

1 Introduction
Segment Anything (SA)는 이미지에서 promptable segmentation에 대한 foundation 모델을 도입했다. 그러나 이미지는 시각 segmentation가 복잡한 행동을 나타낼 수 있는 현실 세계의 정적 snapshot에 불과하며 멀티미디어 컨텐츠의 빠른 성장과 함께 매우 큰 포션이 시간적 차원을 가지고 기록된다. 특히 비디오 데이터가 그렇다. AR/VR, 로보틱스, 자율주행와 비디오 편집과 같은 많은 중요한 응용에서 이미지 레벨 segmentation을 너머 시간적 localization이 요구된다. 우리는 universal 시각 segmentation 시스템이 이미지와 비디오 모두에 적용가능해야 한다고 믿는다.
비디오에서 segmentation은 개체의 spatio-temporal 범위을 결정하는 것을 목표하며 이것은 이미지를 너머 고유한 도전을 제시한다. 개체는 움직임, deformation(변형), occlusion(차폐), 조명 변화와 기타 다른 요인 때문에 큰 도전을 받을 수 있다. 게다가 많은 수의 프레임을 효율적으로 처리하는 것이 핵심 도전이다. SA이 이미지에서 segmentation을 성공적으로 다루었지만, 기존의 video segmentation model과 데이터셋은 ‘video에서 segment anything’ 능력을 제공하는데 미흡하다.
우리는 Segment Anything Model 2(SAM 2)을 소개한다. 이것은 비디오와 이미지 segmentation에 대해 통합된 모델이다(우리는 이미지를 단일 프레임 비디오로 고려한다). 우리의 작업은 task, model, dataset을 포함한다(그림 1)
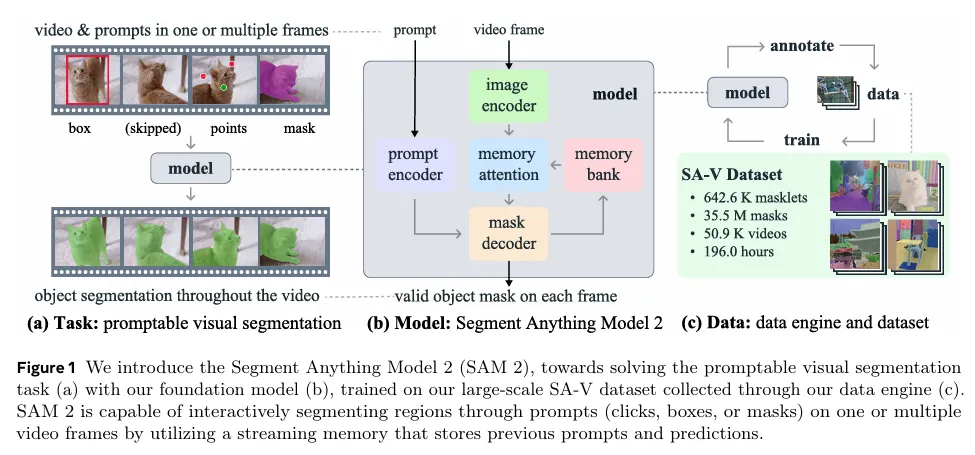
우리는 이미지 segmentation을 video 도메인으로 일반화한 Promptable Visual Segmentation(PVS) 작업에 초점을 맞춘다. 이 작업은 비디오의 임의의 프레임에서든 point, box 또는 mask를 입력으로 취하고 spatio-temporal mask(즉 masklet)를 예측해야 하는 관심있는 segment를 결정한다. masklet이 예측되면, 추가 프레임에서 prompt를 제공하여 반복적으로 개선할 수 있다.
우리 모델은 단일 이미지와 비디오 프레임 전체에 걸쳐 관심있는 객체의 segmentation mask를 생성한다. SAM 2는 객체와 이전 상호작용에 관한 정보를 저장하는 메모리를 갖추고 있어서 비디오 전체에 걸쳐 masklet 예측을 생성할 수 있으며, 이전에 관찰된 프레임에서 객체의 저장된 메모리 context에 기반하여 이것을 효과적으로 수정할 수 있다. 우리의 streaming 아키텍쳐는 비디오 도메인에 대한 SAM의 자연스러운 일반화이다. 한 번에 하나의 비디오 프레임을 처리하여, 대상 객체의 이전 memory에 attend 할 수 있는 memory attention 모듈을 갖추고 있다. 이미지에 대해 적용될 때 메모리는 empty이고 모델은 SAM처럼 동작한다.
우리는 모델을 주석 작업자와 함께 loop에 넣어 새롭고 도전적인 데이터를 interactively 주석처리하는 data engine을 사용한다. 대부분의 기존 비디오 segmentation 데이터셋과 달리, 우리의 data engine은 특정 카테고리의 객체에 제한되지 않고, part와 subpart를 포함하여 유효한 경계를 가진 임의의 객체를 segmenting 하기 위한 학습 데이터를 제공하는데 목표를 둔다. 기존의 model-assisted 접근과 비교하여 SAM 2를 loop에 넣은 우리의 data engine은 유사한 품질에서 8.4배 더 빠르다. 우리의 최종 Segment Anything Video(SA-V) 데이터셋은 50.9K 비디오에 걸쳐 35.5M 마스크로 구성되며, 이는 기존의 어떤 비디오 segmentation 데이터셋 보다 53배 더 많은 마스크를 갖는다. SA-V는 video 전체에 걸쳐 occluded 됐다가 다시 등장하는 작은 객체와 part로 인해 도전적이다. 우리의 SA-V 데이터셋은 지리적으로 다양하고 SAM 2의 공정성 평가는 인지된 성별에 기반한 비디오 segmentation에서 성능 차이가 최소화되었고 우리가 평가한 3가지 인지된 연령 그룹에 사이에 적은 분산을 나타낸다.
우리의 실험은 SAM 2가 video segmentation 실험에서 획기적 변화를 가져오는 것을 보인다. SAM 2는 이전 접근보다 3배 더 적은 상호작용으로 더 나은 segmentation 정확도를 생성할 수 있다. 게다가 SAM 2는 여러 평가 설정 하에 기존의 video 객체 segmentation 벤치마크에서 이전 작업들을 능가하며 이미지 segmentation benchmark에서 SAM 보다 더 나은 성능을 보이면서 6배 더 빠르다. SAM 2는 17개의 비디오 segmentation와 37개의 단일 이미지 segmentation를 포함한 수많은 zero-shot 벤치마크를 통해 관찰된 다양한 비디오 및 이미지 분포에 걸쳐 효과적임이 입증되었다.
2 Related work
Image segmentation.
Segment Anything은 promptable image segmentation 작업을 소개했다. 여기서 목표는 bounding box나 관심 있는 객체를 가리키는 점과 같은 입력 prompt가 주어지면 유효한 segmentation mask를 출력하는 것이다. SA-1B 데이터셋으로 학습된 SAM은 유연한 prompting을 통한 zero-shot segmentation을 가능하게 하여 광범위한 downstream 응용에 채택될 수 있었다. 최근의 작업들은 SAM의 품질을 개선하여 확장했다. 예컨대 HQ-SAM은 고품질 출력 토큰을 도입하고 모델을 세밀한 마스크로 학습하여 SAM을 향상시켰다. 또 다른 작업 방향은 EfficientSAM, MobileSAM, FastSAM과 같이 현실 세계와 mobile 응용에서의 더 넓은 사용을 가능하게 하기 위해 SAM의 효율성에 초점을 맞춘다. SAM의 성공은 의학 이미지, remote sensing, motion segmentation, camouflaged object detection 등 광범위한 응용 분야에서의 채택으로 이어졌다.
Interactive Video Object Segmentation (iVOS).
Interactive video object segmentation은 종종 scribbles, clicks, bounding box의 형식의 사용자 가이드를 사용하여 video에서 객체 segmentation(masklet)을 효율적으로 얻는 작업에 핵심으로 부상했다. 몇몇 초기 접근은 graph 기반 최적화를 배치하여 segmentation annotation process를 가이드한다. 더 최근 접근은 주로 modular design을 채택하여 사용자 입력을 단일 프레임의 mask representation으로 변환한 다음 이를 다른 프레임으로 전파한다. 우리의 작업은 좋은 interactive 경험으로 video 전체에 걸쳐 객체를 segment 하는 이러한 작업과 유사한 목표를 공유하며, 이 목표를 추구하기 위해 크고 다양한 데이터셋과 함께 강력한 모델을 구축한다.
특히 DAVIS interactive benchmark는 여러 프레임에 대한 scribble 입력을 통해 객체를 interactively segmenting 할 수 있게 한다. DAVIS interactive benchmark에 의해 영감을 받아, 우리도 promptable video segmentation 작업에 대한 interactive 평가를 채택했다.
Click 기반 입력은 interactive video segmentation을 위해 수집하기 쉽다. 최근 작업은 mask 또는 points을 기반으로 한 video tracker와 함께 이미지에 SAM을 사용하는 조합을 사용했다. 그러나 이런 접근은 한계를 갖는다. tracker가 모든 객체 대해 작동하지 않을 수 있고 SAM이 video의 이미지 프레임에 대해 잘 수행하지 않을 수 있으며, 오류가 있는 프레임에서 SAM을 처음부터 다시 주석을 달고 거기서부터 추적을 재시작하는 것 외에 모델의 실수를 interactively 조정하는 메커니즘이 없다.
Semi-supervised Video Object Segmentation (VOS).
Semi-supervised VOS는 대개 첫 프레임에 객체 mask를 입력으로 시작하며, 이것을 video 전체에 걸쳐 정확하게 추적해야 한다. 첫 번째 프레임에 대해서만 사용 가능한 객체 외형의 supervision 신호로 볼 수 있는 입력 mask가 있기 때문에 ‘semi-supervised’라 부른다. 이 작업은 video 편집, 로보틱스, 자동 배경 제거 등 다양한 응용과 관련되기 때문에 큰 주목을 받아왔다.
초기 신경망 기반 접근은 종종 첫 번째 프레임 또는 모든 프레임에 대해 online fine-tuning을 사용하여 모델을 대상 객체에 적응시켰다. offline 학습된 모델을 사용하여 더 빠른 추론이 가능해졌는데, 이는 첫 번째 프레임만 조건화 하거나, 이전 프레임도 통합하는 방식으로 이루어졌다. 이 multi-conditioning은 RNN과 cross-attention을 사용하여 모든 프레임으로 확장되었다. 최근 접근은 단일 vision transformer를 확장하여 현재 프레임과 모든 이전 프레임 및 관련 예측을 결합으로 처리하여 단순한 아키텍쳐를 만들었지만 감당하기 어려운 추론 비용을 갖는다. Semi-supervised VOS는 첫 번째 비디오 프레임에서만 mask prompt를 제공하는 것과 동등하기 때문에 우리의 Promptable Visual Segmentation(PVS) 작업의 특별한 경우로 볼 수 있다. 그럼에도 불구하고 첫번째 프레임에서 요구되는 고품질 객체 마스크를 주석처리하는 것은 실제로 도전적이고 시간이 많이 소모된다.
Video segmentation datasets.
VOS 작업을 지원하기 위해 많은 데이터셋이 제안되었다. DAVIS 같은 초기 VOS 데이터셋들은 높은 품질 주석을 포함했지만, 딥러닝 기반 접근을 학습하기에 제한된 크기였다. 4천개 비디오에 걸쳐 94개 객체 카테고리를 커버하는 YouTube-VOS는 VOS 작업을 위한 첫 대규모 데이터셋이었다. 알고리즘이 개선되고 벤치마크 성능이 포화되기 시작하면서 연구자들은 특히 occlusion, long video, 극단적 변형, 객체 다양성, 또는 장면 다양성에 초점을 맞춰서 VOS 작업의 어려움을 증가하는데 주목했다.
우리는 현재 video segmentation 데이터셋이 ‘video에서 segmenting anything’의 능력을 달성하기 위해 충분히 커버가 부족함을 발견했다. 이것들은 일반적으로 전체 객체(부분이 아닌)에 주석이 달렸고 데이터셋은 종종 사람, 차량, 동물 같은 특정 객체 클래스 중심으로 구성된다. 이러한 데이터셋과 비교하여 우리가 공개한 SA-V 데이터셋은 전체 객체에 초점을 맞출 뿐만 아니라 객체의 부분도 커버하고 더 많은 규모 측면에서 마스크를 포함한다.
3 Task: promptable visual segmentation
PVS 작업은 비디오의 어느 프레임에서든 모델에 prompt를 제공한다. 프롬프트는 segment를 위한 객체를 정의하는 것이나 model 예측을 조정하기 위해 positive/negative 클릭, bounding box 또는 mask일 수 있다. interactive 경험을 제공하기 위해, 특정 프레임에서 프롬프트를 받으면 모델은 즉각적으로 이 프레임의 객체에 대한 유효한 segmentation mask를 응답한다. 초기 (하나 또는 여럿) 프롬프트를 받은 후, 모델은 이러한 프롬프트를 전파하여 비디오 전체에 걸쳐 객체의 masklet을 얻는다. 이것은 모든 비디오 프레임에서 대상 객체의 segmentation mask를 포함한다. 비디오 전체에 걸쳐 segmentation을 조정하기 위해 임의의 프레임에서 모델에 추가 프롬프트를 제공할 수 있다(그림 2). 이것에 대한 자세한 내용은 부록 A 참조.
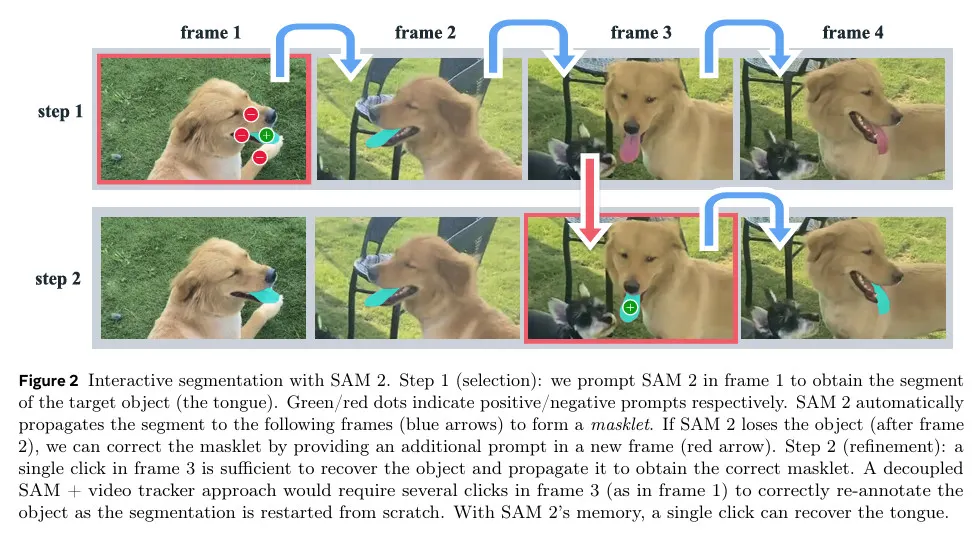
다음 섹션에서 소개하는 SAM 2는 SA-V 데이터셋을 구축하기 위한 데이터 수집 도구로 PVS 작업에 적용되었다.
모델은 여러 프레임에 걸친 주석을 포함하여 interactive 비디오 segmentation 시나리오를 시뮬레이션하여 online과 offline 설정에서 평가되며, 주석이 첫 번째 프레임으로 제한되는 기존의 semi-supervised VOS 설정에서, 그리고 SA 벤치마크에서의 이미지 segmentation에 대해 평가된다.
4 Model
우리 모델은 SAM을 video(와 이미지) 도메인으로 일반화한 것으로 볼 수 있다. SAM 2(그림 3)은 비디오에 걸쳐 segmented 될 객체의 공간적 extent(범위)를 정의하기 위해 개별 프레임에 대한 점, box와 mask prompt를 지원한다. 이미지 입력에 대해 모델은 SAM과 유사하게 동작한다. promptable과 light-weight mask decoder는 현재 프레임의 frame embedding과 프롬프트(있는 경우)를 받아 해당 프레임에 대한 segmentation mask를 출력한다. 마스크를 조정하는 측면에서 프레임에 프롬프트를 반복적으로 추가할 수 있다.
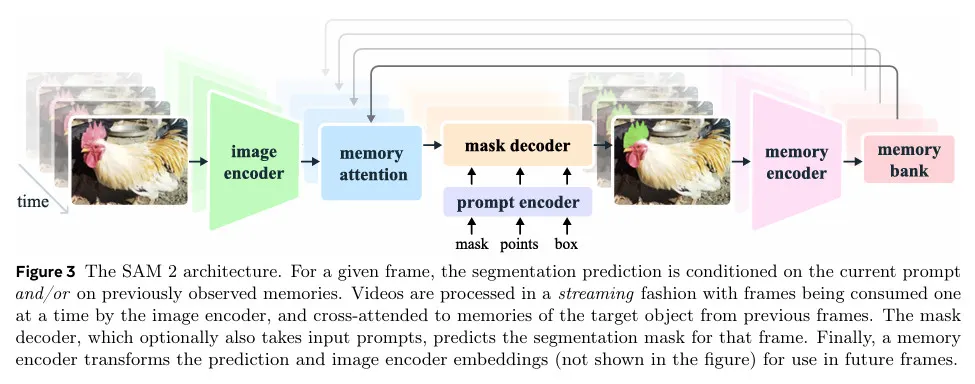
SAM과 달리 SAM 2 decoder에서 사용된 frame embedding은 이미지 encoder에서 직접 오지 않고 과거 예측과 prompted frame의 memory에 조건화된다. prompted frame이 현재 프레임에 대해 ‘미래에서’ 올 수도 있다. frame의 메모리는 memory encoder에 의해 현재 예측을 기반으로 생성되고, 후속 프레임에서 사용하기 위해 memory bank에 저장된다. memory attention 연산은 이미지 인코더에서 프레임당 임베딩을 가져와 memory bank에 조건화 하여 mask decoder로 전달되는 임베딩을 생성한다.
우리는 아래에서 개별 컴포턴트와 학습에 대해 설명하고 더 상세한 내용은 부록 C 참조.
Image encoder.
임의의 긴 비디오의 실시간 처리를 위해 우리는 비디오 프레임이 사용 가능해지는대로 소비하는 streaming 접근을 취한다. 이미지 인코더는 전체 interaction에서 오직 한 번만 실행되고, 그 역할은 각 프레임을 나타내는 조건화되지 않은 token(feature embedding)을 제공한다. 우리는 MAE로 pre-train된 Hiera image encoder를 사용한다. 이것은 계층적이어서 디코딩 하는 동안 multi-scale feature를 사용할 수 있게 한다.
Memory attention.
memory attention의 역할은 현재 프레임 feature를 과거 프레임 feature의 예측 뿐만 아니라 새로운 프롬프트에 대해 조건화하는 것이다. 우리는 개 transformer block을 쌓는데 첫 번째 블록은 현재 프레임의 이미지 인코딩을 입력으로 취한다. 각 블록은 self-attention을 수행한 다음 memory bank(아래 참조)에 저장된 (prompted/unprompted) frame들의 memory와 object pointer(아래 참조)에 대한 cross-attention을 수행한 다음 MLP를 수행한다. 우리는 self와 cross-attention을 위해 vanilla attention 연산을 사용하여 최근의 efficient attention kernel 개발의 이점을 얻는다.
Prompt encoder and mask decoder.
우리의 프롬프트 인코더는 SAM의 것과 동일하며, 주어진 프레임에서 객체의 extent를 정의하기 위해 click(positive/negative), bounding box 또는 mask 프롬프트일 수 있다. sparse 프롬프트는 각 프롬프트 유형에 대해 학습된 임베딩과 합산된 positional encoding으로 표현되며, 마스크는 convolution을 사용하여 임베딩되고, 프레임 임베딩과 합산된다.
우리의 디코더 설계는 대체로 SAM을 따른다. 우리는 프롬프트와 프레임 임베딩을 업데이트하는 ‘two-way’ transformer block을 쌓는다. SAM에서와 같이 여러 호환 가능한 대상 마스크가 있을 수 있는 모호한 프롬프트(즉, single 클릭)의 경우 여러 마스크를 예측한다. 이 설계는 모델이 유효한 마스크를 출력하도록 보장하는데 중요하다. 모호성이 비디오 프레임 전체에 걸쳐 확장될 수 있는 비디오에서는 모델이 각 프레임에 대해 여러 마스크를 예측한다. 후속 프롬프트가 모호성을 해결하지 않으면, 모델은 현재 프레임에 대해 가장 높게 예측된 IoU를 갖는 마스크만 전파한다.
positive 프롬프트가 주어질 때 항상 segment할 유효한 객체가 있는 SAM과 달리 PVS 작업에서는 일부 프레임에 유효한 객체가 존재하지 않을 가능성이 있다(occlusion 때문에). 이 새로운 출력 모드를 고려하기 위해 우리는 현재 프레임에 관심있는 객체가 존재하는지 여부를 예측하는 추가적인 head를 추가한다. SAM과 또 다른 차이는 마스크 디코딩을 위해 고해상도 정보를 통합하기 위해 계층적 이미지 인코더에서 skip connection(memory attention을 우회하는)을 사용한다는 것이다.
Memory encoder.
memory encoder는 convolutional 모듈을 사용하여 출력 마스크를 down-sampling한 다음 이를 이미지 인코더(그림 3에 보이지 않는)의 unconditioned 프레임 임베딩과 element-wise로 합산하여 메모리를 생성한 다음, light-weight convolutional layer를 사용하여 정보를 융합한다.
Memory bank.
memory bank는 최대 개의 최근 프레임의 메모리로 구성된 FIFO queue를 유지하여 비디오에서 대상 객체에 대한 과거 예측에 정보를 유지하고, 최대 개의 prompted 프레임의 FIFO queue에 프롬프트의 정보를 저장한다.
예컨대 초기 마스크가 유일한 프롬프트인 VOS 작업에서 memory bank는 첫 프레임의 memory와 함께 최대 개의 최근 (unprompted) 프레임의 메모리를 일관되게 유지한다. 두 집합의 메모리 모두 spatial feature map으로 저장된다.
spatial memory 외에도, 우리는 각 프레임의 마스크 디코더 출력 토큰에 기반하여 segment 할 객체의 high-level semantic 정보를 위한 lightweight vector로써 object pointer의 list를 저장한다. 우리의 memory attention은 이러한 spatial memory feature와 object pointer 모두에 대해 cross-attend를 수행한다.
우리는 개의 최근 프레임의 메모리에 시간적 위치 정보를 임베딩하여 모델이 short-term 객체 motion을 표현할 수 있게 하지만, prompted frame의 memory에는 이를 임베딩하지 않는다. 이는 prompted frame에서 학습 신호가 더 희소하고, prompted 프레임이 학습하는 동안 본 것과 매우 다른 시간 범위에서 올 수 있는 추론 설정으로 더 일반화하기 어렵기 때문이다.
Training.
모델은 이미지와 비디오 데이터에 대해 결합으로 학습된다. 이전 작업과 유사하게, 우리는 모델의 interactive prompting을 시뮬레이션한다. 우리는 8개 프레임의 시퀀스를 샘플하고, 최대 2개 프레임을 무작위로 선택하여 프롬프트하고, 학습하는 동안 ground-truth masklet과 모델 예측을 사용하여 샘플된 수정 click을 확률적으로 받는다.
학습 task는 순차적(그리고 ‘interactively’) ground-truth masklet을 예측한다. 모델에 대한 초기 프롬프트는 확률 0.5의 ground-truth mask, 확률 0.25의 ground-truth mask에서 샘플된 positive click 또는 확률 0.25의 bounding box 입력일 수 있다. 자세한 사항은 부록 C 참조.
5 Data
video에서 ‘segment anything’ 능력을 개발하기 위해, 우리는 대규모의 다양한 video segmentation 데이터셋을 수집하기 위한 data engine을 구축했다. 우리는 인간 주석자와 함께 interactive model을 loop에 포함하는 설정을 활용한다. Kirillove et al과 유사하게, 우리는 주석처리된 masklet에 의미론적 제약을 부과하지 않고, 전체 객체(예: 사람)와 부분(예: 사람의 모자) 모두에 초점을 맞춘다. 우리의 date engine은 주석자에게 제공된 모델의 지원 수준에 따라 분류된 3단계를 거쳤다. 다음으로 우리는 각 데이터 엔진 phase와 SA-V 데이터셋을 설명한다.
5.1 Data engine
Phase 1: SAM per frame.
initial phase는 이미지 기반 interactive SAM을 사용하여 인간 주석자를 보조한다. 주석자는 SAM을 사용하여 초당 6프레임(FPS)으로 video의 모든 프레임에서 대상 객체의 마스크를 주석처리하고 ‘brush’와 ‘eraser’ 같은 같은 픽셀-정밀 수동 편집 툴을 사용하는 작업을 맡았다. 다른 프레임으로 마스크를 시간적으로 전파를 하는 것을 돕는 추적 모델은 포함되지 않았다. 이것은 프레임별 방법이며 모든 프레임에 대해 처음부터 mask 주석이 필요하므로, 절차는 느리고, 우리의 경험에서 프레임당 평균 37.8초의 주석처리 시간이 필요하다. 그러나 이것은 프레임당 고품질 공간적 주석을 산출한다. 이 단계에서 우리는 1.4K 비디오에 걸쳐 16K masklet을 수집했다. 게다가 이 접근을 사용하여 평가하는 동안 SAM 2의 잠재적 편향을 완화시키기 위해 SA-V validation과 test 셋에 주석 처리를 했다.
Phase 2: SAM + SAM 2 Mask.
두 번째 단계에서는 loop에 SAM 2를 추가한다. 여기서 SAM 2는 마스크만 프롬프트로써 받아들인다. 우리는 이 버전을 SAM 2 Mask로 참조한다. 주석자들이 Phase 1에서와 같이 SAM과 다른 툴을 사용하여 첫 번째 프레임에서 공간적 마스크를 생성한 다음, SAM 2 Mask를 사용하여 주석처리된 마스크를 다른 프레임에 시간적으로 전파하여 전체 spatio-temporal masklet을 얻는다. 이후 어떤 비디오 프레임에서도 주석자는 SAM, ‘brush’ 또는 ‘eraser’로 처음부터 mask를 주석처리하여 SAM 2 mask가 만든 예측을 공간적으로 수정하고 SAM 2 Mask로 다시 전파할 수 있으며, masklet이 정확해질 때까지 이 과정을 반복했다. SAM 2 Mask는 처음에 phase 1 데이터와 공개적으로 사용가능한 데이터셋으로 학습되었다. phase 2에서 우리는 수집된 데이터를 사용하여 주석 loop에서 SAM 2 mask를 두 번 재학습하고 업데이트했다. Phase 2에서 우리는 63.5K masklet을 수집했다. 주석 시간은 프레임 당 7.4초가 걸렸고 Phase 1에 비해 최대 5.1배까지 빨라졌다.
주석 시간이 개선되었음에도, 이 decoupled 접근은 이전 memory 없이 중간 프레임에서 처음부터 mask를 주석처리해야 한다. 그 후 interactive 이미지 segmentation과 mask 전파를 통합 모델에서 수행할 수 있는 fully-featured SAM 2를 개발하게 되었다.
Phase 3: SAM 2.
마지막 단계에서 우리는 point와 mask를 포함한 다양한 유형의 프롬프트를 수용하는 fully-featured SAM 2를 활용한다. SAM 2는 시간적 차원에 걸친 객체의 memory를 활용하여 mask 예측을 생성한다. 이것은 주석자들이 이런 memory context가 없는 공간적 SAM을 사용하여 처음부터 주석처리를 해야 했던 것과 달리, 중간 프레임에서 예측된 masklet을 편집하기 위해 SAM 2에 가끔씩 개선 클릭만 제공하면 된다는 것을 의미한다. 3단계 동안, 수집된 주석을 사용하여 SAM 2를 5번 재학습하고 업데이트했다. SAM 2를 loop에 넣음으로써 프레임 당 주석 시간은 4.5초로 감소했고 Phase 1보다 8.4배 빨라졌다. Phase 3에서 197K masklet을 수집했다.
Quality verification.
주석에 대해 높은 수준을 유지하기 위해, 우리는 검증 단계를 도입했다. 별도의 주석자들이 각 주석처리된 masklet의 품질을 ‘satisfactory’(모든 프레임에 걸쳐 대상 객체를 올바르고 일관되게 추적) 또는 ‘unsatisfactory’ (대상 객체는 분명한 경계로 잘 정의되지만 masklet은 올바르거나 일관성 없음)으로 확인하는 작업을 맡았다. unstatisfactory masklet은 개선을 위해 주석 파이프라인으로 다시 돌아간다. 잘 정의되지 않은 객체를 추적하는 masklet 완전히 거절된다.
Auto masklet generation.
주석에서 다양성을 보장하는 것은 모델의 anything ㄴ으력을 보장하기 위해 중요하다. 인간 주석자들은 일반적으로 더 salient 객체에 초점을 맞춘다. 우리는 주석자들이 자동적으로 masklet을 생성하기 위해(이것을 ‘Auto’라고 한다) 주석을 증강했다. 이것은 주석의 범위를 증가시키고 모델 실패 경우를 식별하는데 도움이 되는 2가지 목적을 제공한다. auto masklet을 생성하기 위해 우리는 SAM 2를 첫 번째 프레임에서 점들의 regular grid를 사용하여 SAM 2를 프롬프트하고 후보 masklet을 생성한다. 그 다음 filtering을 위해 masklet 검증 단계로 보내진다. ‘staisfactory’로 태그되는 automatic masklet은 SA-V 데이터셋에 추가된다. Masklet은 ‘unsatisfactory’(즉, 모델 실패 케이스)로 식별되는 masklet은 샘플되고 loop에서 SAM 2를 갖는 재조정하기 위해 주석자들을 표현한다.(데이터 엔진의 phase 3). 이러한 automatic masklet은 대규모 salient central 객체를 커버하지만 배경에서 다다양한 크기와 위치의 객체도 커버한다.
Analysis.
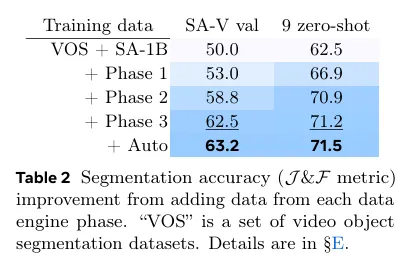
표 1은 통제된 실험을 통해 각 데이터 엔진의 주석 프로토콜 비교를 보인다(상세는 D.2.2 참조). 우리는 프레임 당 평균 주석처리 시간, masklet 당 수동 편집된 프레임의 평균 비율과 클릭된 프레임 당 평균 클릭 수를 비교한다. 품질 평가를 위해, 우리는 Phase 1 Mask Alignment Score를 1 단계의 해당 mask와 비교하여 IoU가 0.75를 초과하는 마스크의 비율로 정의한다. Phase 1 데이터는 프레임별로 고품질 수동 주석이 있어 레퍼런스로 선택된다. loop에 Sam 2를 포함한 Phase 3은 효율성 증가와 유사한 품질을 이끈다. 이것은 Phase 1에 비해 8.4배 빠르고, 편집된 프레임 비율과 프레임 당 클릭 수가 가장 낮으며, 더 나은 alignment를 갖는다.
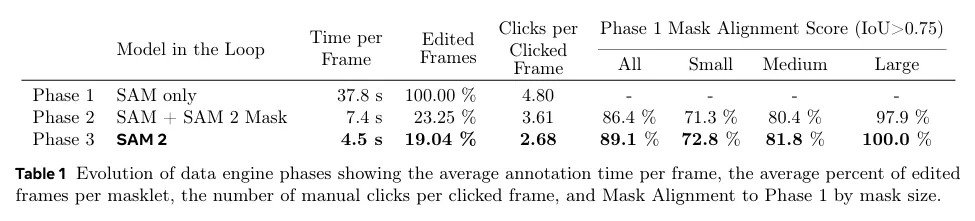
표 2는 반복수를 고정하고, 각 단계의 끝에 사용 가능한 데이터 학습된 SAM 2의 성능 비교를 보인다. 그러므로 추가 데이터의 영향만 측정한다. 우리는 자체 SA-V validation set과 9개의 zero-shot 벤치마크에서 첫 프레임에 3 클릭으로 프롬프팅할 때, 표준 J&F 정확도 메트릭(높을수록 더 좋은)를 사용하여 평가한다. 우리는 각 단계에서 데이터를 반복적으로 포함한 후에 일관된 개선을 확인했다. 이는 도메인 내 SV-V 검증 셋 뿐만 아니라 9개 zero-shot 벤치마크에서도 마찬가지이다.
5.2 SA-V dataset
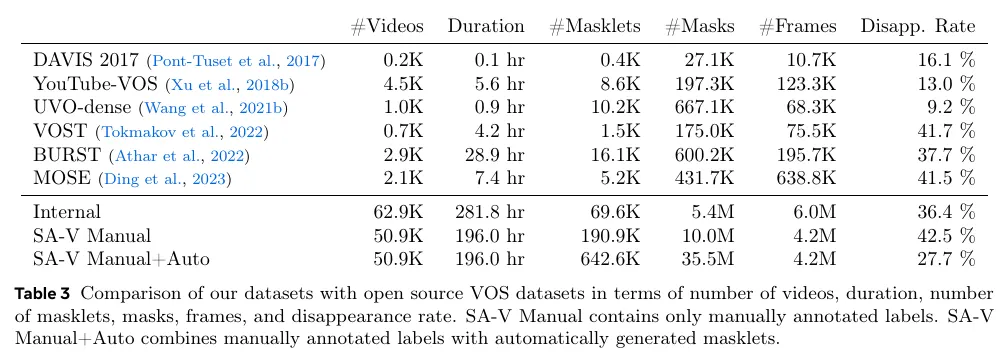
SA-V 데이터셋은 우리의 데이터 엔진을 사용하여 수집되었고 50.9K 비디오와 642.6K masklet으로 구성된다. 표 3에서 비디오, masklet, mask의 수를 기준으로 SA-V의 구성과 일반적인 VOS 데이터셋을 비교한다. 특히 주석처리된 마스크의 수는 기존의 어떤 VOS 데이터셋보다 53배(auto 없이 15배) 더 크다. 미래 작업에 대한 후속 자원을 제공하기 위해 우리는 permissive 라이센스 하에 SA-V를 배포한다.
Videos.
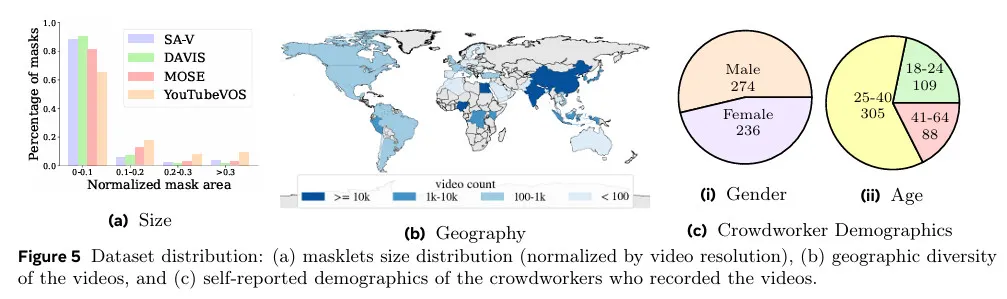
우리는 crowdworker에 의해 촬영된 50.9K 비디오의 새로운 집합을 수집했다. Video는 54%의 실내와 46%의 실외 장면으로 구성되고 평균 14초 길이이다. video feature는 ‘자연 상태’의 다양한 환경을 특징으로 하며 다양한 일상 시나리오를 커버한다. 우리의 데이터셋은 기존 VOS 데이터셋 보다 더 많은 비디오를 가지고 그림 5에 보여진다. 비디오는 47개국에 걸쳐 있으며 다양한 참가자(자가 보고된 인구 통계)에 의해 촬영된다.
Masklets.
주석은 190.9K 수작업 masklet 주석과 우리의 데이터 엔진으로 수집된 451.7K automatic masklet으로 구성된다. masklet이 overlaid인(수동과 자동) 예제 비디오는 그림 4에 보여진다. SA-V는 가장 큰 VOS 데이터셋에 비해 53배 (자동 주석 없이 15배) 더 많은 mask를 갖는다. SA-V 수동의 소실률(최소 한 프레임에서 사라졌다가 다시 등장하는 주석처리된 masklet의 비율)은 42.5%로, 기존 데이터셋과 비교하여 경쟁력 있다. 그림 5a는 DAVIS, MOSE, YouTubeVOS와 mask 크기 분포(비디오 해상도에 의해 정규화된)를 비교한 것이다. SA-V mask의 88% 이상이 0.1 미만의 정규화된 마스크 영역을 가지고 있다.

SA-V training, validation and test splits.
우리는 비디오 저자(와 그들의 지리적 위치)에 기반하여 SA-V를 분할하여 유사한 객체의 중복을 최소화한다. SA-V val과 SA-V test 셋을 생성하기 위해 우리는 도전적인 시나리오에 초점을 맞추고 비디오를 선택하고, 주석자들에게 빠른 움직임, 다른 객체에 의해 복잡한 차폐 뿐만 아니라 사라졌다가 다시 나타나는 패턴과 같은 도전적인 대상을 식별할 것을 요청한다. 이러한 대상은 데이터 엔진 Phase 1 설정을 사용하여 6 FPS로 주석처리된다. SA-V val split에는 293개 masklet과 155개 video가 존재하고, SA-V test split에서 278개 masklet과 150개 비디오를 갖는다.
Internal dataset.
우리는 학습 셋을 증강하기 위해 내부적으로 사용가능한 라이센스 비디오 데이터를 사용했다. 우리의 내부 데이터셋은 학습을 위해 Phase 2, Phase 3에서 주석 처리된 62.9K 비디오와 69.9K masklet으로 구성되고, test(내부 테스트)를 위해 Phase 1을 사용하여 주석처리된 96개 비디오와 189개 masklet으로 구성되었다.
데이터 엔진과 SA-V 데이터셋에 대한 더 상세한 내용은 부록 D 참조.
6 Zero-shot experiments
여기에서 우리는 SAM 2를 zero-shot video task와 image task에 대한 이전 작업과 비교한다. 우리는 비디오에 대해 메트릭을, 이미지 task에 대해 mIoU에 대한 표준 리포트한다. 달리 언급되지 않는 한, 이 섹션에서 리포트된 결과는 1024 해상도의 Hiera-B+ 이미지 encoder를 사용하고 모든 데이터셋의 combination에서 학습된 우리의 기본 설정을 따른다. 즉 Table 7의 SAM 2(Hiera-B+)이다(자세한 내용은 C.2 참조).
6.1 Video tasks
6.1.1 Promptable video segmentation
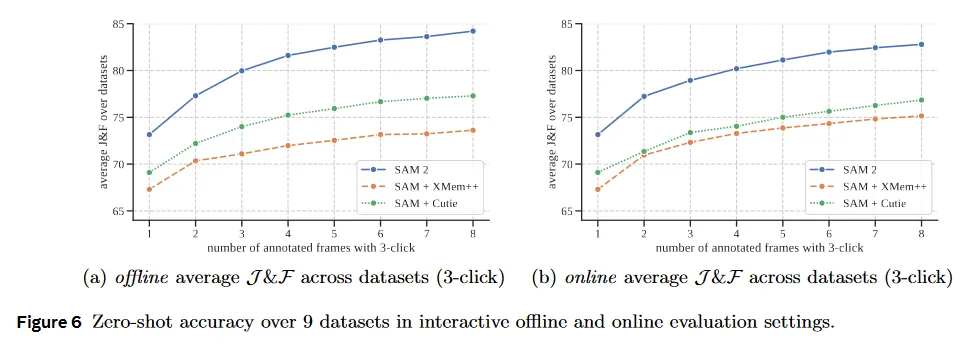
우리는 우선 사용자 경험과 유사한 interactive 설정을 시뮬레이션하는 promptable video segmentation을 평가한다. 두 가지 설정이 있다. offline 평가에서는 가장 큰 모델 error에 기반하여 상호작용할 프레임을 선택하기 위해 비디오를 multiple pass하고, online 평가에서는 비디오를 한 번 forward pass하면서 프레임에 주석처리 한다. 이러한 평가는 프레임당 클릭을 사용하여 9개의 밀집으로 주석처리된 zero-shot 비디오 데이터셋에서 수행된다.
우리는 video object segmentation을 위한 최첨단 모델인 XMem++와 Cuite를 기반으로 SAM+XMem++와 SAM+Cuite라는 두 가지 강력한 baseline을 생성한다. 우리는 XMem++을 사용하여 하나 또는 여러 프레임의 mask 입력을 기반으로 video segmentation을 생성한다. SAM은 초기 mask를 제공하거나 출력을 조정하는데 사용된다(현재 segmentation을 SAM에 mask prompt로써 제공). SAM+Cutie baseline의 경우 여러 프레임에서 mask 입력을 받을 수 있도록 Cutie를 수정한다.
그림 6에서 우리는 상호작용 프레임에 대한 평균 정확도를 리포트한다. SAM 2는 offline과 online 평가 설정 모두에서 SAM+XMem++와 SAM+Cutie를 능가한다. 9개의 모든 데이터셋에서(데이터셋 별 결과는 E.1에서 확인) SAM 2는 두 방법을 압도하며, SAM 2가 소수의 클릭만으로 고품질 비디오 segmentation을 생성할 수 있고, 추가 프롬프트로 결과를 계속 개선할 수 있음을 확인한다. 전체적으로 SAM 2는 3배 더 적은 iteration으로 더 나은 segmentation 정확도를 생성할 수 있다.
6.1.2 Semi-supervised video object segmentation
우리는 다음으로 비디오의 첫 프레임에서만 click, box 또는 mask 프롬프트를 사용하는 semi-supervised video object segmentation(VOS) 설정을 평가한다. 클릭 프롬프트를 사용할 때, 우리는 비디오의 첫 프레임에서 1, 3, 5 click을 interactively샘플링한 다음 이러한 클릭에 기반하여 object를 추적한다.
6.1.1의 interactive 설정과 유사하게, 우리는 XMem++과 Cuite를 비교하며, click과 box prompt에는 SAM을 사용하고, mask prompt를 사용할 때는 기본 설정을 사용한다. 우리는 VOST만 제외하고 표준 정확도를 리포트한다. VOST에서는 해당 프로토콜을 따라 메트릭을 리포트한다. 결과는 Table 4 참조. SAM 2는 다양한 입력 prompt를 사용항여 17개 데이터셋에서 두 basline을 모두 능가한다. SAM 2가 다른 작업들이 특별하게 설계된 mask 입력을 사용하는 기존의 non-interactive VOS task에서도 뛰어난 성능을 보인다는 것을 강조한다. 더 자세한 내용은 E.1.3 참조

6.1.3 Fairness evaluation
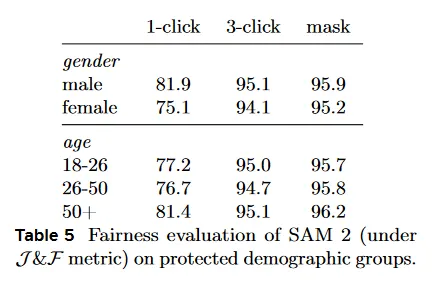
인구통계힉적 그룹 간 SAM 2의 공정성을 평가한다. 우리는 EgoExo4D 데이터셋의 사람 카테고리에 대한 주석을 수집한다. 이것은 비디오의 주제가 제공한 자체 리포트된 인구통계 정보를 포함한다. 우리는 SA-V val과 test set에 대해 동일한 주석 설정을 사용하여 3인칭 (exo) 비디오의 20초 클립에 적용한다. 첫 프레임에서 1 클릭과3 클릭, ground-truth mask를 사용하여 이 데이터에 대해 SAM 2를 평가한다.
Table 5는 성별과 연령에 따른 사람 segmenting 을 위한 SAM 2의 정확도 비교를 보인다. 3클릭과 ground-truth mask prompt에서 차이가 미미하다. 우리는 1 클릭 prediction을 수동으로 관찰한 결과 모델이 빈번하게 사람 전체 대신 일부분에 대한 mask를 예측하는 것을 발견했다. 사람이 올바르게 segmented인 클립으로 비교를 제한할 때, 1 클릭에서의 격차가 상당히 줄어든다( male은 94.3, female은 92.7). 이것은 불일치가 부분적으로 프롬프트의 모호성에 기인할 수 있음을 시사한다. 부록 G에서 우리는 SA-V에 대한 모델, 데이터, 주석 카드를 제공한다.
6.2 Image tasks
우리는 SAM이 이전의 평가에 사용한 23개 데이터셋을 포함하여 37개의 zero-shot 데이터셋에 걸쳐 Segment Anything task에 대해 SAM을 평가한다. Table 6에서 1 클릭과 5 클릭 mIoU를 리포트하고, 단일 A100 GPU에서 데이터셋 도메인별 평균 mIoU와 FPS로 측정한 모델 속도를 보인다.

첫 열(SA-23 All)은 SAM의 23개 데이터셋에 대한 정확도를 보인다. SAM 2는 임의의 추가 데이터 사용 없이 SAM(1 클릭으로 58.1 mIoU) 보다 더 높은 정확도(1 클릭으로 58.9 mIoU)를 달성하면서 6배 더 빠르다. 이것은 주로 SAM 2의 더 작지만 효과적인 Hiera image encoder 덕분이다.
마지막 행은 SA-1B과 비디오 데이터 혼합으로 학습하면 23개 데이터셋에서 평균 정확도를 61.4%로 개선시킬 수 있음을 보인다. 우리는 SA-23에서 비디오 벤치마크(비디오 데이터셋은 Kirillov et al(2023)과 동일하게 이미지로써 평가된다)와 우리가 추가한 14개의 새로운 비디오 데이터셋에서 예외적인 성과를 볼 수 있다.
전체적으로 이 결과는 SAM 2의 interactive video와 image segmentation에서 이중 능력을 강조하며, 이는 visual 도메인 전반에 걸쳐 비디오와 정적 이미지를 포괄하는 우리의 다양한 학습 데이터에서 비롯된 강점이다. 데이터셋 별 breakdown을 포함한 더 상세한 결과는 E.3 참조
7 Comparison to state-of-the-artin semi-supervised VOS
우리의 주요 초점은 일반적인 interactive PVS task에 있지만 역사적으로 일반적인 프로토콜이었던 specific semi-supervised VOS 설정도 다룬다(첫 프레임에서 ground-truth mask가 prompt로 주어지는 경우). 우리는 speed-vs-accuracy tradeoff가 다른 다양한 이미지 encoder 크기(Hiera-B+/-L)를 가진 SAM 2의 2가지 버전을 평가한다. 우리는 단일 A100 GPU에서 배치 사이즈 1을 사용하여 FPS를 측정한다. Hiera-B+와 Hiera-L에 기반한 SAM 2는 각각 43.8과 30.2 FPS의 실시간 속도로 실행된다.
우리는 Table 7에서 기존 최첨단과 비교를 제시하고 표준 프로토콜을 사용한 정확도를 리포트한다. SAM 2는 기존의 최고 방법보다 상당한 개선을 보인다. 더 큰 이미지 encoder를 사용하면 전반적으로 상당한 정확도 향상을 얻을 수 있음을 관찰한다.
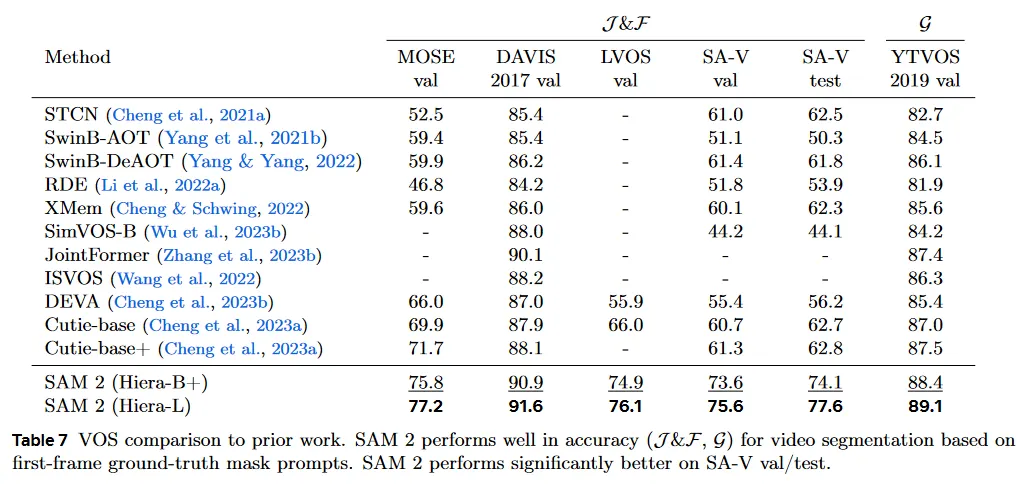
우리는 또한 ‘any’ object class의 open-world segment에 대한 성능을 측정하는 SA-V val 과 test set에서 기존 작업을 평가한다. 이 벤치마크에서 비교할 때, 대부분의 이전 방법들이 비슷한 정확도에서 정점을 찍는 것을 볼 수 있다. 이전 연구에서 SA-V val과 SA-V test에서 최고 성능은 상당히 낮아 video에서 segment anything하는 능력과 격차를 시연을 한다. 마지막으로 LVOS 벤치마크 결과에서 볼 수 있듯이 SAM 2가 long-term video object segmentation에서도 주목할만한 이점을 얻는 것을 본다.
8 Data and model ablations
이 섹션에서 SAM 2의 설계 결정에 영향을 준 abalation을 제시한다. 우리는 MOSE 학습 분할에서 무작위로 샘플링된 200개의 비디오를 포함하는 MOSE development set(”MOSE dev”)와 우리의 ablation에서 SA-V val, 그리고 9개 zero-shot 비디오 데이터셋의 평균에서 제외된 데이터에 대해 평가한다. 비교를 위한 메트릭으로, 우리는 1 클릭 체제와 VOS-style mask prompt 사이의 균형으로 첫 프레임에 3 클릭 입력을 사용한 를 리포트한다. 추가적으로 이미지에 대한 SA 작업을 위해 SAM이 사용한 23개 데이터셋 벤치마크에서 평균 1 클릭 mIoU을 리포트한다.
달리 명시하지 않는 한, 우리는 512 해상도와 SA-V 수동, SA-1B의 10% 부분집합을 사용하여 ablation을 실행한다. 추가 상세는 C.2 참조
8.1 Data ablations
Data mix ablation.
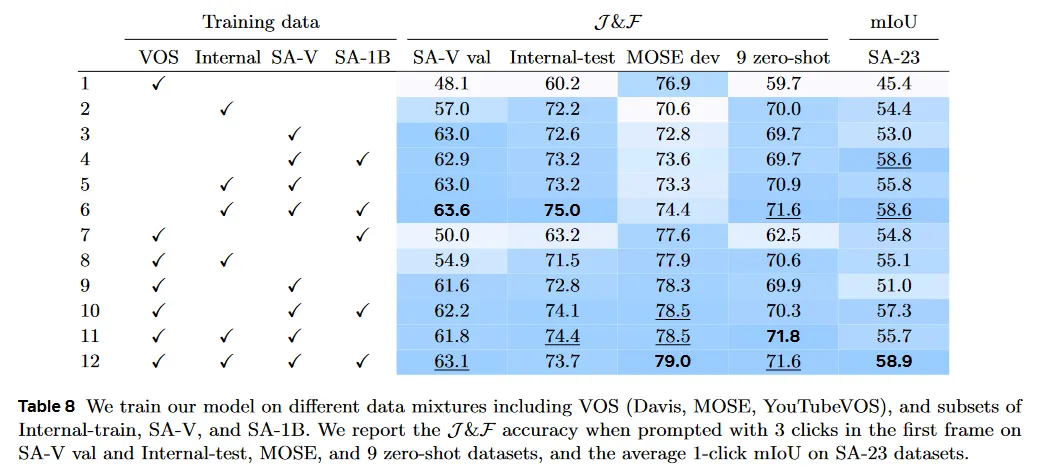
Table 8에서 우리는 다양한 데이터 혼합에서 학습될 때 SAM-2의 정확도를 비교한다. 우리는 SA-1B에서 pre-train하고 각 설정에 대해 별도의 모델을 학습한다. 우리는 iteration의 수(200k)와 batch size(128)을 고정하고 실험 사이의 학습 데이터만 변경한다. SA-V val set, MOSE, 9개 zero-shot video 벤치마크와 SA-23 task에 대한 정확도를 리포트한다. 1행은 순수하게 VOS 데이터셋(Davis, MOSE, YouTubeVOS)에서 학습된 모델이 도메인 내 MOSE dev 에서 잘 수행되지만, 9개의 zero-shot VOS 데이터셋(59.7 )을 포함하여 다른 모든 것에서는 빈곤하게 수행되는 것을 보인다.
학습 혼합에 우리의 데이터 엔진 데이터를 추가함으로써 엄청난 이익을 관찰한다. 9개의 zero-shot 데이터셋에서 12.1% 평균 성능 개선(11행과 1행)을 얻는다. 이것은 VOS 데이터셋의 제한된 커버리지와 크기 때문일 수 있다. SA-1B 이미지를 추가하면 VOS 능력의 감소 없이 이미지 segmentation task에서 성능을 개선할 수 있다(3행 vs 4행, 5행 vs 6행, 9행 vs 10행, 11행 vs 12행). SA-V와 SA-1B에서만 학습하는 것(4행)은 MOSE를 제외한 모든 벤치마크에서 강력한 성능을 얻는데 충분하다. 전체적으로 우리는 모든 데이터셋을 혼합할 때 최고 결과를 얻는다. VOS, SA-1B 그리고 우리의 데이터 엔진 데이터(12행)
Data quantity ablation.
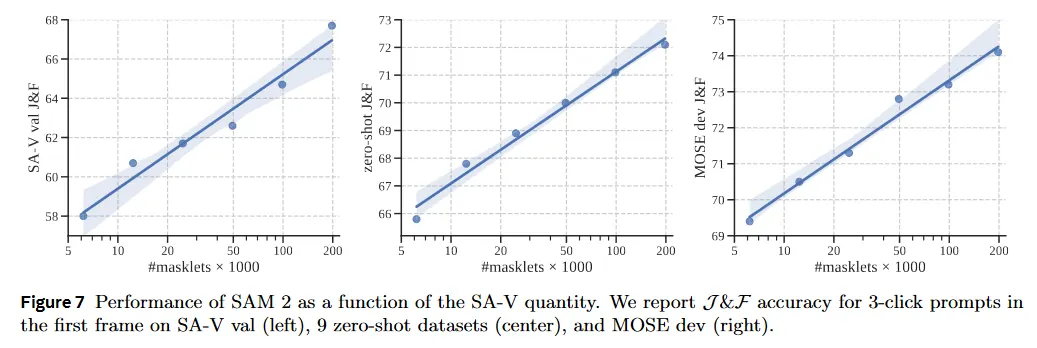
다음으로 우리는 학습 데이터의 규모를 확장하는 것의 효과를 연구한다. SAM 2는 다양한 크기의 SA-V에서 학습하기 전에 SA-1B에서 pre-trained이다. 우리는 3개의 벤치마크(SA-V val, zero-shot, MODE dev)에 대해 평균 점수를 리포트한다(첫 프레임에서 3 클릭으로 prompt된). 그림 7은 모든 벤치마크에서 학습 데이터의 양과 비디오 segmentation 정확도 사이의 일관된 멱법칙을 보인다.
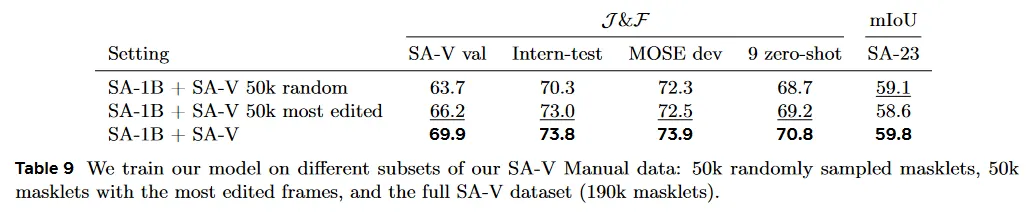
Data quality ablation.
Table 9에서 우리는 품질을 위한 filtering 전략을 실험한다. SA-V에서 50k masklet을 무작위로 샘플링하거나 주석자들에 의해 가장 많이 편집된 masklet을 선택하여 샘플링한다. 수정된 프레임의 수에 기반한 필터링은 데이터의 25%만 사용하여 강력한 성능을 보이며, 무작위 샘플링을 능가한다. 그러나 이것은 190k SA-V masklet을 전체를 사용하는 것보다는 나쁘다.
8.2 Model architecture ablations
이 섹션에서 우리는 설계 결정을 가이드하는 모델 ablation 을 제시한다. 이것은 default로 512 입력 해상도를 갖는 더 작은 모델 설정 하에 수행되었다. 각 ablation 설정에 대해, 우리는 video()와 이미지(mIoU) task에 대한 segmentation 정확도와 상대적인 video segmentation 속도(gray로 표시된 ablation default 설정 대비 최대 추론 처리량)를 리포트한다. 우리는 이미지와 비디오 컴포넌트에 대한 설계 선택이 대체로 구별된다는 것을 발견한다. 이것은 우리의 모듈식 설계와 학습 전략 때문일 수 있다.
8.2.1 Capacity ablations
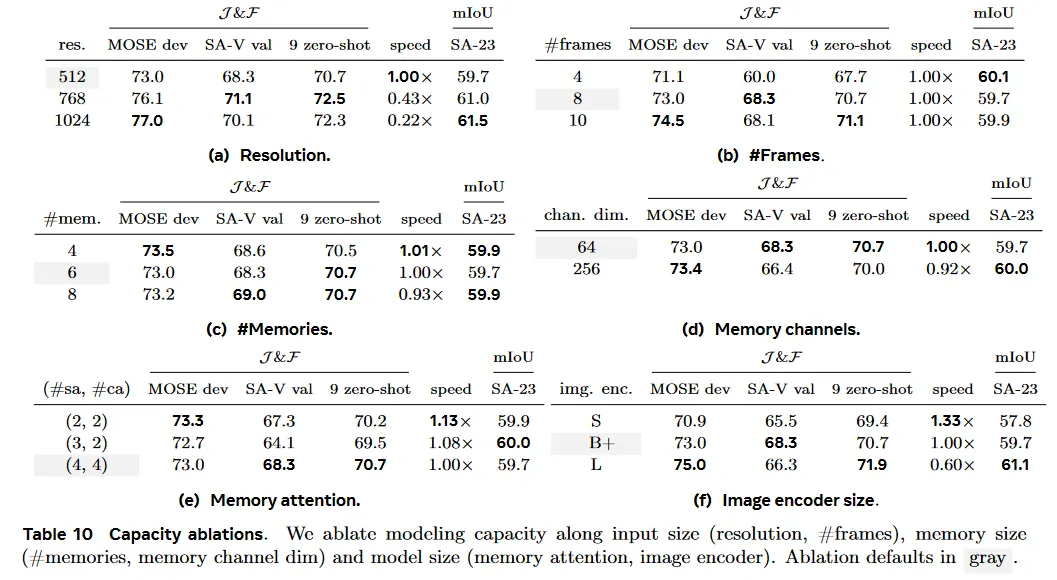
Input size.
학습하는 동안 우리는 고정된 해상도와 고정된 길이의 프레임(여기서 #frames로 표기됨)의 시퀀스를 샘플링한다. Table 10a, 10b에서 그것의 영향을 ablate한다. 더 높은 해상도는 이미지와 비디오 작업에 걸쳐 상당한 개선을 이끌고, 우리는 마지막 모델에서 1024 입력 해상도를 사용한다. 프레임의 수의 증가는 비디오 벤치마크에서 주목할만한 이점을 가져오고, 속도와 정확도의 균형을 잡기 위해 8개를 기본으로 사용한다.
Memory size.
메모리의 (최대) 수 를 증가시키면 일반적으로 성능이 향상되지만 Table 10c에서 보듯이 약간 편차가 있을 수 있다. 우리는 temporal context 길이와 계산 비용 사이의 균형을 잡기 위해 6개 과거 프레임을 default 값으로 사용한다. 메모리의 채널 수를 줄여도 Table 10d에서처럼 성능 저하가 크지 않으며 저장에 필요한 메모리는 4배 더 적다.
Model size.
이미지 encoder 또는 memory-attention(#self-/#cross-attention block)에서 더 많은 수용량을 추가하면 일반적으로 결과를 개선한다. Table 10e, 10f 참조. 이미지 encoder를 확장하면 이미지와 비디오 메트릭 모두에서 이익을 가져오는 반면 memory-attention을 확장하는 것은 비디오 메트릭만 개선한다. 우리는 속도와 정확도 사이의 균형을 맞추기 위해 B+이미지 encoder를 default로 사용한다.
8.2.2 Relative positional encoding
기본적으로 우리는 항상 이미지 encoder과 memory attention 모두에 절대값 positional encoding을 사용한다. Table 11에서 우리는 상대값 positional encoding 설계 선택을 연구한다. 여기에서 우리는 LVOSv2에서 첫 프레임에 3 클릭을 사용하는 long-term video object segmentation에 대한 벤치마크로 평가한다.

SAM이 Li et al(2022b)를 따라 relative positional bias(RPB)를 모든 image encoder 레이어에 추가했지만, Bolya et al(2023)은 global attention layer를 제외한 모든 곳에서 RPB를 제거하고 ‘absolute-win’ positional encoding을 채택하여 큰 속도 향상을 이끌었다. 우리는 이것에 추가로 이미지 encoder에서 모든 RPB를 제거했다. SA-23에서 성능 저하 없이 비디오 벤치마크에서 최소 저하만 발생했으며(Table 11), 1024 해상도에서 상당한 속도 향상을 얻는다. 우리는 또한 memory attention에서 2d-RoPE를 사용하는 것이 유익함을 발견한다.
8.2.3 Memory architecture ablations

Recurrent memory.
우리는 memory feature를 GRU에 전달한 후 memory bank에 추가하는 효과를 조사한다. 8.2.2와 유사하게 우리는 long-term object segmentation에 대한 추가 벤치마크로써 LVOSv2에서 평가한다. 이전 작업들이 일반적으로 GRU 메모리를 추적하는 과정에 통합하는 수단으로 사용했지만 Table 12에서 우리의 발견은 이 접근이 개선을 제공하지 않음을 시사한다(LVOSv2에서 약간 예외). 대신 우리는 memory feature를 직접 memory bank에 저장하는 것이 더 간단하고 효율적임을 발견한다.
Object pointers.
우리는 다른 프레임의 mask decoder 출력에서 object pointer vector에 cross-attending 하는 것의 영향을 ablate한다(섹션 4). Table 12의 결과는 object pointer에 cross-attending 하는 것이 9개 zero-shot 데이터셋에 걸쳐 평균 성능을 개선하지 않지만, SA-V val 데이터셋과 도전적인 LVOSv2 벤치마크(validation split)에서 성능을 크게 향상시킨다는 것을 보인다. 따라서 우리는 memory bank와 함께 object pointer에 대해 cross-attending하는 것을 default로 한다.
9 Conclusion
우리는 Segment Anything을 비디오 도메인으로 자연스럽게 발전시킨 결과를 제시한다. 이것은 3가지 핵심 측면을 기반으로 한다. (i) promptable segmentation 작업을 비디오로 확장 (ii) 비디오에 적용할 때 memory를 사용할 수 있도록 SAM 아키텍쳐를 개선 (iii) 비디오 segmentation을 학습하고 벤치마킹하기 위한 다양한 SA-V 데이터셋. 우리는 SAM 2가 시각적 인식에서 큰 진보를 이루었다고 믿으며, 우리의 기여가 이 분야의 추가 연구와 응용을 촉진할 마일스톤이 될 것이라 생각 한다.
