프레임임을 의미한다.

4.1. Semi-Truck Highway Dataset (Real)
Setup.
stereo 설정은 땅에서 약 3m 높이에 대형 세미트럭에 장착된다. 카메라는 조정 가능한 custom mount를 사용하여 rigid bar에 장착되고 운전의 시작과 끝에서 정확성을 보장하기 위해 calibration을 수행한다. 이 데이터셋에서 사용된 주요 센서는 약 1/2인치 CMOS 센서를 기반으로 RCCB format의 raw 데이터를 레코딩하는 OnSemi AR0820 카메라이다. 우리의 설정은 baseline을 0.6m와 0.7m 사이로 변하는 2m wide baseline 배열의 동기화된 4개 AR0820s으로 구성된다. 카메라 3848x2168 픽셀 해상도에서 15Hz로 이미지를 레코딩한다.
Scene Diversity.
데이터셋은 New Mexico와 Virginia의 geographically 다양한 지역에서 기록으로 구성된다. 데이터셋은 고속도로와 도시 지역에서 다양한 scene들로 구성되지만, 캡쳐 차량이 세미트럭이므로 밀집한 도시 scene의 샘플은 수집되지 않았다. 또한 오후, 저녁과 야간 시나리오에 이르기까지 다양한 조명 조건의 데이터를 제공한다.
이 데이터셋은 50,029개의 유니크 stereo 쌍으로 구성된다. 우리는 4개 카메라로 캡쳐하고 각 카메라에 대한 offline 보정 파라미터를 제공한다. 4개 카메라 설정을 통해 최대 6가지 다양한 stereo 쌍의 조합을 사용하거나 심지어 3개나 4개 카메라를 동시에 사용할 수 있다. 이것은 rectification 작업을 고려할 때 두 카메라 사이의 상대적 포즈(calibration에서) 에러가 고유하기 때문에 필수적이다. 데이터는 빈곤한 rectification quality 때문에 downstream stereo 작업이 inadequately(부적절하게) 수행된 시나리오에서 샘플링된다. 수집된 데이터는 장거리 운행 시 online rectification 접근법의 필요성을 입증한다.
4.2. Carla Dataset (Synthetic)
Setup.
알려진 ground truth pose 정보와 real capture에서는 희귀한 극단적인 pose 편차를 시뮬레이션 하는 능력을 가진 Carla 주행 시뮬레이터를 활용하여 추가로 합성 데이터셋을 생성한다. 여기서 sensor 설정은 regular 교통 차량에 장착된 각 0.8m의 baseline으로 분리된 3개 RGB 카메라로 구성된다. 각 카메라는 2560x1440 해상도의 이미지를 30hz로 캡쳐한다.
Scene Diversity.
우리는 traffic이 있는 대부분 도시 환경과 일부 추가 고속도로 scene에서 시뮬레이션한다. 다양성을 추가하는 측면에서 Carla의 조명과 날씨 제어 기능을 활용하여 다양한 환경 효과를 갖는 무작위 scene을 생성한다. trucking 데이터셋과 유사하게 새벽, 아침, 낮, 황혼 등 다양한 자연 조건의 scene들을 캡쳐한다. 또한 안개, 비, 흐린 날씨, 맑은 날씨 등 무작위 날씨도 추가한다. 시나리오가 전체 레코딩 동안 바뀌지 않기 때문에 이를 통해 조명과 날씨 조건이 다른 매우 유사한 scene이 생성된다.
이 데이터셋은 7,722 stereo 쌍으로 구성되고, trucking 데이터셋과 비교하여 더 작지만, 회전의 3개 축 모두에서 도 범위의 상당한 교란을 도입하여 평가 난이도를 높였다. 이를 통해 대부분의 rectification 접근에서 견고함(또는 견고함 부족)을 지시할 수 있다. 평행 이동 컴포넌트에는 교란을 도입하지 않는다는 점에 유의하라. 위와 같은 multi-camera 설정을 통해 stereo rectification을 위한 다양한 쌍을 샘플링 할 수 있다.
5. Experiments
이어서, 제안된 방법을 위에서 정의된 테스트 셋에 대해 평가하고 baseline 접근과 비교하여 검증한다. 우리는 또한 ablation(제거) 실험을 사용하여 설계 선택의 효과를 확인한다.
Baselines.
우리는 카메라 pose 추정에 대한 전통적인 접근과 학습된 접근과 비교한다. 학습된 컴포넌트는 2가지 방법으로 통합된다. 첫째, hand-crafted와 학습된 feature를 -RANSAC과 MAGSAC과 같은 견고한 추정기와 결합한 keypoint 기반 접근을 사용한다. 둘째, 우리의 방법을 En et al(RPNet), Chen et al(DirectionNet)과 Rockwell et al(우리는 이 접근을 ViTPose라 한다)와 같은 기존 최첨단 end-to-end pose 추정 모델과 비교한다. 모든 방법이 기존 pose 추정 데이터셋(예: MatterPort3D)에서 잘 작동하지만 wide baseline 데이터에 평가할 때는 어려움을 겪는 것을 발견했다.
Metrics.
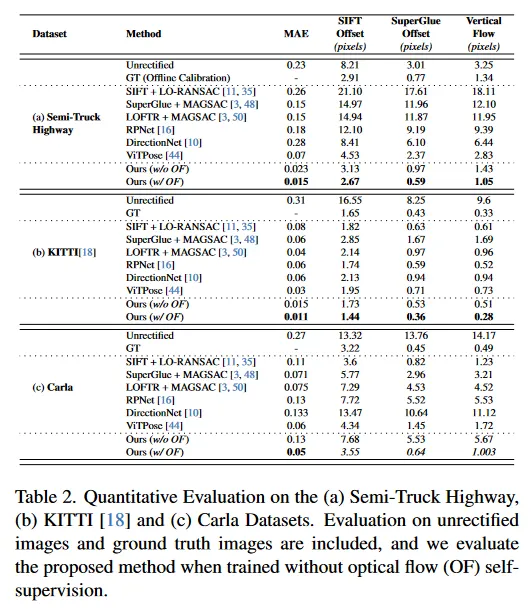
rectification 품질을 평가하기 위해 표 2의 key-point offset 메트릭을 도입한다. 이 메트릭은 우선 기존 방법을 사용하여 keypoint를 찾은 다음 stereo image 간 matching을 수행한다. 그 다음 두 key-point 유형 SIFT와 Superglue에 대해 keypoint 매칭의 y-축을 따라 평균 offset을 계산한다. 또한 Ground Truth rectified 이미지와 각 방법에서 생성된 rectified 이미지 사이의 Mean Absolute Error(MAE)를 사용하여 rectification을 평가한다. 마지막으로 vertical flow offset 측정(우리 방법이 최소화하도록 학습된)을 보고한다. 또한 회전 추정치의 각도 오차도 부록에서 리포트한다.
추가적으로 rectification 품질과 stereo depth 추정 사이의 correlation에 대한 통찰을 얻기 위해 downstream depth 추정 모델을 평가한다. 여기에는 ground truth depth와 다양한 rectification 방법에서 추정된 depth 사이의 Mean Absolute Error(MAE)를 계산하는 것이 포함된다. downstream 평가에 대한 추가 논의는 부록에 나열된다.
5.1. Quantitative Analysis and Ablation Studies
우리는 평가 결과를 표 2에 리포트한다. baseline이 좁고, pose 변화가 적은 KITTI 평가에서 다른 접근법이 경쟁력 있는 결과를 보였음에도 우리 방법이 가장 우수한 성능을 냈다. 심지어 우리 방법은 Ground Truth(offline calibration)도 능가한다. 심각한 pose 변화가 있는 Carla 데이터셋과 Semi-Truck Highway 데이터셋에 대한 평가에서 모든 방법의 견고함(또는 부족)을 포착한다.
제안된 접근이 전반적으로 모든 지표에서 가장 좋은 성능을 내며, Semi-Truck Highway에서 Ground Truth(offline calibration) 보다, Carla에서 Ground Truth(simulation calibration)와 비슷한 수준의 성는을 낸다. 게다가 이 평가는 새로운 self-supervised vertical flow loss(우리의 w/o OF)의 중요성을 입증한다.
5.2. Effect on Downstream Depth Estimation
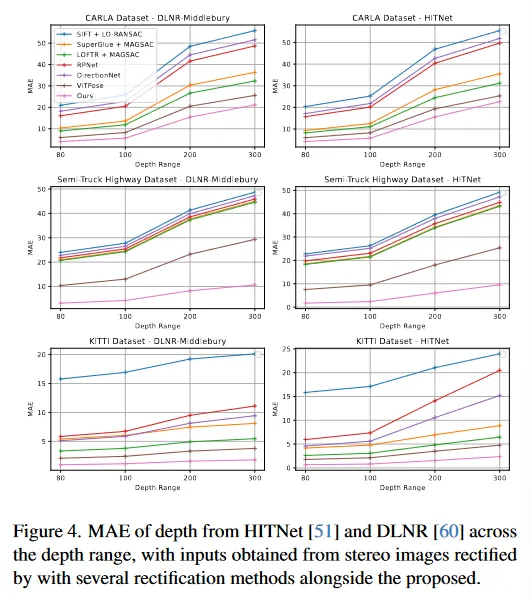
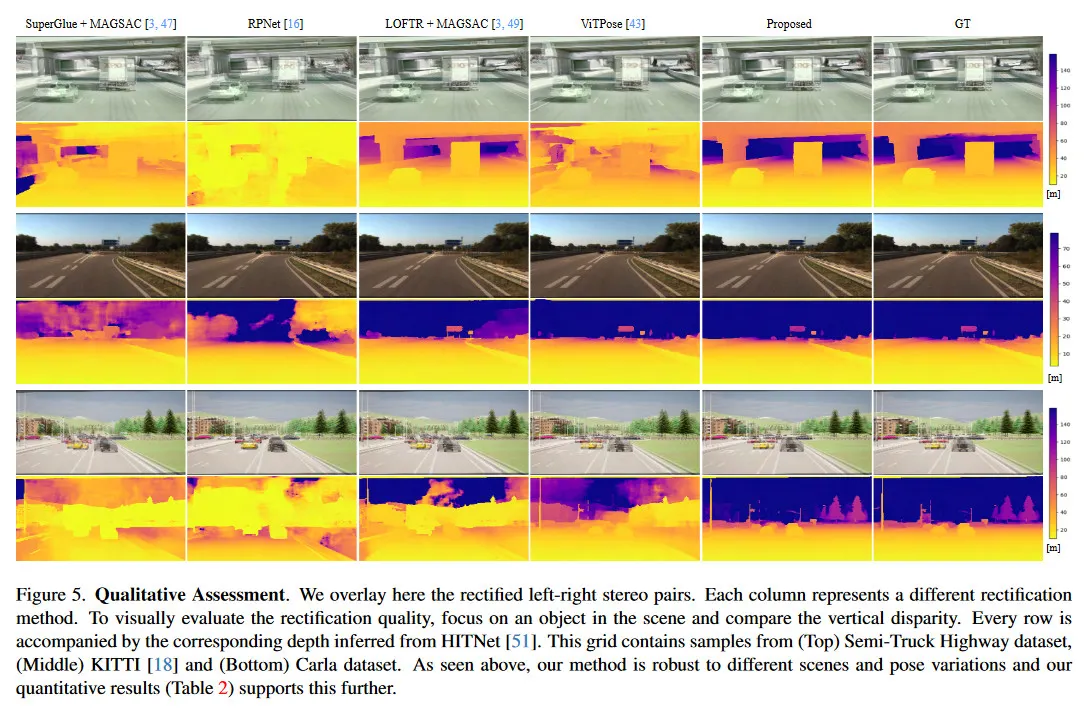
우리는 개선된 rectification이 downstream 작업 성능에 미치는 영향을 평가하고 다른 접근 법을 사용하여 두 가지 SOTA stereo 모델(HITNet과 DLNR)에 전달한다. 그림 4는 다양한 거리에 대한 MAE의 정량적 비교를 보여주며(이 MAE 메트릭은 Ground Truth Depth에 대해 계산되므로 표 2와 다름), 그림 5는 rectification과 결과 stereo depth의 정성적 비교를 보여준다. 우리는 먼 거리에서 depth 추정이 전반적으로 나쁘다는 경향을 관찰했는데, 이는 rectification 보다 모델 자체의 문제로 인한 것이다. 이를 염두해 두고 제안된 방법을 사용할 때 Carla 데이터셋에서 DLNR로 [0-300]m 범위에서 평균 17%, HITNet으로 평균 10%의 MAE 개선을 측정했다. KITTI에서는 MAE가 다른 방법과 유사하지만 두 SOTA 모델 모두에서 [0-300]m 범위에서 51% 개선되었다. 마지막으로 세미트럭 고속도로 데이터셋에서 두 모델 모두 [0-300]m 범위에서 평균 63% 이상의 큰 MAE 성능 향상을 측정했다. 이를 통해 제안된 모델의 rectification 성능이 더 낫고 더 높은 정확도의 깊이 추정을 가능하게 함을 확인할 수 있다.
6. Conclusion
우리는 wide baseline stereo 설정을 위한 online stereo rectification 방법을 제안한다. 이는 환경 영향과 장기 노출로 인해 발생하는 calibration 저하 문제를 해결하는 것을 목표로 한다. 이러한 영향은 온도와 응력 구배로 인한 진동, 늘어남, 꼬임 현상으로 나타난다. 우리 방법은 offline calibration에서 weak supervision와 vertical flow를 사용한 self-supervision에 기반한다. stereo correlation volume 기반 접근법을 사용하여 대응관계를 설정하고 stereo 쌍 간 상대적 회전을 추정한다. 이 접근법을 고속도로에서 세미트럭으로 캡쳐한 새로운 wide-baseline stereo 데이터셋과 극단적 pose 변화가 있는 시뮬레이션 데이터셋에 대해 학습하고 평가한다. 우리 방법은 기존 전통적/학습된 pose 추정 및 online calibration 방법과 비교할 때 calibration 정확도와 downstream stereo depth 정확도 면에서 유리하다. 향후 흥미로운 방향으로는 calibration의 multi-scale iterative refinement와 동시 multi-camera rectification이 있다.
