
Feature Pyramid Networks (FPN)
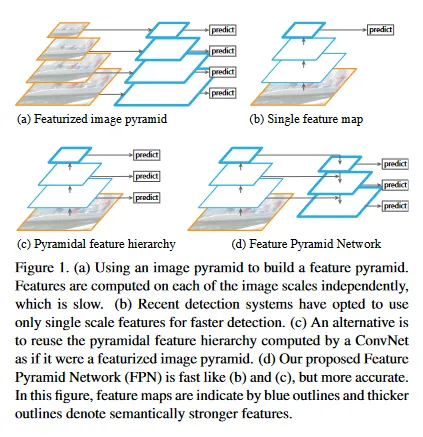
Feature Pyramid Network(FPN)은 특정 AI 모델이 아니라 UNet과 같은 아키텍쳐를 의미한다. FPN을 이해하기 위해서는 우선 위 그림의 (a) Featurized Image Pyramid, (b) Single Feature Map, (c) Pyramidal (d) Feature Hierarchy를 이해해야 한다.
(a) Featurized Image Pyramid는 단일 이미지를 여러 해상도의 이미지로 만든 후에, 각각에 대해 feature를 추출(SIFT, HOG, CNN 등)해서 feature map을 만들고 예측을 수행하는 방식이다. 이것은 낮은 해상도에서 high-level feature를 추출하고, 높은 해상도에서 low-level feature를 추출하기 위한 방식이었다. 물론 동일한 이미지를 여러 해상도로 만들어서 예측을 수행하기 때문에 연산 시간이 그만큼 늘어난다는 단점이 존재한다.
(b) Single Feature Map은 일반적으로 생각할 수 있는 CNN과 같은 신경망으로 단일 이미지를 여러 layer에 통과시키면서 이미지 크기를 줄이고, 마지막 layer에서 feature를 뽑아 예측하는 방식이다. 이것은 당연히 multi-scale의 object를 인식하는데 한계가 존재한다.
(c) Pyramidal feature hierarchy는 Featurized Image Pyramid와 Single Feature Map을 합친 방식으로, Single Feature Map과 같이 layer을 통과시키며 이미지 크기를 줄이는데, 모든 layer에서 feature를 추출하여 feature map을 만들고 예측하는 방식이다. 모든 layer에서 feature를 추출하기 때문에 초기 layer에서는 고해상도의 low-level feature를 추출하고, 뒤의 layer에서는 저해상도의 high-level feature를 추출하게 된다.
(d) Feature Pyramid Network(FPN)은 Pyramidal feature hierarchy를 확장시킨 방법으로 Pyramidal feature hierarchy를 bottom-up pathway로 두고, 그 뒤에 축소된 이미지를 다시 upsampling 하여 원래 크기로 되돌리는 top-down pathway를 붙인다. pyramidal feature hierarchy 처럼 top-down pathway의 모든 layer에서 feature를 추출하여 feature map을 만들고 예측을 수행하는데, 이미지 크기가 작은 top-down의 초기 layer에서는 high-level feature를 추출하고, 이미지가 큰 top-down의 후반부 layer에서는 low-level feature를 추출하게 된다.
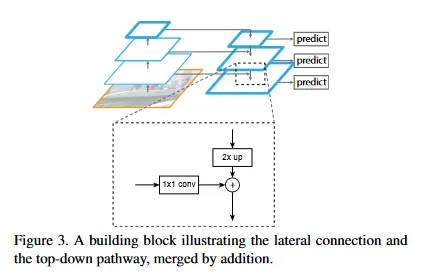
top-down에서 단순히 feature를 추출할 때는 bottom-up pathway의 동일한 layer에서 추출된 feature를 lateral connection으로 병합하여 feature를 추출한다. (이것은 UNet의 skip-connection과 유사하다)
여기까지만 보면 DownSampling 했다가 다시 UpSampling하는 것이나 DownSampling 단계의 결과를 UpSampling 단계에 connection 한다는 점에서 FPN이 UNet과 매우 유사하게 생각될 수 있다. 실제로도 두 아키텍쳐는 많이 비교된다.
다만 차이는 UNet은 마지막에 한 번만 예측을 수행하는 반면, FPN은 layer 별로 예측을 한다는 점이 다르다. 따라서 UNet은 pixel-level로 단일 예측을 해야 하는 경우 —diffusion model, 의료 이미지 segmentation 등—에 주로 쓰이고, FPN은 multi-scale의 여러 object가 존재하는 object detection 분야에 주로 쓰인다. 논문 저자에 의하면 FPN으로 segmentation도 잘 된다고 한다.
Sample Code
Facebook Detecton 2 참조. github의 detectron/detectron/modeling/backbon/fpn.py에 존재함.
bottom_up에 대해서는 다양한 backbone을 사용할 수 있다.
forward 부분 코드를 보면 우선 입력을 bottom_up에 넣어 결과를 얻은 후, 반복문을 통해 top_down path를 진행하면서 bottom_up의 동일 layer에서 feature를 뽑아 lateral_features로 추가하는 것을 볼 수 있다. 이때 top_down_feature는 이전 feature에 대해 nearest 모드로 interpolate한 것을 사용하고 bottom_up의 feature는 lateral_conv를 통과시켜 lateral_features로 만들어서 합친다. 그렇게 합쳐진 feature는 최종적으로 output_conv를 통과시켜 layer별 result에 담는다.
따라서 bottom_up에 해당하는 backbone을 pre-trained 모델을 사용한다고 하면, 이 네트워크에서 학습이 되는 부분은 lateral_conv와 output_conv가 된다. upsampling은 interpolate —default은 nearest—을 통해 계산하므로 학습되지 않는다.
class FPN(Backbone):
"""
This module implements :paper:`FPN`.
It creates pyramid features built on top of some input feature maps.
"""
_fuse_type: torch.jit.Final[str]
def __init__(
self,
bottom_up,
in_features,
out_channels,
norm="",
top_block=None,
fuse_type="sum",
square_pad=0,
):
"""
Args:
bottom_up (Backbone): module representing the bottom up subnetwork.
Must be a subclass of :class:`Backbone`. The multi-scale feature
maps generated by the bottom up network, and listed in `in_features`,
are used to generate FPN levels.
in_features (list[str]): names of the input feature maps coming
from the backbone to which FPN is attached. For example, if the
backbone produces ["res2", "res3", "res4"], any *contiguous* sublist
of these may be used; order must be from high to low resolution.
out_channels (int): number of channels in the output feature maps.
norm (str): the normalization to use.
top_block (nn.Module or None): if provided, an extra operation will
be performed on the output of the last (smallest resolution)
FPN output, and the result will extend the result list. The top_block
further downsamples the feature map. It must have an attribute
"num_levels", meaning the number of extra FPN levels added by
this block, and "in_feature", which is a string representing
its input feature (e.g., p5).
fuse_type (str): types for fusing the top down features and the lateral
ones. It can be "sum" (default), which sums up element-wise; or "avg",
which takes the element-wise mean of the two.
square_pad (int): If > 0, require input images to be padded to specific square size.
"""
super(FPN, self).__init__()
assert isinstance(bottom_up, Backbone)
assert in_features, in_features
# Feature map strides and channels from the bottom up network (e.g. ResNet)
input_shapes = bottom_up.output_shape()
strides = [input_shapes[f].stride for f in in_features]
in_channels_per_feature = [input_shapes[f].channels for f in in_features]
_assert_strides_are_log2_contiguous(strides)
lateral_convs = []
output_convs = []
use_bias = norm == ""
for idx, in_channels in enumerate(in_channels_per_feature):
lateral_norm = get_norm(norm, out_channels)
output_norm = get_norm(norm, out_channels)
lateral_conv = Conv2d(
in_channels, out_channels, kernel_size=1, bias=use_bias, norm=lateral_norm
)
output_conv = Conv2d(
out_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1,
bias=use_bias,
norm=output_norm,
)
weight_init.c2_xavier_fill(lateral_conv)
weight_init.c2_xavier_fill(output_conv)
stage = int(math.log2(strides[idx]))
self.add_module("fpn_lateral{}".format(stage), lateral_conv)
self.add_module("fpn_output{}".format(stage), output_conv)
lateral_convs.append(lateral_conv)
output_convs.append(output_conv)
# Place convs into top-down order (from low to high resolution)
# to make the top-down computation in forward clearer.
self.lateral_convs = lateral_convs[::-1]
self.output_convs = output_convs[::-1]
self.top_block = top_block
self.in_features = tuple(in_features)
self.bottom_up = bottom_up
# Return feature names are "p<stage>", like ["p2", "p3", ..., "p6"]
self._out_feature_strides = {"p{}".format(int(math.log2(s))): s for s in strides}
# top block output feature maps.
if self.top_block is not None:
for s in range(stage, stage + self.top_block.num_levels):
self._out_feature_strides["p{}".format(s + 1)] = 2 ** (s + 1)
self._out_features = list(self._out_feature_strides.keys())
self._out_feature_channels = {k: out_channels for k in self._out_features}
self._size_divisibility = strides[-1]
self._square_pad = square_pad
assert fuse_type in {"avg", "sum"}
self._fuse_type = fuse_type
@property
def size_divisibility(self):
return self._size_divisibility
@property
def padding_constraints(self):
return {"square_size": self._square_pad}
def forward(self, x):
"""
Args:
input (dict[str->Tensor]): mapping feature map name (e.g., "res5") to
feature map tensor for each feature level in high to low resolution order.
Returns:
dict[str->Tensor]:
mapping from feature map name to FPN feature map tensor
in high to low resolution order. Returned feature names follow the FPN
paper convention: "p<stage>", where stage has stride = 2 ** stage e.g.,
["p2", "p3", ..., "p6"].
"""
bottom_up_features = self.bottom_up(x)
results = []
prev_features = self.lateral_convs[0](bottom_up_features[self.in_features[-1]])
results.append(self.output_convs[0](prev_features))
# Reverse feature maps into top-down order (from low to high resolution)
for idx, (lateral_conv, output_conv) in enumerate(
zip(self.lateral_convs, self.output_convs)
):
# Slicing of ModuleList is not supported https://github.com/pytorch/pytorch/issues/47336
# Therefore we loop over all modules but skip the first one
if idx > 0:
features = self.in_features[-idx - 1]
features = bottom_up_features[features]
top_down_features = F.interpolate(prev_features, scale_factor=2.0, mode="nearest")
lateral_features = lateral_conv(features)
prev_features = lateral_features + top_down_features
if self._fuse_type == "avg":
prev_features /= 2
results.insert(0, output_conv(prev_features))
if self.top_block is not None:
if self.top_block.in_feature in bottom_up_features:
top_block_in_feature = bottom_up_features[self.top_block.in_feature]
else:
top_block_in_feature = results[self._out_features.index(self.top_block.in_feature)]
results.extend(self.top_block(top_block_in_feature))
assert len(self._out_features) == len(results)
return {f: res for f, res in zip(self._out_features, results)}
def output_shape(self):
return {
name: ShapeSpec(
channels=self._out_feature_channels[name], stride=self._out_feature_strides[name]
)
for name in self._out_features
}
Python
복사
