

•
RNN의 단점들
◦
길이가 길어질수록 gradient를 잃어버리게 되는 문제가 있고 비슷한 맥락으로 한참 전의 input을 잃어버리는 문제가 있음

•
이 문제를 해결하는게 LSTM과 GRU
◦
하지만 이것도 완벽하게 해결해 주지는 않는다.
•
Seq2Seq 모델은 Many-to-Many 모델의 input과 output이 1:1로 매칭되어야 한다는 한계를 개선한 모델
•
LSTM이 완벽하게 해결해 주지 않기 때문에 최근에는 Attention 모델을 많이 사용함
◦
(이건 다음 강의)
•
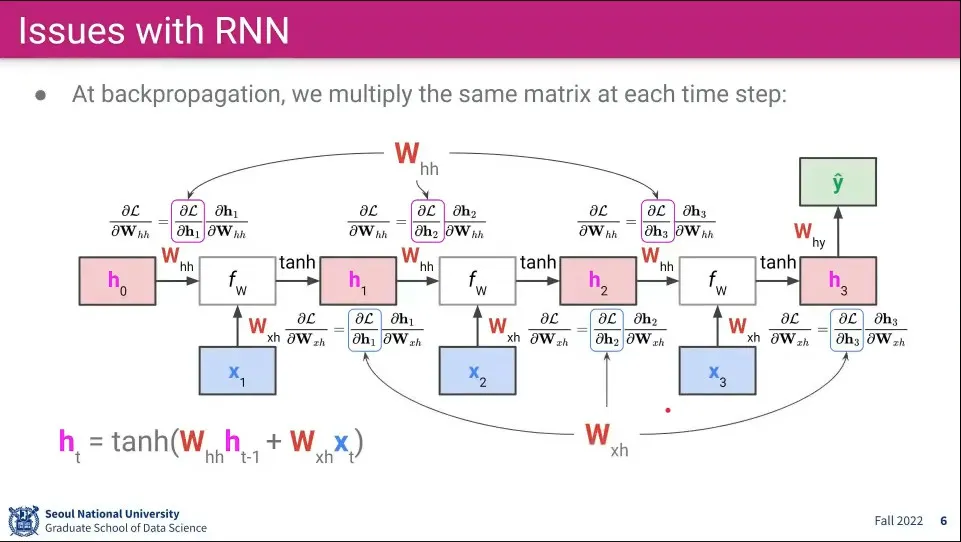
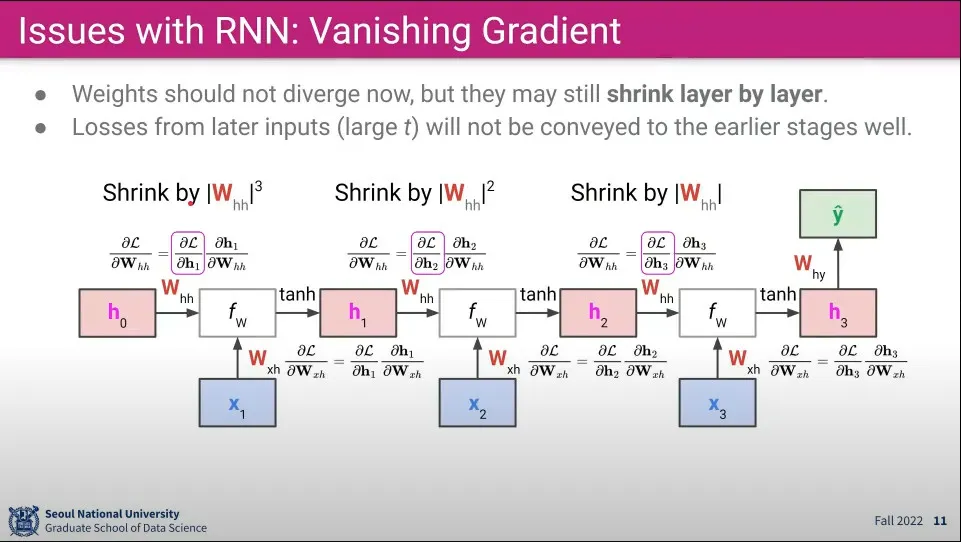
RNN은 그 특성상 시퀀스가 계속 되면서 같은 가중치를 반복해서 사용하기 때문에 Backpropagation 할 때 같은 가중치에 대해 편미분을 계속하다보면 Gradient가 소실되는 문제가 발생함.
•
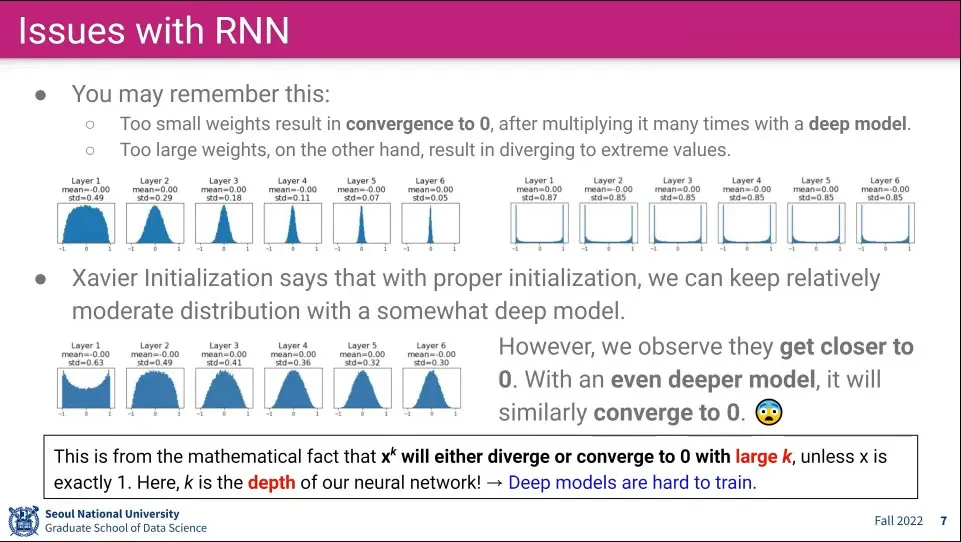
초기 가중치를 너무 작거나 너무 크게 만들면 점점 0 (혹은 1, -1)에 수렴하게 되는 문제
•
이를 해결하기 위해 Xavier Initialization 을 사용할 수 있지만, 이것도 천천히 수렴하게 할 뿐 수렴 자체를 막지는 못함. RNN처럼 긴 시퀀스를 사용하면 결국에는 0으로 수렴하는 문제가 발생하게 됨
•
수학적으로 볼 때 값이 정확히 1이 아닌 이상 1보다 크면 발산하고, 1보다 작으면 0으로 수렴하게 되는 문제가 존재하기 때문에 아주 깊은 (Deep) Layer를 만들기에는 한계가 존재 함.
•
이것은 Neural Network의 Layer가 깊어지는데는 근본적인 한계가 존재함을 보여준다.
•
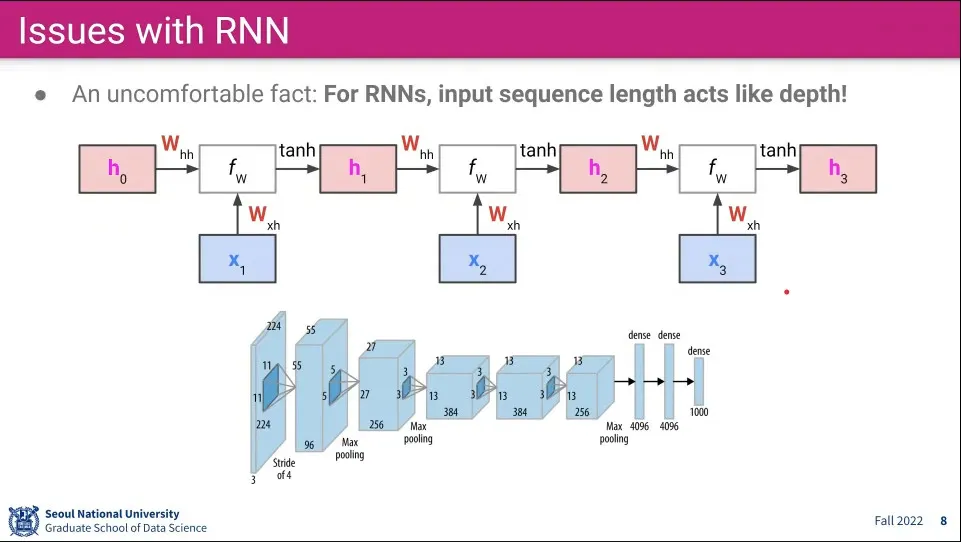
CNN은 적당한 Layer 갯수로 타협할 수 있지만 RNN은 문장이 계속 길어질 수 있기 때문에 그렇게 할 수 없음.
•
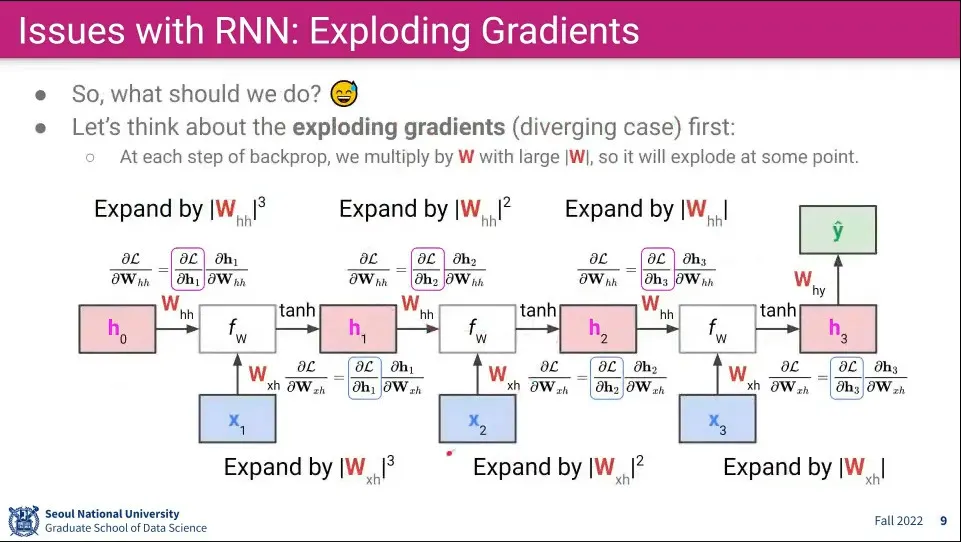
가 1보다 크면 식이 반복되면서 값이 폭발적으로 커지게 됨
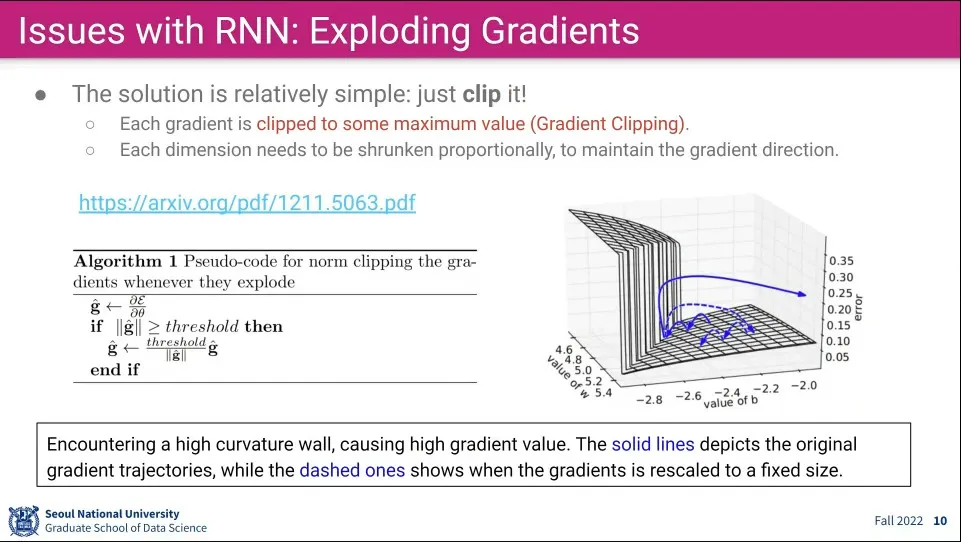
•
이를 해결하기 위해 값이 어느 수준 이상으로 커지면 그냥 설정한 Max로 자름
◦
그런데 이 경우 input이 Vector 형식이라 Vector 내부의 일부 요소에 대해 Cliping하면 Vector의 방향이 바뀌는 문제가 발생함
◦
이 문제를 해결하기 위해 Clipping이 발생하면 나머지 요소들도 같은 scale로 resize 해줌
◦
예컨대 Max가 50인 상태에서 어떤 값이 100이 나오면 해당 값을 50으로 Clip 해주고 Vector 내의 다른 값들은 1/2을 해줌
◦
방향은 유지하고 크기만 줄인다.
•
반면 의 값이 작으면 계산이 반복되면서 값이 소실됨
•
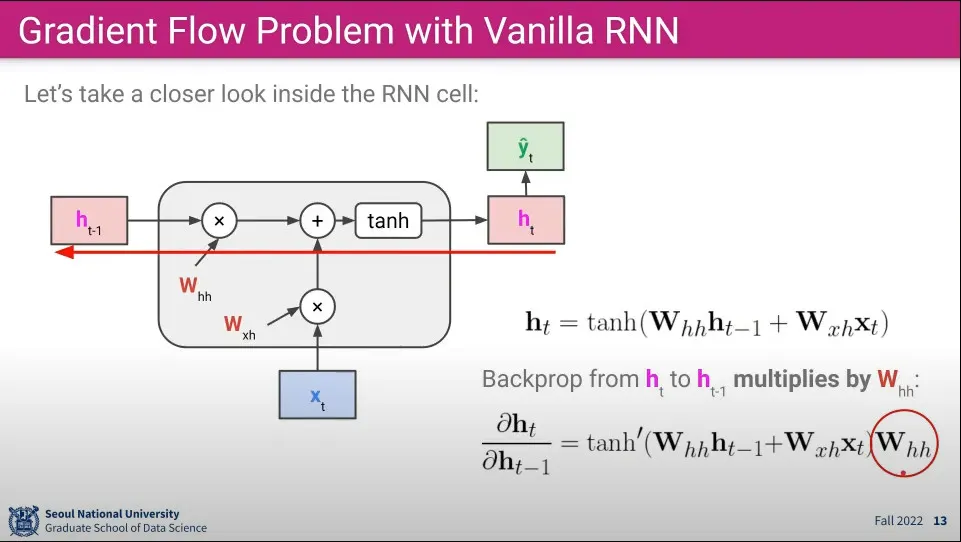
RNN의 역전파에서 계산은 위와 같이 이루어진다.
◦
이전 를 로 편미분하게 됨
•
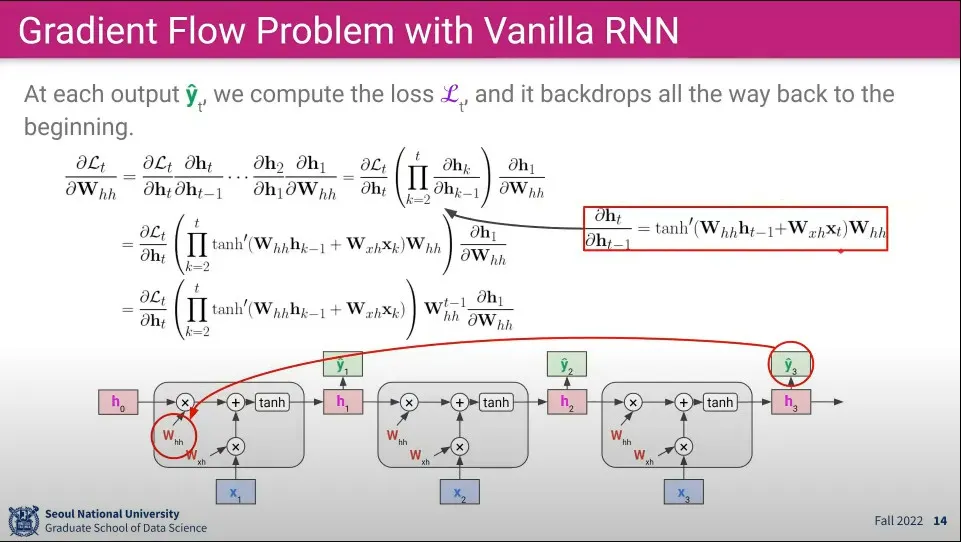
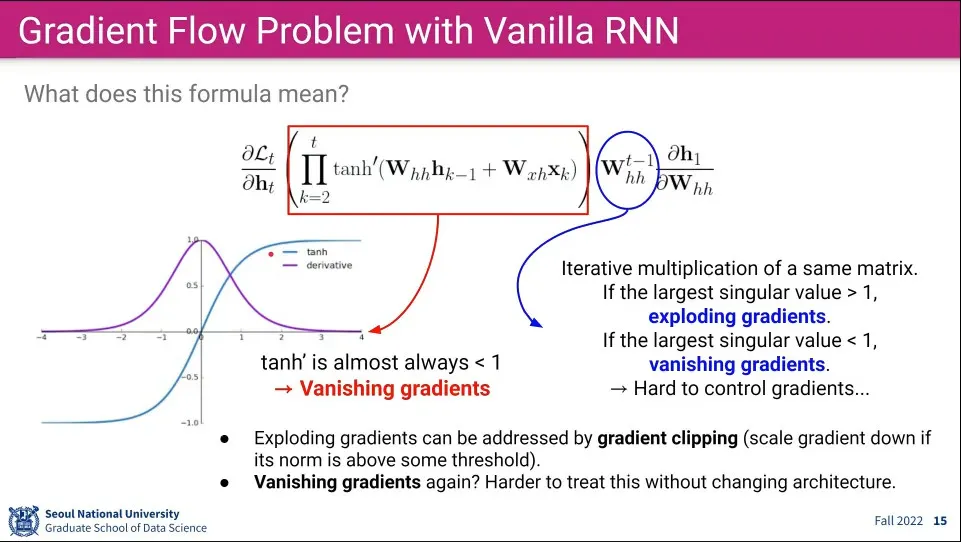
이전식을 풀어 쓰면 위 식과 같다.
◦
계속 같은 를 사용하기 때문에 곱으로 합쳐서 표현할 수 있음
•
위 식을 분해해 보면
◦
탄젠트 하이퍼볼릭은 함수 특성상 1보다 작은 값이 나오는데, 그걸 반복해서 곱하고 있으므로 점점 소실 되게 됨
◦
의 경우 값이 1보다 커지면 폭발하고, 1보다 작으면 소실되게 됨
◦
만일 탄젠트와 가 모두 소실하게 되면 값은 더더욱 빨리 소실되게 되고, Loss 값이 앞으로 전달이 안 되게 됨
•
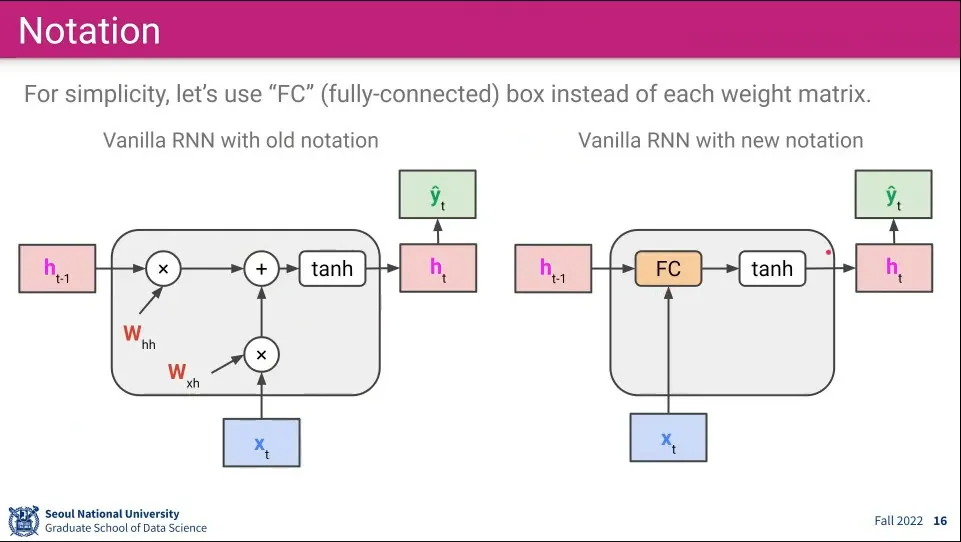
우선 앞서 본 RNN의 구조 표기를 위와 같이 변경함. 두 가중치를 곱해서 더하는 부분을 간편하게 Fully-conntected로 표기
•
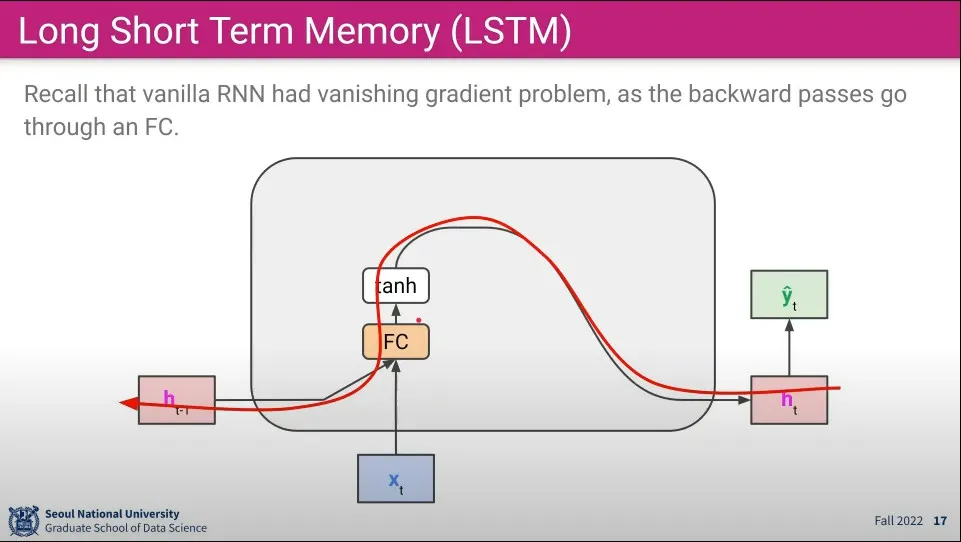
기존 RNN의 backpropagation은 이와 같이 표현할 수 있다.
◦
여기서 Fully-connected 부분에서 가중치가 반복적으로 곱해지면서 점점 소실되는 문제가 발생 됨
•
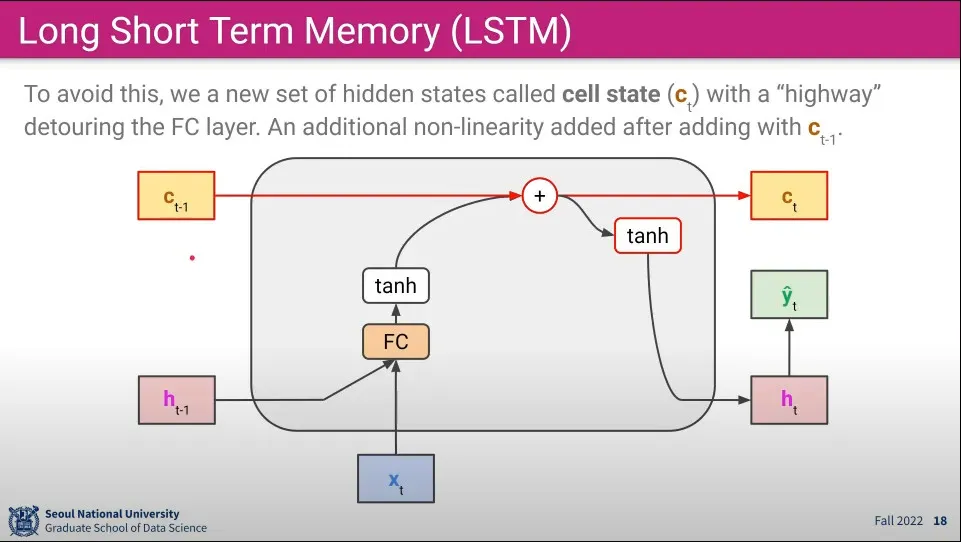
Gradient가 소실되는 문제를 해결하기 위해 기존의 hidden layer 외에 새로운 cell state layer를 만든다.
•
Cell State는 C State라고 부르며 기존의 Hidden Layer와 다른 경로를 갖기 때문에 Gradient가 소실되는 문제를 겪지 않는다.
◦
이 c layer는 오래된 것을 잘 기억할 수 있기 때문에 long term memory라고 부르고
◦
기존의 h layer는 최근의 것을 잘 기억할 수 있기 때문에 short term memory라고 부른다.
◦
그래서 이 둘을 합쳐 Long Short Term Memory(LSTM)이라고 부른다.
•
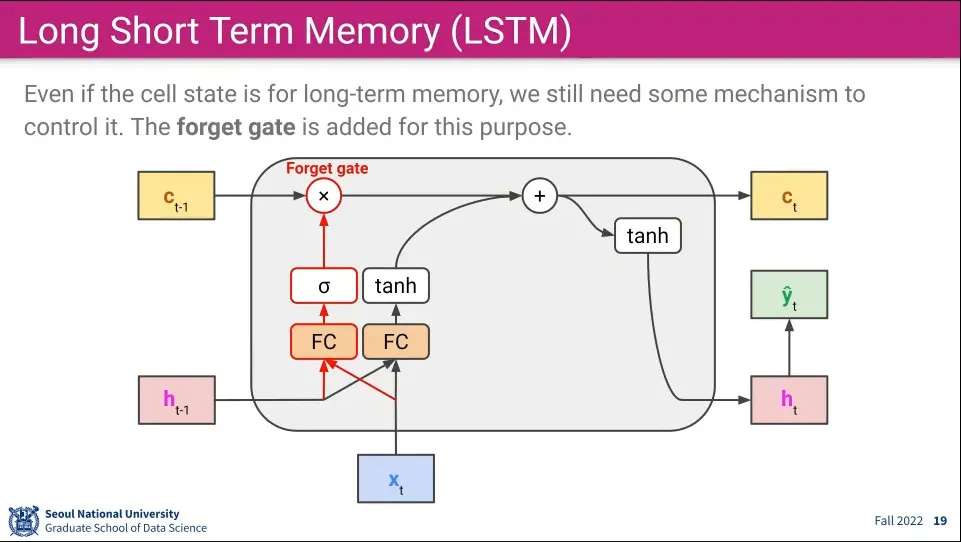
Long Term Memory가 기존 것을 모두 가지고 있으면 학습이 잘 안되기 때문에 몇가지 gate들을 추가해준다.
◦
Cell State는 장기 기억, Hidden State는 단기 기억을 담당한다.
•
우선 forget gate라는 것을 추가해 준다. 연산 순서는 다음과 같다.
1.
새로 들어온 input x와 이전 단기 기억의 값을 fully-connected 한다.
•
(이것은 4번 반복 되므로 실제 코드 상에서는 1번만 연산할 것이다.)
2.
1의 결과를 sigmoid 함수에 넣고 값을 얻는다.
3.
2의 결과를 이전 장기기억에 곱한다.
•
이것은 장기 기억 중에 잊어버릴 필요가 있는 기억은 잊어버리게 한다는 의미를 갖는다.
◦
곱하기를 통해 기존 것을 날림
•
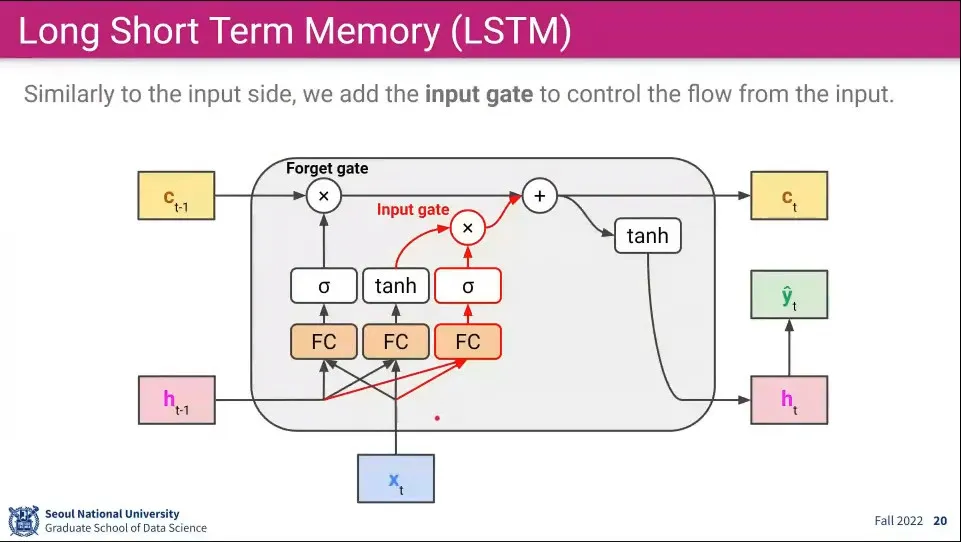
비슷한 컨셉으로 input gate라는 것도 추가해 준다. 연산 순서는 다음과 같다.
1.
새로 들어온 input x와 이전 단기 기억의 값을 fully-connected 한다.
2.
1의 결과를 sigmoid 함수에 넣고 값을 얻는다.
3.
1의 결과를 tanh 함수에 넣고 값을 얻는다.
4.
2와 3의 결과를 곱한다. —이게 Input Gate
5.
Input Gate를 통과한 결과를 Forget Gate를 통과한 결과와 합쳐서 장기 기억을 업데이트 한다.
•
이것은 장기기억에 들어갈 필요가 있는 현재 Input을 장기 기억에 추가해 준다는 의미를 갖는다.
◦
더하기를 통해 기존 것에 추가 함
•
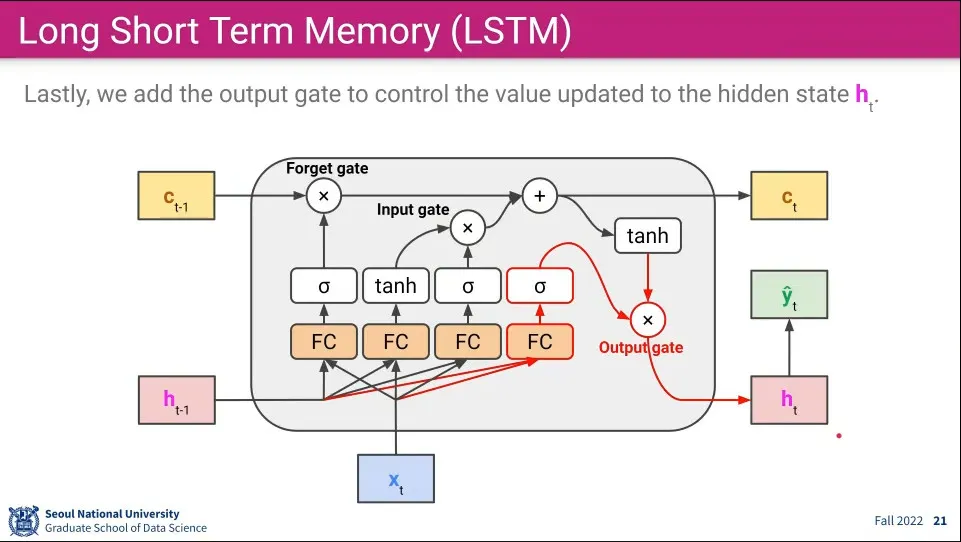
마지막으로 output gate라는 것을 추가한다. 연산 순서는 다음과 같다.
1.
새로 들어온 input x와 이전 단기 기억의 값을 fully-connected 한다.
2.
1의 결과를 sigmoid 함수에 넣고 값을 얻는다.
3.
업데이트 된 장기 기억을 tanh 함수에 넣고 값을 얻는다.
4.
2와 3의 결과를 곱해서 값을 얻는다. —이게 Output Gate
•
이것은 장기 기억의 일부를 단기기억에 반영한다는 의미를 갖는다.
◦
곱하기를 통해 장기 기억을 단기 기억에 반영 함
•
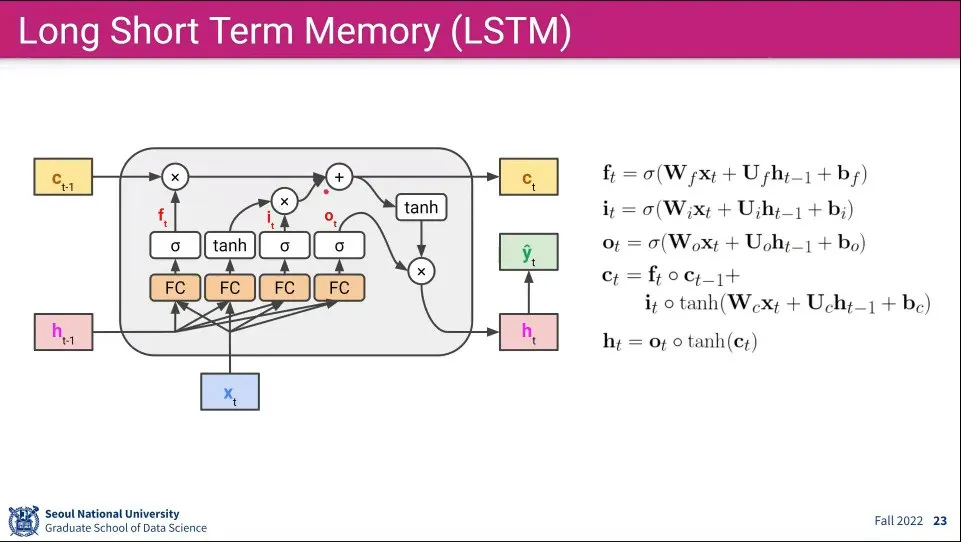
각 게이트와 state에 들어가는 식은 위와 같이 정의된다.
◦
계산하는 것들이 많아져서 표기가 달라짐. input에 붙는 것은 로 h state에 붙는 것은 로 표기됨
•
장기 기억(Cell State)는 forget gate를 통해 데이터를 일부 잃지만, input gate에서 새로운 input을 지속적으로 더해주기만 하기 때문에 기억을 오래 유지할 수 있다.
◦
반면 단기 기억(Hidden State)는 Fully-Connected와 장기 기억과의 곱이 다음 State로 넘어가기 때문에 기억을 잃게 됨. 가장 최근의 Input만 오래 살아 남는다.
◦
기억이라는게 결국 그냥 수치일 뿐이지만

•
Cell state는 long-range information을 vanilla RNN 보다 잘 지켜준다.
•
하지만 완전히 해결해 주지는 못한다. 이것은 Neural Network의 근본적인 문제이다.
◦
LSTM은 Vanishing Gradient 때문에 학습이 제대로 안 되는 것을 어느 정도 완화시켜주기만 한다.
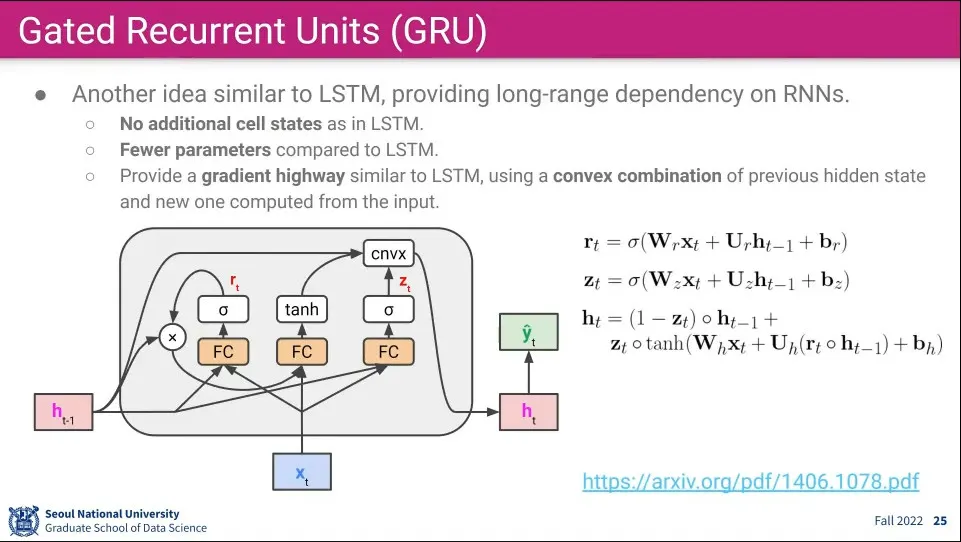
•
LSTM과 비슷한 최신 논문. LSTM에 비해 gate를 1개 덜 쓴다. 2개의 gate가 3개의 gate를 적절히 나눠서 처리 함
◦
LSTM은 상당히 오래 전에 나온 논문이다.
•
실용적으로 사용할 때는 LSTM이나 GRU가 비슷함.

•
PyTorch에서 LSTM을 사용할 때 nn.LSTM을 이용하면 내부적으로 알아서 LSTM으로 만들어서 처리해 준다. 나머지 input은 RNN과 동일함
◦
차이는 output에 hidden state와 cell state 2개가 나온다는 것 뿐

•
RNN을 쓸 때는 LSTM을 사용하는게 기본
◦
GRU도 대안이 될 수 있음
•
기존에는 NLP 쪽 문제에서만 쓰였지만, 이제는 Vision에서도 Transformer 기반으로 사용함
•
Seq2Seq의 대표적인 예제는 문장 번역.
•
문장 번역은 Many-to-Many 형태이므로 Many-to-Many RNN을 시도해 볼 수 있다.
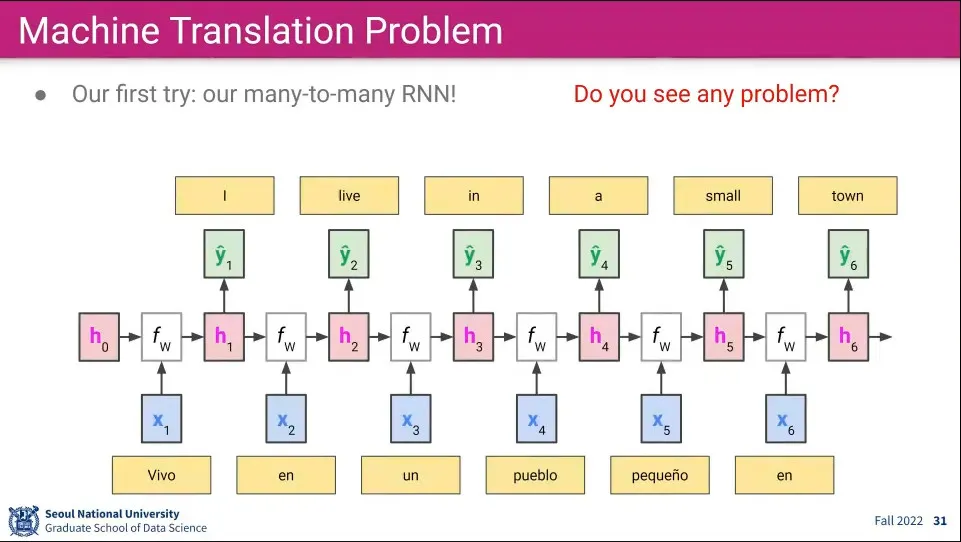
•
Many-to-Many RNN을 쓰면 위와 같이 번역을 할 수 있다.
•
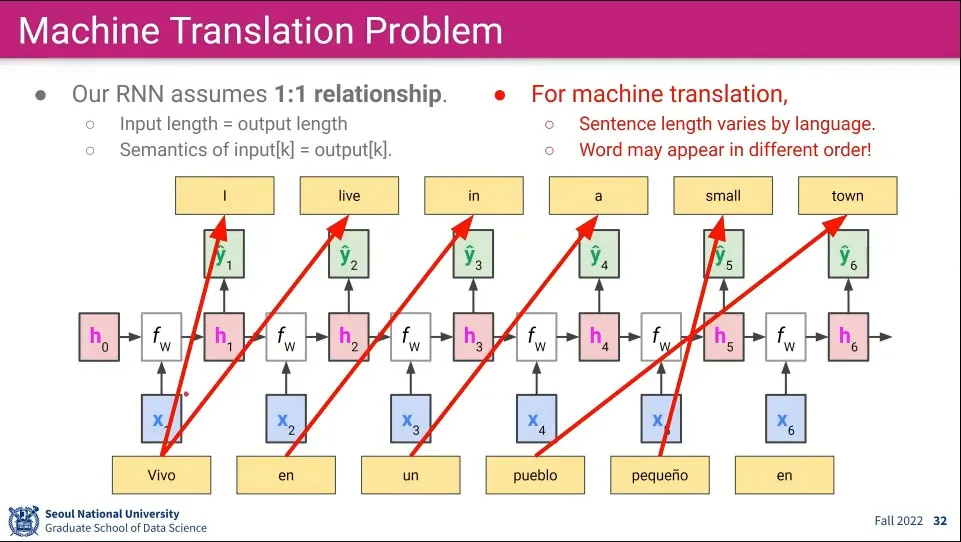
그러나 Many-to-Many는 1:1 관계를 매핑되는 것을 가정하고 있기 때문에 언어 변역으로는 쓸 수 없다. 언어는 같은 의미를 가져도 문장의 길이도 다르고 단어의 순서도 다르기 때문.
•
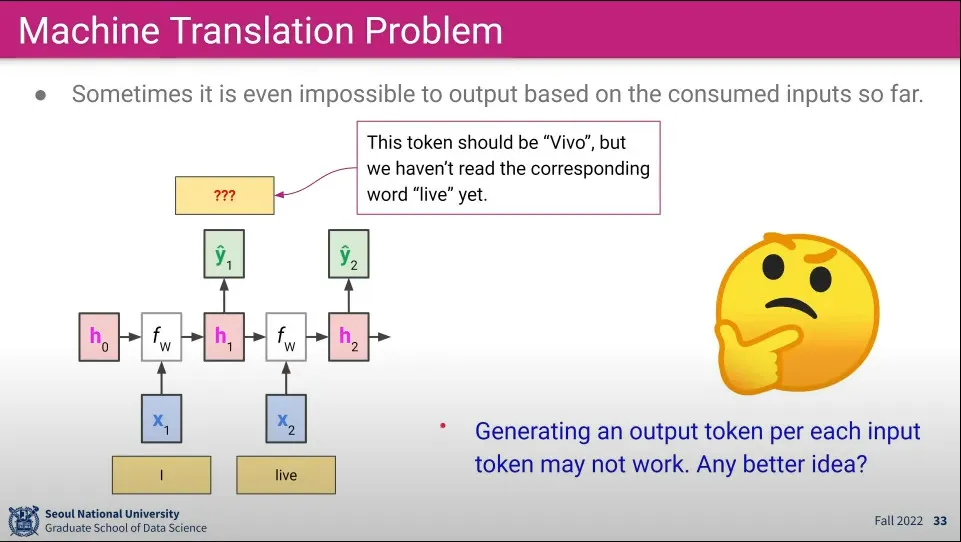
거꾸로 영어를 스페인어로 바꿀 때는 I를 받은 후에 Vivo를 만들 수가 없다.
•
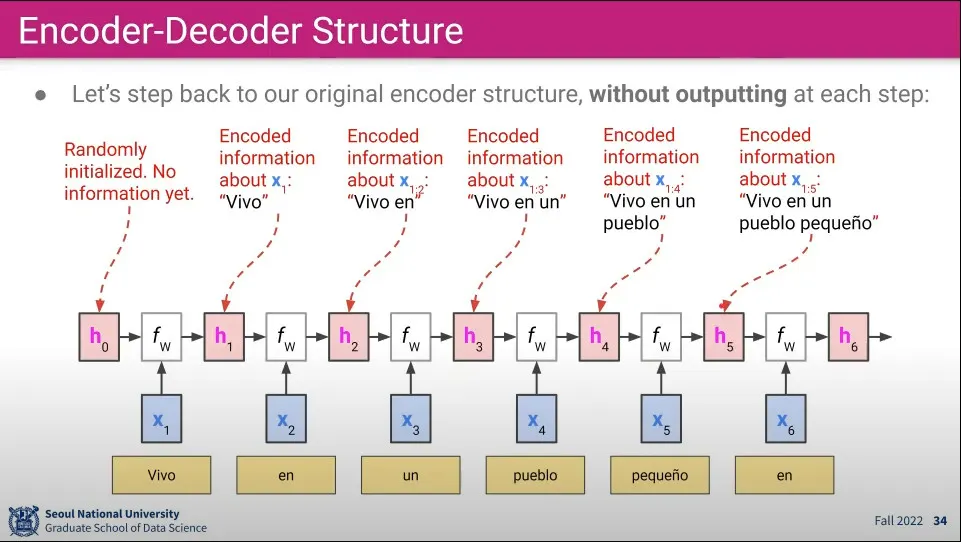
이 문제를 해결하기 위해 Encoder-Decoder를 사용할 수 있다. 이게 바로 Seq2Seq
◦
문장 전체를 차례로 받아 encoding한 후 그걸 다시 decoding 한다.
•
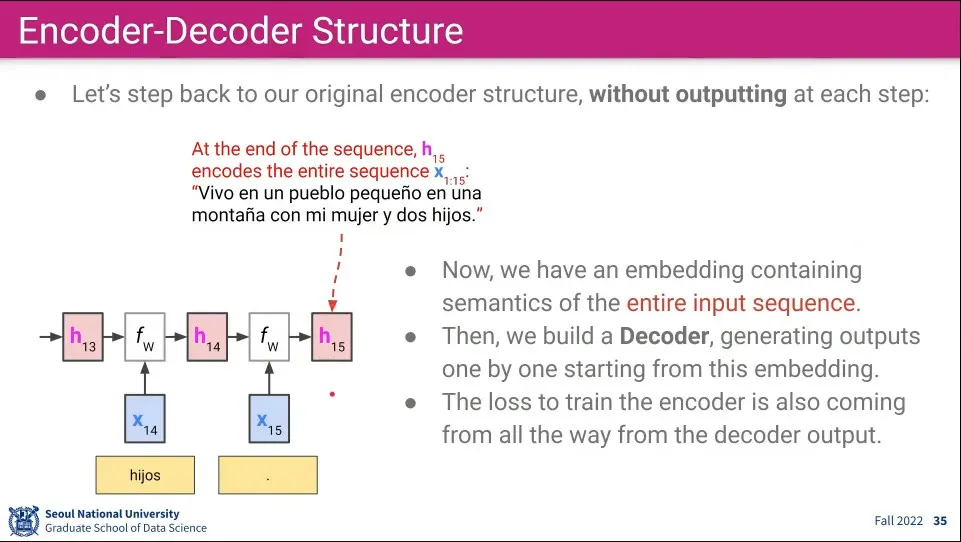
Encoding 단계는 기존의 RNN과 유사하다. 단어 하나하나 들어오는 것을 계속 hidden state에 담아둔다.
1.
최초 는 랜덤 값으로 초기화 한다.
2.
문장의 첫 번째 단어()를 와 계산해서 을 만든다.
3.
문장의 두 번째 단어()를 과 계산해서 를 만든다.
4.
입력 문장이 끝날 때까지 2-3을 반복한다.
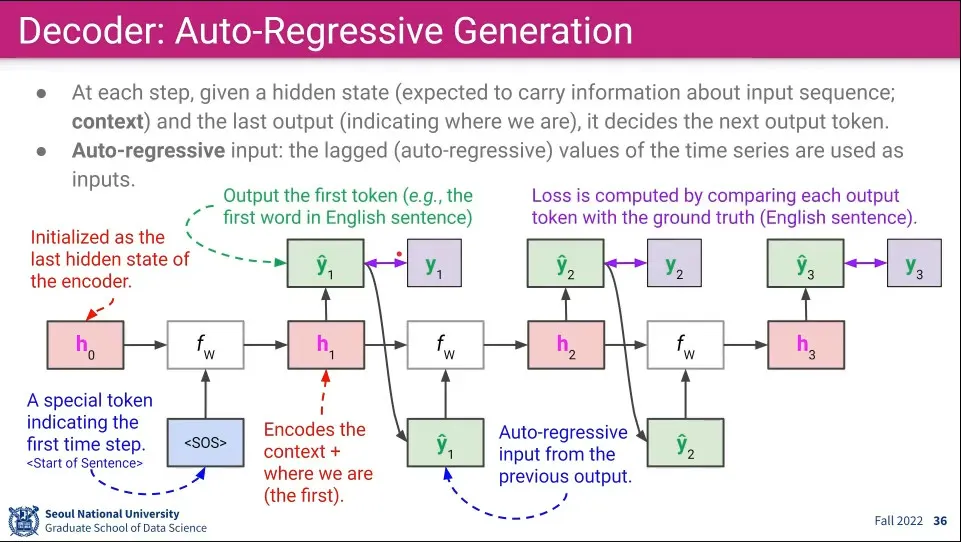
•
모든 문장을 담은 후에 Decoding 단계가 시작된다. Decoding 단계는 many-to-many와 비슷하다.
1.
최초 encoding된 것을 이용한 에서 시작하고, 첫 단계를 위한 sos(start of sentence) 토큰으로 시작한다.
2.
과 sos를 이용해서 을 계산하고 거기서 첫 번째 output()을 출력한다. 이때 에는 첫 번째 단어 위치가 포함되어 저장된다.
3.
그렇게 출력된 을 다시 input으로 넣어서 를 계산하고 거기서 다시 를 뽑는다.
4.
문장이 끝날 때까지 2-3을 반복한다.
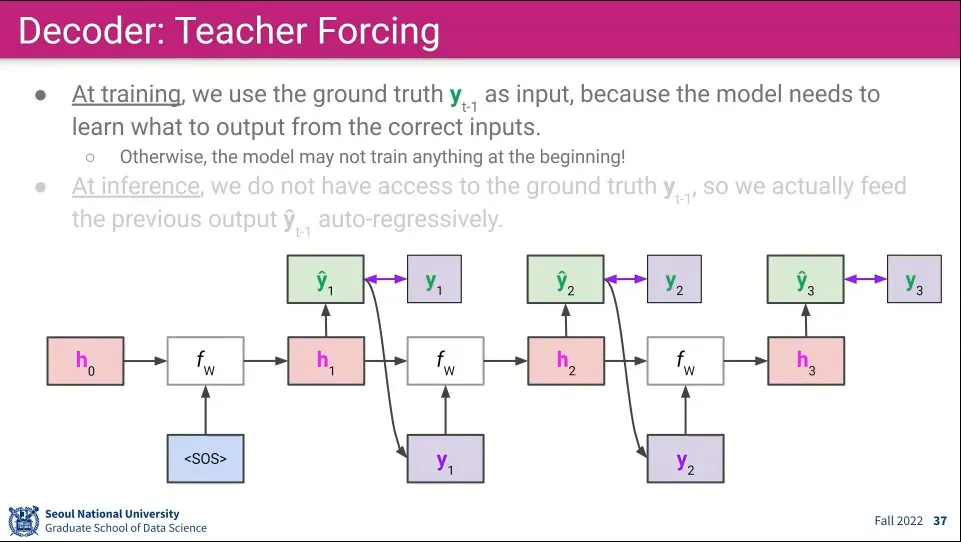
•
Decoder의 학습은 Teacher Forcing 이라고 한다.
◦
학습 단계에서 Decoder 특성상 생성해 내기 때문에 앞의 Input이 잘못된 것이 들어가면 이후 예측은 무의미한 것이 된다.
◦
따라서 모델의 Output은 정답과 비교해서 학습하는데만 사용하고 다음 단계의 Input으로는 이전 단계의 정답을 사용한다.
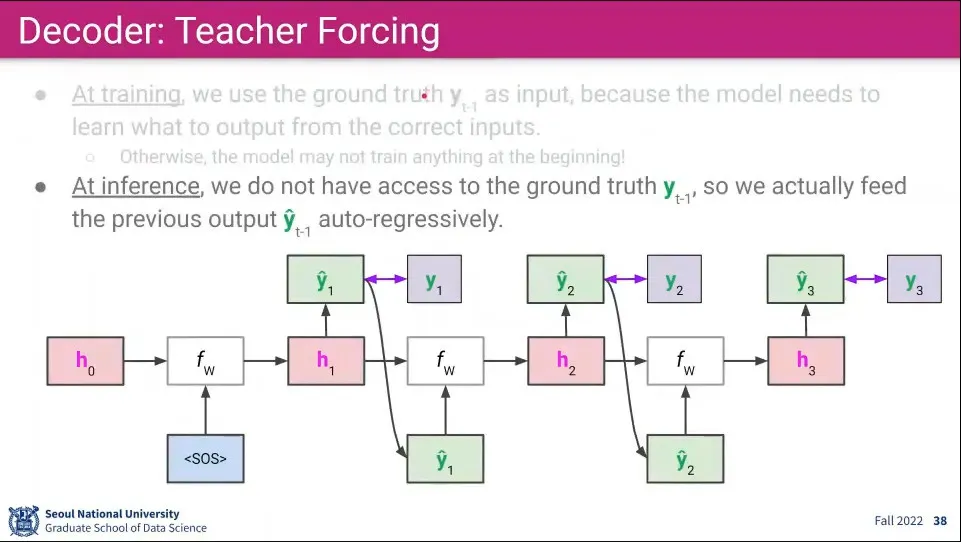
•
물론 Inference 할 때는 정답이 아니라 모델이 만들어낸 Output을 사용한다.
•
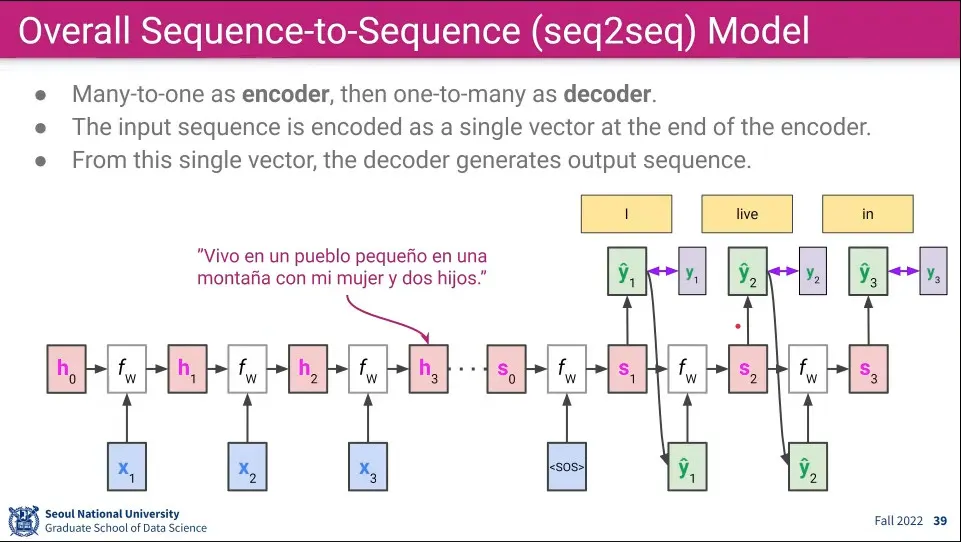
Seq2Seq 모델은 Encoder와 Decoder를 연결해서 사용한다.
◦
이때 Encoder는 Many-to-One의 구조이고, Decoder는 One-to-Many 구조이다.
◦
Encoder의 output이 Decoder의 input으로 사용 된다.
•
input으로 들어가는 는 Embedding 된 Vector를 사용하는 반면 결과로 나오는 는 실제 단어가 나온다.
•
Decoding이 끝나는 것을 알기 위해 마침표(.)나 end-of-sentence token을 이용한다.
•
(backpropagation은 어떻게 되는거야? decoder의 output에서 시작해서 encoder까지 학습이 되나? 아니면 encoder, decoder는 별개로 학습 되나?)

•
Encoder 구현 예 -여기서는 LSTM을 이용했음
•
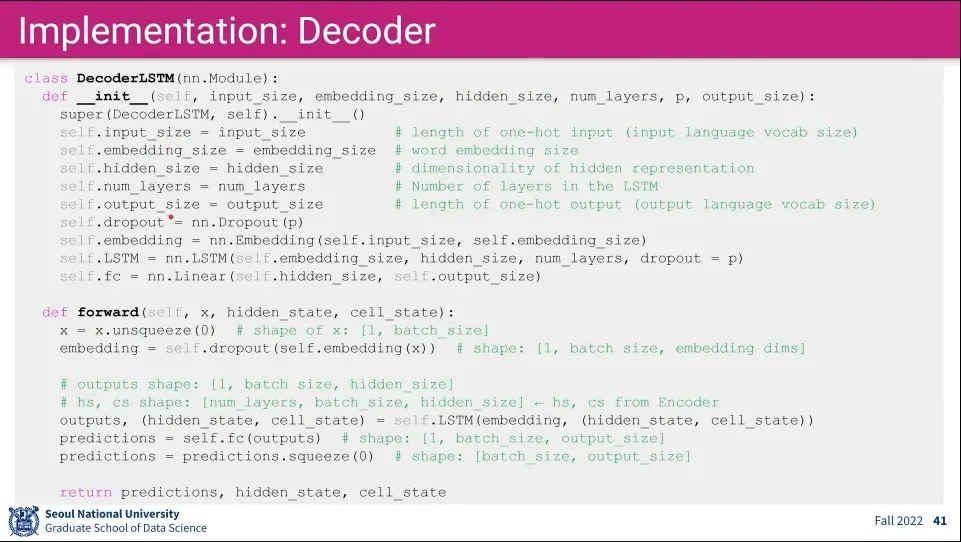
Decoder 구현 예 -여기서도 LSTM을 사용했음
•
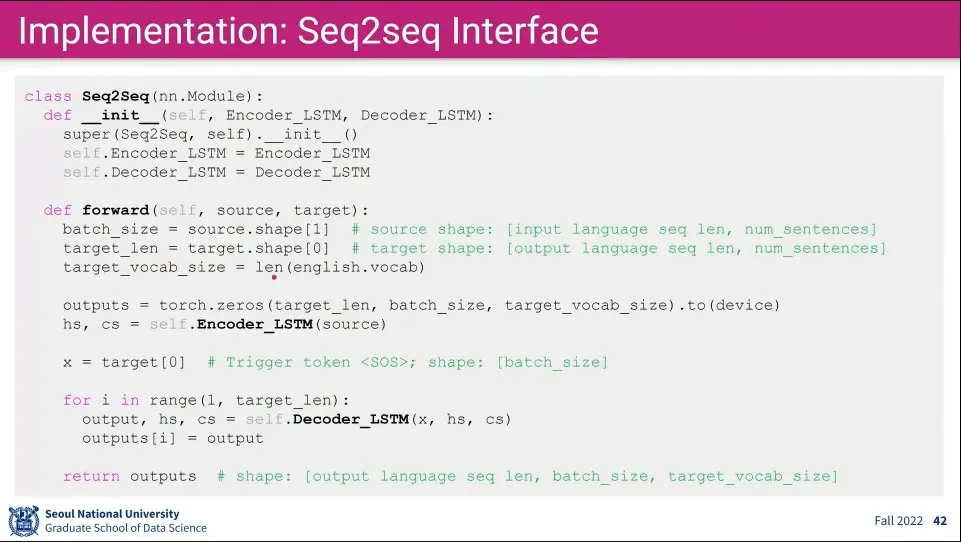
Encoder-Decoder Interface 구현 예
◦
Encoding은 Source를 한 번에 넣고, Decoding은 반복문을 돈다.
