
Abstract
우리는 Image segmentation에 대한 새로운 task, model, dataset인 Segment Anything(SA) 프로젝트를 소개한다. 효율적인 모델을 data collection loop에 사용하여 11M 라이센스와 privacy를 존중하는 이미지에서 1 billion mask를 포함하는 지금까지 가장 큰 segmentation dataset을 구축한다. 이 모델은 새로운 이미지 분포와 task에 대해 zero-shot으로 transfer 할 수 있도록 promptable로 설계되었고 학습되었다. 우리는 다양한 task에서 능력을 평가한 결과, zero-shot 성능이 인상적임을 발견했다. 종종 이전 fully supervised 결과와 경쟁적이거나 능가한다. 우리는 computer vision의 foundation 모델로 연구를 촉진하기 위해 Segment Anything Model(SAM)과 1B 마스크와 11M 이미지가 포함된 데이터셋(SA-1B)를 https://segment-anything.com에서 공개한다.
1. Introduction
web-scale 데이터셋으로 pre-trained인 Large Language Model이 강력한 zero-shot과 few-shot 일반화로 NLP를 혁신했다. 이러한 ‘foundation model’은 그것들이 학습하는 동안 보지 못한 task와 데이터 분포에 일반화될 수 있다. 이러한 능력은 종종 prompt engineering을 통해 구현되며, 이는 수작업으로 작성된 텍스트를 사용하여 해당 작업에 유효한 텍스트 응답을 생성하도록 언어 모델을 유도하는 방식이다. web에서 방대한 text corpora를 사용하여 모델을 확장하고 학습하면, zero와 few-shot 성능은 놀라울 정도로 fine-tuning 모델과 잘 비교된다(때로 일치하기도 함). 실험적 경향은 모델 스케일, 데이터셋 크기와 전체 학습 계산량이 증가할수록 이러한 성능이 개선된다는 것을 보인다.
Foundation 모델은 computer vision에서도 탐구되었지만 규모는 제한적이다. 아마도 가장 두드러진 예시는 웹에서 짝지어진 text와 image를 정렬하는 방식이다. 예컨대 CLIP과 ALIGN은 contrastive learning을 사용하여 text와 image encoder를 학습 시켜 2가지 모달리티를 정렬한다. 일단 학습되면, 설계된 텍스트 프롬프트는 새로운 시각 컨셉과 데이터 분포에 대해 zero-shot 일반화를 가능하게 한다. 이러한 encoder들은 또한 다른 모듈과 효율적으로 결합하여 이미지 생성(DALLE)과 같은 downstream task를 수행할 수 있게 한다. vision과 language encoder에 많은 발전이 있었으나, computer vision은 이 범위를 넘어서는 광범위한 문제를 포함하며, 그중 많은 문제에 대해 풍부한 학습 데이터가 존재하지 않는다.
이 연구에서 우리의 목표는 image segmentation을 위한 foundation model을 만드는 것이다. 즉 우리는 promptable model을 개발하고 강력한 일반화를 가능하게 하는 task를 사용하여 광범위한 데이터셋에서 pre-train을 수행한다. 이 모델을 통해 새로운 데이터 분포에서 prompt engineering을 사용하여 다양한 downstream segmentation 문제를 해결하려 한다.
이 계획의 성공은 task, model, data라는 3가지 컴포넌트에 달려 있다. 이를 개발하기 위해 우리는 image segmentation에 대한 다음의 질문을 다룬다.
1.
어떤 task가 zero-shot generalization을 가능하게 하는가?
2.
어떤 model 아키텍쳐가 이에 해당하는가?
3.
어떤 data가 이 작업과 모델을 강력하게 하는가?
3가지 질문은 얽혀있으며, 포괄적인 해결책을 필요로 한다. 우리는 강력한 pre-training 목적을 제공하고 광범위한 downstream 응용을 가능하게 할만큼 promptable segmentation task를 정의하는 것에서 시작한다. 이 task는 유연한 prompting을 지원하고 prompt가 주어지면 실시간으로 segmentation mask를 출력하여 상호작용적인 사용을 가능하게 하는 모델을 필요로 한다. 우리의 모델을 학습하기 위해 다양한 대규모 스케일의 데이터 소스가 필요하다. 불행히도 segmentation을 위한 web-scale 데이터 소스가 없기 때문에, 이것을 해결하기 위해 우리는 ‘data engine’을 개발했다. 즉 우리는 우리의 효율적인 모델을 사용하여 데이터 수집을 지원하고, 새롭게 수집된 데이터를 사용하여 모델을 개선하는 작업을 반복한다. 다음으로 우리는 각 상호 연결된 컴포넌트를 소개하고, 우리가 생성한 데이터과 접근 방식의 효율성을 시연하는 실험을 설명한다.
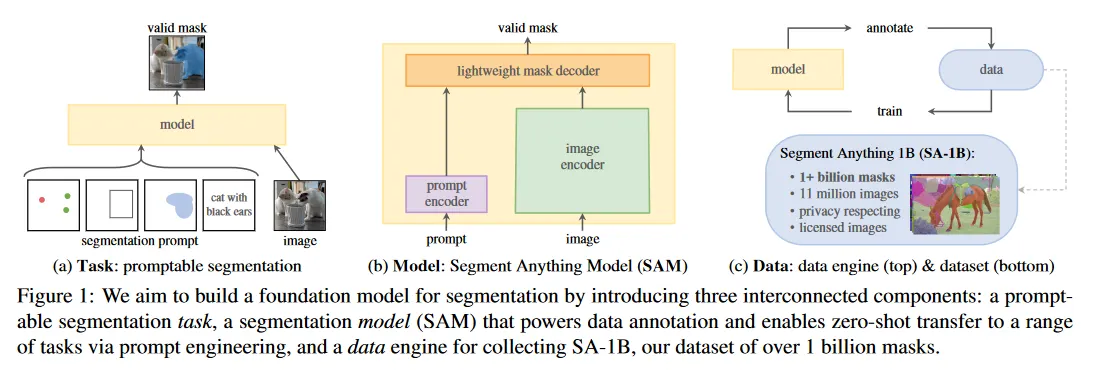
Task(섹션 2)
NLP와 최근 computer vision에서 foundation 모델은 새로운 데이터셋과 task를 위한 zero-shot과 few-shot learning을 수행할 수 있는 유망한 발전이다. 종종 ‘prompting’ 기법을 사용하여 구현한다. 일련의 작업에 영감을 받아 우리는 promptable segmentation task를 제안한다. 여기서 목표는 임의의 segmentation prompt가 주어지면 유효한 segmentation mask를 반환하는 것이다(그림 1a). prompt는 단순히 이미지에서 무엇을 segment를 지정하는 것이다. 예: prompt에는 object를 식별하는 공간적 또는 텍스트 정보가 포함될 수 있다. 유효한 출력 마스크의 요구사항은 prompt가 모호할 때도(예컨대 shirt 위의 점이 shirt 또는 그것을 입은 사람 모두를 의미할 수 있다) 출력은 최소 1개에 대해 합리적인 mask를 생성해야 한다는 의미이다. 우리는 promptable segmentation task를 pre-training 목적으로 사용하고, prompt engineering을 통해 일반적인 downstream segmentation task를 해결한다.
Model(섹션 3)
promptable segmentation tasks와 실제 사용의 목표는 모델 아키텍쳐에 제약을 부여한다. 특히 모델은 flexible prompt를 지원해야 하고, 상호작용을 허용하기 위해 실시간으로 mask를 계산해야 하며, ambiguity-aware 해야 한다. 놀랍게도 우리는 간단한 설계가 이 세 가지 제약을 모두 만족함을 발견했다. 강력한 이미지 encoder가 이미지 embedding을 계산하고, prompt encoder는 prompt를 embedding한 다음, 이 두 정보 소스를 lightweight mask decoder에서 결합하여 segmentation mask를 예측한다. 우리는 이 모델을 Segment Anything Model(SAM, 그림 1b)라 부른다. SAM을 이미지 encoder와 fast prompt encoder/mask decoder로 분리하여, 동일한 이미지 embedding를 다른 prompt와 함께 재사용할 수 있다(그 비용은 분할된다)
이미지 embedding이 주어지면, prompt encoder와 mask decoder는 웹 브라우저에서 ~50ms 안에 prompt에서 mask를 예측한다. 우리는 point, box, mask prompt에 초점을 맞추고 free-form text prompt와 관련된 초기 결과도 제시한다. SAM을 ambiguity-aware으로 만들기 위해, 단일 prompt에 대해 여러 mask를 예측하도록 설계하여, shirt vs person 예제와 같은 모호한 상황을 SAM이 자연스럽게 처리할 수 있게 했다.
Data Engine(섹션 4)
새로운 데이터 분포에 대한 강력한 일반화를 달성하기 위해 기존의 임의의 segmentation 데이터셋을 넘어는 대규모 다양한 집합에서 SAM을 학습하는 것이 필요했다. foundation 모델에 대한 전통적인 접근은 online에서 data를 얻는 것이지만 mask는 자연적으로 풍부하지 않기 때문에 우리는 대안 전략이 필요하다. 우리의 솔루션은 ‘data engine’을 구축하는 것이다. 즉 모델과 model-in-loop 데이터셋 주석을 공동 개발한다(그림 1c). 우리의 데이터 엔진은 assisted-manual, semi-automatic, fully automatic의 3가지 단계를 갖는다. 첫 단계에서 SAM은 전통적인 상호작용 segmentation 설정과 유사하게 annotating mask에서 annotator를 지원한다. 두 번째 단계에서 SAM은 prompting을 통해 일부 object에 대해 자동으로 mask를 생성하고, annotator들은 나머지 object를 annotating하는데 초점을 맞추어 mask 다양성을 높이는데 중점을 둔다. 마지막 단계에서 우리는 SAM을 foreground point의 regular grid로 prompt하여 이미지당 평균 ~100개의 고품질 mask를 산출한다.
Dataset(섹션 5)
우리의 최종 데이터셋인 SA-1B는 11M개의 라이센스와 개인정보 호보 이미지에서 1B 이상의 mask를 포함한다(그림 2). SA-1B는 우리의 데이터 엔진의 최종 단계를 사용하여 완전히 자동적으로 수집되었으며, 기존의 어떤 segmentation 데이터셋보다 400배 이상 많은 mask를 갖는다. 우리는 이 mask들이 고품질이고 다양하다는 것을 광범위하게 확인했다. SAM을 견고하고 일반적인 모델로 학습하는 데 사용하는 것을 너머, SA-1B가 새로운 foundation model을 구축하려는 연구에 가치 있는 자원이 되기를 희망한다.
Responsible AI(섹션 6)
우리는 SA-1B와 SAM을 사용할 때 발생할 수 있는 잠재적 공정성과 편향 문제를 연구하고 리포트한다. SA-1B의 이미지는 지리적과 경제적으로 다양한 나라에서 수집되었으며, SAM은 다양한 그룹의 사람들에 대해 유사한 성능을 발휘함을 발견했다. 이를 통해 우리의 작업이 현실 세계 사례에서 더 공정해지기를 희망한다. 우리는 모델과 데이터셋 카드를 부록에 제공한다.
Experiments(섹션 7)
우리는 SAM을 광범위하게 평가한다. 우선 새로운 23개의 다양한 segmentation 데이터셋에서 SAM이 단일 foregrounding point에서 고품질 마스크를 생성하며, 이는 종종 수작업으로 주석처리된 ground truth와 거의 일치함을 발견했다. 두번째, edge detection, object proposal generation, instance segmentation과 text-to-mask 예측의 초기 탐구를 포함하여 다양한 downstream task에서 zero-shot transfer 프로토콜을 사용해 일관된 강력한 양적과 질적 결과를 발견한다. 이러한 결과는 SAM이 prompt engineering을 통해 학습 데이터 너머의 object와 이미지 분포와 관련된 다양한 작업을 즉시 해결할 수 있음을 시사한다. 그럼에도 불구하고 개선의 여지는 남아 있다. 섹션 8에서 논의한다.
Release
우리는 연구 목적으로 SA-1B 데이터셋을 공개하며, open license(Apache 2.0)로 사용할 수 있도록 할 예정이다. 또한 online demo에서 SAM의 능력을 시연한다.

2. Segment Anything Task
우리는 NLP에서 영감을 받는다. 여기서 다음 토큰 예측 작업이 foundation model pre-training에 사용되며, prompt 엔지니어링을 통해 다양한 downstream task를 해결한다. segmentation을 위한 foundation 모델을 구축하기 위해 우리는 유사한 능력을 가진 task를 정의하는데 초점을 맞춘다.
Task.
우리는 prompt의 아이디어를 NLP에서 segmentation으로 변환하여 시작한다. 여기서 prompt는 foreground/background point 집합, 러프한 box나 mask, free-form text 이거나 일반적으로 이미지에서 무엇을 segment를 나타내는 정보일 수 있다. 따라서 promptable segmentation task는 주어진 prompt에 대해 유효한 segmentation을 반환하는 것이다. ‘유효한’ mask의 요구사항은 prompt가 모호하여 multiple object를 나타낼 지라도 (shirt vs person의 예, 그림 3) 그러한 object의 최소 1개에 대한 합리적인 mask를 출력해야 한다는 의미이다. 이 요구사항은 언어 모델이 모호한 prompt에 대해 일관성 있는 응답을 출력하는 것과 유사하다. 우리는 이러한 task이 자연스러운 pre-training 알고리즘을 제공하고, prompting을 통해 zero-shot으로 downstream segmentation으로 transfer할 수 있는 일반적인 방법을 이끌기 때문에 선택했다.

Pre-training.
promptable segmentation 작업은 각 학습 샘플에 대해 prompt(예. point, box, mask)의 시퀀스를 시뮬레이션 하고 model의 마스크 예측을 ground truth와 비교하는 자연스러운 pre-training 알고리즘을 제안한다. 우리는 이 방법을 interactive segmentation에서 차용했지만, interactive segmentation이 사용자 입력을 충분히 받은 후에 유효한 mask를 예측하는 것을 목표로 하는 반면, 우리의 목표는 임의의 prompt에 대해 prompt가 모호할지라도 항상 유효한 mask를 예측하는 것이다. 이것은 pre-trained 모델이 모호성을 포함하는 사용자 케이스에서도 효과적으로 작동할 수 있음을 보장한다. 이는 섹션 4의 데이터 엔진에서 필요한 automatic annotation과 같은 경우에 유용하다. 이 작업에서 성능을 잘 발휘하는 것은 도전적이며, 특별한 모델링과 학습 loss 선택이 필요 하다는 것에 유의하라. 섹션 3에서 논의한다.
Zero-shot transfer.
직관적으로 우리의 pre-training task는 모델이 추론 시간에 임의의 prompt에 적절하게 응답하는 능력을 부여한다. 따라서 적절한 prompt 엔지니어링을 통해 downstream task를 해결할 수 있다. 예컨대 고양이 instance segmentation에서 고양이 bounding box detector의 출력을 우리 모델에 prompt로 제공하여 해결할 수 있다. 일반적으로 많은 실용적인 segmentation task prompting으로 변환될 수 있다. automatic dataset labeling 외에도, 우리는 우리의 실험에서 5가지 다양한 예제 task를 탐구한다.
Related tasks.
segmentation은 광범위한 분야로 interactive segmentation, edge detection, super pixelization, object proposal generation, foreground segmentation, semantic segmentation, instance segmentation, panoptic segmentation 등이 있다. 우리의 promptable segmentation task의 목표는 prompt 엔지니어링을 통해 많은 (전체는 아닌) 기존과 새로운 segmentation task에 적용할 수 있는 범용적인 능력의 모델을 생성하는 것이다. 이 능력은 일반화 작업의 한 형식이다. 이것이 multi-task segmentation 시스템 작업과 다름에 유의하라. multi-task system에서 단일 모델이 fixed task 집합을 수행하지만, (예. joint semantic, instance, panoptic segmentation) 학습과 테스트 task는 동일하다. 우리의 작업에서 중요한 차이는 promptable segmentation을 위해 학습된 모델이 더 큰 시스템의 component의 역할로 추론 시간에 새롭고 다양한 task를 수행할 수 있다는 것이다. 예컨대 promptable segmentation model은 기존의 object detector와 결합하여 instance segmentation을 수행할 수 있다.
Discussion.
Prompting과 composition은 단일 모델이 확장 가능한 방식으로 사용될 수 있게 하는 강력한 툴로 모델 설계 시간에 알려지지 않은 작업도 잠재적으로 성취할 수 있다. 이 접근은 다른 foundation 모델이 사용되는 것과 유사하다. 예컨대 CLIP은 DALLE 이미지 생성 시스템의 text-image alignment component로 사용되는 방식과 같다. 우리는 prompt 엔지니어링 같은 기법에 의해 구동되는 composable 시스템 설계가 고정된 task 집합을 위해 특화된 학습된 시스템 보다 광범위한 응용을 가능하게 할 것으로 예상한다. promptable과 interactive segmentation을 composition의 관점에서 비교하는 것도 흥미롭다. interactive segmentation 방법은 인간 사용자를 염두에 두고 설계되는 반면, promptable segmentation을 위해 학습된 모델은 이후에 보이는 것처럼 더 큰 알고리즘 시스템으로 compose 될 수 있다.
3. Segment Anything Model
다음으로 promptable segmentation을 위한 Segment Anything Model(SAM)을 설명한다. SAM은 그림 4에 나오는 것처럼 3가지 component를 갖는다. image encoder, flexible prompt encoder, fast mask decoder가 그것이다. 우리는 (amortized) 실시간 성능을 위해 특별한 tradeoff을 통해 Transformer Vision Model을 기반으로 한다. 여기서는 component를 high-level로 설명하고, 상세한 내용은 부록 A에 남긴다.
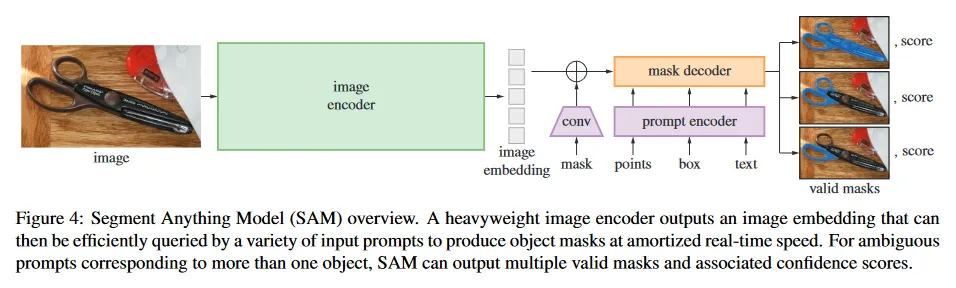
Image encoder.
확장성과 강력한 pre-training 방법에 대한 동기를 바탕으로 우리는 MAE pre-trained Vision Transformer(ViT)를 사용한다. 고해상도 입력을 처리하기 위해 최소한으로 조정했다. image encoder는 이미지당 한 번 실행되며, 모델을 prompting 하기 전에 적용할 수도 있다.
Prompt encoder.
우리는 두 가지 종류의 prompt를 고려한다. sparse(point, box, text)와 dense(mask). 우리는 point와 box를 positional encoding으로 표현하며, 각 프롬프트 유형에 대해 학습된 embedding과 함께 합산된다. free-form text는 CLIP에서 제공되는 off-the-shelf text encoder를 사용한다. Dense prompt(즉 mask)는 convolution을 이용하여 embedding 되고 image embedding과 element-wise로 합산된다.
Mask decoder.
mask decoder는 이미지 임베딩, prompt embedding과 출력 토큰을 mask로 효율적으로 매핑한다. 이 설계는 [14, 20]에서 영감 받았고, 수정된 Transformer decoder block과 dynamic mask prediction head를 활용한다. 우리의 수정된 decoder block은 prompt self-attention과 cross-attention을 두 가지 방향(prompt-to-image embedding과 그 반대 방향)으로 사용하여 모든 embedding을 업데이트한다. 두 개의 블록을 실행한 후에 이미지 embedding을 업샘플링하고 MLP가 출력 토큰을 dynamic linear classifier에 매핑하여 각 이미지 location에서 mask foreground 확률을 계산한다.
Resolving ambiguity.
출력이 하나일 때, 모델은 모호한 prompt가 주어지면 여러 유효한 마스크를 평균화한다.
이것을 해결하기 위해 우리는 모델이 단일 prompt에 대해 multiple 출력 마스크를 예측하도록 수정한다(그림 3). 우리는 3개 mask 출력이 대부분 일반적인 경우를 다루는데 충분하다는 것을 발견했다(중첩된 mask는 종종 최대 3겹이다. whole, part, subpart). 학습하는 동안 우리는 mask에 대한 minimum loss만 역전파한다. 마스크에 랭킹을 매기기 위해, 모델은 각 마스크에 대해 confidence score(즉 추정된 IoU)를 예측한다.
Efficiency.
전체 모델 설계는 효율성을 염두하여 만들어졌다. 사전 계산된 이미지 embedding이 주어지면 prompt encoder와 mask decoder는 웹 브라우저에서 CPU에서 50ms로 실행된다. 이 런타임 성능은 모델의 seamless, real-time interactive prompting을 가능하게 한다.
Losses and training.
우리는 [14]에서 사용된 focal loss와 dice loss의 선형 결합하여 mask 예측을 supvervise한다. 우리는 기하학적 prompt 혼합을 사용하여 promptable segmentation task을 학습한다(텍스트 prompt에 대해서 섹션 7.5 참조). [92, 37]을 따라 우리는 11 round에 걸쳐 mask에서 prompt를 무작위로 샘플링하여 interactive 설정을 시뮬레이션 하고, SAM이 우리의 데이터 엔진에 대해 seamlessly 통합되도록 한다.
4. Segment Anything Data Engine
인터넷에 segmentation mask가 풍부하지 않기 때문에, 우리는 1.1B mask dataset의 수집할 수 있도록 data engine을 구축했다. data engine은 3 단계로 이루어진다. (1) model 지원 수작업 주석 단계 (2) 자동으로 예측된 mask와 model 지원 주석이 혼합된 semi-automatic 단계 (3) 인간 주석자의 입력 없이 모델이 mask을 생성하는 fully-automatic 단계. 각 단계를 자세히 설명한다.
Assisted-manual stage.
첫 단계에서 전통적인 interactive segmentation과 유사하게, 전문적인 주석자의 팀이 브라우저 기반의 SAM이 구동하는 interactive segmentation 툴을 사용하여 foreground/background object를 클릭하여 mask를 라벨링한다. mask는 픽셀 정밀도 ‘brush’와 ‘eraser’ 툴을 사용하여 조정될 수 있다. 모델 지원 주석은 사전 계산된 이미지 embedding을 사용하여 브라우저 안에서 실시간으로 실행되어 interactive 경험을 제공한다. 우리는 라벨링 object에 semantic 제약을 부과하지 않고, 주석자들에게는 이름을 붙이거나 설명할 수 있는 객체를 라벨링하도록 권장했으나 이러한 이름이나 설명을 수집하지 않았다. 주석자들은 중요한 순서대로 object를 라벨링하도록 요청 받았으며, 마스크 주석에 30초 이상 소요될 경우 다음 이미지로 넘어가도록 권장 받았다.
이 단계의 시작에서 SAM은 일반적인 public segmentation 데이터셋을 사용하여 학습되었다. 충분한 데이터 주석 후에 SAM은 새롭게 주석처리된 mask만 사용하여 재학습 되었다. 더 많은 mask가 수집됨에 따라 이미지 encoder는 ViT-B에서 ViT-H로 확장되고 다른 아키텍쳐적 디테일도 진화된다. 우리는 모델을 총 6번 재학습했으며, 모델이 개선됨에 따라 mask 당 평균 주석 시간은 34초에서 14초로 감소했다. 14초는 COCO의 mask 주석 보다 6.5배 빠르고, extreme point를 사용한 bounding-box 보다 2배만 느리다. SAM이 개선됨에 따라 이미지당 mask의 평균 수는 20개에서 44개로 증가했다. 이 단계에서 우리는 120k 이미지에서 4.3M 마스크를 수집했다.
Semi-automatic stage.
이 단계에서 모델이 ‘무엇이든 segment’하는 능력을 향상 시키기 위해 mask의 다양성을 증가시키는데 초점을 맞춘다. 주석자들이 덜 두드러진 object에 초점을 맞추도록, 먼저 자동으로 confident mask를 검출한 다음 이러한 마스크로 채워진 이미지를 주석자들에게 제시하고 추가적으로 주석처리되지 않은 object를 주석처리하도록 요청했다. confident mask를 검출하기 위해 우리는 첫 번째 단계의 모든 mask를 사용하여 ‘object’라는 일반적인 카테고리를 사용하여 bounding box detector를 학습했다. 이 단계에서 우리는 추가적으로 180k 이미지에서 5.9M 마스크를 수집했다(총 10.2M mask). 첫 단계와 마찬가지로 새로 수집된 데이터를 사용해 주기적으로모델을 재학습했다(5번). 라벨링이 어려운 object들이 포함되어 mask 당 평균 주석 시간은 다시 34초로 증가했지만(automatic mask를 제외하고), 이미지 당 평균 mask 수는 44개에서 72개로 증가했다(automatic mask를 포함).
Fully automatic stage.
마지막 단계에서 모델에 대한 두 가지 주요한 진보 덕분에 주석 작업은 완전 자동이었다. 첫째, 이 단계의 시작에서 우리는 이전 단계에서 수집한 다양한 마스크를 포함한 충분한 mask를 수집하여 모델을 크게 개선했다. 두 번째, 이 단계에서 우리는 모호성 인식 모델을 개발하여 모호한 경우에도 유효한 mask를 예측하도록 한다. 구체적으로 우리는 모델을 32x32 regular grid의 point로 prompt하여 각 점에서 유효한 object에 해당할 수 있는 mask 집합을 예측한다. 모호성 인식 모델을 사용하여, point가 part 또는 sub-part에 놓이면, 모델은 subpart, part와 전체 object를 반환한다. 모델의 IoU prediction 모듈은 confident mask를 선택하는데 사용되며, 또한 stable mask만 선택했다(probability map을 와 로 thresholding할 때, 유사한 mask가 생성되면, 그 mask를 안정적이라 간주). 마지막으로 confident와 stable mask를 선택한 후에 non-maximal suppresion(NMS)를 적용하여 중복을 필터링한다. 더 작은 mask의 품질을 개선하기 위해 우리는 여러 중첩된 확대 이미지를 처리한다. 이 단계의 추가 디테일은 부록 B 참조. 우리는 fully automatic mask 생성을 데이터셋의 총 11M 이미지에 적용하여 총 1.1B 고품질 mask를 생성한다. 다음으로 결과 데이터셋 SA-1B 을 설명하고 분석한다.
5. Segment Anything Dataset
우리의 데이터셋 SA-1B는 11M의 다양하고, 고 해상도 라이센스를 포함하며, 개인 정보 보호가 적용된 이미지를 바탕으로 data engine을 통해 수집된 1.1M 고품질 segmentation mask를 갖는다. 우리는 SA-1B를 기존 데이터셋과 비교하고 mask 품질과 속성을 분석한다. 우리는 SA-1B를 computer vision foundation 모델의 미래 개발을 돕기 위해 공개한다. SA-1B는 연구자들을 보호하기 위해 특정 연구에 선호되는 라이선스 정책 하에 배포할 예정이다.
Images.
우리는 사진작가들과 직접 협력하는 제공업체로부터 새로운 11M 이미지 라이센스를 받았다. 이러한 이미지는 고해상도(평균적으로 3300x4950 픽셀)이고 그 결과 데이터 크기 때문에 접근과 저장에 어려움이 있을 수 있다. 따라서 우리는 짧은 쪽이 1500 픽셀이 되도록 downsampling하여 배포한다. downsampling 후에도 우리의 이미지는 기존의 많은 vision dataset 보다 훨씬 높은 해상도이다.(예: COCO 이미지는 480x640 픽셀이다). 오늘날 대부분의 모델은 훨씬 낮은 해상도의 입력에서 작동함에 유의하라. 얼굴과 자동차 라이센스 번호판은 blur하고 공개한다.
Masks.
우리의 data engine은 1.1B mask를 생성하며, 99.1%는 완전 자동으로 생성되었다. 따라서 automatic mask의 품질이 매우 중요하다. 우리는 그것들을 전문가의 주석과 직접 비교하고 다양한 mask 속성이 주요 segmentation 데이터셋과 어떻게 비교되는지 본다. 아래 분석과 섹션 7 실험에서 확인할 수 있는 것처럼 우리의 automatic mask는 매우 고품질이고 모델을 학습에 효과적이다. 이러한 발견에 동기부여 받아 SA-1B는 automaticaly 생성된 mask만 포함한다.
Mask quality.
mask 품질을 평가하기 위해 우리는 무작위로 500개 이미지(50k mask)를 샘플링하고, 전문 주석자들에게 모든 mask의 품질을 개선하도록 요청한다. 따라서 주석자들은 우리의 모델과 픽셀 정밀도 ‘brush’와 ‘eraser’ editing 도구를 사용한다. 이러한 절차는 자동으로 예측된 mask와 전문적으로 수정된 mask의 pair를 생성하며, 각 pair 사이의 IoU를 계산한 결과, 94%의 pair가 90% 이상의 IoU를 기록했다(97%의 pair는 75% 이상의 IoU). 참고로 prior 작업에서 주석자 사이의 일관성을 85-91% IoU로 추정한다. 섹션 7의 실험에서 다양한 데이터셋과 비교했을 때, mask 품질이 높다는 것을 인간 평가로 확인했으며, automatic mask로 학습된 모델이 data engine에서 생성된 모든 mask를 사용하는 것과 근접함을 확인했다.
Mask properties.
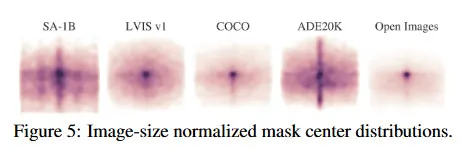
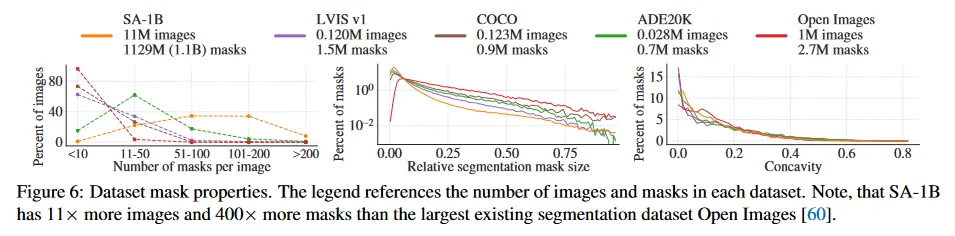
그림 5에서 SA-1B의 object 중심의 공간적 분포를 가장 큰 기존 segmentation 데이터셋과 비교하여 그린다. 모든 데이터셋에서 공통적으로 사진가 편향이 존재한다. SA-1B는 LVIS v1과 ADE20K와 비교하여 유사한 데이터셋보다 이미지 코너 커버리지가 더 넓은 반면 COCO와 Open Image V5는 더 두드러지는 center bias를 갖는다. 그림 6(legend)에서 이러한 데이터셋을 크기별로 비교한다. SA-1B는 두 번째 큰 데이터셋인 Open Image 보다 이미지가 11배 더 많고 mask가 400배 더 많고 평균적으로 Open Image 보다 이미지당 36배 더 많은 mask를 갖는다. 이 측면에서 가장 가까운 데이터셋은 ADE20K이고 여전히 이미지당 마스크가 3.5배 적다. 그림 6 중간에서 이미지에 대한 mask의 상대적 크기(mask area의 제곱근을 이미지 area로 나눈 값)를 보인다. 예상대로 우리의 데이터셋이 이미지당 더 많은 mask를 가지므로, 상대적으로 small과 medium mask가 더 많이 포함된다. 마지막으로 형태의 복잡성을 분석하기 위해, mask 오목성(mask의 볼록의 area에 의해 나눠짐 1-mask area)을 본다. 그림 6 오른쪽. mask 크기와 shape 복잡성이 상관있기 때문에, 우리는 우선 mask 크기별로 계층화된 샘플링을 수행하여 각 데이터셋의 마스크 크기 분포를 조정한다. 우리는 mask의 오목성 분포가 다른 데이터셋과 대체로 유사함을 발견한다.
6. Segment Anything RAI Analysis
다음으로 SA-1B와 SAM을 사용할 때 발생할 수 있는 공정성 문제와 편향을 조사하여 Responsible AI(RAI) 분석을 수행한다. 우리는 SA-1B의 지리적 및 소득 분포와 SAM의 공정성 사람들의 보호된 속성 따라 중점적으로 분석한다. 또한 dataset, data annotation, model card를 부록 F에서 제공한다.
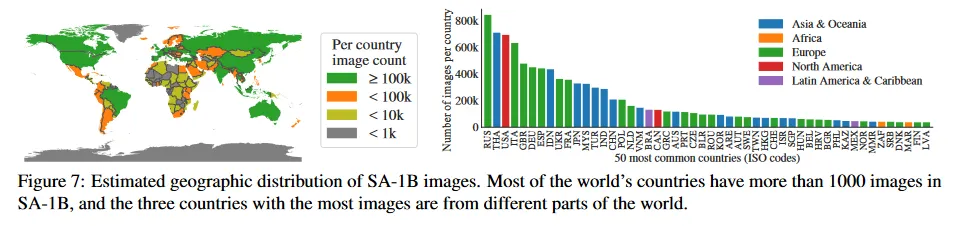
Geographic and income representation.
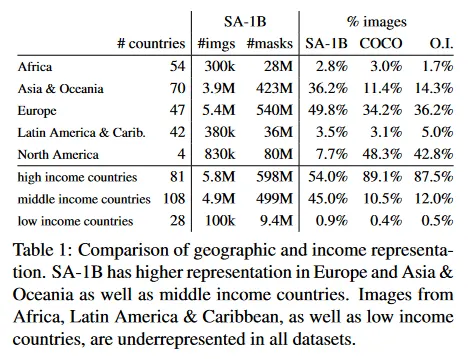
우리는 표준 방법(부록 C)를 사용하여 이미지가 촬영된 국가를 추론한다. 그림 7에서 우리는 SA-1B(left)의 국가별 이미지 수와 이미지 수가 가장 많은 50개 국가(오른쪽)을 시각화한다. 상위 3개 국가가 세계의 다른 지역임에 주목한다. 다음으로 Table 1에서 SA-1B, COCO, Open Images의 지리적과 소득 분포를 비교한다. SA-1B는 유럽과 아시아 및 오세아니아 지역과 중소득 국가의 이미지 비율이 상당히 높다. 모든 데이터셋은 아프리카와 소득이 낮은 국가들을 과소 나타낸다. SA-1B에서는 아프리카를 포함하여 모든 region에서 최소 28 M 마스크를 가지며, 이는 기존 데이터셋보다 최소 10배 더 많은 mask의 수이다. 마지막으로 region과 income에 따라 이미지당 mask 평균수가(표시되지 않음) 비교적 일정하게 나타난다(이미지당 94-108).
Fairness in segmenting people.
우리는 SAM의 구별 성능을 측정하기 위해 인식된 성별 표현, 연령대, 피부톤에 따른 잠재적 공정성 문제를 조사한다. gender presentation과 age에 대해서는 More Inclusive Annotations for People(MIAP)를 사용하고, skin tone에 대해서는 독점 데이터셋(부록 C)을 사용했다. 우리의 평가는 1개 및 3개 포인트를 랜덤 샘플링하여 시뮬레이션된 interactive segmentation을 사용 한다(부록 D). Table 2(top left)는 인식된 성별 표현에 대한 결과를 보인다. 여성이 detection과 segmentation 데이터셋에서 과소 대표된 것으로 알려져 있지만, SAM은 그룹 간에 유사한 성능을 보인다. Table 2(bottom left)에서는 인식된 나이에 대한 분석을 반복했으며, 어린 사람과 나이든 사람들이 대규모 데이터셋에서 과소 대표된 것으로 나타났다. SAM은 나이가 많은 것으로 인식된 사람들에서 가장 좋은 성능을 보였지만 confidence interval이 크다. 마지막으로 Table 2 (right)에서 인식된 피부 톤에 대한 분석을 반복했으며, 더 밝은 피부색이 더 많이 대표되고 어두운 피부색이 대규모 데이터셋에서 덜 대표되는 것으로 알려져 있다. MIAP은 인식된 피부색 주석을 포함하지 않기 때문에 우리는 Fitzpatrick 피부 유형에 대한 주석이 포함된 proprietary dataset을 사용했으며, 이는 1(가장 밝은)에서 6(가장 어두운) 범위를 갖는다. 평균 값이 다소 차이가 있지만 그룹 사이에 큰 차이가 없음을 발견했다. 우리는 이러한 결과가 작업 특성에서 비롯된 것으로 보고 있으며, SAM이 더 큰 시스템의 component로 사용될 때 드러날 수 있음을 인지한다. 마지막으로 부록 C에서 우리는 옷 segmenting으로 확장한다. 여기서 인식된 성별 표현에 대한 편향이 나타남을 발견한다.

7. Zero-Shot Transfer Experiments
이 섹션에서 우리는 SAM(Segment Anything Model)을 사용한 zero-shot transfer 실험을 제시한다. 우리는 5가지 task를 고려하며, 이것의 4개는 SAM을 학습하는데 사용된 promptable segmentation task에서 매우 다르다. 이러한 실험은 SAM을 학습하는 동안 보지 못한 데이터셋과 task에서 평가한다(우리의 ‘zero-shot transfer’는 CLIP에서 사용을 따른다). 이 데이터셋에는 underwater나 ego-centric 이미지 같은(그림 8) 새로운 이미지 분포를 포함할 수 있다.

우리의 실험은 promptable segmentation의 핵심 목표인 임의의 prompt에서 유효한 mask를 생성하는 시험에서 시작한다. 우리는 단일 foreground point prompt와 같이 더 구체적이지 않은 prompt일 때 모호해질 가능성이 높기 때문에 이 도전적인 시나리오를 강조한다. 그 다음으로 우리는 low, mid, high level 이미지 이해를 넘나드는 일련의 실험을 제시하며, 이는 대략적으로 이 분야에서 역사적 발전을 평행으로 따른다. 구체적으로 우리는 SAM에게 다음을 prompt 한다. (1) edge detection 수행, (2) segment anything. 즉 object proposal generation, (3) segment detected object. 즉 instance segmentation, (4) POC로써 free-form text에서 object를 segment. 이러한 4가지 task는 SAM이 학습되고 구현된 promptable segmentation task에서 매우 다르며 prompt 엔지니어링을 통해 구현된다. 우리의 실험은 ablation study로 결론내린다.
Implementation.
별도로 명시하지 않는 한 (1) SAM은 MAE pre-trained ViT-H 이미지 encoder를 사용하고 (2) data engine의 마지막 단계에서 자동적으로 생성된 mask만 포함하는 SA-1B에서 학습된다. 다른 모든 모델과 하이퍼파라미터 같은 학습 세부 사항은 부록 A 참조.
7.1. Zero-Shot Single Point Valid Mask Evaluation
Task.
우리는 single foreground point에서 object를 segmenting하는 것을 평가한다. 이 task는 one point가 여러 object를 나타낼 수 있기 때문에 ill-posed이다. 대부분의 데이터셋에서 ground truth mask는 가능한 모든 mask를 열거하지 않기 때문에 automatic metric을 신뢰하지 못하게 만들 수 있다. 그러므로 우리는 예측과 ground truth mask 사이의 모든 IoU의 평균인 표준 mIoU 메트릭에 더해 주석자들이 마스크 품질을 1(nonsense)에서 10(pixel-perfect)까지 평가하는 인간 연구를 보완적으로 수행한다. 상세한 내용은 부록 D1, E, G 참조
기본적으로 우리는 interactive segmentation에서 표준 평가 프로토콜을 따라 ground truth mask의 ‘center’(mask의 내부 거리 변환의 최대값)에 해당하는 point를 샘플링한다. SAM이 multiple mask를 예측할 수 있는 능력이 있기 때문에, 우리는 기본적으로 모델의 가장 confident mask만 평가한다. baseline은 모든 single-mask 방법이다. 우리는 주로 RITM과 비교하는데, 이것은 다른 강력한 baseline과 비교하여 우리의 벤치마크에서 가장 우수한 성능을 보였다.
Datasets.
우리는 다양한 이미지 분포를 갖는 23개의 새로운 dataset suit를 사용한다. 그림 8은 dataset을 리스트업하고 각각에서 샘플을 보인다(더 상세한 것은 부록에서 Table 7 참조). 우리는 mIoU 평가에 모든 23개 데이터셋을 사용한다. 인간 연구에서는 리소스 요구 사항으로 인해 그림 9b에서 리스트된 하위 집합을 사용한다. 이러한 하위 집합에는 automatic 메트릭을 따라 SAM이 RITM을 능가하거나 열등한 성능을 데이터셋이 모두 포함된다.
Results.
우선 23개 dataset의 full suite에 대해 automatic 평가를 수행하고 mIoU를 사용하여 RITM과 비교한다. 데이터셋 별 결과는 그림 9a에 그린다. SAM은 23개 데이터셋에서 16개에서 RITM 보다 더 높은 결과를 산출하며 최대 47 IoU까지 차이가 난다. 우리는 또한 oracle 결과를 제시한다. 이것은 가장 신뢰할 수 있는 것 대신 SAM의 3개 mask 중 가장 관련성이 높은 것을 ground truth와 비교하여 선택한 것이다. 이를 통해 automatic 평가에서 모호성의 영향을 확인할 수 있다. 특히 oracle을 사용하여 모호성 해결하면 SAM은 모든 데이터셋에서 RITM을 능가한다.
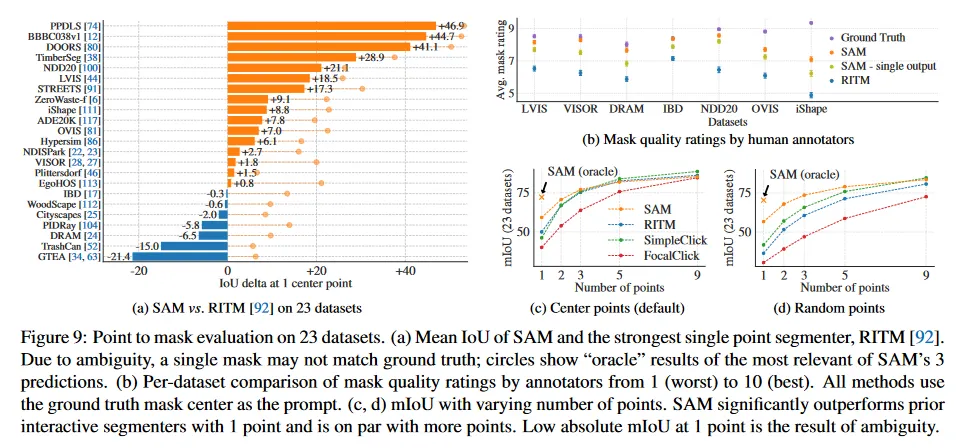
그림 9b에서 인간 연구 결과를 보인다. Error bar는 평균 mask rating에 대한 95% confidence intervals이다(모든 차이는 유의미하다. 부록 E 참조). 주석자들은 SAM의 mask의 품질을 가장 강력한 baseline인 RITM과 비교하여 일관되게 훨씬 높게 rate한 것을 볼 수 있다. ablated인 single output mask를 갖는 모호성 ‘미인식’ 버전의 SAM은 일관되게 rating이 낮지만 여전히 RITM보다 높다. SAM의 평균 rating은 7과 9 사이이고 이것은 정성적인 rating 가이드라인에 해당한다. ‘높은 평점(7-9): object는 식별가능하고, 에러는 적고 드물다(예: 작은, 많이 가려진 연결되지 않은 component를 놓침). 이러한 결과는 SAM이 single point에서 유효한 mask를 segment 하는 것을 학습했다는 것을 나타낸다. DRAM과 IBD 같은 데이터셋에서 SAM은 automatic 메트릭에서 열등한 성능을 보였지만, 인간 연구에서는 일관되게 더 높은 rating을 받았다.
그림 9c는 추가적인 baseline인 SimpleClick과 FocalClick을 보인다. 이것들은 RITM과 SAM 보다 single point 성능이 낮다. point의 수가 1에서 9로 증가함에 따라 방법들 간의 격차가 감소함을 관찰할 수 있다. 이것은 task가 쉬워짐에 따라 예상된 것이며, SAM은 매우 높은 IoU 체제에 최적화 되어 있지 않았다. 마지막으로 그림 9d에서 default center point 샘플링을 random point sampling으로 교체한 것을 보인다. 우리는 SAM과 baseline 사이의 격차가 커지는 것을 관찰하고, SAM이 어떤 sampling 방법 하에서도 비교 가능한 결과를 달성할 수 있음을 관찰한다.
7.2. Zero-Shot Edge Detection
Approach.
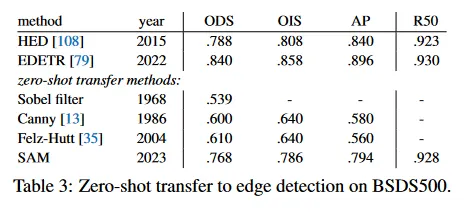
우리는 BSDS500을 사용하여 SAM을 전통적인 low-level task인 edge detection에서 평가한다. 우리는 우리의 automatic mask 생성 파이프라인의 단순화 버전을 사용한다. 구체적으로 SAM에 16x16 regular grid로 foreground point를 프롬프트하여 768개의 mask를 예측한다(point 당 3개). 중복된 mask는 NMS에 의해 제거된다. 그 다음 unthresholded mask 확률 맵에 Sobel filtering과 edge NMS를 포함한 표준 lightweight 후처리를 통해 edge map을 계산한다(자세한 것은 부록 D.2 참조).
Results.
우리는 그림 10에서 대표적인 edge map을 시각화한다(더 자세한 것은 그림 15 참조). 정성적으로 우리는 SAM이 edge detection에 대해 학습되지 않았음에도 합리적인 edge map을 생성함을 관찰한다. ground truth와 비교할 때, SAM은 BSDS500에서 주석처리되지 않은 합리적인 것을 포함하여 더 많은 edge를 예측한다. 이러한 bias는 Table 3에서 정량적으로 반영되며 50% 정밀도에서의 recall(R50)은 높은 대신 정밀도가 떨어진다. SAM은 자연히 BSDS500의 bias(즉 어떤 edge를 억제해야 하는지)를 학습한 최첨단 모델에 뒤쳐지지만, HED와 같은 선구자 딥러닝 방법과 비교해도 잘 수행되고, 이전의(구식이지만) zero-shot transfer 방법 보다 훨씬 나은 성능을 보인다.

7.3. Zero-Shot Object Proposals
Approach.
다음으로 우리는 SAM을 mid-level task인 object proposal 생성에서 평가한다. 이 task는 object detection 연구에서 선구자적인 시스템에서 중간 단계를 제공함으로써 중요한 역할을 수행한다. object proposal을 생성하기 위해 우리는 automatic mask 생성 파이프라인의 약간 수정된 버전을 실행하고 이 mask들을 proposal로 출력한다(자세한 것은 부록 D.3 참조)
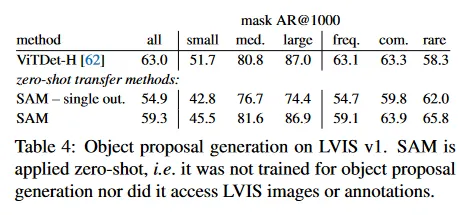
우리는 LVIS v1에서 standard average recall(AR) 메트릭을 계산한다. LVIS는 많은 카테고리를 포함하고 있어 도전적인 테스트를 제공한다. 우리는 ViTDet detector(cascade Mask R-CNN ViT-H 사용)로 구현된 강력한 baseline과 비교한다. 이 ‘baseline’은 AR을 개선하기 위해 설계된 ‘Detector Masquerading as Proposal generator’(DMP) 방법에 해당하며 매우 까다로운 비교이다.
Results.
Table 4에서 보이듯, ViTDet-H의 detection을 object proposal로 사용하는 것(AR을 개선하는 DMP 방법)이 전체적으로 가장 높은 성능을 수행한다. 그러나 SAM은 여러 메트릭에서 주목할만하다. 특히 SAM은 medium, large, 희귀하고 일반적인 object에서 ViTDet-H를 능가한다. 실제로 SAM은 small과 빈번한 object에 대해서만 ViTDet-H를 밑돌았다. 이것은 ViTDet-H가 SAM과 달리 LVIS에서 학습되었기 때문에 LVIS 특유의 annotation 편향을 쉽게 학습할 수 있기 때문이다. 우리는 또한 ablated인 모호성 미인식 버전의 SAM(single out)과도 비교한다. 이것은 모든 AR 메트릭에서 SAM 보다 매우 나쁘게 수행된다.
7.4. Zero-Shot Instance Segmentation
Approach.
high-level vision으로 넘어가, 우리는 SAM을 instance segmenter의 segmentation 모듈로 사용한다. 구현은 간단하다. 우리는 object detector(이전에 사용된 ViTDet)를 실행하고, 그것의 출력을 사용하여 SAM을 prompt한다. 이것은 SAM을 더 큰 시스템에 구성하는 방법을 보여준다.
Results.
우리는 Table 5에서 COCO와 LVIS에서 SAM과 ViTDet에 의해 예측된 mask를 비교한다. mask AP 메트릭을 보면 두 데이터셋 모두에서 격차가 있지만, SAM은 ViTDet에 비해 상당히 근접한 성능을 보인다. 출력을 시각화하면, SAM mask가 ViTDet의 것보다 crisper boundary에서 낫고, 질적으로 더 낫다는 것을 관찰한다(부록 D.4와 그림 16 참조). 이 관찰을 탐구하기 위해 우리는 주석자들에게 ViTDet mask과 SAM mask의 품질을 1에서 10까지 평가하도록 하는 추가 인간 연구를 수행한다. 그림 11에서 인간 연구에서 SAM이 일관되게 ViTDet를 능가하는 것을 볼 수 있다.
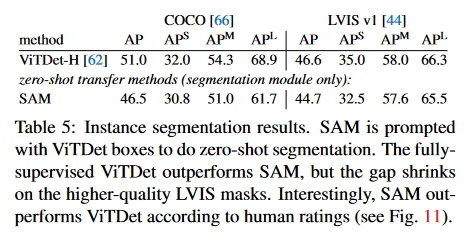
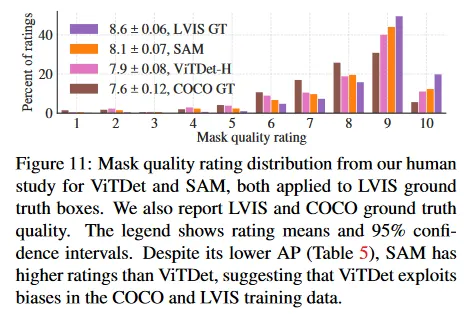
COCO에서 mask AP 격차는 더 크고 ground truth 품질은 상대적으로 낮다(인간 연구에 의해 확인됨)는 것을 근거로, ViTDet가 COCO mask의 특정한 bias를 학습했다고 가정한다. SAM은 zero-shot 방법이므로 이러한 (일반적으로 바람직하지 않은) bias를 활용할 수 없다. LVIS 데이터셋은 더 높은 품질의 ground truth를 갖지만 특정한 idiosyncrasies(특이성)이 존재하고(예: mask가 구멍을 포함하지 않고 단순한 다각형으로 구성됨) model vs amodal mask에 대한 bias가 존재한다. 다시말해 SAM은 이러한 bias를 학습하지 않지만 ViTDet은 그것들을 활용한다.
7.5. Zero-Shot Text-to-Mask
Approach.
마지막으로 우리는 free-form text에서 object를 segmenting하는 더 높은 레벨 task를 고려한다. 이 실험은 SAM이 텍스트 프롬프트를 처리하는 능력을 보이는 proof-of-concept이다. 이전 모든 실험에서 모두 동일한 SAM을 사용했지만, 여기서는 SAM의 학습 절차를 text-aware를 하도록 수정했다. 그러나 새로운 텍스트 주석은 필요하지 않다. 구체적으로 각 수작업으로 수집된 mask area가 보다 큰 각 mask에 대해 CLIP image embedding을 추출한다. 그 다음 학습 중에 SAM에 첫 번째 상호작용으로 추출된 CLIP 이미지 embedding을 prompt로 제공한다. 여기서 핵심 관찰은 CLIP의 이미지 embedding이 그것의 text embedding과 정렬되도록 학습되었기 때문에, 우리는 이미지 embedding으로 학습할 수 있지만 추론 시에 텍스트 embedding을 사용할 수 있다는 것이다. 즉 추론시간에 CLIP의 텍스트 encoder로 텍스트를 처리하고 결과 텍스트 embedding을 SAM에 프롬프트로 제공한다(자세한 내용은 D.5 참조).
Results.
우리는 그림 12에서 정성적 결과를 보인다. SAM은 ‘a wheel’ 같은 간단한 텍스트 프롬프트 뿐만 아니라 ‘beaver tooth grille’ 같은 phase로도 object를 segment할 수 있다. SAM이 텍스트 프롬프트만으로 올바른 object를 고르는 것을 실패할 때, [31]과 유사하게 추가 포인트를 제공하면 종종 예측이 수정된다.

7.6. Ablations
우리는 single center point prompt protocol을 사용하여 23개 데이터셋 suite에서 여러 ablation을 수행한다. single point가 모호할 수 있고, 모호성은 ground truth에 나타나지 않을 수 있다는 것을 떠올려라. ground truth에는 point 당 single mask만 포함하기 때문이다. SAM이 zero-shot transfer 설정에서 수행되기 때문에, SAM의 top-ranked mask와 data 주석 가이드라인에 따른 mask 사이에 시스템적 bias가 존재할 수 있다. 따라서 우리는 ground truth와 비교한 최고의 mask(oracle)도 추가로 리포트한다.
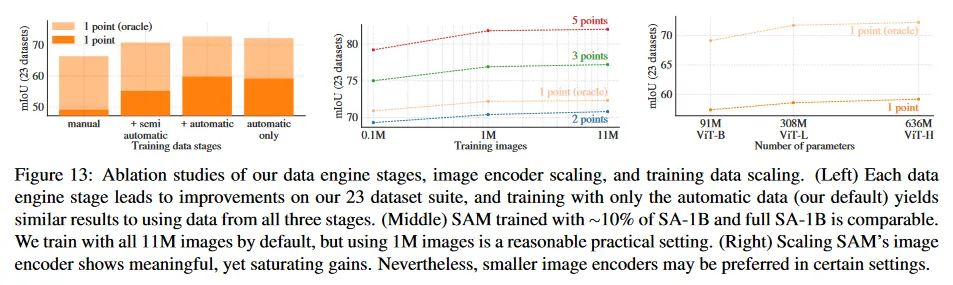
그림 13(왼쪽)은 data engine 단계에서 누적된 데이터에 학습될 때 SAM의 성능을 보인다. 각 단계가 mIoU를 증가시키는 것을 볼 수 있다. 3 단계를 모두 사용하여 학습할 때, automatic mask가 수작업, semi-automatic mask보다 훨씬 많다. 이것을 해결하기 위해 우리는 학습하는 동안 수작업과 semi-automatic을 10배 oversampling하는 것이 최고 결과를 제공한다는 것을 발견했다. 이 설정은 학습을 복잡하게 한다. 따라서 우리는 자동적으로 생성된 마스크만 사용하는 4번째 설정을 테스트한다. 이 데이터를 사용한 SAM은 모든 데이터를 사용할 때보다 약갖 낮은 성능(약 0.5 mIoU)을 보였다. 따라서 기본적으로 우리는 학습 설정을 간단하게 하기 위해 자동적으로 생성된 mask만 사용한다.
그림 13(중간)에서 데이터 볼륨의 영향을 본다. 전체 SA-1B는 11M 이미지를 포함하며, 이 데이터를 1M와 0.1M개로 균등하게 subsample한다. 0.1M 이미지의 경우 모든 설정에서 큰 mIoU 감소를 관찰한다. 그러나 전체 데이터셋의 10%인 1M 이미지를 사용하면, 전체 데이터셋을 사용하는 것과 유사한 결과를 볼 수 있다. 약 100M의 mask를 포함하는 이 데이터 범위는 많은 실용 사례에서 실용적인 설정이 될 수 있다.
마지막으로 그림 13(오른쪽)은 ViT-B, ViT-L과 ViT-H 이미지 encoder를 사용한 결과를 보인다. ViT-H는 상당히 ViT-B를 능가하지만 ViT-L에 대해서는 약간의 이득만 갖는다. 추가적인 이미지 encoder 확장은 현재로서는 유익함이 나타나지 않는다.
8. Discussion
Foundation models.
pre-trained 모델은 머신 러닝 초기부터 downstream task에 적용되었다. 이러한 패러다임은 최근 몇 년간 규모에 대한 강조가 커지면서 점점 더 중요해졌고, 이런 모델은 최근 ‘foundation models’이라는 이름으로 리브랜딩되었다. 즉 ‘광범위한 데이터셋에서 학습되고, 다양한 downstream task에 적용할 수 있는 모델’이다. 우리의 작업은 이러한 정의에 잘 연관된다. 이미지 segmentation을 위한 foundation model은 computer vision의 중요한 부분이지만 전체적인 범위로는 제한적이라는 점을 주목할 필요가 있다. 우리는 또한 우리의 접근과 [8]에서 강조한 foundation model에서의 self-supervised learning과 대비된다. 우리의 모델이 self-supervised 기법(MAE)를 사용하여 초기화되었지만, 그 능력의 주요한 부분은 능력은 대규모 supervised 학습에서 온다. 우리의 data engine처럼 주석을 확장할 수 있는 경우, supervised 학습이 효과적인 해결책을 제공한다.
Compositionality.
pre-trained 모델은 학습 시점에 상상했던 능력을 넘어서는 새로운 능력을 제공할 수 있다. 주목할만한 예는 어떻게 CLIP이 DALLE와 같은 더 큰 시스템의 컴포넌트로 사용되는 방식이다. 우리의 목표는 SAM을 통해 이러한 composition를 간단하게 만드는 것이다. 우리는 SAM이 광범위한 segmentation prompt에 대해 유효한 mask를 예측하도록 요구함으로써 이를 달성하고자 한다. 그 효과는 SAM과 다른 컴포넌트 사이의 믿을만한 인터페이스를 만드는 것이다. 예컨대 MCC는 SAM을 사용하여 관심있는 object를 segment하고 단일 RGB-D 이미지에서 본적 없는 object에 대한 3D reconstruction에서 강력한 일반화를 달성할 수 있다. 또 다른 예는 SAM은 wearable device를 통해 검출된 gaze point(시선 포인트)로 프롬프트 될 수 있고, 새로운 응용을 가능하게 한다. SAM의 ego-centric 이미지 같은 새로운 도메인에 대한 일반화 능력 덕분에 이런 시스템은 추가 학습 없이도 작동할 수 있다.
Limitations.
SAM이 일반적으로 잘 수행되지만 완벽하지는 않다. 이것은 미세한 구조를 놓칠 수 있고, 작은 분리된 component를 hallucinate 하거나, zoom-in 방식으로 더 계산 집약적 방법만큼 경계선을 선명하게 생성하지 못한다. 일반적으로 많은 포인트가 제공될 때 전용 interactive segmentation 방법이 SAM을 능가할 것으로 예상한다. 이런 방법과 달리 SAM은 높은 IoU interactive segmentation보다 일반성과 폭넓은 사용을 위해 설계되었다. 게다가 SAM은 실시간으로 prompt를 처리할 수 있지만, 무거운 이미지 encoder를 사용할 때 전체 성능은 실시간이 아니다. text-to-mask task에 대한 우리의 시도는 탐구적이고 완전히 견고하지 않지만 더 많은 노력을 기울이면 개선될 수 있다고 믿는다. SAM은 많은 task를 수행할 수 있지만, semantic과 panoptic segmentation을 구현하는 간단한 prompt를 설계하는 방법은 아직 불분명하다. 마지막으로 domain-specific 도구들[7]은 해당 도메인에서 SAM을 능가할 것을 예상한다.
Conclusion.
Segment Anything 프로젝트는 image segmentation을 foundation model의 영역으로 끌어올리기 위한 시도이다. 우리의 주요 기여는 새로운 task(promptable segmentation), model(SAM), dataset(SA-1B)으로 이러한 도약을 가능하게 한다. SAM이 foundation 모델의 지위를 달성할지는 커뮤니티에서 어떻게 사용되는지지에 달려 있지만, 이 연구의 관점, 1B mask 배포, 우리의 promptable segmentation model이 앞으로 나아가는 길을 닦는데 도움이 될 것이라 기대한다.
