
•
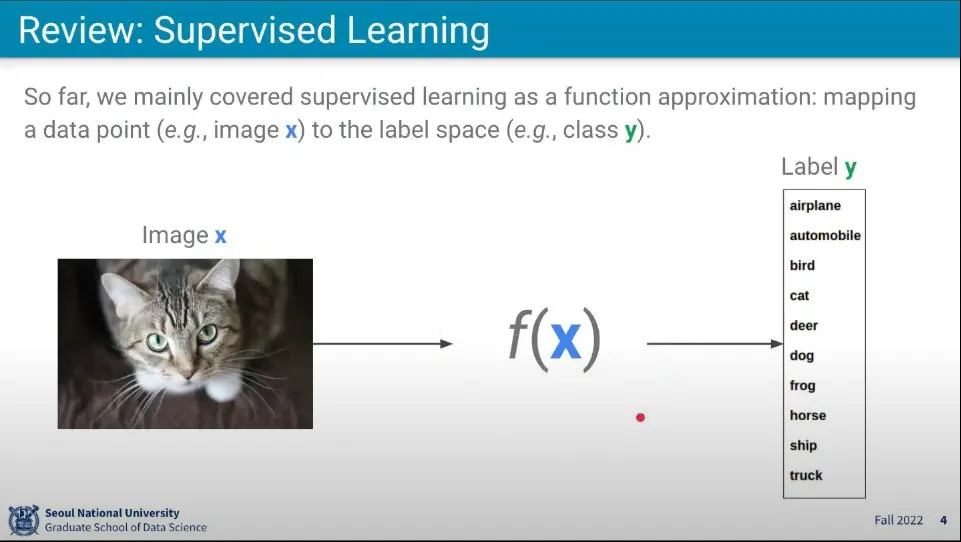
이전까지 배운 것은 Supervised Learning

•
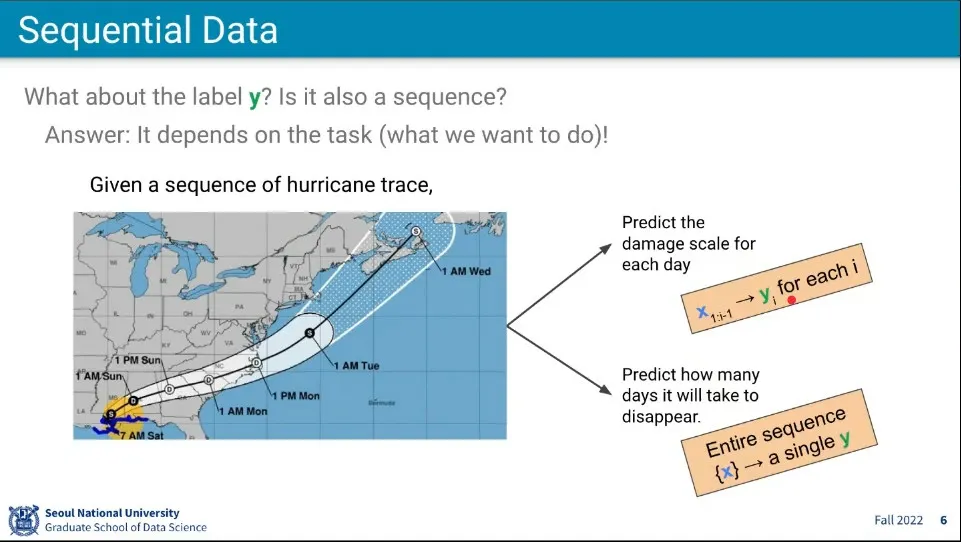
만일 x가 하나의 이미지가 아니라 무언가의 sequence라고 한다면, 그것을 어떻게 모델링 할 수 있을 것인가? 현실의 데이터는 많은 경우 sequence가 존재함
•
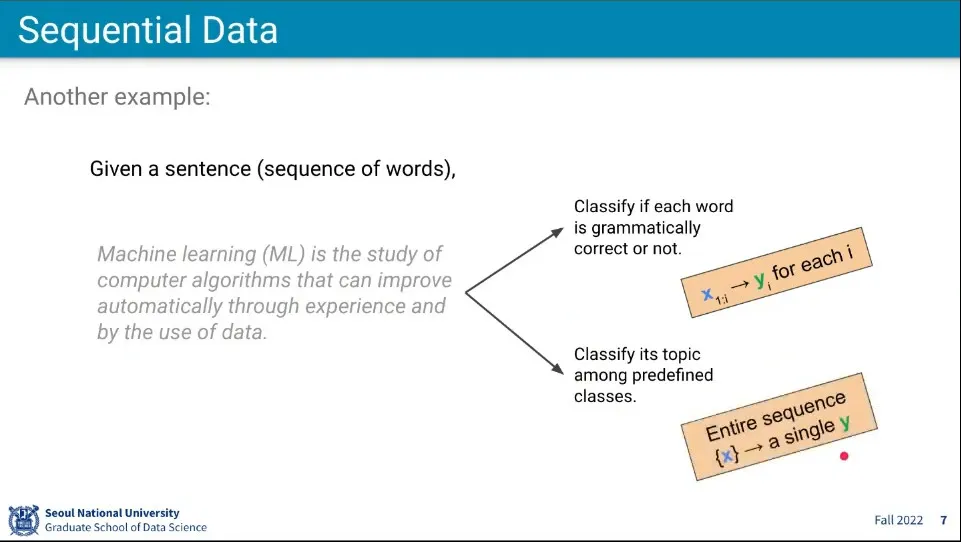
x가 시퀀스로 주어졌다면 y도 시퀀스일까?
◦
그럴 수도 있고 아닐 수도 있음. 문제에 따라 다르다.
•
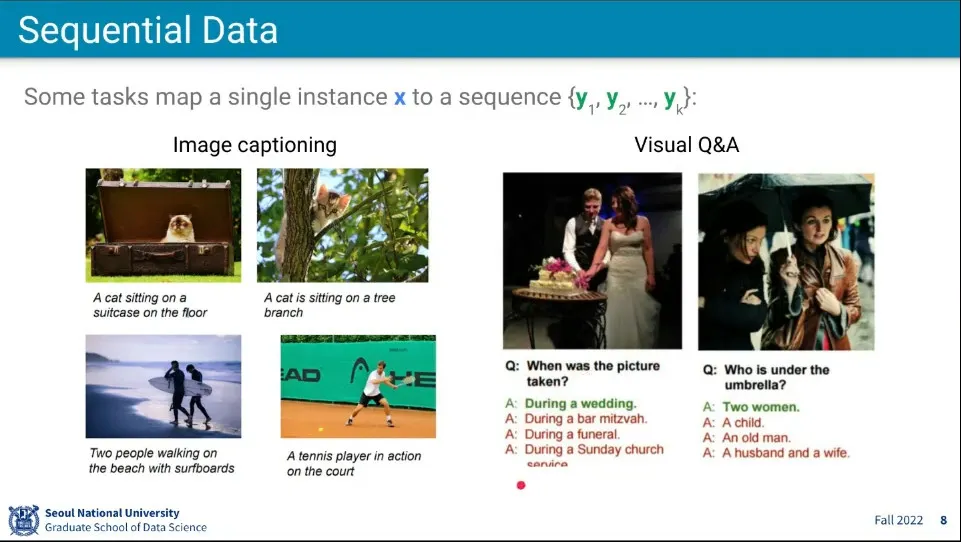
x는 시퀀스가 아닌데, y가 시퀀스일 수 있음
◦
이미지를 보고 문장을 만들어내는 것은 x는 싱글인데, y가 시퀀스인 예

•
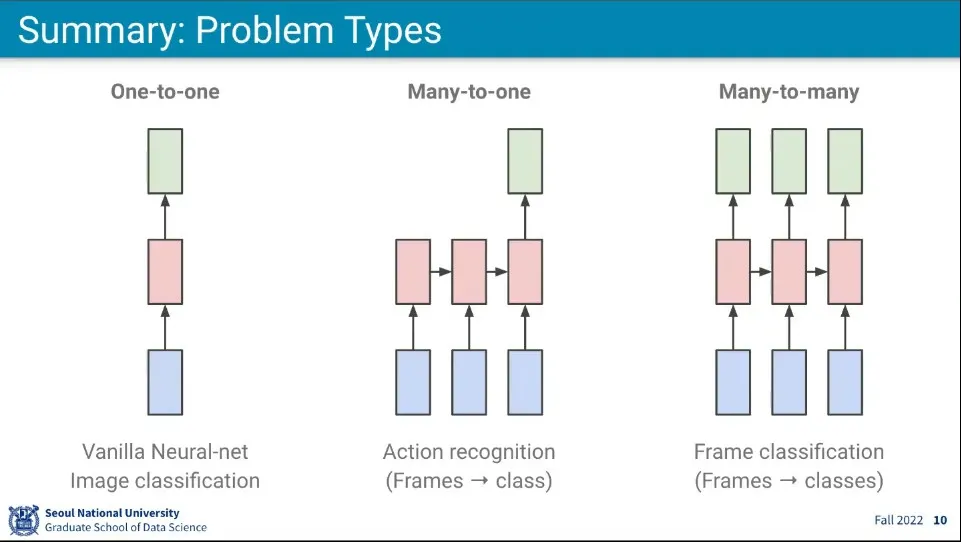
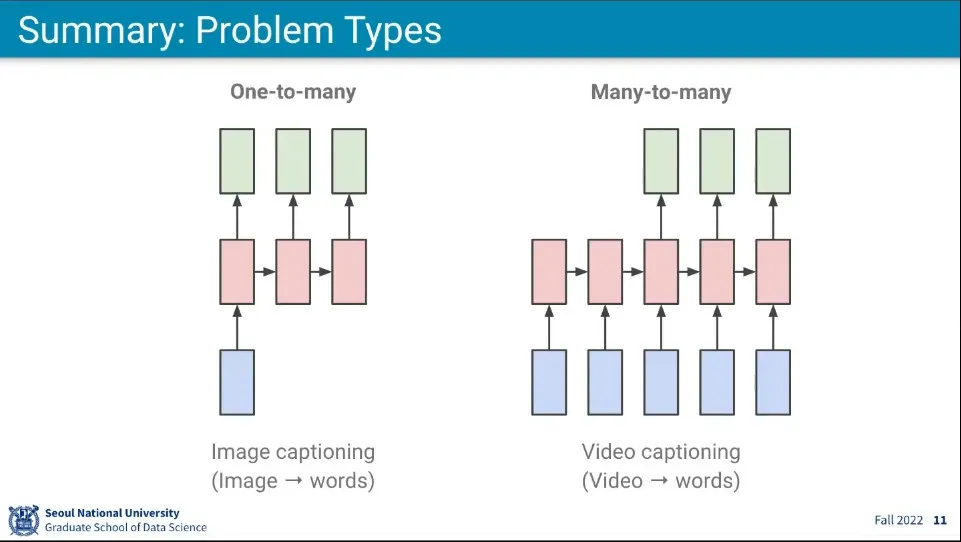
더 복잡한 문제들도 있다.
•
문제의 종류는 위와 같은 것이 가능하다.

•
단어에 대한 몇 가지 정의
•
우리는 말을 할 때 개별 단어의 의미를 생각하면서 말을 하지 않는다.

•
각 단어를 벡터로 표현한 것을 Word Embedding이라고 하고 이게 언어 딥러닝 모델링의 시작

•
데이터 기반으로 단어를 처리하는 것은 그것과 가까운 단어를 표현하는 것

•
Word2Vec은 모은 데이터셋을 이용해서 어떤 단어에 대해 그 단어의 앞, 뒤로 나올 수 있는 단어들의 확률을 구하는 것
◦
into라는 단어의 앞에 혹은 뒤에 어떤 단어가 나올지를 구한다.

•
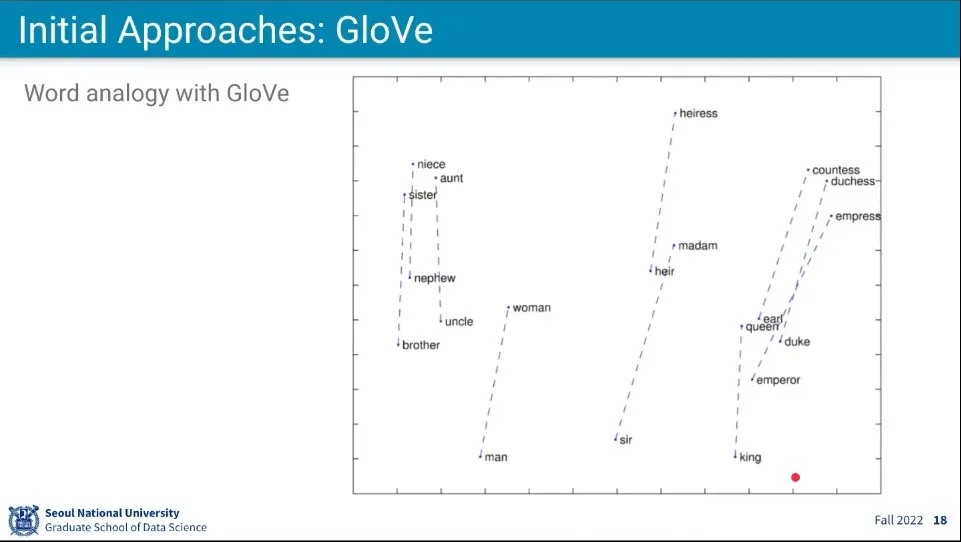
또 다른 방식은 GloVe
◦
Word2Vec과 달리 한 단어만 보지 않고, 두 단어가 같이 있을 때 어떤 단어가 나올 확률을 구한다.
◦
ice와 steam에 대해 각각 확률을 구하고, ice와 steam이 함께 나올 때 (조건부 확률, ice가 나온 상태에서 steam이 나올 확률) 나올 수 있는 단어의 확률을 구한다.
•
그 방식을 이용하면 위와 같이 단어에 대해 여성-남성형 연결도 가능하고
•
Word 들에 대해 연산이 가능해짐
◦
queen에 woman을 빼고 man을 더하면 king이 된다.
•
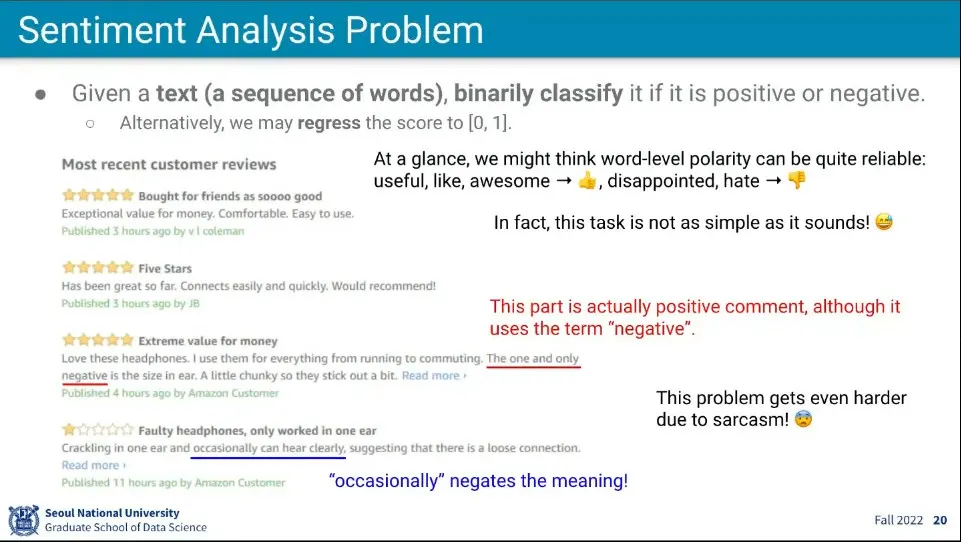
many to one의 예
◦
리뷰 문장을 받아서 긍정적인지 부정적인지 결과를 판단한다.
◦
문장의 의미만 봐서는 이해하기 어렵다. 반어적으로 이야기할 수 있기 때문
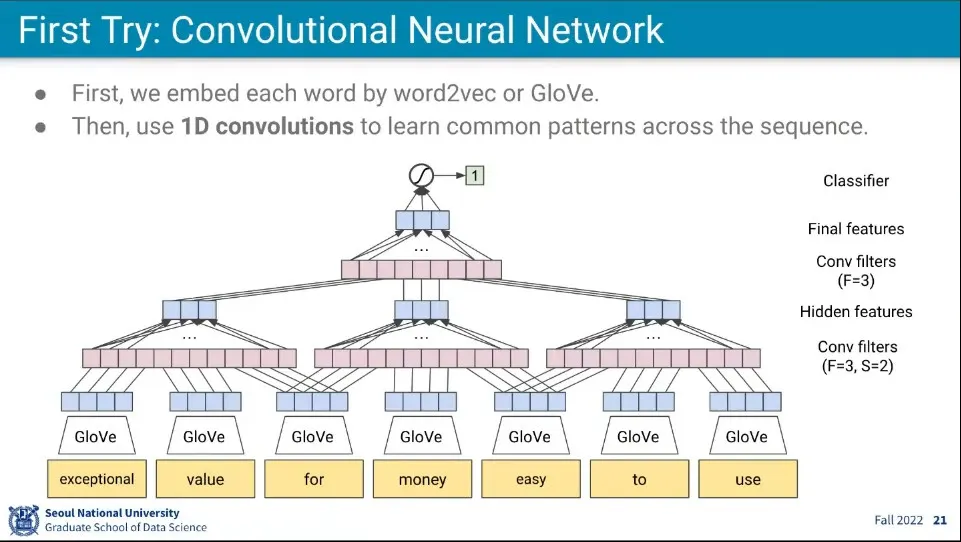
•
CNN을 이용해서 시도
◦
문장이기 때문에 1차원이고, Layer를 쌓아서 결과를 뽑음
◦
벡터화 해야 하기 때문에 input에서는 GloVe(혹은 Word2Vec)을 이용해서 벡터화 해준다.

•
CNN을 이용하려면 크기가 고정되어야 하는데 문장은 다양한 길이가 존재하기 때문에 사용하기 어렵다.
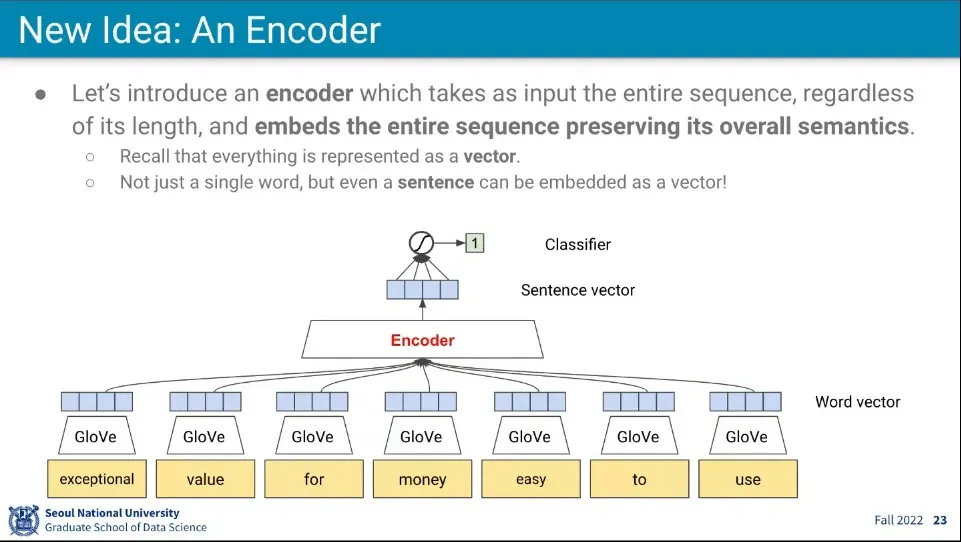
•
CNN의 문제를 해결하기 위해 Encoder라는 개념을 사용
◦
전체 문장을 길이에 상관없이 한번에 받아서 Encoding해서 Sentence Vector를 만들고 그에 대해 Classifier를 수행한다.
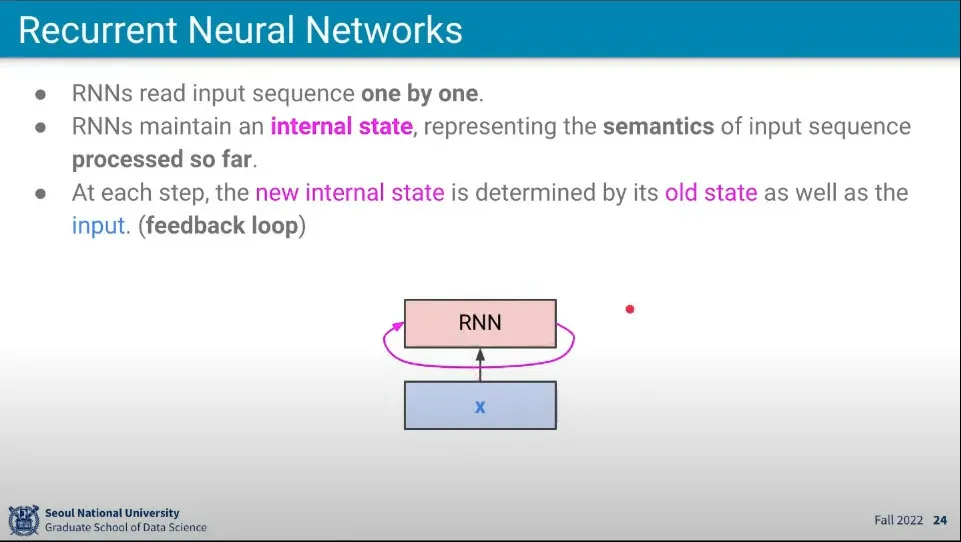
•
이렇게 된 것을 RNN을 이용해서 학습을 수행한다.
◦
RNN은 매 단계에서 새로 들어오는 Input을 추가해서 state를 업데이트한다.
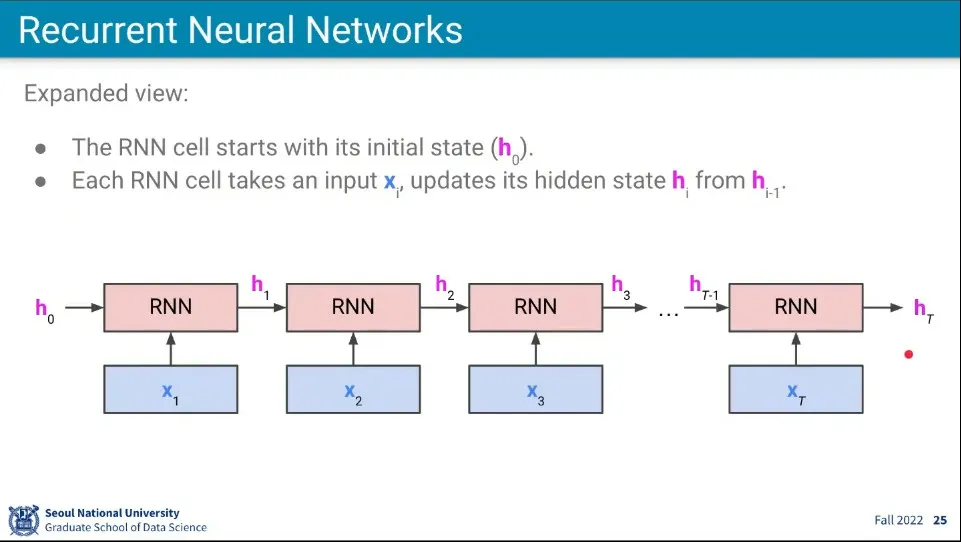
•
순차적으로 단어를 받아오면서 상태를 업데이트한다.
◦
상태는 의 입력을 모두 갖고 업데이트 된 상태이다.
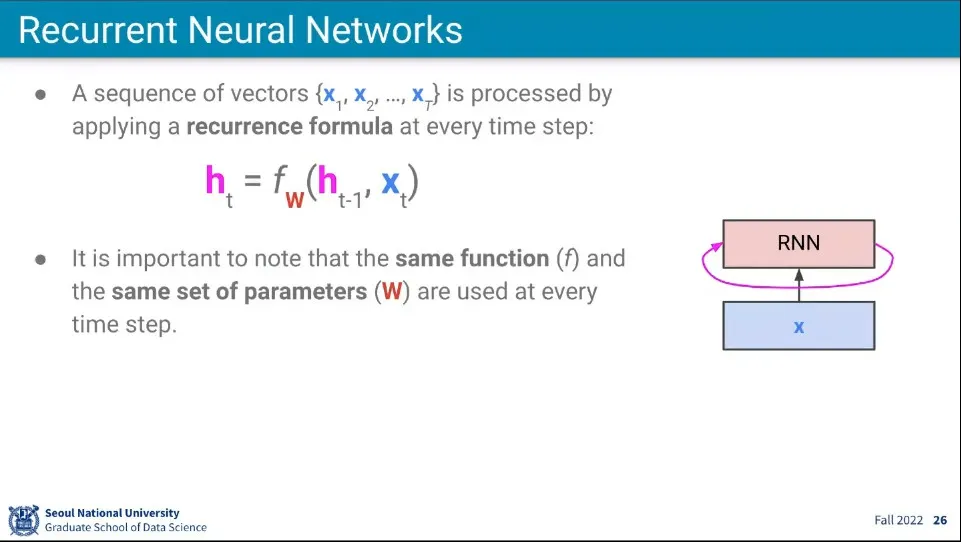
•
식은 위와 같이 할 수 있다.
◦
새로운 상태()는 기존 상태()와 새로운 input()을 함수 에 넣어서 구한다.
◦
이때 함수에 쓰이는 가중치 는 고정된 것을 사용해야 하는데, 만일 단계별로 다른 를 써주려면 input의 길이가 가변적인 것을 처리할 수 없기 때문. 어떤 길이의 input이 들어오더라도 처리 가능하려면 는 고정되어 있어야 한다.
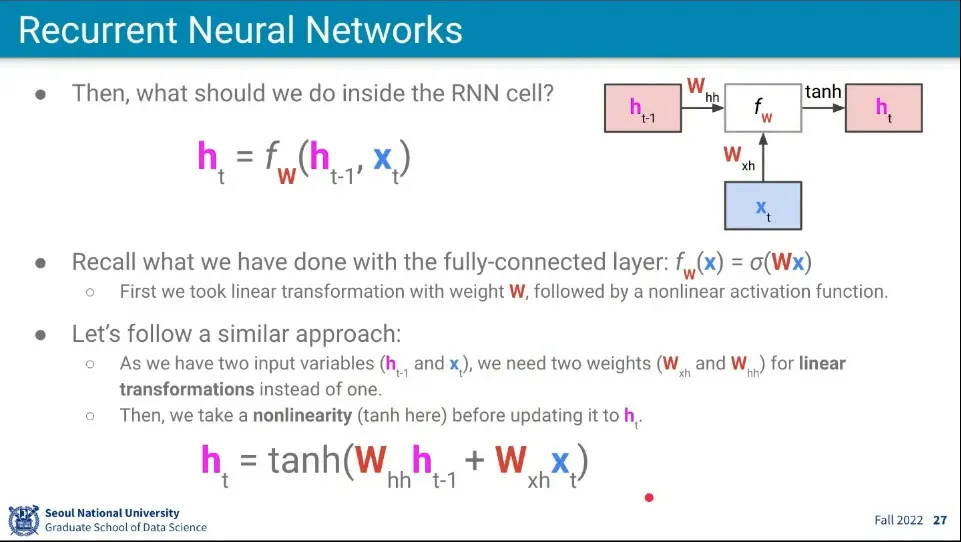
•
input과 이전 상태 2개의 값을 받기 때문에 함수는 위와 같이 가중치 를 상태와 input에 대해 따로 계산한 후에 더한 것을 사용한다.
◦
함수는 일반적으로 탄젠트 하이퍼볼릭을 사용한다.
•
내부 계산 자체는 이전의 것들과 동일하다.
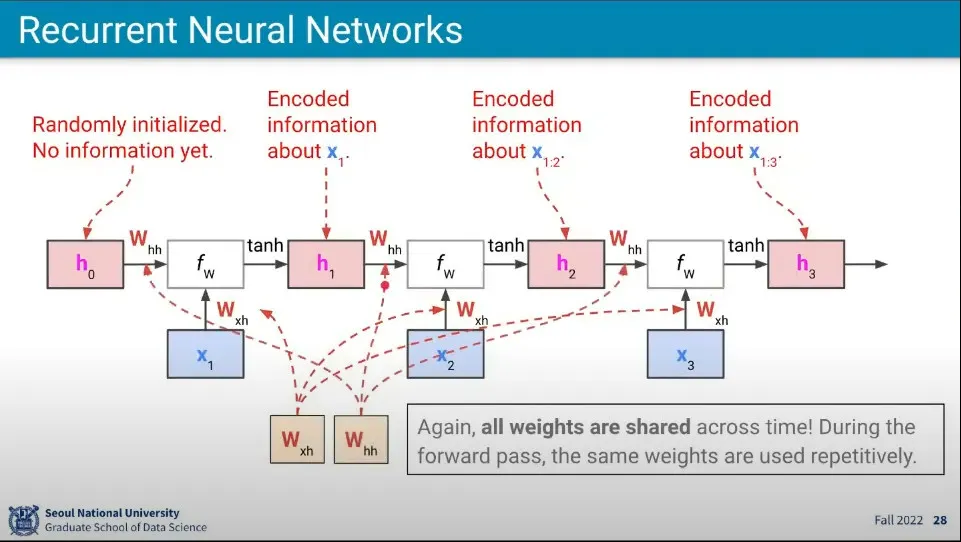
•
위 개념의 예시
◦
각 학습 단계에서 사용되는 와 는 모두 같은 것을 사용한다.
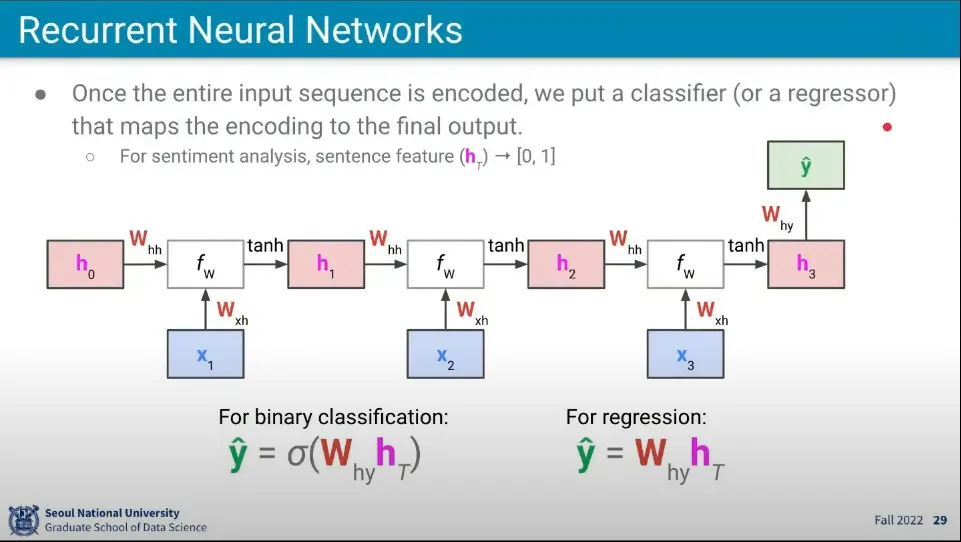
•
최종 결과를 구하기 위해 또 다른 가중치 를 사용한다.
◦
만일 최종 결과를 이진 형태 —예컨대 긍정, 부정— 로 받으려면 sigmoid 함수를 이용하고
◦
regression 결과를 얻으려면 그냥 계산된 값을 사용한다.
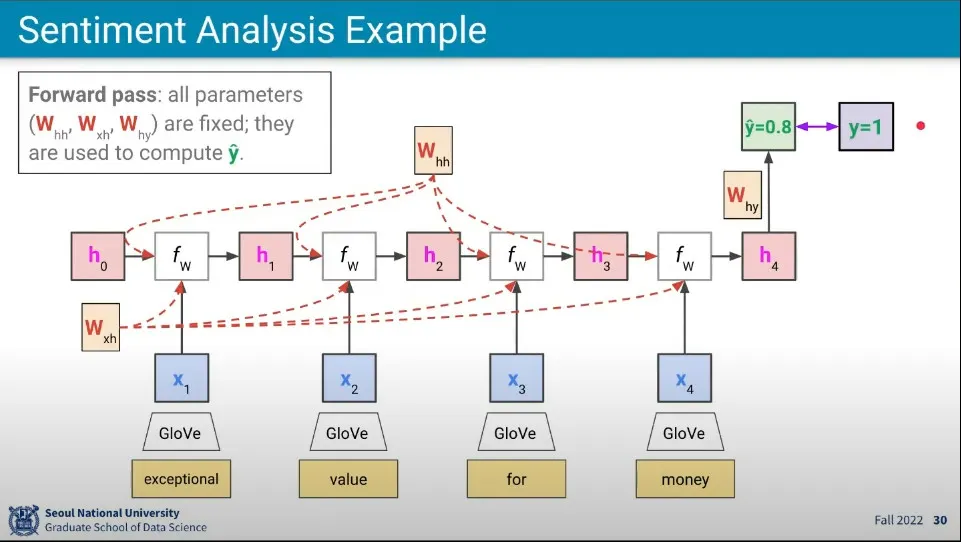
•
Forward 예시
◦
앞서 설명한 흐름대로 Forward가 진행되고 최종적으로 의 값을 구했다고 가정하자. 그러면 그 와 차이를 이용해서 Loss 값이 발생한다.
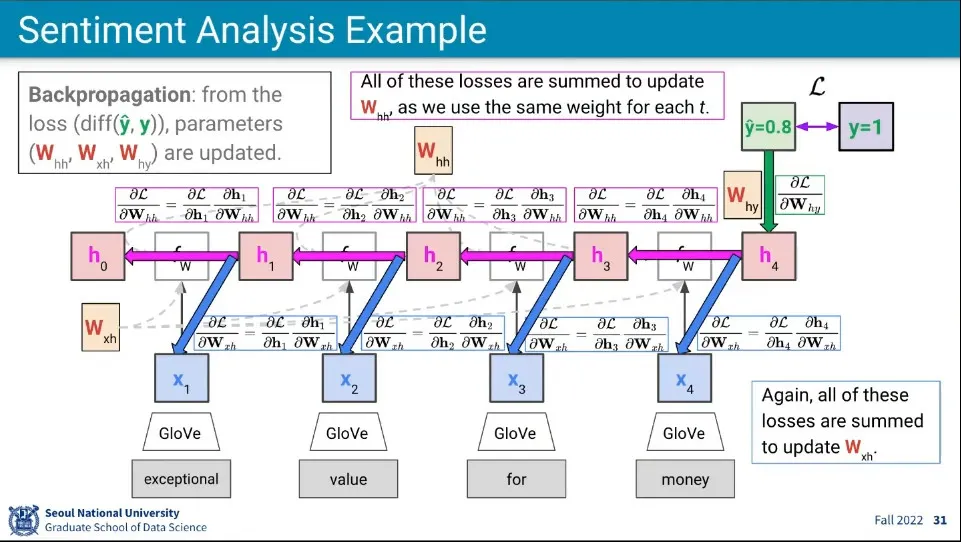
•
Backpropagation 예시
◦
Backpropagation 자체는 기존의 것과 동일함
◦
다만 여기서 는 모두 같은 것이기 때문에 각 단계의 gradient 값을 더해서 업데이트 함 —평균하지 않고

•
언어 모델에서는 단어들의 순서에 대한 가능성을 모델링 함
◦
(이것은 영어에 대한 것이다. 영어는 순서가 문법이지만 한국어는 다르다)

•
문장 안에 나타나는 단어는 독립적이지 않다. 단어는 앞에 나온 단어와 연관이 되어 있다.
•
이때 모든 단어에 대해 모든 가능성을 계산하는 것은 계산이 너무 많기 때문에 그걸 다 하지는 않고 앞의 몇개 단어만 보는 것이 Markove assumption
◦
Unigram은 앞의 단어 1개만 보고, Bigram은 앞의 단어 2개까지 본다.
◦
당연히 많이 보면 볼수록 계산량은 많아진다.

•
언어 모델을 위한 RNN은 다음에 나올 단어의 가능성을 예측한다.
◦
현재까지 입력으로 받은 단어들에 대해 다음 단어를 예측 함
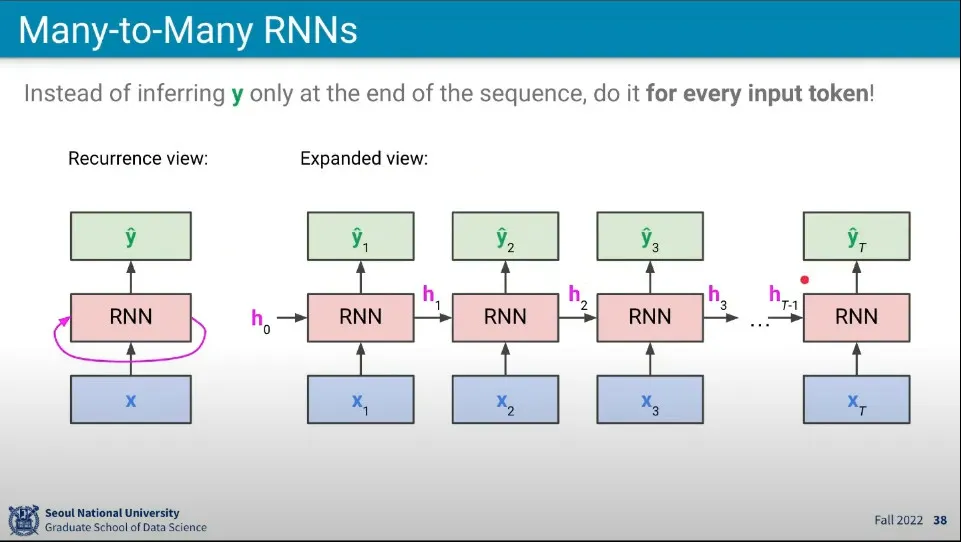
•
여기서는 모든 단어를 입력 받아서 1번 예측하는 것이 아니라 입력이 들어올 때마다 매번 예측을 하게 된다.
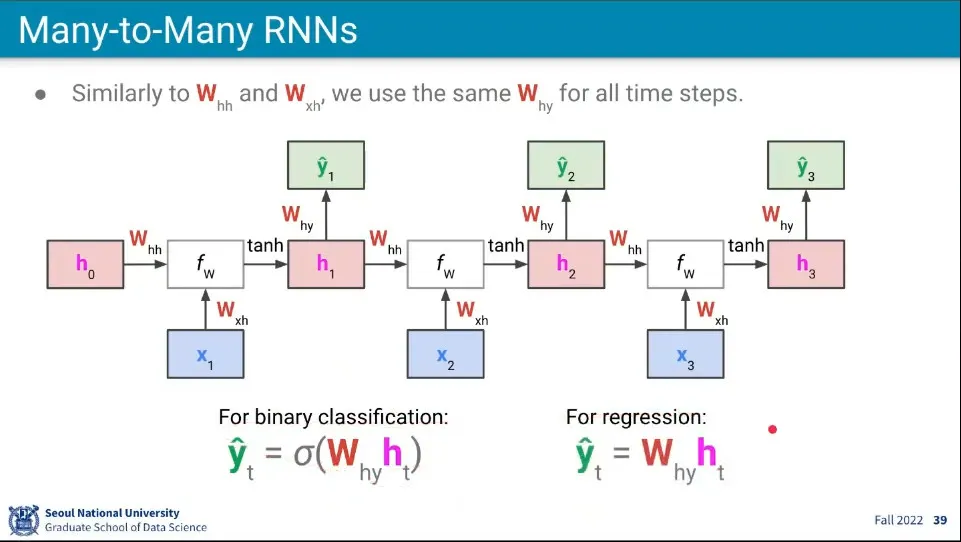
•
흐름은 동일하지만 매번 예측을 한다는 점만 다르다.
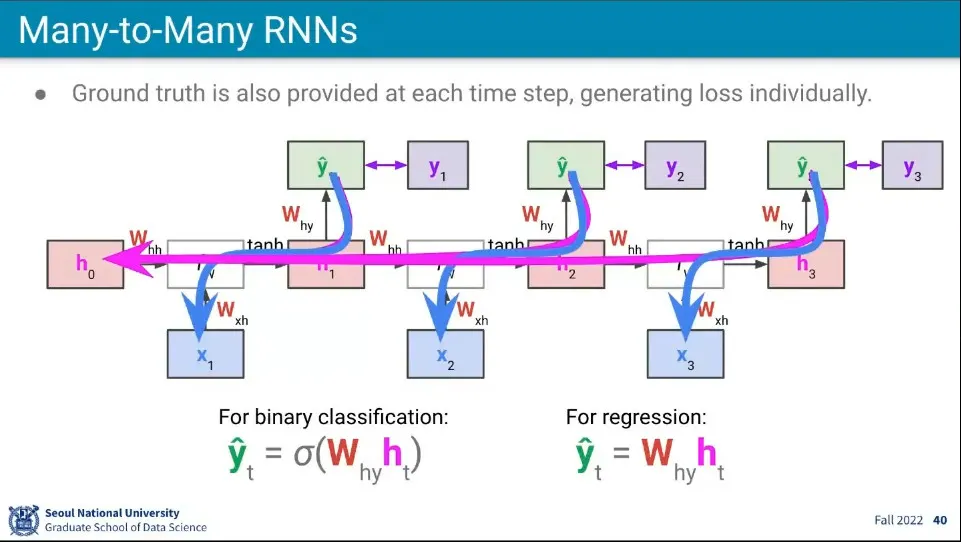
•
예측을 매번 하기 때문에 backpropagation도 매번 하게 된다.
◦
예측할 때 기존의 모든 input이 활용되기 때문에 backpropagation에서도 마찬가지로 기존의 input을 모두 사용해서 gradient를 구한다.
•
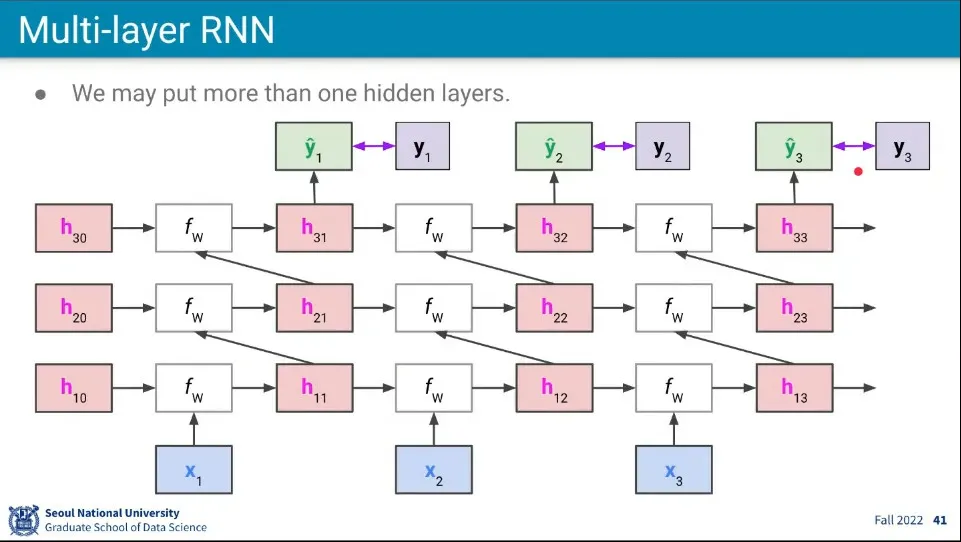
RNN도 Layer를 여러층으로 쌓을 수 있다.
◦
이때 다음 레이어는 이전 레이어와 이전 시퀀스의 동일 레벨의 레이어를 input으로 받는다.
◦
이전 레이어에서는 input을 받고, 이전 시퀀스의 동일 레벨 레이어에서는 state를 받는 것
•
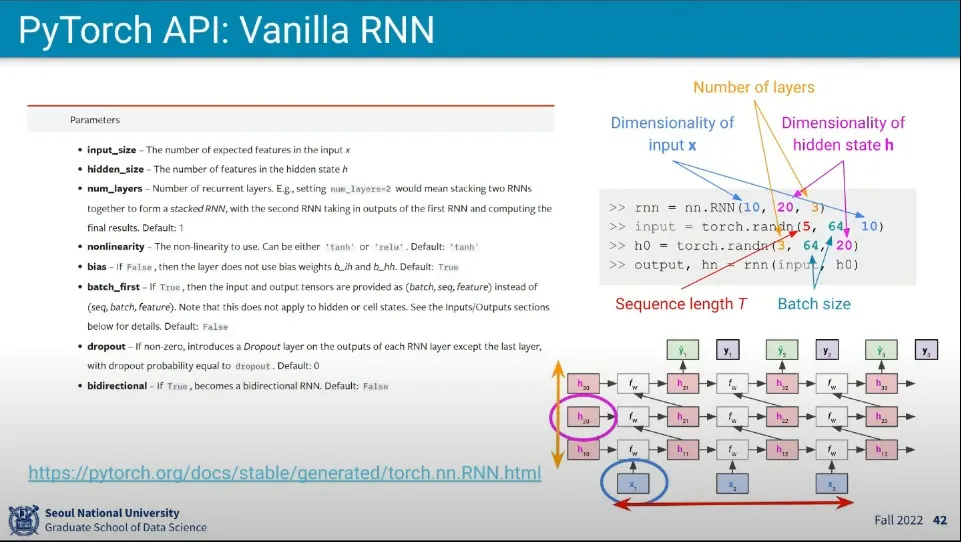
PyTorch에서는 RNN을 위와 같이 만들 수 있고, 각 파라미터의 의미는 설명과 같다.
◦
개념적으로 RNN에서 Sequence는 길이 제한이 없지만, 현실적으로 제한적인 Sequence 길이를 갖고 학습한다.

•
RNN의 장점
◦
input의 길이가 가변적인 것을 처리할 수 있다.
◦
모델 크기가 input이 늘어나도 늘어나지 않는다. 연산은 더 하지만 메모리는 더 커지지 않는다.
◦
이론적으로는 모든 이전 단계의 정보를 사용할 수 있다.
◦
같은 weight를 사용한다.
•
RNN의 단점
◦
순차적으로 처리되어야 하기 때문에 느리다.
◦
CNN과 달리 병렬처리가 안 됨
◦
input의 길이가 계속 길어지면 앞의 값에 대해 vanishing gradient 문제가 발생하게 됨. 이래서 실제적으로 길이가 무한하지 않음
◦
비슷한 이유로 길어지면 한참 전의 input은 잃어버리게 됨
◦
그래서 오래전 것을 활용하기 어려움
◦
(이걸 해결하기 위해 LSTM이 나옴)
