
1 Introduction
전통적인 stereo의 주요 아이디어는 triangulation을 통해 대응점 와 를 사용하여 3d 점 의 위치를 추정하는 것이다. 여기서 핵심 도전은 대응 문제를 해결하는 것이다. 즉 점 가 또 다른 이미지에서 점 에 실제로 대응되는지 어떻게 판단할 수 있는가? 이 문제는 장면에 존재하는 많은 3d점을 처리해야 한다는 사실로 인해 더욱 accentuated(부각된)다. 이 노트에서는 3d 구조를 잘 재구성할 수 있는 대안 기법을 논의한다.
2 Active stereo
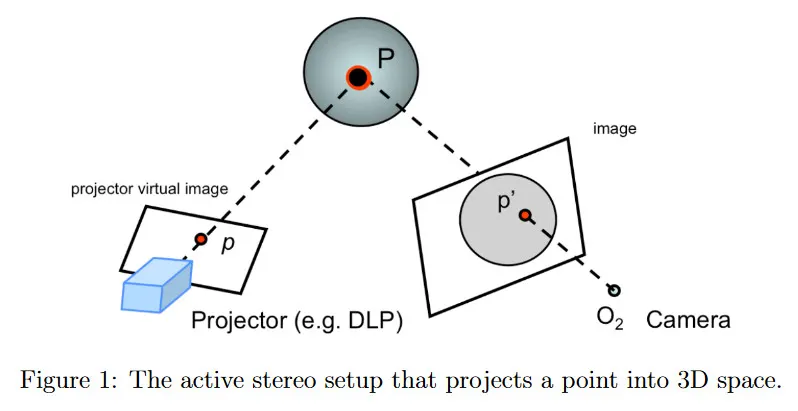
우선 active stereo라는 기법을 소개한다. 이것은 전통적인 stereo에서 대응점 문제를 완화하는데 도움을 준다. active stereo의 주요 아이디어는 두 카메라 중 하나를 3d 환경과 상호작용하는 장치로 교체하고 두 번째 카메라에서 쉽게 식별가능한 패턴을 객체에 projecting하는 것이다. 이 새로운 projector-camera 쌍은 카메라 쌍에 대해 소개한 것과 동일한 epipolar geometry를 정의한다. 교체된 카메라의 이미지 평면은 projector virtual plane으로 교체된다. 그림 1에서 projector는 virtual plane의 점 를 3d 공간의 객체에 project하여 3d 공간의 점 를 생성한다. 이 3d 점 는 2번째 카메라에서 점 로 관찰되어야 한다. 우리가 무엇을 projecting하는지 알기 때문에(예: virtual plane에서 의 position, projection의 color와 intensity 등), 두 번째 카메라에서 대응하는 관측치 를 쉽게 발견할 수 있다.
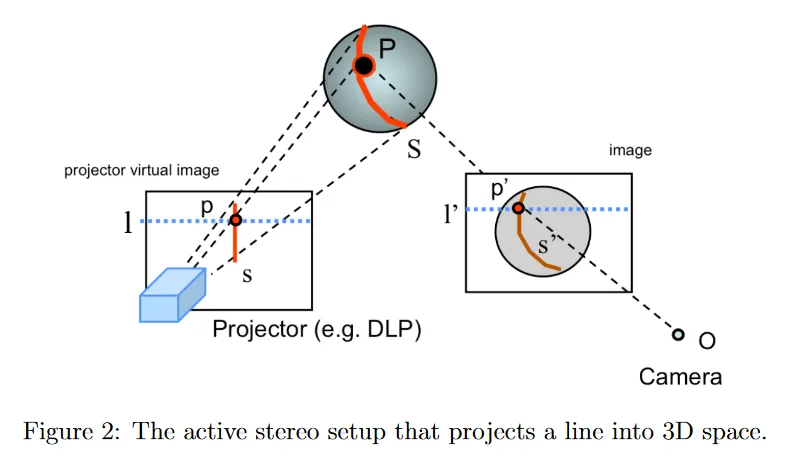
active stereo에서 일반적인 전략은 단일 점 대신 virtual plane에서 vertical stripe 를 투영하는 것이다. 이 경우는 점의 경우와 매우 유사하다. 여기서 선 가 3d 공간 stripe 에 투영되고 카메라에서는 선 로 관찰된다. projector와 카메라가 평행하거나 rectified 되면 horizontal epipolar 선과 의 교점을 간단히 찾음으로써 대응점을 쉽게 찾을 수 있다. 이 대응점을 이용하여 이전 강의 노트에서 소개한 triangulation 방법으로 stripe 상의 모든 3d 점을 재구성할 수 있다. line을 장면 전체에 걸쳐 swiping하고 이 절차를 반복하면 장면 내의 모든 visible 객체의 전체 형상을 복구할 수 있다.
이 알고리즘이 작동하기 위한 한 가지 요구사항은 projector와 카메라가 calibrated 이어야 한다는 것이다. active stereo system은 이전 노트에서 설명한 것과 유사한 기법을 사용하여 calibrated 될 수 있다. 우선 calibration rig을 사용하여 카메라를 calibrate한 다음 알려진 stripes를 calibration rig에 투영하고 새로 calibrated 카메라에서 대응 관측치를 사용하여 projector의 intrinsic과 extrinsic 파라미터를 추정하기 위한 제약조건을 설정할 수 있다. 일단 calibrated 되면 이 active stereo 설정은 매우 정확한 결과를 생성할 수 있다. 2000년에 Stanford에서 Marc Levoy와 그의 학생들은 정밀하게 조정된 laser scanner를 사용하여 sub-millimeter 정확도로 Michaelangelo의 Pieta의 형상을 복구했다.
그러나 경우에 따라 정밀하게 조정된 projector는 매우 비싸고 cumbersome(번거롭다). 더 저렴한 설정을 사용하는 대안 접근은 그림자를 활용하여 복구하기를 원하는 객체에 대한 active pattern을 생성한다. 알려진 위치에 있는 광원과 객체 사이의 stick을 배치하면 이전과 같이 객체에 대해 효율적으로 stripe를 투영할 수 있다. stick을 움직이면 객체에 다른 그림자 stripe를 투영할 수 있고 이전과 유사한 방법으로 객체를 복구할 수 있다. 이 방법은 훨씬 저렴하지만 stick과 카메라와 광원 사이에 매우 정확한 calibration이 필요하고 stick의 그림자의 길이와 thickness 사이의 tradeoff가 필요하기 때문에 덜 정확한 결과를 생성하는 경향이 있다.
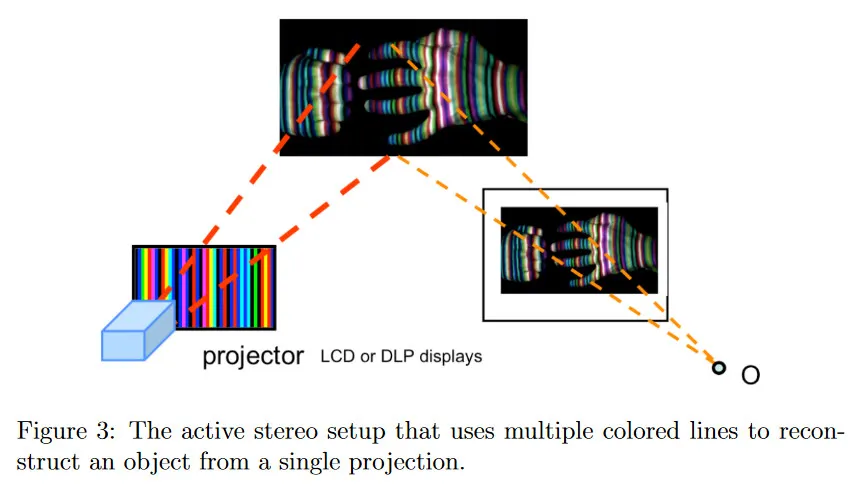
단일 stripe를 객체에 투영하는 것의 한계는 projector가 전체 객체를 swipe 해야 하므로 상대적으로 느리다는 것이다. 또한 이 방법으로는 현실 세계의 deformations(변형)을 포착할 수 없다. 자연스러운 확장은 단일 프레임 또는 이미지를 투영하여 객체를 복구하려고 시도하는 것이다. 이 아이디어는 단일 stripe 대신 객체의 전체 visible에 알려진 다양한 stripe 패턴을 투영하는 것이다. 이 stripes의 색상은 이미지에서 stripes를 고유하게 식별할 수 있도록 설계된다. 그림 3은 이 여러 색상 코드된 stripe 방법을 보인다. 이 컨셉은 Microsoft Kinect의 원래 버전 같은 많은 현대 depth 센서의 기반이 되었다. 실제로 이러한 센서들은 임의의 ambient light 조건 하에 3d 에서 비디오 데이터를 포착할 수 있도록 infrared(적외선) 레이저 projector를 사용한다.
3 Volumetric stereo
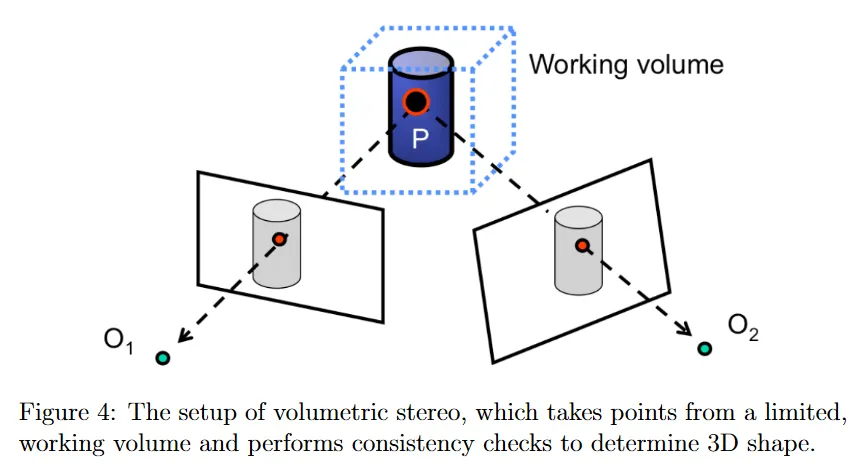
전통적인 stereo와 active stereo 접근 모두에 대한 대안은 volumetric stereo이다. 이것은 대응점을 사용하여 3d 구조를 찾는 문제를 반전시킨다. volumetric stereo에서는 추정하려는 3d 점이 일부 포함된, 알려진 volume 내에 있다고 가정한다. 그 다음 hypothesized(가설적) 3d 점을 calibrated 카메라에 다시 투영하고 이러한 투영이 여러 view에 걸쳐 consistent(일관된)지 여부를 평가한다. 그림 4는 volumetric stereo 문제의 일반적인 설정을 보인다. 이러한 기법들은 재구성하려는 점들이 limited volume에 포함되어 있다고 가정하므로, unbounded인 장면 모델 복구을 복구하는 것과 달리 특정 객체의 3d 모델을 복구하는데 주로 사용된다.
모든 volumetric stereo 주요 tenet(교리)는 포함된 volume내의 3d점을 여러 이미지 view로 reproject할 때, ‘consistent’의 의미를 우선 정의하는 것이다. 따라서 consistent 관측이라는 개념의 정의에 따라 다양한 기법이 유도될 수 있다. 이 노트에서 3가지 주요 기법의 개요를 설명한다. 이것은 space carving, shadow carving, voxel coloring이다.
3.1 Space carving
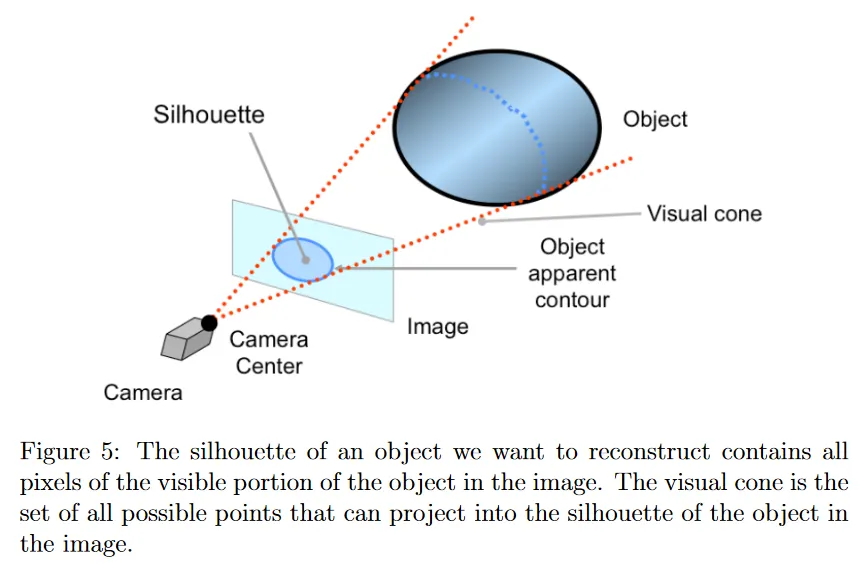
space carving의 아이디어는 주로 객체의 contour(윤곽)이 객체에 관한 풍부한 geometric 정보 소스를 제공한다는 관찰에서 유도된다. 먼저 multiple view의 맥락에서 그림 5에 설명된 문제를 설정해 보자. 각 카메라는 contour를 결정할 수 있는 객체의 일부 visible portion을 관찰한다. 이미지 평면에 투영될 때, 이 contour는 이미지 평면에 있는 객체의 silhouette으로 알려진 픽셀의 집합을 encloses(둘러싸다). space carving은 궁극적으로 multiple view에서 객체의 silhouettes를 사용하여 consistency를 강화한다.
그러나 3d 객체의 정보가 없고 이미지만 있다면 silhouette 정보를 어떻게 얻을 수 있는가? 다행히 silhouette 작업의 실질적인 이점 중 하나는 복구하려는 객체 뒤의 background의 제어할 수 있는 경우 이미지에서 silhouette을 쉽게 검출할 수 있다는 것이다. 예컨대 객체 뒤에 ‘green screen’을 사용하여 background에서 객체를 쉽게 segment 할 수 있다.
이제 silhouettes를 갖고 어떻게 활용할 수 있는가? volumetric stereo에서는 객체가 그 안에 있을 수 있다고 보장하는 어떤 volume 추정치가 있다는 점을 떠올려라. 이제 visual cone의 개념을 유도한다. 이것은 카메라 중심과 이미지 평면의 객체의 contour에 의해 정의되는 surface를 enveloping(감싼다). 구성에 의해 객체가 초기 volume과 visual cone 모두에서 완전히 포함되는 것이 보장된다.
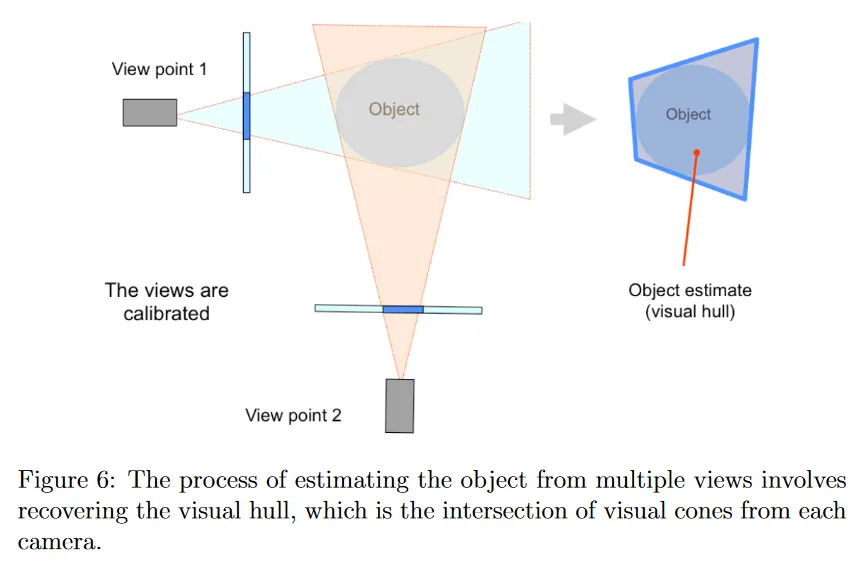
그러므로 multiple view를 가지면 각 view에 대해 visual cone를 계산할 수 있다. 정의 상 객체는 이러한 모든 visual cone에 존재하므로, 그림 6에 나온대로 객체는 이 visual cone의 교집합에 존재해야 한다. 이런 교집합을 종종 visual hull이라 부른다.
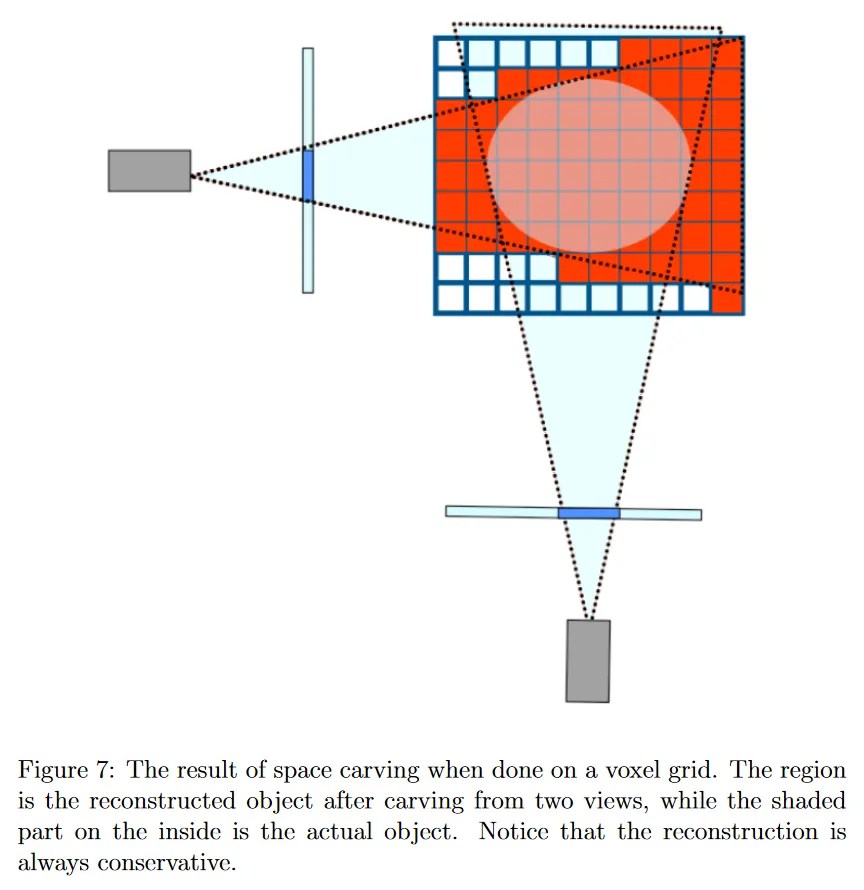
실제로는 먼저 객체가 포함되어 있다고 알려진 working volume을 정의한다. 예컨대 카메라가 객체를 둘러싸고 있다면 working volume을 카메라에 의해 둘러싸인 공간 내부 전체라고 말할 수 있다. 우리는 이 volume을 voxel이라 부르는 작은 단위로 분할하여 voxel grid를 정의한다. voxel grid의 각 voxel을 모든 view에 투영한다. voxel이 어떤 view의 shilhouette에 포함되지 않으면 폐기된다. 결과적으로 space carving 알고리즘의 끝에서 우리는 visual hull 내에 포함된 voxel만 남긴다.
space carving 방법이 대응점 문제를 피하고 상대적으로 간편하지만 여전히 많은 한계를 갖는다. space carving의 한 가지 한계는 grid의 voxel의 수에 선형적으로 확장된다는 것이다. 각 voxel의 크기를 줄이면 grid에 필요한 voxel의 수가 3차적으로 증가한다. 그러므로 더 미세한 재구성 결과를 얻으려면 시간이 크게 증가한다. 그러나 octrees를 사용하는 것과 같은 방법으로 이 문제를 완화할 수 있다. 관련된 더 간단한 방법으로는 초기 voxel grid의 크기를 줄이기 위해 반복적으로 carving을 수행하는 것이 있다.
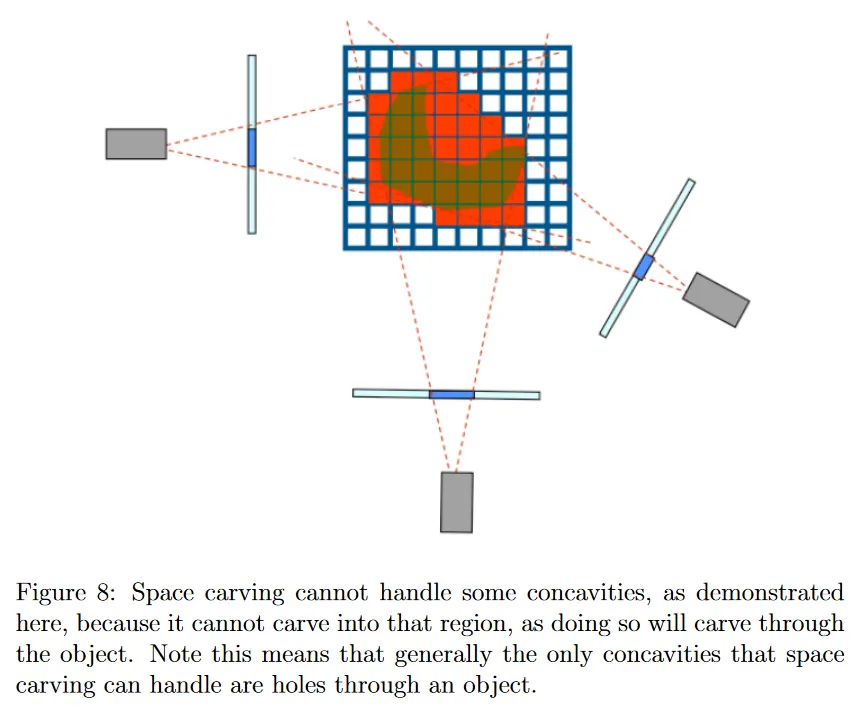
또 다른 한계는 space carving의 효율성이 view의 수, silhouette의 정밀도 그리고 심지어 재구성하려는 객체의 shape에 의존한다는 것이다. view의 수가 너무 낮으면 객체의 visual hull에 대한 매우 느슨한 추정을 얻는다. view의 수가 증가할 수록 일관성 체크에 의해 더 많은 extraneous voxel이 제거된다. 게다가 일관성 체크의 유효성은 silhouette이 정확하다는 사실에 전적으로 의존한다. silhouette가 매우 conservative(보수적)이고 필요한 것보다 더 많은 pixel을 포함하면, carving은 정밀하지 않을 수 있다. 심지어 silhouette이 실제 객체의 portion을 놓치면 과도하게 carved인 reconstruction 결과가 발생할 수 있다. 마지막으로 space carving의 주요 단점은 그림 8에서 보이는 대로 객체의 특정 오목한 부분을 모델링할 수 없다는 것이다.
3.2 Shadow carving
space carving이 야기하는 오목성 문제를 해결하기 위해 다른 형식의 consistency 체크를 살펴야 한다. 객체의 3d shape을 결정하는데 사용할 수 있는 위한 중요한 단서는 self-shadows의 존재이다. self-shadows는 객체가 자기 자신에 투영한 그림자이다. 오목 객체의 경우에 대해 객체는 종종 오목 영역에 self-shadows를 cast 한다.
Shadow carving은 근본적으로 self-shadow을 사용하여 더 나은 오목성을 추정하는 아이디어로 space carving을 보완한다. 그림 9에 나온대로, shadow carving의 일반적인 설정은 space carving과 매우 유사하다. 객체는 calibrated 카메라가 바라보는 회전 테이블에 놓인다. 그러나 카메라 주위에는 알려진 위치에 있는 조명의 배열이 있으며, 이 조명을 적절히 켜고 끌 수 있다. 이 조명은 객체에 self-shadow를 cast하는데 사용된다.
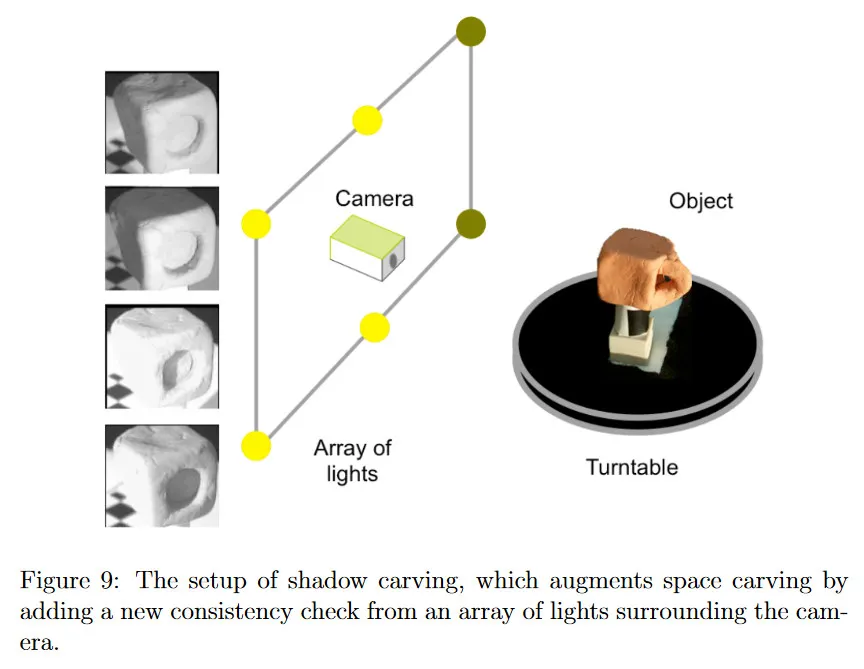
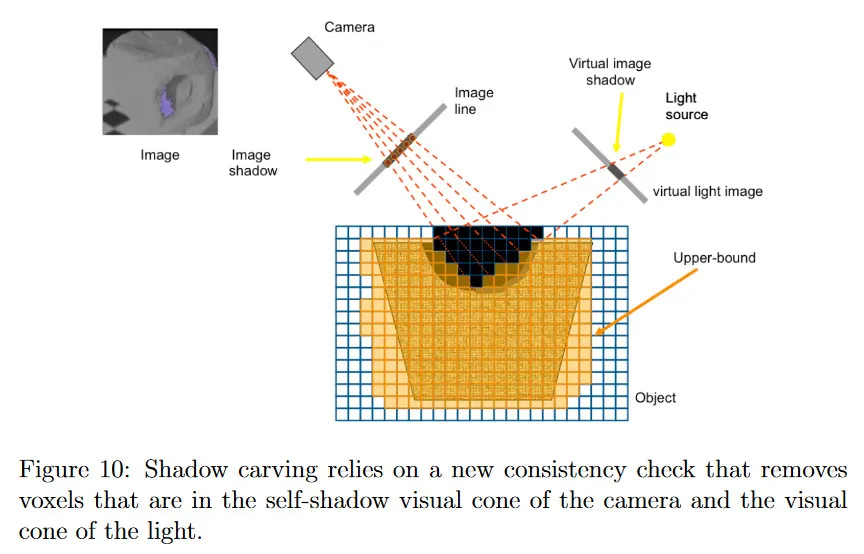
그림 10에 나온대로 shadow carving 절차는 space carving에서 동일한 접근을 사용하여 trimmed down된 초기 voxel grid에서 시작한다. 그러나 각 view에서 카메라를 둘러싼 조명 배열의 각 조명을 켜고 끌 수 있다. 각 조명은 객체에 대해 다양한 self-shadow을 생성한다. 이미지 평면에서 그림자를 식별한 후, trimmed voxel grid의 surface에 있으며 그림자의 visual cone에 있는 voxel을 찾을 수 있다. 이 surface voxel을 사용하면 이미지 소스와 새로운 visual cone을 생성할 수 있다. 그 다음 두 visual cone의 일부일 수 없는 voxel은 객체의 일부일 수 없다는 유용한 사실을 활용하여 오목 부분의 voxel을 제거한다.
space carving과 유사하게 shadow carving의 실행 시간은 voxel grid의 해상도에 의존한다. 실행 시간은 voxel grid의 해상도에 3차적으로 증가한다. 그러나 개 조명이 존재하면, 각 voxel을 카메라와 개 조명에 각각 투영해야 하므로 shadow carving은 space carving 보다 대략 배 더 오래 걸린다.
요약하면 shadow carving은 항상 보수적인 volume 추정을 생성하며 오목한 3d shape를 더 잘 재구성한다. 결과의 품질은 view의 수와 조명의 수에 의존한다. 이러한 접근의 단점은 객체에 reflective(반사) 또는 low albedo region이 있는 경우를 다룰 수 없다는 것이다. 그러한 조건에서는 그림자를 정확하게 검출할 수 없기 때문이다.
3.3 Voxel coloring
volumetric stereo에서 우리가 다루는 마지막 기법은 voxel coloring이다. 이것은 space carving에서 contour consistency 대신 color consistency를 사용한다.
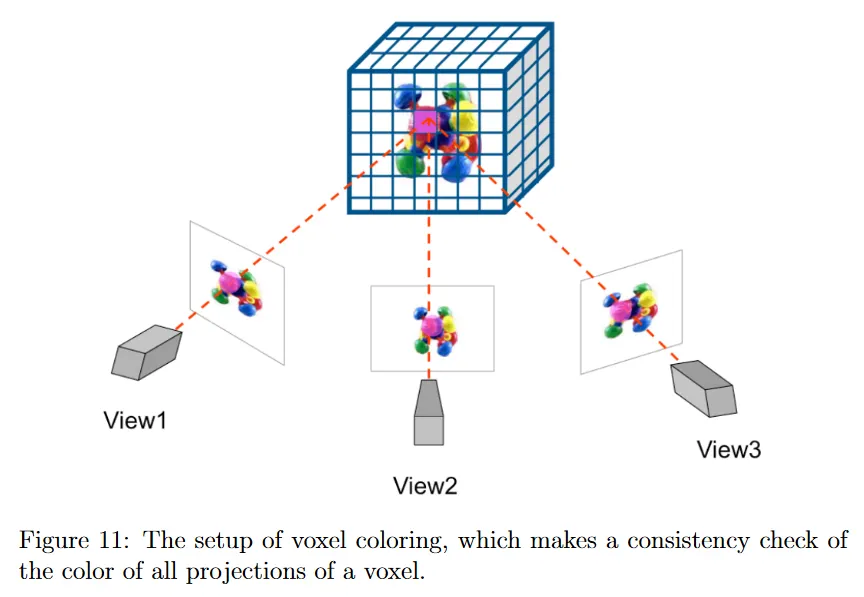
그림 11에 나온 것처럼 재구성하려는 객체의 multiple-view에서 이미지가 주어진다고 가정하자. 각 voxel에 대해 모든 이미지에서 해당하는 투영을 살피고 이 투영의 color를 비교한다. 이러한 투영의 color가 충분히 일치하면 해당 voxel을 객체의 일부로 표시한다. space carving에서 없는 voxel coloring의 이점은 투영과 관련된 color을 voxel에 전달하여 colored reconstruction을 제공한다는 것이다.
전체적으로 color consistency 체크에 사용할 수 있는 많은 방법이 존재한다. 한 가지 예는 투영 사이의 color similarity 사이의 threshold를 설정하는 것이다. 그러나 사용되는 모든 color consistency check에는 중요한 가정이 존재한다. reconstructed인 객체는 반드시 Lambertian이어야 한다. 이것은 객체의 임의의 부분의 인지된 luminance(휘도)가 viewpoint의 위치나 포즈에 따라 변하지 않아야 한다는 의미이다. 높은 반사율 재질로 된 non-Lambertian 객체의 경우, 실제 객체의 일부인 voxel에서 color consistency check가 실패할 수 있다.
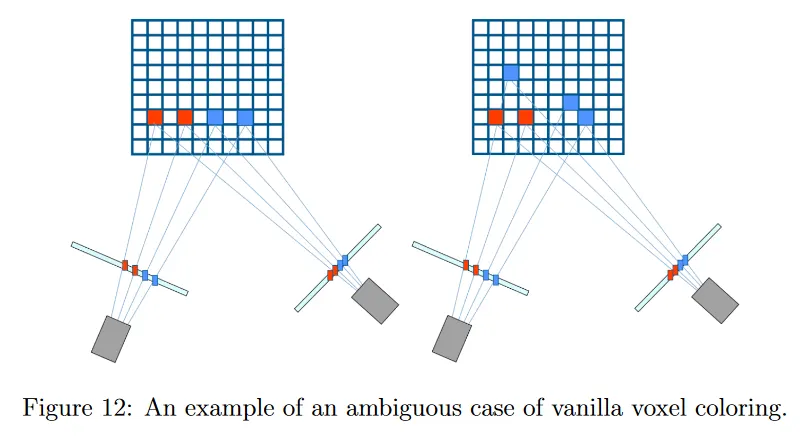
vanilla voxel coloring의 한 가지 단점은 그림 12와 같이 반드시 고유한 해를 생성하지 않는다는 것이다. voxel coloring로 reconstruction할 때 진정한 유일한 해를 찾는 것은 문제를 더욱 복잡하게 한다. voxel에 대한 visibility 제약을 도입하여 특정한 순서로 voxel을 탐색함으로써 reconstruction의 모호성을 제거할 수 있다.
특히 카메라에 가까운 voxel에서 시작한 다음 더 먼 voxel로 레이어별로 voxel을 탐험하기를 원한다. 이 순서를 사용할 때 color consistency 체크를 수행한다. 그런 다음 해당 voxel이 최소 두 카메라에서 보여지는지 확인하여 visibility 제약을 구성한다. voxel이 최소 두 카메라에서 보이지 않으면 차폐된 것이고 따라서 객체의 부분이 아니다. 가까운 voxel 부터 처리하는 순서 덕분에 나중에 처리되는 voxel을 가릴 수 있는 voxel을 유지하여 이 visibility 제약을 적용할 수 있다.
결론적으로 voxel coloring은 객체의 shape과 texture를 동시에 포착할 수 있는 이점을 갖는다. 단점은 객체가 Lambertian이라고 가정해야 하고 visibility 제약 때문에 voxel이 특정한 순서로 진행되어야 하므로 카메라를 특정 위치에 둘 수 없다는 것이다.
