
•
이번에는 GAN을 배워보겠다.

•
GAN의 성능은 매년 급격히 좋아지고 있음
◦
2017년부터 진짜 사람 수준이 됨

•
GAN을 이용해서 자화상을 만들어서 경매에 올렸더니 실제로 $432,500에 팔림
•
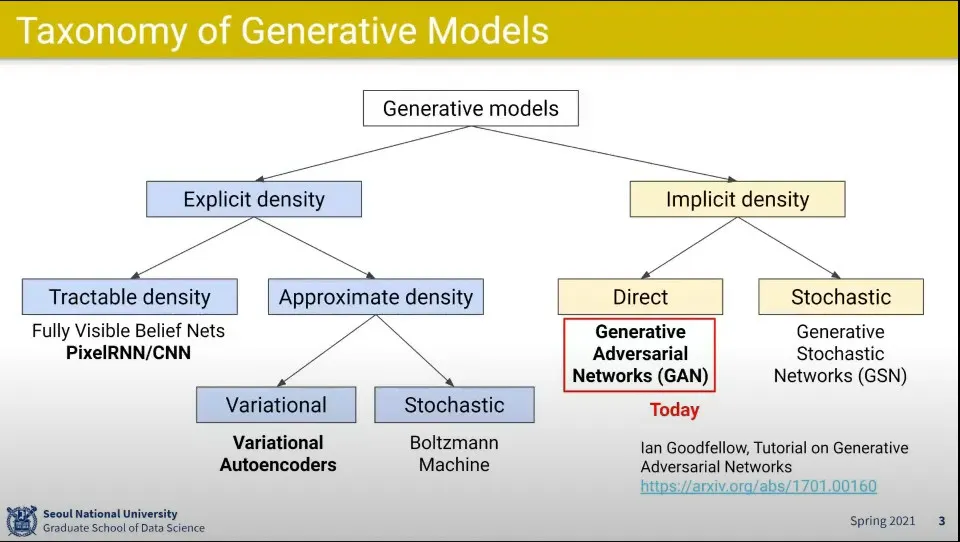
이미지가 어떤 분포 공간 를 쓰지 않고 Discriminator라는 것을 이용함
•
실제 이미지 셋인 x와 Generator가 생성해낸 이미지셋을 Discriminator에 넣고 Discriminator가 real/fake를 구분하게 함
◦
그 결과는 다시 generator에게 흘러들어가서 generator는 최대한 실제 이미지와 비슷한 이미지를 만들어 내도록 학습 함
•
Generator는 최대한 진짜 같은 것을 만들어서 Discriminator를 속이려고 학습하고, Discriminator는 Generator에게 안 속기 위해 학습 함

•
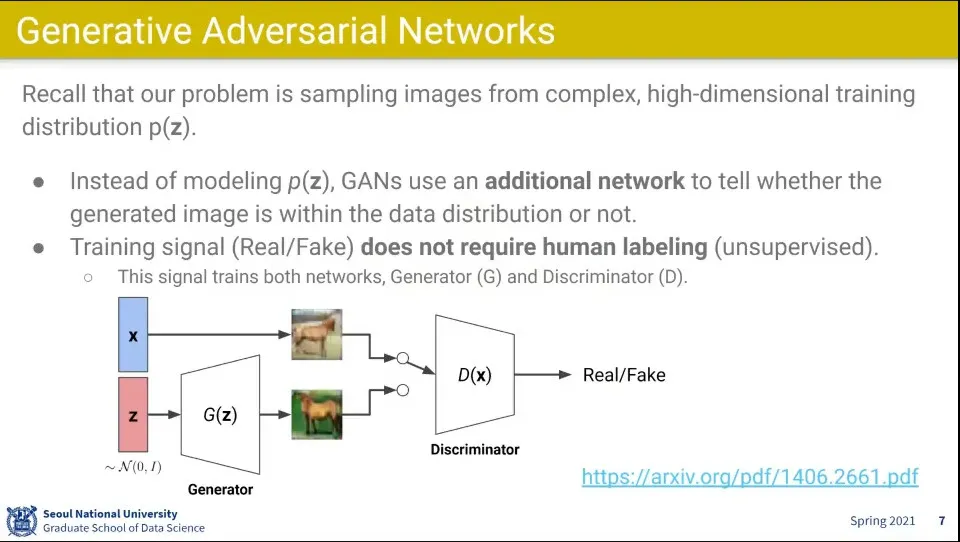
Discriminator는 이미지를 받아서 진짜인지 아닌지를 구분함
◦
진짜일 수록 1에 가깝고 가짜일수록 0에 가깝게 나오도록 학습 함
•
Discriminator는 위 수식을 maximize하는게 목표인데
◦
식에서 왼쪽 부분은 진짜 사진에서 들어오는 값으로 그 값을 최대화 하도록 하고
◦
식의 오른쪽 부분은 Generator에서 들어오는 부분으로 그 값을 최소화 하도록 해야 함
◦
그 둘의 합해서 전체 식을 최대화 하는게 Discriminator가 하는 일
•
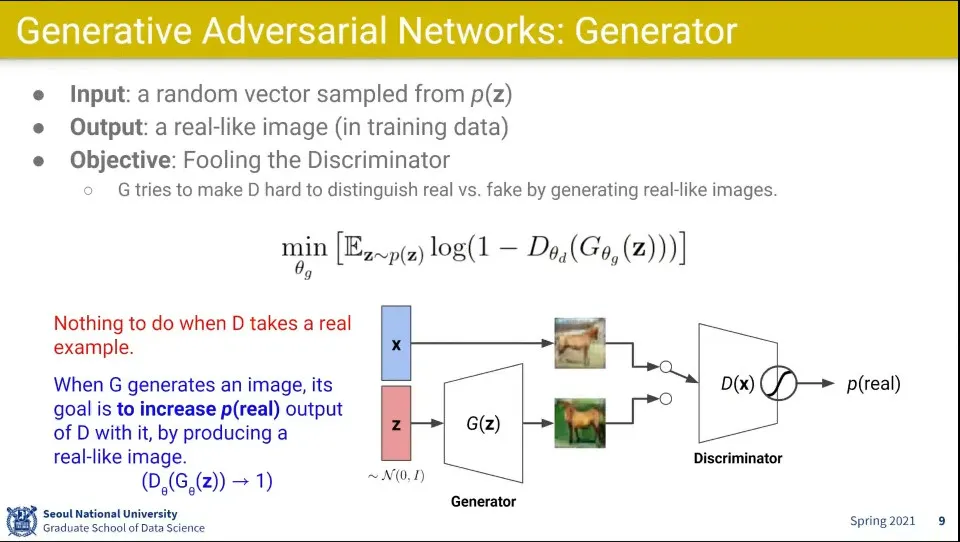
Generator는 Discriminator를 속이도록 함
•
Generator는 위 식을 minimize 하는게 목표
◦
Generator의 식은 Discriminator의 오른쪽 수식과 같은 식이고, 같은 식을 두고 Discriminator는 최대화하려고 하고, Generator는 최소화 하려고 함

•
전체 수식을 모으면 위와 같음

•
논문에 소개된 알고리즘
◦
우선 Discriminator로 maximize하고
◦
그 다음 Generator로 minimize 하도록 함
•
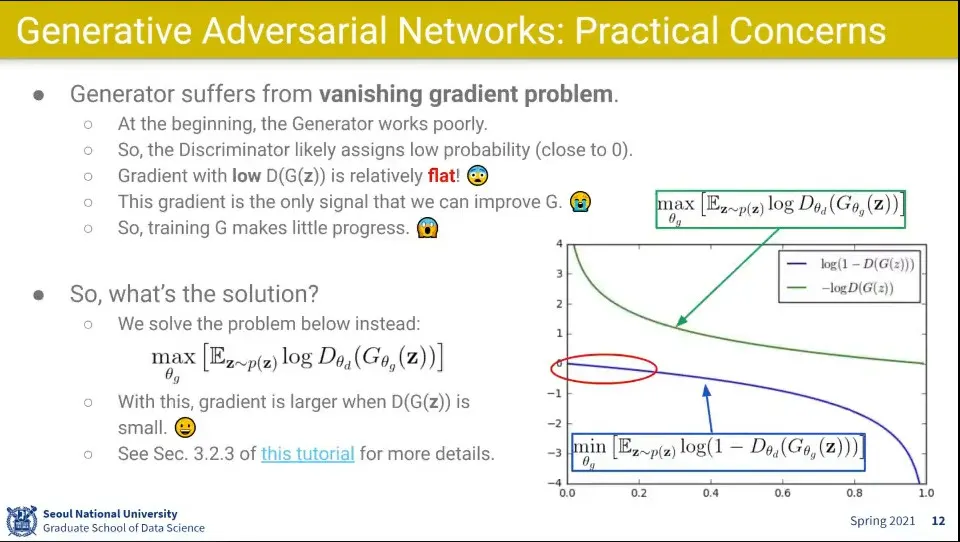
Generator 입장에서 초반에는 많이 틀리기 때문에
◦
Gradient가 작게 나오고 —위 이미지 그래프의 파란색 선. 잘 맞출 때는 크게 나옴— 그러다 보니 vanishing gradient 문제가 발생함
•
그래서 초반에는 loss를 위 그래프의 녹색선과 같이 바꿔서 학습 시킴
◦
1에서 빼는 부분을 없애고 maximize 하도록 바꿈
◦
그랬더니 초반에 gradient가 크게 나와서 학습이 잘 되더라

•
처음 GAN 만들때는 Fully-Connected를 썼었음. Deconv-conv 레이어도 조금 써 봄.

•
아이디어는 좋았는데 실제 구현이 잘 안 되는 문제가 많았음
◦
하이퍼파라미터를 조금만 바꿔도 자꾸 튀고, 불안정함
◦
만들어내는 이미지에 대한 해석도 안 됨
•
그래서 GAN을 수정한게 DCGAN
◦
pooling layer를 없애고 convolution layer로만 함. pooling layer는 학습이 없음. 그냥 계산만 함. 그래서 요즘은 pooling을 안 쓰는게 대세임
◦
batch norm도 씀
◦
fully-connected도 없애고 conv만 썼음
•
이랬더니 좀 더 학습이 잘 되더라
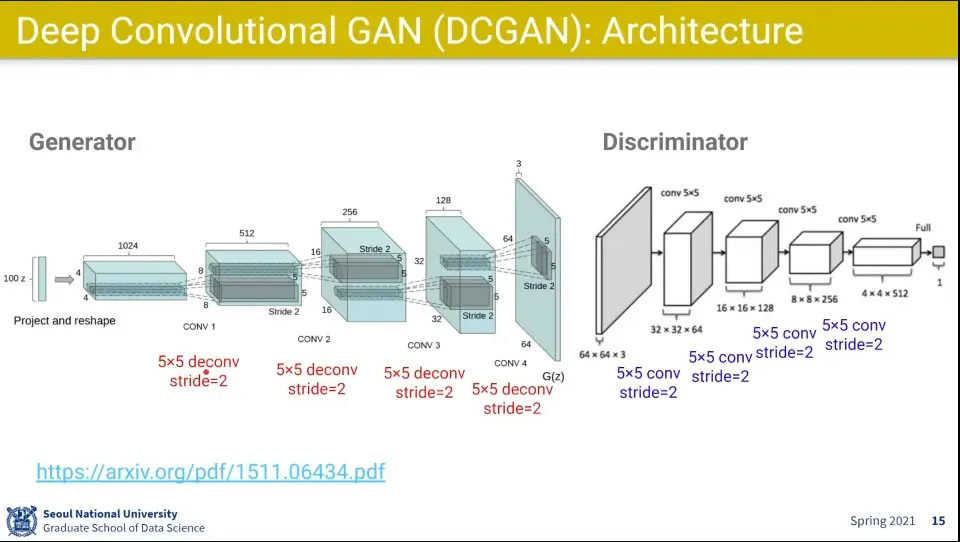
•
Generator는 이미지를 키워야 해서 deconv 하고, Discriminator는 이미지를 줄여야 해서 conv를 씀

•
흥미롭게도, vector간의 연산이 됨
1.
안경을 쓴 남자들의 벡터를 가져와서 평균내고
2.
안경을 안 쓴 남자들의 벡터를 가져와서 평균내고
3.
안경을 안 쓴 여자들의 벡터를 가져와서 평균내고
4.
1에서 2를 빼고 3을 더했더니 안경을 쓴 여자가 나옴
•
해석 가능한 벡터가 나왔다.

•
생성된 이미지들 사이에 interpolation을 시켰더니 실제로 서서히 바뀌는 모습이 나옴
•
GAN은 blackbox가 아니라 설명이 가능한 모델이 되더라

•
Unstable Training이 DCGAN에서 개선이 되긴 했지만 여전히 잘 안 됨
◦
Generator에게 들어오는 Loss가 Discriminator를 통해서 들어오는게 문제. Generator 입장에서 얼마나 학습이 잘 된 건지 알 수가 없음.
•
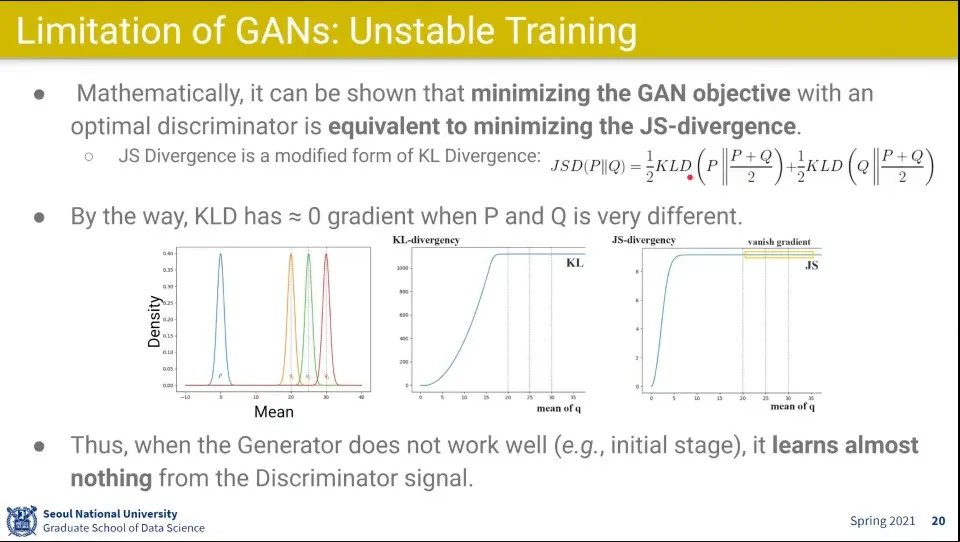
GAN의 목표를 수학적으로 보면, Generator가 만들어 내는 이미지 분포가 실제 이미지의 분포와 비슷해져야 하는 것.
◦
JS-divergence를 minimize 하는 것
◦
두 확률 분포의 distance를 minimize하는 것
•
KL-divergency나 JS-divergency로 보나 일정 영역에서 vanishing gradient가 발생하는 문제가 발생
◦
위 그래프 의 오른쪽 편평해지는 부분
•
Generator는 Discriminator로부터 거의 배울 수 있는게 없다.
◦
학습 초반부에

•
또 다른 문제는 Mode collapse
◦
실제 분포에서 일부 분포만 배움
◦
0-9까지 학습을 시켰는데 1, 7만 생성해 내더라
•
뭘 배웠는지는 알기 쉽지만, 뭘 잊어버렸는지는 알기 어려움

•
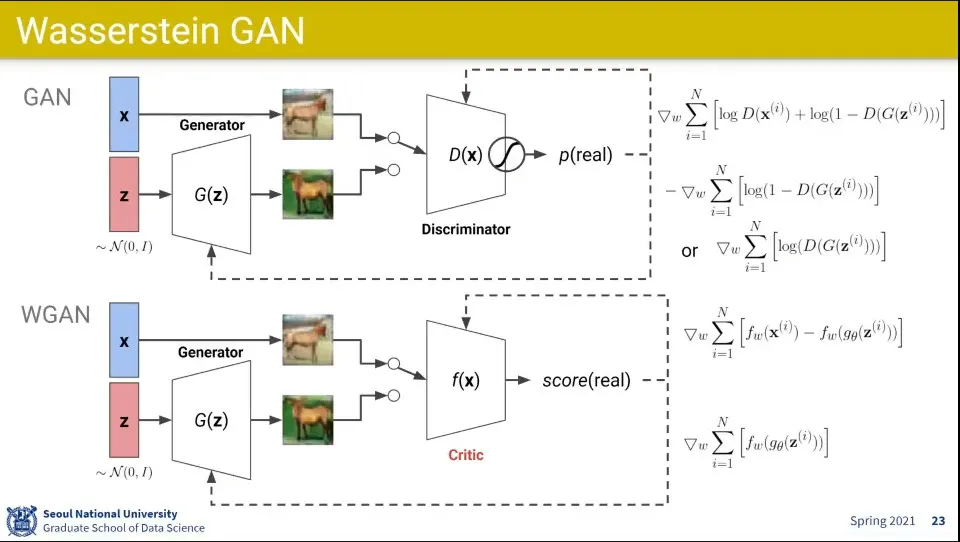
위 문제들을 개선하기 위해 나온게 WGAN(Wasserstein GAN)
•
KL Divergence 대신에 Earth Mover(EM) Distance를 사용함
◦
EM distance를 minimize하도록 하면 위의 식과 같이 바뀜
◦
0-1사이의 값이 아니라 어떤 값이나 사용 가능함
◦
1-Lipschitz continuous function 제약 조건이 있어서 -c, c로 값을 clip 해서 사용함
•
original GAN과 WGAN 차이 비교
◦
진짜 이미지에 대해서는 최대한 높은 점수를 주고, 가짜 이미지에 대해서는 최대한 낮은 점수를 주는 것은 동일함
◦
근데 0-1 사이의 output이 아니라 임의의 값이 나옴
•
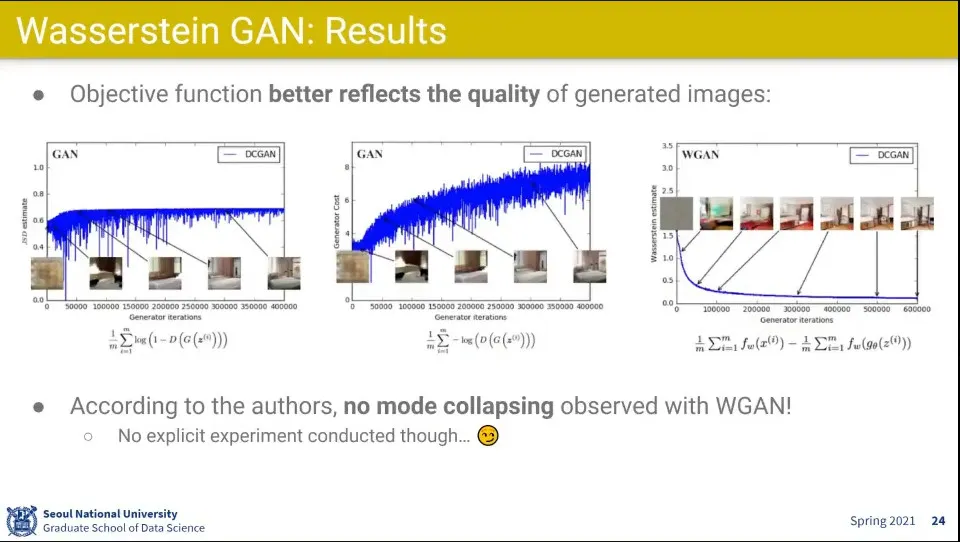
그것만 바꿨더니 GAN에서는 실제 점수와 결과 매치가 잘 안됐는데, WGAN은 점수와 실제 이미지의 성능이 잘 매치됨
◦
Loss만 봐도 그림이 어느 정도 만들어졌는지 추정할 수 있음

•
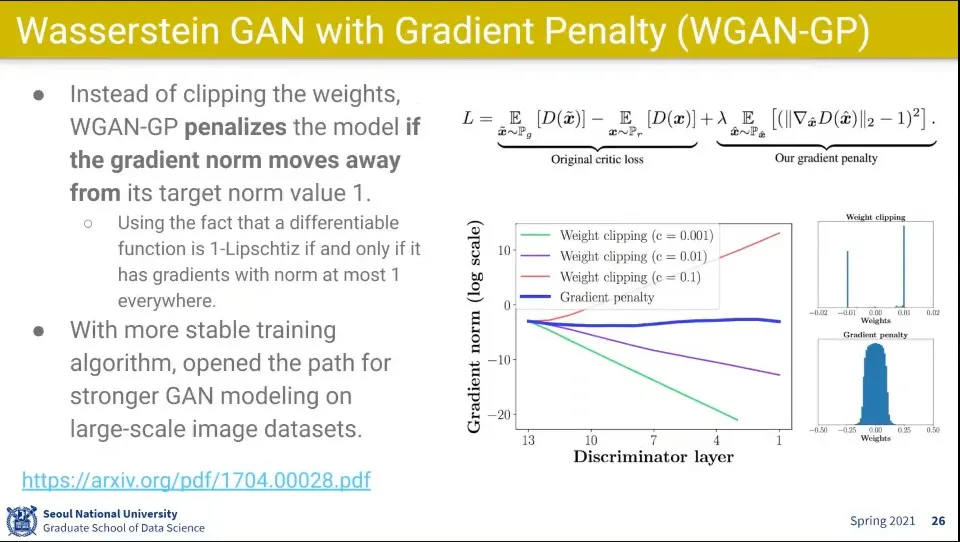
그러나 WGAN은 clip 하는 c 를 얼마나 주느냐가 문제가 됨
◦
c를 조금만 커지거나 작게 해도 gradient가 exploding하거나 vanishing하는 문제가 발생함
•
WGAN의 강제로 c로 clip 하는거를 개선한게 WGAN-GP(Gradient Penalty)
◦
gradient를 강제로 clip하는 대신 regularization처럼 loss 함수에 패널티를 줘서 값이 튀지 않고 적당히 잘 되더라

•
WGAN에 비해 좀 더 잘 되더라는 예시

•
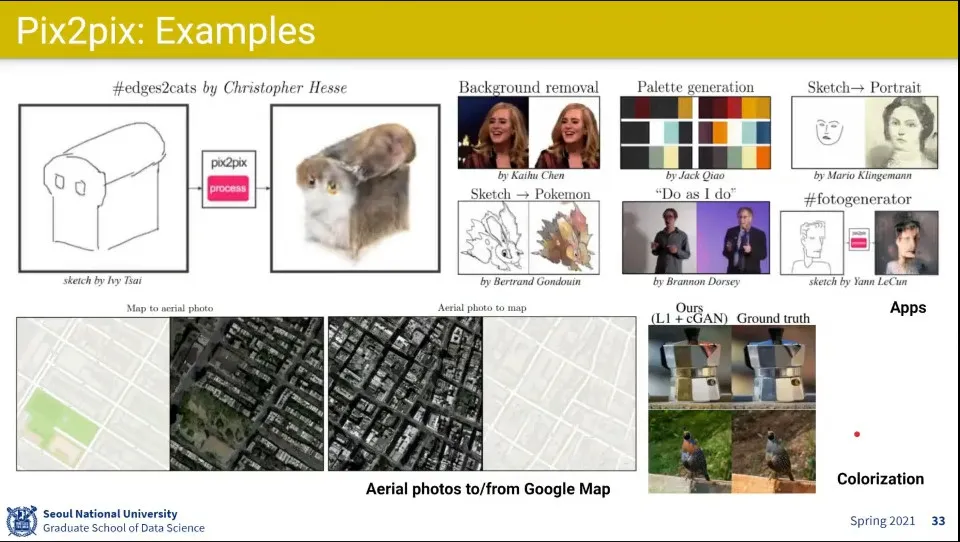
이미지를 다른 이미지로 바꾸는 예시
◦
input으로 넣는 이미지를 원하는 다른 형태로 만들어 줌
◦
이런거 하는데도 GAN이 많이 사용 됨

•
서로 다른 이미지를 pair로 주어줌
•
Generator는 input을 다른 도메인 이미지로 만들고
•
Discriminator는 pair를 받아서 real, fake를 판별함
•
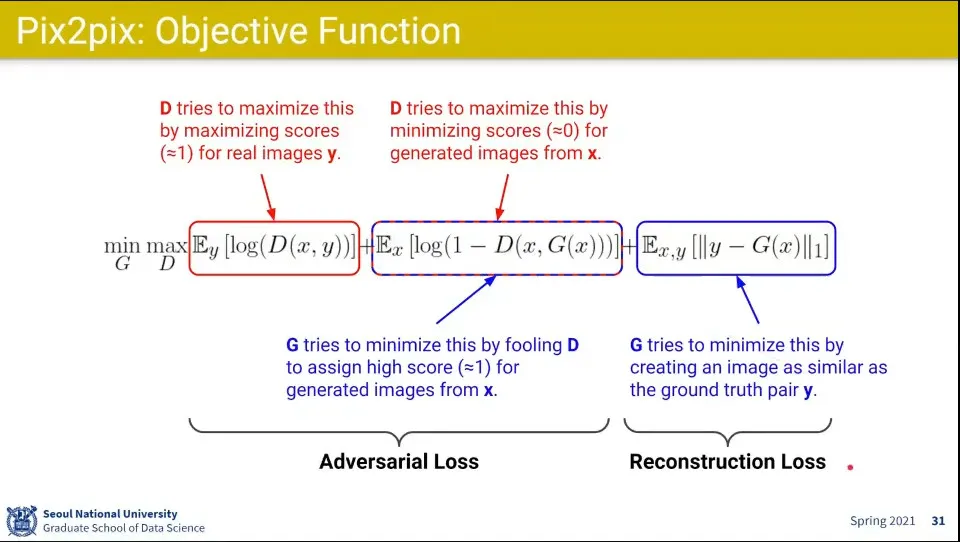
Pix2pix의 목적함수
◦
Adversarial Loss 부분은 기존의 GAN과 동일. 이미지가 진짜처럼 보이도록 함
◦
뒤의 Reconstruction Loss는 실제 Pair를 맞추도록 함

•
이미지를 1x1로 쪼개서 할 때보다 크기를 키워서 했더니 잘 되더라
•
예시
◦
이미지를 바꿔주는 것 뿐만 아니라 색상 바꿔주는 것도 가능 함. 흑백 이미지에 색상 입혀주는 것이나
•
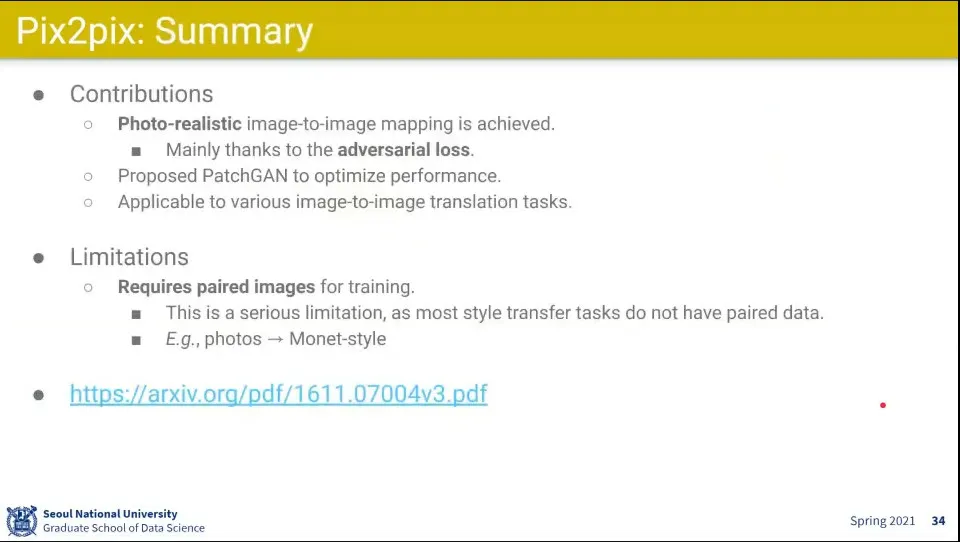
Pix2pix 요약
◦
photo-realistic 한 이미지 변환이 됐다
◦
그런데 학습 이미지가 pair가 필요해서 한계가 있음
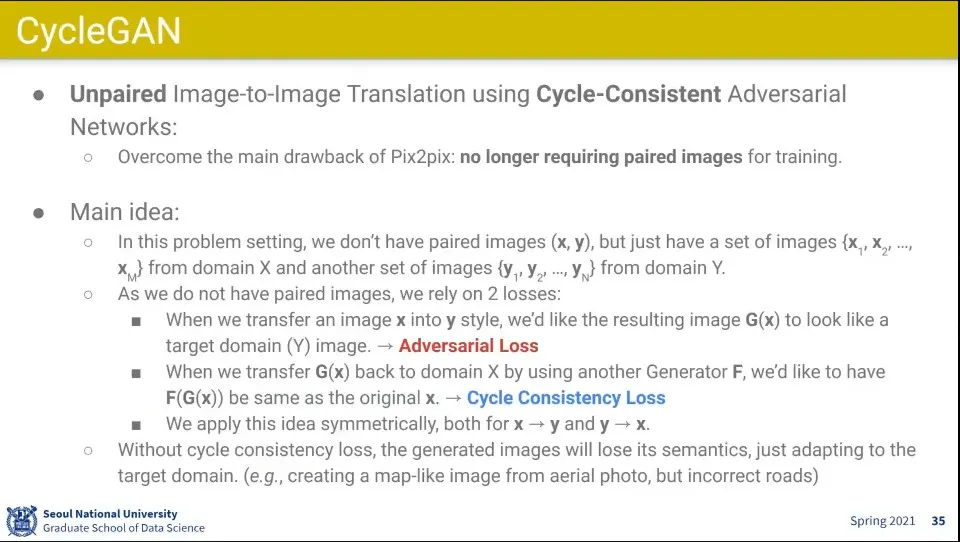
•
pair가 없는 이미지로 학습시키도록 하는게 CycleGAN
◦
X를 Y로 만든 후에 그걸 다시 X로 바꿨을 때 원래 X와 같도록 하는 아이디어
◦
이렇게 하면 X를 Y로 바꾸고, Y를 X로 바꾸는 학습이 동시에 된다.
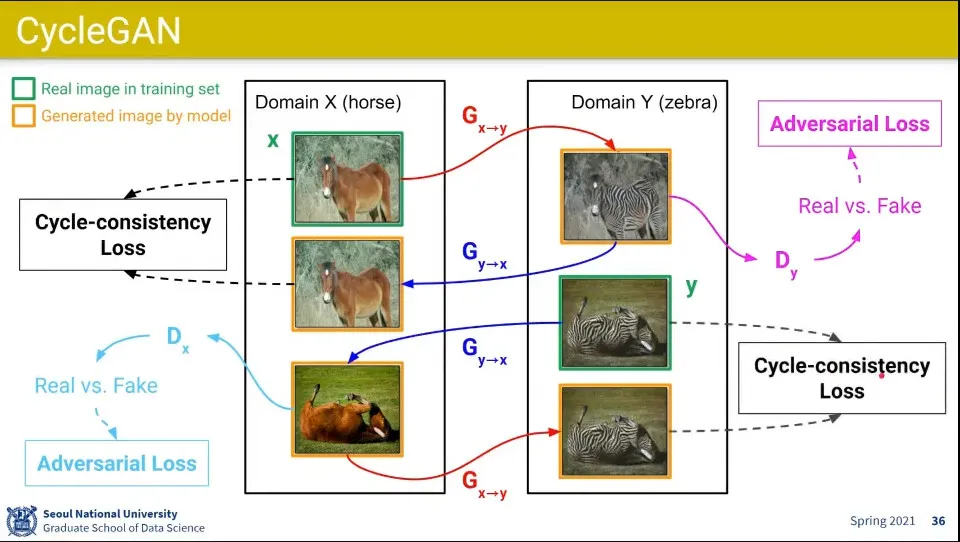
•
X를 Y로 바꾼 것에 대해 real, fake를 구분하는 adversal loss를 적용하고, 그렇게 바꾼 Y를 다시 X로 바꿀 때 원본 X와 같은지를 판별하는 Cycle-consistency Loss를 적용함
•
같은 것을 Y에서 X 방향으로도 학습해 주면 쌍으로 학습이 가능함
◦
X에서 Y가는 generator와 Y에서 X로 가는 generator는 다른 generator임
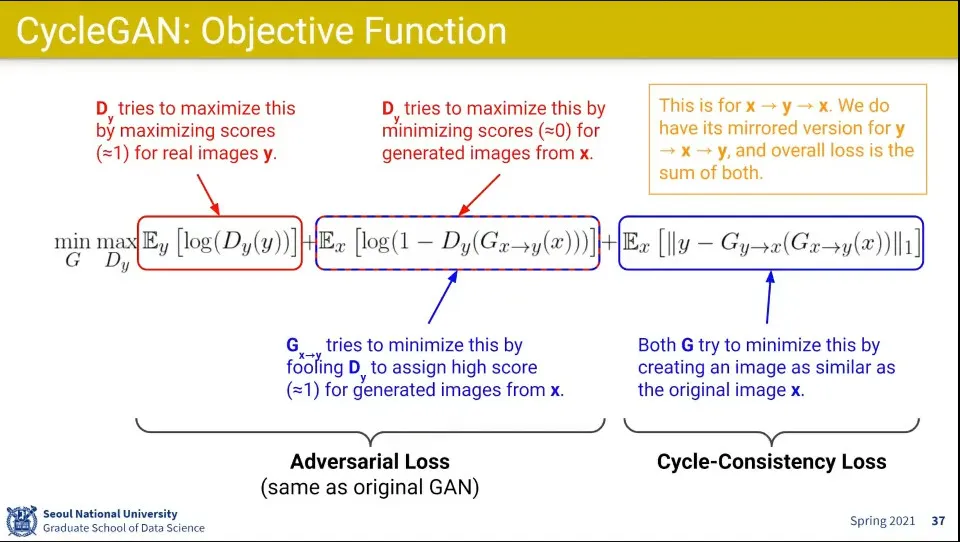
•
CycleGAN의 수식의 앞부분은 기존 GAN과 유사함. 다만 x에서 y로 변환한 것이 사용된다는 부분만 차이가 있음
◦
수식의 뒷부분은 다시 원복 시켰을 때 loss를 계산하는 부분. Cycle-Consistency Loss

•
CycleGAN 상세
◦
Generator는 ResNet을 썼음
◦
Discriminator는 70x70 패치를 사용 (pix2pix랑 같음)
◦
Loss는 LSGAN을 사용 (cross-entropy 대신 regression 처럼)
◦
Generator에도 진짜 이미지를 넣는 것을 사용함. Generator가 진짜 이미지를 받으면 그대로 나가야 함. 이게 Identity Loss


•
예제
•
CycleGAN은 pair 된 이미지가 없어도 학습할 수 있다는데 큰 영향력을 끼침
•
단점은 네트워크가 커서 느림. 스타일을 바꾸는거는 잘 하는데, 모양을 바꾸는거는 잘 못 함
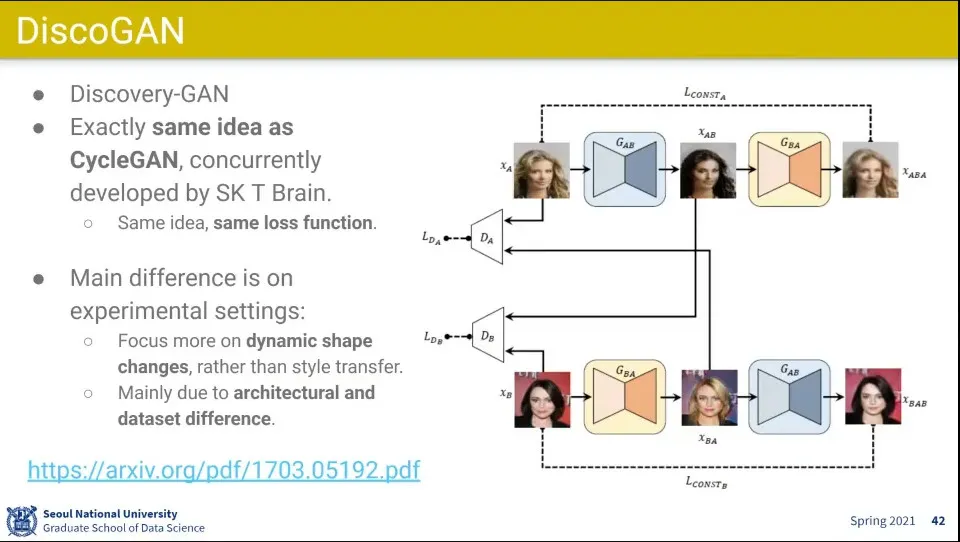
•
CycleGAN이랑 비슷한 아이디어로 나온게 DiscoGAN. SK T Brain에서 만듦
•
CycleGAN과 달리 스타일 바꾸는 것보다 모양 바꾸는 것에 집중해서 결과가 꽤 다르게 나옴

•
CycleGAN과 달리 이미지를 작게 했더니 오히려 모양이 바뀌는 것에 잘 적응 됨

•
가방에서 구두로 바꾸거나 의자를 자동차로 바꾸거나
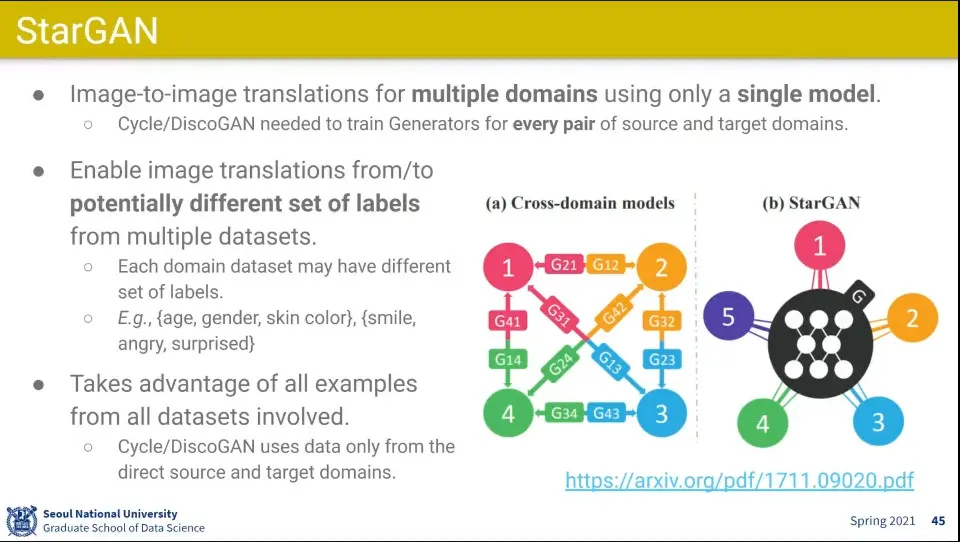
•
StarGAN도 한국에서 만듦
◦
하나의 domain에서 다른 domain으로 갈 때 따로 학습을 해줘야 했던 것을 개선해서 중앙의 domain을 두고 어느 domain으로든 갈 수 있게 함
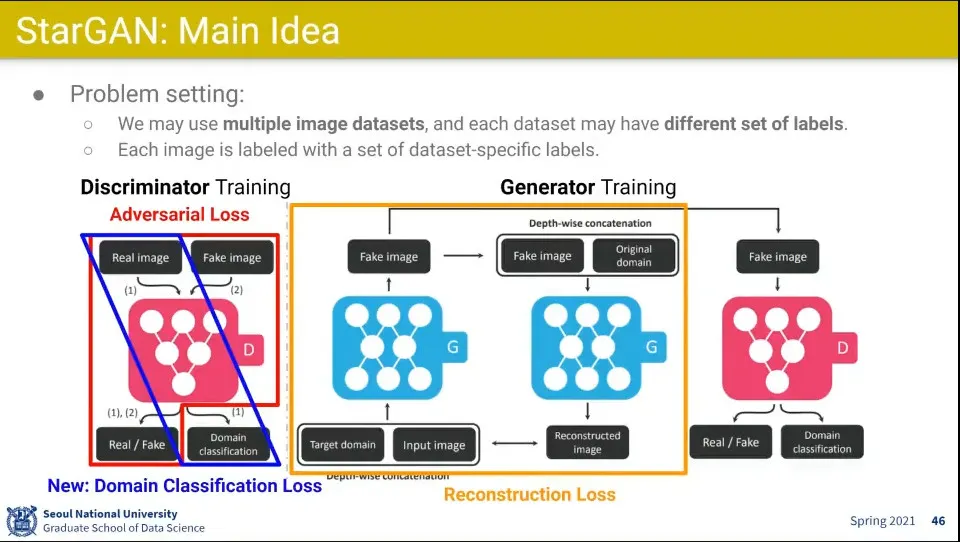
•
Adversal Loss는 이전 GAN과 비슷함.
◦
Reconstruction Loss는 CycleGAN과 비슷한데, 원래 도메인으로 변환하는게 아니라 어느 도메인으로도 변환할 수 있음.
◦
추가로 Domain Classfication을 넣어서 Discriminator는 Domain을 맞추려고 하고 Generator는 Domain을 속이려고 함

•
StarGAN의 loss 함수들
◦
Adversal은 기존과 유사
◦
Reconstruction은 x를 원래 클래스 c’에서 바꾸고자 하는 클래스 c로 바꿨다가 다시 c’으로 바꾸게 됨. Generator는 같은 것을 사용 함
◦
Domain classification에서 real class 부분은 Discriminator가 클래스가 진짜인걸 맞추려는 것
◦
fake class 부분은 Discriminator는 클래스가 진짜인거를 맞추려고 해서 c’으로 분류되도록 하고, Generator는 자기가 만들어낸 클래스로 속이려고 하는 것. c로 분류되도록 함
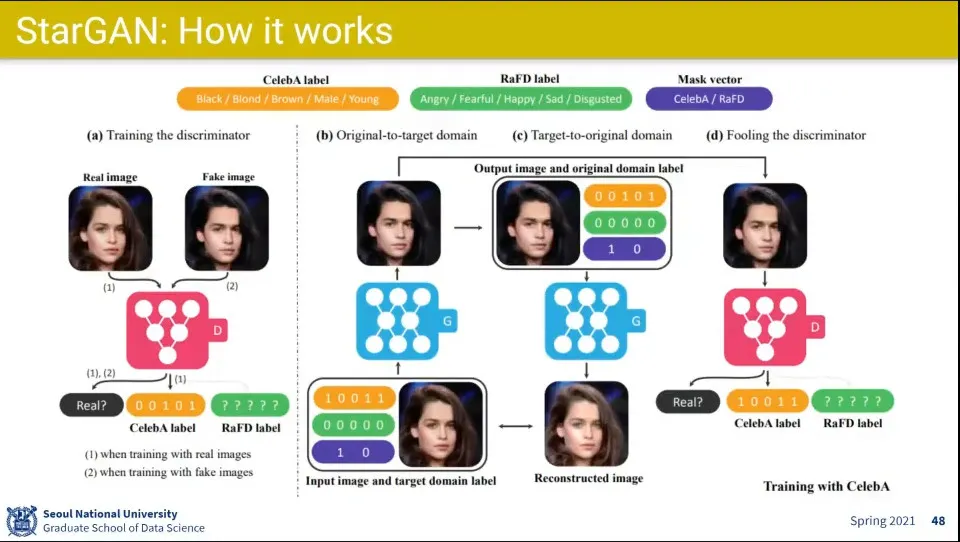
•
동작하는 방식
•
왼쪽 영역의 이미지는 Discriminator가 진짜인지 가짜인지를 맞추는 것은 기존과 동일
•
그 다음 오른쪽 영역의 이미지에서 왼쪽 아래가 최초 시작하는 이미지로 여자의 이미지이고 그것을 흑발의 남자로 바꿈
◦
그 후 바꾼 이미지를 다시 원래 이미지로 복원하고, 그 복원한 것과 원래 이미지의 픽셀단위로 차이를 학습함
•
추가로 바꾼 남자 이미지에 대해
◦
진짜인지 가짜인지 맞추고
◦
celebA label에 대해 Discriminator는 원래의 것을 맞춰야 하고, Generator는 자신이 만들어낸 것을 맞춰야 함

•
위 조건을 통해 이미지를 변형한 예

•
Generator는 black-box라서 해석 불가능했는데, 그걸 개선한게 StyleGAN
•
StyleGAN은 Generator에만 대한거였고 Discriminator는 아무거나 써도 된다고 함
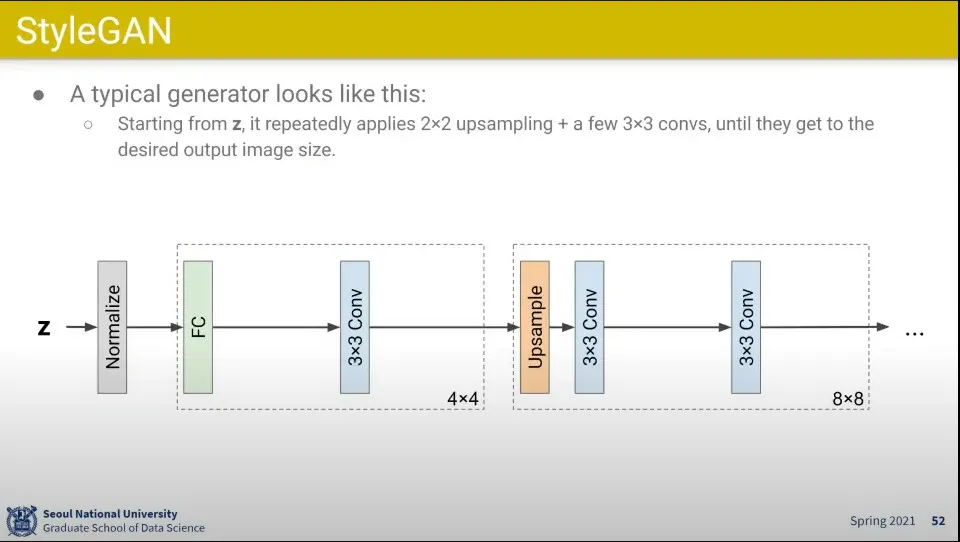
•
일반적인 Generator는 Z로부터 시작해서 Conv Layer를 통과하고 Upsampling 하면서 이미지 크기를 키워 감
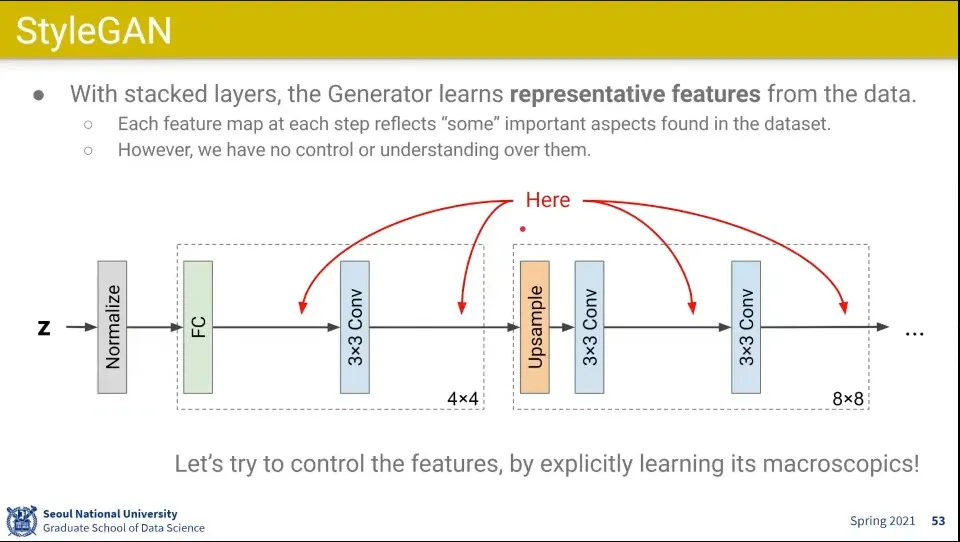
•
이런 방식에서는 Conv Layer를 통과하는 부분에 대해 해석이 안되고 컨트롤이 안 됨
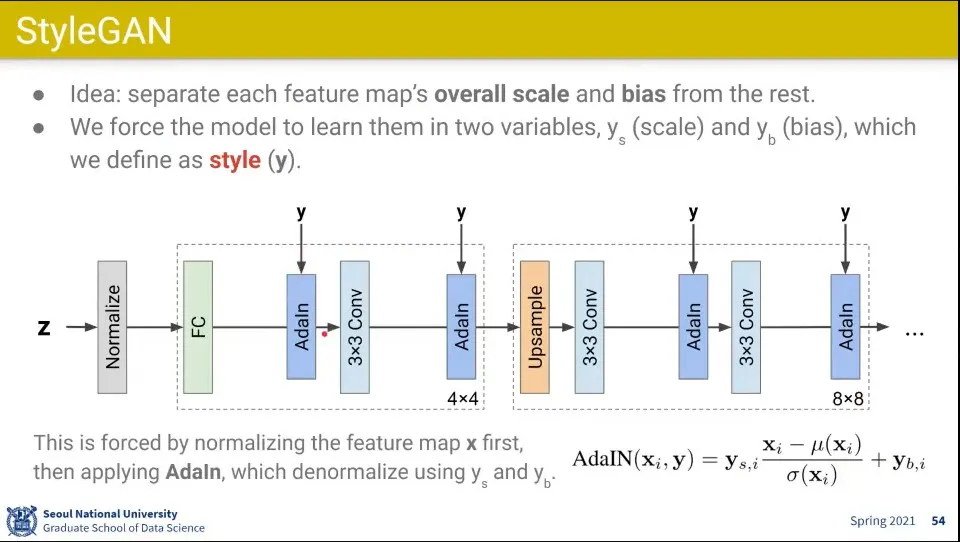
•
그래서 해당 부분에 style을 입힐 수 있는 vector를 추가함.
◦
일단 이전 layer를 통과한 데이터에 대해 normalize(평균을 뺴고 분산으로 나눔) 시킨 후에 거기에 scale을 곱하고 bias를 더해서 style을 입힘. 이걸 AdalN이라고 부름
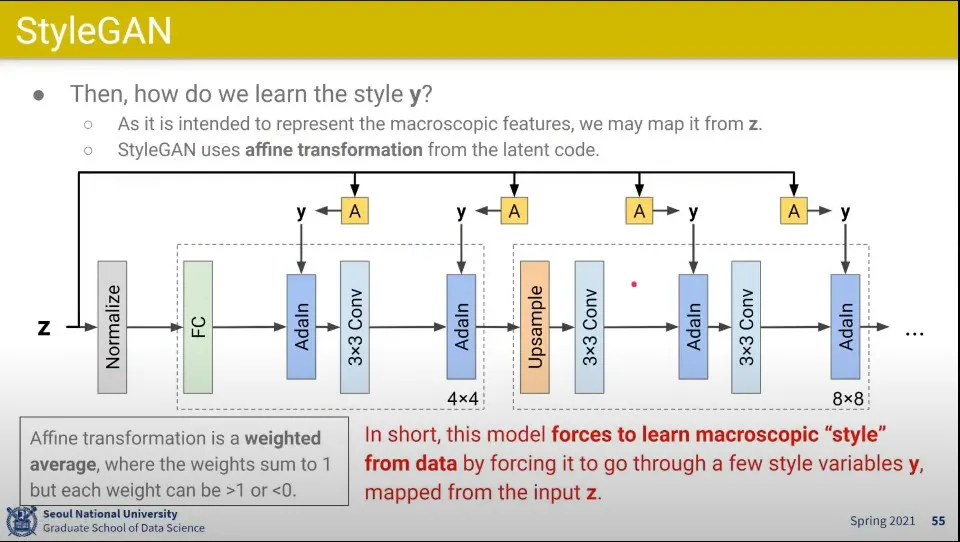
•
이걸 위해 affine transformation을 이용함
◦
위 그림에서 A가 Z로부터 affine transform 된 것이고, 그것을 이용해서 style 벡터 y를 만든다.
•
기본적으로 어떤 weight 들을 곱하고 더하는 것을 linear transform이라고 하고
◦
이때 그 weight들의 합이 1이 되도록하는게 affine transformation이라고 한다. (weighted average)
◦
추가로 그 weight들의 합이 1이면서 모든 weight이 0-1사이의 값이 되도록 하는게 convex combination - 이래서 확률처럼 보이도록 함. 확률 분포를 곱할 때 convex combination이라고 함
•
style 벡터 y를 거쳐가도록 해서 강제로 style을 주입할 수 있도록 함
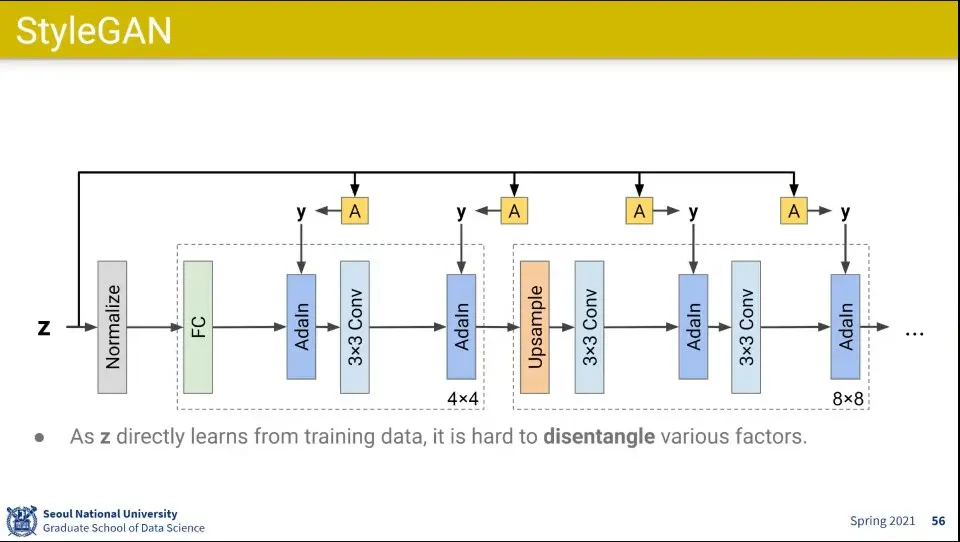
•
기존 학습 모델들은 factor들을 구분해 내는게 쉽지 않았음
◦
예컨대 일반적으로 학습 데이터에는 남자는 머리가 짧고, 여자는 머리가 긴데, 그렇다고 머리가 짧으면 남자는 아니고 머리가 길면 여자는 아님. 이 두 개는 별개의 요인인데, 학습 데이터만 가지고 학습을 하다보니 기존 모델들은 그런 것을 제대로 구분해내지 못했음
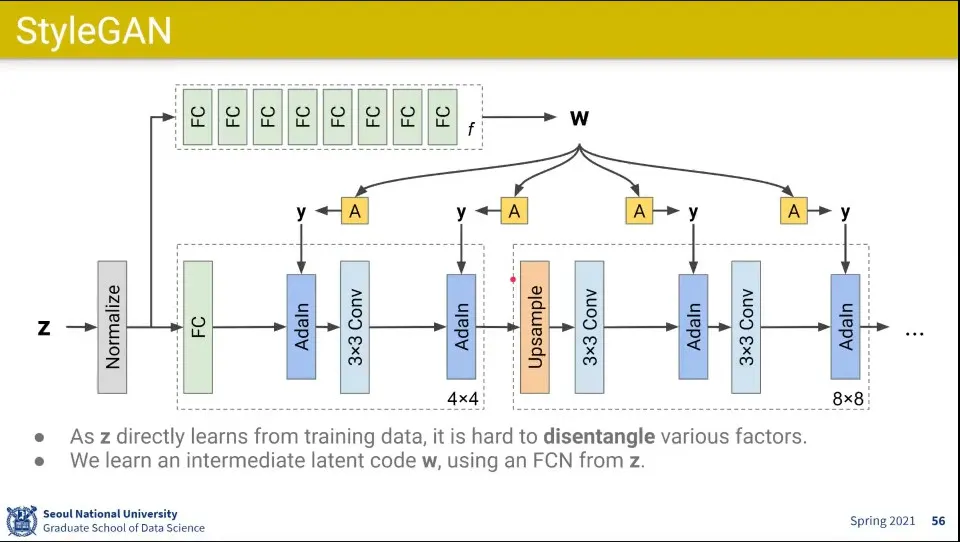
•
그런데 그걸 Z를 바로 사용하면 그것들을 분리해내는게 잘 안되서 fully-connected layer 여러층을 쌓은 것을 통과한 W를 먼저 만들고 그걸 affine transform 하도록 함
◦
Fully-connected 여러 레이어를 통과하면서 그런 요인들이 잘 분리가 됨
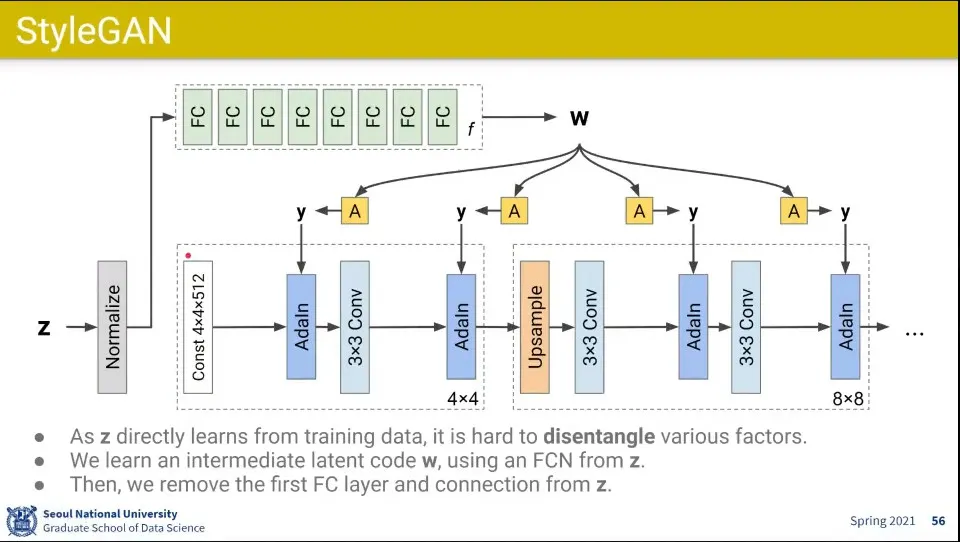
•
그러다 보니 Z에서 바로 넘어가는 path가 아예 필요가 없어짐
•
그래서 처음에는 아예 const 값을 이용해서 시작하고, 그 중간 중간에 Z에서 나온 style을 입혀서 생성하도록 하는 것
◦
const는 4x4의 아주 작은 값이고, 거기에 적절히 예컨대 사람의 얼굴 같은게 담겨 있어서 그것부터 시작하는 것
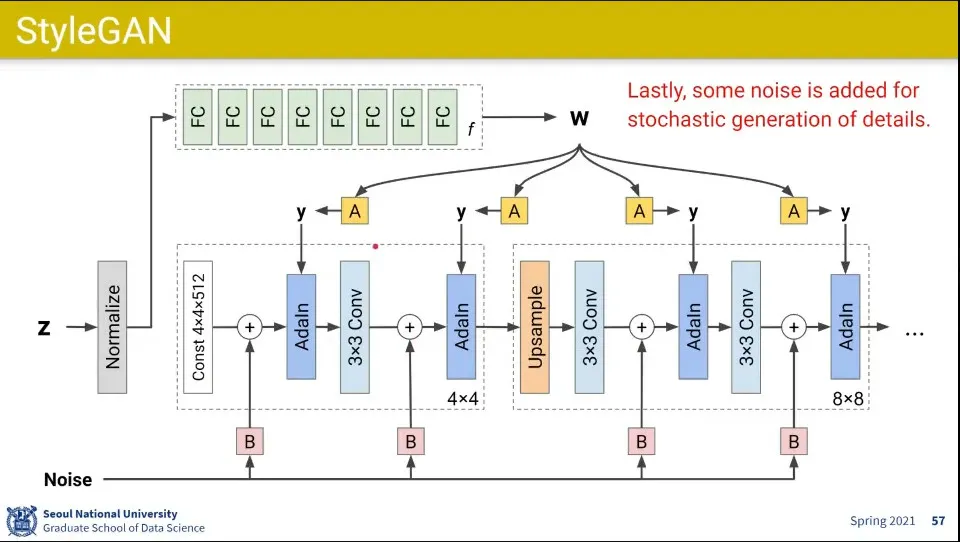
•
추가로 중간에 noise를 추가해서 다양한 베리에이션이 되도록 함
◦
이 noise들은 작은 단위에서 변화를 주는데, 예컨대 금발이라고 해도 다 같은 금발이 아닌 것처럼 그런 부분에 영향을 주고
◦
style 벡터는 남자인지 여자인지와 같은 보다 큰 개념에 영향을 줌
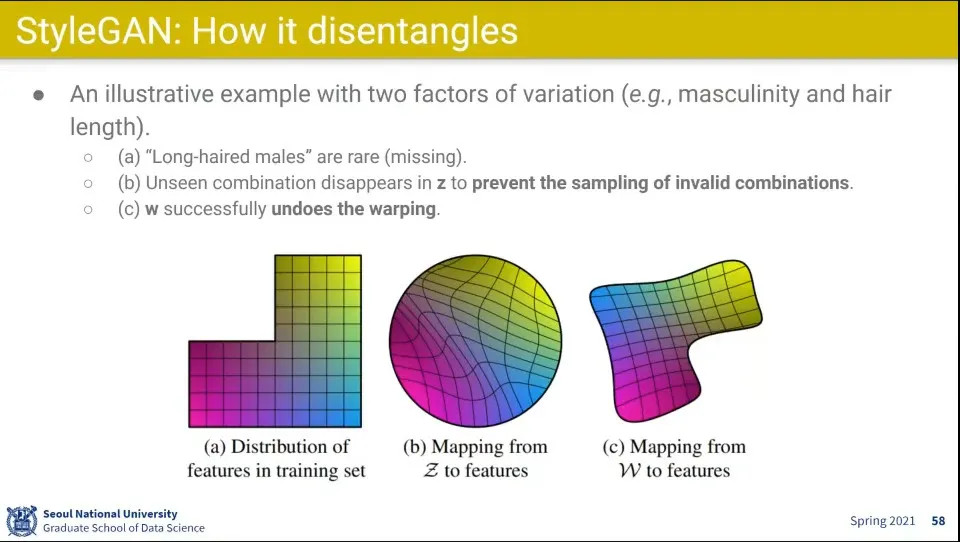
•
최초 학습 데이터가 다양성이 떨어지기 때문에 학습 셋이 a와 같은 모양이 됨
◦
남자이면서 긴머리 데이터는 많지 않음
•
그걸 이용해서 학습하면 학습 셋이 부족하다는 생각을 안하고 b처럼 완전하게 만들어 버림
•
그걸 강제로 스타일을 주입해서 분리해내면 c 처럼 실제와 비슷하게 구성할 수 있음

•
Style은 여러 레벨에서 변경해 줄 수 있음. Coarse, Middle, Fine
