
지금까지 GAN, VAE, Flow-Based 모델이라는 3가지 생성 모델에 관해 작성했다. 그것들은 높은 품질 샘플을 생성하는데 훌륭한 성공을 보였지만 각각 그 자체로 한계가 있다. GAN은 적대적 학습 특성 때문에 잠재적으로 불안정안 학습과 생성의 다양성이 적다. VAE는 surrogate loss에 의존하고 Flow 모델은 가역 변환을 구성하는 특수 아키텍쳐를 사용해야 한다.
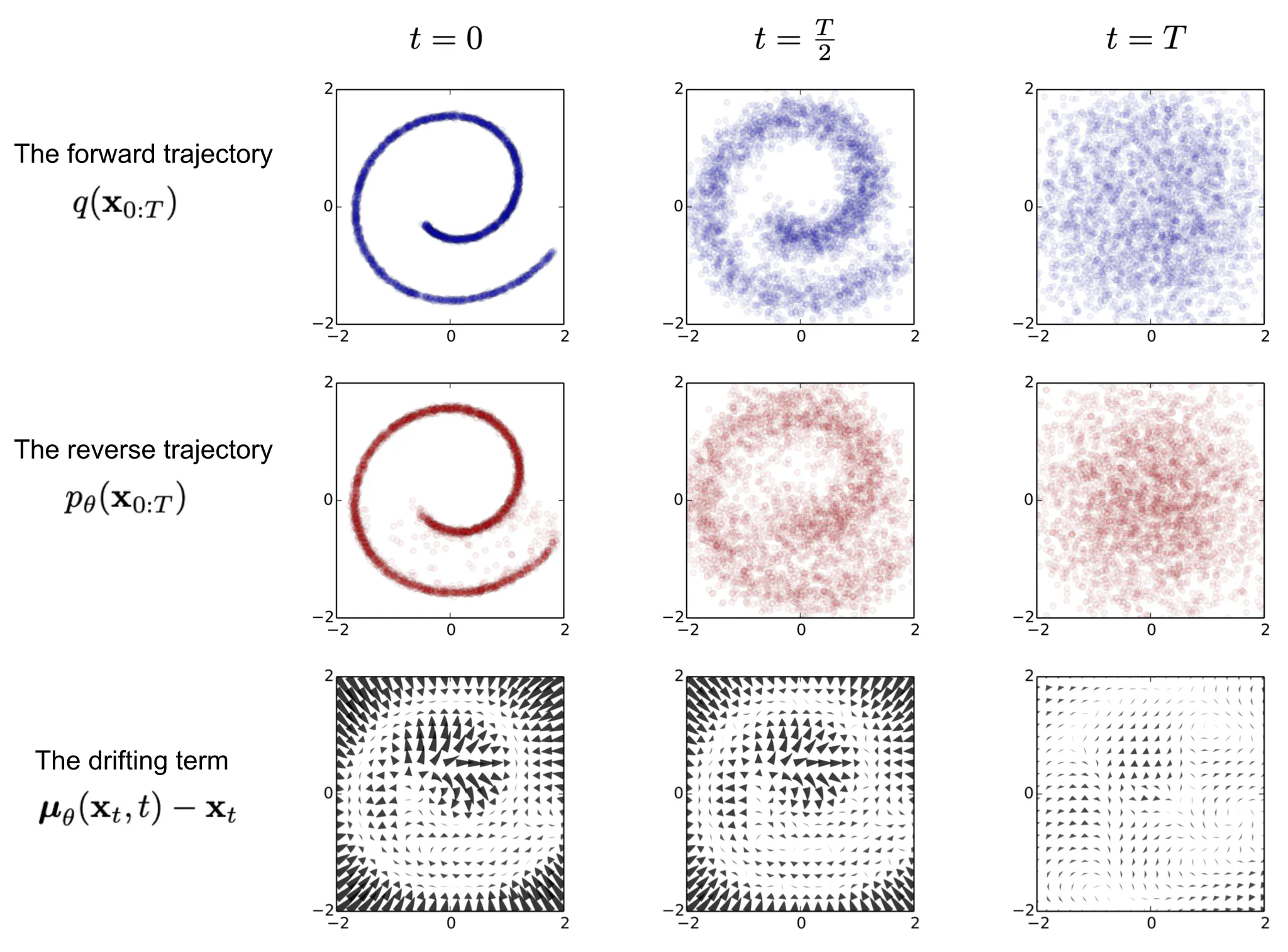
Diffusion 모델은 non-equilibrium thermodynamics(비평형 열역학)에 의해 영감을 받았다. 그들은 diffusion step의 Markov chain을 정의하여 데이터에 랜덤 노이즈를 천천히 추가한 다음 diffusion 절차를 역으로 학습하여 노이즈에서 원하는 데이터 샘플을 구성한다. VAE나 flow 모델과 다르게 diffusion model은 고정된 절차로 학습되고 잠재 변수는 높은 차원을 갖는다(원본 데이터와 같은)

What are Diffusion Models
여러 diffusion-based 생성 모델이 유사한 아이디어 아래 제안되었다. ‘diffusion probabilistic model’, ‘noise-conditioned score network(NCSN)’, ‘denoising diffusion probabilistic model(DDPM)’
Forward diffusion process
실제 데이터 분포 에서 샘플링된 데이터 포인트가 주어지면, 단계로 샘플에 소량의 가우스 노이즈를 추가하여 일련의 노이즈 샘플 를 생성하는 forward diffusion process를 정의한다. step size는 분산 스케쥴 에 의해 제어됩니다.
step 가 커짐에 따라 데이터 샘플 은 점차 구별가능한 특징을 잃게 됩니다. 결국 가 되면 는 isotropic Gaussian 분포와 동일해집니다.
위 프로세스의 좋은 특성은 reparameterization trick을 사용하여 닫힌 형식으로 모든 임의의 time step 에서 를 샘플링할 수 있다는 것이다. 와 라 하자.
(*) 분산이 다른 두 가우시안, 과 을 병합하면 새로운 분포는 이 된다는 것을 떠올려라. 여기서 병합된 표준 편차는 이다.
일반적으로 샘플의 노이즈거 커지면 더 큰 update step을 수행할 수 있다. 따라서 이고 그러므로 이다.
Connection with stochastic gradient Langevin dynamics
Langevin Dynamics은 molecular systems(분자 시스템)을 통계적으로 모델링하기 위해 개발된 물리학의 개념입니다. stochastic gradient descent와 결합된 stochastic gradient Langevin dynamics은 Markov chain 업데이트에서 gradient 만 사용하여 확률 밀도 에서 샘플을 생성할 수 있다.
여기서 는 step size이다. 일 때, 는 실제 확률 밀도 와 같아진다.
표준 SGD과 비교하여 stochastic gradient Langevin dynamics는 가우시안 노이즈를 파라미터 업데이트에 주입하여 local minima로 붕괴하는 것을 피한다.
Reverse diffusion process
위의 절차를 반전하고 에서 샘플을 추출할 수 있다면 가우시안 노이즈 입력 에서 실제 샘플을 재생성할 수 있다. 만일 가 충분히 작으면 도 가우시안이 된다는 점에 유의하라.
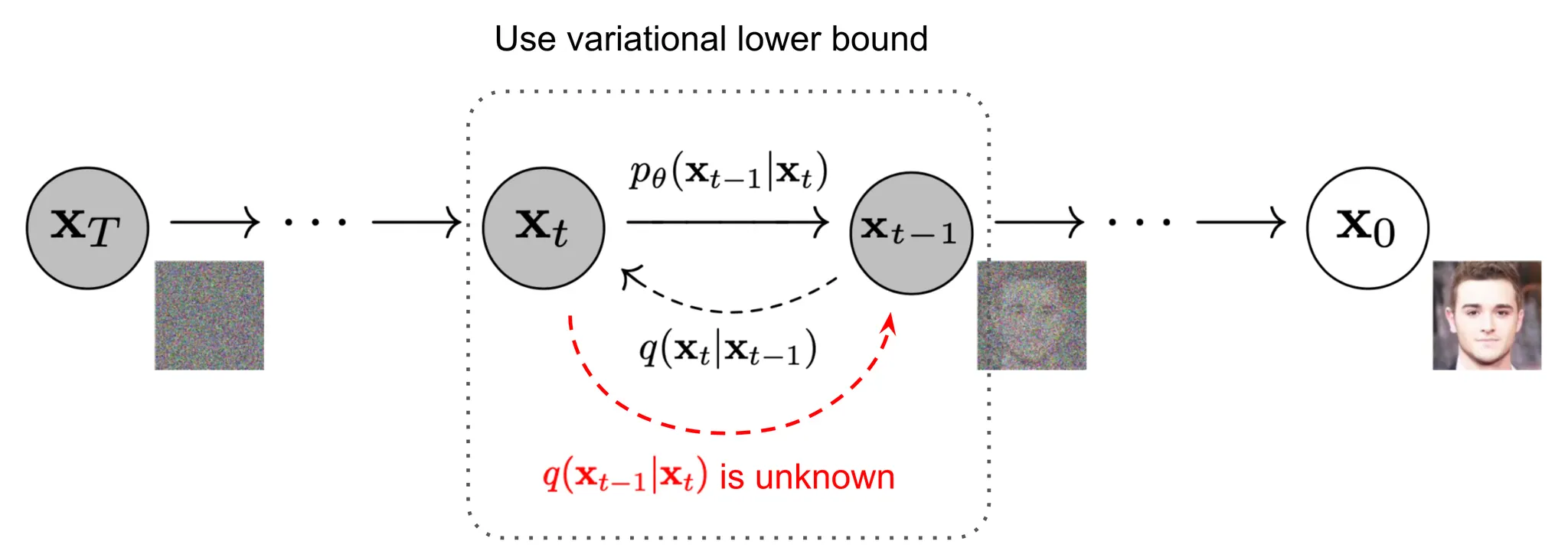
불행히 전체 데이터셋을 사용해야 하기 때문에 를 쉽게 추정할 수 없다. 그러므로 reverse diffusion 프로세스를 실행하기 위해 이 조건부 확률을 근사하도록 모델 을 학습해야 한다.
에 조건화될 때 reverse 조건부 확률이 다루기 쉬워진다는 점에 주목할 가치가 있다.
베이지안 룰을 사용해서
여기서 는 를 포함하지 않는 함수이고 자세한 설명은 생략합니다. 표준 가우스 밀도 함수에 따라 평균과 분산을 다음과 같이 파라미터화 할 수 있습니다 (와 ):
nice property 덕분에 을 표현할 수 있고 위의 방정식에 연결하여 다음과 같은 결과를 얻을 수 있습니다:
그림 2에서 볼 수 있듯이 이러한 설정은 VAE와 매우 유사하고 따라서 variational lower bound(VLB)를 사용하여 negative log-likelihood를 최적화할 수 있다.
Jensen의 부등식을 사용하여 동일한 결과를 얻는 것도 간단하다. 학습 목적으로 cross entropy를 최소화하기를 원한다고 가정하자.
방정식의 각 항을 해석적으로 계산할 수 있도록 변환하기 위해 목적을 몇몇 KL divergence와 entropy 항의 결합으로 재작성할 수 있다.(자세한 단계별 프로세스는 부록 B의 Sohl-Dickstein et al., 2015 참조):
variational lower bound 손실에서 각 성분을 개별적으로 라벨링 해보자.
의 모든 KL 항( 제외)은 두 가우시안 분포를 비교하므로 닫힌 형식으로 계산할 수 있다. 가 학습 가능한 파라미터를 갖지 않고 가 가우시안 노이즈이므로 는 상수이고 학습하는 동안 무시할 수 있다. Ho et al. 2020은 에서 유도된 분리 이산 디코더를 사용하여 을 모델링합니다. .
Parameterization of for Training Loss
reverse diffusion 프로세스 에서 조건화된 확률 분포를 근사하도록 신경망을 학습해야 한다는 것을 떠올려라. 을 훈련하여 를 예측하기를 원한다.
훈련 시간에 를 입력으로 사용할 수 있으므로 대신 가우시안 노이즈 항을 재파라미터화 하여 시간 단계 에서 입력 로부터 를 예측하도록 할 수 있다.
손실 항 는 에서 차이를 최소화 하도록 파라미터화됩니다. :
Simplification
Ho 등(2020)은 가중치 항을 무시하는 단순화된 목적의 diffusion 모델을 학습하는 것이 더 낫다는 것을 경험적으로 발견했다.
최종 단순한 목적은 다음과 같다.
여기서 는 에 의존하지 않는 상수입니다. .

Connection with noise-conditioned score networks (NCSN)
Song & Ermon(2019)은 score-based 생성 모델링 방법을 제안했다. 여기서 샘플은 score matching을 사용하여 추정된 데이터 분포의 gradient를 사용하는 Langevin dynamics를 통해 생성된다. 각 샘플 의 밀도 확률의 score는 그것의 gradient 로 정의된다. score 네트워크 는 을 추정하도록 학습된다.
이것을 딥러닝 설정에서 고차원 데이터로 확장하기 위해 그들은 denoising score matching(Vincent, 2011)이나 sliced score matching(랜덤 projection을 사용. Song et al. 2019)을 사용할 것을 제안했다. Denoising score matching은 미리 지정된 작은 노이즈를 에 추가하고 score matching을 사용하여 을 추정한다.
Langevin dynamics가 반복적인 절차에서 score 만 사용하여 확률 밀도 분포에서 데이터 포인트를 샘플링할 수 있다는 점을 떠올려라.
그러나 manifold 가설에 따르면, 관찰된 데이터가 임의의 고차원으로 보이더라도 데이터의 대부분은 저차원 manifold에 집중될 것으로 예상된다. 이는 데이터 포인트가 전체 공간을 커버할 수 없기 때문에 score 추정에 부정적인 영향을 미친다. 데이터 밀도가 낮은 region에서 score 추정은 덜 신뢰할만 하다. 교란된 데이터 분포가 커버하는 전체 공간 을 만들기 위해 작은 가우시안 노이즈를 추가한 후에 score 추정 네트워크의 학습은 더 안정적이 된다. Song & Ermon (2019)은 다양한 수준의 잡음으로 데이터를 교란하고 노이즈 조건화된 score 네트워크를 학습하여 다양한 노이즈 레벨에서 모든 교란된 데이터의 score를 결합으로 추정함으로써 이를 개선했다.
노이즈 레벨을 증가시키는 스케쥴은 forward diffusion 프로세스과 유사하다. diffusion 프로세스 주석을 사용하면 score를 근사할 수 있다. . 가우시안 분포 가 주어지면 그것의 밀도 함수의 log의 도함수를 로 작성할 수 있다. 여기서 . 임을 떠올려라. 그러므로
Parameterization of
Ho et al. (2020)에서 forward 분산은 선형으로 증가하는 상수의 시퀀스로 설정된다. 에서 까지이다. 이것은 사이로 정규화된 이미지 픽셀 값에 비해 상대적으로 작다. 그들의 실험에서 Diffusion 모델은 높은 품질의 샘플을 보였지만 여전히 다른 생성 모델만큼 경쟁력 있는 모델 log-likelihood를 달성하지 못했다.
Nichol & Dhariwal(2021)은 확산 모델이 더 낮은 NLL을 얻는 데 도움이 되는 몇 가지 개선 기법을 제안했다. 개선 사항 중 하나는 cosine 기반 분산 스케줄을 사용하는 것입니다. 스케줄링 함수의 선택은 학습 프로세스의 중간에 선형에 가깝게 하락하고 과 근처에서 미묘한 변화를 제공하는 한 임의적일 수 있다.
여기서 작은 오프셋 는 에 가까울 때 가 너무 작아지는 것을 방지하기 위한 것입니다. .
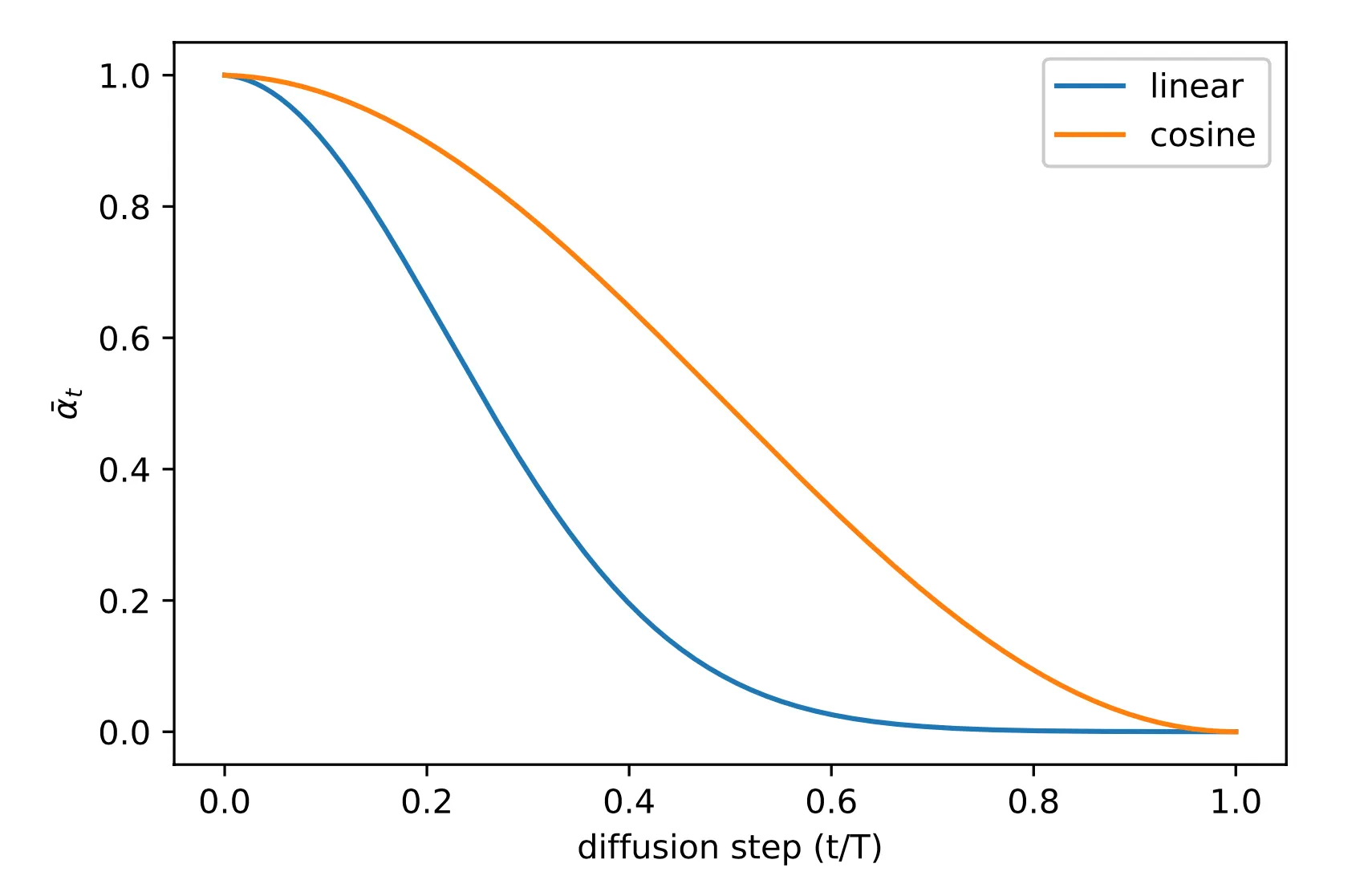
[그림] 훈련 중 의 선형 기반 스케줄링과 코사인 기반 스케줄링 비교. (이미지 출처: Nichol & Dhariwal, 2021)
Parameterization of reverse process variance
Ho et al. (2020)은 를 학습 가능하게 하는 대신 상수로 고정하고 를 설정했다. 여기서 는 학습되지 않고 또는 로 설정한다. 대각 분산 를 학습하는 것이 학습이 불안정하게 하고 샘플 품질이 저하된다는 사실을 발견했기 때문이다.
Nichol & Dhariwal (2021)은 혼합 벡터 를 예측하는 모델을 통해 과 사이의 보간으로 를 학습할 것을 제안했습니다:
그러나 단순 목적 은 에 종속되지 않습니다. 종속성을 추가하기 위해 그들은 혼합 목적 을 구성했다. 여기서 는 작고 항에서 에 대한 gradient를 중지하여 가 의 학습만 유도하도록 했다. 경험적으로 그들은 noisy gradient 때문에 를 최적화하는 것이 꽤 어렵다는 것을 관찰했고, 따라서 importance sampling을 통해 의 time-averaging smoothed 버전을 사용할 것을 제안했다.
Conditioned Generation
이미지넷 데이터셋 같은 조건화 정보를 갖는 이미지에 생성 모델을 학습할 때는 클래스 라벨이나 설명 텍스트의 조각에 조건화된 샘플을 생성하는 것이 일반적이다.
Classifier Guided Diffusion
클래스 정보를 diffusion 프로세스에 명시적으로 통합하기 위해 Dhariwal & Nichol(2021)은 noisy 이미지 에 분류기 를 학습하고 gradient 를 사용하여 노이즈 예측을 변경하여 조건 정보 (예: 목표 클래스 라벨)로 diffusion 샘플링 프로세스를 가이드한다.
과 결합 분포 에 대한 score 함수를 다음과 같이 작성할 수 있다는 것을 떠올려라.
따라서 새로운 classifier-guided 예측기 는 다음과 같은 형식을 취한다.
classifier guidance의 강도를 제어하기 위해 델타 부분에 가중치 를 추가할 수 있다.
결과 ablated diffusion model(ADM)과 추가로 classifier guidance(ADM-G)를 갖는 버전은 최신 성능 생성 모델(예: BigGAN) 보다 나은 결과를 달성했다.

추가적으로 U-Net 아키텍쳐에 대해 일부 수정을 통해 Dhariwal & Nichol(2021)은 diffusion model을 사용하는 GAN보다 나은 성능을 보였다. 아키텍쳐 수정에는 더 큰 모델 깊이와 너비, 더 많은 attention head, multi-resolution attention, up/down sampling에 대한 BigGAN residual block, 에 의한 residual connection rescale과 adaptive group normalization(AdaGN)이 포함된다.
Classifier-Free Guidance
독립적인 classifier 없이도 conditional과 unconditional diffusion 모델에서 score를 통합하여 조건부 diffusion step을 실행하는 것이 가능하다. (Ho & Salimans, 2021). score 추정기 을 통해 파라미터화 된 unconditional denoising diffusion 모델 와 를 통해 파라미터화 된 conditional 모델 를 예로 들어보자. 이 두 모델은 단일 신경망을 통해 학습될 수 있다. 정확히 말하면 conditional diffusion 모델 는 paired 데이터 에 대해 학습된다. 여기서 조건 정보 는 주기적으로 랜덤으로 폐기되어 모델이 unconditionally 이미지를 생성하는 방법도 알게 한다. 즉
암시적 분류기의 gradient는 conditional과 unconditional score 추정기를 사용하여 표현할 수 있다. classifier-guided 수정된 score에 연결하면 score는 별도의 classifier에 대한 의존성을 포함하지 않는다.
그들의 실험에 따르면 classifier-free guidance가 FID(합성과 생성 이미지 사이의 구별)와 IS(품질과 다양성) 사이의 좋은 균형을 달성함하는 것으로 나타났다.
guided diffusion model인 GLIDE(Nichol, Dhariwal & Ramesh 외. 2022)에서 CLIP guidance와 classifier-free guidance에 대한 두 가지 guiding 전략을 모두 살펴본 결과 후자가 더 선호된다는 것을 발견했매
Speed up Diffusion Models
가 1에서 수천 단계에 이를 수 있기 때문에 reverse diffusion 프로세스의 Markov 체인에 의해 DDPM에서 샘플을 생성하는 것은 매우 느리다. 송 등의(2020) 한 데이터 포인트: 예컨대 DDPM에서 32x32 크기의 이미지 5만개를 샘플링하는데는 약 20시간이 걸리지만, Nvidia 2080 Ti GPU에서 GAN은 1분도 걸리지 않는다.
Fewer Sampling Steps & Distillation
한 가지 단순한 방법은 프로세스를 에서 step으로 줄이기 위해 단계마다 샘플링 업데이트를 취하는 strided 샘플링 스케쥴(Nichol & Dhariwal, 2021)을 수행하는 것이다. 생성을 위한 새로운 샘플링 스케쥴은 이다. 여기서 이고
또 다른 접근에 대해 nice property를 따라 원하는 표준 편차 에 의해 파라미터화 되도록 를 재작성해 보겠다.
여기서 모델 는 에서 를 예측한다.
을 떠올려라. 따라서 다음이 성립한다.
샘플링 확률성을 제어하기 위한 를 하이퍼파라미터로 조정할 수 있도록 라 한다. 인 특수한 경우에 샘플링 프로세스를 결정론적이 된다. 이런 모델을 denoising diffusion implicit model(DDIM; Song et al, 2020)이라 한다. DDIM은 동일한 marginal noise 분포를 갖지만 노이즈를 원본 데이터 샘플에 결정론적으로 다시 매핑한다.
생성하는 동안 전체 체인 를 따르는 것이 아니라 단계의 부분 집합을 따른다. 를 이 가속화된 궤적에서 2단계로 표기하자. DDIM 업데이트 단계는 다음과 같다.
diffusion step을 사용하여 모델을 학습한 실험에서, 가 작을 때 DDIM()이 가장 높은 품질의 샘플을 생성할 수 있지만 DDPM()의 성능은 더 나쁜 것을 관찰했다. full reverse Markov diffusion step()을 수행할 수 있을 때 DDPM이 더 나은 수행을 했다. DDIM을 사용하면 임의의 수의 forward step까지 diffusion 모델을 수행할 수 있지만 생성 프로세스의 step의 부분집합에서만 샘플링할 수 있다.
DDPM과 비교하여 DDIM은 다음이 가능하다.
1.
훨씬 적은 수의 단계로 더 높은 품질의 샘플을 생성할 수 있다.
2.
생성 프로세스가 결정론적이기 때문에 '일관성' 속성을 가지며, 이는 동일한 잠재 변수에 조건화 된 여러 샘플이 유사한 상위 수준의 특징을 가져야 함을 의미한다.
3.
일관성 때문에 DDIM은 잠재 변수에서 semantically 의미 있는 보간을 수행할 수 있다.
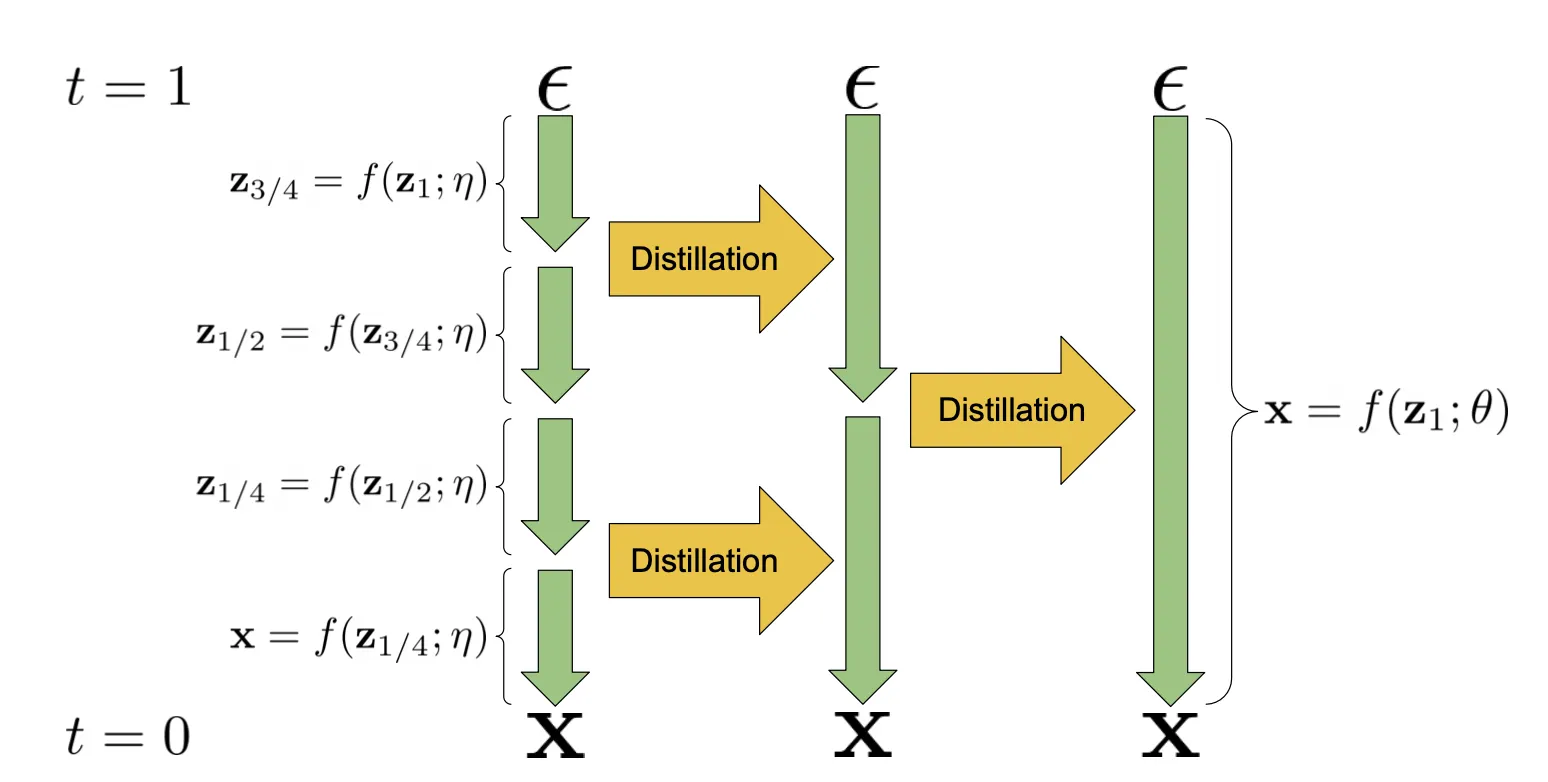
Progressive Distillation (Salimans & Ho, 2022)는 학습된 결정론적 샘플러를 절반 샘플링 단계의 새로운 모델로 distilling(증류) 하는 방법이다. 학생 모델은 교사 모델로 초기화되고 원본 샘플 을 denoise target으로 사용하는 대신 하나의 학생 DDIM step이 2개의 교사 단계와 일치하는 target을 향해 denoise 한다. 매 progressive distillation 반복에서 샘플링 step을 절반으로 줄일 수 있다.

Consistency Model (Song et al. 2023)은 diffusion 샘플링 궤적에서 임의의 중간 noisy 데이터 포인트 을 원본 에 직접 매핑하는 방법을 학습한다. 동일한 궤적에 있는 데이터 포인트가 모두 동일한 원점에 매핑되는 self-consistency라는 속성 때문에 consistency model이라 불린다.

궤적 이 주어지면 consistency 함수 는 로 정의되고 등식 는 모든 에 대해 참이다. 이면 는 항등 함수이다. 모델은 다음과 같이 파라미터화 될 수 있다. 여기서 와 함수는 인 방법으로 설계된다.
consistency 모델은 multi-step 샘플링 프로세스를 따라 더 나은 품질을 위해 trading computation의 유연성을 유지하면서 단일 step으로 샘플을 생성할 수 있다.
그 논문은 consistency 모델을 학습하는 2가지 방법을 소개했다.
1.
Consistency Distillation (CD)
동일한 궤적에서 생성된 쌍에 대한 모델 출력 사이의 차이를 최소화하여 diffusion 모델을 consistency 모델로 distill 한다. 이를 통해 훨씬 더 저렴한 샘플링 평가가 가능하다. consistency distillation loss는 다음과 같다.
여기서
•
는 one-step ODE solver의 업데이트 함수이다.
•
는 에 대한 균등 분포를 갖는다.
•
네트워크 파라미터 는 학습을 매우 안정 시키는 의 EMA 버전이다.(DQN 또는 momentum contrastive learning 같은)
•
는 , 또는 LPIPS(learned perceptual image patch similarity) 거리 같이 이고 이면 이고 iff를 만족하는 positive distance metric 함수이다.
•
는 positive weighting 함수이고 논문에서는 을 설정했다.
2.
Consistency Training (CT)
다른 옵션은 consistency 모델을 독립적으로 훈련하는 것이다. CD에서는 pre-trained score model 이 ground truth score 를 근사하기 위해 사용되지만 CT에서는 이 score 함수를 추정하는 방법이 필요하고 의 비편향 추정기가 로 존재한다는 것이 밝혀졌다. CT loss는 다음처럼 정의된다.
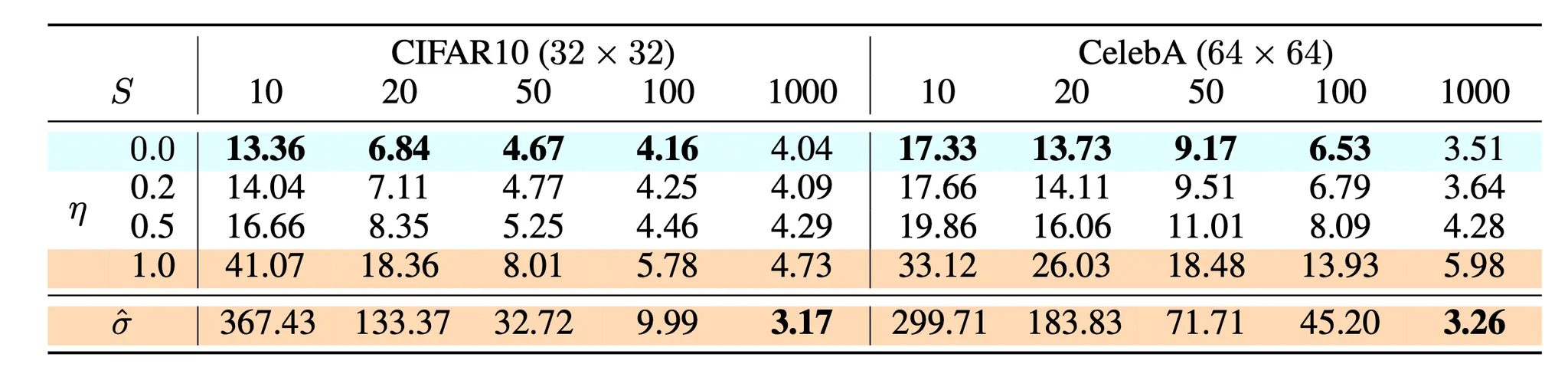
그 논문의 실험에 따르면 그들은 다음을 발견햇다.
•
고차 ODE solver가 동일한 에서 더 작은 추정 에러를 갖기 때문에 Heun ODE solver가 Euler’s first-order solver 보다 잘 작동한다.
•
거리 메트릭 함수 의 다양한 옵션 사이에서 LPIPS 메트릭은 과 거리보다 더 잘 작동했다.
•
이 작을수록 수렴이 빨라지지만 샘플은 나쁘고, 이 클수록 수렴은 느려지지만 수렴시 샘플은 더 좋아진다.
Latent Variable Space
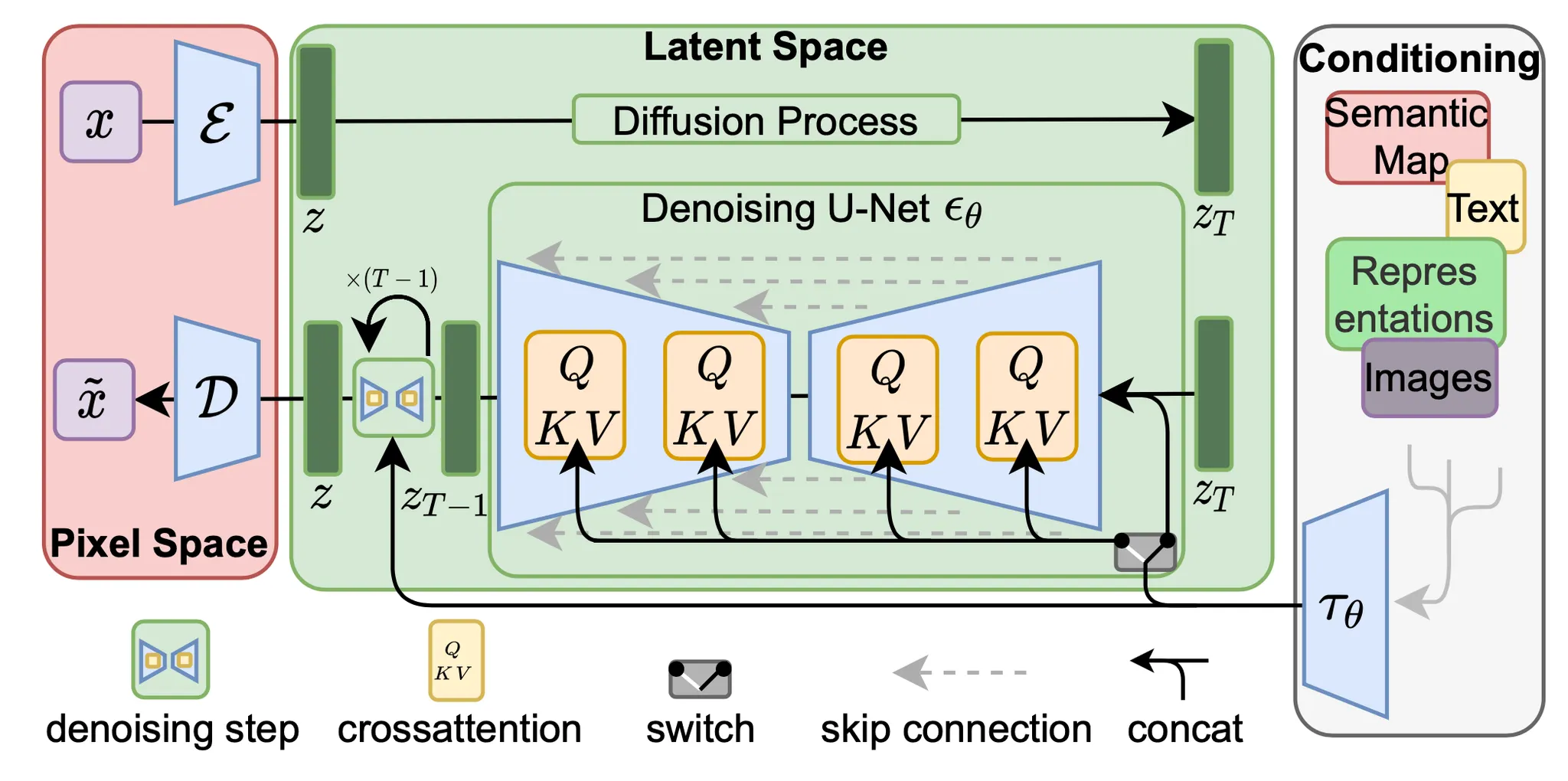
Latent Diffusion odel(LDM; Rombach & Blattmann 등, 2022)은 픽셀 공간 대신 latent 공간에서 diffusion 프로세스를 실행하여 훈련 비용은 낮추고 추론 속도는 더 빠르게 한다. 이는 이미지의 대부분의 비트가 지각적 디테일에 기여하고 공격적인 압축 후에도 의미 및 개념적 구성이 여전히 남아 있다는 관찰에 기반합니다. LDM은 먼저 autoencoder로 픽셀 수준의 중복성을 제거한 다음 학습된 latent에 대한 diffusion 프로세스를 통해 의미적 개념을 조작/생성하는 방식으로 지각적 압축과 의미적 압축을 생성 모델링 학습으로 느슨하게 분해합니다.
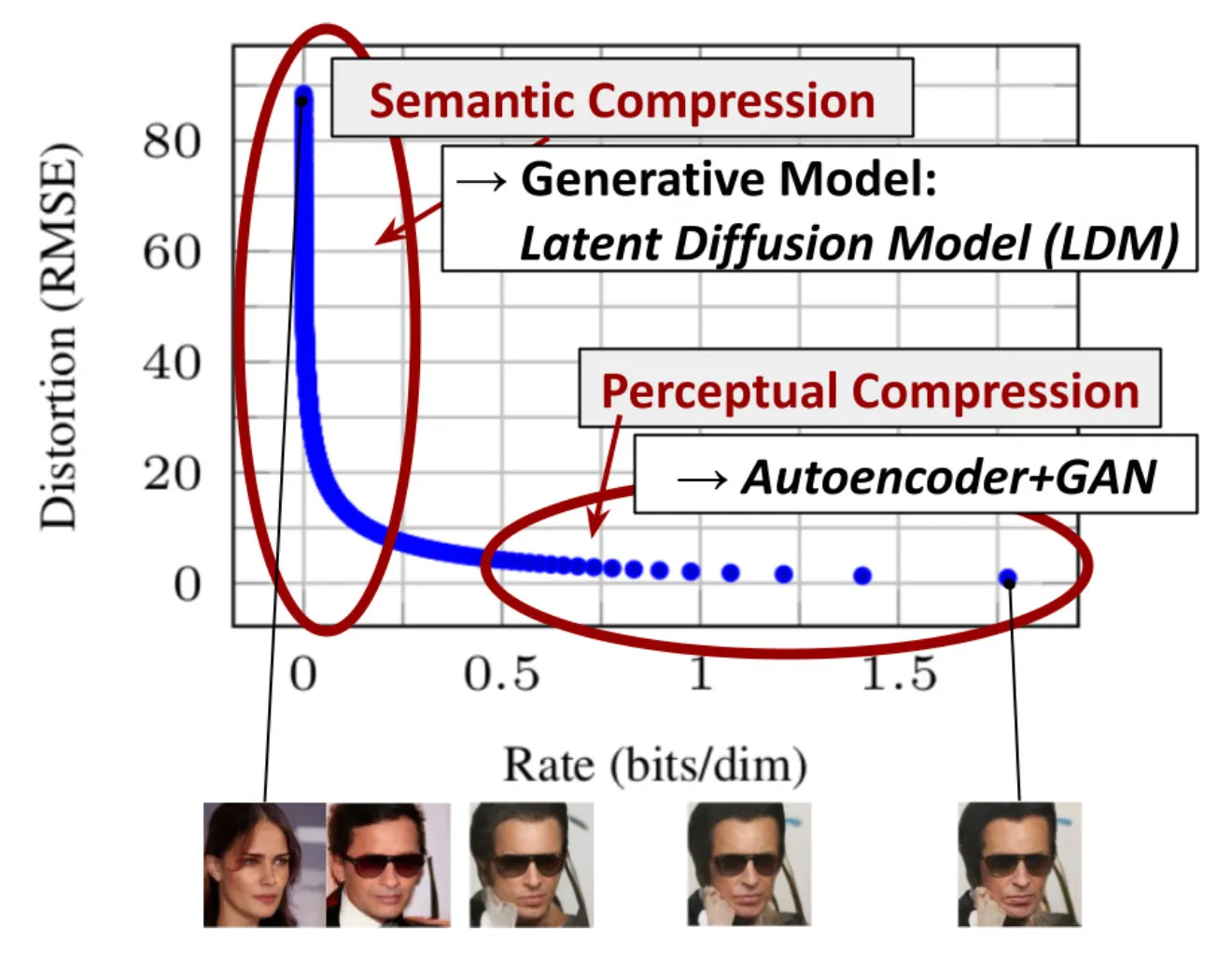
지각적 압축 프로세스는 autoencoder 모델에 의존합니다. 인코더 는 입력 이미지 를 더 작은 2D latent 벡터 로 압축하는 데 사용되며, 여기서 다운샘플링 비율은 입니다. 그 다음 디코더 는 latent 벡터에서 이미지를 재구성합니다. . 해당 논문에서 autoencoder 학습에서 두 가지 유형의 정규화를 통해 latent 공간에서 임의의 높은 분산을 피할 수 있는 방법을 살펴봤습니다.
•
KL-reg: VAE와 유사하게 학습된 latent에 대해 표준 정규 분포 방향으로 작은 KL 페널티
•
VQ-reg: VQVAE와 유사하게 디코더 내에서 벡터 양자화 계층을 사용하지만 양자화 계층은 디코더에 흡수 됨
diffusion 및 denoising 프로세스는 잠재 벡터 에서 발생합니다. denoising 모델은 시간-조건화된 U-Net으로 이미지 생성을 위한 유연한 조건화 정보를 다루기 위해 cross-attention 메커니즘을 사용하여 강화된다. (예, 클래스 라벨, semantic map, 이미지의 blurred 변종). 이 디자인은 cross-attention 메커니즘을 통해 서로 다른 modality의 표현을 모델에 융합하는 것과 같다. 각 유형의 조건화된 정보는 도메인별 인코더 와 짝을 이루어 cross-attention 컴포넌트로 매핑될 수 있는 중간 표현에 조건화된 입력 을 투영한다.
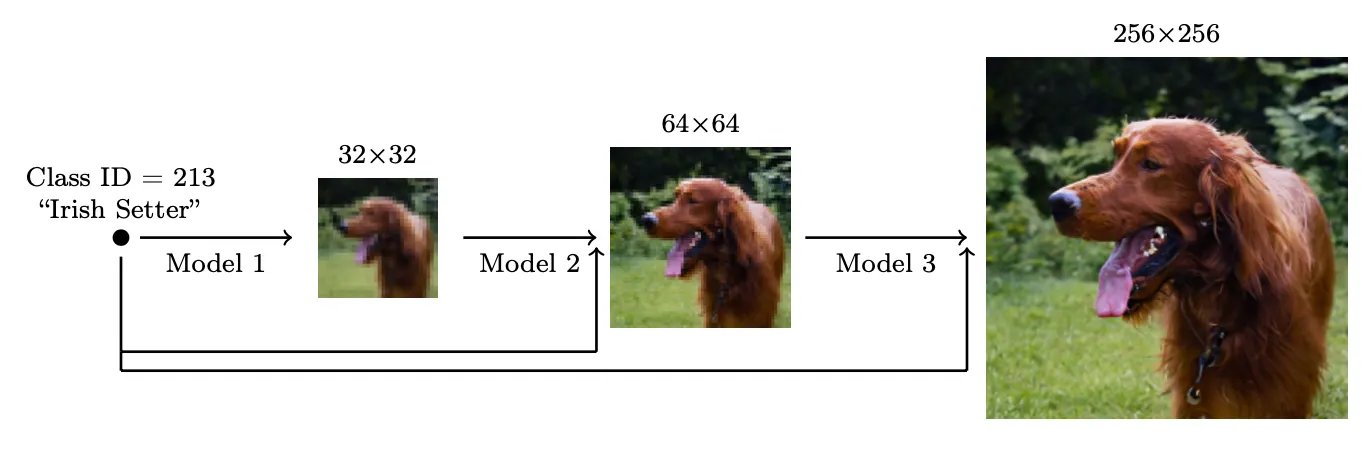
Scale up Generation Resolution and Quality
높은 해상도에서 높은 품질의 이미지를 생성하기 위해 Ho et al. (2021)은 해상도를 증가시킬 때 여러 diffusion 모델의 pipeline을 사용할 것을 제안했다. pipeline 모델 사이의 Noise Conditioning Augmentation(NCA)가 최종 이미지 품질에 핵심이다. NCA는 각 super-resolution 모델 의 conditioning 입력 에 강력한 데이터 augmentation을 적용하는 것을 말한다. conditioning 노이즈는 pipeline 설정에서 복합 에러를 줄이는데 도움이 된다. U-net은 고해상도 이미지 생성을 위한 diffusion 모델링에서 모델 아키텍쳐의 일반적인 선택이다.
그들은 저해상도에서는 가우시안 노이즈를 적용하고 고해상도에서는 가우시안 블러를 적용하는 것이 가장 효과적인 노이즈라는 것을 발견했다. 또한 학습 프로세스에 작은 수정이 필요한 conditioning augmentation의 2가지 형식을 살펴보았다. conditioning 노이즈는 학습에만 적용되고 추론에는 적용되지 않는다는 것에 유의하라.
•
Truncated conditioning augmentation은 저해상도에 대해 step 에서 diffusion 프로세스를 조기에 중지한다.
•
Non-truncated conditioning augmentation은 step 0까지 전체 저해상도 reverse 프로세스를 실행하지만 만큼 오염 시키고, 그 다음 오염된 를 super resolution 모델에 공급한다.
2-stage diffusion model unCLIP(Ramesh, 2022)은 고 품질에서 text-guided 이미지를 생성하도록 CLIP 텍스트 인코더를 많이 활용했다. pretrained CLIP 모델 와 diffusion 모델에 대한 쌍별 학습 데이터가 주어지면 (여기서 는 이미지이고 는 해당 캡션) CLIP text와 이미지 embedding을 각각 계산할 수 있다. 와 . unCLIP은 병렬로 2가지 모델을 학습한다.
•
prior model : 텍스트 가 주어질 때 출력 CLIP 이미지 embedding
•
디코더 : CLIP 이미지 embedding 와 optional 로 원본 텍스트 가 주어질 때 이미지 를 생성.
이 두 모델은 조건부 생성을 가능하게 한다. 왜냐하면
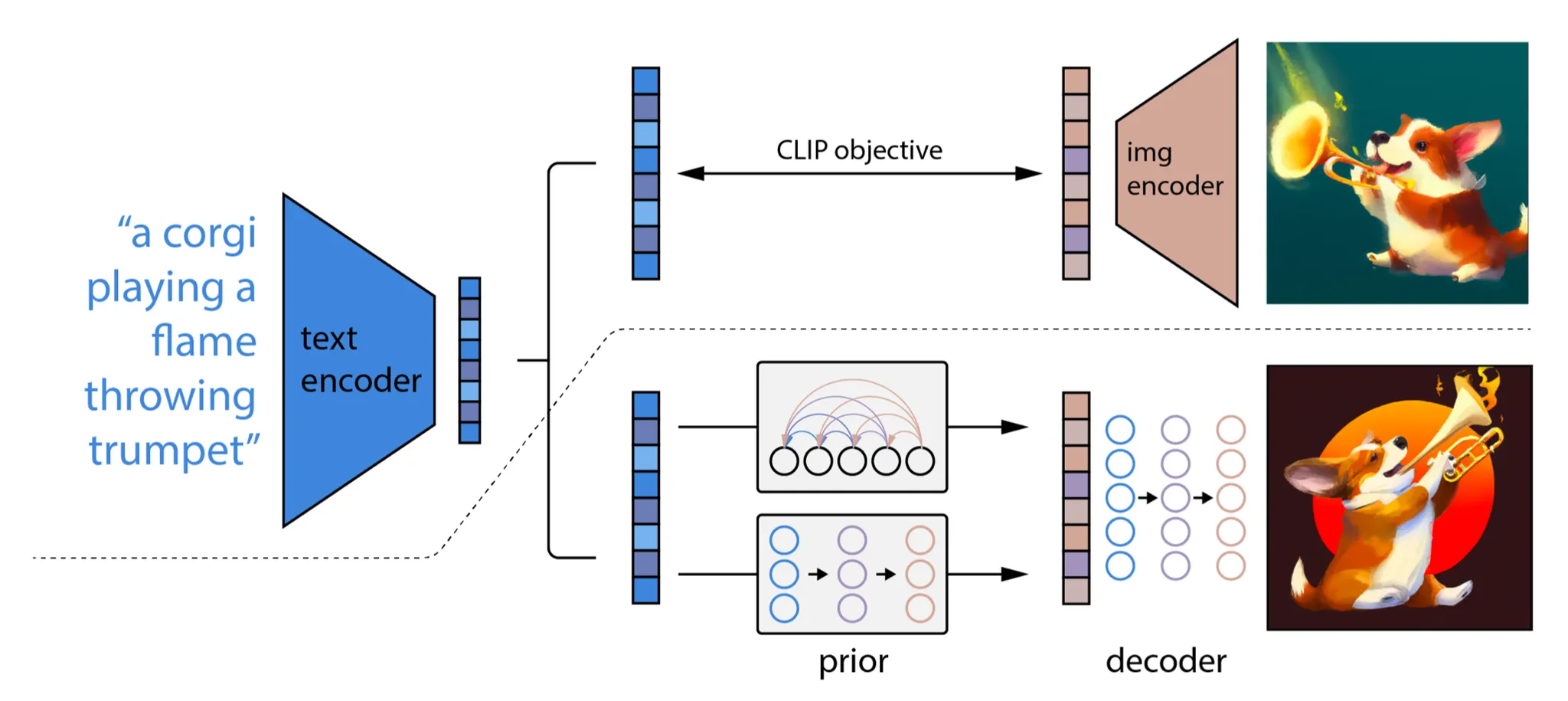
unCLIP은 2단계 이미지 생성 프로세스를 따른다:
1.
텍스트 가 주어지면 CLIP 모델은 우선 텍스트 임베딩 을 생성하도록 사용된다. CLIP latent 공간을 사용하여 텍스트를 통해 zero-shot image manipulation이 가능하다.
2.
diffusion 또는 autoregressive prior 가 이 CLIP 텍스트 임베딩을 처리하여 이미지 prior를 구성한 다음 diffusion decoder 가 prior에 조건화된 이미지를 생성한다. 이 디코더는 또한 스타일과 semantics를 보존하며 이미지 입력에 조건화된 이미지 변종을 생성할 수도 있다.
CLIP 대신 Imagen(Saharia, 2022)는 pre-trained 대형 LM(예: frozen T5-XXL text encoder)을 사용하여 이미지 생성에 대한 텍스트를 인코드 했다. 더 큰 모델 크기는 더 나은 이미지 품질과 text-image alignment를 이끄는 일반적인 경향이 존재한다. 그들은 T5-XXL과 CLIP text 인코더가 MS-COCO에 대해 유사한 성능을 달성했지만 인간 평가자는 DrawBench(11개 카테고리를 커버하는 프롬프트의 컬렉션)에 대해 T5-XXL을 더 선호 했다.
classifier-free guidance를 적용할 때, 를 증가시키면 더 나은 image-text alignment를 이끌지만 이미지 fidelity(충실도)는 낮아진다. 그들은 이것이 train-test 미스매치 때문이라는 것을 발견했다. 이것은 다시 말해 학습 데이터 가 범위 내에 있기 때문에 테스트 데이터도 그래야 한다. 두 thresholding 전략이 유도되었다.
•
static thresholding: 예측을 로 clip 한다.
•
dynamic thresholding: 각 샘플링 단계에서 를 특정한 백분위수 절대 픽셀 값으로 계산. 이면 예측을 로 clip하고 로 나눈다.
Imagen은 U-net에서 여러 설계를 수정하고 efficient U-Net을 만들었다.
•
낮은 해상도에 더 많은 residual lock을 추가하여 모델 파라미터를 고해상도 블록에서 저해상도로 이동
•
skip connection을 로 확장
•
forward pass의 속도를 개선하는 측면에서 downsampling(convolution 전에 이동)과 upsampling(convolution 후에 이동) 연산의 순서를 반전.
그들은 noise conditioning 증강, dynamic thresholding과 efficient U-Net이 이미지 품질에 더 중요하지만 텍스트 인코더 크기를 scaling하는 것이 U-Net 크기 보다 중요하다는 것을 발견했다.
Model Architecture
일반적으로 diffusion 모델에 대한 2가지 backbone 아키텍쳐 선택이 존재한다. U-Net과 Transformer이다.
U-Net(Ronneberger, 2015)는 downsampling stack과 upsampling stack의 구성이다.
•
Downsampling: 각 단계는 2개의 3x3 convolution(unpadded convolution)을 반복적으로 적용한 다음, 각각 ReLU, stride 2의 2x2 max pooling을 적용하는 것으로 구성된다. 각 downsampling 단계마다 feature channel은 2배가 된다.
•
Upsampling: 각 단계는 feature map의 upsampling과 2x2 convolution으로 구성되며 각각 feature channel의 수를 절반으로 줄인다.
•
Shortcuts: Shortcut connection은 downsampling stack의 해당 레이어와 연결되며 upsampling 프로세스에 필수적인 고해상도 feature를 제공한다.

Canny edges, Hough lines, user scribbles, human post skeletons, segmentation maps, depths and normals 같은 구성 정보에 대한 추가 이미지를 조건으로 이미지를 생성할 수 있도록 ControlNet(Zhang 등, 2023)은 U-Net의 각 인코더 레이어에 원본 모델 가중치의 학습 가능한 복사본인 ‘샌드위치’된 zero convolution layer를 추가하여 아키텍쳐의 변화를 도입한다. 정확하게 신경망 블록 가 주어지면 ControlNet은 다음을 수행한다.
1.
우선 원래 블록의 원래 파라미터 을 freeze 한다.
2.
학습 가능한 파라미터 와 추가적인 conditioning 벡터 를 사용하여 복사본으로 복제한다.
3.
이 두 블록을 연결하기 위해 와 로 표기되는 2가지 zero convolution 레이어를 사용한다. 이것은 가중치와 bias 모두 0으로 초기화된 1x1 conv layer이다. Zero convolution은 초기 학습 단계에서 gradient의 랜덤 노이즈를 제거하여 이 back-bone을 보호한다.
4.
최종 출력은 다음과 같다.

diffusion 모델링을 위한 Diffusion Transformer(DiT, Preebles & Xie, 2023)은 Latent Diffusion Model(LDM)과 동일한 디자인 공간을 사용하여 latent patch에서 작동한다. DiT는 다음 설정을 따른다.
1.
입력 의 latent 표현을 DiT의 입력으로 취한다.
2.
크기 의 noise latent를 크기 의 패치로 ‘patchify’ 하고 크기 의 패치의 시퀀스로 변환한다.
3.
그 다음 이 토큰의 시퀀스를 Transformer 블록에 통과시킨다. 그들은 timestep 나 클래스 라벨 와 같은 contextual 정보에 조건화된 생성을 수행하는 3가지 다른 디자인을 탐험 했다. 3개의 디자인 사이에서 adaLN(Adaptive layer norm)-Zero가 가장 성능이 좋았고 in-context conditioning과 corss-attention block 보다 우수하다. scale과 shift 파라미터 와 는 와 의 임베딩 벡터의 합에서 회귀된다. 차원별 스케일링 파라미터 또한 회귀되고 DiT 블록 내의 모든 residual connection에 즉시 prior로 적용된다.
4.
transformer 디코더는 노이즈 예측과 출력 대각 공분산 예측을 출력한다.

트랜스포머 아키텍쳐는 쉽게 확장할 수 있는 것으로 알려져 있다. 이것은 더 많은 컴퓨팅에 따라 성능이 확장되고 실험에 따르면 더 큰 DiT 모델이 더 컴퓨팅 효율적이기 때문에 DiT의 가장 큰 장점 중 하나이다.
Quick Summary
•
장점: 추적 가능성과 유연성은 제너레이티브 모델링에서 상충되는 두 가지 목표이다. 추적 가능한 모델은 분석적으로 평가할 수 있고 가우스 또는 라플라스 등을 통해 저렴하게 데이터를 맞출 수 있지만, 풍부한 데이터 세트의 구조를 쉽게 설명할 수 없다. 유연한 모델은 데이터의 임의의 구조에 맞출 수 있지만, 이러한 모델을 평가, 학습 또는 샘플링하는 데는 일반적으로 비용이 많이 든다. 확산 모델은 분석적으로 추적 가능하고 유연하다.
•
단점: 확산 모델은 샘플을 생성하기 위해 긴 확산 단계의 마르코프 체인에 의존하므로 시간과 컴퓨팅 비용이 상당히 많이 들 수 있다. 프로세스를 훨씬 빠르게 만드는 새로운 방법이 제안되었지만, 샘플링은 여전히 GAN보다 느리다.
