
(review 생략)
•
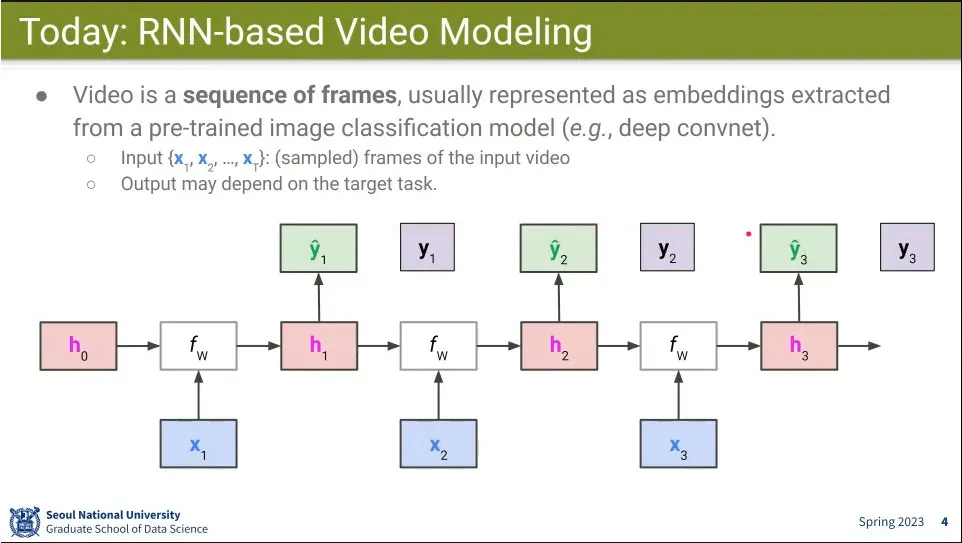
RNN을 이용해서 video를 처리하는 방법을 배워보자

•
LRCN 모델은 CNN을 통해 feature를 뽑고 그걸 RNN에 넣어서 돌리는 모델.
◦
CNN은 CaffeNet을 쓰고, RNN은 LSTM을 씀.
•
최종적으로 classifier를 달아서 label을 예측 함.

•
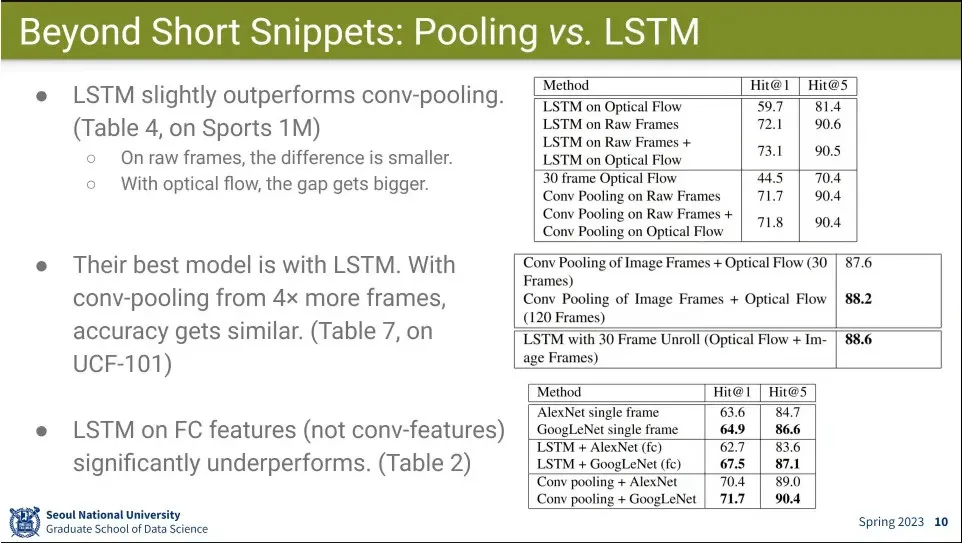
Beyond Short Snippets은 2014년 이전 모델들은 16 frame 정도만 가지고 했었기 때문에, 최대 5분까지 처리할 수 있는 video 처리를 함
◦
대신 1초에 1장씩 뽑아서 처리.
◦
추가로 optical flow feature도 사용함

•
Conv로 feature를 뽑아서, Conv pooling, Late pooling, Slow pooling, local pooling, Time-Domain Conv 등을 해 봄.
◦
결과적으로는 별 차이 없었지만 Conv Pooling을 제일 나았다.

•
multi layer로 LSTM도 써 봄. 이것 저것 방법을 시도 함.
•
pooling 보다는 LSTM이 조금 더 낫더라는 결론
•
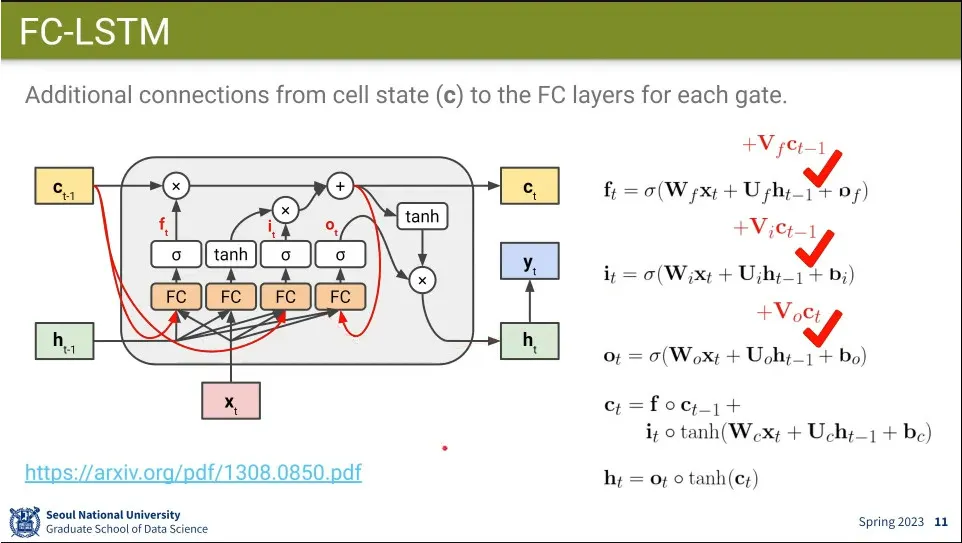
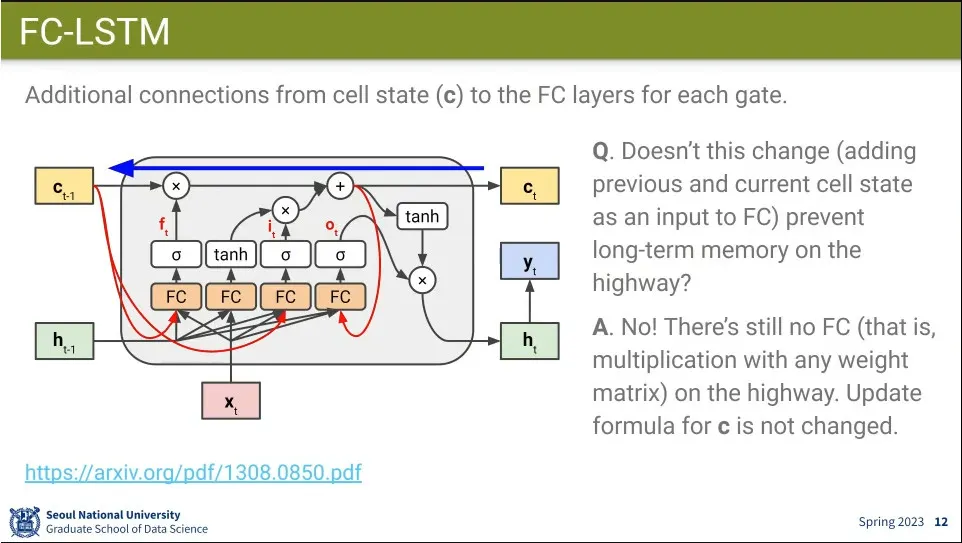
FC-LSTM은 cell state의 정보를 fc에 추가해 주는 것을 해 봄. long term memory도 활용하자는 것.
•
FC에 넣더라도 역전파할 때는 fc를 거치지 않기 때문에 long term 메모리를 유지할 수 있다.

•
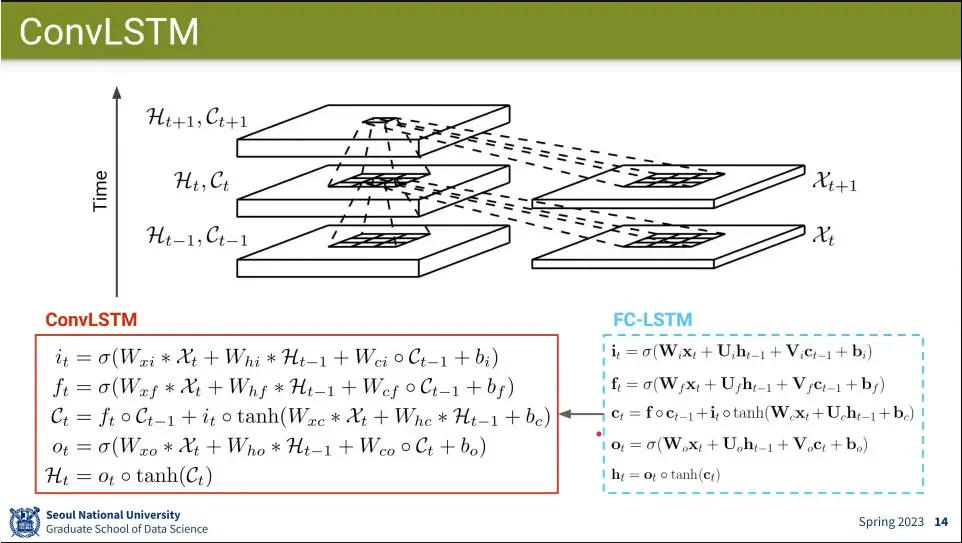
ConvLSTM은 input과 hidden을 vector가 아니라 matrix로 사용하고 weight에 대해 convolution 연산을 수행함
•
기존의 FC-LSTM의 식에서 convolution 연산을 사용함.
•
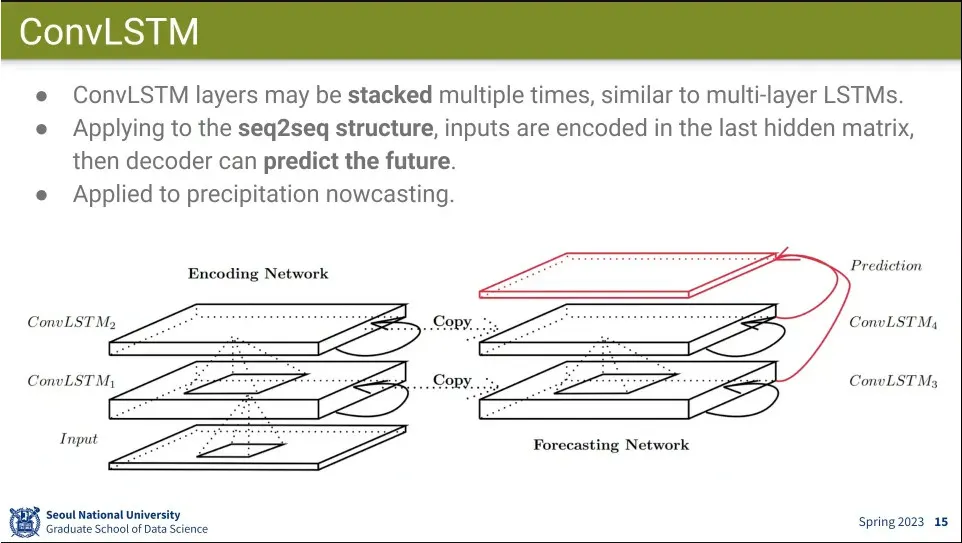
LSTM을 여러 층 쌓는 것처럼 ConvLSTM을 여러 층으로 쌓음.
◦
seq2seq 구조로도 적용 가능.
•
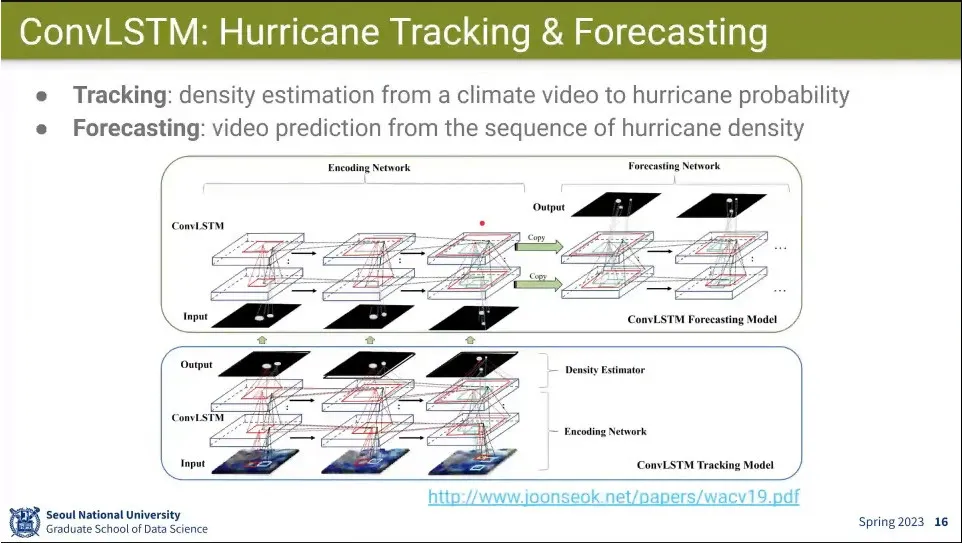
ConvLSTM을 이용해서 허리케인 추적과 날씨 예측을 한 예

•
ConvGRU는 LSTM 대신 GRU를 적용

•
Multilayer인 경우 같은 layer의 이전 state와, 하위 layer의 state를 받는데, ConvGRU에는 input도 추가해서 3개를 받도록 함.
•
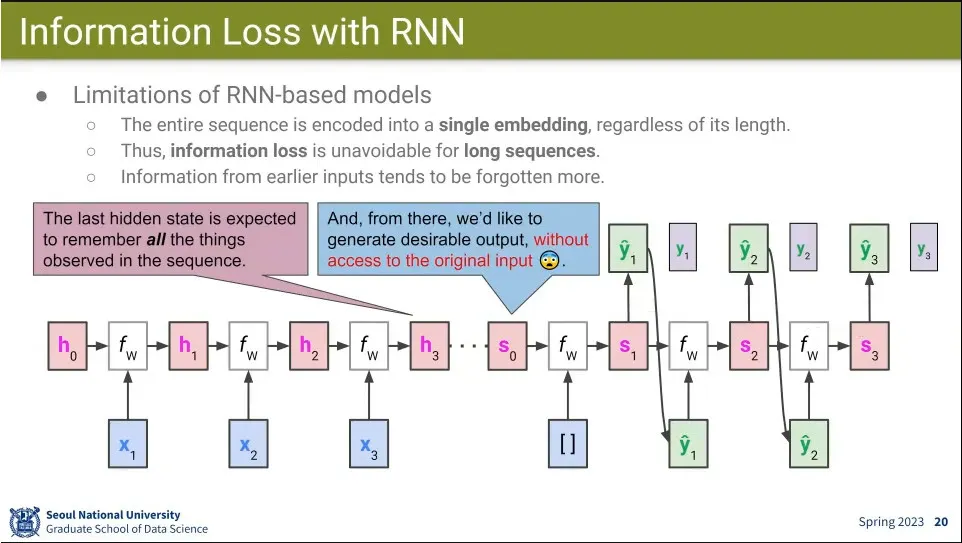
RNN은 마지막 state에서 모든 정보를 다 기억해야 하기 때문에 문제가 됨. 오래전 정보는 잊어버리게 됨.

•
그래서 아예 input의 모든 state를 아예 output에서 참조할 수 있게 하자는게 attention main idea

•
Attention 함수는 Query, Key, Value를 받아서 Attention Value를 출력하는 함수.
◦
query는 현재 주어진 context이고, key-value는 참고할 것.
◦
attention 함수의 출력은 value들의 weighted average가 나옴. 이때 query와 key가 관계가 있으면 score가 높게 나옴.
◦
query와 key는 계산 가능해야 하고, value와 attention value는 같은 dimension이어야 함. 대부분은 그냥 다 같은 크기를 사용 함.
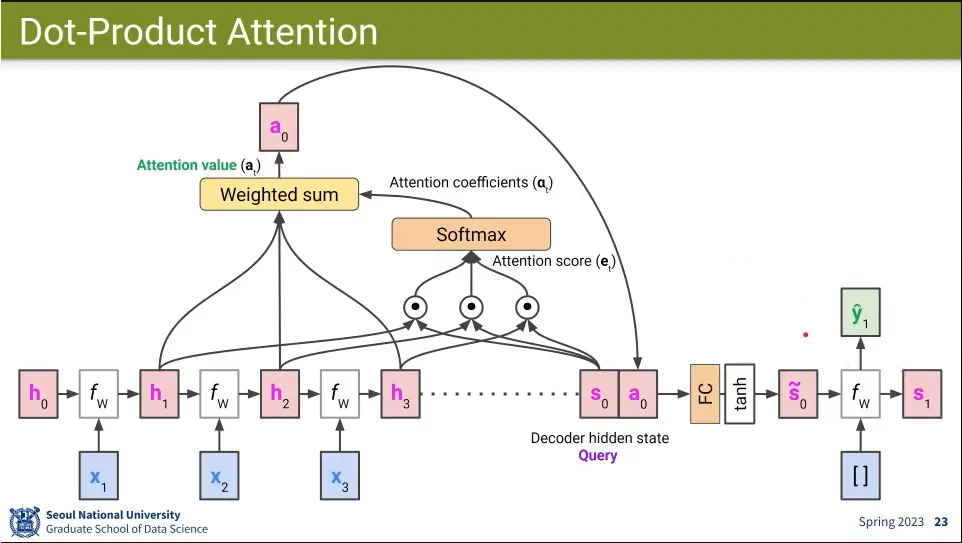

•
Attention score 계산 흐름
1.
decoder의 hidden state를 Query로 삼고 encoder의 모든 hidden state를 Key로 삼아서 그 둘을 dot-produt를 함
2.
그 결과에 대해 softmax를 씌우면 0-1사이의 확률 분포가 되는데 이게 Attention coefficient
3.
그 다음 다시 encoder의 모든 hidden state를 value로 삼아서 방금 구한 attention coefficient와 weighted sum을 해서 attention value를 구함.
4.
그 결과를 최초 decoder의 hidden state에 concatenate 한 후 원래 사이즈로 되돌리기 위해 fully-connected와 tanh를 통과 시킴.
5.
그렇게 업데이트된 hidden state로 decoder의 다음 단계를 진행하고 그 다음 state에서 1번으로 돌아감.

•
attention 개념 요약

•
Q, K에 대해 dot product가 아닌 다른 것도 사용 가능하지만, dot product가 가장 심플하고 성능이 좋아서 그냥 대부분 dot product를 사용 함.
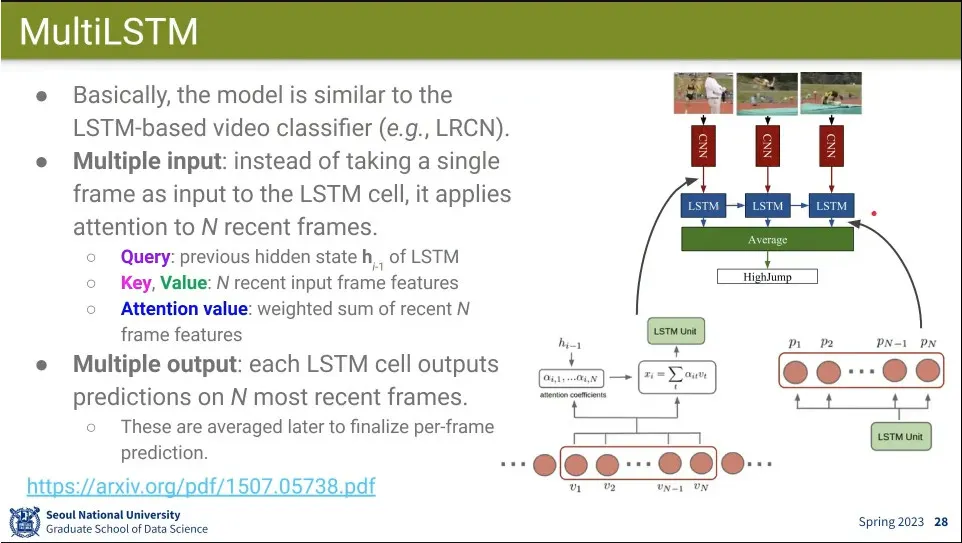
•
LRNC에 대해 Attention을 적용한 것이 MultiLSTM
◦
LSTM에서 hidden state를 업데이트 할 때 기존 frame들을 보고 attention해서 업데이트 함.
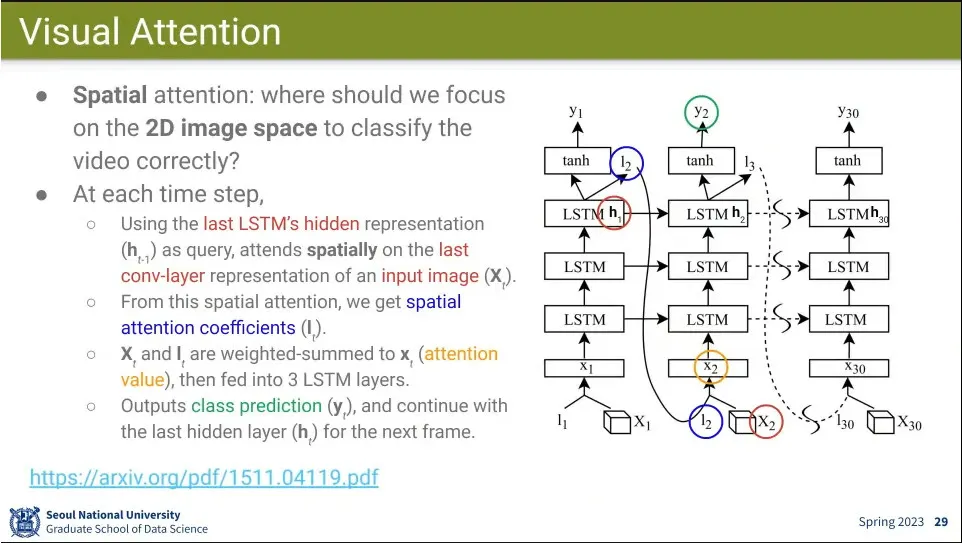
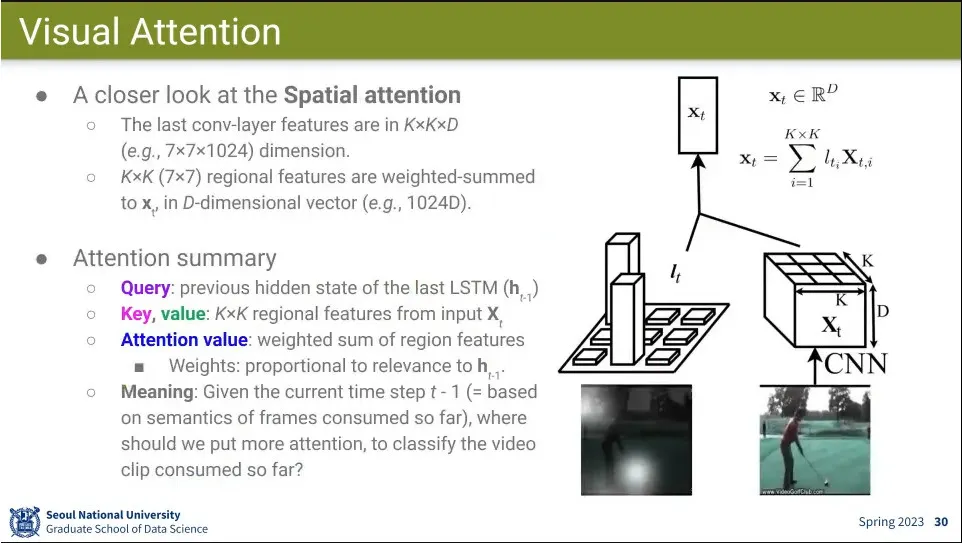
•
Spatial attention을 이용한 것이 Visual Attention
◦
MultLSTM이 어느 시간을 볼 것이냐인 반면, 이번에는 어느 공간에 attention 할 것이냐를 봄.



•
Spatial attention을 하면 해석 가능성이 높다.
◦
이 이미지를 판단하는데, 어느 부위에 주의를 주고 있는지를 시각화 할 수 있음.
◦
심지어 실패한 경우에도 어디를 보고 실패했는지를 확인할 수 있음
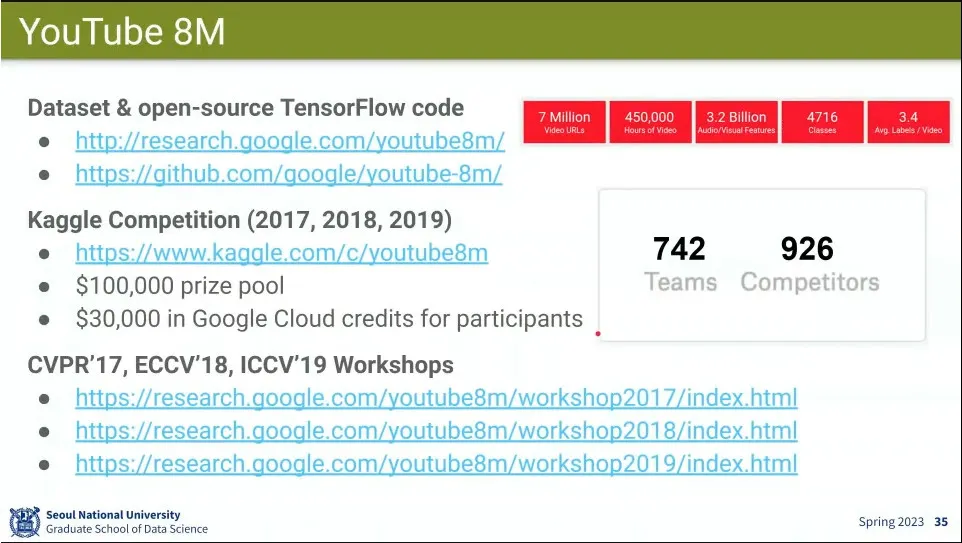
•
YouTube 8M 프로젝트 사례 소개
◦
(이하 생략)
