
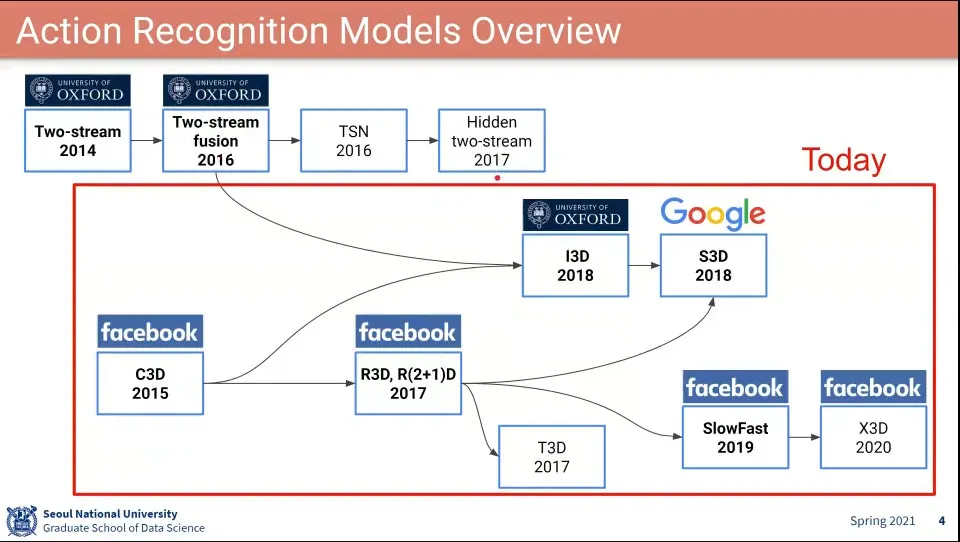
•
지난 번 이후의 모델들 확인

•
2D Convolution

•
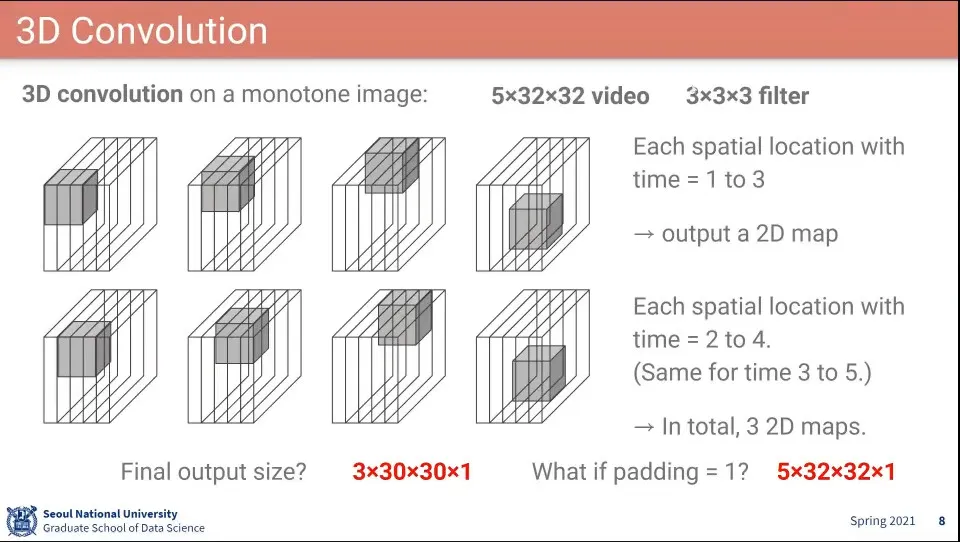
3D Convolution은 시간 길이가 추가 된다.
◦
Filter의 가장 앞에 들어간 것은 시간 정보. 3이면 3프레임까지 본다는 것
•
sliding 할때 공간적으로만 하지 않고 시간축으로도 sliding 해줘야 함
◦
padding도 시간축으로 늘어남

•
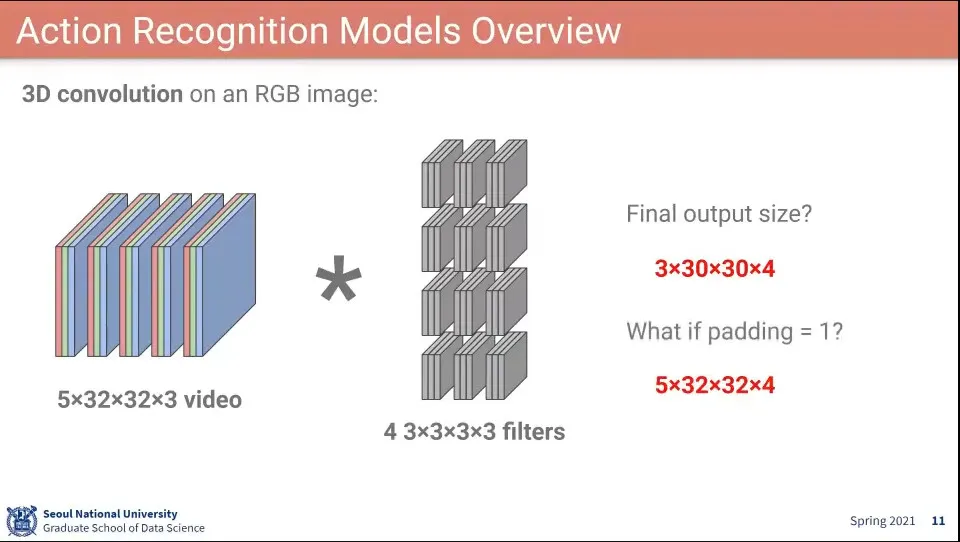
2D Conv에서 filter가 3개 있는 경우
◦
가로x세로x채널

•
시간 차원이 늘어나서 filter도 4개로 늘어남
◦
시간x가로x세로x채널
•
거기에 필터 자체의 개수도 있으므로 고려하여 계산하면 이렇게 됨.
◦
패딩은 시간, 공간을 따로 줄 수도 있다.
•
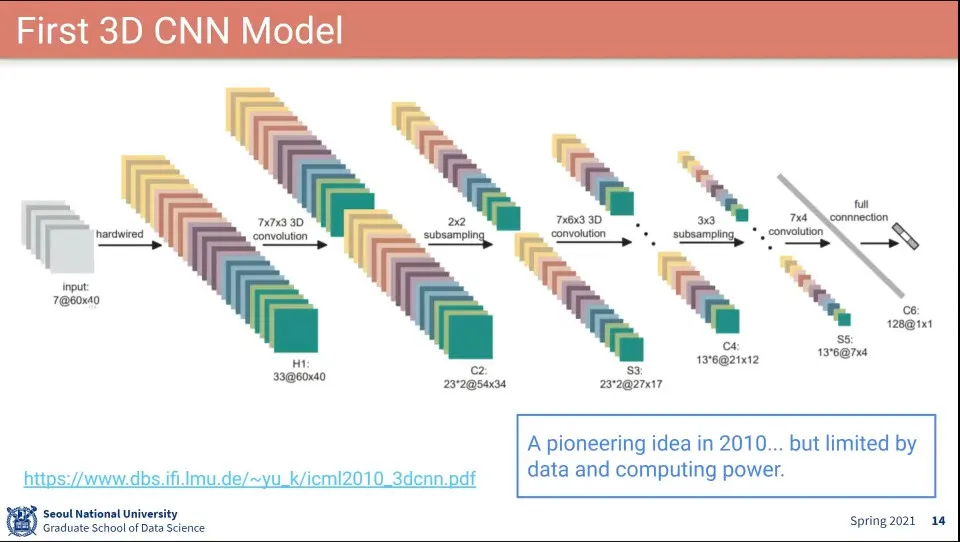
최초의 3D Conv Model
◦
당시에는 이걸 돌릴만한 컴퓨팅 파워가 없어서 널리 쓰이지 못함

•
3D Conv를 비디오에 적용한 모델
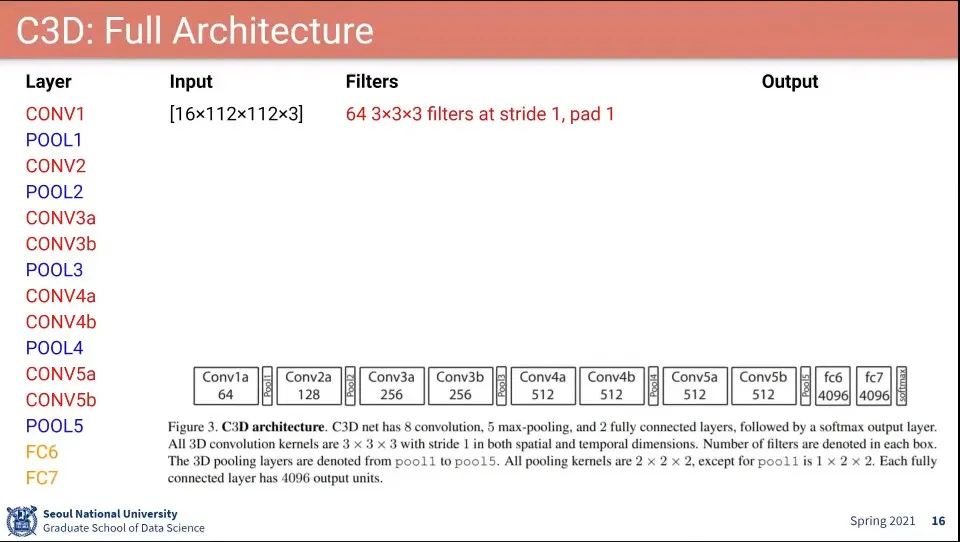
•
C3D의 아키텍처

•
Long range 문제가 있었고, 수작업 feature가 여전히 존재 했음

•
그 다음으로 나온게 ResNet을 3D로 확장한 것
◦
원래 ResNet은 152층을 쌓았지만 3D는 너무 커서 34층으로 줄임
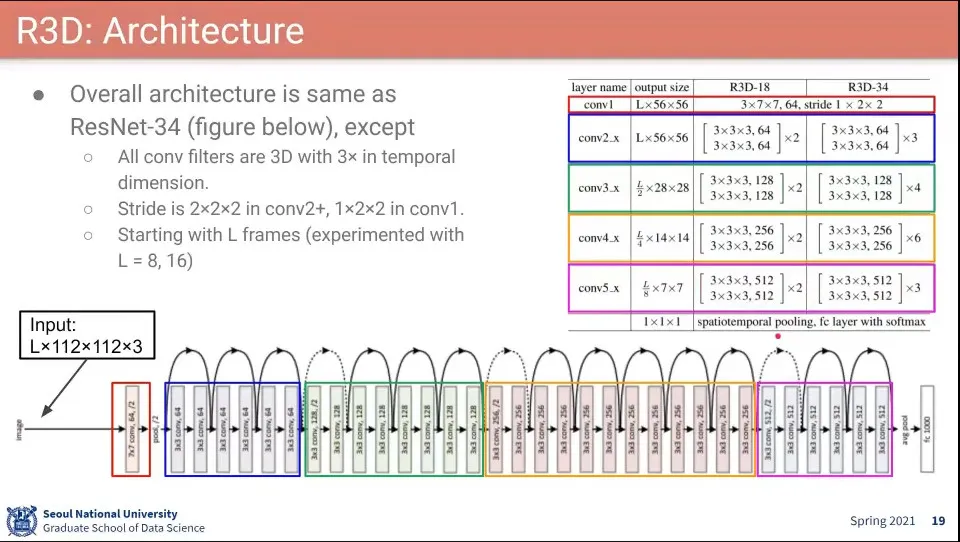
•
R3D의 아키텍처
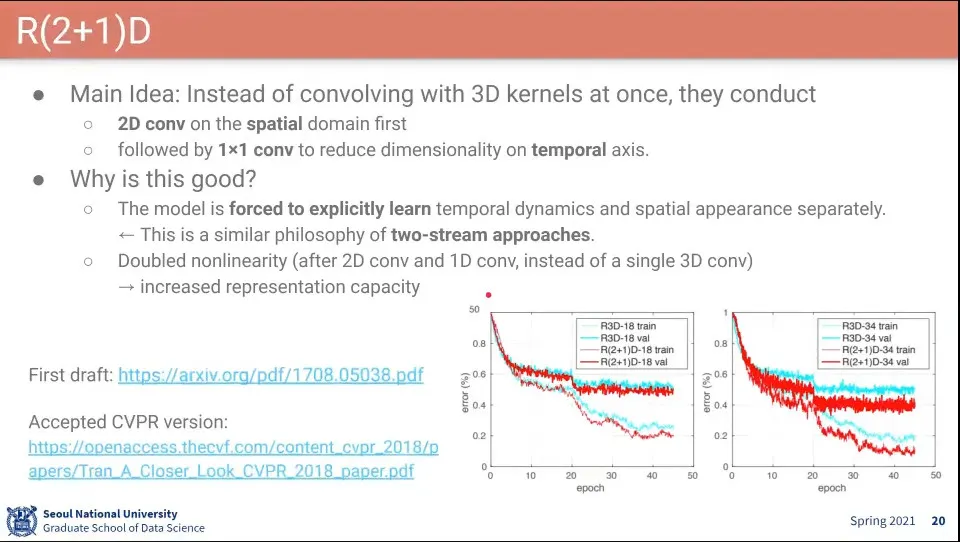
•
R2+1는 3D 커널로 한번에 하지 않고, 시간쪽 filter와 공간쪽 filter를 쪼개서 학습함
◦
그 점에서 Two-Stream과 비슷함
•
R2+1D이 R3D보다 성능이 좋다고 함
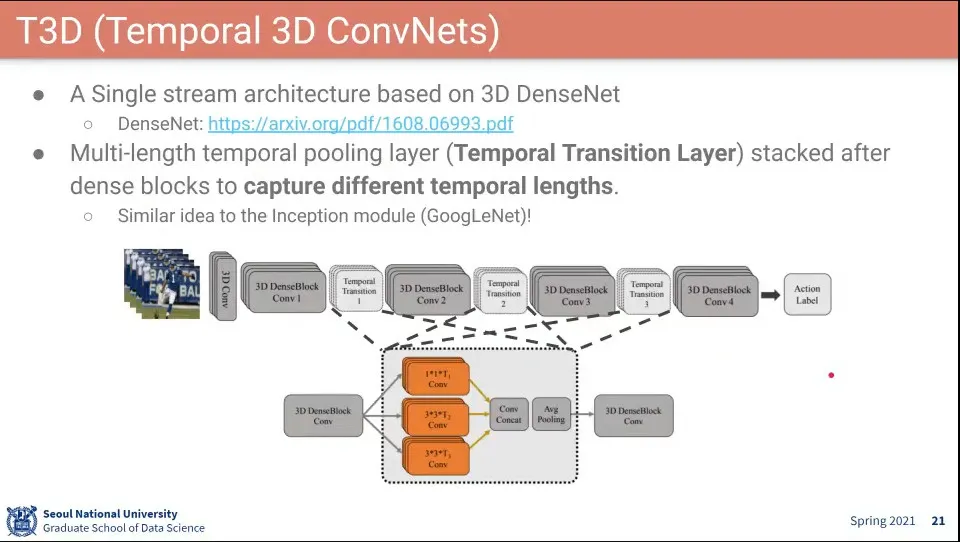
•
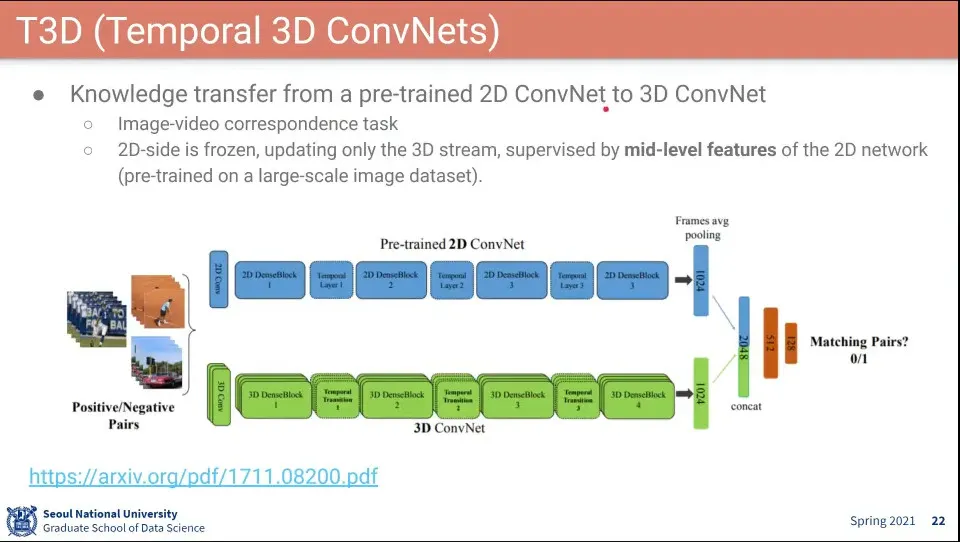
DenseNet을 이용해서 만든게 T3D
•
학습할 때 2D ConvNet을 이용함.
•
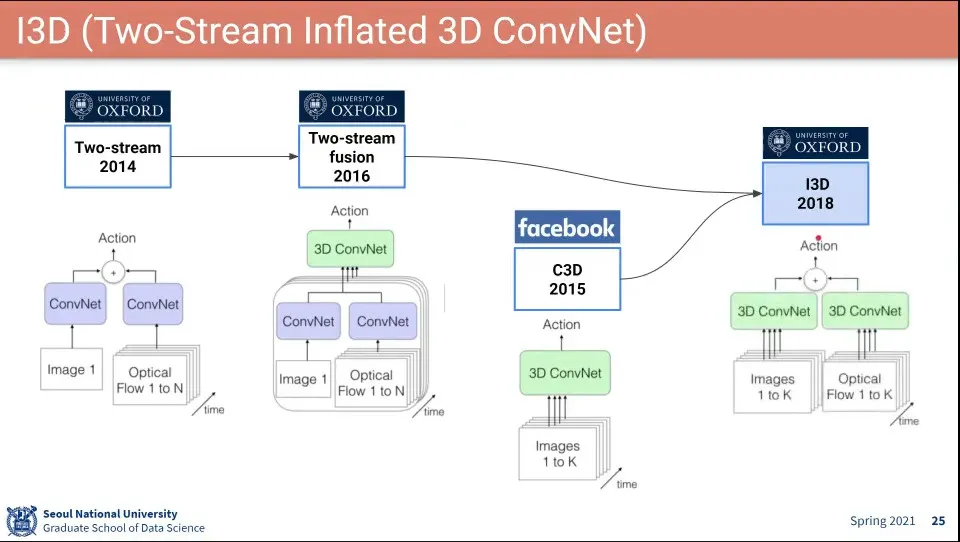
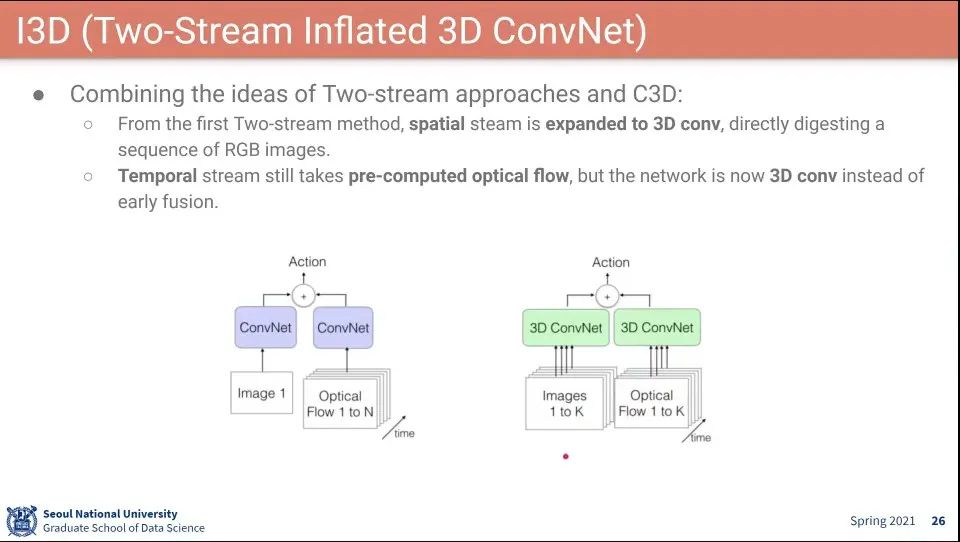
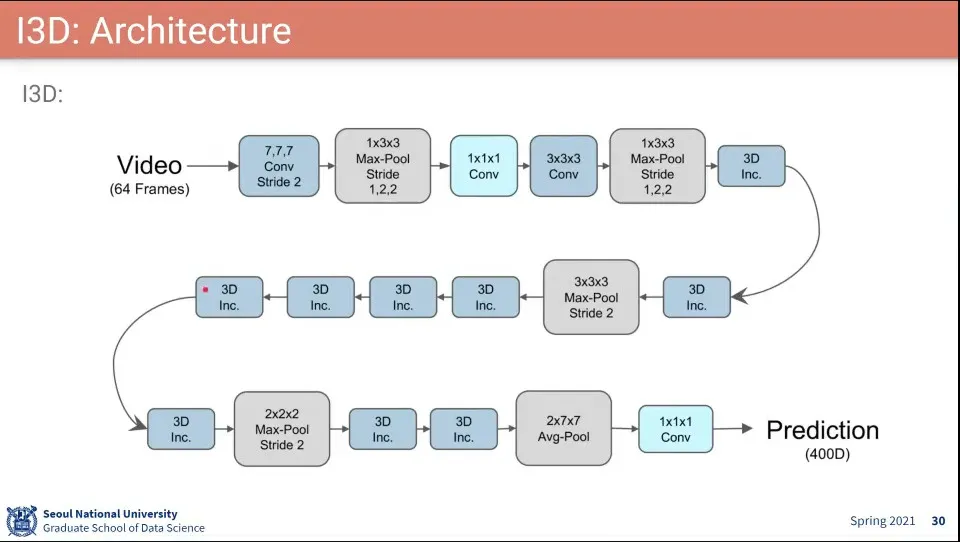
I3D는 Two-Stream과 3D Conv를 합하여 사용한 모델
◦
이 모델이 요즘 Default가 됨
•
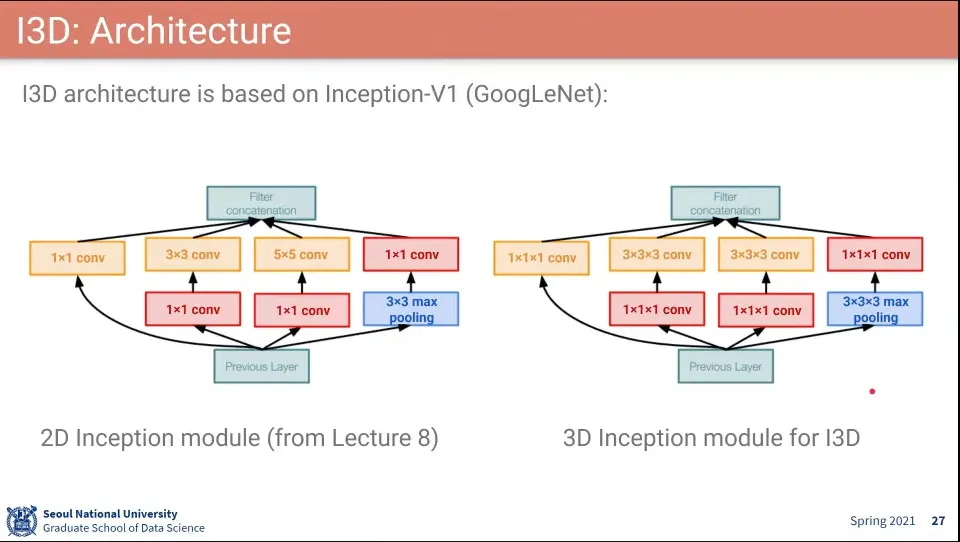
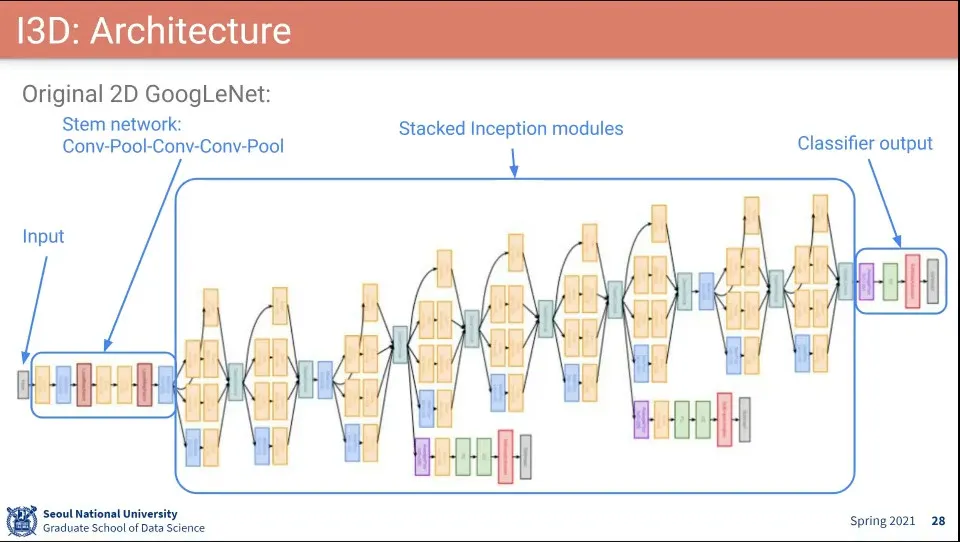
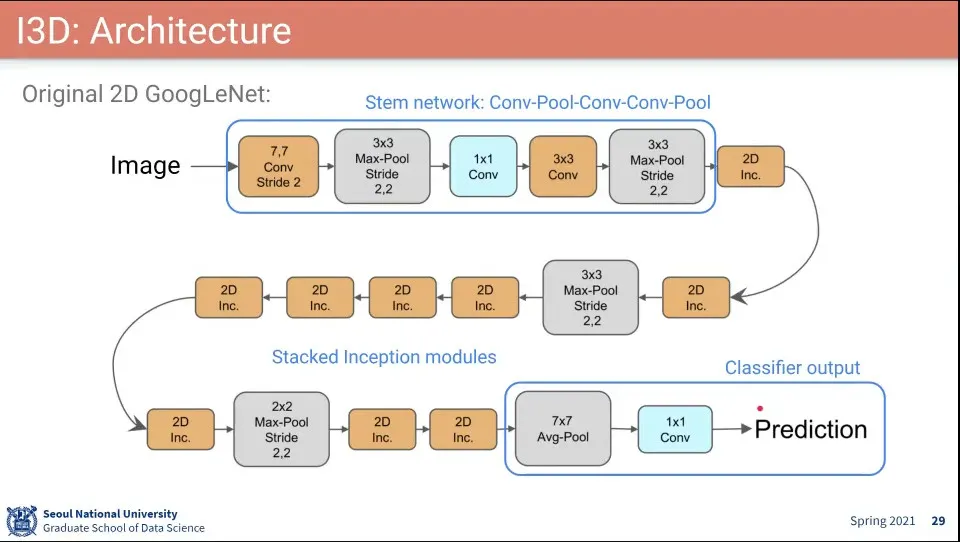
I3D의 구조는 Inception 모듈을 사용함
◦
I3D에서 3x3x3 이 2개가 나오는데 이거는 실수라고 생각 됨. 근데 실제 코드도 3x3x3으로 되어 있다고 함.
◦
Inception은 컨셉상 다른 크기를 한번에 보는건데 같은게 2개 들어 있다는게 실수로 보임
•
I3D의 구조

•
I3D에서도 Optical Flow를 쓰는게 일단 도움이 되었다고 함
◦
하지만 이 논문 후에는 Optical Flow는 안 나옴
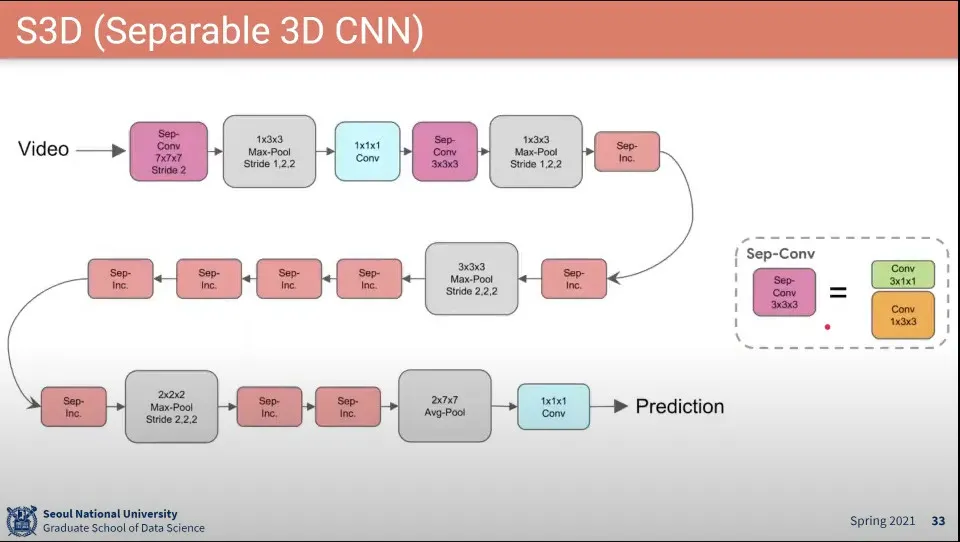
•
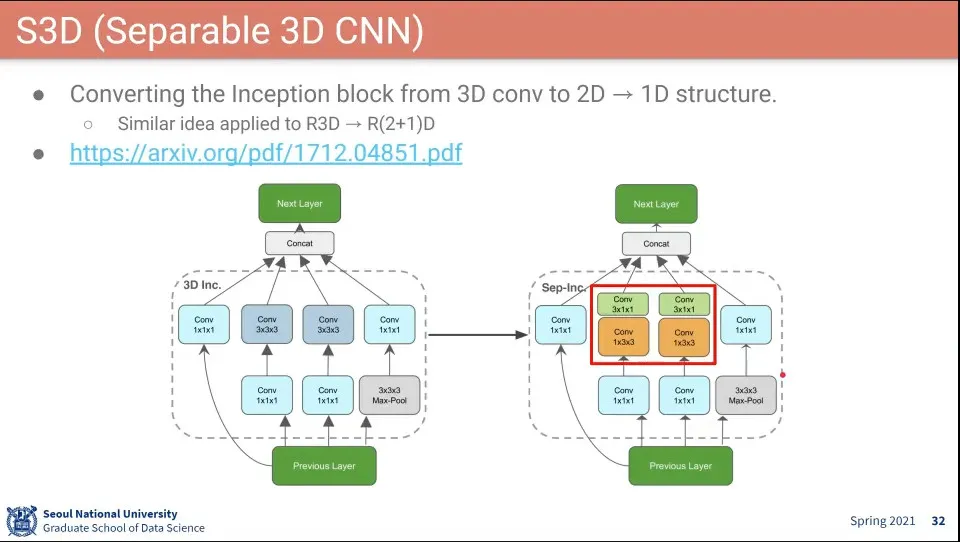
I3D와 같은데 시간, 공간을 쪼갠 것
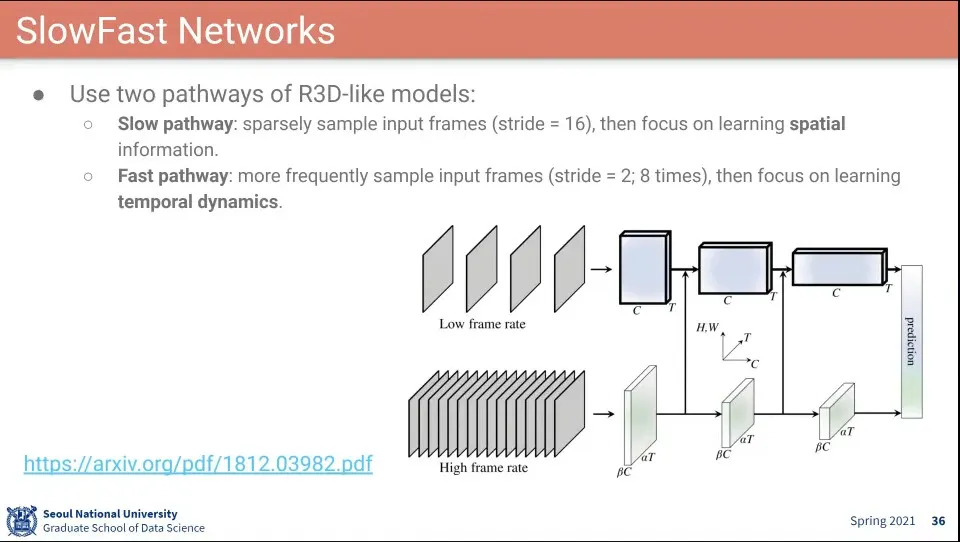
•
시간 간격을 듬성듬성 뽑은 것(Low Frame Rate, Slow pathway)과 촘촘히 뽑은것(High Frame Rate, Fast pathway)을 따로 뽑고 그것을 합쳐서 하자는게 SlowFast Net
◦
Slow path는 공간적인 정보를 주로 보고, Fast path는 시간적인 정보를 주로 본다.
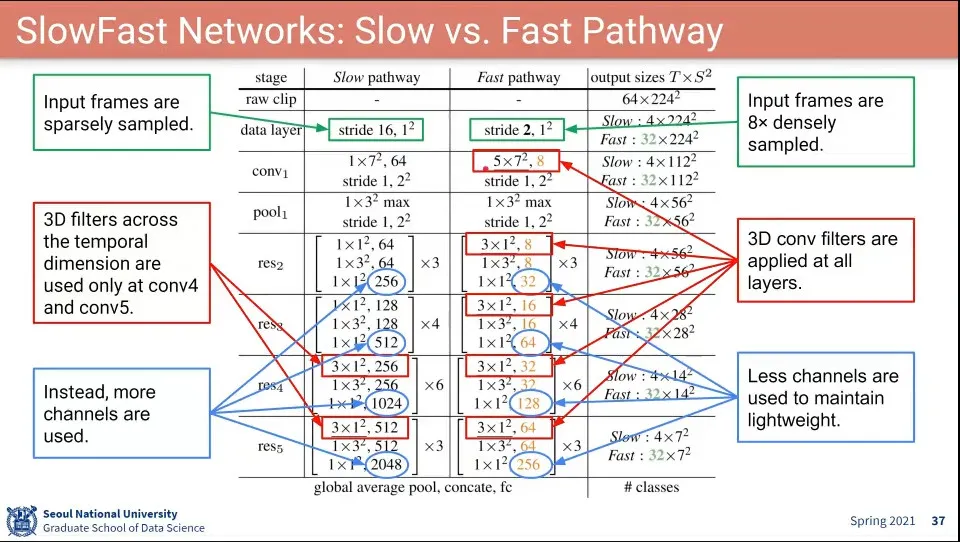
•
Slow, Fast path의 차이

•
위 구조로 그냥 학습 시켰더니 좀 잘 안되서, Fast의 중간 결과를 Slow에서 받거나 Slow의 중간 결과를 Fast에서 받아서 처리하는 식으로도 해봤는데, 결과적으로는 Fast에서 Slow로 가는 것만해도 성능은 잘 나왔다고 함.
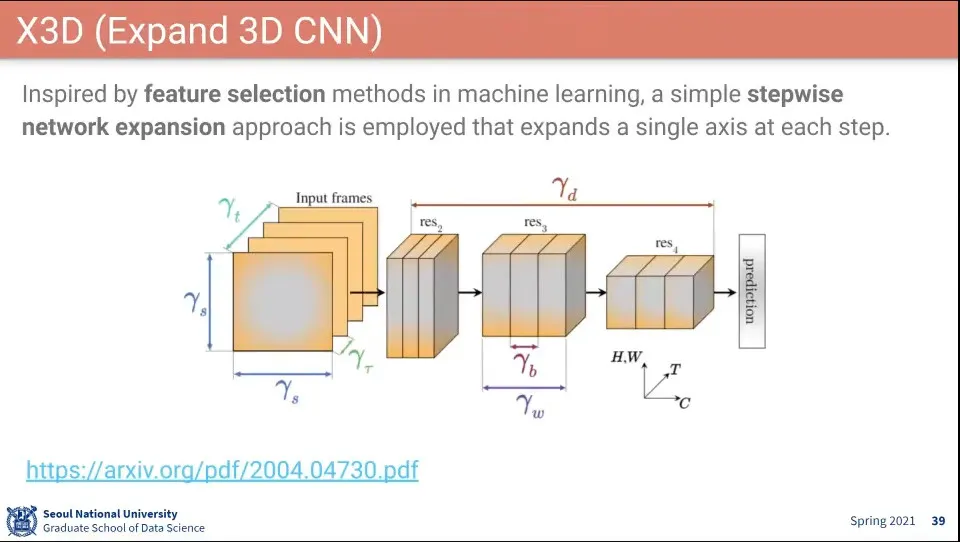
•
기존 모델들에 대해 파라미터를 바꿔가며 학습해 볼 수 있게 한 모델.
◦
그냥 실험해 본 논문

•
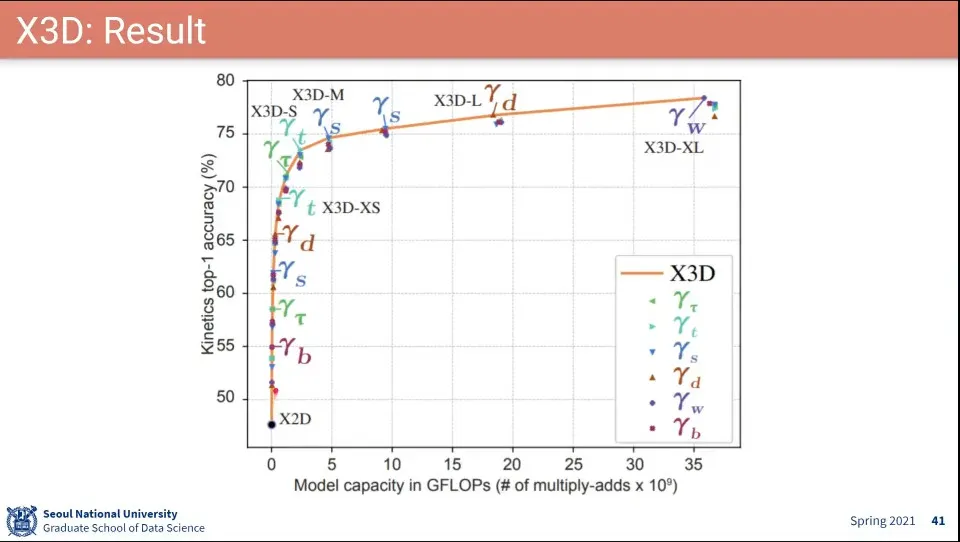
X3D에서 설정할 수 있는 파라미터들
•
파라미터 바꿔가며 위와 같이 성능을 했다.
•
현재 상태
