
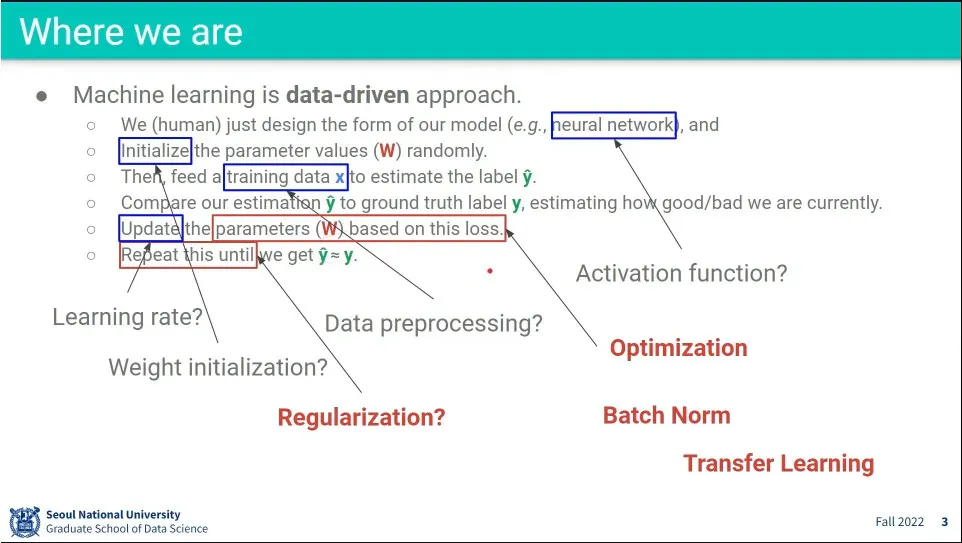
•
빨간 글씨가 이번 수업에서는 배울 것들.
•
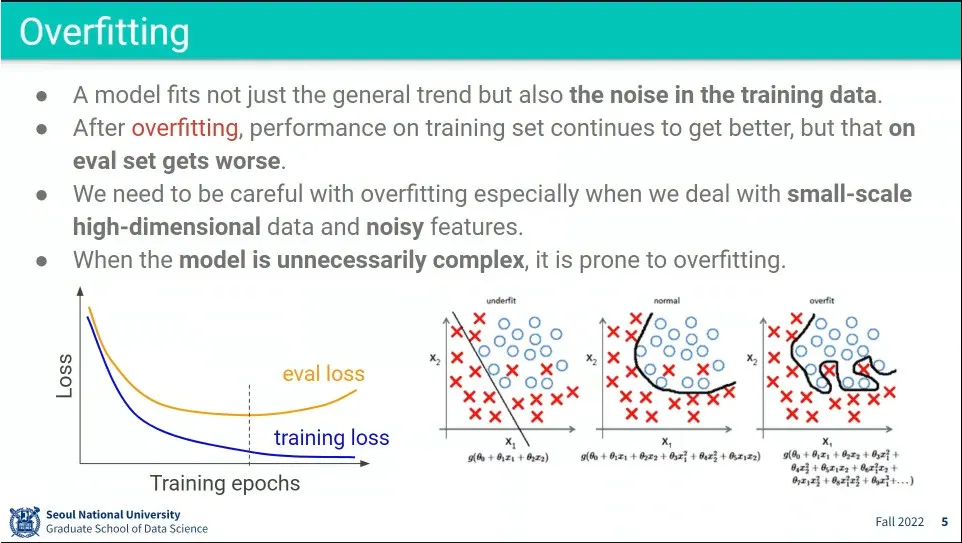
Underfitting, Overfitting 문제.
•
Overfitting은 training loss는 줄어드는데 evaluation loss가 늘어나는 상황을 말함

•
일단 모델을 복잡하게 하되, Overfitting을 방지하기 위해 규제항을 추가함.
◦
규제항은 학습되어야 하는 파라미터()들의 합을 페널티로 더해줌으로써 파라미터가 정말로 필요한 경우가 아니면 작아지도록 한다.
◦
규제항에 곱해지는 는 규제를 얼마나 강하게 줄지를 조정하는 하이퍼파라미터

•
Ridge Regression의 예.
◦
규제를 제곱의 합을 구함. L2 거리
◦
제곱의 합이라서 원형이 됨.
◦
규제 영역 밖의 를 minimize하면 규제영역 테두리까지 가져온다.
•
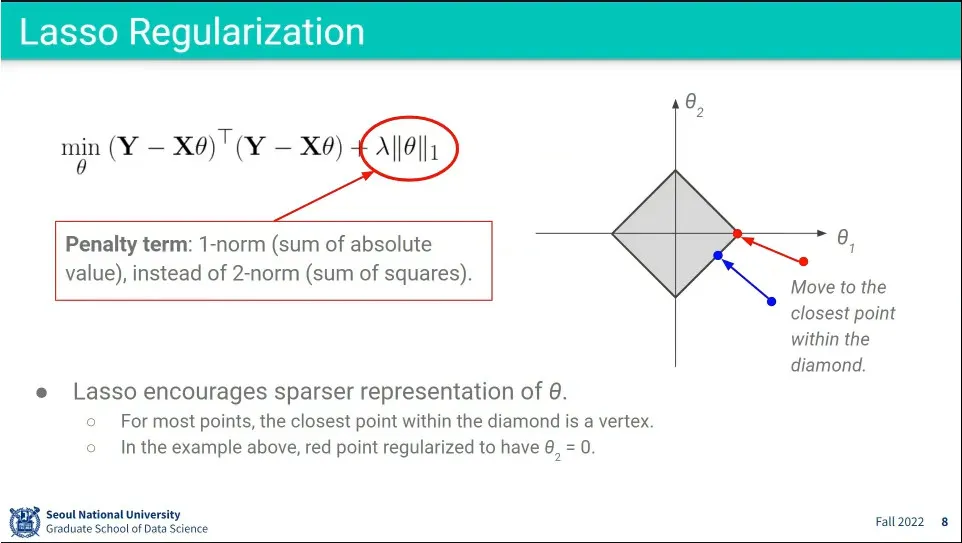
Lasso Regularization 예
◦
규제의 절대값의 합을 구함. L1 거리.
◦
절대값의 합이기 때문에 다이아몬드 형태가 됨
◦
가 다이아몬드의 꼭지점으로 모이는 경우가 많게 되는데, 그러면 나머지 는 0이 되게 됨. sparse한 표현이 된다.

•
딥러닝은 overfitting에 아주 취약함

•
L2, L1 규제와 마찬가지로 뉴럴 네트워크에서도 가중치)의 합을 제곱이나 절대값으로 더해 줌.

•
overfitting이 되기 전에 학습을 멈춘다.
◦
train set, validation set을 나눠서 사용
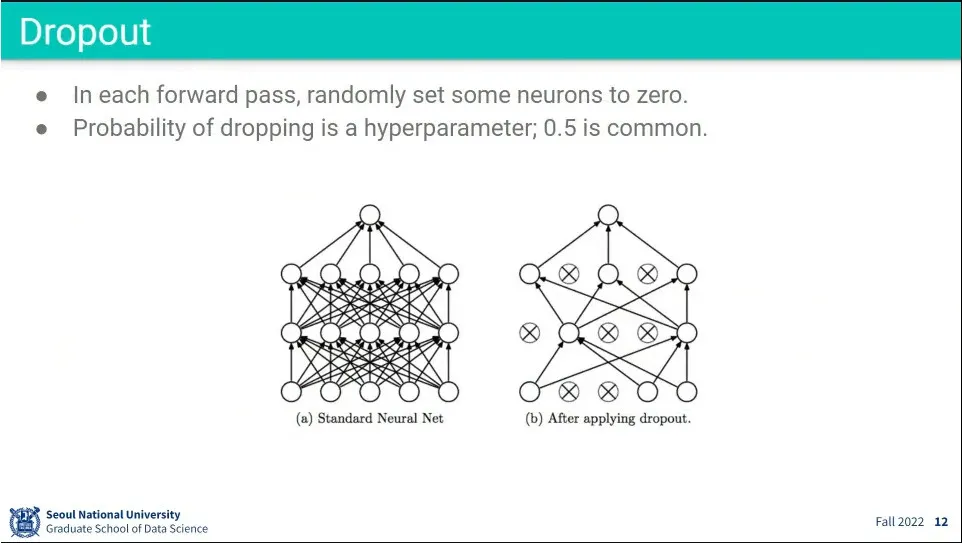
•
학습할 때마다 노드 중 일부를 무작위로 꺼서 overfitting을 방지함.

•
dropout은 일부를 가려도 대상을 맞추도록 훈련하는 것

•
Dropout 구현 예
◦
train할 때 비율만큼 끄고, 살아남은 노드들은 그 비율만큼 키워서 학습을 돌린다. (비율만큼 나눠서 처리)
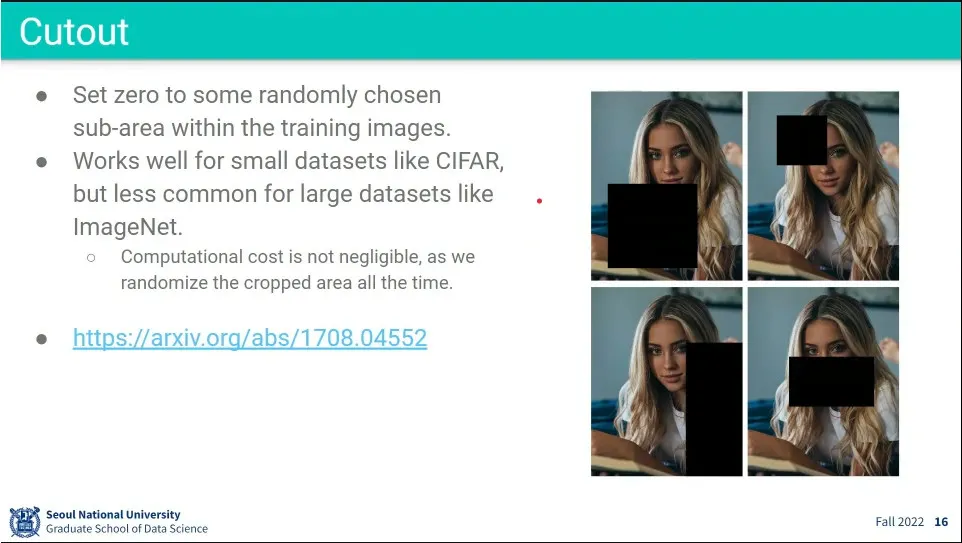
•
Cutout은 input에 대해 dropout 같은 효과를 주는 것.
◦
다만 데이터셋이 작을 때는 유용하지만, 클 때는 별로 사용하지 않음

•
dropout을 써라
•
batch normalization을 써라
•
data augmentation도 하면 좋다.
•
early stopping도 써라

•
Stochastic Gradient Descent의 문제점들.
◦
한 방향은 경사가 급하고, 다른 방향은 완만할 때 지그재그(jittering) 문제가 발생해서 매우 느려짐
◦
saddle point에 갇히는 문제.
◦
계산 효율성을 위해 mini-batch 쓰는데, 너무 작으면 전체 데이터셋을 잘 대표하지 못 함
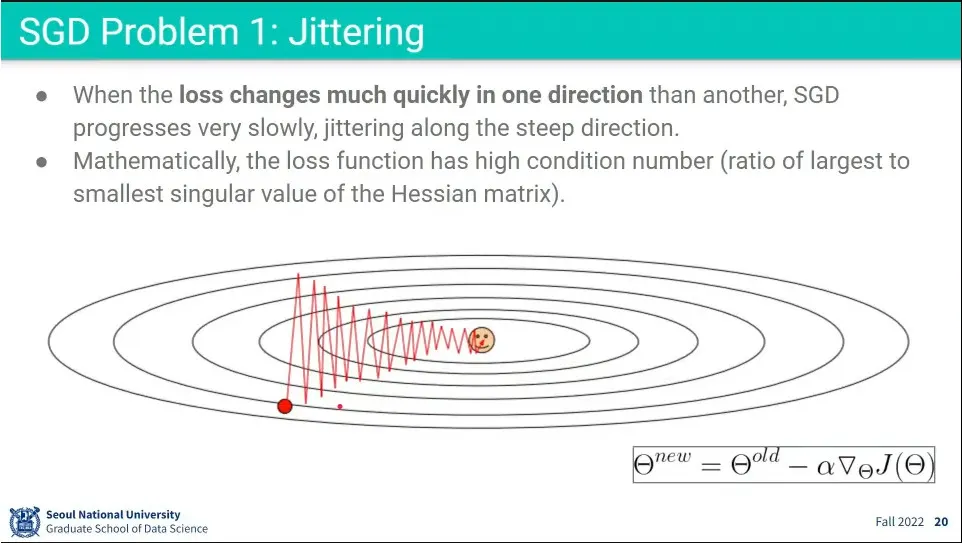
•
Jittering 문제

•
saddle point 문제
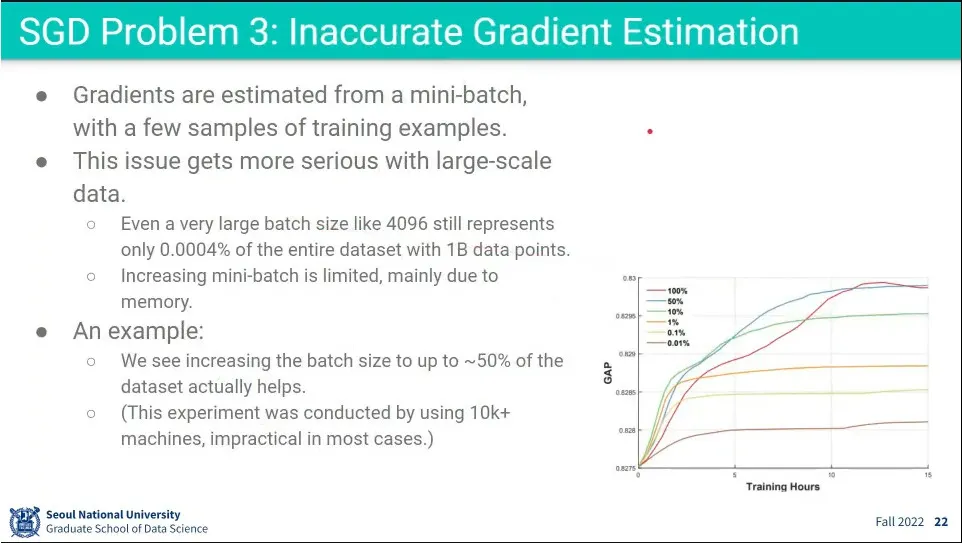
•
미니배치가 전체 데이터셋을 적게 대표할 수록 성능이 떨어짐.
◦
50% 이상 써야 좋은데, 그럴거면 mini-batch를 쓰는게 애매함.

•
Jittering 이슈를 해결하기 위해 Momentum을 추가해 줌.
◦
정확히는 관성을 추가해 줌. 이전에 썼던 값들을 누적해서 더해 줌. 과거의 것일 수록 덜 반영 되게.
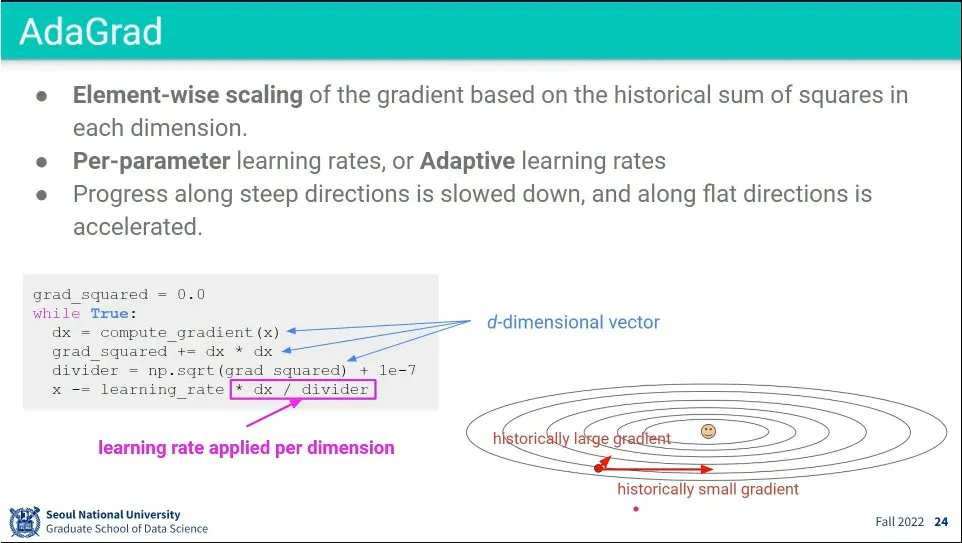
•
가파른 방향으로는 조금만 움직이고, 완만한 방향으로는 많이 움직일 수 있도록 보정해 준 것이 AdaGrad
◦
과거 데이터를 계속 갖고 가는게 문제

•
AdaGrad에 대해 과거의 데이터일수록 약화시켜주는 것이 RMSProp
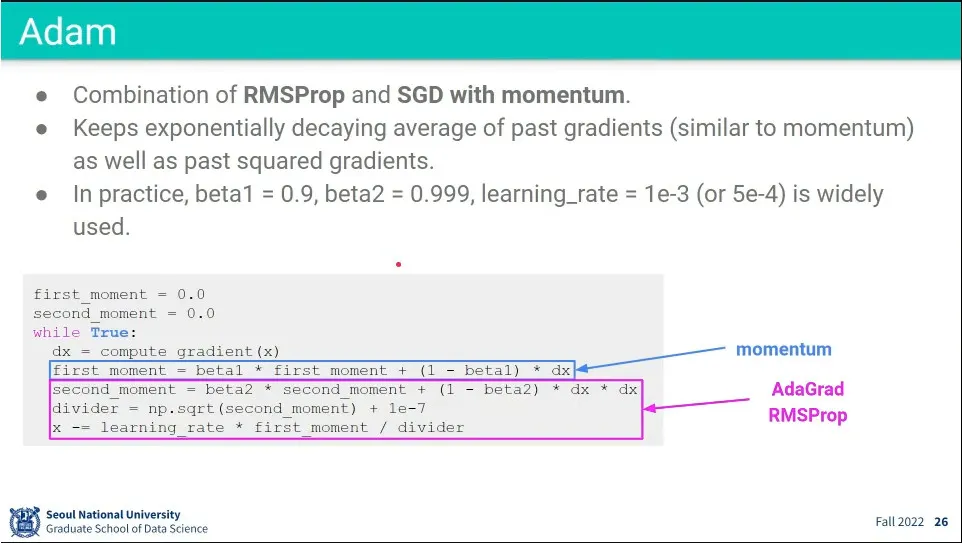
•
RMSProp과 모멘텀을 더한게 Adam
•
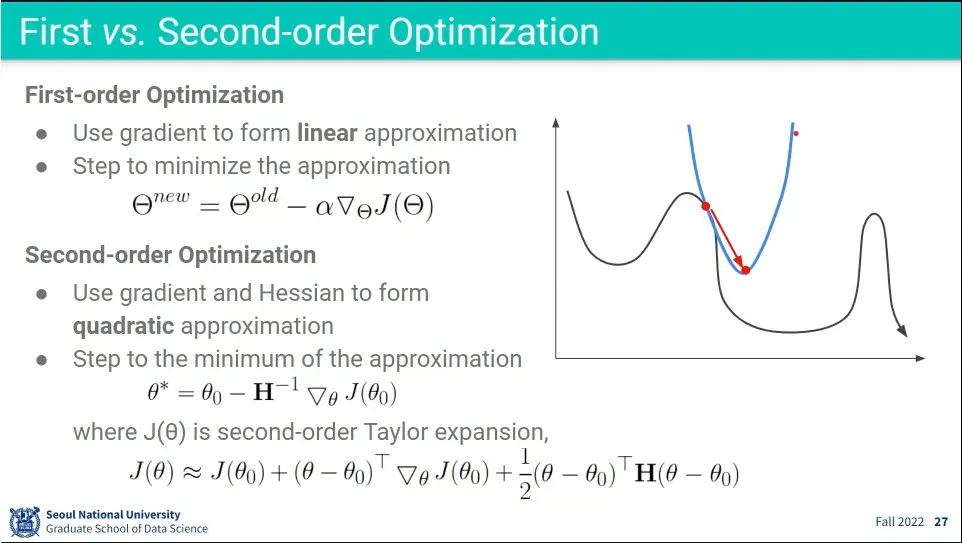
First-order는 1차식으로 Gradient를 구하는 거고, Second-order는 2차식으로 Gradient를 구하는 것
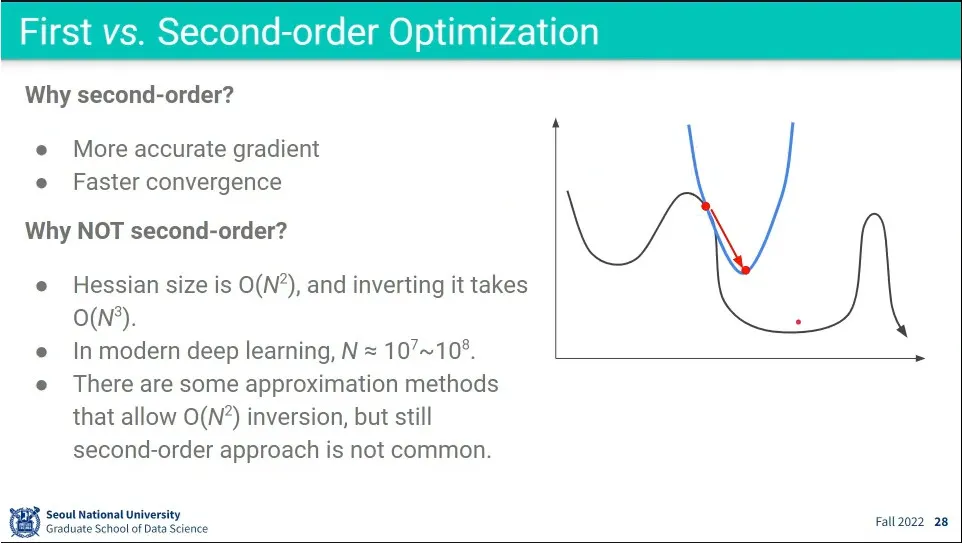
•
2차식이 더 정확하고, 계산 횟수가 적다는 장점이 있지만, 계산 자체가 오래 걸리는 문제가 있음
•
기본적으로 Adam을 써라
•
learning rate을 잘 찾는게 중요함. learning rate가 잘못되서 학습이 안되는 경우가 많음.
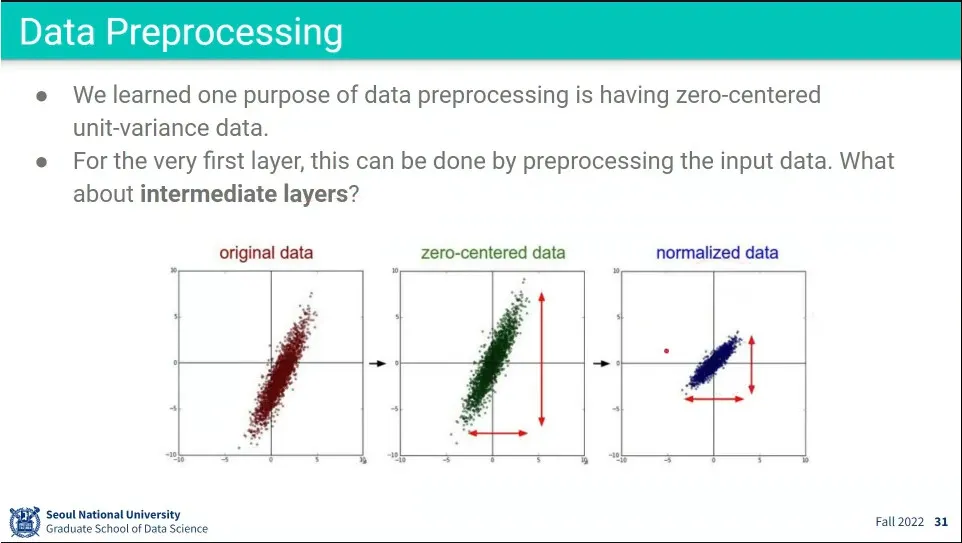
•
input에 대해 zero-centered, normlization을 적용하는 것은 첫 번째 레이어만 적용됨.

•
그래서 아예 layer 단에서 batch normalization을 돌림
◦
미니배치 단의 평균과 분산을 이용해서 normalization을 수행함.

•
Batch Normalization의 계산 방식

•
BatchNorm은 현재 layer의 input에 대해 수행한 것이기 때문에, output에 대해 원래의 값으로 되돌리는 돌리는 과정이 필요함.

•
Test 할 때는 미니배치의 평균과 분산을 알 수 없으므로, 학습할 때 사용한 평균과 분산을 저장해 놨다가 사용함.

•
batch normalization의 장점
◦
학습이 쉽고 gradient가 빨리 수렴하고 등등

•
Batch Normalization은 학습할 때의 평균과 분산을 사용하는데, 테스트할 때 평균과 분산이 달라지면 잘 안 됨.
◦
초기에는 학습할 때와 평균과 분산이 비슷하지만, 몇 년정도 지나면 평균과 분산이 달라지기 때문에 제대로 안 됨
•
그걸 해결하기 위해 Batch Renormalization이 발표 됨.
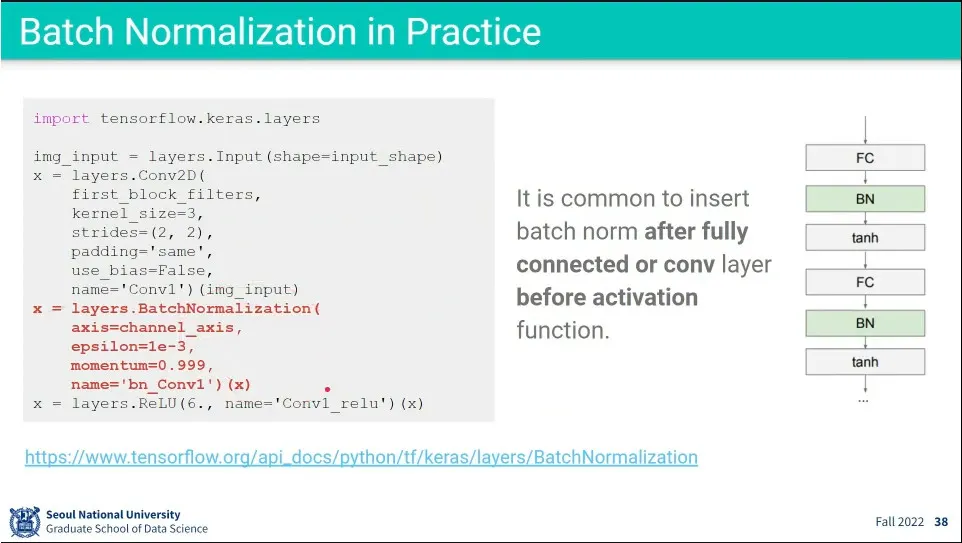
•
코드 예시
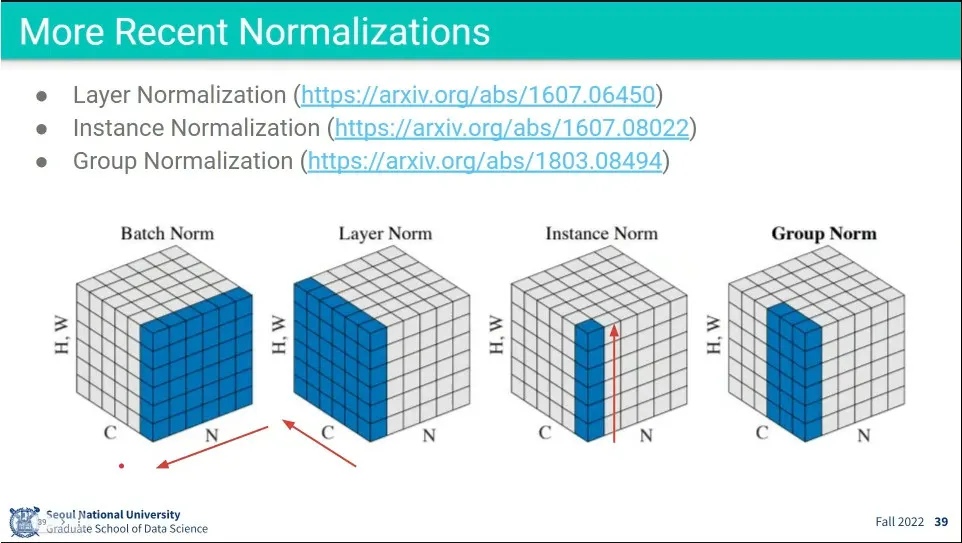
•
BatchNorm의 변형으로 Layer Norm, Instance Norm, Group Norm 등이 나옴.
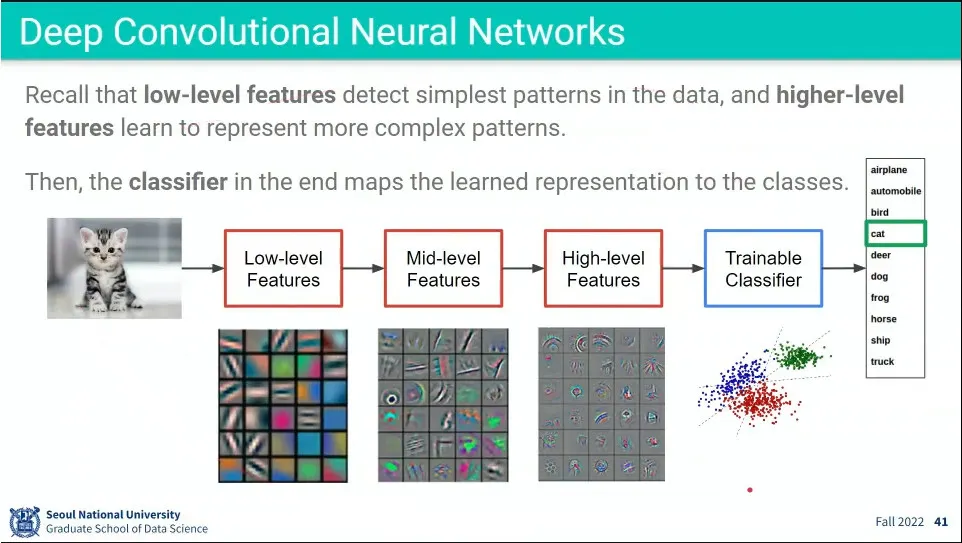
•
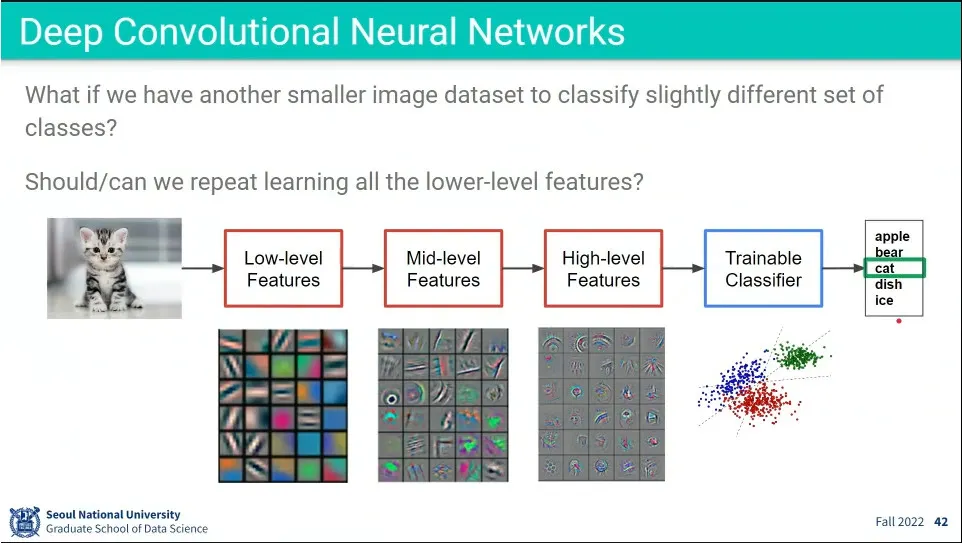
low level에서는 이미지의 기본적인 것을 학습하고, high-level로 갈수록 상위 개념을 학습하게 됨
•
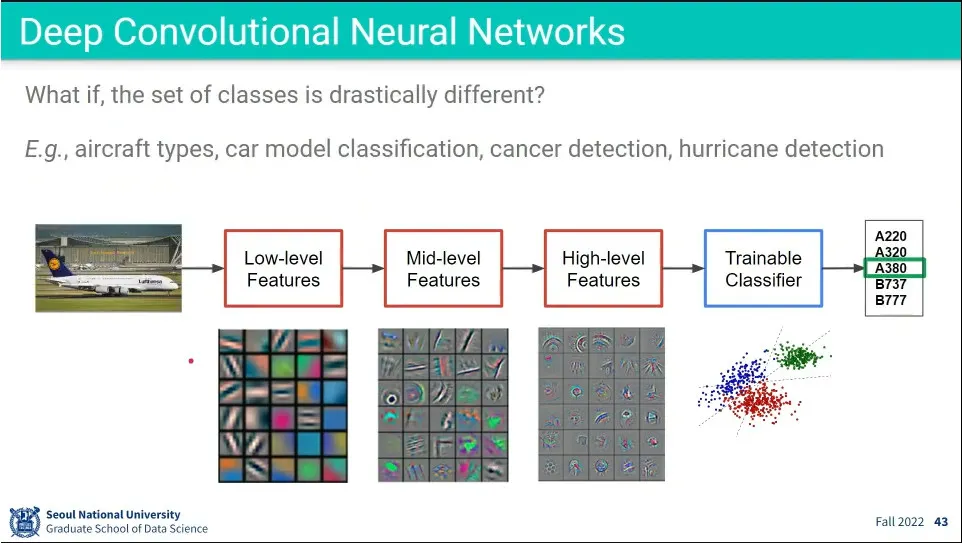
만일 분류 항목이 바뀌면 학습을 다시 해야 할 것 같지만, low-level, middle-level feature는 이미지의 기본적인 특성을 학습하는 것이고, high-level만 분류기에 맞춰져 있기 때문에 high-level만 바꿔서 새로운 분류 문제에 적용하는게 transfer learning

•
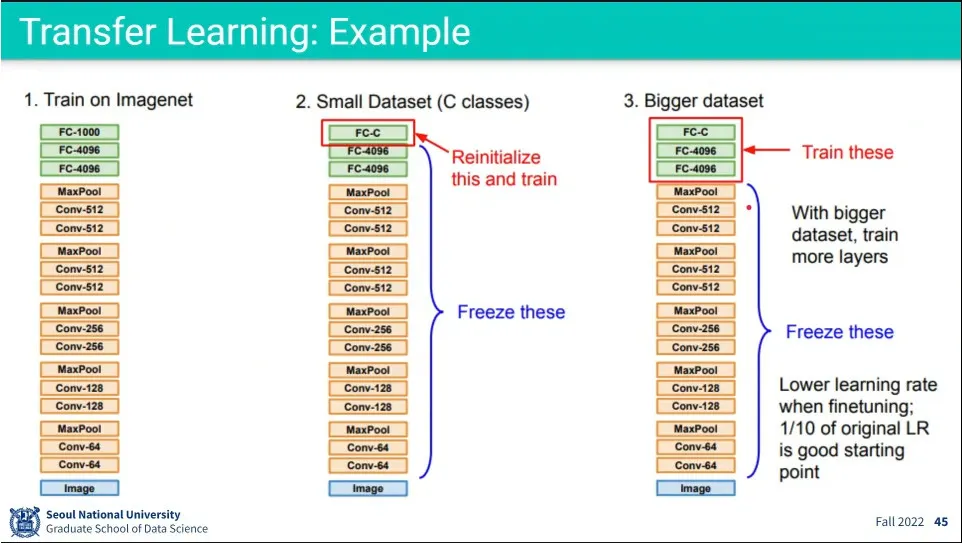
큰 데이터셋에서 학습을 시킨 것을 Pre-training이라고 함.
•
다른 문제에 적용할 때, 앞쪽 layer는 freeze 시키고, 뒷 부분만 다시 학습하는 것을 fine-tuning이라고 함.
•
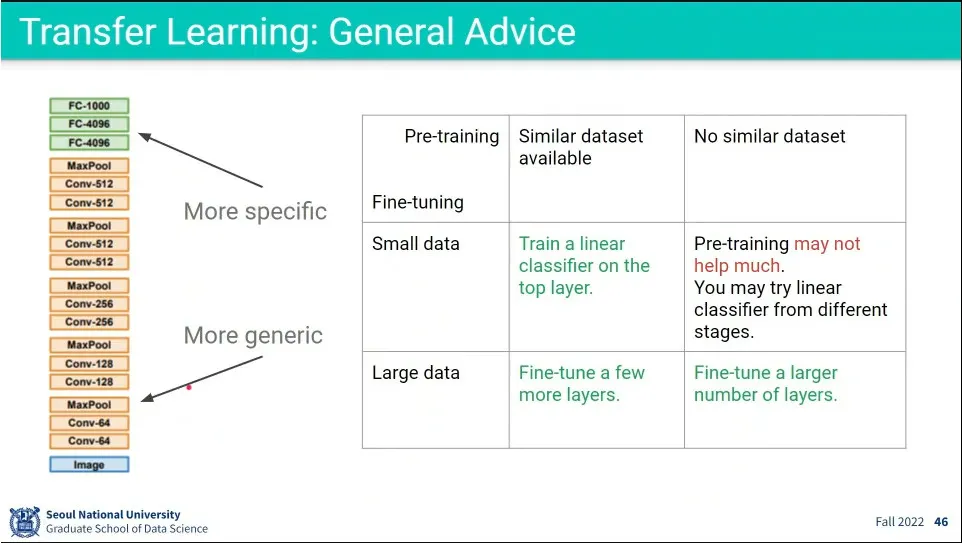
공개된 모델을 이용해서, 내가 가진 데이터셋의 양에 따라 몇 개의 layer를 학습할지 결정함.

•
Pretraining을 한다고 최종 성능이 올라가는건 아니고, 다만 개발 시간 단축이 됨.

•
큰 데이터셋으로 pretraining 하고, 사용하려는 데이터셋으로 fine-tuning 해라.
