
•
지금까지 배운 것은 Supervised Learning

•
Relative Relationship은 명시적으로 Labeling을 해주지는 않고, 대신 현재 이미지와 비슷한 이미지를 제시함
◦
(결국 클러스터링을 해주는 것)

•
Metric Learning이란 오브젝트 간의 Distance Function을 만드는 머신러닝
•
데이터셋의 의미가 상황에 따라 다를 수 있음

•
두 이미지의 유사도를 점수로 내려면 어떻게 모델링 해야 할까?

•
어떤 것은 어떤 것에 비해 더 비슷하다.

•
유사도를 위와 같이 할 수도 있음

•
기존의 라벨링 대신 유사한 이미지를 이용해서 학습하는 이유는 그게 데이터 수집이 더 쉽기 때문
◦
positive pairs를 만들기도 쉬움 - data augmentation
•
하지만 수학적으로 noise가 발생하기 쉬움
◦
a가 b보다 가깝고, b가 c보다 가깝고, c가 d보다 가까운데, d가 a보다 가까운 상황이 나올 수 있음

•
Metric Learning도 Supervised Learning이다.
◦
다만 label 형식이 다른 형태임

•
레이블은 다른 형식으로도 할 수 있음

•
오늘 배울 것들

•
Learning to Rank는 말 그대로 Rank를 배우는 것
•
Learning to Rank의 학습데이터는 어느 정도 order가 적용된 아이템들의 list로 되어 있음
•
Rank Model은 어느 정도 정렬된 item들의 순열을 생성해 낸다.
◦
추천 영상 목록 등 —정확히 정렬되었다고 하기는 어렵지만, 적당히 정렬됨. 애초에 사용자의 데이터가 희소하기 때문
•
문서 검색, 추천 시스템, 광고 등이 예시

•
문제는 Point-wise, Pair-wise, List-wise로 구분할 수 있음
◦
Point-wise는 regression, classification과 비슷함. 각 아이템은 점수가 있고 그걸 학습 함.
◦
Pair-wise는 선호가 반영된 쌍으로 된 아이템을 학습함 —두 개 중 어느게 더 나은지 판단
◦
List-wise는 2개 이상의 정렬된 아이템을 받아서 최적을 학습함. 이거는 비용이 비싸서 잘 안 쓰임

•
Rank 모델을 만드는 이유는 추천을 잘하려는 목표도 있고, image나 video를 representation 하려는 목표도 있음
•
선호를 ordering 하는 과정에서 image와 video를 representation할 것이다는 가정. 그걸로 일반화가 가능할 것이다.
◦
비슷한 얼굴을 계속 학습하면 결국 얼굴이 비슷하다는 컨셉을 이해할 수 있을 것이다.

•
Ranking을 평가하는 방식으로는 NDCG를 많이 사용 함
◦
리스트가 있을 때 리스트 상위에 높은 점수를 갖도록 하는게 중요함.
•
DCG 식
◦
식의 좌우는 rel가 지수냐 아니냐의 차이인데 rel은 정답이면 1 아니면 0이 나오는 값이 됨
▪
보통 1아니면 0을 쓰는데 이러면 두 식은 사실 같음
▪
그런데 넷플릭스 같은데는 1-5개짜리 별점을 사용해서 왼쪽 식을 사용하면 1-5점이 나오고 오른쪽 수식을 사용하면 1-31점까지 나올 수 있음
◦
아래의 i는 순위에 대한 것으로 만일 1순위였으면 분모는 1이 되고, 3순위였으면 분모는 2가 되고, 7순위 였으면 분모는 3이 되어서 순위가 아래일 수록 점수가 낮아지도록 설계함
▪
3위는 1위보다 2배 덜 중요하고 7위는 1위보다 3배 덜 중요하다.
•
NDCG는 Normalized DCG라는 의미가 된다.
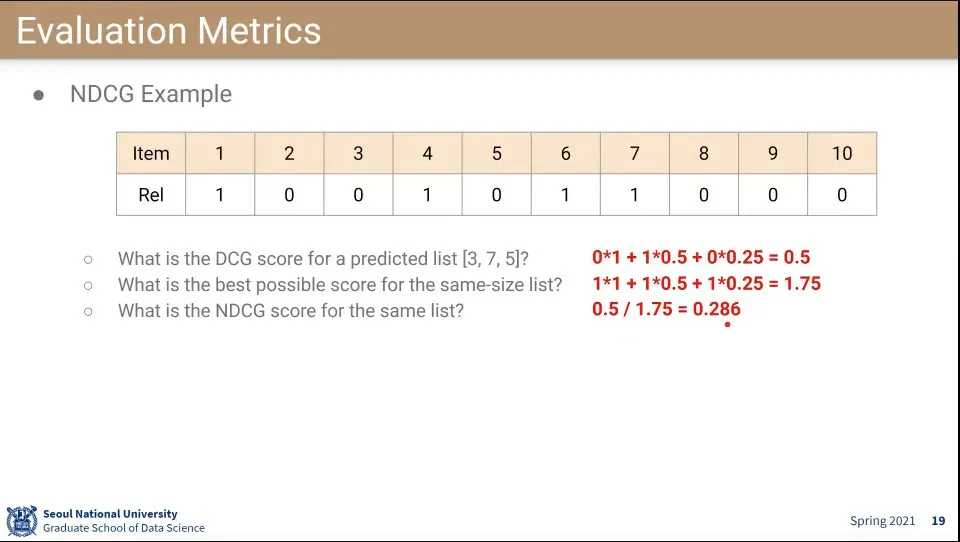
•
NDCG 계산 예 —위 수식에서 2번째는 0.5가 아닌데 실수함. 3번째가 0.5이고, 2번째는 값이 됨
◦
1순위를 틀리고, 2순위를 맞추고, 3순위를 틀린 상태에서 위와 같이 계산 됨
◦
맞춘 점수 —위 예에서 0.5— 를 best일 때 가능한 점수 —위 예에서 1.75— 로 나눠서 normalize 시킨다. —최종 0.286

•
Triplet Loss는 3가지가 하나의 데이터를 이루고, 각각 anchor, positive, negative가 됨.
◦
이때 anchor는 기준이 되고 —query가 됨—, positive는 anchor와 가까운 것, negative는 anchor와 먼 것을 의미한
•
고로 anchor와 positive가 가까이, anchor와 negative를 멀게 하도록 학습하는게 목표임. 아래 수식은 그것에 대한 것
◦
anchor와 positive의 거리, anchor와 negative의 거리 차이를 이용하여 그 결과를 minimize되도록 하는게 L값이 됨
◦
는 하이퍼파라미터인데, positive - negative의 값이 보다 커지면 전체 수식은 음수가 되고 그렇게 되면 학습이 잘 된 것으로 본다.
◦
그래서 목표는 보다 postivie - negative의 값이 작아지도록 하는 것

•
positive 데이터는 anchor와 관련 있는 데이터로 하고 negative 데이터는 보통 랜덤으로 뽑음.
•
다만 단순 무작위로 하면 잘 안 됨
◦
처음에는 학습이 조금 되지만, 몇 번 학습하면 더 배울게 없어짐

•
위와 같이 학습하면 금방 학습이 되어서 더 학습이 안 됨. 아래와 같이 해줘야 학습이 잘 됨

•
그래서 Online Negative Mining을 함
◦
일단 처음에는 random으로 시작 함
◦
그러다가 나중에는 나머지 batch에서 negative로 쓸만한 것들을 찾음
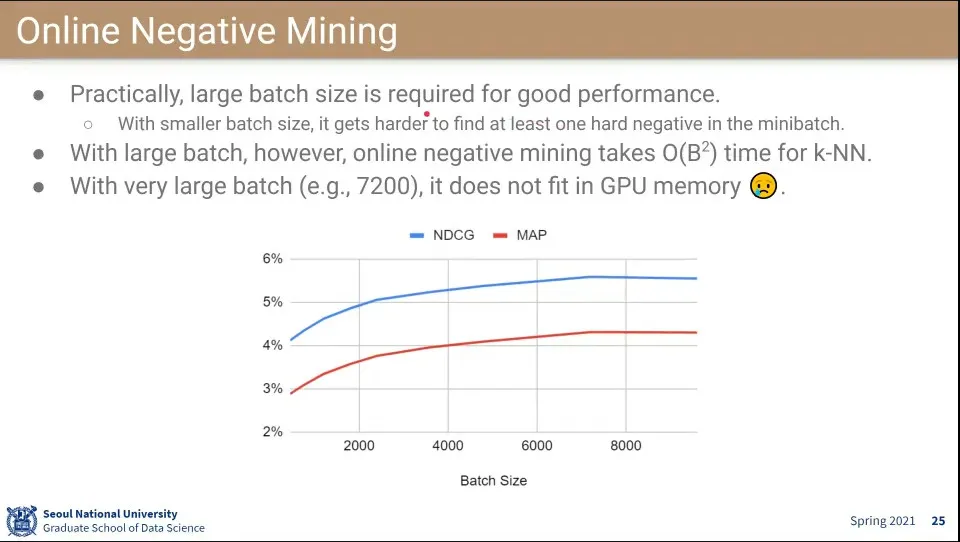
•
그래서 이 방법이 효과를 보려면 batch size가 커야 됨
◦
근데 batch size가 커질수록 계산량이 커짐.
◦
또한 메모리 한계도 존재 함

•
3가지 negative가 있다고 할 때
1.
positive 보다 가까움
•
이 경우 수식 상 negative 부분이 더 작기 때문에 positive의 값이 0에 수렴되도록 학습 됨
2.
positive 보다는 멀지만, 를 더한 것보다는 가까움
•
이게 학습하기 좋음
3.
를 더한 것보다도 멈
•
이거는 딱히 학습할게 없음
•
고로 2번에 해당하는 negative 데이터를 mining 함

•
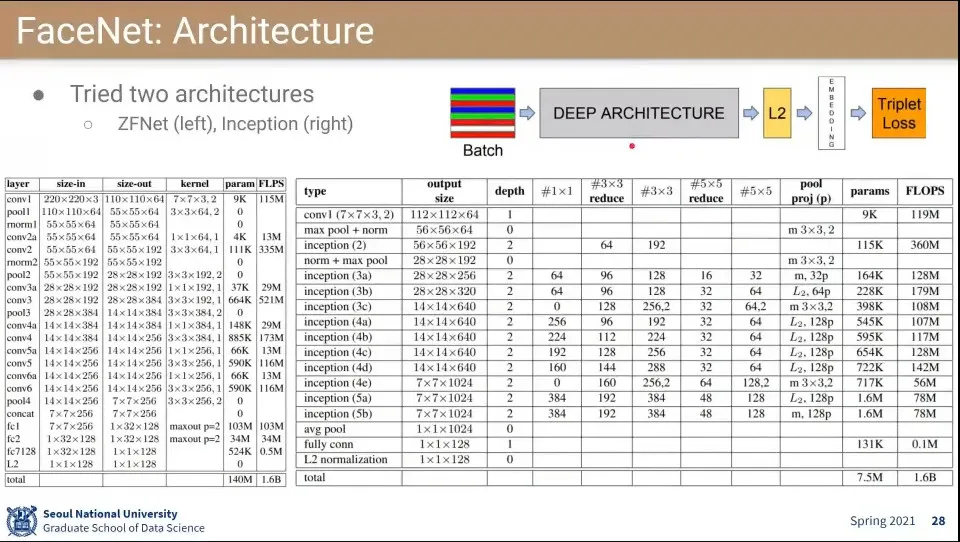
FaceNet은 TripleLet 적용한 첫 논문
◦
얼굴 클러스터링 문제를 처리함
•
같은 사람을 찾는데 정확도가 99%, 95%라는 놀라운 수치가 나옴
◦
실제로 공항에서 사용될 정도로 잘 됨
•
앞 부분은 기존 deep learning과 유사하고 마지막 loss 부분만 Triplelet Loss를 사용함
•
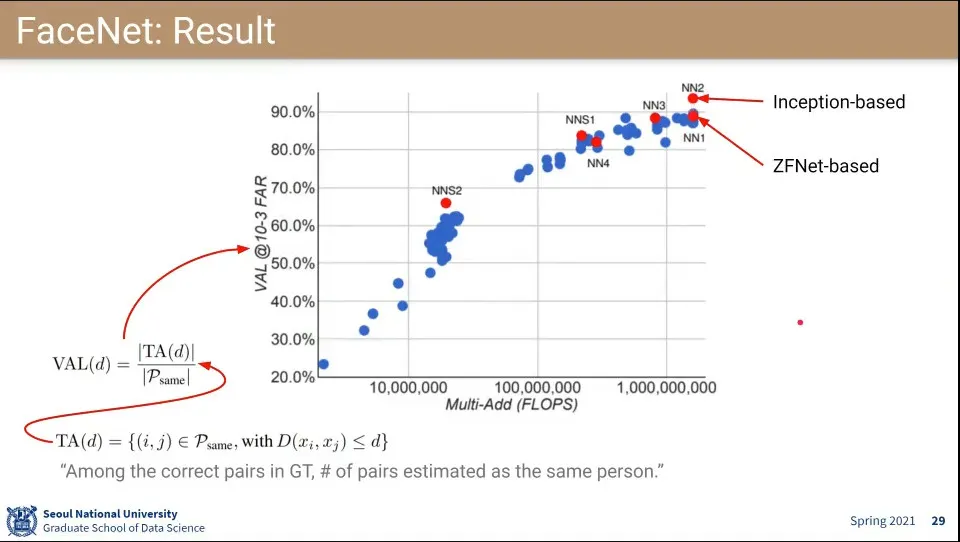
모델별로 결과

•
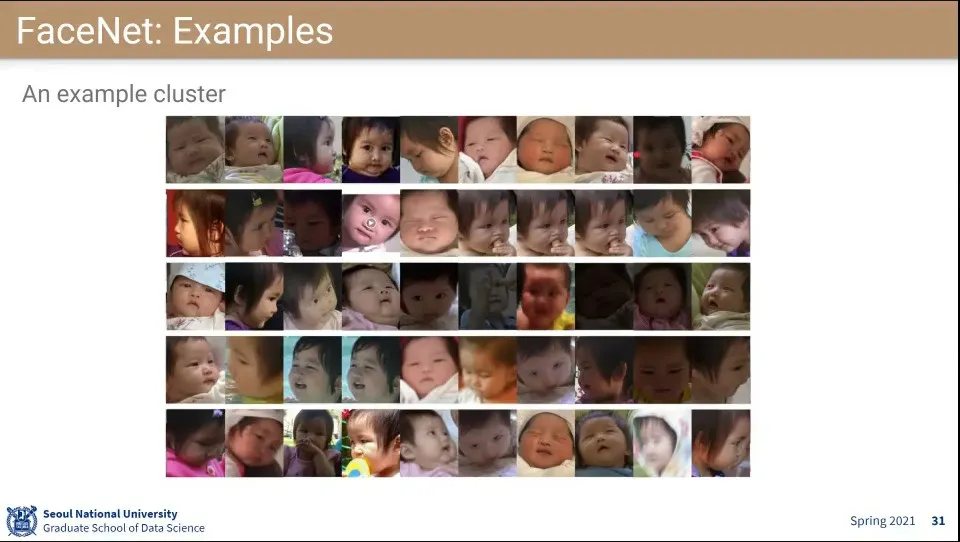
결과 예시

•
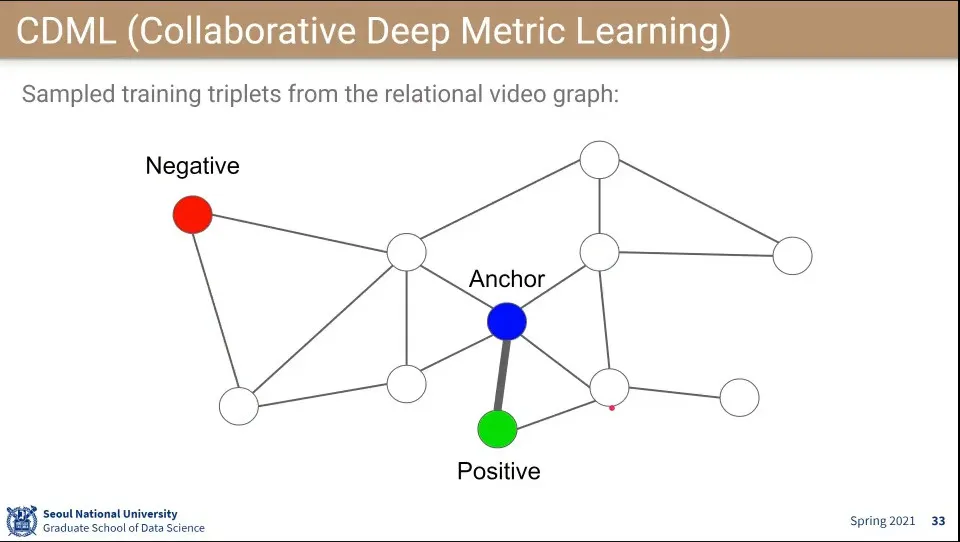
CDML은 같은 아이디어를 Video 추천에 적용한 모델
◦
좋아요, 싫어요를 이용해서 나와 비슷한 사람들을 모음
•
Anchor를 랜덤하게 잡고, 연결성이 있는 것을 Positive로 관련성이 없는 것을 Negative로 잡고 학습 함
•
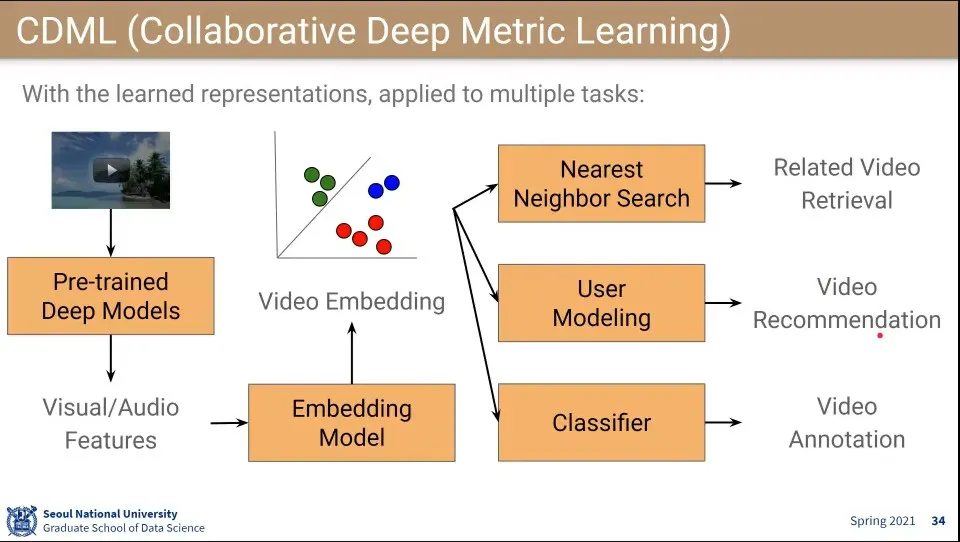
Video Embedding 모델을 만들면 다른 것을 붙여서 여러 형태로 사용할 수 있음
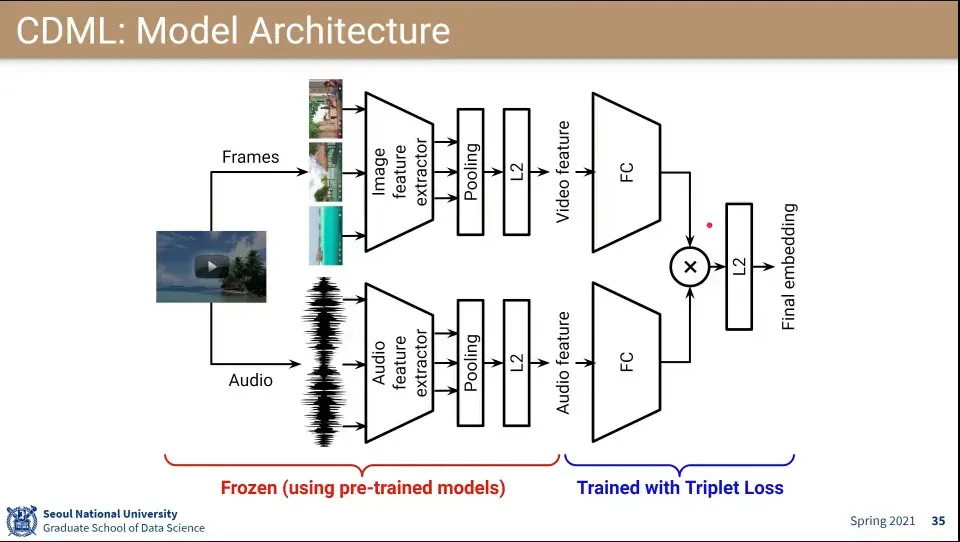
•
모델 Layer 구조
◦
이미지와 audio를 나눠서 학습시키고 나중에 합침
◦
loss 부분은 Triplet Loss를 사용함
•
사례

•
CDML의 한계
◦
batch size가 커야 됨
◦
online negative mining 때문에 메모리 한계로 GPU도 못 씀
•
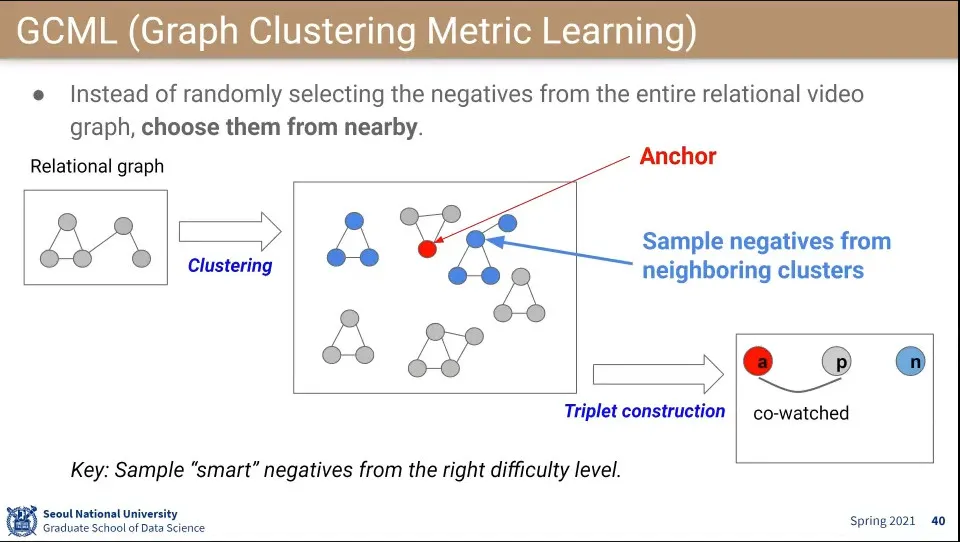
CDML의 한계를 개선한게 GCML
◦
Negative를 Random하게 찍지 않고, 잘 고르자는 것
•
relational graph를 잘 클러스터링 함
◦
가까운 cluster에서 negative로 고르자
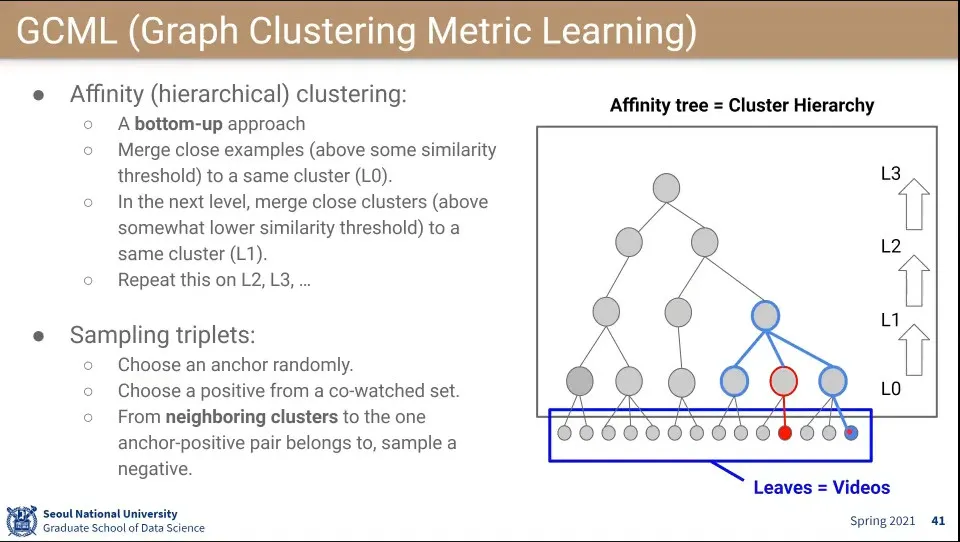
•
bottom up으로 cluster를 합침
•
그렇게 합친 후에 negative를 형제 cluster 중에서 고름
◦
만일 형제에서 안 되면 한 단계 더 올라가서 고름
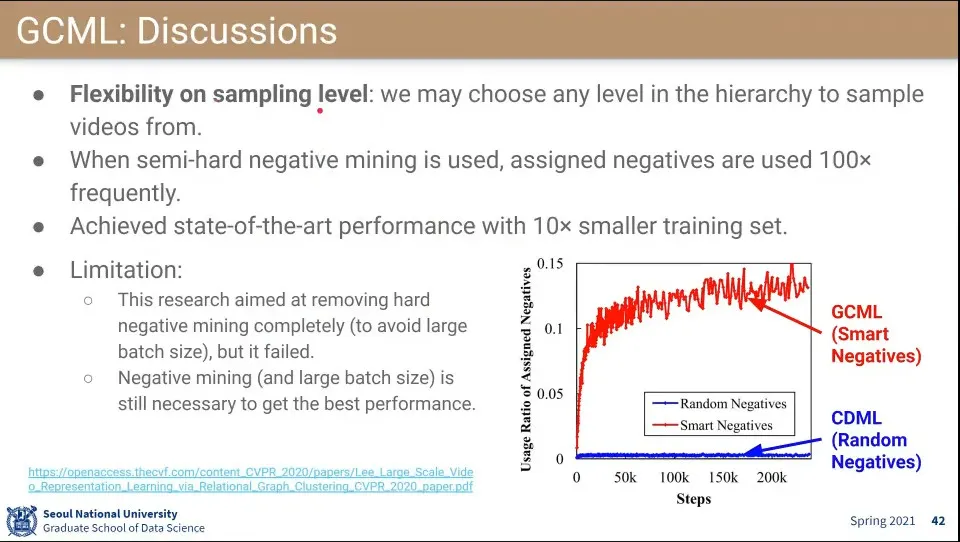
•
Level을 조절하면서 데이터를 샘플링할 수 있음
•
효과는 있었지만 semi-hard negative를 완전히 없애지는 못 함
◦
훨씬 작은 데이터셋(1/10)으로도 성능은 비슷하게 할 수 있었음

•
Contrastive Learning은 3개를 쓰는 Triplet과 달리 2개만 사용함
◦
대신 두 이미지가 비슷하면 0, 비슷하지 않으면 1이 되도록 함
•
유사한 경우와 유사하지 않은 경우에 Loss 를 다른 것을 사용함
◦
유사한 이미지일 경우 distance가 커질수록 loss가 커지도록 함
◦
유사하지 않은 이미지일 경우 distance가 가까울수록 loss가 커지도록 함

•
학습 방법

•
이미지들을 classfication 할 때 맨 마지막에 class 개수만큼의 softmax 함수를 사용
•
만일 클래스 개수가 수백만-수천만개 있다면 저걸 다 계산하는게 비효율적이다.
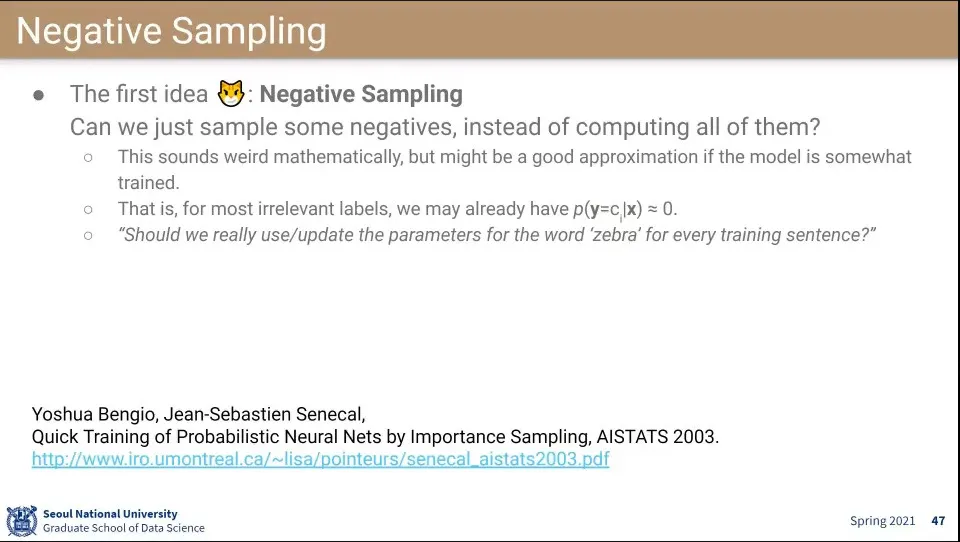
•
zebra 같은 잘 안 쓰이는 단어를 반영해주는게 비효율적이므로 여기에도 negative sampling을 해주자는 아이디어
•
근데 실제로는 잘 되기도 할 때도 있고 잘 안될 때도 있음
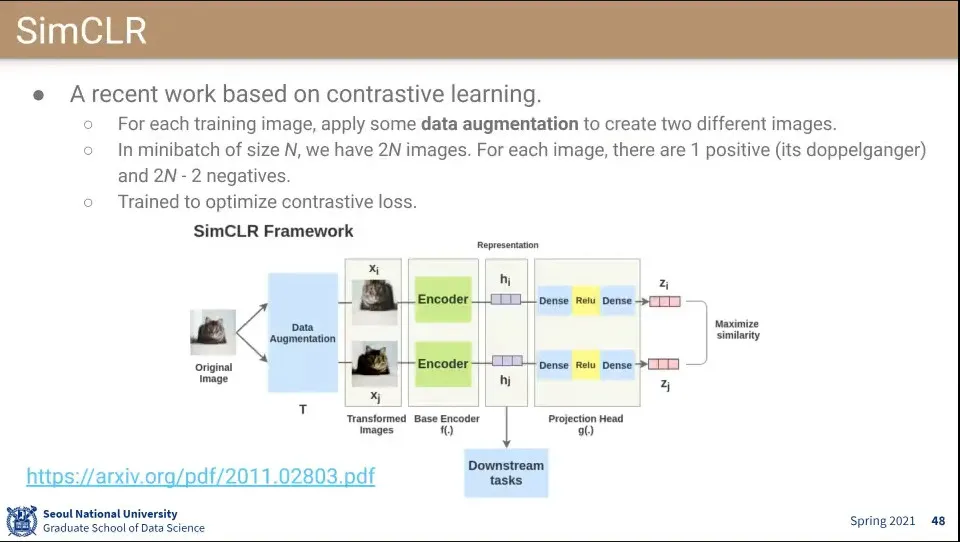
•
SimCLR은 contrastive learning을 적용한 방식
◦
오리지날 데이터에 대해 data augmentation을 적용해서 pair를 만들고 그것을 positive로 설정.
◦
오리지날 데이터에 pair를 만들었으므로 데이터 전체는 2N개가 되고, 자기 자신과 positive를 제외한 2N-2개를 모두 negative로 설정
◦
그것을 이용해서 contrastive learning을 한다.

•
Contrastive loss
◦
분자는 유사도를 구하고 그 값이 높아지도록 함
◦
분모는 2N개의 미니 배치에 대해서만 유사도를 구하고 그 값이 낮아지도록 함
•
이렇게 했더니 self-supersized learning 효과가 발생함. 사람이 labeling 하지 않아도, 스스로 관련 있는 것들을 찾아냄

•
위 방법을 좀 더 체계화 한 것이 NCE. 요즘 많이 쓰임
◦
처음에는 word embedding에서 적용되었음
•
true-pair(중심에 있는 단어와 같이 등장한 단어)가 있고 fake-pair(랜덤하게 고른 단어)가 있음
•
pair가 들어왔을 때 true-pair냐, fake-pair냐를 학습함
◦
이렇게 하면 word vector들이 의미를 할 것이다는 기대

•
학습 example 개가 있을 때, 그 학습 example이 만들어진 어떤 확률 분포 이 있다고 가정
◦
이것이 각 단어들의 출현 확률 같은 것이 됨. 알고자 하는 것이 바로 이 확률 분포
•
예전에는 classfication을 위해 softmax를 씌우고 했었는데 이걸 안하기 위해 —안하는 이유는 계산량이 비효율적이기 때문— fake 확률 분포 이 있다고 가정.
◦
그리고 거기서 개의 샘플을 만들어 냄
•
과 에서 데이터를 가져와서 무작위로 섞은 후에 binary classification 을 푸는 형식으로 바꿈
◦
softmax를 풀지 않고 진짜인거 가짜인것만 구별하도록 함

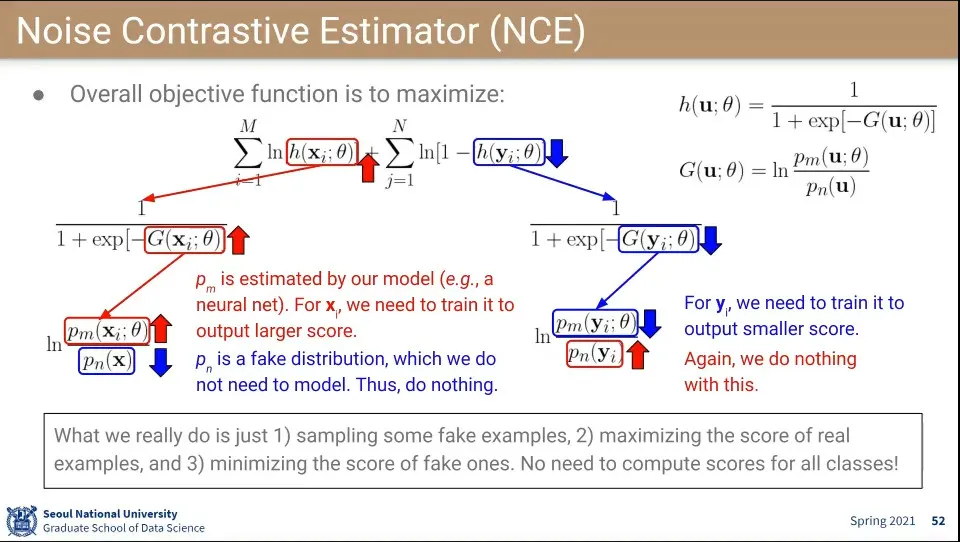
•
위 식이 기본 식인데, 왼쪽 것(M개)은 진짜이고 오른쪽(N개)은 fake가 됨. 목표는 식이 maximize하게 하는 것
◦
maximize해야 하므로 진짜는 값이 크게 나오도록 해야 하고, 가짜는 값이 작게 나오도록 학습이 되어야 함
•
진짜, 가짜의 수식의 의미는 box의 화살표를 따라가면 됨
◦
둘 다 함수 자체는 동일한데 그 결과가 반대가 나오도록 해야 함
◦
시그모이드 함수 말고 다른 함수는 (진짜일 확률 / 가짜일 확률)의 형식으로 값이 커질 수록 진짜일 확률이 높아짐
•
이렇게 해서 진짜인 것끼리 가깝게 하고 가짜인 것은 멀어지게 함
