
Latent Diffusion Model(LDM)
이미지에 대한 Diffusion Model의 속도를 높이기 위해 이미지를 Latent Space로 임베딩한 후에 Diffusion Model을 임베딩에 맞추는 방법을 사용할 수 있다. 이것은 이미지의 대부분의 비트가 지각적 디테일에 기여하고 압축 후에도 의미와 개념적 구성이 여전히 남아 있다는 관찰에 기반한다.
LDM은 우선 autoencoder로 픽셀 수준의 중복성을 제거한 후에 학습된 latent에 대한 diffusion 프로세스를 통해 의미적 개념을 manipulating/generating 하는 방식으로 perceptual 압축과 semantic 압축을 생성 모델링 학습으로 느슨하게 분해한다.
지각적 압축 프로세스는 autoencoder 모델에 의존한다. 인코더 는 입력 이미지 를 더 작은 2D latent 벡터 로 압축하는 데 사용되며, 그 다음 디코더 는 latent 벡터에서 이미지를 재구성합니다. .
diffusion과 denoising 프로세스는 latent 벡터 에서 발생한다. denoising 모델은 시간에 조건화된 U-Net으로 이미지 생성을 위한 유연한 조건화 정보를 다루기 위해 cross-attention 메커니즘을 사용한다. 이것은 여러 modality의 표현을 모델에 융합하는 것과 같다.
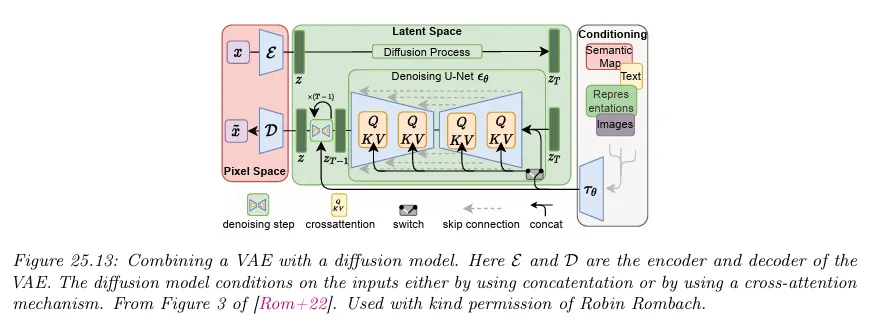
속도를 높이는 것 외에 diffusion 모델을 autoencoder와 결합하는 것의 또 다른 이점은 텍스트나 그래프 같은 다양한 종류의 데이터에 diffusion을 간단히 적용할 수 있다는 것이다. 입력 도메인을 연속 공간으로 임베딩하는 적합한 아키텍쳐만 정의하면 된다. 물론 diffusion을 이산 상태 공간에 직접 정의하는 것도 가능하다.
일반적으로 VAE의 위에 diffusion을 적용하는 방법을 사용하지만 거꾸로 DDPM 모델 위에 VAE를 맞추는 것도 가능하다. 여기서 diffusion model을 VAE에 나오는 블러 샘플을 ‘후처리’하는데 사용한다.
