
ABSTRACT
우리는 object detection을 위한 간단하고 일반적인 프레임워크인 Pix2Seq를 제안한다. task에 관한 prior 지식을 명시적으로 통합하는 기존 접근과 달리 우리는 object detection을 관찰된 픽셀 입력을 조건으로 한 언어 모델링 task로 object detection을 변환한다. object description(예: bounding box와 class label)은 이산 토큰의 시퀀스로 표현되고, 우리는 신경망을 학습하여 이미지를 인식하고 원하는 시퀀스를 생성한다. 우리의 접근은 주로 신경망이 object가 어디에 있고 무엇인지를 안다면 단지 단지 그것들을 어떻게 읽어내는지를 가르치면 된다는 직관에 기반을 둔다. task-specific data augmentation을 사용하는 것 외에는 task에 관한 최소한의 가정만 사용하며, 매우 특화되고 매우 잘 최적화된 detection 알고리즘과 비교하여 도전적인 COCO 데이터셋에서 경쟁력 있는 결과를 달성한다.
1 INTRODUCTION
visual object detection 시스템은 이미지에서 사전 정의된 카테고리의 모든 object를 인식하고 위치를 식별하는 것을 목표로 한다. 검출된 객체는 일반적으로 bounding box와 연관된 클래스 라벨로 설명된다. task의 어려움 때문에, 대부분의 기존 방법들은 조심스럽게 설계되고 아키텍쳐와 loss 함수의 선택에서 상당한 양의 prior 지식과 포함하여 고도로 커스터마이징 된다. 예컨대 많은 아키텍쳐들은 bounding box proposal의 사용에 맞춰 조정된다(예: region proposal과 RoI pooling). 다른 방법들은 object binding을 위한 object 쿼리의 사용에 의존한다. loss 함수도 종종 bounding box의 사용에 맞춰지거나(예: box regression, set-based matching), bounding box에 대한 intersection-over-union(IoU)을 포함한 특정한 성능 메트릭을 통합한다. 이러한 시스템들이 self-driving car, 의학 이미지 분석, 농업 등 무수한 도메인에서 응용되지만, 이들의 특화성과 복잡성은 더 큰 시스템으로 통합하거나 general intelligence와 연관된 훨씬 넓은 영역의 task로 일반화하는데 어려움을 준다.
이 논문은 새로운 접근을 지지한다. 이것은 신경망이 object가 어디에 있고 무엇인지 안다면, 그것을 읽어 내는 방법만 가르치면 된다는 직관에 기반한다. object를 ‘설명하도록’ 학습함으로써, 모델은 픽셀 관찰을 통해 ‘언어’를 기반으로 유용한 object representation을 학습할 수 있다. 이것은 우리의 Pix2Seq 프레임워크(그림 1)에서 실현된다. 이미지가 주어지면 우리 모델은 object description(예: object bounding box와 class label)에 해당하는 이산 토큰의 시퀀스를 생성하며, 이것은 이미지 captioning 시스템을 연상시킨다. 근본적으로 우리는 object detection을 픽셀 입력을 조건으로 하는 언어 모델링 task로써 변환하였고, 이 모델 아키텍쳐와 loss 함수는 detection task에 특별하게 엔지니어링 될 필요 없이 일반적이고 상대적으로 간단하다. 따라서 이 프레임워크는 다양한 도메인이나 응용으로 손쉽게 확장할 수 있으며, 광범위한 vision task을 지지하는 general intelligence의 인지 시스템으로 통합될 수 있다. 이것을 위해 우리는 vision task에 대한 언어 인터페이스를 제공한다.
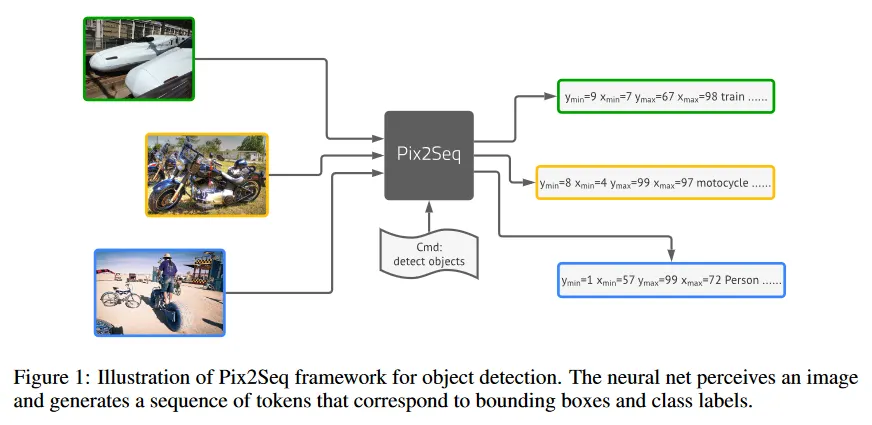
Pix2Seq를 사용하여 detection task를 다루기 위해 우리는 우선 bounding box와 class label을 이산 토큰의 시퀀스로 변환하는 quantization(양자화)와 serialization(직렬화)하는 scheme를 제안한다. 그 다음 픽셀 입력을 인식하고 타겟 시퀀스를 생성하는 encoder-decoder 아키텍쳐를 활용한다. object function은 간단히 픽셀 입력과 선행 토큰을 조건으로 하는 maximum likelihood이다. 아키텍쳐와 loss 함수 모두 task-agnostic(bounding box와 같은 object detection에 관한 prior 지식을 가정하는 것 없이)인 반면, 우리는 학습하는 동안 입력과 타겟 시퀀스를 변경하는 sequence augmentation 기법을 통해 task 특화된 prior 지식을 여전히 통합할 수 있다. 광범위한 실험을 통해 이 간단한 Pix2Seq 프레임워크가 Faster R-CNN과 DETR을 포함하여 고도로 커스터마이즈되고 잘 확립된 접근에 대해 COCO 데이터셋에서 경쟁력 있는 결과를 제시함을 시연한다. 더 큰 object detection 데이터셋으로 우리 모델을 pre-training하면 성능은 더 개선될 수 있다.
2 THE PIX2SEQ FRAMEWORK
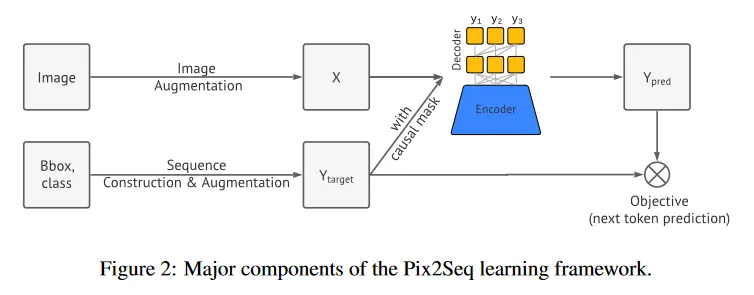
제안 된 Pix2Seq 프레임워크에서 우리는 object detection을 픽셀 입력을 조건화 된 언어 모델링 작업으로 변환한다(그림 1). 시스템은 4가지 주요 컴포넌트로 구성된다(그림 2).
•
Image Augmentation: computer vision 모델을 학습하는 일반적은 관례로써 우리는 고정된 학습 예제 집합을 풍부하게 하기 위해 image augmentation을 사용한다. (예: 무작위 스케일링과 crop)
•
Sequence construction & augmentation: 이미지에 대한 object 주석은 일반적으로 bounding box와 class 라벨의 집합으로 표현된다. 우리는 이것을 이산 토큰의 시퀀스로 변환한다.
•
Architecture: 우리는 encoder-decoder 모델을 사용한다. 여기서 인코더는 픽셀 입력을 인식하고, 디코더는 타겟 시퀀스를 생성한다(한 번에 하나의 토큰)
•
Objective/loss function: 모델은 이미지와 이전 토큰에 조건화된 토큰의 log likelihood를 최대화하도록 학습되고 토큰을 생성한다(softmax cross-entropy loss를 사용하여)
2.1 SEQUENCE CONSTRUCTION FROM OBJECT DESCRIPTIONS
Pascal VOC, COCO, OpenImages와 같은 일반적인 object detection 데이터셋에서 이미지는 bounding box와 class 라벨로써 표현되는 object의 다양한 수를 갖는다. Pix2Seq에서는 그것들을 이산 토큰의 시퀀스로 표현한다.
클래스 라벨은 자연스럽게 이산 토큰으로 표현되는 반면, bounding box는 그렇지 않다. bounding box는 두 corner point(즉, top-left와 bottom-right) 또는 center point와 height, width에 의해 결정된다. 우리는 corner point의 좌표(다른 format에서는 height, width)로 사용되는 연속적인 수를 이산화하는 방법을 제안한다. 구체적으로 object는 5개 이산 토큰의 시퀀스로 나타난다. 즉 , 여기서 각 연속 코너 좌표는 사이의 정수로 균등하게 이산화되고 는 클래스 index이다. 우리는 모든 토큰에 대해 공유된 vocabulary를 사용하고 따라서 vocabulary 크기는 ‘bins 수 + class 수’와 같다. 이 bounding box 양자화 방식은 작은 vocabulary로도 높은 정밀도를 달성할 수 있도록 한다. 예컨대 600x600 이미지는 단지 600 bins만으로 zero 양자화 에러를 달성한다. 이것은 32K 또는 그 이상의 vocabulary 크기를 갖는 현대의 언어 모델링 보다 훨씬 작다. bonding box의 위치에 대한 다양한 양자화 레벨의 효과는 그림 3에 설명된다.

각 object description은 짧은 이산 시퀀스로 표현되면, 그 다음으로 여러 object description을 serialize하여 주어진 이미지에 대한 단일 시퀀스를 형성 해야 한다. detection 작업에서 object의 순서가 중요하지 않기 때문에, 우리는 매번 이미지가 표시될 때마다 객체의 순서를 무작위로 변경하는 무작위 ordering 전략을 사용한다. 우리는 또한 다른 결정론적 ordering 전략을 탐험하지만 유능한 신경망과 auto-regressive 모델링(관찰된 객체를 기반으로 나머지 객체의 분포를 학습할 수 있는 경우)을 사용하면 무작위 ordering이 결정론적 ordering 만큼 잘 작동할 것이라고 가설한다.
마지막으로 다양한 이미지에 있는 object의 수가 다르기 때문에, 생성된 시퀀스도 다른 길이를 갖는다. 시퀀스의 끝을 가리키기 위해 우리는 EOS 토큰을 통합한다. 다양한 ordering 전략을 사용하는 시퀀스 생성 절차는 그림 4에 나타난다.

2.2 ARCHITECTURE, OBJECTIVE AND INFERENCE
object description에서 구성한 시퀀스를 일종의 ‘dialect(방언)’으로 간주하여, 우리는 언어 모델링에서 효율적이었던 generic 아키텍쳐와 objective function을 전환한다.
Architecture
우리는 encoder-decoder 아키텍쳐를 사용한다. encoder는 픽셀을 인식하고 이를 hidden representation으로 인코딩하는 일반적인 이미지 인코더일 수 있다. 예컨대 ConvNet, Transformer 또는 그들의 결합일 수 있다. 생성의 경우 우리는 현대 언어 모델링에서 널리 사용되는 Transformer decoder를 사용한다. 이것은 이전 토큰과 인코딩된 이미지 representation을 조건으로 한 번에 하나의 토큰을 생성한다. 이것은 현대 object detector의 아키텍쳐에서 복잡성과 customization을 제거한다. 예컨대 bounding box proposal과 regression을 제거하고, 토큰은 softmax를 사용하여 단일 vocabulary에서 생성된다.
Objective
언어 모델링과 유사하게 Pix2Seq는 주어진 이미지와 이전 토큰으로 maximum likelihood loss를 사용하여 토큰을 예측하도록 학습된다. 즉
여기서 는 주어진 입력이고 와 는 와 연관된 입력과 타겟 시퀀스이고, 은 타겟 시퀀스 길이이다. 와 는 표준 언어 모델링 설정에서 동일하지만 시퀀스 구성을 augmented 할 경우 다를 수 있다. 또한 는 시퀀스에서 -번째 토큰에 대해 pre-assigned 가중치이다. 우리는 를 설정하지만 토큰 유형(예: 좌표 vs 클래스 토큰)이나 해당 객체의 크기에 따라 토큰에 가중치를 부여할 수도 있다.
Inference
추론 시간에 model likelihood에서 토큰을 샘플링한다. 즉 이다. 이것은 가장 큰 likelihood( 샘플링)의 토큰을 취하거나 다른 stochastic 샘플링 기법을 사용하여 수행할 수 있다. 우리는 nucleus sampling(Holtzman et al, 2019)를 사용하는 것이 샘플링 보다 더 높은 recall을 이끈다는 것을 발견했다(부록 C). 시퀀스는 EOS 토큰이 생성될 때 끝난다. 시퀀스가 한 번 생성되면, object description(예: 예측된 bounding box와 클래스 라벨)을 추출하고 de-quantize 하는 것은 매우 간단하다.
2.3 SEQUENCE AUGMENTATION TO INTEGRATE TASK PRIORS
EOS 토큰은 모델이 언제 생성을 종료할지를 결정하도록 하지만, 실제로 모델이 모든 object를 예측하지 않고 종료하는 경향이 있다는 것을 발견했다. 이것은 1) annotation noise(예: annotator는 모든 object를 식별하지 않은 경우) 2) 일부 object를 인식하거나 localizing 하는데 발생하는 불확실성 때문일 가능성이 크다. 이로 인해 전체 성능에 작은 영향(평균 정밀도에서 1-2%)을 미치지만, recall에는 더 큰 영향을 준다. 더 높은 recall rate를 장려하기 위한 한 가지 트릭은 EOS 토큰의 likelihood를 인공적으로 감소시켜서 샘플링을 지연하는 것이다. 그러나 이것은 종종 noisy와 중복 예측을 이끈다. 이러한 precision과 recall 사이의 어려운 trade-off는 우리의 모델의 detection task에 특화되지 않았기 때문에 발생하는 문제이다.
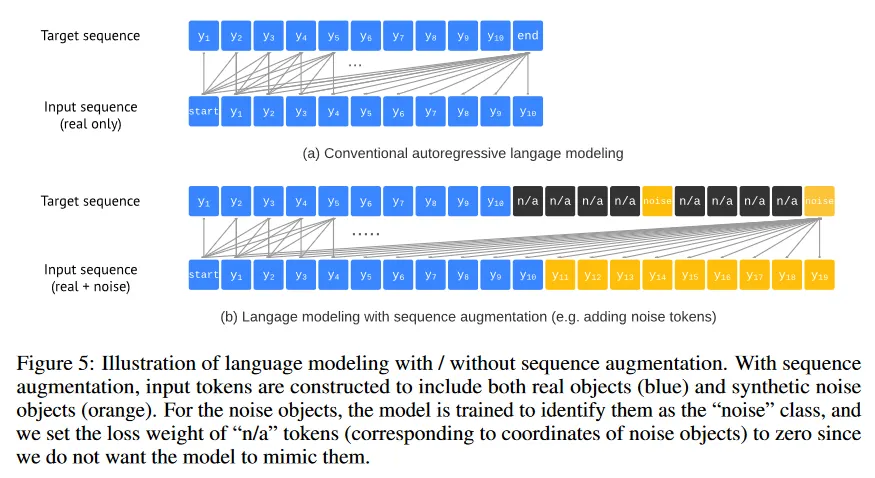
이 문제를 완화하기 위해 우리는 간단히 시퀀스 augmentation 기법을 도입하여 task에 관한 prior 지식을 통합한다. 관례적인 auto-regressive 언어 모델링에서 타겟 시퀀스 는 입력 시퀀스 와 동일하다. 그리고 시퀀스에서 모든 토큰은 real(예: 인간 주석자에 의해 변환된 것)이다, 시퀀스 증강을 사용하여 학습하는 동안 입력 시퀀스 증강하여 real과 synthetic 노이즈 토큰을 모두 포함한다. 또한 모델이 노이즈 토큰을 모방하는 대신 이를 식별하도록 타겟 시퀀스를 수정 한다. 이를 통해 노이즈와 중복된 예측에 대한 모델의 견고성이 개선된다(특히 recall을 높이기 위해 EOS 토큰이 지연시킬 때). 시퀀스 증강으로 인한 수정은 그림 5 참조. 상세 설명은 아래 참조.
Altered sequence construction
우리는 다음 두 가지 방법으로 입력 시퀀스를 증강하여 synthetic noise object를 생성한다. 1) 기존 ground-truth object에 노이즈를 추가(예: bounding box를 random scaling 하거나 shifting) 2) 무작위로 연관된 클래스 라벨로 완전히 무작위 박스를 생성. noise object의 일부는 어떤 ground-truth object의 동일하거나 겹쳐질 수 있으며 이는 노이즈와 중복된 예측을 시뮬레이션한다. 그림 6 참조. noise object가 합성되고 이산화된 후에 이를 원래의 입력 시퀀스의 끝에 추가한다. 타겟 시퀀스의 경우 noise object의 타겟 토큰을 ‘noise’ 클래스로 설정하고(어떤 ground-truth class label의 임의의 것에 속하지 않는), 좌표 토큰을 “n/a”로 설정하여 loss 가중치를 0으로 만든다. 즉 방정식 1에서 로 설정한다.

Altered inference
시퀀스 증강을 통해 우리는 EOS 토큰을 상당히 지연시킬 수 있어, recall을 개선하면서도 노이즈와 중복된 예측의 빈도를 증가시키지 않는다. 따라서 우리는 모델이 최대 길이까지 예측 하도록 하여, 고정된 크기의 object 리스트를 산출한다. 생성된 시퀀스에서 bounding box의 클래스 라벨 list를 추출할 때, ‘noise’ 클래스 라벨을 모든 real 클래스 라벨 중 가장 높은 likelihood를 갖는 real class 라벨로 대체한다. 우리는 선택된 클래스 토큰의 likelihood를 object의 (ranking) score로 사용한다.
3 EXPERIMENTS
3.1 EXPERIMENTAL SETUP
우리는 제안된 방법을 118k 학습 이미지와 5k 평가 이미지를 포함하는 MS-COCO 2017 detection 데이터셋에서 평가한다. DETR과 Faster R-CNN과 비교하기 위해, 마지막 학습 epoch에서 validation set에 대해 multiple threshold에 대한 통합 메트릭인 average precision(AP)를 리포트한다.
우리는 2가지 학습 전략을 활용한다. 1) baseline과 공정하게 비교하는 측면에서 COCO에서 시작부터 학습 2) pre-training+fine-tuning 즉, Pix2Seq 모델을 더 큰 object detection 데이터셋인 Objects365에서 pre-train한 다음 COCO 에서 모델을 fine-tune 하는 방식. 우리의 접근이 object detection task에 대한 inductive bias이나 prior 지식이 zero이므로, 우리는 두 번째 학습 전략이 우수할 것으로 기대한다.
처음부터 학습하는 경우 우리는 (Carion et al., 2020)을 따라 ResNet backbone과 6개 레이어의 transformer encoder와 6개 레이어의 (causal) transformer decoder를 사용한다. 이미지를 고정된 종횡비로 resize 하여 더 긴 쪽이 1333 픽셀이 되게 한다. 시퀀스 생성시 2000개 quantization bins를 사용하고 매번 이미지가 보이는대로 object의 순서를 무작위로 변경한다. 또한 real object에 noise object를 추가하여 각 이미지가 총 100개의 object를 갖도록 한다. 따라서 시퀀스 길이는 500이 된다. 모델은 배치 크기 128로 300 epoch 동안 학습된다.
Objects365 데이터셋에서 pre-training 하는 경우 위와 유사하지만 약간 차이가 있는 설정을 사용한다. 특히, 1333x1333의 대형 이미지 크기를 사용하는 대신, 640x640의 더 작은 이미지 크기를 사용하고 256 배치 크기로 400k 단계 동안 모델을 pre-train한다. 더 작은 이미지 크기의 사용하므로 이 pre-training 절차가 시작부터 학습하는 것보다 빠르다. COCO 데이터셋에서 fine-tuning 하는 동안 적은 수의 epoch(예: 20에서 60 epoch)만으로도 좋은 성능을 달성할 수 있으며, fine-tuning 하는 동안에는 더 큰 이미지 크기를 사용할 수도 있다. 더 큰 pre-training 데이터셋을 사용하기 때문에 Vision Transformer를 사용하는 더 큰 모델을 사용하는 실험도 진행한다.
두 학습 전략에 대한 더 많은 상세는 부록 B에서 볼 수 있다. ablastion 실험을 위해 우리는 ResNet-101 backbone과 더 작은 이미지 크기(긴 쪽이 640)를 사용하여 모델을 처음부터 200 epoch 동안 학습한다.
3.2 MAIN COMPARISONS
Training from scratch on COCO
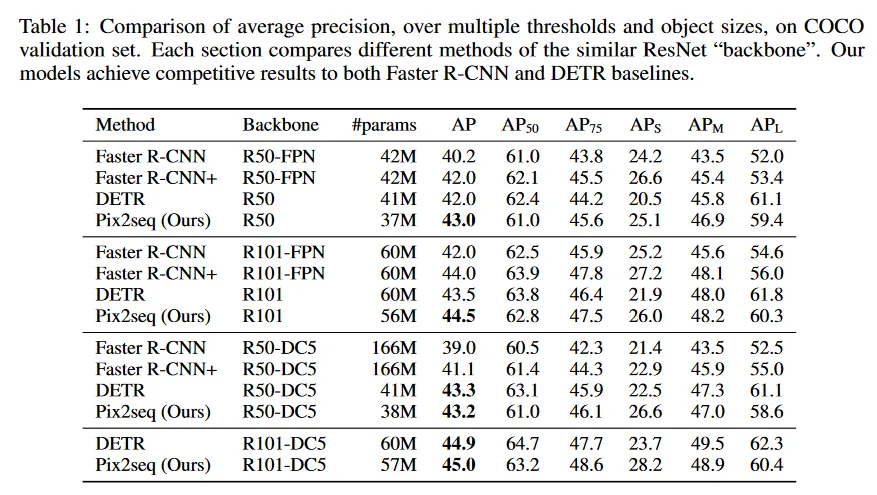
우리는 주로 두 가지 널리 인정받는 baseline인 DETR과 Faster R-CNN과 비교한다. DETR은 우리의 모델은 비교 가능한 아키텍쳐를 갖지만, 우리의 Transformer decoder는 ‘object query’나 box regression과 classification에 대한 분리된 head가 필요하지 않다. 이는 우리 모델이 single softmax를 사용하여 다양한 토큰 유형(예: 좌표와 클래스 토큰)을 생성하기 때문이다. Faster R-CNN은 feature-pyramid network(FPN)과 같이 최적화된 아키텍쳐를 사용하여 잘 정립된 방법이다. Faster R-CNN은 일반적으로 DETR 이나 우리 모델 보다 더 적은 epoch으로 학습되는데, 이는 아키텍쳐 자체에서 task에 대한 prior 지식을 명시적으로 통합하기 때문이다. 따라서 우리는 개선된 Faster R-CNN baseline을 포함하고 Faster R-CNN+라 표기한다. 이 모델은 GIoU loss, 학습 시간 중 random crop augmentation과 긴 9x 학습 스케쥴을 사용하여 학습된다.
결과는 Table 1 참조. 여기서 각 섹션은 동일한 ResNet ‘backbone’을 서로 다른 방법과 비교한다. 전체적으로 Pix2Seq는 두 baseline과 경쟁력 있는 결과를 달성한다. 우리의 모델은 small과 medium object에서 Faster R-CNN과 비교할 만하고 더 large object에서는 더 잘 수행한다. DETR과 비교하여 우리의 모델은 large와 medium object에서 약간 나쁘지만 small object에서는 더 뛰어나다(4-5 AP 향상)
Pretrain on Objects365 and finetune on COCO
Table 2에서 보이는대로 Object365 pre-trained Pix2Seq 모델은 댜앙한 모델 크기와 이미지 크기에 걸쳐 강력하다. 최고 성능(1333 이미지 크기)는 50 AP이고, 이것은 처음부터 학습된 모델보다 5% 더 좋고, 640 이미지 크기에서도 성능은 매우 잘 유지된다. 주목할만한 것은 pre-training에 더 작은 이미지 크기를 사용할 때, pre-train+fine-tuning 절차가 처음부터 학습한 것보다 더 빠르고 일반화도 더 낫다는 것이다. 이 두 factor는 더 크고 더 뛰어난 모델을 학습하는데 핵심이다.
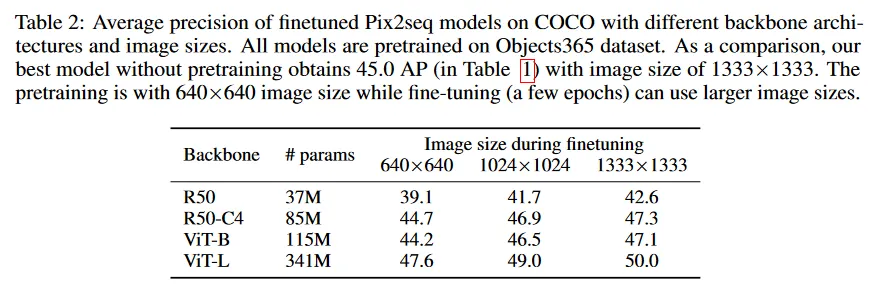
3.3 ABLATION ON SEQUENCE CONSTRUCTION
그림 7a는 좌표 양자화의 성능에 대한 효과를 탐구한다. 이 ablation의 경우 우리는 가장 긴 변의 길이가 640 픽셀인 이미지를 고려한다. plot은 500 bin 이상의 양자화가 충분함을 나타낸다. 500 bin에서는 bin 당 약 1.3 픽셀로 이것은 큰 approximation error를 발생시키지 않는다. 실제로 이미지의 가장 긴 변을 기준으로 픽셀 수만큼 많은 bin을 가지면, bounding box 좌표의 양자화로 인한 유의미한 에러는 발생하지 않아야 한다.
우리는 또한 학습하는 동안 시퀀스 구축에서 다양한 object ordering 전략도 고려한다. 이것에는 1) random 2) area(즉, descending object size), 3) dist2ori(즉, bounding box의 top-left 코너에서 origin까지 거리), 4) class(name), 5) class + area (즉, 객체가 클래스에 의해 우선 정렬된 다음 동일 클래스내에 multiple object가 존재하면 area로 정렬), 6) class+dis2ori를 포함한다. 그림 7b는 average precision(AP)를, 그림 7c는 average recall(AR)을 top-100 prediction에서 보인다. precision과 recall 모두에서 무작위 ordering이 최고의 성능을 산출한다. 우리는 결정론적 ordering을 사용하는 것이 모델이 초기 단계에서 missing object의 실수를 복구하는데 어려울 수 있지만, 무작위 ordering은 나중에라도 이를 검색할 가능성이 있다고 어림짐작한다.
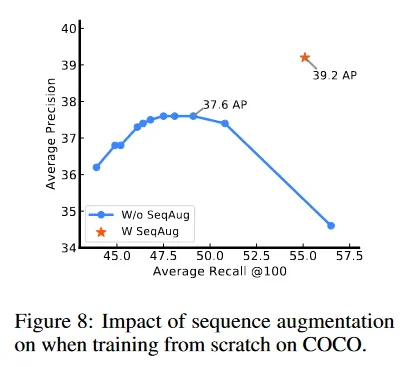
3.4 ABLATION ON SEQUENCE AUGMENTATION
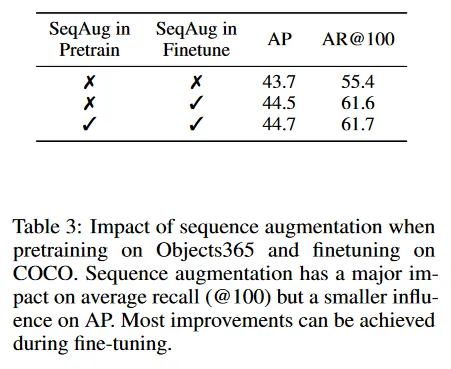
여기서 우리는 시퀀스 증강(즉, noise object 추가)이 두 가지 모델 학습 전략에 미치는 영향을 연구한다. 1) COCO에서 시작부터 학습 2) Object 365에서 pre-training 후에 COCO에서 fine-tuning. 시퀀스 증강을 사용한 경우와 사용하지 않은 경우의 처음부터 학습하는 결과는 그림 8에 보여진다. 시퀀스 증강 없이 추론 하는 동안 EOS 토큰의 샘플링을 지연시키면(likelihood offsetting을 통해) AP가 약간 나빠지지만, 최적의 AP에서 recall이 매우 나빠지는 것을 발견했다. Table 3은 pre-training + fine-tuning 설정에 대한 유사한 결과를 보인다(여기서는 ending token에 대해 likelihood offset을 조정하는 대신 loss 가중치를 0.1로 설정한다). AP에는 큰 영향이 없지만 시퀀스 증강이 없으면 recall이 매우 나쁘다는 것을 발견했다. 또한 시퀀스 증강이 주로 fine-tuning 하는 동안 효과를 갖는다는 점도 주목할만 하다.
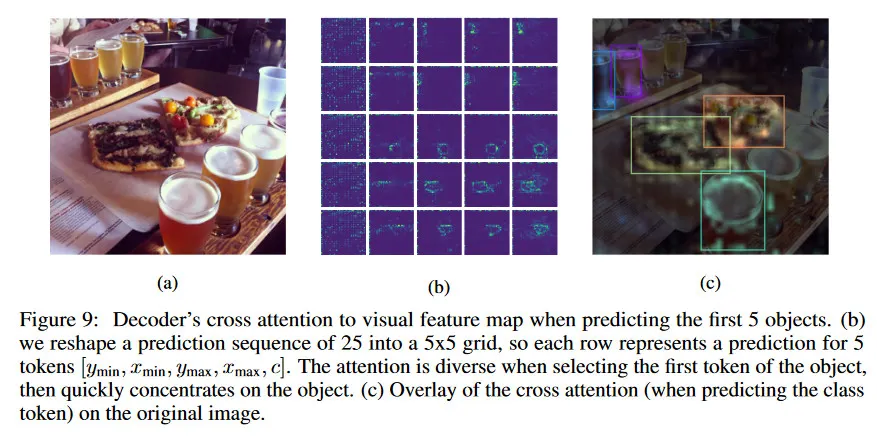
3.5 VISUALIZATION OF DECODER’S CROSS ATTENTION MAP
새로운 토큰을 생성할 때, transformer decoder는 이전 토큰에 대해 self attention을 사용하고 인코딩된 visual feature map에 대해 cross attention을 수행한다. 여기서 우리는 모델이 새로운 토큰을 예측할 때, cross attention을 시각화한다(레이어와 head에 걸쳐 평균화 됨). 그림 9는 처음 몇 개의 토큰이 생성될 때의 cross attention map을 보인다. 첫 번째 좌표 토큰(즉 )을 예측할 때 attention이 매우 발산하는 것을 볼 수 있지만, 이후에 빠르게 집중되어 object에 고정되는 것을 볼 수 있다.
4 RELATED WORK
Object detection
기존 object detection 알고리즘은 아키텍쳐와 loss 함수의 선택에서 작업에 관한 prior 지식을 명시적으로 통합한다. bounding box의 집합을 예측하도록 현대의 detector의 아키텍쳐는 대규모 proposal, anchor, window center을 생성하기 위해 특별하게 설계된다. 종종 중복 예측을 방지하는데 Non-maximum suppression가 필요하다. DETR이 복잡한 bounding box proposal과 non-maximum suppression을 피하지만, 여전히 object binding을 위해 학습된 ‘object query’의 집합이 필요하다. 이러한 detector는 모두 bounding box와 class label을 regressing하기 위해 별도의 sub-network(또는 추가 layer)가 필요 하다. Pix2Seq는 generic image encoder와 sequence decoder를 가져서 이런 복잡성을 피하고, 단일 softmax를 사용하여 좌표 토큰과 클래스 라벨을 생성한다.
아키텍쳐 외에도 기존 detector의 loss 함수는 또한 bounding box를 매칭하기 위해 고도로 맞춤화 된다. 예컨대 loss 함수는 종종 bounding box regression, intersection over union과 set-based matching에 기반한다. Pix2Seq는 이러한 특화된 loss를 피하며, softmax cross entropy를 사용하는 간단한 maximum likelihood object도 잘 동작한다는 것을 보인다.
우리의 작업은 또한 object detection에서 recurrent 모델과 연관되어 있다. 이러한 시스템은 한 번에 하나의 object를 예측하도록 학습 된다. 위에서 언급한 것처럼, 이러한 접근에서 아키텍쳐와 loss 함수 모두 종종 detection task에 맞춰져 있으며, 이러한 접근은 Transformer에 기반하지 않고, 더 큰 데이터셋에서 현대적인 baseline에 비교 평가되지 않는다.
Language modeling
우리의 작업은 현대 언어 모델링의 최근 성공에 영감 받았다. 원래는 자연어를 위한 것이었지만, 이 방법은 기계 번역, 이미지 캡셔닝 등 다양한 시퀀셜 데이터를 모델링하는 능력을 보였다. 우리의 작업은 이러한 포트폴리오를 풍부하게 하고, object의 집합을 토큰의 시퀀스로 전환하여 시퀀셜이 아닌 데이터에 대해서도 잘 작동함을 보인다. 우리는 task-specific prior 지식을 통합하기 위해 모델의 입력과 타겟 시퀀스를 모두 증강한다. 유사한 시퀀스 오염 방식은 언어 모델에서 사용되었고 noise-contrastive learning과 유사하고 GAN의 discriminator와도 일부 유사점을 갖는다.
5 CONCLUSION AND FUTURE WORK
이 논문은 object detection을 위한 간단하고 일반화된 프레임워크인 Pix2Seq를 소개한다. object detection을 언어 모델링 작업으로 변환하여, 우리의 접근은 detection 파이프라인을 매우 단순하게 하고 현대 detection 알고리즘에서 대부분의 특수화를 제거한다. 우리는 이 프레임워크가 object detection 뿐만 아니라 출력이 상대적으로 간결한 이산 토큰 시퀀스로 표현될 수 다른 vision 작업(예: keypoint detection, image captioning, visual question answering)에도 적용될 수 있으리라 믿는다. 이를 위해 Pix2Seq를 다양한 vision task를 해결할 수 있는 generic이고 통합된 인터페이스로 확장하는 것을 목표로 한다.
우리 접근의 주요 한계는 auto-regressive 모델링이 긴 시퀀스에 대해 비싸다는 것이다(특히 모델 추론시에). 이 이슈를 완화하기 위한 실용적인 방법으로는 1) ending token이 생성되면 추론을 중지(예: COCO 데이터셋에서 이미지당 평균적으로 7개 object가 존재하며, 약 35개의 토큰만 필요함) 2) offline 추론 또는 관심 있는 object는 상대적으로 희소한 온라인 시나리오(예: 언어 description을 사용하여 특정한 object 위치 찾기)에 적용하는 것이 있다. 그러나 object detection 응용을 위해서는 더 빠르게 만드는 추가 연구가 필요하다. 또 다른 한계는 Pix2Seq의 현재 학습 방법이 인간 주석자에 기반한다는 것이다. 이런 의존성을 줄이면 모델이 더 많은 라벨링 되지 않은 데이터에서 이점을 얻을 수 있을 것이다.
