

A Details on the PVS Task
Promptable Visual Segmentation(PVS) 작업은 정적 이미지에서 비디오로 Segment Anything(SA) 작업을 확장한 것으로 볼 수 있다. PVS 설정에서 입력 비디오가 주어지면 모델은 비디오에서 임의의 프레임에서든 입력의 다양한 유형(클릭, 박스, 또는 마스크를 포함하여)으로 상호작용적으로 prompt 될 수 있다. 목표는 비디오 전체에 걸쳐 유효한 객체를 segmenting(와 추적)이다. 비디오와 상호작용할 때, 모델은 프롬프트되는 프레임에 대해 즉각적인 응답을 제공하고(이미지에 대한 SAM의 상호작용 경험과 유사), 실시간에 가깝게 전체 비디오에 걸쳐 객체의 segmentation을 반환한다. SAM과 유사하게 명확하게 정의된 경계를 갖는 유효한 객체에 초점을 맞추며, 시각적 경계가 없는 영역은 고려하지 않는다. 그림 8 참조.
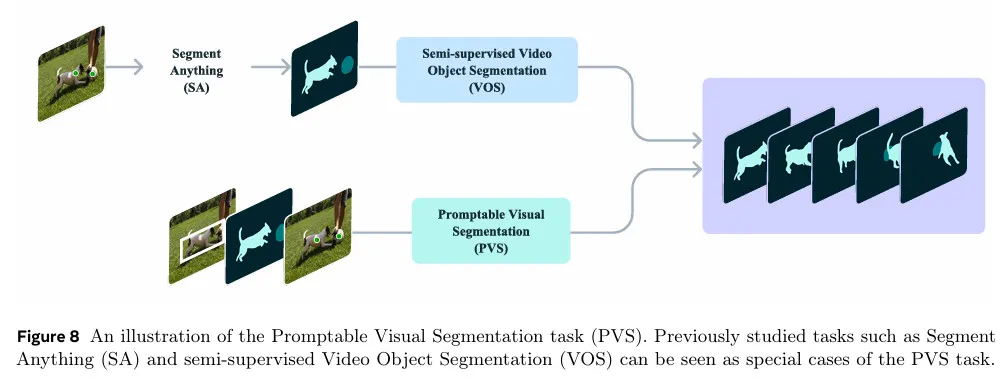
PVS는 정적 이미지와 비디오 도메인 모두에서 여러 작업과 연관된다. 이미지에서 SA 작업은 비디오를 단일 프레임으로 축소시킨 PVS의 부분 집합으로 고려될 수 있다. 유사하게 기존의 semi-supervised와 interactive VOS 작업은 PVS의 특별한 경우로, 각각 첫 번째 프레임에만 제공되는 mask 프롬프트와 비디오에 걸쳐 객체를 segment하기 위해 여러 프레임에 그려진 scribbles로 제한된다. PVS에서 프롬프트는 click, mask, box 일 수 있고 상호작용 경험을 향상 시키는데 초점을 맞추어 최소한의 상호작용으로 객체의 segmentation의 쉽게 수정할 수 있게 한다.
B Limitations
SAM 2는 이미지와 비디오 도메인에서 모두 강력한 성능을 시연하지만 아직 특정한 시나리오에서 어려움을 겪는다. 모델은 샷 변화 시 객체를 segment 하는데 실패할 수 있고, 복잡한 장면에서 긴 occlusion이나 확장된 비디오에서 객체를 놓치거나 혼동할 수 있다.
이 이슈를 완화하기 위해 우리는 SAM 2가 임의의 프레임에서도 프롬프트될 수 있도록 설계했다. 오류로 모델이 객체를 놓치거나 오류를 범하면, 대부분의 경우 추가 프레임에 수정 클릭으로 빠르게 올바른 예측을 복구할 수 있다. SAM 2는 또한 매우 얇거나 미세한 디테일을 갖는 객체가 특히 빠르게 움직일 때 정확하게 추적하는데 어려움을 겪는다. 또 다른 도전적인 시나리오는 유사한 외형을 갖는 객체가 가까이 있을 때 발생한다(예: 여러 동일한 저글링 공). SAM 2에 더 명시적인 모션 모델링을 통합하면 이러한 경우의 에러를 완화시킬 수 있다.
SAM 2가 비디오에서 여러 객체를 동시에 추적할 수 있지만, 각 객체를 별도로 처리하며, 객체 사이의 커뮤니케이션 없이 공유된 프레임별 임베딩만 활용한다. 이런 접근은 단순하지만, 공유된 객체-레벨의 맥락 정보를 통합하면 효율성을 증가시키는데 도움이 된다.
우리의 데이터 엔진은 masklet 품질을 확인하고, 교정이 필요한 프레임을 선택하기 위해 인간 주석자에 의지한다. 향후 개발에서는 이 절차를 자동화하여 효율성을 높이는 것이 포함될 수 있다.
C SAM 2 details
C.1 Architecture
여기서 섹션 4의 모델 설명을 확장하여 아키텍쳐 상세를 추가로 논의한다.
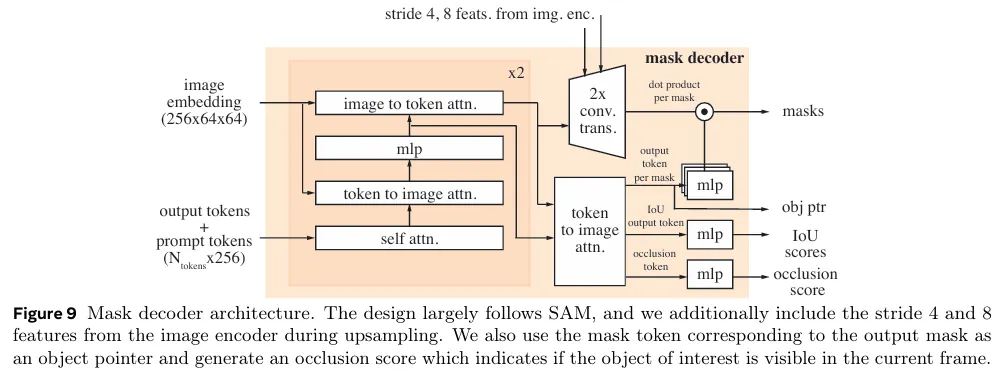
Image encoder. 우리는 feature pyramid network를 사용하여 Hiera 이미지 인코더의 Stage 3과 4에서 각각 stride 16과 32개 feature를 융합하여 각 프레임에 대한 이미지 임베딩을 생성한다. 또한 Stage 1과 2의 stride 4와 8개 feature는 memory attention에 사용되지 않지만 mask 디코더의 upsampling layer에 추가되어(그림 9) 고해상도 segmentation 디테일을 생성하는데 도움이 된다.
우리는 Bolya et al을 따라 Hiera 이미지 인코더에서 windowed absolute positional 임베딩을 사용한다. Bolya et al에서 RPB는 이미지 인코더의 windows를 가로지르는 positional 정보를 제공했지만, 우리는 대신 windows를 가로지르도록 global positional 임베딩을 보간하는 더 단순한 접근을 채택한다. 우리는 relative positional encoding을 사용하지 않는다. 우리는 다양한 이미지 인코더 크기()로 모델을 학습한다. 우리는 Li et al을 따라 이미지 인코더 레이어의 부분집합에만 global attention을 사용한다. (표 13)

Memory attention. sinusoidal absolute positional embedding 외에도 우리는 2d spatial Rotary Positional Embedding(RoPE)를 self-attention과 cross-attention 레이어에 사용한다. object pointer token은 특정 공간적 대응이 없기 때문에 RoPE에서 제외된다. 기본적으로 memory attention은 레이어를 사용한다.
Prompt encoder and mask decoder. prompt 인코더 디자인은 SAM을 따르고 다음으로 mask 디코더에서 설계 변경에 대한 추가 세부 사항을 논의한다. 우리는 출력 마스크에 해당하는 mask 토큰을 해당 프레임의 object pointer token으로 사용하며 이것은 memory bank에 저장된다. 섹션 4에서 논의한 것처럼 우리는 occlusion 예측 헤드를 도입한다. 이것은 마스크와 IoU 출력 토큰과 함께 추가 토큰을 포함하여 구현된다. 이 새로운 토큰에 추가 MLP 헤드를 적용하여 현재 프레임에서 관심 있는 객체가 보일 likelihood를 나타내는 점수를 생성한다.(그림 9 참조)
SAM은 이미지에서 segmented인 객체에 관한 모호성이 있을 때, 여러 개의 유효 마스크를 출력하는 기능을 도입한다. 예컨대 사람이 바이크의 타이어를 클릭할 때, 모델이 이 클릭을 타이어만 또는 전체 바이크를 지칭하는 것으로 해석하여 여러 예측을 출력할 수 있다. 비디오에서 이런 모호성은 비디오 프레임에 전체로 확장될 수 있다. 예컨대 단일 프레임에서만 타이어만 보이면, 이 클릭은 단지 타이어만 의미할 수 있지만, 후속 프레임에서 바이크의 더 많은 부분이 보이게 되면, 이 클릭이 전체 바이크를 의도하는 것일 수 있다. 이런 모호성을 다루기 위해 SAM 2는 비디오의 각 단계에서 여러 마스크를 예측한다. 추가 프롬프트로 모호성이 해결되지 않으면, 모델은 현재 프레임에 대해 예측된 IoU가 가장 높은 마스크를 선택하여 비디오에서 추가 전파한다.
Memory encoder and memory bank. 우리의 memory encoder는 추가 이미지 인코더를 사용하지 않고 대신 Hiera encoder에 의해 생성된 이미지 임베딩을 재사용한다. 이것은 예측된 마스크 정보와 융합되어 memory feature를 생성한다(섹션 4에서 논의한 것처럼). 이 설계는 memory feature가 이미지 인코더에 의해 생성된 강력한 표현에서 이점을 얻을 수 있게 한다(특히 이미지 인코더를 큰 사이즈로 확장할 때). 추가로 우리는 memory bank의 memory feature를 64차원으로 투영하고 memory bank에 대한 cross-attention를 위해 256차원의 object point를 64차원의 4개 token으로 분할한다.
C.2 Training
C.2.1 Pre-training
우리는 우선 SA-1B 데이터셋에서 정적 이미지로 SAM 2를 pre-train한다. 표 13a는 SA-1B에서 pre-training 동안 사용된 설정의 상세이다. 여기서 언급되지 않은 다른 설정은 Kirillov et al을 따른다. 이미지 인코더는 MAE pre-trained Hiera로 초기화된다. SAM과 유사하게 우리는 이미지의 90% 이상을 커버하는 마스크를 필터링하고 이미지당 랜덤하게 샘플된 64개 마스크로 학습을 제한했다.
SAM과 달리 우리는 IoU 예측을 더 적극적으로 supervise 하기 위해 loss를 사용하고, IoU logit에 sigmoid 활성화를 적용하여 출력을 0과 1 사이의 범위로 제한하는 것이 이점이 있다는 것을 발견했다. multi-mask 예측(첫 번째 클릭에서)의 경우, 우리는 마스크가 나쁠 수 있는 경우를 더 잘 학습하도록 모든 마스크의 IoU 예측을 supervise하지만, segmentation loss(focal과 dice 손실의 선형결합)이 가장 낮은 마스크 logit만 supervise 한다. SAM에서 점의 반복 샘플링 중 추가 프롬프트 없이(이전 마스크 logit만 입력) 두 번의 반복이 삽입되었지만, 우리는 학습 중 이러한 반복을 추가하지 않고 7개의 수정 클릭을 사용한다(SAM에서 8개 대신). 우리는 또한 학습하는 동안 horizontal flip 증강을 활용하고 이미지를 1024x1024의 정사각 크기로 조정한다.
우리는 AdamW을 사용하고, 이미지 인코더에 layer decay를 적용하고, reciprocal square-root schedule을 따른다. pre-training 단계의 hyperparameter에 대해 표 13(a) 참조.
C.2.2 Full training
pre-training 후에 우리는 도입된 데이터셋 SA-V+Internal(섹션 5.2), SA-1B의 10% 부분집합과 DAVIS, MOSE, YouTubeVOS를 포함한 open-source video 데이터셋의 혼합에서 SAM 2를 학습한다. 공개된 모델은 SA-V manual + Internal과 SA-1B에서 학습되었다.
SAM 2는 2가지 작업을 위해 설계되었다. PVS 작업(비디오에서)와 SA 작업(이미지에서). 학습은 이미지와 비디오 데이터를 결합하여 진행된다. 학습하는 동안 데이터 사용량과 계산 자원을 최적화하기 위해, 우리는 비디오 데이터(여러 프레임)과 정적 이미지(단일 프레임) 사이의 교대 학습 전략을 채택한다. 구체적으로 각 학습 반복에서 우리는 이미지 또는 비디오 데이터셋에서 full batch를 샘플링하며, 샘플링 확률은 각 데이터 소스의 크기에 비례한다. 이 접근 방식은 두 작업에 대해 균형 잡힌 노출을 가능하게 하며, 각 데이터 소스에 대해 다양한 배치 크기를 사용하여 계산 활용을 최대화한다. 이미지 작업에 대해 여기서 명시적으로 언급되지 않은 설정은 pre-training 단계의 설정을 따른다. full training 단계에서 hyper-parameter는 표 13(b) 참조. 학습 데이터는 약 15.2%의 SA-1B, 약 70%의 SA-V, 약 14.8% Internal의 혼합으로 구성된다. 오픈소스 데이터셋이 포함될 때도 동일한 설정이 사용되며, 추가 데이터가 포함된다(약 1.3% DAVIS, 약 9.4% MOSE, 약 9.2% YouTubeVOS, 약 15.5% SA-1B, 약 49.5% SA-V, 약 15.1% Internal)
우리는 interactive 설정을 시뮬레이션하여 학습한다. 8개 프레임 시퀀스를 샘플링하고 최대 2개 프레임(첫 프레임을 포함하여)을 무작위로 선택하여 수정 클릭을 수행한다. 학습하는 동안 ground-truth masklet과 모델 예측을 사용하여 프롬프트를 샘플링하며, 초기 프롬프트는 ground-truth mask(50% 확률), ground-truth mask에서의 positive click(25%) 또는 bounding box input(25%)이다.
8개 프레임의 시퀀스마다 최대 masklet 수를 무작위로 선택된 3개로 제한한다. bi-directional 전파에 대한 일반화를 돕기 위해 50%의 확률로 시간적 순서를 반전한다. 수정 클릭을 샘플할 때 —10%의 작은 확률로— 모델 예측의 관계없이 ground-truth mask에서 무작위로 클릭을 샘플링하여 마스크 개선에 추가적인 유연성을 제공한다.
Losses and optimimzation. 모델의 예측을 supervise 하기 위해 마스크 예측에는 focal과 dice loss의 선형 결합을 사용하고, IoU 예측에는 mean-absolute-error(MAE) error를, 객체 예측에는 cross-entropy loss를 각각 20:1:1:1의 비율로 사용한다. pre-training 때와 마찬가지로, multi-mask 예측의 경우 가장 낮은 segmentation loss를 갖는 mask만 supervise한다. ground-truth에 프레임에 대한 마스크가 없는 경우, 마스크 출력을 supervise하지 않는다(그러나 프레임에 마스크가 존재해야 하는지 예측하는 occlusion prediction head는 항상 supervise 한다)
C.3 Speed benchmarking
우리는 모든 벤치마킹 실험을 A100 GPU에서 PyTorch 2.3.1과 CUDA 21.1, bfloat16의 자동 혼합 정밀도 아래 수행했다. 모든 SAM 2 모델에 대해 torch.compile을 사용하여 이미지 인코더를 컴파일하며, SA 작업과 직접 비교하기 위해 SAM과 HQ-SAM에도 동일하게 적용한다(표 6과 15) SA 작업을 위한 FPS 측정은 10개 이미지의 batch 크기를 사용하여 수행되었으며, 이것은 3가지 모델 유형 모두에서 가장 높은 FPS를 산출했다. 비디오 작업에 대해, 비디오 segmentation에서 일반적인 프로토콜을 따라 배치 크기 1을 사용했다.
(이하 데이터셋과 측정 결과 내용 생략)
