

•
이전에는 Image에 대한 Multimodal을 봤고 이번에는 Video에 대해 보겠다.

•
이미지와 달리 video에는 sequence가 있다.
•
비디오, 텍스트 pair 데이터는 유튜브나 동영상 자막(ASR) 등을 이용해서 수집한다.

•
VideoBERT는 BERT에 Video를 적용함
◦
특정 장면과 말이 관련이 있다는 가정으로 학습
◦
말을 안 하는 영상도 있고, 뮤직비디오 같은 경우는 텍스트와 영상이 관련 없기 때문에 요리 영상을 이용해서 학습 함

•
이미지는 Faster R-CNN을 이용해서 Mask를 씌워서 할 수 있지만, Video에서는 특정 frame을 mask 씌우고 할 수가 없음. —video의 frame에 mask를 씌우면 계산량이 너무 많아짐
◦
그래서 clustering을 돌림.
◦
그랬더니 mask 된 프레임에 클러스터된 다름 프레임을 집어 넣게 됨. 그런데 맥락은 맞음
◦
이것은 마치 말에서도 단어가 여러 의미를 갖고 있는 것과 비슷하게 mask 된 프레임에 맥락에 맞는 다른 영상의 frame을 가져옴
•
픽셀 단위로 영상을 채우는 것은 못하지만 다른 영상의 것을 가져옴
•
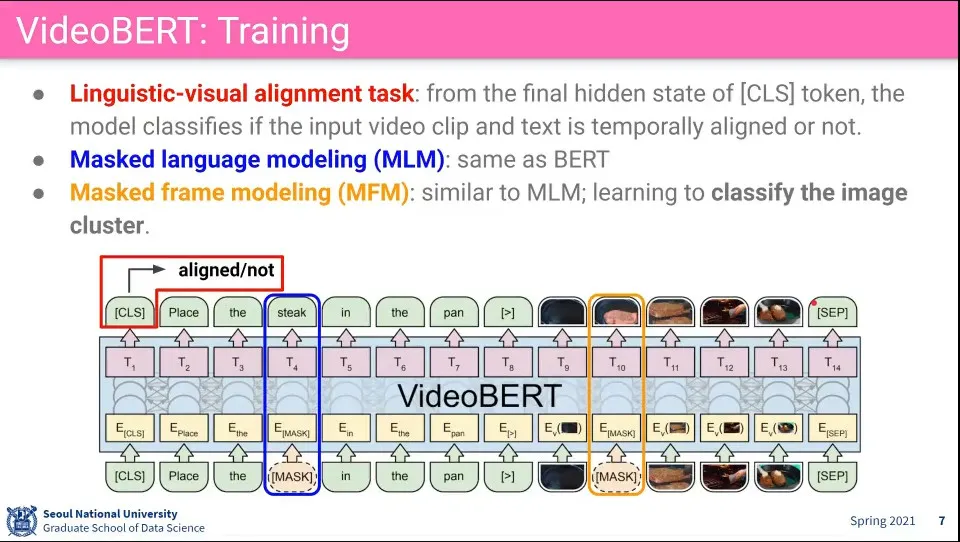
VL-BERT와 비슷하게 텍스트와 Video의 Frame을 같이 집어 넣음
◦
Visual 정보와 텍스트 정보가 관련 있는지를 학습
•
Text에 BERT에서 하는 것처럼 Mask를 씌움 (MLM)
•
Video에는 Frame에 Mask를 씌움 (MFM)
•
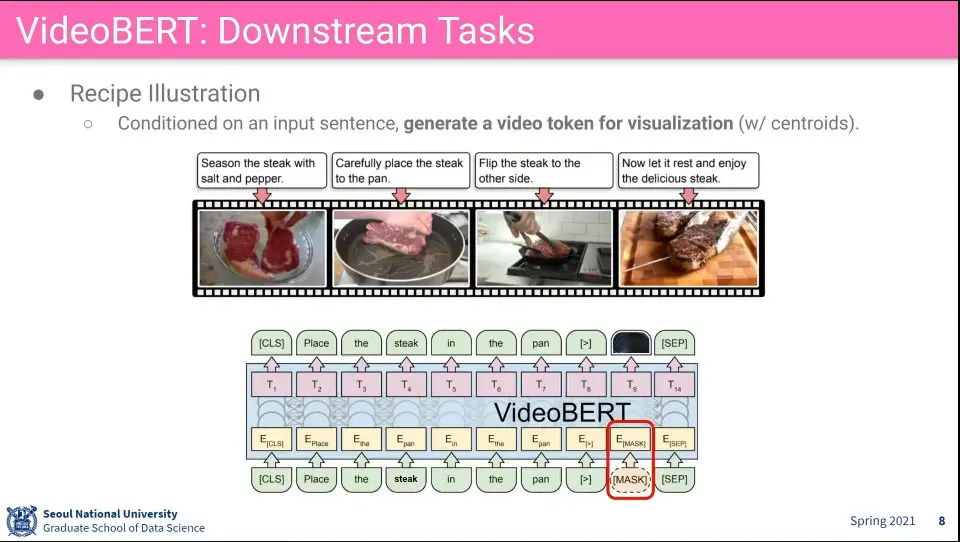
text를 받아서 video에서 조건에 맞는 frame을 가져옴
•
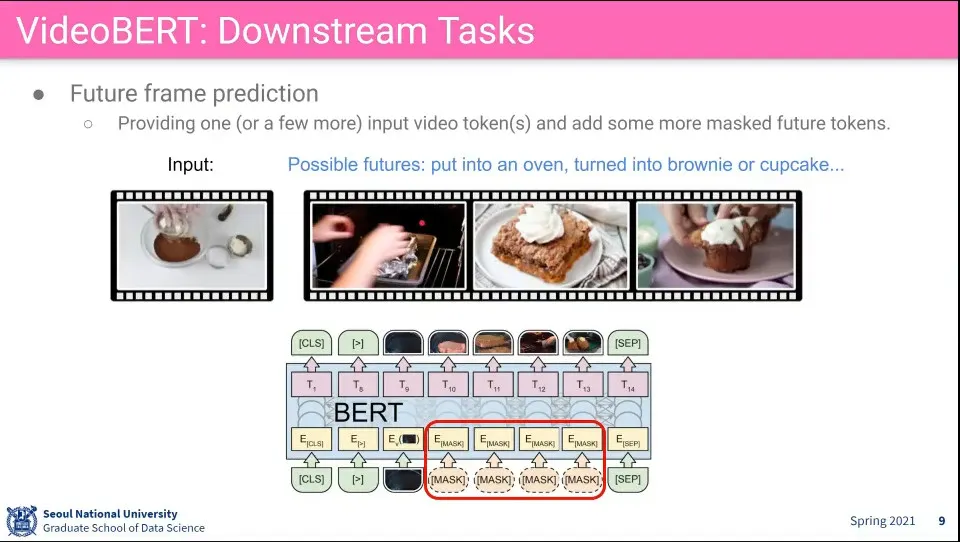
연속된 frame을 mask 씌우고 주어진 영상 다음에 뭐가 나와야 할지를 맞추는 문제
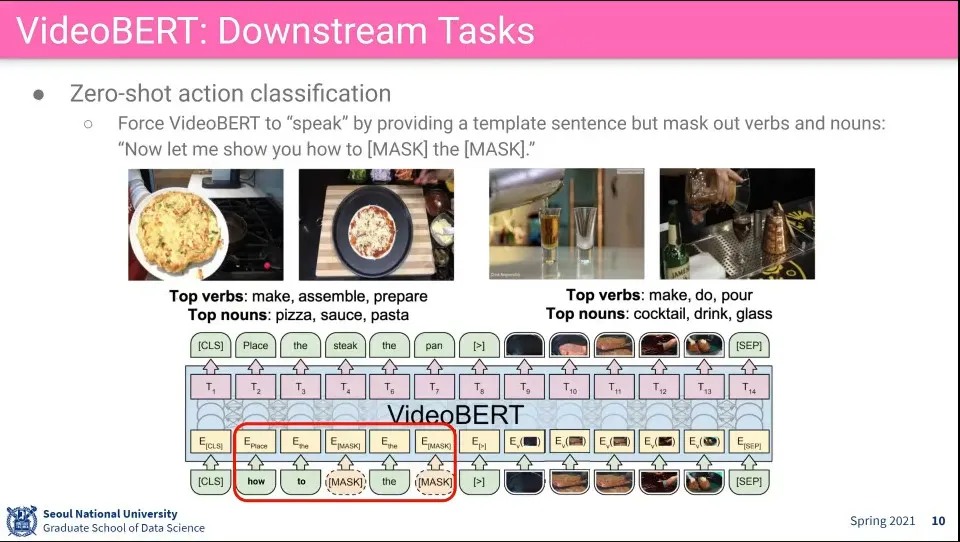
•
영상을 보고 뭘 하고 있는지를 맞춤.
◦
이때 text에는 일부만 mask를 씌워서 사용
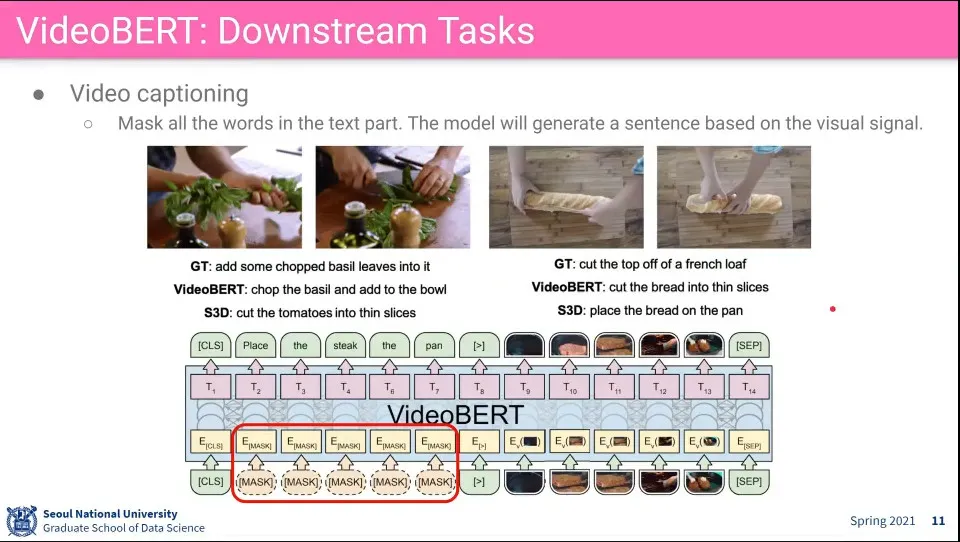
•
이거는 아예 모든 text에 mask를 씌워서 captioning을 함
•
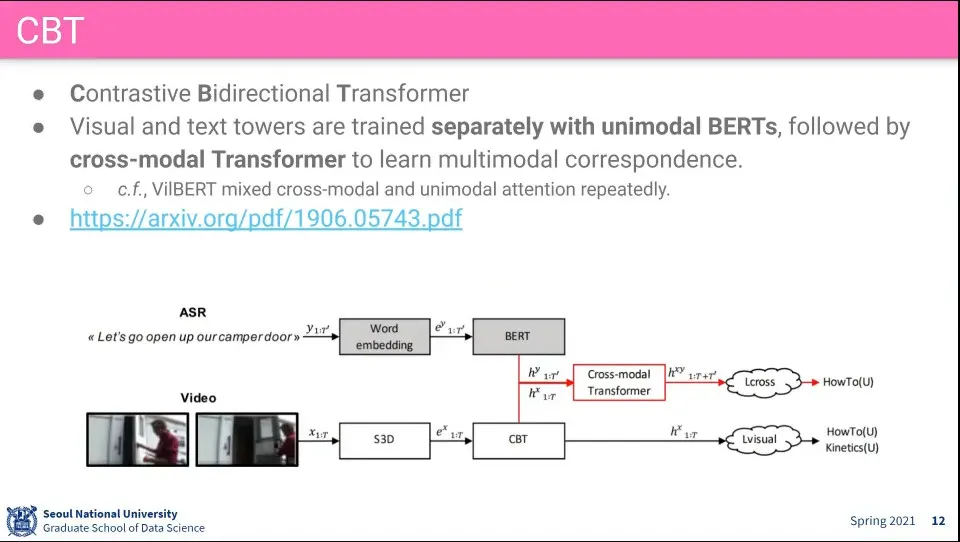
VideoBERT에서 클러스터링 하는 부분 때문에 End-to-End 학습이 안되서 그걸 수정한 것이 CBT
◦
Video 쪽에 CBT(Contrastive Bidirectional Transformer)를 추가함
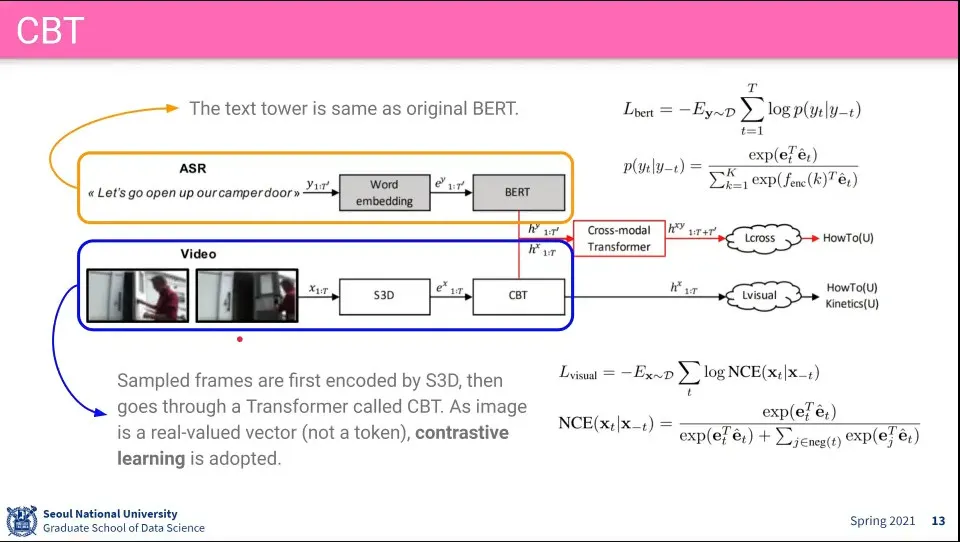
•
Text 쪽은 기존 BERT와 동일
•
Video 쪽은 모든 frame에 대해 softmax를 구하기 어려우니 전체에 대해 구하지 않고 일부에 대해 Negative를 구분해서 처리 함. contrastive learning에서 했던 것
◦
원래 하던 클러스터링을 NCE를 이용해서 함
◦
clustering이 들어가면 backpropagation이 안되기 때문에 end-to-end가 안 됨
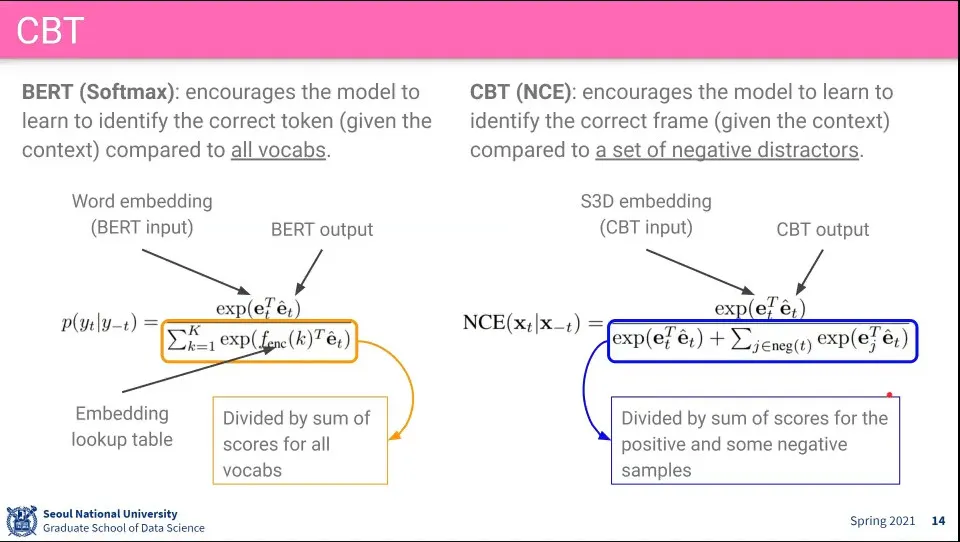
•
text를 처리하는 부분은 기존과 동일 - BERT(softmax)
•
video를 처리하는 부분에서는 전체가 아니라 일부 샘플에 대해 positive, negative sample을 구해서 clustering을 함

•
이렇게 해서 end-to-end 학습이 된다.
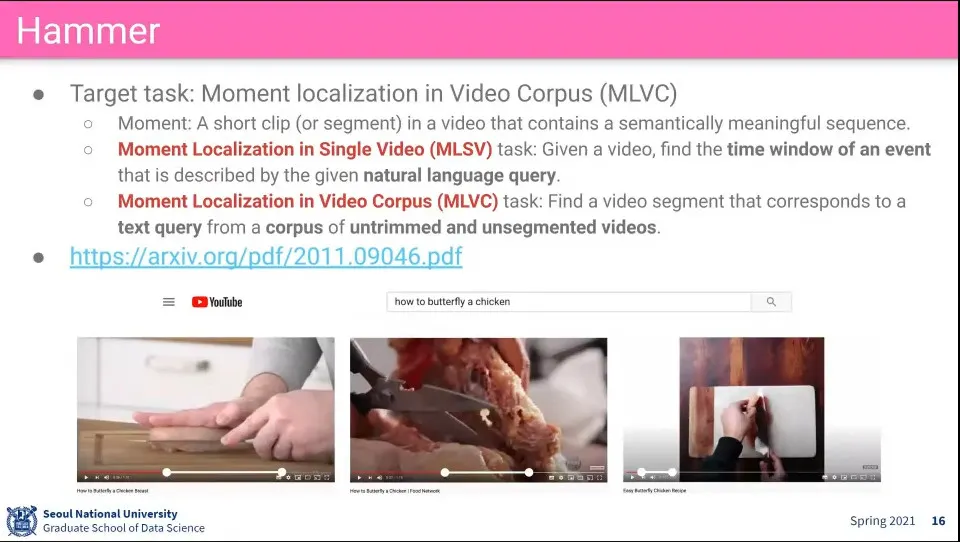
•
Hammer는 텍스트가 묘사하고 있는 내용이 비디오의 어느 부분에 있는지를 찾음
◦
한 개의 Video가 아니라 여러 개의 Video에서 각각 어느 부분을 봐야 하는지를 찾는게 목표. 아직은 잘 안 됨
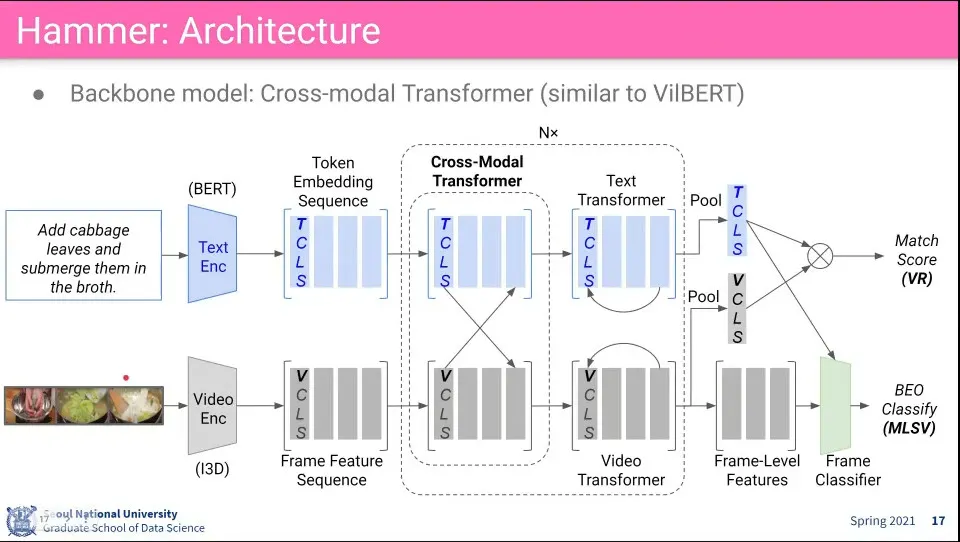
•
모델은 VilBERT를 이용해서 함
◦
이미지가 들어가던 것이 video가 들어가는 걸로 바뀜
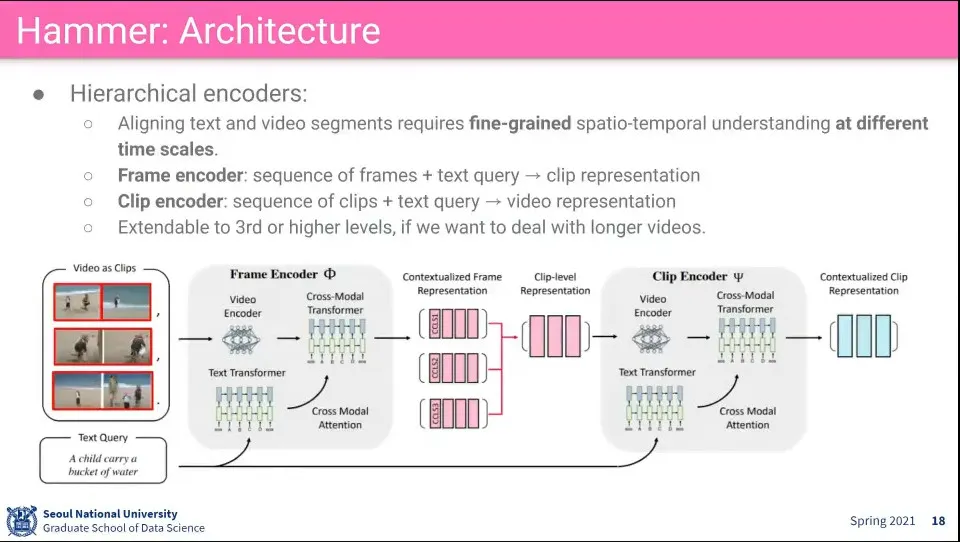
•
추가로 video를 encoding 할 때 작은 clip 단위로 하고, 좀 더 큰 clip 단위로 하고, 그렇게 몇 개의 level 단위로 나눠서 학습함
◦
실제로 할 때는 2단계까지만 함
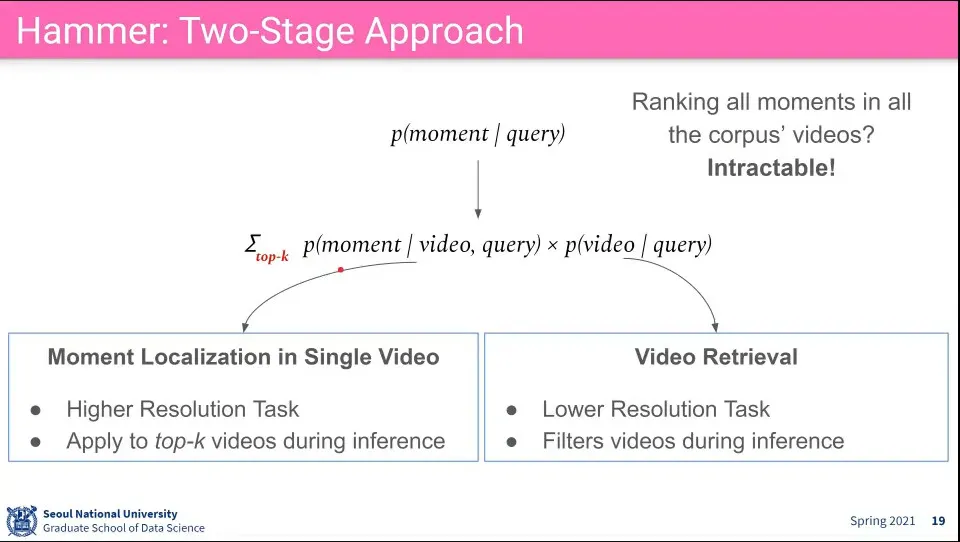
•
모든 video에 대해 모든 순간을 찾을 수는 없기 때문에 2단계로 나눠서 처리함
◦
일단 비디오를 찾고
◦
찾은 비디오에서 moment를 찾음
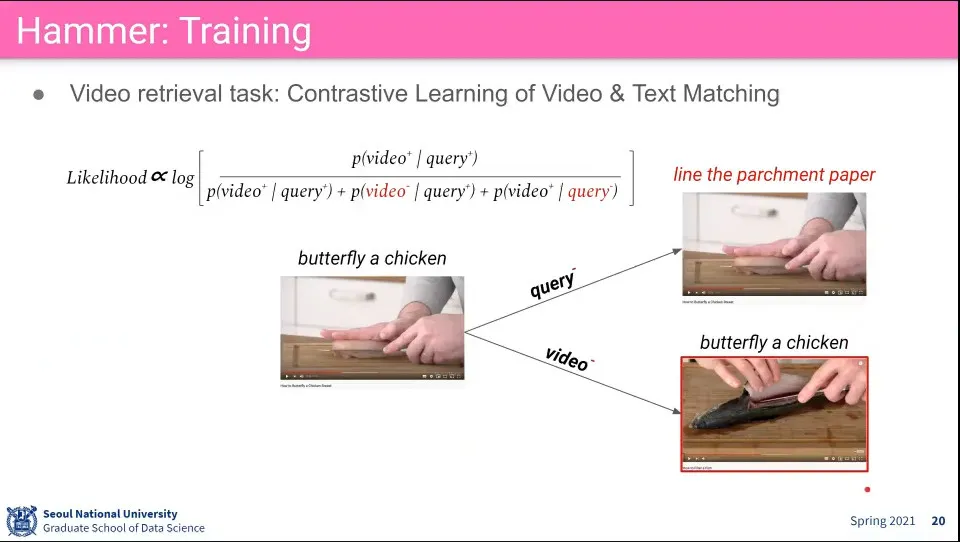
•
Text에 대해 랜덤한 것을 넣고 Video에 대해서 랜덤한 것을 넣어서 Negative를 만들고 Contrastive Learning을 함
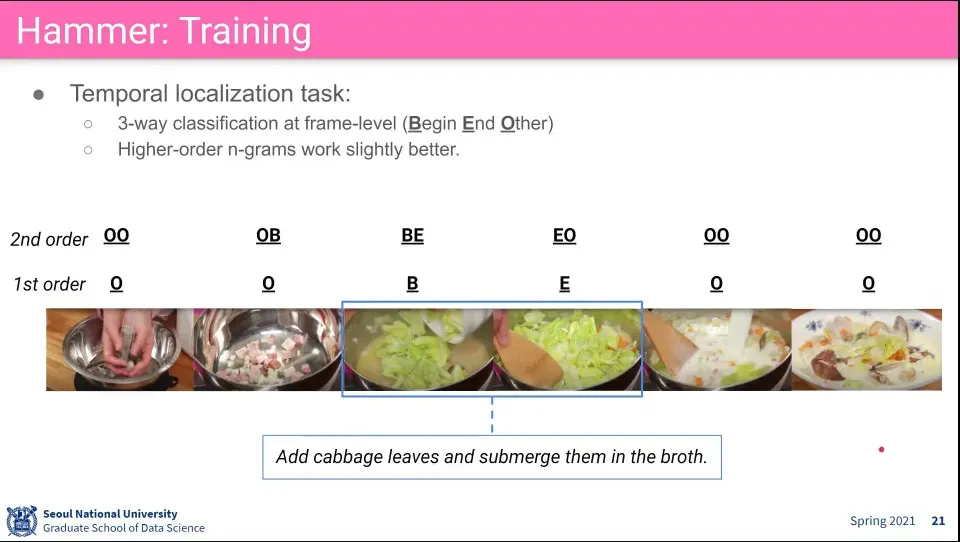
•
시간적인 위치를 처리하기 위해 frame을 Begin, End, Other 3개로 나눠서 학습 함
•
추가로 2nd order로 2개씩 조합해서 —OO, OB, BE, EO, OO 등— 학습하면 성능이 더 좋아짐
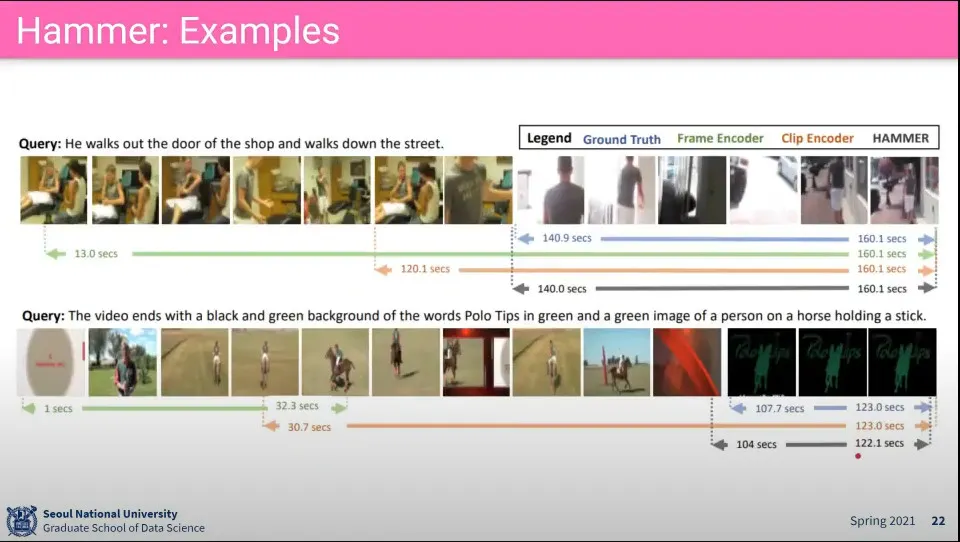
•
예시

•
MFM, VSM, MLM, FOM을 모두 합한 모델이 HERO
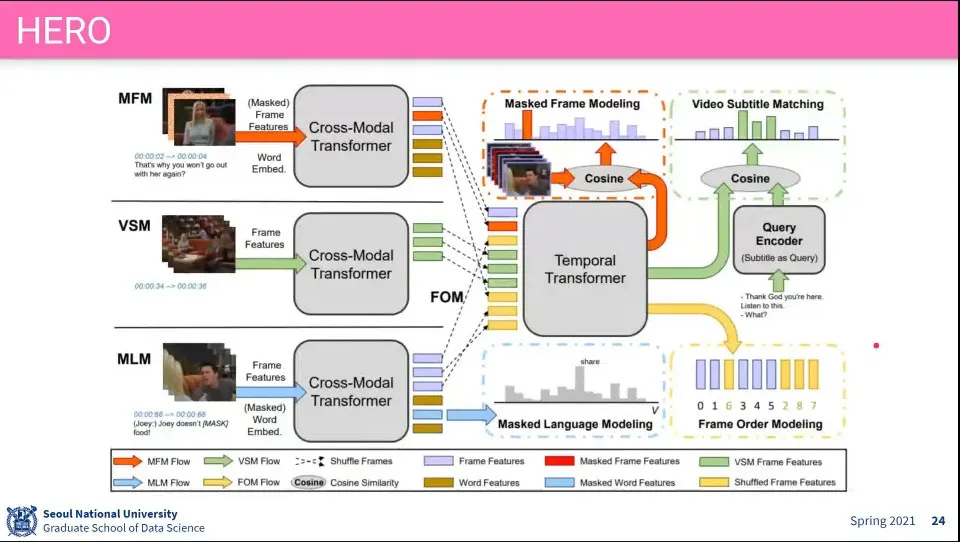
•
모델 구성 - 기존에서 나왔던 기법들을 합해서 돌려봤다
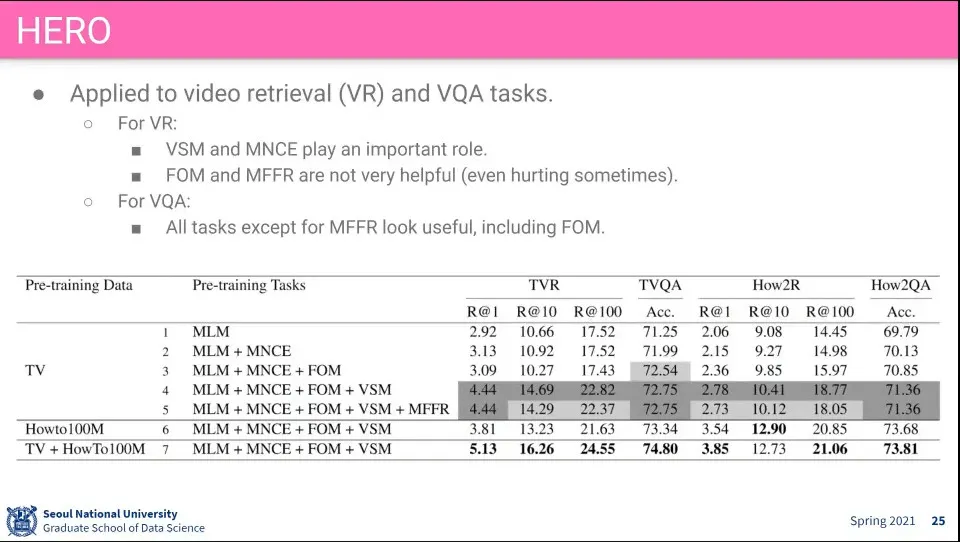
•
결과 성능

•
이미지를 보고 Caption을 생성하는 것
•
학습 데이터는 이미지와 labeling 된 text가 pair로 주어짐
•
그걸 학습해서 새로운 이미지가 주어졌을 때 caption을 생성해 내는 것

•
이걸 하기 위한 4가지 모델

•
LRCN은 이미지에 대해 CNN으로 feature를 뽑고, 그것들을 LSTM을 돌려서 평균 냄
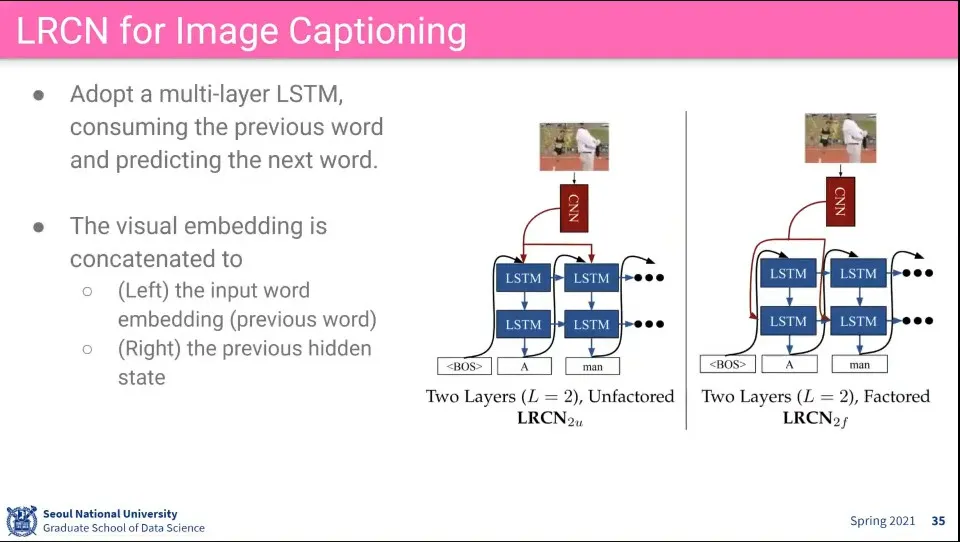
•
LRCN으로 captioning 할 때도 비슷하게 CNN와 LSTM을 이용함
•
이때 LSTM으로 auto regressive 하게 output을 뽑는데
◦
CNN에서 뽑은 Feature를 input으로 넣는 경우도 있고, hidden state에 넣는 경우로 할 수 있음
◦
결과적으로는 비슷함


•
NCE를 이용한 captioning
◦
positive에 대해 진짜 이미지와 caption pair을 넣어주고
◦
negative에 대해 랜덤하게 이미지와 caption pair을 넣어줌
•
진짜에 대해 확률을 높여주고 가짜에 대해 확률을 낮춰주는게 목표
◦
maximize이기 때문에 loss 함수하고 할 수 없음

•
이미지와 caption을 이용하는 식으로 수식을 바꿈
•
이 모델을 이용하면 caption을 distinguish 하게 만들어 준다.

•
예제에서 녹색으로 표현된 것이 보다 구별된 caption. 보다 구체적으로 나옴
◦
그 위의 AA는 이전의 general 한 caption

•
Attention을 이용한 captioning 방법
•
input image에 대해 LSTM을 이용해서 문장을 만드는데, 그때 attention을 걸어서 어느 부분을 보는지를 확인
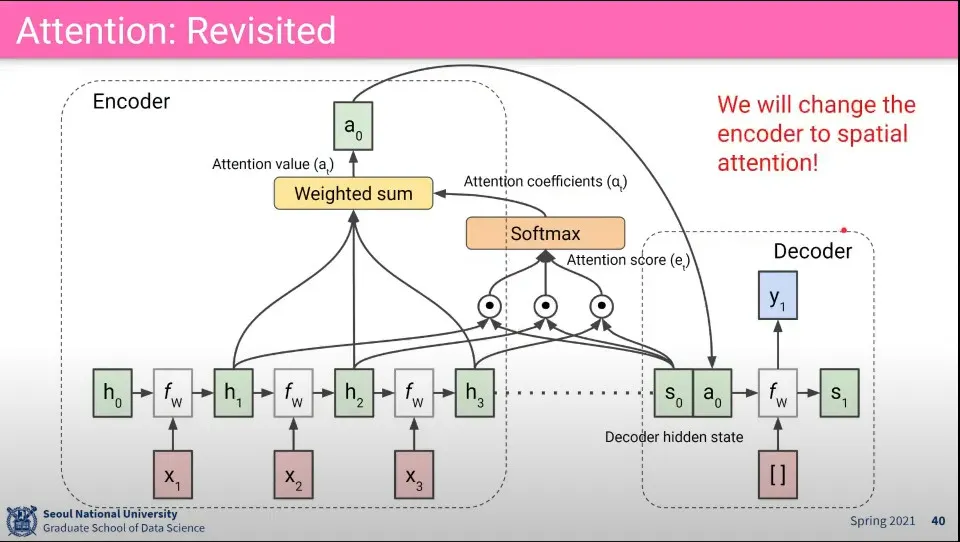
•
Attention 흐름
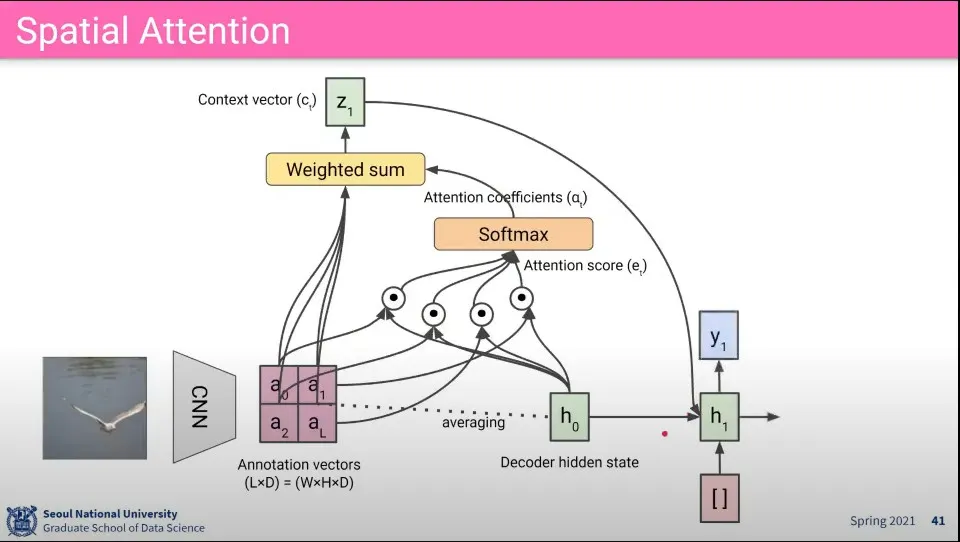
•
공간 정보를 찾기 위한 Attention 적용 흐름 - 흐름 자체는 동일하다.
◦
일단 CNN에서 뽑은 feature 들에 대해 attention score를 구하고 softmax 씌워서 attention coefficients 구하고 그걸 다시 weighted sum 해서 최종적으로 context vector Z를 구함
◦
그 Z를 다음 hidden state에 input으로 넣어서 output을 출력 함
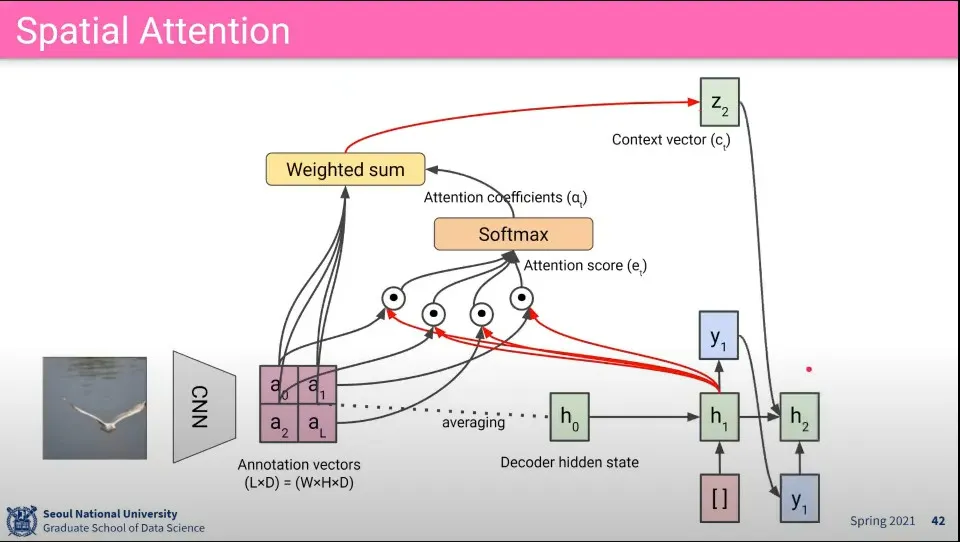
•
다음 hidden state에서 같은 과정을 반복해서 다시 output을 만들고 다음 state로 넘어가는 것을 반복 함

•
Q, K, V는 위와 같이 정의 됨

•
output 만들 때는 현재 구해진 context vector Z와 전단계 hidden state, 전단계 output에 적절한 하이퍼파라미터를 곱해서 구함

•
Soft attention은 이미지 전체 픽셀이나 feature 단위로 weight가 정해짐.
•
Hard attention은 attetntion 할 한 점을 찍음
•
일반적으로 attention 하면 soft attention을 많이 쓴다.

•
이 모델의 예제

•
이건 실패한 예제

•
시간 Attention을 이용해서 Video의 Caption 달기
•
비디오이기 때문에 3D-CNN을 사용함
•
LSTM 기반으로 Temporal Attention을 함
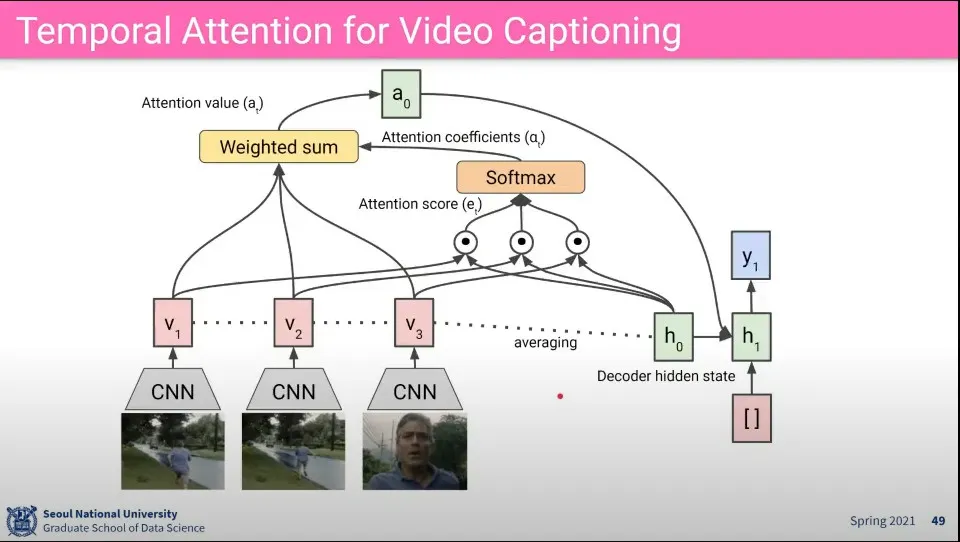
•
이미지에서 attention 한 것과 동일한데 비디오 이므로 시간에 attention을 걸어 줌
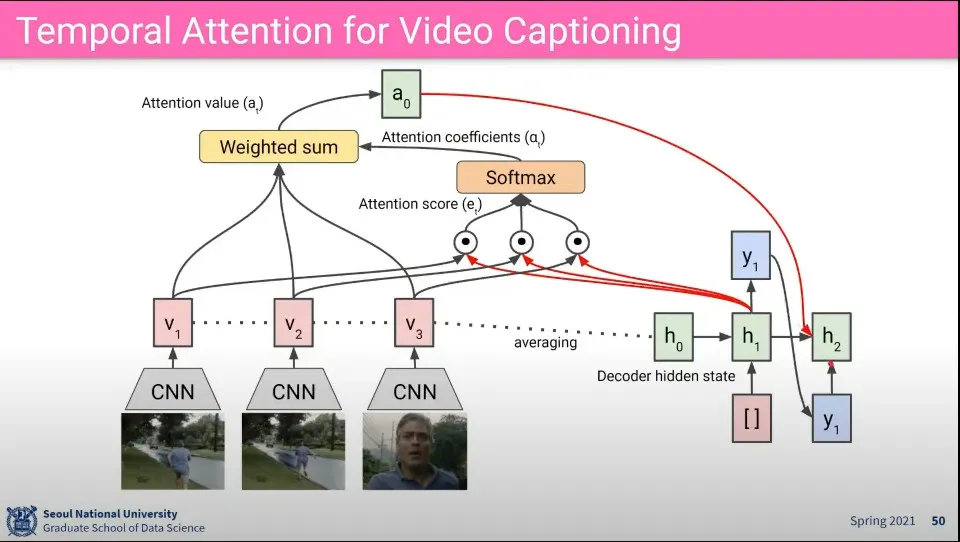
•
이후 과정은 동일

•
Q, K, V는 위와 같다
