
•
RNN에 대해서 이전에 들었던 것에 더 상세한 부분이 있음. 아래 페이지 참조
•
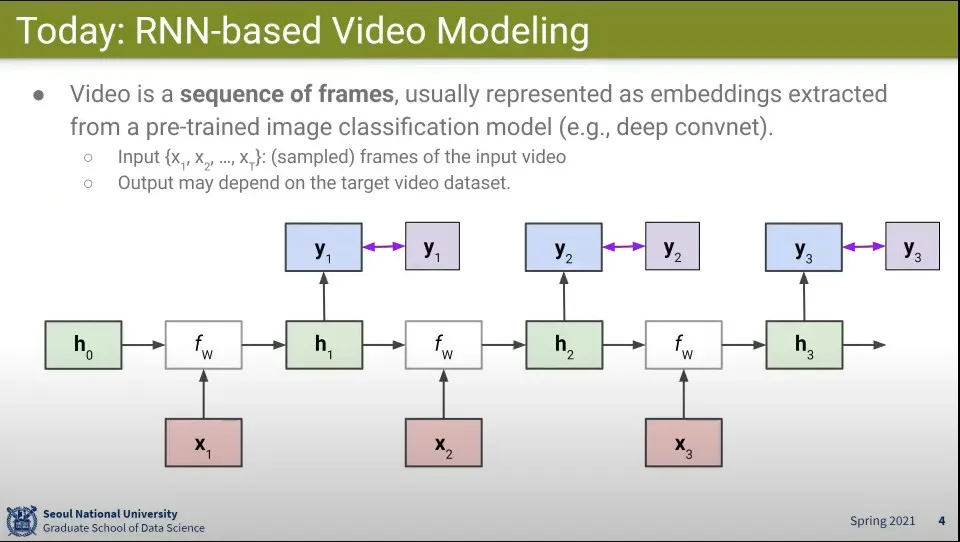
RNN을 Video 분류 문제에 사용하는 방법
◦
Video는 Sequence가 있으므로 RNN이 적합한 것으로 보인다.

•
LRCN은 LSTM과 CNN을 결합한 모델
◦
Sequence가 넘어가면서 CNN의 결과를 LSTM이 업데이트를 반복함
◦
최종적으로 그 결과를 평균 냄
•
이 모델은 image/video captioning에서도 사용 됨

•
Beyond Short Snippets 모델. 이전까지 16프레임으로 동영상 처리를 했는데, 이 모델에서 300 프레임으로 처리 함
◦
초당 1장씩 뽑아서 5분짜리 영상을 처리 함

•
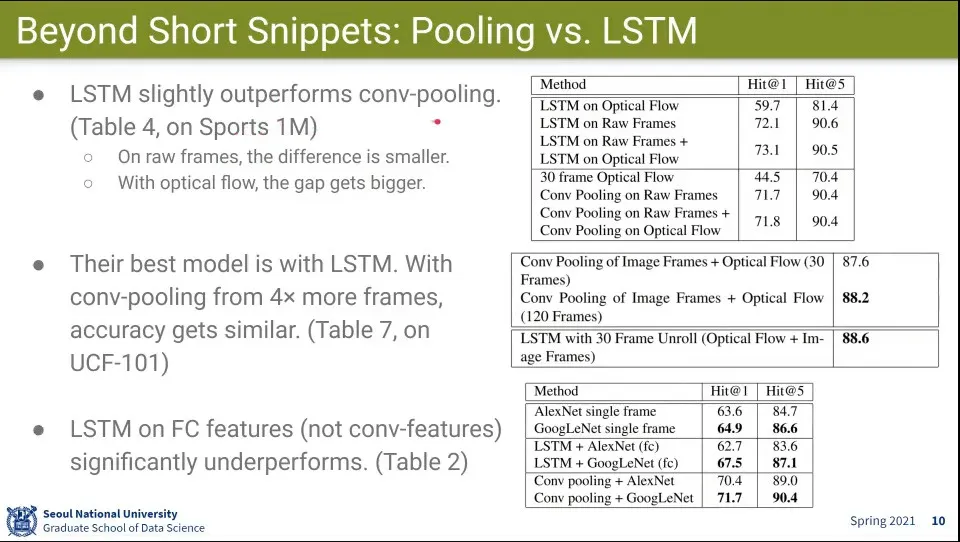
Beyond Short Snippets의 Pooling

•
Beyond Short Snippets의 LSTM
◦
LSTM을 Multi-layer로 시도 해 봄
•
이것저것 해봤는데 결과는 다 비슷비슷 했음
•
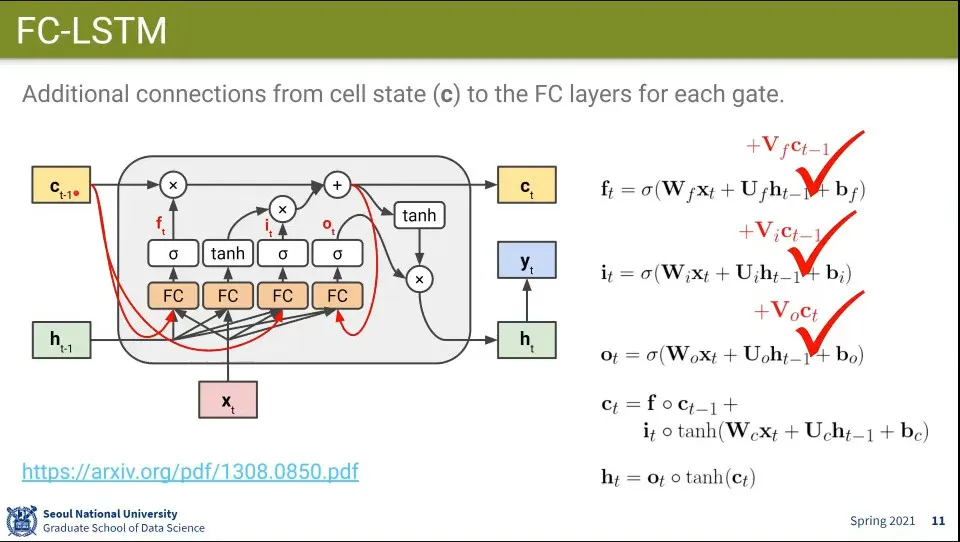
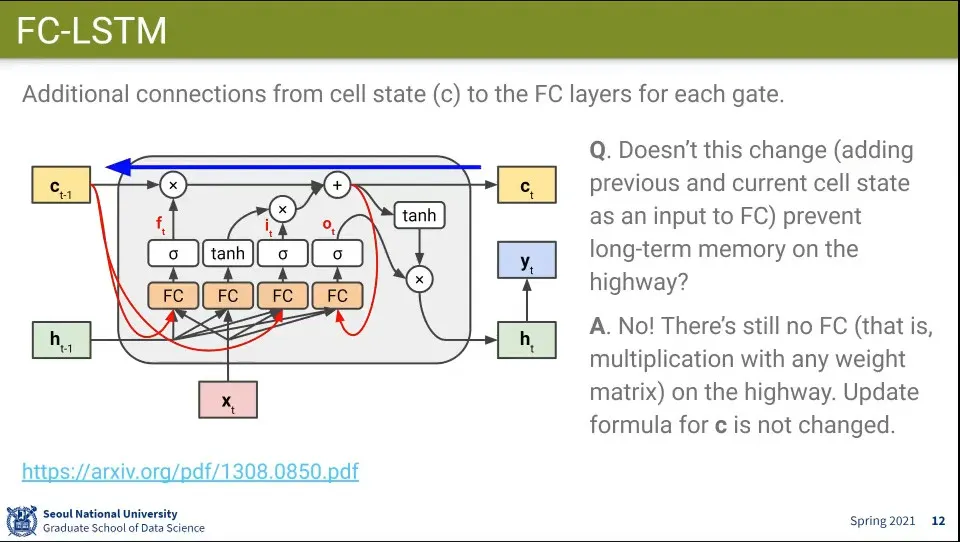
LSTM을 약한 변화를 줄 수 있음
◦
원래 구조에서 Cell State를 기존 값에 더해 줌
•
위와 같이 이전 Cell State를 더해줘도 Cell State가 소실되지는 않음. 기존 값에 더해주는 것일 뿐이고 Cell State는 결국 더하기 되어서 업데이트 되기 때문

•
FC-LSTM을 이용한 ConvLSTM 모델
◦
LSTM과 달리 Fully-Connected를 하지 않고 Convolution만 함
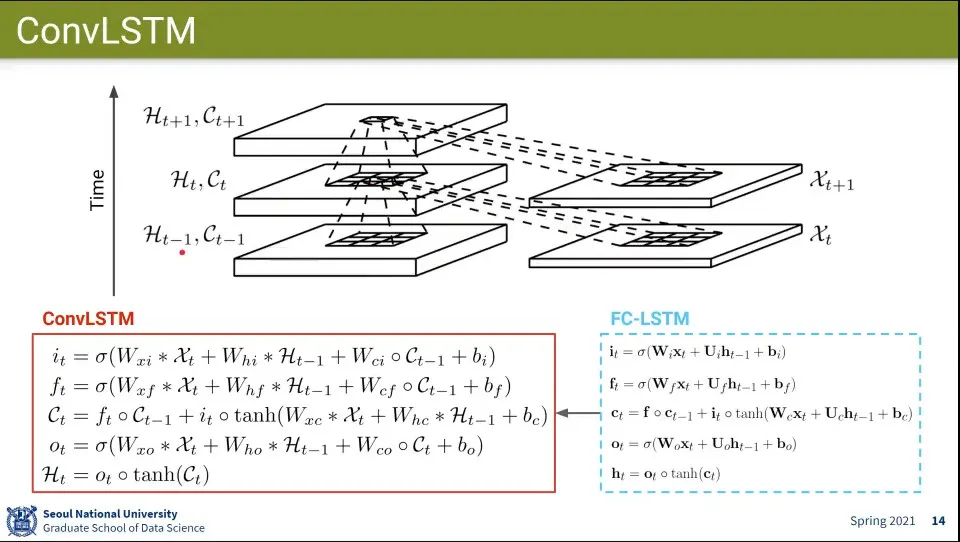
•
ConvLSTM 흐름 이미지와 계산식
◦
LSTM을 썼기 때문에 끝까지 가도 공간적인 정보가 남아 있게 함
•
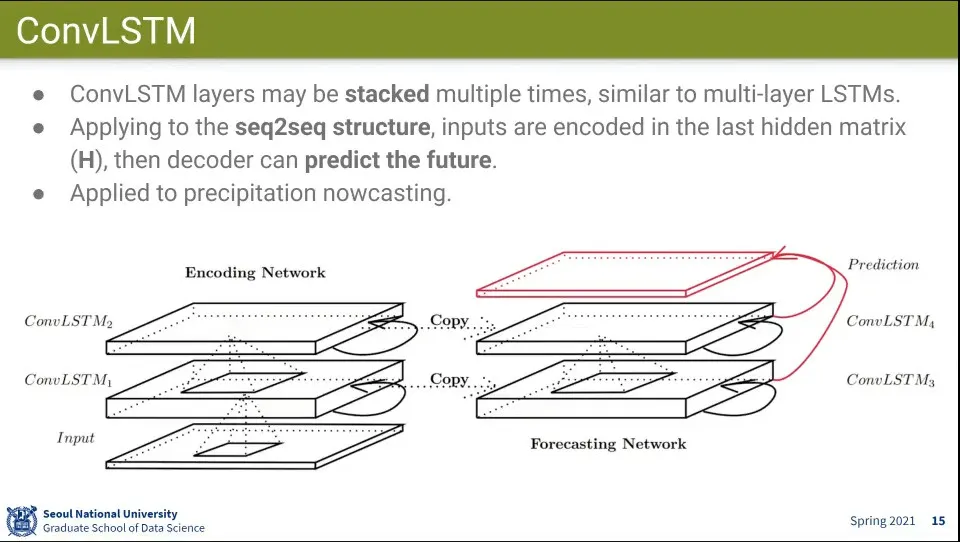
공간적인 정보를 활용해서 다음 예측을 생성할 때도 사용할 수 있음
•
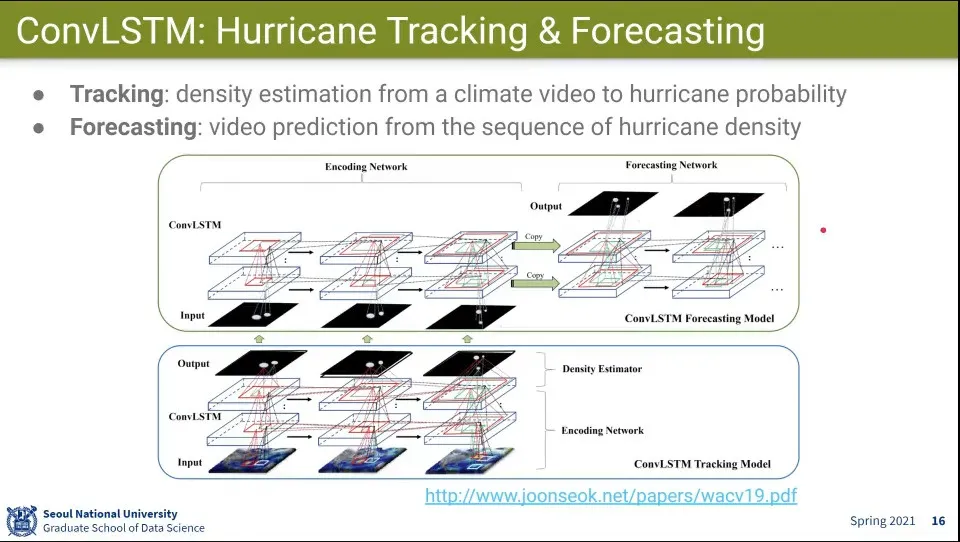
다음 예측에 사용한 예
◦
ConvLSTM으로 학습하고, 그 위에 다시 ConvLSTM을 쌓아서 예측 모델을 만듦

•
ConvLSTM처럼 GRU를 적용한 ConvGRU가 나옴
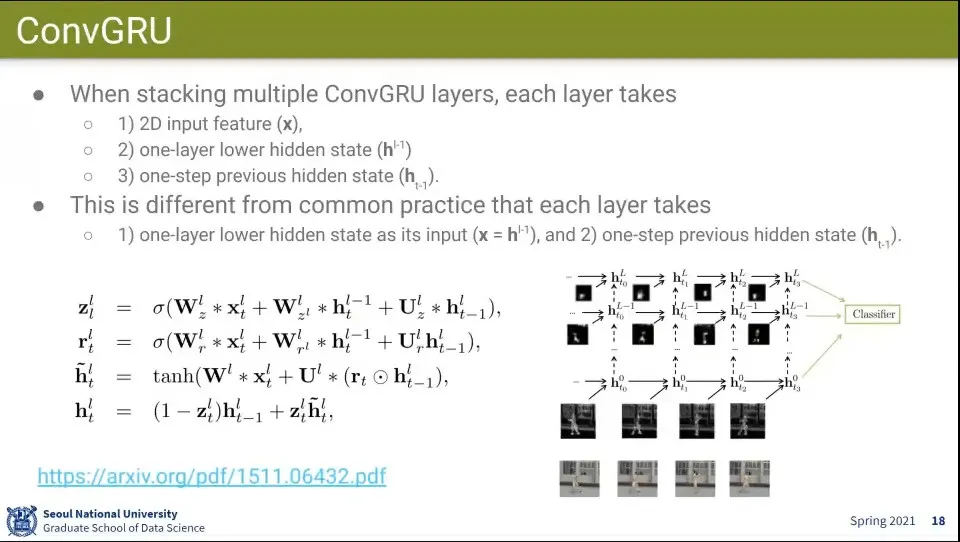
•
이전 Layer와 이전 State, 현재 input 3개를 받아서 처리 함
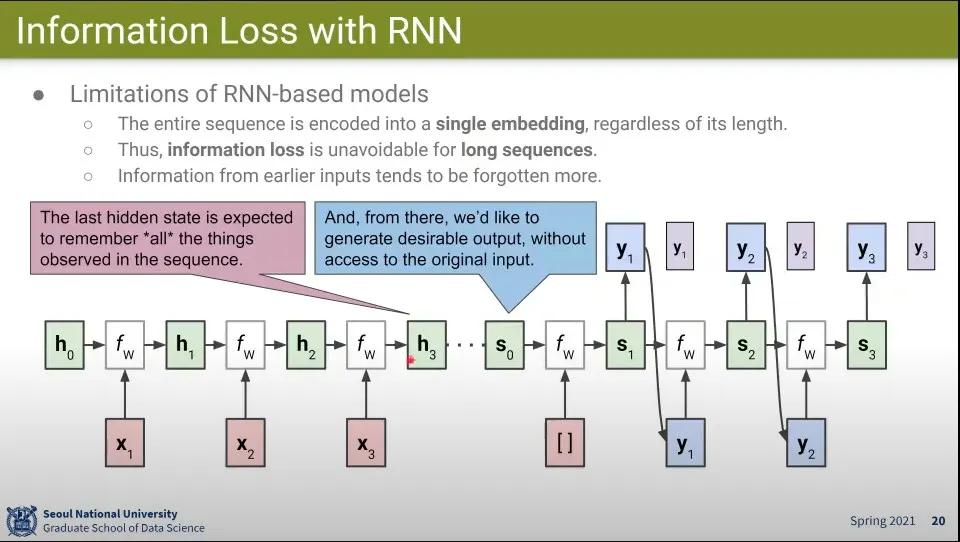
•
Encoder와 Decoder로 구성된 RNN 예
◦
Sequence가 길면 한참 앞의 State를 잊을 수 있음
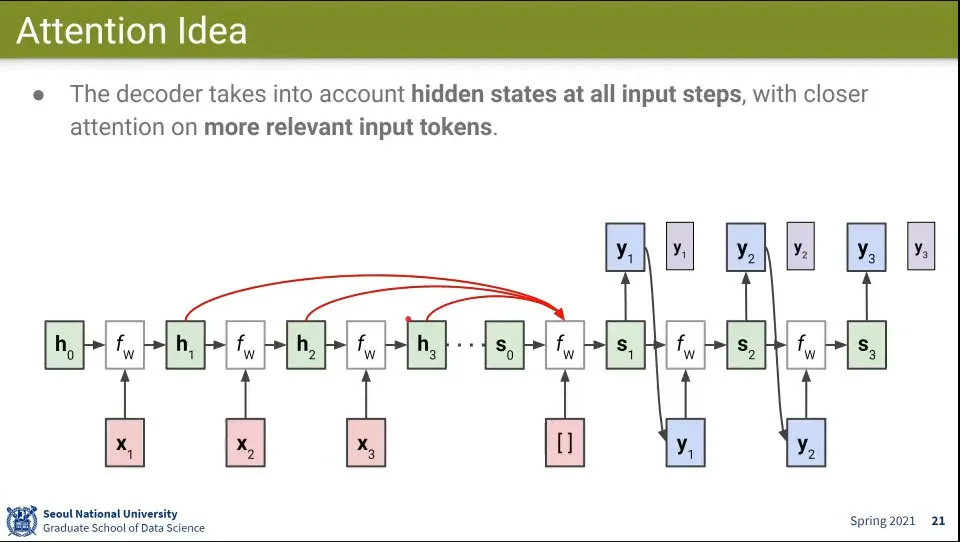
•
이전 State를 모두 참조 하고 그 중에 어디에 집중해야할지 결정하도록 함
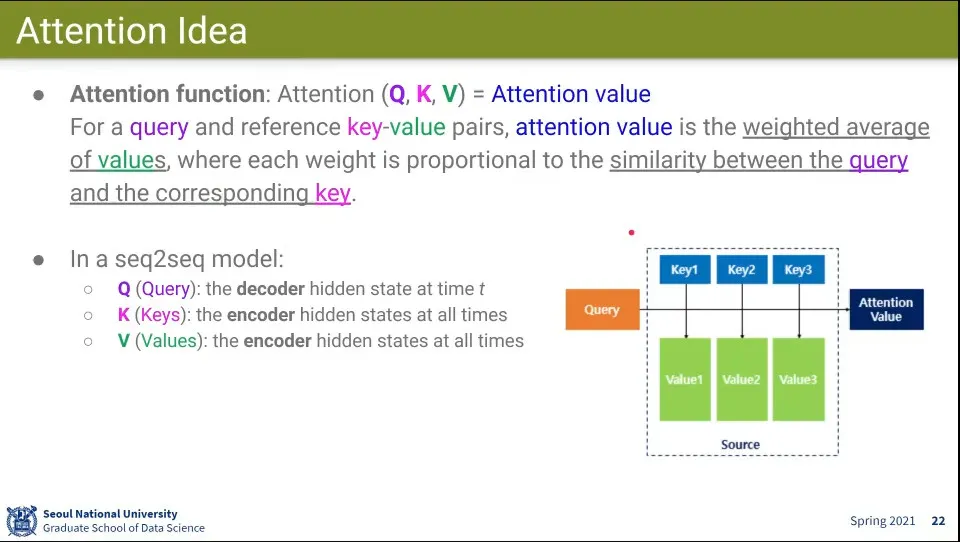
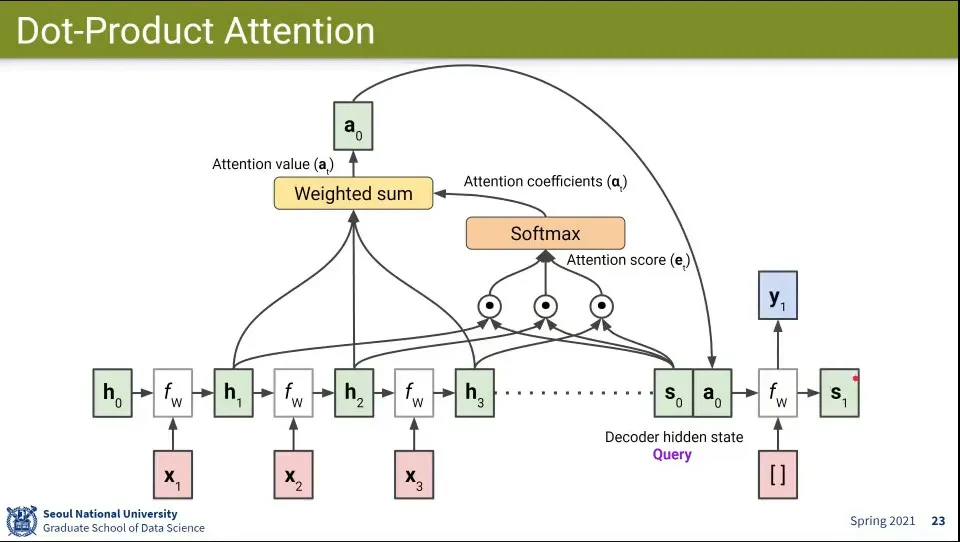
•
Attention function은 Query, Key, Value로 구성 됨
◦
모델 별로 정의되는 Query, Key, Value가 달라짐
•
Value들의 대표자가 Key가 되고, Key를 Query랑 계산해서 Value가 Query가 얼마나 비슷한지(Similar) 계산함
◦
그런데 대부분 Key와 Value는 같은 것을 쓰는 경우가 많음
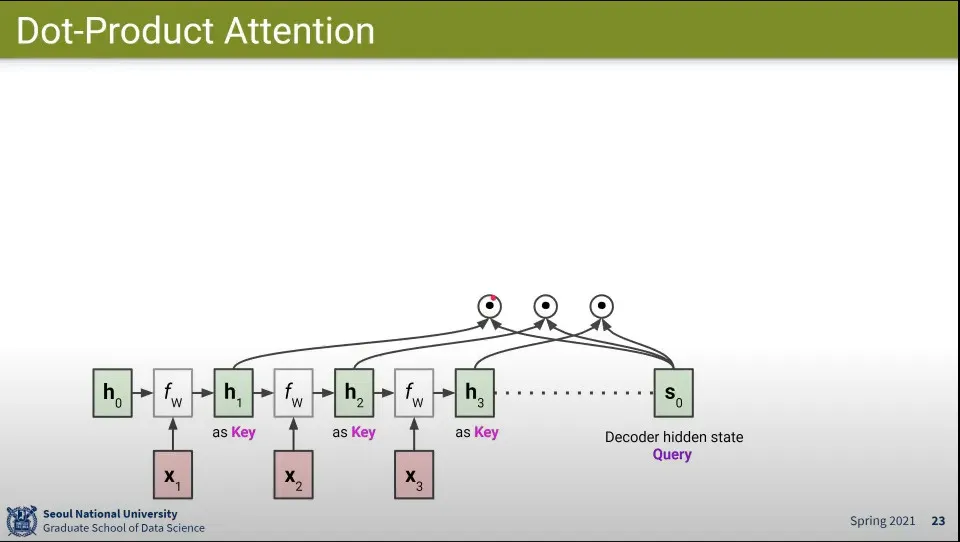
•
Attention 계산 흐름
1.
decoder의 현재 state를 query로 사용하고 encoder의 state를 key로 써서 query와 유사도를 계산함
2.
그 결과들을 합해서 attention score를 만듦
3.
그 후에 attention score에 softmax를 씌워서 attention coefficients를 만듦
4.
그 후 attention coefficients들을 weighted sum해서 attention value를 만듦
5.
그렇게 만들어진 attention value를 decoder의 state()에 concatenate 함
6.
그렇게 만들어진 state로 input을 처리해서 output을 만들고 새로운 state를 만듦
7.
새로운 state에 대해 1-6 반복

•
앞선 예에서의 query, key, value, attention value

•
Attention에 사용할 수 있는 다른 방법들이 있는데 Dot-product가 간단하므로 대부분 Dot-product를 한다.
•
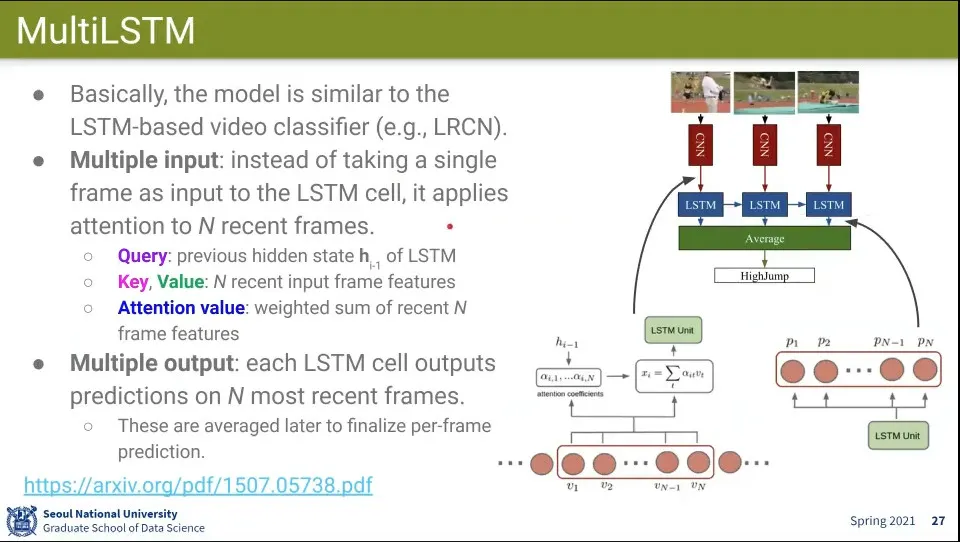
MultiLSTM은 Input과 Output이 Multiple
•
Input에서는 LSTM에 넣을 때 이전 단계 frame들을 넣어서 Attention 메커니즘이 동작하도록 함
◦
Query는 현재 이전 hidden state
◦
Key, Value는 N개의 최근 Frame Features
◦
Attention Value는 최근 N개의 Frame Features의 Weighted Sum
•
Output에서는 Attention과는 관계 없음
◦
LSTM이 output을 낼 때 N개의 가장 최근의 output을 냄
•
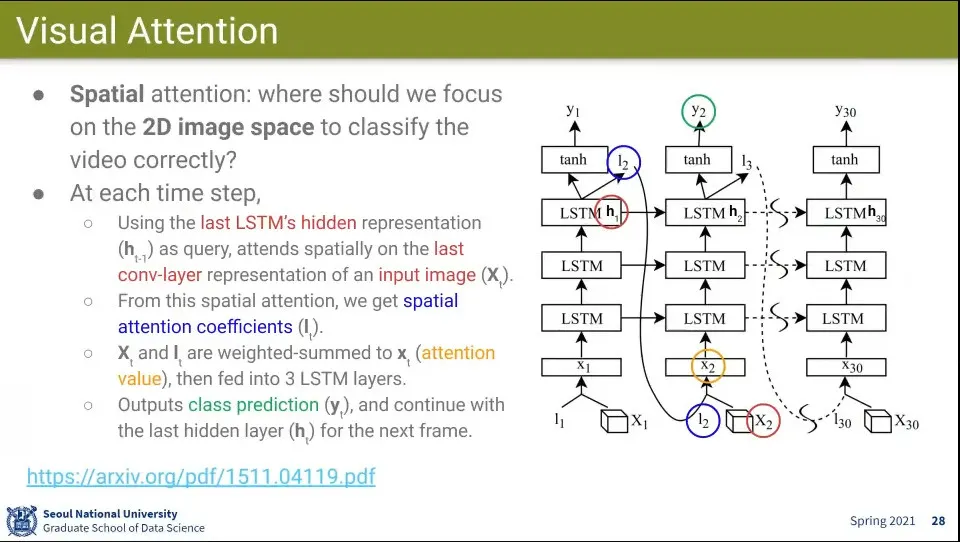
Visual Attention은 Attention을 공간적으로 사용한 예
◦
MultiLSTM에서 Attention은 이전 몇 개의 Frame에 Attention을 적용한 반면, 여기서는 Convolution에서 들어오는 Feature들에 대해 Attention을 적용함.
◦
그 feature에 대해 유사도를 구하고 weighted sum을 수행 함
◦
Query는 앞서와 마찬가지로 이전 hidden state
•
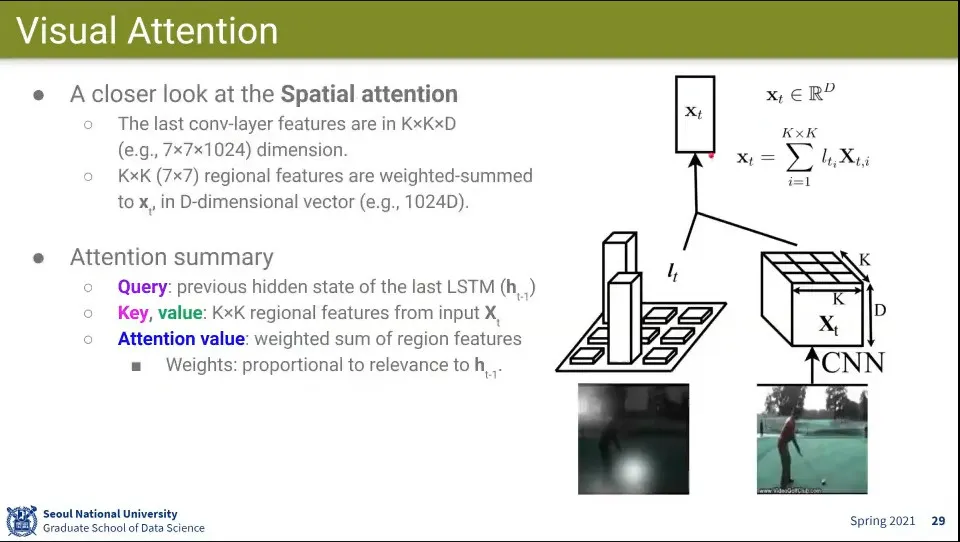
공간적으로 어느 위치에 Attention을 해야 현재 이미지를 이해할 수 있느냐에 하는 것
◦
위 예시 이미지에서 흰색으로 표현된 부분이 Attention 된 부분이고, 모델은 그것을 보고 저 활동이 골프인지를 알아 맞출 수 있다.


•
Video에서 Attention 된 부분을 표시

•
잘못된 Attention 예시
◦
잘못된 것도 어디를 보고 그렇게 판단했는지를 이해할 수 있음

•
YouTube Case Study
◦
Video 저작권이 업로더에게 있기 때문에 YouTube에서도 함부로 처리할 수 없음. YouTube 소유가 아님
•
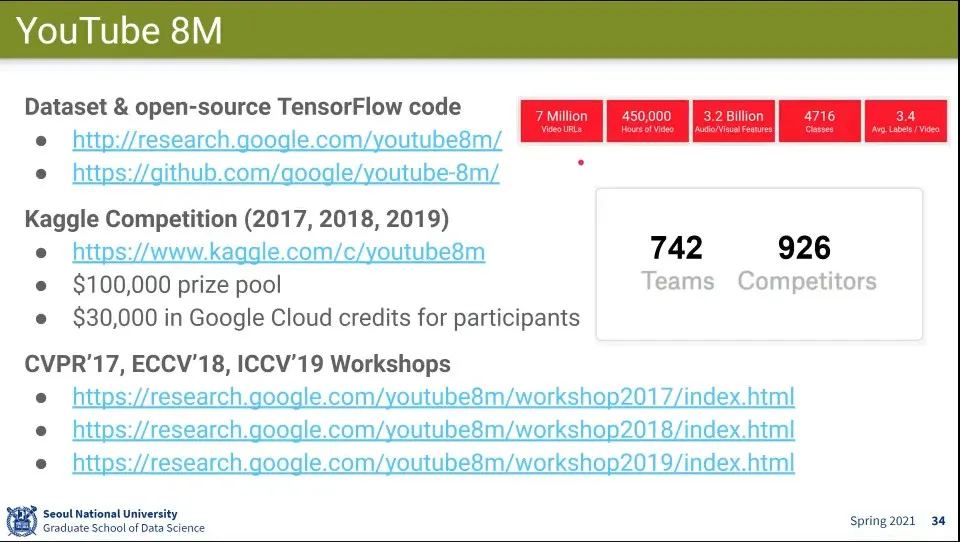
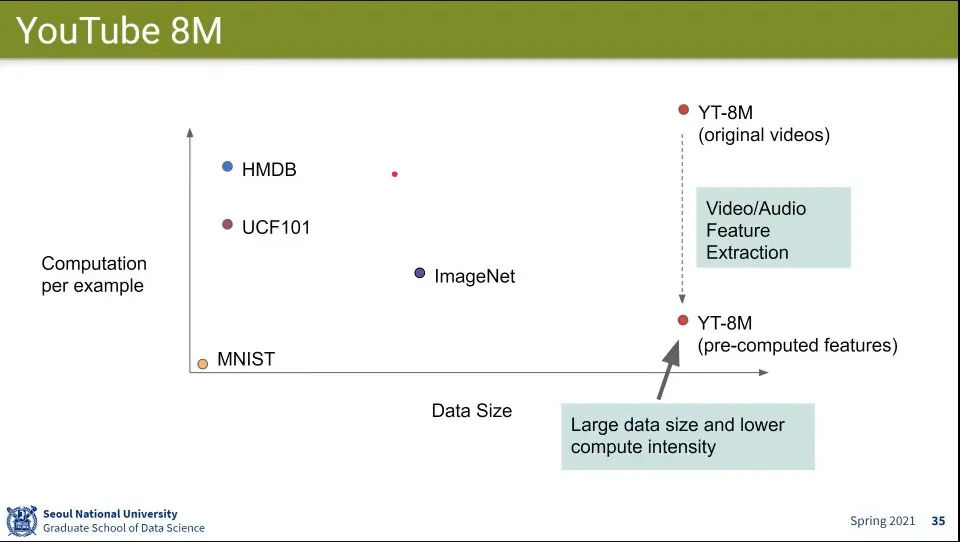
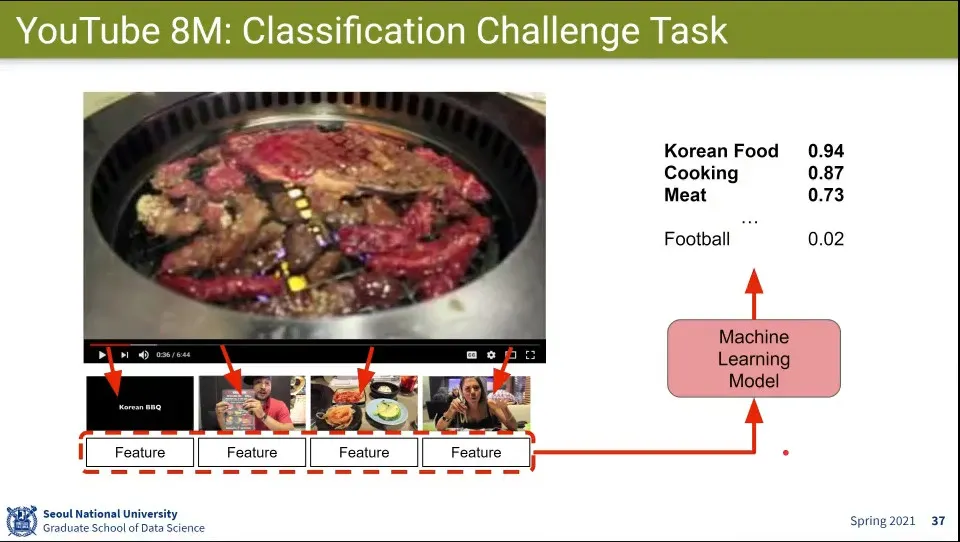
YouTube 데이터셋을 이용한 Challenge
•
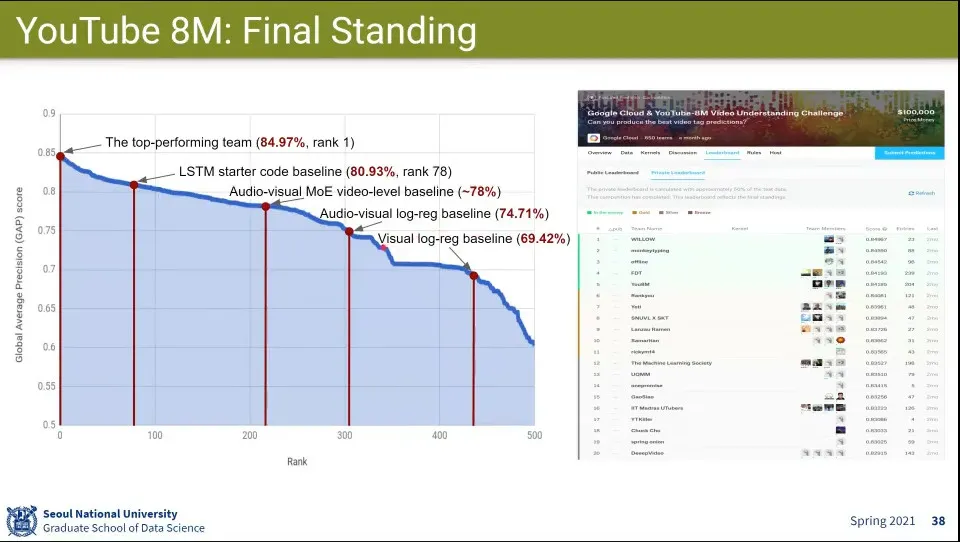
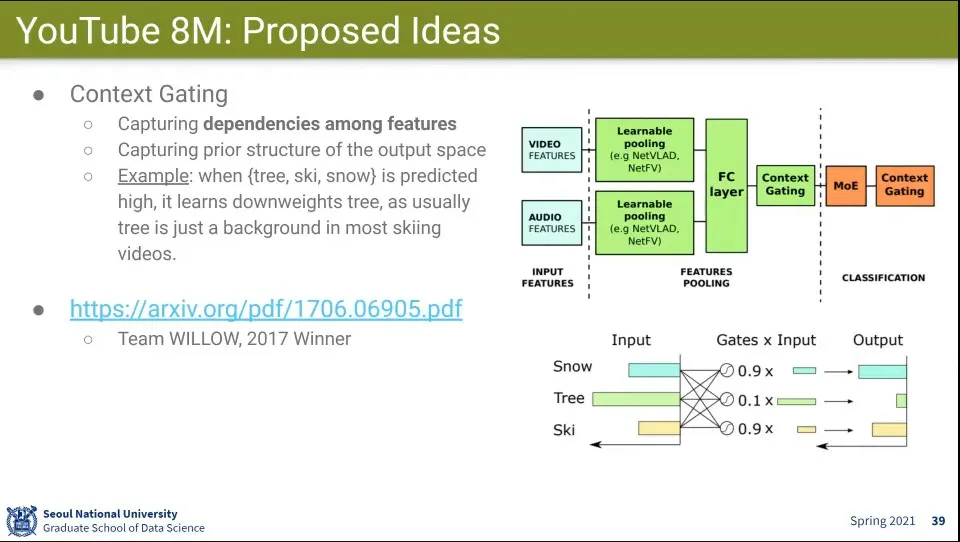
우승팀 사례
◦
다른 부분은 기존 방식과 비슷하지만 Context Gating이라는 방법이 특별함
◦
Label 간의 Dependency를 따져서 처리함.
▪
Tree는 크리스마스에는 중요하지만, 스키장에서는 중요하지 않다.
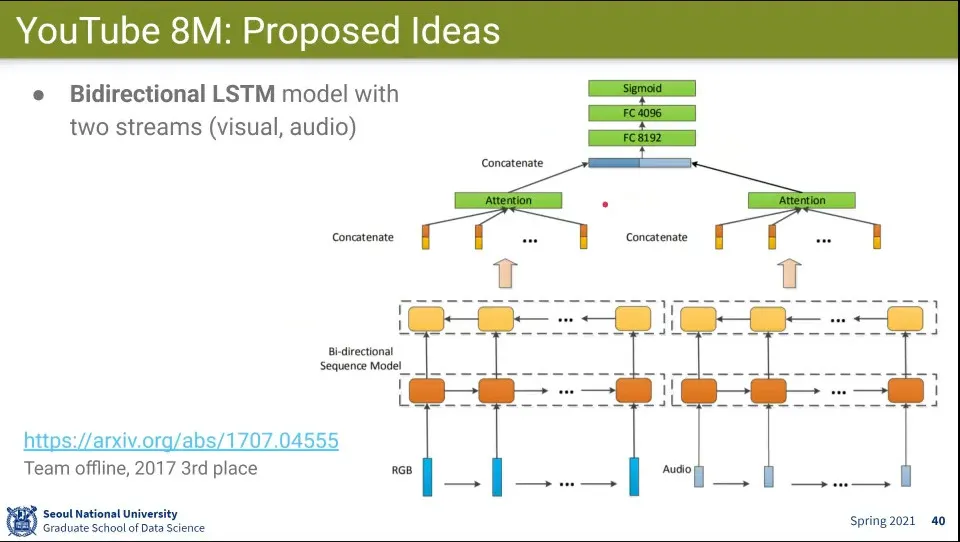
•
Visual과 Audio를 Bidirectional LSTM을 이용해서 처리함
◦
홀수층과 짝수층의 방향을 다르게 함
◦
맨 마지막 층에는 Attention을 걸어서 처리 함
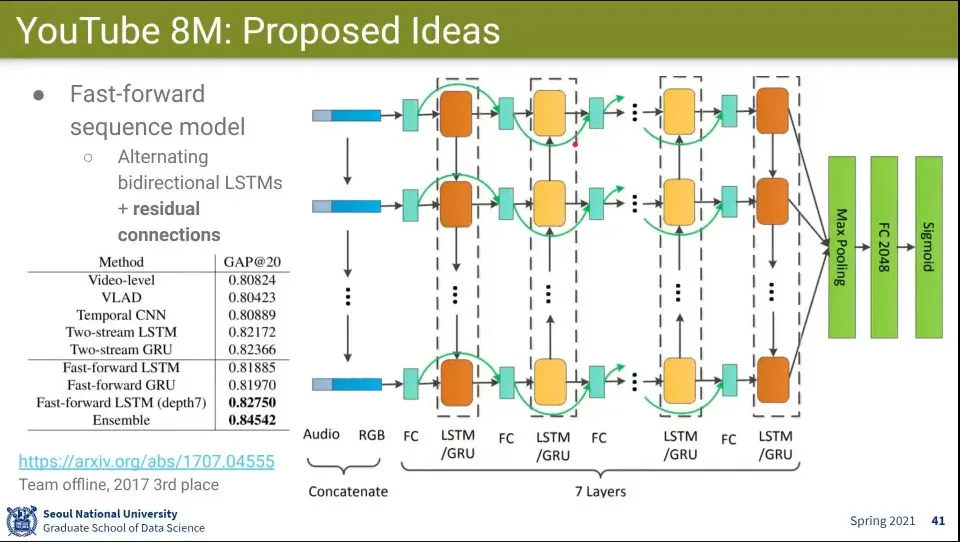
•
Alternating Bidirectional LSTM에 Residual Connection을 사용한 팀
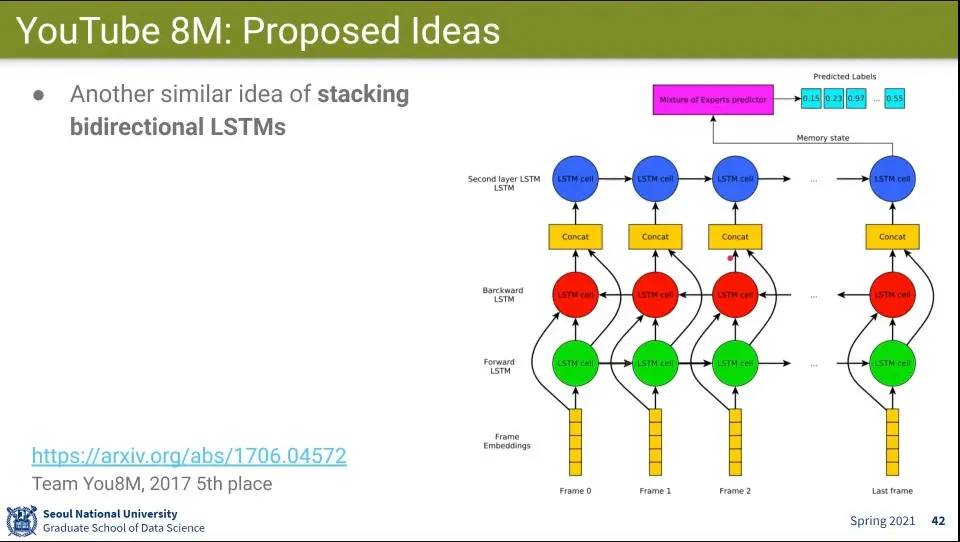
•
Bidirectional LSTM 적용

•
대회 내용
◦
처음 대회에서는 일단 왕창 기능 때려 박아서 성능을 좋게 함. 그런데 그런 heavy한 것은 실용적이지 않음
◦
그래서 다음 대회에서 모델 크기 제한을 걸었더니 사람들이 일단 모델을 크게 만들고 그걸 경량화하는 모델을 만듦
