
Greedy Decoding
RNN에서 생성하는 가장 간단한 방법은 매 단계에서 를 계산하는 greedy decoding을 사용하는 것이다. 이 절차를 end-of-sentence(eos) 토큰이 생성될 때까지 반복할 수 있다.
그러나 greedy deconding은 로 정의되는 MAP 시퀀스를 생성할 수 없다. 각 단계 에서 지역 최적 심볼이 전역 최적 경로가 아닐 수 있기 때문이다.
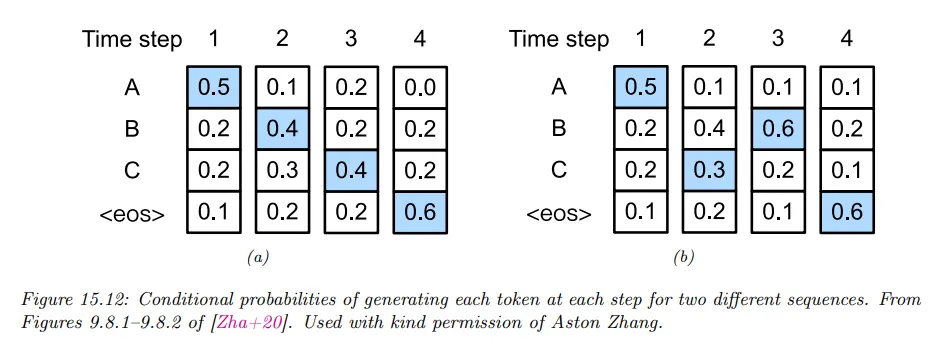
예컨대 아래 그림 a를 보자. 단계 에서 MAP 심볼을 greedily 고르면 이다. 이것을 조건으로 을 가정하여 MAP 심볼을 greedily 고르면 결과는 가 되고, 이것을 조건으로 을 가정하고 MAP 심볼을 greedily 고르면 가 된다. 이것을 조건으로 을 가정하고 MAP 심볼을 고르면 eos(end of sentence)가 되고 생성이 멈춘다. 생성된 시퀀스의 전체 확률은 이다.
b를 고려하자. 단계 에서 2번째로 가장 가능한 토큰을 고르면 가 된다. 이것을 조건화으로 을 가정하여 MAP 심볼을 greedily 고르면 가 된다. 이것을 조건화으로 을 가정하고 MAP 심볼을 greedily 고르면 eos(end of sentence)가 나오고 생성은 멈춘다. 생성된 시퀀스의 전체 확률은 이다. 따라서 덜 greedy 한 것이 전체 대해 더 높은 likelihood를 갖는 시퀀스를 찾게 한다.
은닉 마르코프 모델에 대해 Viterbi decoding(dynamic programming의 한 예이다)이라 불리는 알고리즘을 사용하면 시간에 전역 최적 시퀀스를 계산할 수 있다. 여기서 는 어휘 속의 단어 수이다. 반면 RNN에 대해 전역 최적은 가 걸린다. 이는 은닉 상태가 데이터에 대해 충분 통계량이 되지 않기 때문이다.
Beam Search
Beam Search는 너비 탐색과 깊이 탐색의 절충안이다. 이것은 한 번에 다수의 경로를 동시에 고려하면서도 계산 효율성을 위해 제한된 수의 최상위 경로만 선택하여 탐색을 진행한다.
Beam Search는 Beach width의 크기만큼 후보를 유지하면서 시퀀스를 확장하였다가 후보 중 개 상위 요소를 고르는 식으로 진행된다.
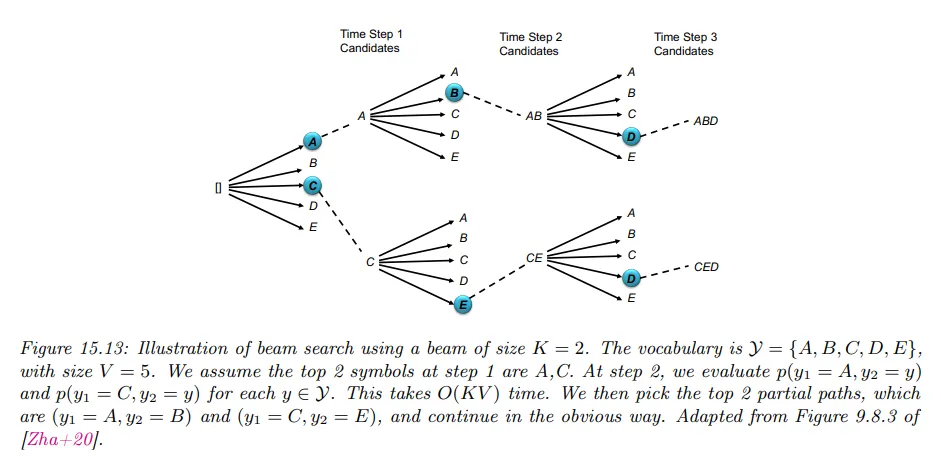
Beam width가 3이고 최상위 을 선택할 때 예는 다음과 같다.
1.
초기화 - The로 시작
2.
다음 가능한 단어 3개(beam width) - [capital, city, main]를 추가하여 후보 생성
•
The Capital
•
The City
•
The Main
3.
각 후보에 대해 다시 가능한 단어 3개를 추가하여 후보 생성
•
The Capital - [of, is, was]
◦
The Capital of
◦
The Capital is
◦
The Capital was
•
The City - [of, is, was]
◦
The City of
◦
The City is
◦
The City was
•
The Main - [city, attraction, point]
◦
The main city
◦
The main attraction
◦
The main point
4.
확장된 후보 중 확률이 높은 순으로 최상위 3개() 선택
•
The capital of
•
The capital is
•
The city of
5.
각 후보에 대해 다시 가능한 단어 3개를 추가하여 후보 생성
•
The capital of - [France, Germany, Spain]
◦
The capital of France
◦
The capital of Germany
◦
The capital of Spain
•
The capital is - [Paris, Berlin, Madrid]
◦
The capital is Paris
◦
The capital is Berlin
◦
The capital is Madrid
•
The city of - [Paris, London, Berlin]
◦
The city of Paris
◦
The city of London
◦
The city of Berlin
6.
확장된 후보 중 확률이 높은 순으로 최상위 3개 선택하고 eos가 나올 때까지 위의 절차(3-4) 반복
또한 stochastic beam search라 불리는 방법을 사용하여 교체 없이 상위 개 시퀀스를 샘플링하는 알고리즘으로 확장할 수 있다.(즉 최상위 1개를 고르고 renormalize하고 새로운 최상위를 고르고 등). 이것을 Gumbel 노이즈로 매 단계에서 모델의 부분 확률을 교란한다. 이 샘플링 방법들은 출력의 diversity를 개선할 수 있다.
