
Abstract
이 논문은 Masked Autoencoder(MAE)가 computer vision을 위한 확장 가능한 self-supervised 학습기라는 것을 보인다. 우리의 MAE 접근은 간단하다. 우리는 입력 이미지의 무작위 패치를 mask하고 누락된 픽셀을 복원한다. 이것은 2가지 핵심 설계에 기반한다. 우선 우리는 비대칭 encoder-decoder 아키텍쳐를 개발한다. encoder는 보이는 patch의 부분집합에서만 작동하고, lightweight decoder는 latent representation과 mask token에서 원래 입력을 복원한다. 둘째, 우리는 입력 이미지의 많은 부분(예 75%)을 마스킹하는 것이 nontrivial이고 의미 있는 self-supervisory task를 산출한다는 것을 발견한다. 이 두 설계를 결합함으로써 대규모 모델을 효율적이고 효과적으로 학습할 수 있다. 우리는 학습 속도를 3배 이상 가속하고 정확도를 개선한다. 우리의 확장 가능한 접근은 학습된 모델이 잘 일반화 될 수 있게 한다. 예컨대 vanilla ViT-Huge 모델은 ImageNet-1K 데이터만 사용하는 방법들 중에 최고 정확도(87.8%)를 달성한다. downstream task에 대한 transfer 성능은 supervised pre-training을 능가하고 유망한 확장 가능성을 보인다.
1. Introduction
Deep learning은 지속적으로 능력과 용량이 증가하는 아키텍쳐의 폭발적인 발전을 목격해왔다. 하드웨어의 빠른 발전 덕분에, 오늘날 모델들은 백만 장의 이미지를 과적합 시킬 수 있으며, 수억 장에 달하는 —종종 공개적으로 접근 불가능한— 라벨링 이미지를 요구하기 시작했다.
이 데이터에 대한 갈증은 NLP에서 self-supervised pre-training을 통해 성공적으로 다루어졌다. GPT의 autoregressive language 모델링과 BERT의 masked auto-encoding에 기반한 솔루션들은 개념적으로 단순하다. 데이터의 일부를 지우고 제거된 컨텐츠를 예측하도록 학습하는 것이다. 이러한 방법은 이제 1000억 개 이상의 파라미터를 가진 일반화 가능한 NLP 모델을 학습할 수 있게 한다.
masked autoencoder의 아이디어는 보다 일반적인 denoising autoencoder의 한 형태로, computer vision에도 잘 응용될 수 있다. 실제로 vision과 밀접하게 관련된 연구는 BERT 보다 앞서서 있었다. 그러나 BERT의 성공 이후 이 아이디어의 상당한 관심에도 불구하고, vision에서 auto-encoding 방법의 발전은 NLP에 뒤쳐져 있다. vision과 language에서 masked autoencoding의 차이는 무엇인가? 우리는 이 질문에 대한 답을 다음의 관점에서 시도한다.
(i) 최근까지 아키텍쳐가 달랐다. vision에서는 지난 10년 동안 convolutional 네트워크가 지배적이었다. convolutional은 일반적으로 regular grid에서 수행되고 mask token이나 positional embedding 같은 지시자들을 convolutional 네트워크에 통합하는 것이 간단하지 않다. 그러나 이러한 아키텍쳐의 차이는 Vision Transformer(ViT)의 도입으로 해결되었고 더는 장애물이 아니다.
(ii) Information density가 언어와 vision 사이에 다르다. 언어는 인간이 생성한 신호로 매우 의미론적이고 정보 밀집이다. 문장 당 몇 개 누락 된 단어를 예측하도록 모델을 학습을 할 때, 이 작업은 복잡한 언어 이해를 유도하는 것처럼 보인다. 반면에 이미지는 자연 신호로 매우 공간 중복을 갖는다. —예컨대 누락된 패치는 이웃 패치로부터 part, object, 장면의 고차원 이해 없이 복원될 수 있다. 이러한 차이를 극복하고 유용한 feature를 학습을 유도하기 위해, 우리는 매우 간단한 전략이 computer vision에서 잘 작동한다는 것을 보인다. 무작위 패치의 매우 높은 포션을 masking하는 것이다. 이 전략은 중복을 크게 줄이고, low-level 이미지 통계를 넘어서는 전체적인 이해를 요구하는 어려운 self-supervisionary 작업을 생성한다. 우리의 복원 작업의 정성적 감에 대해 그림 2-4 참조.



(iii) latent representation을 입력으로 되돌리는 autoencoder의 decoder는 텍스트와 이미지를 복원하는 사이에 다른 역할을 수행한다. vision에서는 decoder가 픽셀을 복원하며 그것의 출력은 일반적인 인식 task 보다 더 낮은 의미론적 레벨이다. 이것은 decoder가 풍부한 의미론적 정보를 포함한 누락된 단어를 예측하는 언어와 대비된다. BERT에서 decoder는 trivial 일 수 있지만(MLP), 우리는 이미지에 대해 decoder가 학습된 latent representation의 의미론적 레벨을 결정하는데 핵심 역할을 한다는 것을 발견했다.
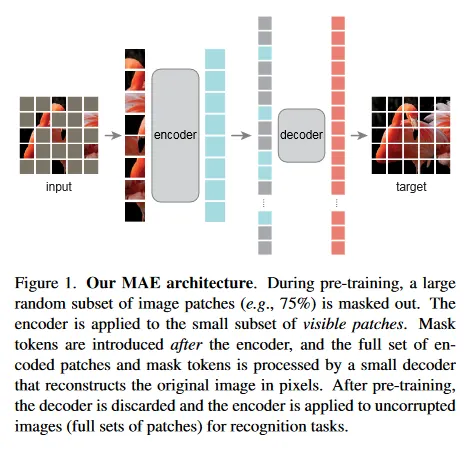
이 분석에 의해, 우리는 visual representation learning을 위한 간단하고 효과적이며 확장가능한 형식의 masked autoencoder(MAE)을 제시한다. 우리의 MAE는 입력 이미지에서 무작위 패치를 마스킹하고, 픽셀 공간에서 누락된 패치를 복원한다. 이것은 비대칭 encoder-decoder 설계를 갖는다. 우리의 encoder는 mask token 없이 보이는 패치의 부분집합에서만 작동하고, decoder는 가중치가 적고, latent representation과 mask token을 사용해 입력을 복원한다(그림 1). 우리의 비대칭 encoder-decoder에서 mask token을 작은 decoder로 shifting하면 계산이 크게 줄어든다. 이 설계 하에, 매우 높은 masking 비율(예: 75%)는 정확도를 최적화하면서 encoder가 소량의 패치(예: 25%)만 처리할 수 있는 win-win 시나리오를 달성할 수 있다. 이것은 전체적인 pre-training 시간을 3배 이상 감소시키고 메모리 소모를 줄여서 MAE를 대규모 모델로 쉽게 확장할 수 있게 한다.
우리의 MAE는 높은 수용량의 모델을 학습하며 잘 일반화된다. MAE pre-training을 통해 우리는 ViT-Large/Huge와 같은 데이터가 많이 필요한 모델을 ImageNet-1k에서 개선된 일반화 성능으로 학습할 수 있다. vanilla ViT-Huge 모델을 사용하여 우리는 ImageNet-1K에서 fine-tune 시에 87.8% 정확도를 달성했다. 이것은 ImageNet-1K 데이터에만 사용하는 모든 이전 결과를 능가한다. 우리는 또한 object detection, instance segmentation, semantic segmentation에 대한 transfer learning을 평가한다. 이러한 작업에서 우리의 pre-training은 supervised pre-training 대응 모델과 비교하여 더 나은 결과를 달성했으며, 더 중요한 것은 모델을 확장하면 상당한 성능 향상을 얻을 수 있다는 것이다. 이러한 관찰은 NLP의 self-supervised pre-training의 증거와 부합하며 우리는 이러한 경로를 우리의 영역에서도 탐구 할 수 있기를 기대한다.
2. Related Work
Masked 언어 모델링과 그것의 autoregressive 대응 모델 (BERT와 GPT)는 NLP에서 pre-training에 대해 매우 성공적이었다. 이러한 방법은 입력 시퀀스의 일부를 제거하고 모델이 누락된 컨텐츠를 예측하도록 학습한다. 이러한 방법은 훌륭하게 확장가능하고, pre-trained representation이 다양한 downstream task에 잘 일반화된다는 증거를 보인다.
Autoencoding은 representation을 학습하기 위한 전통적인 방법이다. 이것은 입력을 latent representation으로 매핑하는 encoder와 입력을 복원하는 decoder를 갖는다. 예컨대 PCA와 k-means는 모두 autoencoder이다. Denoising Autoencoder(DAE)는 autoencoder의 한 종류로 입력 신호를 오염시키고와 오염되지 않은 원본을 복원하도록 학습된다. 이러한 계열의 방법들은 다양한 오염 하에 일반화된 DAE의 종류로 생각할 수 있다. 예: masking pixels, removing color channels 등. 우리의 MAE는 denoising autoencoding의 한 형식이지만 전통적인 DAE와는 여러 방법에서 차이가 있다.
Maksed image encoding 방법은 masking에 의해 오염된 이미지에서 representation을 학습한다. [59]의 선구적인 작업은 DAE에서 masking을 노이즈 유형으로 제시한다. Context Encoder는 convolutional network를 사용하여 대규모 누락된 영역을 inpaint한다. NLP의 성공에 영감받은 최근 작업들은 Transformer에 기반한다. iGPT는 픽셀의 시퀀스에서 작동하고 알려지지 않은 픽셀을 예측한다. ViT 논문은 self-supervised learning을 위한 masked patch 예측을 연구한다. 가장 최근에 BEiT는 이산 토큰을 예측하는 방식을 제안했다.
Self-supervised learning 접근은 computer vision에서 큰 관심을 받았으며 주로 pre-training을 위한 다양한 pretext task에 초점을 맞춘다. 최근 contrastive learning이 인기를 얻었다. 여기서 두 개 이상의 뷰에서 이미지 유사성과 비유사성(또는 단순히 유사성만)을 모델링한다. contrastive와 연관된 방법들은 data augmentation에 크게 의존한다. 반면 Autoencoding은 개념적으로 다른 방향을 추구하고 우리는 이 방법들이 다른 행동을 보인다는 것을 제시한다.
3. Approach
우리의 masked autoencoder(MAE)는 부분적으로 관찰된 신호가 주어지면 원본 입력 신호를 복원하는 간단한 autoencoder 접근이다. 모든 autoencoder와 유사하게, 우리의 접근도 관찰된 신호를 latent representation으로 매핑하는 encoder와 latent representation에서 원본 신호를 복원하는 decoder를 갖고 있다. 그러나 전통적인 autoencoder와 다르게 우리는 비대칭 설계를 채택하여, encoder가 부분적으로 관찰된 신호에서만 작동하게 하고(mask token 없이) lightweight decoder가 latent representation과 mask token을 통해 전체 신호를 복원하게 한다. 그림 1 참조.
Masking.
ViT를 따라 우리는 이미지를 regular 겹침 없는 패치로 분할한다. 그 다음 패치의 일부를 샘플링하고 나머지를 mask(즉, 제거) 한다. 우리의 샘플링 전략은 간단하다. 우리는 균등 분포를 따라 중복 없이 무작위로 패치를 샘플링한다. 이것을 단순히 ‘random sampling’이라 부른다.
높은 마스킹 비율(즉 제거된 패치의 비율)의 랜덤 샘플링은 중복을 대부분 제거하며, 보이는 이웃 패치에서 쉽게 해결될 수 없는 task를 생성한다(그림 2-4). 균등 분포는 잠재적으로 center bias(즉 이미지 중심에 더 많은 패치가 마스킹 되는 현상)를 방지한다. 마지막으로 매우 희소한 입력은 효율적인 encoder 설계를 가능하게 한다.
MAE encoder.
우리의 encoder는 ViT이지만, unmasked patch인 visible에만 작동한다. 표준 ViT에서와 같이 encoder는 패치들을 positional embedding하고 linear projection 하여 임베딩한 다음, Transformer block의 일련의 과정을 통해 결과 집합을 처리한다. 그러나 우리의 encoder는 전체 집합 중 작은 부분(예: 25%)에서만 동작한다. 마스킹된 패치는 제거되며, 마스크 토큰은 사용되지 않는다. 이를 통해 계산과 메모리의 비율만으로 매우 큰 encoder를 학습할 수 있다. 전체 패치 집합은 다음에 설명할 lightweight decoder에 의해 처리된다.
MAE decoder.
MAE decoder에 대한 입력은 (i) 인코딩된 visible patch 와 (ii) mask token으로 구성된 전체 토큰 집합이다. 그림 1 참조. 각 마스크 토큰은 예측할 누락된 패치의 존재를 나타내는 공유된 학습 벡터다. 우리는 이 전체 집합에서 모든 토큰에 positional embedding을 추가한다. 이것이 없으면 mask 토큰은 이미지에서 위치 정보를 알 수 없게 된다. decoder는 또 다른 일련의 Transformer block이다.
MAE decoder는 pre-training 동안에만 이미지 복원 작업을 수행하는데 사용되며(이미지 인식을 위한 representation을 생성할 때는 encoder만 사용된다) 따라서 decoder 아키텍쳐는 encoder 설계와 독립적으로 유연하게 설계될 수 있다. 우리는 encoder에 비해 매우 small, narrower, shallower인 decoder로 실험했다. 예컨대 우리의 default decoder는 encoder 대비 token당 계산량이 10% 미만이다. 이 비대칭 설계를 사용하여, 전체 token 집합은 lightweight decoder에 의해 처리되어 pre-training 시간을 크게 줄인다.
Reconstruction target.
우리의 MAE는 각 masked 패치에 대한 픽셀 값을 예측하여 입력을 복원한다. decoder의 출력에서 각 요소는 패치를 나타내는 픽셀 값의 벡터이다. decoder의 마지막 레이어는 패치의 픽셀 값의 수와 동일한 출력 채널의 수를 갖는 linear projection이다. decoder의 출력은 복원된 이미지로 reshape 된다. loss 함수는 복원된 이미지와 원래 이미지 사이의 픽셀 공간에서 mean squared error(MSE)를 계산한다. 우리는 BERT와 유사하게 masked patch에서만 loss를 계산한다.
우리는 또한 masked 패치의 normalized 픽셀값을 복원 타겟으로 하는 변종도 연구한다. 구체적으로 우리는 패치에서 모든 픽셀의 평균과 표준편차를 계산하고 이것을 사용하여 이 패치를 normalize 한다. 실험에서 normalized 픽셀을 복원 대상으로 사용하는 것이 표현 품질을 개선했다.
Simple implementation.
우리의 MAE pre-training은 효율적으로 구현될 수 있으며, 중요한 것은 특별한 희소 연산이 필요 하지 않다는 것이다. 우선 우리는 각 입력 패치에 대해 토큰을 생성하고(positional embedding을 추가하고 linear projection하여) 다음으로 토큰 리스트를 무작위로 섞고, masking ratio에 기반하여 리스트의 마지막 portion을 제거한다. 이 절차는 encoder를 위한 토큰의 작은 부분 집합을 생성하고, 이는 대체 없이 패치를 샘플링하는 것과 동등하다. encoding 후에 우리는 mask 토큰 리스트를 인코딩된 패치 리스트에 추가하고, 전체 리스트를 unshuffle 하여 모든 토큰을 타겟에 정렬시킨다(random shuffle 연산과 반대로). decoder는 이 전체 리스트에 적용되며(positional embedding이 추가된 상태) 희소한 연산은 필요하지 않다. 이 간단한 구현은 성능에 거의 영향을 미치지 않으며 shuffling과 unshuffling 연산은 매우 빠르다.
4. ImageNet Experiments
우리는 ImageNet-1K(IN1K) training set에서 self-supervised pre-training을 수행한다. 그 다음 (i) end-to-end fine-tuning이나 (ii) linear probing을 통해 representation을 평가하기 위해 supervised training을 수행한다. 우리는 single 224x224 crop에 대한 top-1 평가 정확도를 리포트한다. 자세한 내용은 부록 A.1 참조.
Baseline: ViT-Large.
우리는 ViT-Large(ViT-L/16)을 ablation 연구의 backbone으로 사용한다. ViT-L은 매우 큰 모델로(ResNet-50 보다 훨씬 더 크다) 과적합 하는 경향이 있다. 아래는 처음부터 학습된 ViT-L과 우리의 baseline MAE에서 fine-tune 한 것 사이의 비교이다.
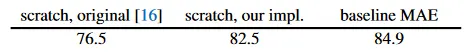
처음부터 supervised ViT-L을 학습하는 것이 nontrivial이고 강력한 regularization를 포함한 좋은 레시피가 필요하다(82.5%, 부록 A.2). 그럼에도 우리의 MAE pre-training은 큰 개선을 가져온다. 여기서 fine-tuning은 50 epoch만 진행되었으며(vs 처음부터 200), fine-tuning 정확도가 pre-training에 매우 의존한다는 것을 암시한다.
4.1. Main Properties
우리는 Table 1의 default 설정(caption 참조)을 사용하여 MAE을 ablation한다. 여러 흥미로운 속성이 관찰된다.

Masking ratio.
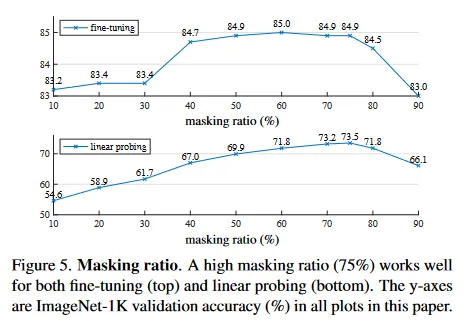
그림 5는 masking 비율의 영향을 보인다. 최적 비율은 놀랍게도 높다. 75%의 비율이 linear probing과 fine-tuning 모두에서 좋다. 이 동작은 masking 비율이 일반적으로 15%인 BERT와 대비된다. 우리의 masking 비율은 computer vision에서 관련된 연구들(20%에서 50%) 보다 훨씬 높다.
모델은 누락된 패치를 추론하여 다양하지만 그럴듯한, 출력을 생성한다(그림 4). 이것은 단순히 line이나 texture를 확장하는 것으로는 완성될 수 없는 object와 장면의 전체적인 의미를 파악한다. 우리는 이러한 추론적인 행동이 유용한 representation을 학습하는 것과 연결되어 있다고 가정한다.
그림 5는 linear probing과 fine-tuning 결과가 서로 다른 경향을 따른다는 것을 보인다. linear probing의 경우 masking 비율이 sweet point에 도달할 때까지 정확도가 꾸준히 증가하며 그 차이는 최대 20%까지이다(54.6% vs 73.5%). fine-tuning의 경우 결과는 비율에 덜 민감하고, 넓은 masking 비율(40-80%)에서 모두 잘 작동한다. 그림 5에서 모든 fine-tuning 결과는 처음부터 학습한 것보다 낫다(82.5%)
Decoder design.
우리의 MAE decoder는 유연하게 설계될 수 있으며, Table 1a와 1b에서 연구된다.
Table 1a는 decoder depth(Transformer block의 수)를 다양화한다. 충분히 깊은 decoder는 linear probing의 경우 중요하다. 이것은 픽셀 복원 작업과 인식 작업 사이의 차이에 의해 설명될 수 있다. autoencoder에서 마지막 몇 개 레이어는 복원에 더욱 특화 되지만, 인식에는 덜 관련된다. 적절한 깊이의 decoder는 복원에 특화된 부분을 담당하며, latent 표현을 더 추상적인 레벨에서 남긴다. 이 설계는 linear probing에서 8% 개선을 산출할 수 있다(Table 1a, ‘lin’) 그러나 fine-tuning을 사용하면, encoder의 마지막 레이어는 인식 작업에 맞게 조정될 수 있다. decoder 깊이는 fine-tuning 성능 향상에는 영향을 덜 미친다(Table 1a, ‘ft’)
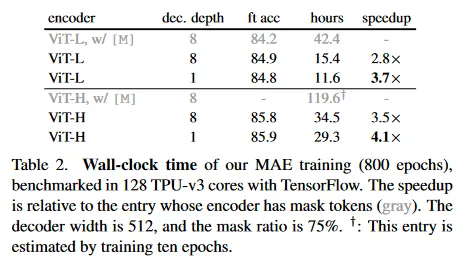
흥미롭게도 우리의 single-block decoder를 갖는 MAE로도 fine-tuning에서 강력한 성능을 발휘할 수 있다(84.8%). 단일 Transformer block은 visible 토큰에서 mask 토큰으로 정보를 전파하는데 최소 요구사항이다. 이런 작은 decoder는 학습 속도를 더욱 높일 수 있다.
Table 1b에서 우리는 decoder width를 연구한다(channel의 수). 우리는 default로 512-d를 사용하며이것은 fine-tuning과 linear probing 에서 모두 잘 수행된다. 더 좁은 decoder도 fine-tuning에서 잘 동작한다.
전체적으로 우리의 default MAE decoder는 lightweight이다. 이것은 8개 블록과 512-d의 width(Table 1에서 gray)를 가지며, ViT-L(24 block, 1024-d)와 비교하여 토큰 당 9% FLOPs만 갖는다. 따라서 decoder는 모든 토큰을 처리하지만 전체 계산량에서는 작은 비중을 차지한다.
Mask token.
MAE의 중요한 설계 중 하나는 encoder에서 mask token [M]을 skip하고 나중에 lightweight decoder에서 이를 적용하는 것이다. Table 1c는 이 설계를 연구한다.
encoder가 mask 토큰을 사용하면 성능이 나빠진다. linear probing에서 이것의 정확도는 14% 떨어진다. 이 경우에, pre-training과 deploying 사이에 격차가 발생한다. 이 encoder는 pre-training에서 입력의 많은 mask token을 갖지만, 오염되지 않은 이미지에는 존재하지 않는다. 이 격차가 배포 시 정확도를 떨어뜨린다. encoder에서 mask 토큰을 제거하여 encoder가 항상 실제 패치만 보도록 강제하고 따라서 정확도를 개선할 수 있다.
또한 encoder에서 mask 토큰을 skip 하면, training 계산을 매우 줄일 수 있다. Table 1c에서 전체 학습 학습 FLOPs를 약 3.3배 줄인다. 이것은 우리의 구현에서 2.8배의 wall-clock 속도를 이끈다(Table 2 참조). 작은 decoder(1-block), 더 큰 encoder(ViT-H) 또는 모두 사용하는 경우 wall-clock speedup은 3.5-4.1배에 달한다. masking ratio가 75%인 경우 속도 향상이 4배 보다 커질 수 있다. 이것은 부분적으로 self-attention 복잡도가 이차적으로 증가하기 때문이다. 추가적으로 메모리가 크게 감소하여 더 큰 모델을 학습하거나 대규모 배치 학습으로 속도를 더욱 개선 할 수 있다. 시간과 메모리 효율성 덕분에 우리의 MAE는 매우 큰 모델을 학습에 적합하다.
Reconstruction target.
Table 1d에서 우리는 다양한 복원 타겟을 비교한다. 지금까지의 결과는 (패치 당) normalization 없는 픽셀에 기반한 것이다. 픽셀에 normalization을 적용하면 정확도가 개선된다. 이 패치별 normalization은 지역적으로 대비를 강화한다. 다른 변종에서는 패치 공간에서 PCA를 수행하고 가장 큰 PCA 계수(여기서 96)을 타겟으로 사용한다. 그러나 이렇게 하면 정확도가 떨어진다. 두 실험 모두 high-frequency 컴포넌트가 우리의 방법에서 유용함을 시사한다.
우리는 또한 BEiT에서 사용된 타겟인 토큰을 예측하는 MAE 변종을 비교한다. 구체적으로 이 변종의 경우 우리는 [2]를 따라 DALLE pre-trained dVAE를 tokenizer로 사용한다. 여기서 MAE decoder는 cross-entropy loss를 사용하여 token 인덱스를 예측한다. 이 토큰화는 unnormalization 픽셀과 비교하여 fine-tuning 정확도를 0.4% 개선하지만, normalized 픽셀과 비교해서는 이점이 없다. 또한 linear probing 정확도를 낮춘다. 섹션 5에서 우리는 토큰화가 transfer learning에서 필요하지 않다는 것을 추가로 보인다.
우리의 픽셀 기반 MAE는 토큰화 보다 훨씬 간단하다. dVAE 토큰화는 추가 데이터(250M 이미지)에 의존할 수 있는 하나 이상의 pre-training 단계가 필요하다. dVAE 인코더는 대규모 convolutional network(ViT-L의 40% FLOPs)이며 상당한 오버헤드를 추가한다. 픽셀을 사용하면 이러한 문제에 시달리지 않는다.
Data augmentation.
Table 1는 MAE pre-trainnig에 대한 data augmentation의 영향을 보인다.
우리의 MAE는 고정된 크기 또는 랜덤 크기의 cropping-only 증강(모두 random horizontal flipping을 갖는다)에서 잘 동작한다. color jittering을 추가하면 결과가 저하되므로 다른 실험에서 사용하지 않는다.
놀랍게도 MAE는 데이터 증강 없이도(flipping 없이 center crop만 사용) 상당히 잘 동작한다. 이 속성은 데이터 증강에 매우 의존하는 contrastive learning이나 관련된 방법과 드라마틱하게 다르다. [21]에서 cropping-only 증강만 사용하는 BYOL과 SimCLR이 각각 정확도를 13%, 28% 감소시킨다는 것을 보인다. 게다가 contrastive learning이 증강 없이 작동할 수 있다는 증거가 없다. 이미지의 두 view는 동일하고 손쉽게 trivial 해를 만족할 수 있다.
MAE에서 데이터 증강의 역할은 주로 random masking에 의해 수행된다(다음에 ablation 됨). 마스크는 각 iteration에서 서로 다르고, 따라서 데이터 증강과 관계없이 새로운 학습 샘플을 생성한다. 마스킹은 pretext task를 어렵게 만들어 학습을 regularize 하는데 증강을 덜 요구한다.
Mask sampling strategy.
Table 1f에서 우리는 다양한 마스크 샘플링 전략을 비교한다. 그림 6 참조.

[2]에서 제안된 block-wise masking 전략은 큰 블록을 제거하는 경향이 있다(그림 6 중간). block-wise masking을 사용하는 MAE는 50%의 비율에서 꽤 잘 작동하지만, 75%의 비율에서 퇴화한다. 이 작업은 랜덤 샘플링보다 어렵고 더 높은 학습 loss를 보인다. 복원 결과도 더 blur이다.
우리는 또한 grid-wise sampling을 연구한다. 이것은 매 4개 패치의 하나를 regularly 유지한다(그림 6 오른쪽). 이것은 더 쉬운 task이고 더 낮은 학습 loss를 갖는다. 복원 결과는 sharper이지만 representation 품질은 더 낮다.
간단한 랜덤 샘플링이 MAE에 최적이다. 이것은 더 높은 masking ratio를 허용하여 좋은 정확도를 유지하면서 상당한 속도 향상 이점을 제공한다.
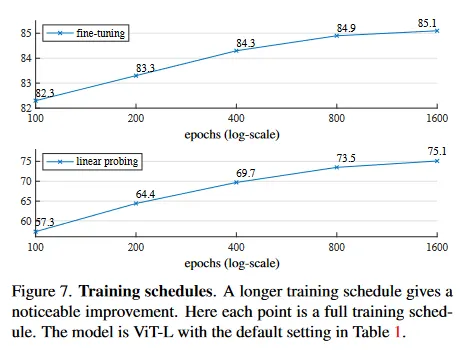
Training schedule.
우리의 ablation은 800-epoch pre-training에 기반한다. 그림 7은 학습 스케쥴 길이의 영향을 보인다. 정확도는 더 긴 학습에서 꾸준히 개선된다. 실제로 linear probing 정확도는 1600 epoch에서 조차 포화가 관찰되지 않했다. 이것은 contrastive learning 방법과 다르다. 예컨대 MoCo v3는 ViT-L에서 300 epoch에서 포화된다. MAE encoder는 epoch 당 전체 패치 중 단지 25%만 보지만, contrastive learning에서는 encoder는 epoch 당 200%(2개 crop) 또는 그 이상(multi-crop)의 패치를 본다.
4.2. Comparisons with Previous Results
Comparisons with self-supervised methods.
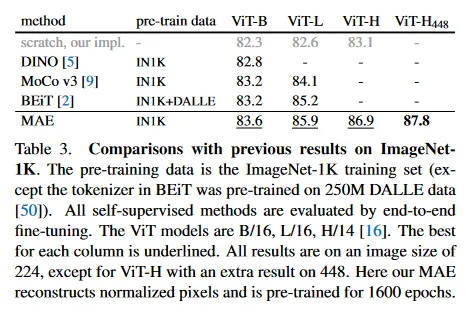
Table 3에서 우리는 self-supervised ViT 모델의 fine-tuning 결과를 비교한다. ViT-B에 대해 모든 방법은 비슷하게 수행된다. ViT-L에 대해 방법들 사이의 격차는 더 크며 이것은 더 큰 모델에서 과적합을 줄이는 것이 도전적이라는 것을 시사한다.
우리의 MAE는 쉽게 확장 가능하고 더 큰 모델에서 꾸준히 성능이 개선 된다. 우리는 ViT-H(224 크기)를 사용하여 86.9% 정확도를 얻는다. 448 크기로 fine-tuning하면 87.8% 정확도를 달성한다. 이전의 IN1K 데이터만 사용하는 모든 방법들 사이에서 최고 정확도는 87.1%(512 크기)로, 이는 진보된 네트워크게 기반한 결과이다. 우리는 IN1K의 매우 경쟁적인 벤치마크에서 확장 데이터 없이 nontrivial 격차로 최첨단을 능가한다. 우리의 결과는 vanilla ViT에 기반하고 더 진보한 네트워크를 사용하면 더 잘 수행할 것이라 기대한다.
BEiT와 비교하여 우리의 MAE는 더 정확하면서 더 단순하고 빠르다. 우리의 방법은 픽셀을 복원하는 반면 BEiT는 토큰을 예측한다. BEiT는 ViT-B에서 픽셀을 복원할 때 1.8% 퇴화를 보고한다. 우리는 dVAE pre-training이 필요하지 않지만 또한 우리의 MAE는 BEiT 보다 epoch 당 3.5배 빠르다. 이유는 Table 1c에서 연구된다.
Table 3에 있는 MAE 모델은 더 나은 정확도를 위해 1600 epoch 동안 pre-trained 된다(그림 7). 그럼에도 동일한 하드웨어에서 학습될 때 우리의 전체 pre-training 시간은 다른 방법보다 적다. 예컨대 128 TPU-v3 core에서 ViT-L을 학습할 때, MAE의 학습 시간은 1600 epoch 동안 31시간이고, MoCo v3는 300 epoch 동안 36시간 걸린다.
Comparisons with supervised pre-training.
원래의 ViT 논문에서 ViT-L을 IN1K에서 학습할 때 퇴화한다. 우리의 supervised 학습 구현은 더 나은 성능을 보이지만 정확도는 포화하지 않는다. 그림 8 참조.
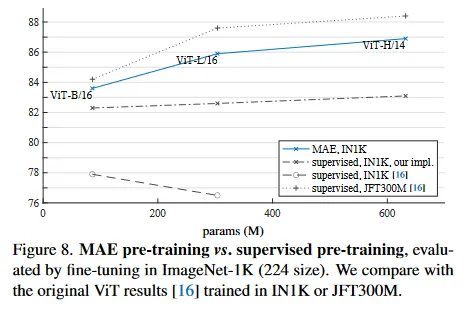
우리의 MAE pre-training은 오직 IN1K만 사용하면서도 일반화가 더 잘 된다. 수용량이 큰 모델일수록 처음부터 학습하는 것보다 더 큰 성능 향상을 보인다. 이것은 [16]의 JFT-300M supervised pre-training과 유사한 경향을 따른다. 이 비교는 우리의 MAE가 모델 크기를 확장하는데 도움이 될 수 있다는 것을 보인다.
4.3. Partial Fine-tuning
Table 1은 linear probing과 fine-tuning 결과가 대부분 상관관계가 없음을 보인다. Linear probing은 과거 몇 년간 대중적인 프로토콜이었으나, 이것은 강력하지만 deep learning의 강점인 비선형적 feature를 추구하는 기회를 놓친다. 중간 지대로써, 우리는 다른 것들은 freezing하고 마지막 몇 개 layer만 fine-tuning 하는 부분적인 fine-turning 프로토콜을 연구한다. 이 프로토콜은 초기 작업에서도 사용되었다.
그림 9는 그 결과를 보인다. 주목할만한 것은 오직 하나의 Transformer block만 fine-tuning 해도 정확도가 73.5%에서 81.0%로 매우 상승한다는 것이다. 또한 last block의 절반(즉 MLP sub-block)만 fine-tune 하면, 79.1%를 얻을 수 있으며 이는 linear probing보다 훨씬 나은 결과이다. 이 변종은 근본적으로 MLP head만 fine-tuning하는 방식이다. 몇 개 블록(예: 4개 또는 6개)을 fine-tuning 하면 full fine-tuning과 유사한 정확도를 달성할 수 있다.
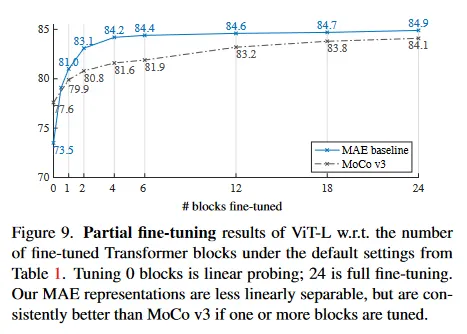
그림 9에서 ViT-L 결과가 있는 contrastive 방법을는 MoCo v3와 비교한다. MoCo v3가 더 높은 linear probing 정확도를 갖지만 모든 부분 fine-tuning 결과는 MAE 보다 나쁘다. 4개 block을 조정할 때 격차는 2.6%이다. MAE representation은 선형으로 분리되기 어렵지만, 비선형 feature가 강하며 non-linear head를 조정할 때 잘 수행된다.
이러한 관찰은 linear 분리가능성이 representation 품질을 평가하는 유일한 메트릭이 아님을 시사한다. 이것은 linear probing이 transfer learning 성능을 사용하여 잘 상관관계가 없다는 것을 관찰한다. 예: object detection. 우리가 아는 한, linear 평가는 NLP에서 pre-training을 벤치마크 하는데 자주 사용되지 않는다.
5. Transfer Learning Experiments
우리는 Table 3의 pre-trained model을 사용하여 downstream task에서 transfer learning을 평가한다.
Object detection and segmentation.
우리는 COCO 데이터셋에서 Mask R-CNN을 end-to-end로 fine-tune 한다. ViT backbone은 FPN과 함께 사용되도록 조정되었다(부록 A.3). Table 4의 모든 항목에 이 접근을 적용한다. 우리는 object detection에 대한 box AP와 instance segmentation에 대한 mask AP를 리포트한다.
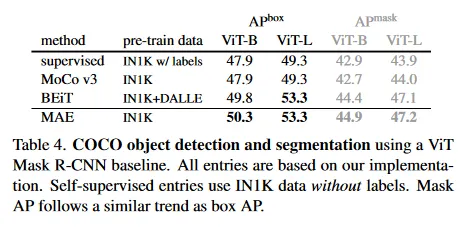
supervised pre-training과 비교할 때, 우리의 MAE는 모든 설정에서 더 잘 수행한다(Table 4). 더 작은 ViT-B의 경우 우리의 MAE는 supervised pre-training 보다 2.4점 더 높다(50.3 vs 47.9 ). 더 큰 ViT-L에서 우리의 MAE pre-training이 supervised pre-training을 4.0점 능가했다(53.3 vs 49.3)
pixel-based MAE는 token-based BEiT와 낫거나 비슷한 성능을 보이면서 MAE가 더 간단하고 빠르다. MAE와 BEiT 모두 MoCo v3 보다 낫고 MoCo v3는 supervised pre-training과 근접하다.
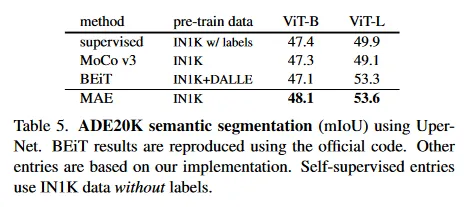
Semantic segmentation.
우리는 UperNet을 사용하여 ADE20K에서 실험한다(부록 A.4). Table 5는 우리의 pre-training이 supervised pre-training을 매우 개선함을 보인다. ViT-L의 경우 3.7 점 향상을 보인다. 우리의 pixel-based MAE는 또한 token-based BEiT를 능가한다. 이러한 관찰은 COCO에서의 결과와 일치 한다.
Classification tasks.
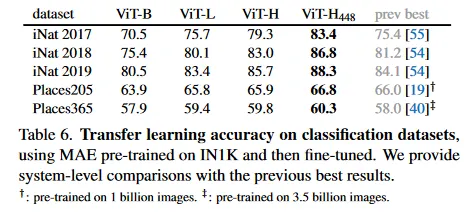
Table 6은 iNaturalist와 Place task에 대한 transfer learning을 연구한다(부록 A.5). iNat에서 우리의 방법이 강력한 확장 성능을 보인다. 더 큰 모델을 사용할 수록 정확도가 상당히 개선된다. 우리의 결과는 수십 억의 이미지에서 pre-training을 통해 얻어진 이전 최고 결과를 큰 격차로 능가한다.
Pixels vs. tokens.
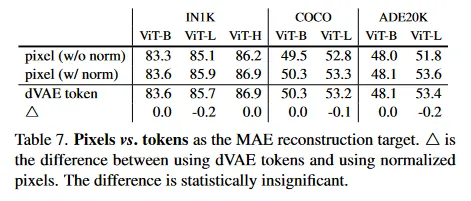
Table 7은 MAE 복원 목표로 pixel vs token을 비교한다. dVAE 토큰이 unnormalized 픽셀을 사용하는 것보다 낫지만, 우리가 테스트한 모든 케이스에서 normalized 픽셀을 사용하는 것과는 통계적으로 유사했다. 이것은 다시 한 번 토큰화가 MAE에 필수가 아님을 보인다.
6. Discussion and Conclusion
잘 확장되는 간단한 알고리즘은 deep learning의 핵심이다. NLP에서 간단한 self-supervised learning 방법들은 이 모델을 지수적으로 확장하는 것에 이점을 준다. computer vision에서 self-supervised learning의 발전에도 불구하고 실용적인 pre-training 패러다임은 supervised가 지배한다. 이 연구에서 ImageNet과 transfer learning에서 NLP에서 기법과 유사한 간단한 self-supervised 방법인 autoencoder가 확장성 이점을 제공한다는 것을 관찰했다. vision에서 self-supervised learning은 이제 NLP에서의 유사한 궤적에 탑승한 것일 수 있다.
반면에 이미지와 언어가 다른 성질의 신호이고 이 차이를 조심스럽게 다뤄야 한다. 이미지는 단지 단어의 기록된 빛이며 시각적 유사물로 의미론적으로 분해되지 않는다. 우리는 object를 제거하려고 시도하는 대신, 우리는 의미론적 segment를 형성하지 않을 가능성이 큰 무작위 패치를 제거한다. 비슷하게, 우리의 MAE는 의미론적 단위가 아니라 픽셀을 복원한다. 그럼에도 우리는 MAE가 복잡하고 전체적인 복원을 추론하는 것을 관찰했으며(그림 4), 이는 수많은 시각적 컨셉, 즉 의미을 학습했음을 시사한다. 우리는 이 행동이 MAE 내부의 풍부한 hidden representation의 덕분에 나타난다고 가정한다. 이 관점이 향후 연구에 영감을 주기를 희망한다.
Broader impacts.
제안된 방법은 학습된 데이터셋의 통계에 기반하여 컨텐츠를 예측하며, 이는 부정적인 사회적 영향을 포함하는 데이터의 bias를 반영할 수 있다. 또한 모델이 존재하지 않는 컨텐츠를 생성할 수 있다. 이러한 이슈는 이 작업 위에 이미지 생성 작업을 구축할 때 추가 연구와 고려가 필요하다.
