

•
이미지 분류 문제는 이미지에 대해 label을 지정해 주는 문제
•
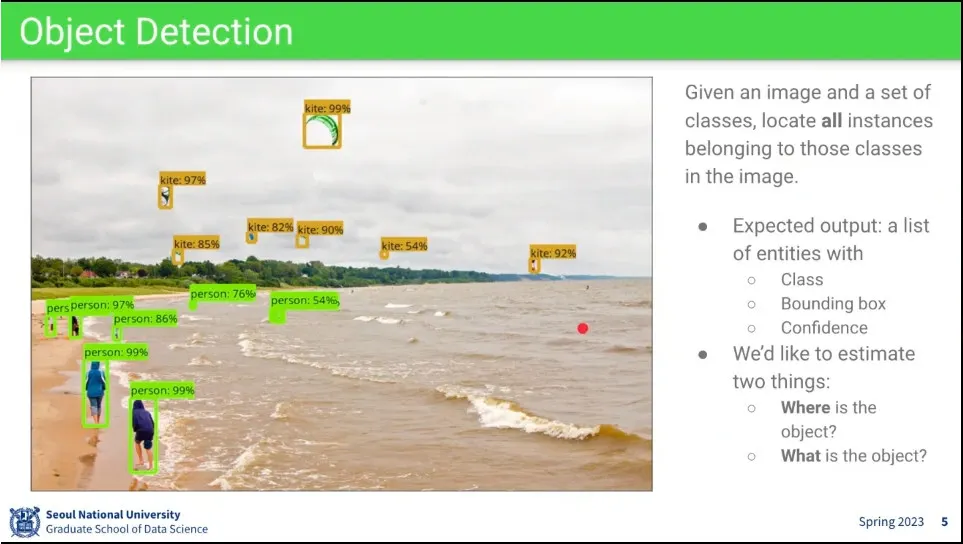
object detection은 object를 인식하고 그 위치까지 알아내야 함.
•
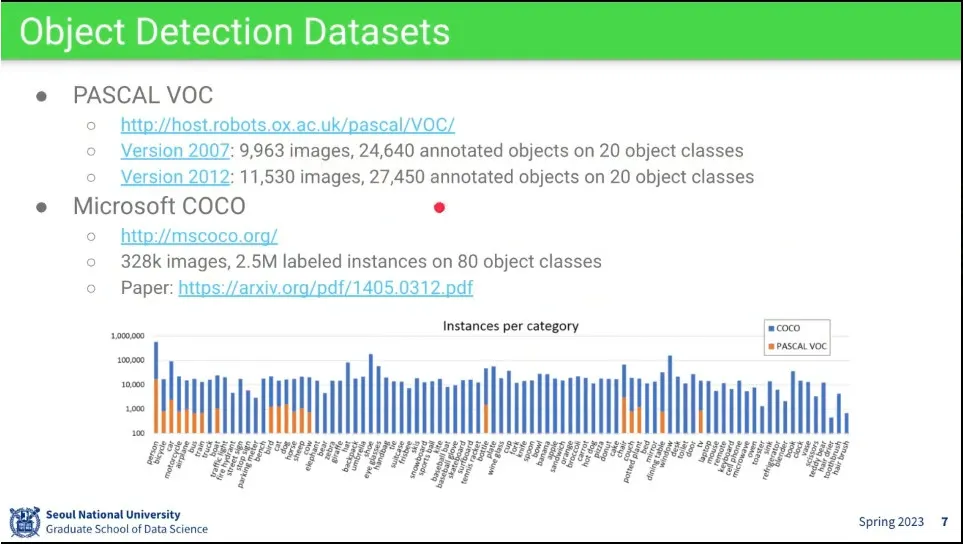
object detection의 dataset
◦
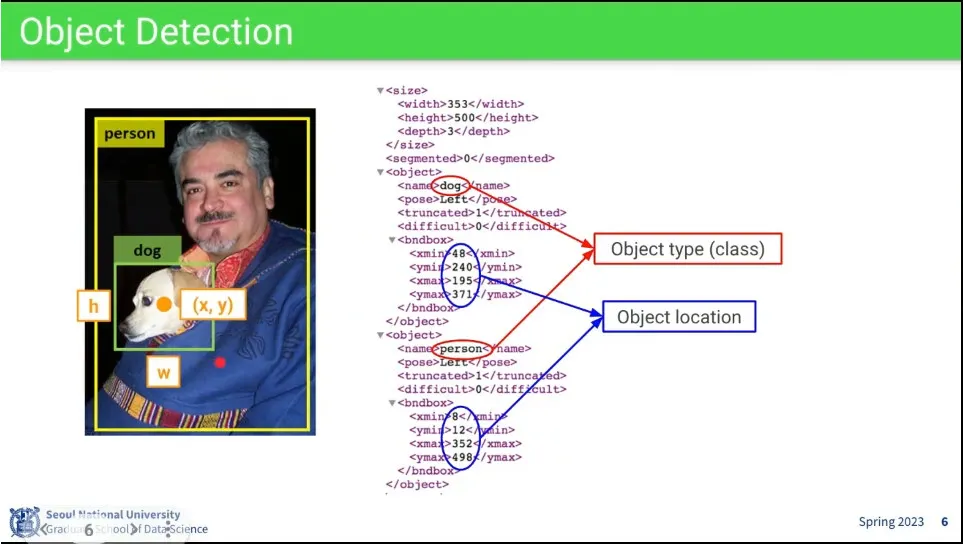
class 정보와 location 정보가 주어짐.
•
많이 쓰이는 데이터셋이 PASCAL VOC와 MS의 COCO

•
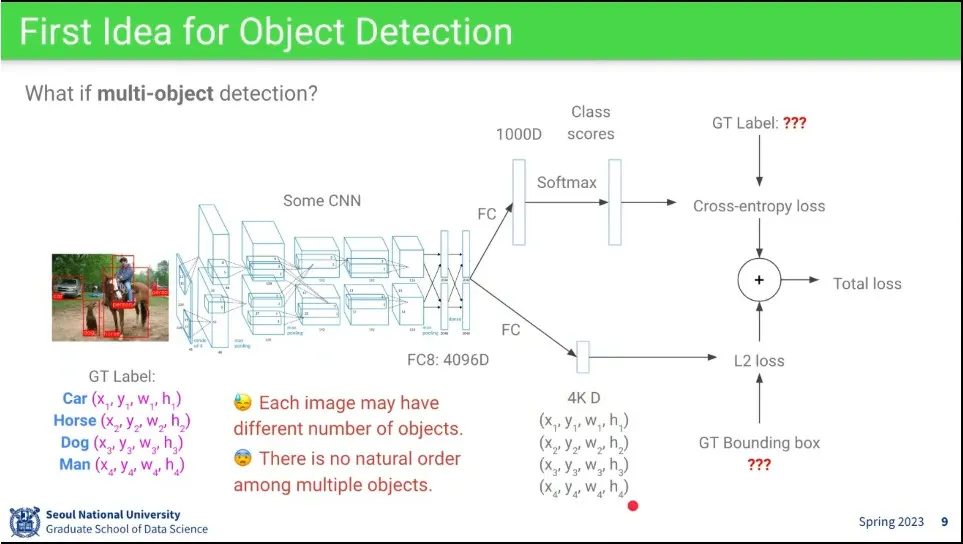
object detection을 위한 기본 아이디어.
◦
CNN을 돌린 후에 classifier와 regression을 해서 결과를 얻어 보자.
•
그런 접근 방법으로는 같은 object가 여러 개 있을 때 사용이 안 됨.

•
이미지를 patch로 자르는 방식은 어떨까? 이러면 계산 비용이 너무 비쌈

•
Proposal-based 방식과 Proposal-free 방식이 존재함.
◦
Proposal은 후보가 되는 box를 만들고 추려내는 방식으로 two-stage 방식이라고 함.
◦
그런거 없이 한 번에 detection이 되게 하는게 proposal-free 방식

•
R-CNN은 우선 Region을 찾고, 그 후에 거기서 object를 detection 함. —RNN과는 관계 없음.
◦
Region proposal은 전통 모델을 가져다 씀. 문제는 그 모델들이 엄청 느림.
◦
그렇게 box를 찾아내면 그걸 잘라내서 object recognition을 함.

•
동작 방식
◦
region에 나오는 값은 bounding box의 위치와 크기를 보정하는 값

•
상대 좌표 기준으로 예측 결과와 ground truth를 비교해서 loss를 줌.

•
R-CNN은 처음으로 딥러닝으로 한 모델.
•
단점은 계산 비용이 비쌈 - 2000장 뽑는 것도 문제고, region proposal도 비쌈.
•
Fast R-CNN은 R-CNN에서 2000장 뽑던 것을 개선함.
◦
Region proposal은 그대로 사용
◦
recognition에서 2000번 돌던 것을 1번만 하도록 함.
•
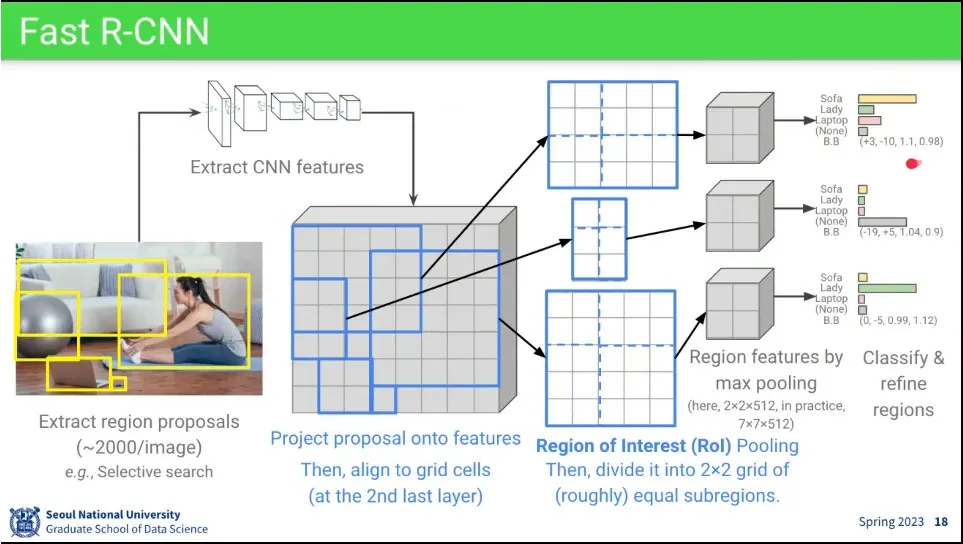
일단 이미지에서 region을 받으면 cnn feature의 마지막에 그 위치를 대응 시키고, 위치를 보정한 후에 max polling 해서 크기를 맞춘 후에 classifier를 돌림.

•
R-CNN 보다 빨라짐.
•
그러나 region proposal을 여전히 해결 못 함

•
Mask R-CNN은 Fast R-CNN에서 pooling 할 때 그냥 합치기 않고 가중치를 줘서 합침.

•
Faster R-CNN은 원래의 R-CNN에서 2단계는 그대로 쓰고 Region Proposal 부분을 개선한 모델

•
모델이 예측한 것과 ground truth와 IoU를 구해서, 그 값에 따라 Positive, Negative, Ignored를 구분
•
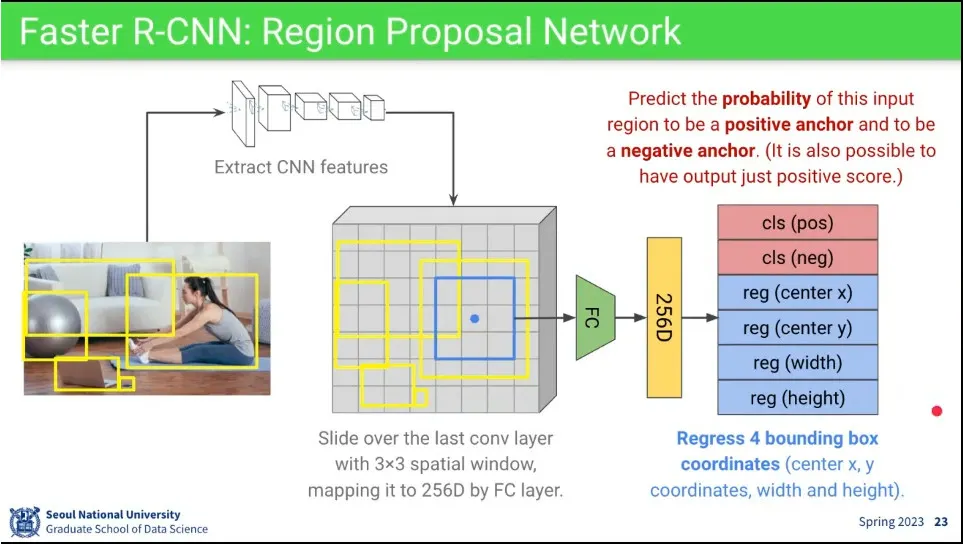
3x3의 box를 움직여가면서 ground truth에 대해 center와 width, height을 얼마나 맞는지와 object가 있는지 없는지를 예측하게 함.

•
다만 3x3으로는 크기와 비율이 안 맞기 때문에 1:1, 1:2, 2:1 3가지 비율과 더 작은 것과 더 큰 것까지 총 3개의 세트를 이용해서 예측하게 함.

•
loss는 앞에는 object가 있는지 없는지를 예측하고, 뒤에서는 bounding box를 예측하는 것을 합해서 사용 함.

•
처음에는 Region Proposal Network를 먼저 학습 시키고, 그게 어느 정도 학습이 되면, RPN을 freeze 시켜서 classifier만 학습 시키고, 그 후에 같이 학습 시킴.
•
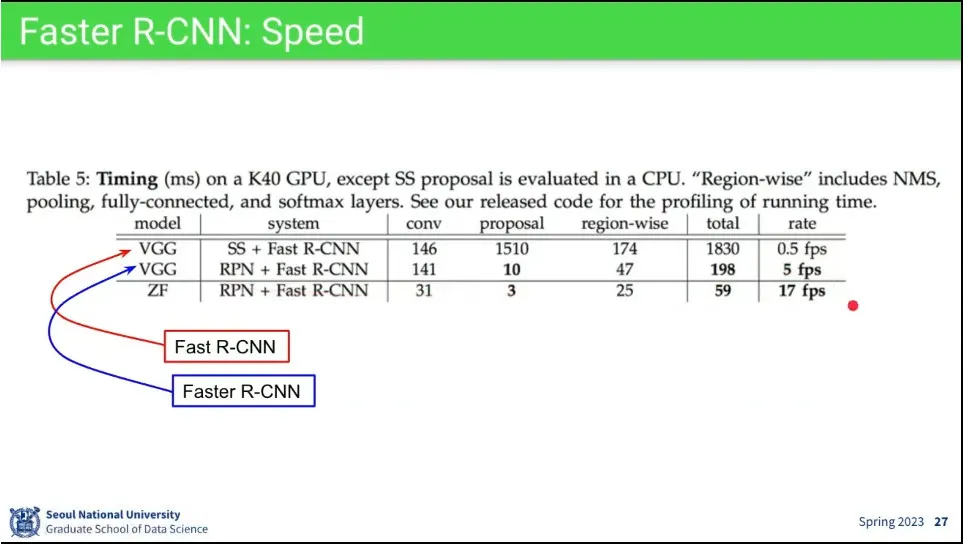
결과적으로 Fast R-CNN 보다 더 빨랐다.

•
Proposal free의 대표적인 것이 YOLO
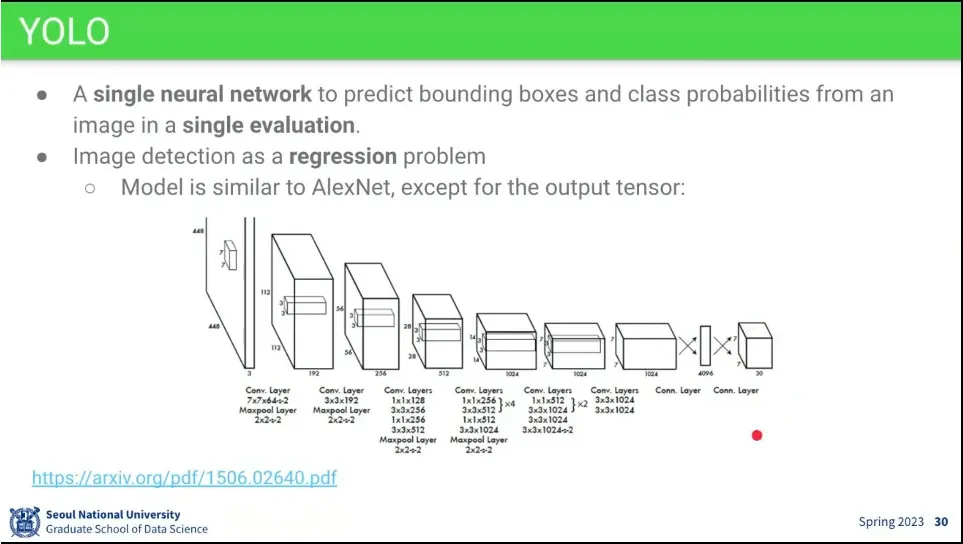
•
아키텍쳐는 Alex-Net과 유사하지만 마지막에 spatial 정보를 위해 7x7 conv를 하나 더 씀

•
기본 알고리즘은 7x7 grid로 나눈 후 각각의 cell이 bounding box의 center를 예측해야 하는 역할을 함 - (cx, cy, w, h, confidence)
◦
이미지처럼 물체가 겹쳐 있는 경우가 있을 수 있으므로 최대 2개까지 겹칠 수 있다고 가정
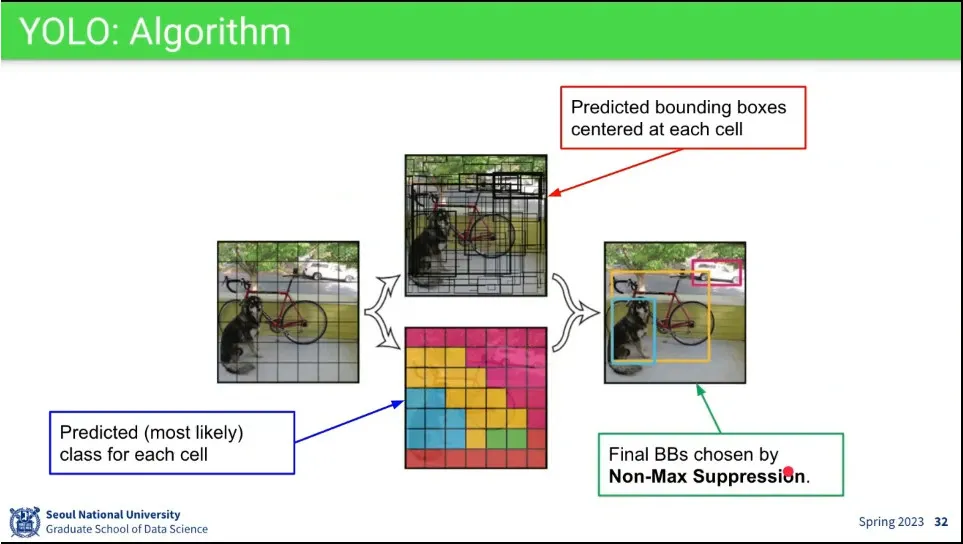
•
그리드를 7x7로 나눈 후, center를 예측하는 것과 class를 예측하는 것을 나눠서 수행하고, 그 결과를 합침.
◦
비슷한 grid에서 예측이 겹치므로 Non-Max Suppression을 이용해서 겹치는 것들 제거하고 최종으로 하나만 남김

•
NMS는 confidence가 제일 높은 것을 기준으로 겹치는 것을 지우는 것을 반복해서 최종적으로 하나씩만 남김
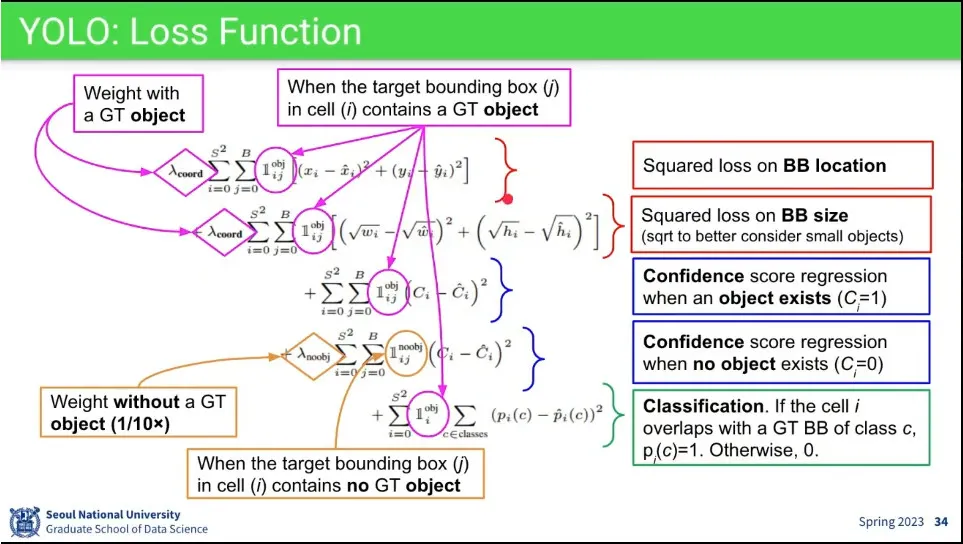
•
Loss는 아래 3개를 다 더해서 준다.
◦
앞 부분에서 cx, cy, width, height에 대한 loss를 주고(object가 없으면 계산 안하게 함),
◦
그 다음으로 confidence에 대한 loss를 더하고, 있는 것을 있다고 하는 것(positive)과 없는 것을 없다고 하는 것(negative) 맞추는 것을 나눠서 줌
◦
마지막으로 class를 맞추는 loss를 줌
•
하나의 식으로 bounding box와 class 예측을 다 함.

•
최종적으로 Fast R-CNN 보다 훨씬 빠른 성능을 냄. 대신 정확도는 조금 떨어짐.

•
SSD는 같은 class지만 크기가 다른 것을 한 번에 찾을 수 있는 것을 목표로 한 모델
◦
기존 vgg의 뒷부분에 conv를 추가하는데, 사이즈를 줄여가면서 처리

•
작은 강아지는 grid가 커야 찾을 수 있고, 큰 강아지는 grid가 작아야 찾을 수 있기 때문에, 각 단계 별로 크기가 다른 물체를 찾음.

•
Loss는 YOLO와 비슷하게 localization과 classification에 대해 주고 합쳐서 처리
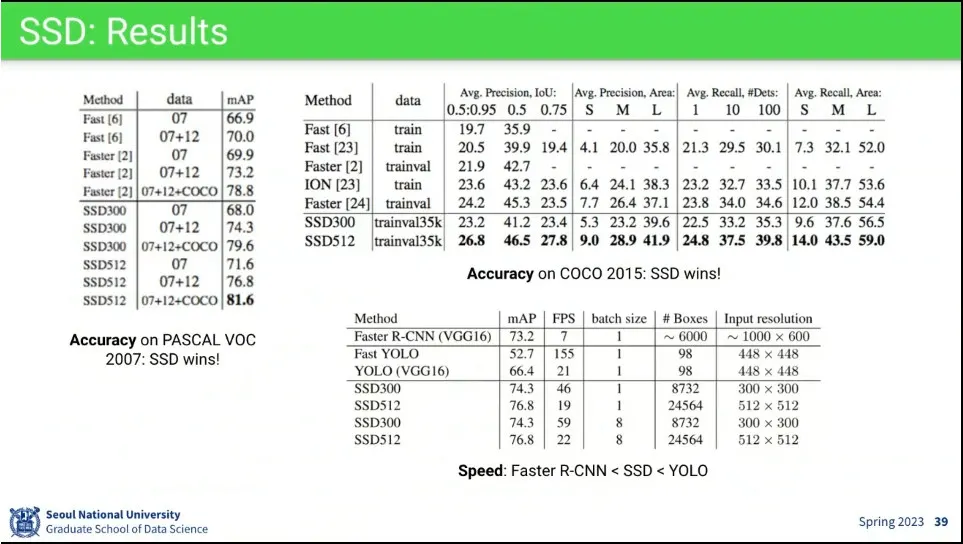
•
전체적으로 성능도 가장 좋음.
◦
속도도 빠르지만 YOLO 보다 느림, 대신 성능은 더 높다.

•
Transformer 기반으로 detection 하는 모델이 DETR
◦
NMS를 사용하지 않음.
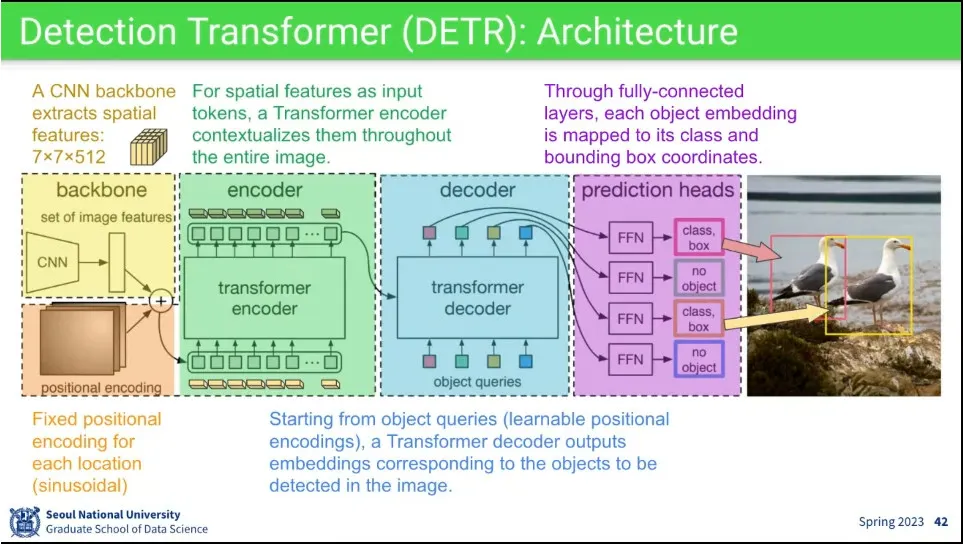
•
CNN으로 feature를 뽑아서 sinusoidal로 positional encoding 한 후에 transformer encoder에 넣음.
◦
그 결과에 대해 decoder에서 object query를 날려서 output을 뽑는데, 그 output이 detection이 되어야 함.
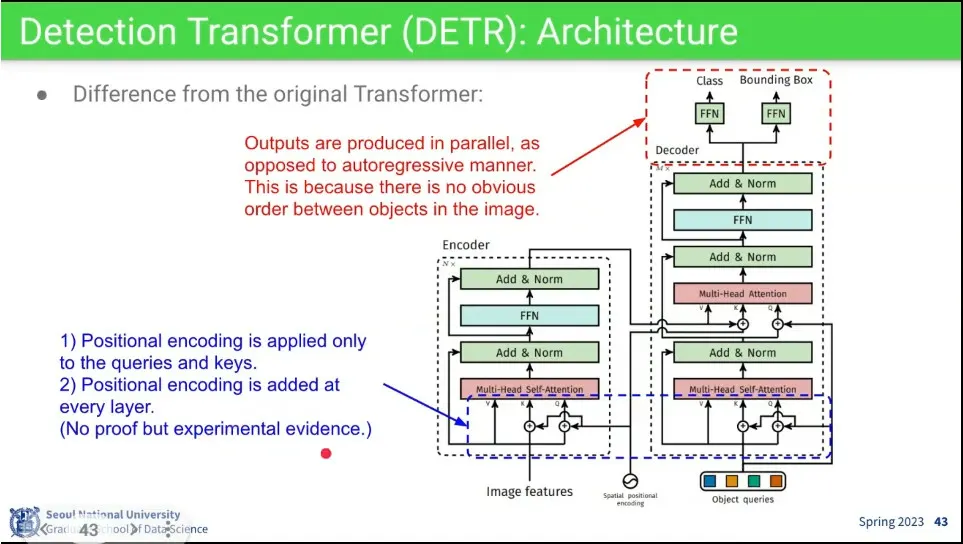
•
기본 transformer와 비슷하지만, 마지막에 decoder의 결과가 순서 없이 parallel로 나오기 때문에 auto-regressive 하지 않음.
◦
추가로 positional encoding을 좀 다르게 줌.

•
transformer 결과가 순서 없이 나오기 때문에, 그게 원본의 어느 것에 대한 결과인지 알 수가 없음.
◦
그래서 bipartite matching을 통해 모든 조합을 매칭한 후 loss가 가장 낮은 것을 사용 함.
◦
bipartite matching은 그룹간 매칭할 때 같은 그룹끼리는 매칭이 안 되는 것을 말함.


•
DETR 결과
◦
bounding box를 찾을 때 테두리를 보고 찾더라.

•
작은 object들이 많을 때는 잘 못 찾는 약점이 있음
