
A. Segment Anything Model and Task Details
Image encoder.
일반적으로 이미지 encoder는 이미지 embedding을 출력하는 임의의 네트워크일 수 있다. 확장성과 강력한 pre-training에 접근하기 위해, 우리는 MAE pre-trained Vision Transformer(ViT)를 사용하고 높은 해상도 입력을 처리하도록 최소한의 수정만 한다. 구체적으로 14x14 windowed attention을 사용하고 4개의 동일하게 배치된 global attention block을 사용하는 ViT-H/16을 사용한다. [62]를 따라. 이미지 encoder의 출력은 입력 이미지의 16배 downscaled embedding이다. 우리의 실행 목표가 각 프롬프트를 실시간으로 처리하는 것이기 때문에 이미지 encoder의 FLOPs가 높아도 문제없다. 이는 프롬프트 당이 아니라 이미지 당 한 번만 계산되기 때문이다.
표준 관행을 따라 우리는 이미지를 rescaling하고 짧은 쪽을 padding하여 입력 해상도를 1024x1024로 사용한다. 따라서 이미지 embedding은 64x64이다. 채널 차원을 줄이기 위해 [62]를 따라 1x1 conv를 사용하여 256 채널로 줄이고, 그 뒤 3x3 conv를 사용해서 256 채널을 얻는다. 각 convolution은 뒤에는 layer normalization이 따른다.
Prompt encoder.
희소 prompt는 아래와 같이 256 차원 벡터 임베딩에 매핑된다. 하나의 point는 해당 location의 positional encoding과 foreground 또는 background 나타내는 두 가지 학습된 embedding 중 하나의 합으로 표현된다. box는 embedding pair로 나타나며 (1) top-left corner의 positional encoding과 ‘top-left corner’를 나타내는 학습된 embedding의 합 (2) 동일한 구조지만 ‘bottom-right corner’를 나타내는 학습된 임베딩을 사용한다. 마지막으로 free-form text를 표현하기 위해 우리는 CLIP의 text encoder를 사용한다(일반적으로 임의의 text encoder가 사용 가능하다). 이 섹션의 나머지 부분에서는 기하학적 prompt에 초점을 맞추며, 텍스트 prompt에 대한 더 깊은 논의는 D.5 참조.
Dense prompt(즉, mask)는 이미지와 공간적 대응 관계를 갖는다. mask는 입력 이미지보다 4배 낮은 해상도로 입력되고, 그 후 2x2와, stride-2 convolution 2개를 사용하여 출력 채널이 각각 4와 6으로 추가로 4배 downscale한다. 마지막으로 1x1 convolution을 사용해 채널 차원을 256으로 매핑한다. 각 레이어는 GELU activation과 layer normalization으로 구분된다. 그 다음 mask와 이미지 embedding은 element-wise로 더한다. mask prompt가 없는 경우, ‘no mask’를 나타내는 학습된 embedding이 각 이미지 embedding location에 추가된다.
Lightweight mask decoder.
이 모듈은 이미지 embedding과 프롬프트 embedding집합을 효율적으로 매핑하여 출력 마스크를 얻는다. 이러한 입력을 결합하기 위해, 우리는 Transformer segmentation model에서 영감을 받아 표준 Transformer decoder를 수정한다. 우리의 decoder를 적용하기 전에, 우리는 프롬프트 임베딩의 집합에 학습된 출력 토큰 임베딩으로 삽입한다. 이것은 [33]에서 [class] 토큰과 유사하며 디코더의 출력에서 사용될 수 있다. 단순성을 위해 우리는 이러한 임베딩(이미지 임베딩을 제외하고)을 ‘token’이라 부른다.
우리의 디코더 설계는 그림 14에 보여진다. 각 디코더 레이어는 4 단계를 수행한다. (1) token에 대한 self-attention (2) token(query로써)에서 이미지 embedding으로 cross-attention (3) 각 token을 업데치트하는 point-wise MLP (4) 이미지 임베딩(query로써)에서 token으로 cross-attention. 이 마지막 단계는 프롬프트 정보를 사용하여 이미지 임베딩을 업데이트 한다. cross-attention 동안 이미지 임베딩은 개의 256-차원 벡터의 집합으로 다뤄진다. 각 self/cross-attention과 MLP는 residual connection, layer normalization과 0.1의 dropout이 적용된다. 다음 디코더 레이어는 이전 레이어에서 업데이트된 token과 이미지 임베딩을 사용한다. 우리는 2개의 디코더 레이어를 사용한다.
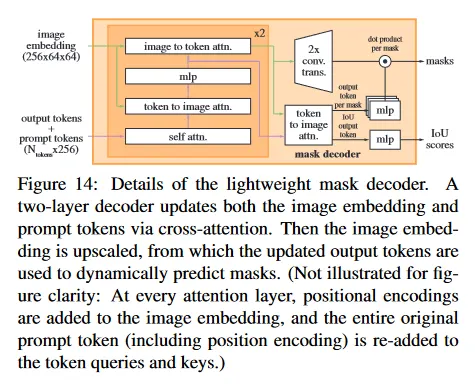
디코더가 핵심적인 기하학 정보에 접근할 수 있도록, attention layer에 참여할 때마다 positional encoding이 이미지 임베딩에 추가된다. 추가적으로 prompt token이 attention layer에 참여할 때마다 original prompt token(positional encoding 포함)이 업데이트된 token에 다시 추가된다. 이것은 프롬프트의 token의 기하학 location과 type 모두 강하게 의존할 수 있게 한다.
디코더를 실행한 후에, 2개의 transposed convolutional layer로 업데이트된 이미지 임베딩을 4배 upsample한다(이제 입력 이미지에 상대적으로 4배 downscale 된 상태). 그 다음 token은 이미지 임베딩에 다시 한 번 attend하고 업데이트된 출력 token 임베딩을 작은 3개 layer MLP에 전달하여, upscale된 이미지 임베딩의 채널 차원과 일치하는 벡터를 출력한다. 마지막으로 upscale된 이미지 임베딩과 MLP의 출력 사이의 공간적 point-wise product를 사용하여 mask를 예측한다.
Transformer는 256차원의 임베딩을 사용한다. transformer MLP 블록은 내부에 2048의 큰 차원을 갖지만 MLP는 상대적으로 희소한 prompt token(20보다 훨씬 작은)에만 적용된다. 그러나 64x64 이미지 임베딩을 갖는 cross-attention layer에서 계산 효율성을 위해 query, key, value의 채널 차원을 2배 축소하여 128로 만든다. 모든 attention layer는 8개 head를 사용한다.
출력 이미지 임베딩을 upscale하기 위해 사용된 transposed convolution은 2x2, stride 2이고 출력 채널 차원은 각각 64와 32이다. 또한 GELU activation을 갖고, layer normalization에 의해 구분된다.
Making the model ambiguity-aware.
앞서 설명한 것처럼 single input prompt는 여러 유효한 mask에 대응할 수 있어 모호할 수 있고 모델은 이러한 mask에 대해 평균화를 학습한다. 우리는 간단한 수정으로 이 문제를 제거한다. single mask를 예측하는 대신, 소수의 출력 token을 사용하여 multiple mask를 동시에 예측한다. 기본적으로 3개의 mask를 예측하는데, 3개 layer(whole, part, subpart)가 중첩된 mask를 설명하는데 충분하다는 것을 관찰했기 때문이다. 학습하는 동안 ground truth와 각 예측된 mask 사이의 loss를 계산하지만 가장 낮은 loss에만 역전파를 수행한다. 이것은 multiple 출력을 갖는 모델에서 일반적으로 사용되는 기법이다. 응용에서 사용할 때, 우리는 예측된 mask의 ranking을 원하기 때문에, 각 예측된 mask와 object 사이의 IoU를 추정하는 작은 head를 추가한다(추가 출력 token에서 작동하는).
모호성은 multiple prompt를 사용할 때 훨씬 희소하고, 3개 출력 mask는 일반적으로 유사하다. 학습하는 동안 불필요한 loss 계산을 최소화하고, single unambiguous mask가 규칙적인 gradient 신호를 수용하도록 하기 위해, 하나 이상의 프롬프트가 주어질 때 single mask만 예측한다. 이것은 추가 마스크 예측을 위한 4번째 출력 토큰을 추가하여 구현된다. 이 네 번째 마스크는 단일 프롬프트에 대해서는 반환되지 않고 multiple prompt에 대해서만 반환되는 유일한 mask이다.
Losses.
우리는 focal loss와 dice loss의 선형 결합으로 mask prediction을 지도학습하고 [20, 14]을 따라 focal loss와 dice loss를 20:1로 사용한다. [20, 14]와 달리 우리는 디코더 레이어 이후에 적용되는 auxiliary deep supervision이 도움이 되지 않는다는 것을 관찰한다. IoU 예측 head는 IoU 예측과 예측된 mask의 ground truth mask와의 IoU 사이의 mean-square-error loss를 사용하여 학습된다. 이것은 mask loss에 1.0의 상수 scaling factor를 사용하여 추가된다.
Training algorithm.
최근 접근 [92, 37]을 따라 우리는 학습하는 동안 interactive segmentation 설정을 시뮬레이션 한다. 우선 동일한 확률로 target mask에 foreground point나 bounding box를 무작위로 선택한다.
Point는 ground truth mask에서 균등하게 샘플링된다. Box는 ground truth의 bounding box를 기준으로하며, 각 좌표에 box의 측면의 10%에 해당하는 표준편차를 가진 무작위 노이즈를 최대 20 픽셀까지 추가한다. 이 noise profile은 target object 주위에 tight box를 생성하는 instance segmentation과 사용자가 loose box를 그릴 수 있는 interactive segmentation 사이의 합리적인 타협이다.
첫 프롬프트에서 예측을 수행한 후에, 후속 point는 이전 mask 예측과 ground truth mask 사이의 error 영역에서 균등하게 샘플링된다. 새로운 점은 error region이 false negative면 foreground로, false positive면 background로 설정된다. 또한 이전 iteration에서 mask prediction을 추가 프롬프트로 모델에 공급한다. 다음 iteration에 최대한의 정보를 제공하기 위해, 이진화된 mask 대신 unthresholded mask logit을 공급한다. multiple mask가 반환되면 다음 iteration에 전달되고, 다음 point를 샘플링하는데 사용되는 mask는 예측된 IoU가 가장 높은 것이다.
8번의 iteration 샘플링 point 이후에 return이 감소하는 것을 발견했다(우리는 16번까지 테스트했다). 추가로 제공된 mask에서 이점을 얻도록 모델을 장려하기 위해, 추가 point가 샘플링 되지 않는 2번의 iteration을 추가로 사용한다. 이 중 하나는 8번의 반복 중 무작위로 삽입되고, 다른 하나는 마지막에 위치한다. 이로서 총 11번의 iteration을 수행한다. 하나의 샘플링된 초기 입력 프롬프트, 8번의 iterative 샘플링 point, 그리고 새로운 외부 정보가 모델에 공급되지 않아 자신의 mask 예측을 조정하도록 학습하는 2번의 iteration이다. lightweight mask decoder는 이미지 encoder의 계산 자원의 1% 미만이므로, 각 iteration은 작은 overhead만 추가된다. 이것은 이전의 interactive 방법들이 optimizer update 당 한, 두 번 만의 interactive 단계를 수행했던 것과 다르다.
Training recipe.
우리는 AdamW optimizer()를 사용하고 250 iteration 동안 linear learning rate warmup과 step-wise learning rate decay 스케쥴을 사용한다. warmup 이후 초기 learning rate은 이다. 우리는 90k iteration(약 2 SA-1B epoch) 동안 학습하고, 60k iteration에서 learning rate를 10의 factor로 감소시키고, 86666 iteration에서 다시 반복한다. batch size는 256 이미지이다. SAM을 regularize 하기 위해 우리는 weight decay를 0.1로 설정하고 0.4의 비율로 drop path를 적용한다. 우리는 0.8의 layer-wise learning rate decay을 사용한다. data augmentation은 적용하지 않는다. 우리는 MAE pre-tarined ViT-H에서 SAM을 초기화한다. 우리는 대형 image encoder와 1024x1024 입력 크기 때문에 학습을 256 GPU에 걸쳐 분산한다. GPU 메모리 사용량을 제한하기 위해, 우리는 GPU 당 64개 무작위로 샘플링된 mask로 학습한다. 게다가 SA-1B mask를 가볍게 filtering 하여 이미지의 90% 이상을 차지하는 mask를 폐기한다. 이는 결과를 질적으로 개선한다.
학습의 ablation과 다른 변종을 위해(예: text-to-mask D.5), 위의 기본 레시피를 다음처럼 설정한다. 첫 번째와 두 번째 data engine의 데이터만으로 학습할 때, 우리는 large-scale jitter를 사용하여 범위의 scale로 입력을 증강한다. 직관적으로 학습 데이터가 더 제한적일 때 데이터 증강이 도움이 될 수 있다. ViT-B와 ViT-L을 학습하기 위해 우리는 128개 GPU에 걸쳐 128개 분산된 배치 크기로 180k iteration을 사용한다. 우리는 ViT-B/L에 대해 각각 learning rate를 , learning rate decay를 , weight decay를 , drop path를 로 설정한다.
B. Automatic Mask Generation Details
여기서 공개된 SA-1B를 생성하는데 사용된 data engine의 fully automatic stage의 상세를 논의한다.
Cropping.
Mask는 전체 이미지에서 32x32 point의 regular grid를 사용해서 생성되었고, 16x16과 8x8 regular point grid를 사용하여 2x2와 4x4 부분 중첩 window에서 생성된 20개의 추가 zoom-in image crop에서도 생성되었다. 이미지는 cropping을 위해 원본 고해상도 사용된다(이때만 사용). crop의 내부 경계를 touch하는 mask는 제거한다. 두 단계로 구성된 표준 greedy box-based NMS(효율성을 위해 box를 사용)를 적용한다.
첫 번째는 각 crop 내에서 두 번째는 crop에 걸쳐 적용되었다.
crop 내에서 NMS를 적용할 때는, 모델이 예측한 IoU를 사용하여 mask 랭킹을 매긴다. crop 간에 NMS를 적용할 때는, mask를 source crop을 기준으로 가장 zoom-in된 것(즉 4x4 crop)부터 가장 적게 zoom-in된 것(즉 원본 이미지) 순으로 mask 랭킹을 매겼다. 두 경우 모두 NMS threshold를 0.7로 사용한다.
Filtering.
우리는 mask 품질을 높이기 위해 3가지 filter를 사용한다. 첫째, confident mask만 유지하기 위해 모델이 예측한 IoU score를 88.0 이상으로 filtering 한다. 둘째, stable mask만 유지하기 위해 동일한 soft mask에서 얻은 두 개의 binary mask를 서로 다른 값으로 thresholding 하여 비교했다. 두 개의 임계값 -1과 +1로 처리된 mask 쌍 간의 IoU가 95.0 이상인 경우에만 예측된 mask(즉 logit을 0으로 thresholding한 binary mask)를 유지했다. 세번째, automatic mask가 종종 전체 이미지를 커버하는 경우가 있음을 발견했다. 이러한 mask는 일반적으로 흥미롭지 않으므로 이미지의 95% 이상을 커버하는 mask를 제거했다. 모든 filtering threshold는 섹션 5에서 설명한 방법을 사용한 전문 주석자들에 의해 판정에 따라 많은 수의 mask와 높은 mask 품질 모두를 달성하기 위해 선택된다.
Post-processing.
post-processing과 함께 쉽게 완화되는 두 가지 에러 유형을 발견했다. 첫째, 약 4%의 mask에 작은 잘못된 component가 포함된다. 이것을 해결하기 위해 연결된 component 중 면적이 100 픽셀보다 작은 것을 제거한다(가장 큰 component가 이 threshold 아래에 있다면 전체 mask를 제거하는 것을 포함). 둘째 약 4%의 mask에 작은 잘못된 구멍이 포함된다. 이것을 해결하기 위해 우리는 100 픽셀 보다 작은 구멍을 채웠다. 구멍은 반전된 mask의 component로 식별된다.
Automatic mask generation model.
우리는 mask 생성 성능을 향상시키기 위해, 추론 속도를 일부 희생하는 특별한 버전의 SAM을 fully automatic mask 생성을 위해 학습했다. 여기서 사용된 SAM과 default SAM의 차이는 다음과 같다. 수작업과 반자동 데이터로만 학습되며, 90k 대신 177656 iteration으로 더 오래 훈련되고, large-scale jitter 데이터 증강이 적용되었으며, 시뮬레이션된 interactive 학습은 point와 mask prompt만 사용하고(no box) 학습하는 동안 mask 당 4개의 point만 샘플링했다(9개에서 4개로 줄이면 학습 속도가 빨라지며 1-point 성능에 영향을 미치지 않지만, 더 많은 point로 평가할 때는 mIoU에 악영향을 줄 수 있음). 마지막으로 mask decoder는 2개가 아니라 3개 레이어를 사용한다.
SA-1B examples.
우리는 그림 2에서 SA-1B 샘플을 보인다. 더 많은 예제는 우리의 데이터셋 탐색기를 참고하라.
D. Experiment Implementation Details
D.1. Zero-Shot Single Point Valid Mask Evaluation
Datasets.
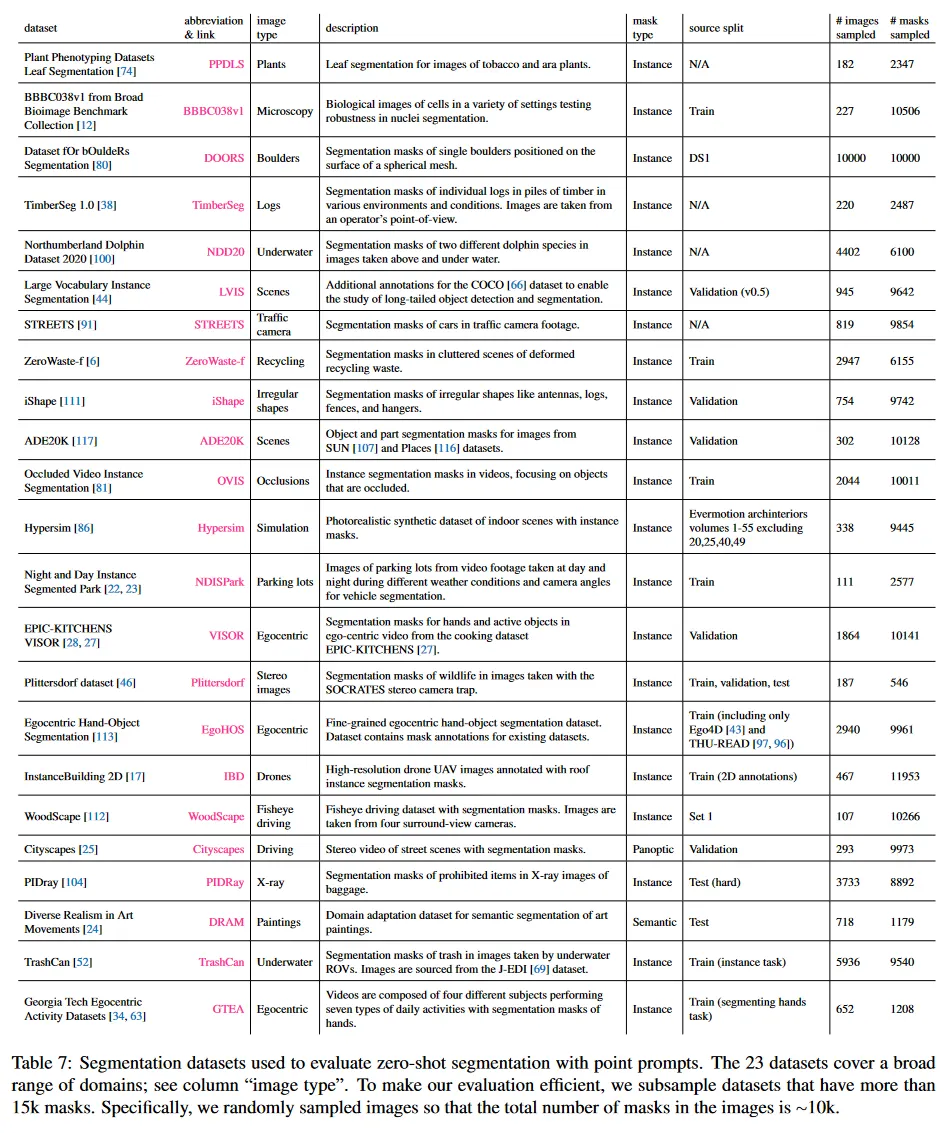
우리는 이전 작업에서 사용된 23개 diverse segmentation dataset을 통해 우리 모델의 zero-shot transfer 능력을 평가할 새로운 segmentation 벤치마크를 구축했다. 각 데이터셋에 대한 설명은 Table 7 참조. 예컨대 본문 그림 8 참조. 이 suite는 egocentric, microscopy, X-ray, underwater, aerial, simulation, driving, painting 이미지를 포함한 도메인 영역을 커버한다. 효율적인 평가를 위해 15k mask 이상 데이터셋은 서브 샘플링한다. 구체적으로 샘플링된 이미지에서 mask의 총 수가 10k가 되도록 이미지를 무작으로 고른다. 모든 데이터셋에서 사람 얼굴은 blur한다.
Point sampling.
우리의 default point 샘플링은 interactive segmentation의 표준 관행을 따른다. 첫 point는 object boundary에서 가장 먼 point을 결정론적으로 고른다. 각 후속 point는 ground truth와 이전 예측 사이의 error region의 boundary에서 가장 먼 것을 고른다. 일부 실험(명시된 경우)은 더 어려운 샘플링 전략을 사용한다. 이것은 첫 point를 결정론적으로 선택된 ‘center’ point가 아니라 무작위이고, 각 후속 점은 위의 설명된 것으로 선택된다. 이 설정은 첫 번째 point가 mask의 중심 근처에 있지 않을 수 있는 eye gaze에서 프롬프팅 같은 사용 사례를 더 잘 반영한다.
Evaluation.
우리는 point prompt 이후의 예측과 ground truth mask 예측 사이의 IoU를 측정하며, point는 위에서 언급된 두 가지 전략 중 하나를 사용하여 iteratively 샘플링된다. 데이터셋 당 mIoU는 데이터셋의 모든 object에 대해 평균화된 mask 별 IoU이다. 마지막으로 23개 데이터셋에 걸쳐 데이터셋 별 mIoU를 평균화하여 top-line metric를 리포트한다. 우리의 평가는 표준 interactive segmentation 평가 프로토콜과 다르다. 그것은 최대 20개 point를 사용하여 % IoU를 달성하는데 필요한 point 수를 측정한다. 우리는 단일 또는 소수만으로 예측하는 것에 초점을 맞추는데, 이는 우리의 많은 사용 사례가 단일 또는 소수의 프롬프트를 포함하기 때문이다.
실시간 프롬프트 처리가 피룡한 우리의 애플리케이션 초점으로 인해, 많은 point를 사용하는 경우에 최고의 interactive segmentation 모델이 SAM을 능가할 것으로 기대한다.
Baselines.
우리는 3가지 최근 강력한 interactive baseline을 사용한다. RITM, FocalClick, SimpleClick. 각각 저자들이 공개한 가장 큰 데이터셋에서 데이터셋에서 학습된 가장 큰 모델을 사용한다. RITM의 경우 저자들이 소개한 COCO와 LVIS의 결합으로 학습된 HRNet32 IT-M을 사용한다. FocalClick의 경우 우리는 8가지 다른 segmentation 데이터셋을 포함하는 ‘combined dataset’에서 학습된 SegFormerB3-S2를 사용한다. SimpleClick의 경우 COCO와 LVIS의 결합에 학습된 ViT-H448을 사용한다. 우리는 데이터 전처리에 대해 권장된 기본 전략을 따르고(즉 데이터 증강 또는 이미지 resizing), 평가를 위한 임의의 파라미터를 변경하거나 조정하지 않는다. 우리의 실험에서 RITM이 23개 데이터셋에서 1 point 평가에서 다른 baseline을 능가했다. 따라서 RITM을 default baseline으로 사용한다. 더 많은 point를 사용하여 평가할 때 우리는 모든 baseline에 대한 결과를 리포트한다.
Single point ambiguity and oracle evaluation.
개 포인트 프롬프트 후에 IoU에 외에도, SAM의 1 point에서 ‘oracle’ 성능을 리포트한다. 이는 SAM이 default로 첫 번째로 선택한 mask가 아닌, SAM의 3가지 예측에서 ground truth와 가장 잘 일치하는 mask를 평가하는 방식이다. 이 프로토콜은 여러 유효한 object 사이에서 하나의 올바른 mask를 맞춰야 하는 요구사항을 완화하여 단일 point 프롬프트 모호성을 해결한다.
D.2. Zero-Shot Edge Detection
Dataset and metrics.
우리는 BSDS500에서 zero-shot edge detection 실험을 수행한다. 각 이미지에 대한 ground truth는 5명의 다른 사람의 수작업 주석에서 온다. 우리는 edge detection에 대한 4가지 표준 메트릭을 사용하여 200개의 이미지 테스트 부분집합에서 결과를 리포트한다. optical dataset scale(ODS), optimal image scale(OIS), average precision(AP), 50% precision에서 recall(R50)
Method.
zero-shot transfer에 대해 우리는 automatic mask generation pipeline의 단순화된 버전을 사용한다. SAM에 16x16 regular grid의 foreground point를 프롬프트로 제공하여 768개의 예측된 마스크(point 당 3개)를 산출한다. 우리는 예측된 IoU나 안정성으로 필터링 하지 않는다. 중복 mask는 NMS로 제거한다. 그 다음 남은 mask의 unthresholded probability map에 Sobel filter를 적용하여 mask의 외부 boundary 픽셀과 교차하지 않는 값은 0으로 설정한다. 마지막으로 모든 예측에 대해 pixel-wise max를 취하고, 결과를 로 선형적으로 normalize 하고 얇은 edge를 위해 edge NMS를 적용한다.
Visualizations.
그림 15에서 SAM의 zero-shot edge 예측의 추가 예제를 보인다. 이러한 정성적 예제는 SAM이 edge detection를 위해 학습되지 않았음에도 불구하고 합리적인 edge map을 갖는 경향을 가짐을 보인다. 우리는 SAM의 edge를 인간 주석자들과 잘 정렬할 수 있음을 볼 수 있다. 그러나 이전에 언급했던 것처럼 SAM은 edge detection을 위해 학습되지 않았기 때문에, BSDS500 데이터셋의 bias를 학습하지 않고, ground truth 주석자들에서 나타난 edge 보다 종종 더 많은 edge를 출력한다.

D.3. Zero-Shot Object Proposals
Dataset and metrics.
우리는 LVIS v1 validation 셋에서 1000개의 proposal에서 mask에 대한 표준 average recall(AR) 메트릭을 리포트한다. LVIS가 1203개 object class에 대한 고품질 mask를 갖기 때문에, object proposal generation에서 도전적인 테스트를 제공한다. 우리 모델의 open-world 특성 때문에 LVIS에 포함되지 않는 class 외의 유효한 mask도 생성할 가능성이 있기 때문에 우리는 AR@1000에 초점을 맞춘다. frequent, common, rare category에서 성능을 측정하기 위해 우리는 AR@1000을 사용하지만 해당 LVIS 카테고리만 포함하는 ground truth set을 기준으로 측정한다.
Baseline.
우리는 LVIS에서 AP 성능이 가장 강력한 모델인 cascade ViTDet-H를 baseline으로 사용한다. 본문에서 언급했듯이 도메인 내에서 학습된 object detector는 AR을 ‘game’ 할 수 있고 open-world proposal 또는 segmentation에 초점을 맞춘 다른 모델보다 더 강력한 baseline이 될 것으로 기대할 수 있다. 1000개의 proposal을 생성하기 위해, 우리는 3가지 cascade stage에서 score thresholding을 disable 하고 스테이지 당 최대 예측 수를 1000으로 증가시킨다.
Method.
우리는 zero-shot transfer를 위해 SAM의 automatic mask 생성 파이프라인의 수정된 버전을 사용한다. 첫째, ViTDet와 비교 가능한 추론 시간을 위해 image crop를 처리하지 않는다. 둘째, 예측된 IoU와 안정성에 따른 filtering을 제거한다. 이것은 이미지당 약 1000개의 mask를 얻기 위해 조정 가능한 두 가지 파라미터 즉, 입력 point grid와 NMS threshold 중복 mask suppression을 남긴다. 우리는 64x64 point grid와 0.9의 NMS threshold를 선택하여 이미지당 평균적으로 900개까지 mask를 생성한다. 평가에서 1000개 이상의 mask가 제안되면, 그들의 confidence와 안정성 점수의 평균을 기준으로 순위매기고 상위 1000개 proposal로 자른다.
multiple mask를 출력하는 SAM의 능력이 이 task에 특히 유용할 것이라고 가정한다. 단일 입력 point에서 multiple scale로 생성된 proposal에서 recall에 이점을 주기 때문이다. 이것을 테스트하기 위해 3개 대신 단일 mask만 출력하는 SAM의 ablated 버전과 비교한다(SAM - 단일 출력). 이 모델이 더 적은 mask를 생성하기 때문에, 샘플된 point의 수와 NMS threshold를 각각 128x128과 0.95로 증가 시키고 이미지당 평균적으로 950개 mask를 얻는다.
게다가 단일 출력 SAM은 automatic mask generation pipeline에서 NMS를 위한 mask를 랭킹 매기기 위한 IoU 점수를 생성하지 않기 때문에 mask는 무작위로 랭킹이 매겨진다. 테스트 결과, ranking mask은 mask의 max logit value을 model confidence에 대한 proxy로 사용하는 더 복잡한 방법과 유사한 성능을 갖는다.
D.4. Zero-Shot Instance Segmentation
Method.
zero-shot instance segmentation을 위해, 우리는 CoCo와 LVIS v1 validation split에서 box 출력을 사용하여 fully-supervised ViTDet-H로 SAM을 prompt한다. 우리는 가장 confident 예측된 mask와 box 프롬프트와 mask decoder에 다시 입력하여 최종 예측을 생성하는 추가 mask 조정 iteration을 적용한다. 우리는 LVIS에 대해 예측된 zero-shot instance segmentation을 그림 16에 보인다. ViTDet과 비교하여 SAM이 더 깨끗한 경계로 더 고품질 mask를 생성하는 경향이 있다. 이 관찰은 섹션 7.4의 인간 연구를 통해 확인된다. SAM이 zero-shot model이므로 데이터셋의 주석 bias를 학습할 수 없음에 유의하라. 예컨대 SAM이 plate에 대해 유효한 modal 예측을 하지만, LVIS mask는 설계상 구멍을 포함하지 않으므로 plate는 amodally로 주석처리된다.

D.5. Zero-Shot Text-to-Mask
Model and training.
우리는 가장 큰 공개 CLIP 모델(ViT-L/14@336px)을 사용하여 텍스트와 이미지 임베딩을 계산하고 사용 전에 normalize를 적용한다. SAM을 학습하기 위해 우리는 우리의 데이터 엔진의 첫 두 단계에서 mask를 사용한다. 또한 픽셀 보다 작은 area의 모든 mask를 폐기한다. 이 모델은 large-scale jitter를 사용하고 120k iteration과 batch size 128로 학습한다. 모든 다른 학습 파라미터는 기본 설정을 따른다.
Generating training prompts.
입력 프롬프트를 추출하기 위해 우선 mask 주위의 bounding box를 1x에서 2x까지 무작위로 확장하고 확장된 box를 square-crop 하여 종횡비를 유지하고 336x336 픽셀로 resize한다. CLIP 이미지 encoder에 crop을 입력하기 전에, 50% 확률로 mask 외부 픽셀을 0으로 만든다. embedding이 object에 초점을 맞추도록 마지막 레이어에서 mask 내부 이미지 position으로의 attention을 제한하는 masked attention을 사용한다. 마지막으로 우리의 프롬프트는 출력 token embedding이다. 학습 시에는 먼저 CLIP 기반 프롬프트를 제공한 후, 추가 반복 point 프롬프트를 통해 prediction을 조정한다.
Inference.
추론하는 동안 CLIP text encoder를 수정 없이 사용하여 SAM에 대한 프롬프트를 생성한다. CLIP이 텍스트와 이미지 임베딩을 정렬하므로, 명시적인 text supervision 없이 text 기반 프롬프트를 사용하여 추론할 수 있다.
D.6. Probing the Latent Space of SAM
마지막으로 SAM이 학습한 latent space를 정성적으로 탐구하기 위한 초기 조사를 수행한다. 특히 SAM이 명시적인 semantic supervision 없이도 representation에서 임의의 semantic을 포착할 수 있는지 여부에 관심이 있다. 이를 위해 mask 주위의 이미지 crop에서 SAM의 이미지 embedding을 추출하고 이를 horizontally flip 버전과 binary mask로 이미지 embedding을 곱한 다음, 공간적 위치에 대해 평균화한다. 그림 17에서 query mask와 같은 이미지 내에서 유사한 mask(latent space)의 예를 보인다. 우리는 각 쿼리에 대한 가장 가까운 이웃이 일부, 비록 불완전함에도 형태와 의미론적 유사성을 보인다는 것을 관찰했다. 이러한 결과는 초기 단계에 불과하지만, SAM의 representation이 데이터 라벨링 추가 작업, 데이터셋 내용 이해 또는 downstream task을 위한 feature로 유용할 수 있음을 시사한다.

