•
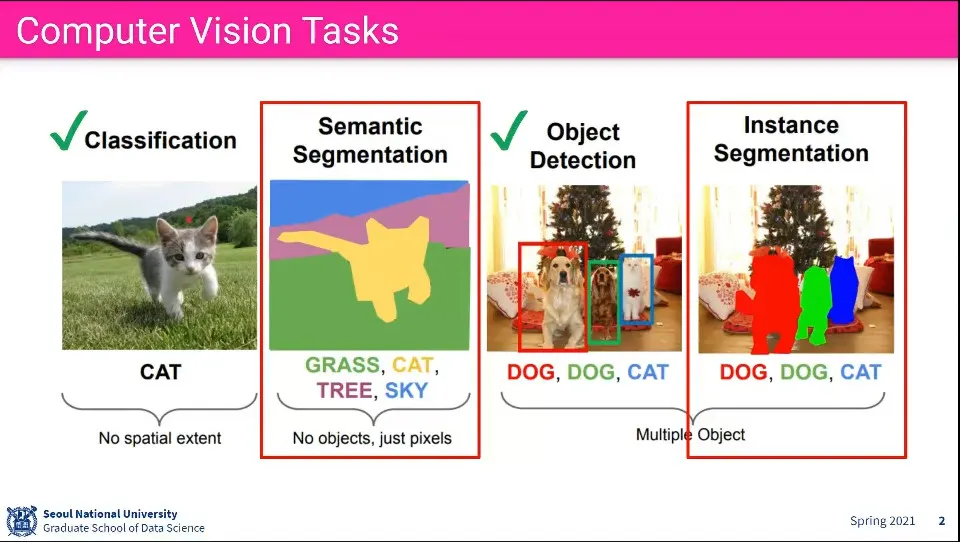
Segmentation은 object의 영역을 구분해 내는 것
◦
Semantic Segmentation은 영역 내의 모든 pixcel에 대해 segmentation을 하는 것이고
◦
Instance Segmentation은 인식된 object에 대해 segmentation을 하는 것

•
Semantic Segmentation은 학습할 때 왼쪽과 같이 배경과 object를 pixcel 단위로 나눠서 학습 시키고, 오른쪽과 같이 segmentation 하는 결과를 얻어 냄
◦
이때 구분만 될 뿐, 이게 어떤 object라는 것은 알지 못함

•
이것을 하기 위해 pixcel이 주위에 어떤 것들이 있는지를 고려해서 자신이 무엇인지를 알아내야 한다.

•
그런데 이렇게 하면 어마어마한 계산량이 필요함

•
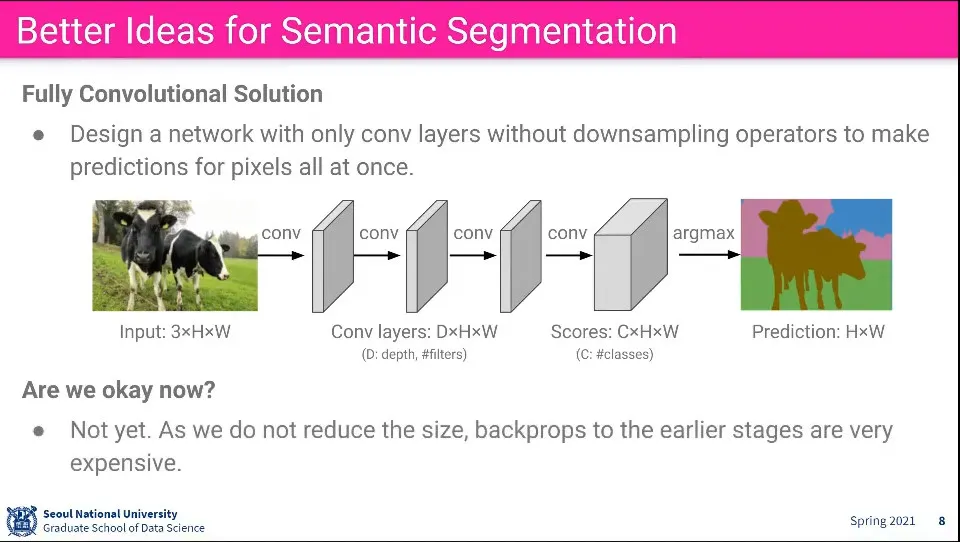
Conv Net을 이용해서 학습을 시켜보면 어떨까?
•
하지만 conv net은 output, input 크기가 같아야 하는데 이걸로는 안 됨
•
Conv Net에서 이미지를 안 줄이면 되지 않을까?
•
이렇게 하면 계산 비용이 너무 비쌈
•
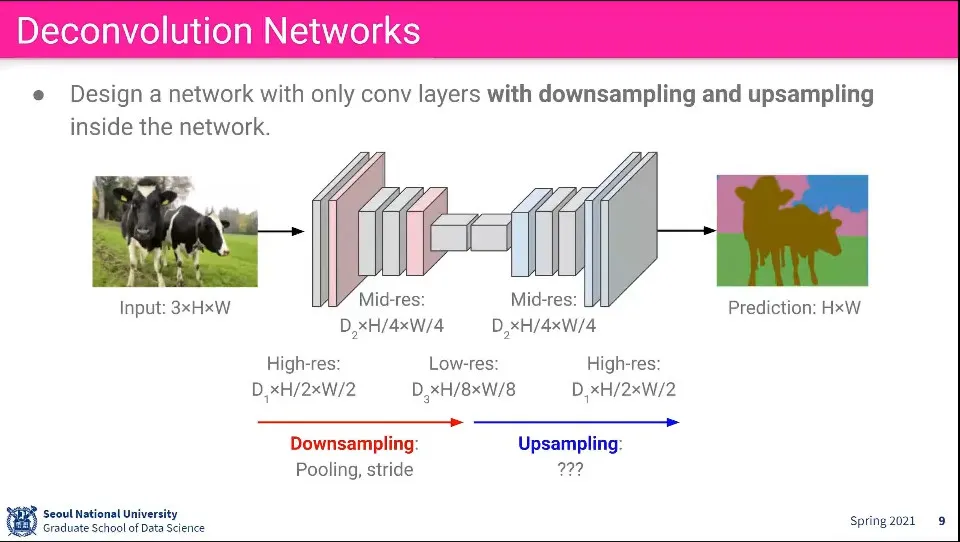
그렇다면 Downsampling, Upsampling을 이용해서 하자.
◦
원래 이미지는 Downsampling 해서 이미지를 줄이고, 나중에 그걸 복원하는 식으로 처리
•
이렇게 하면 이전의 문제는 다 해결할 수 있지만, Upsampling을 어떻게 해야 할까?

•
Nearest Neighbor나 Bed of Nails (나머지는 모두 0으로 채움)을 생각해 볼 수 있다.
•
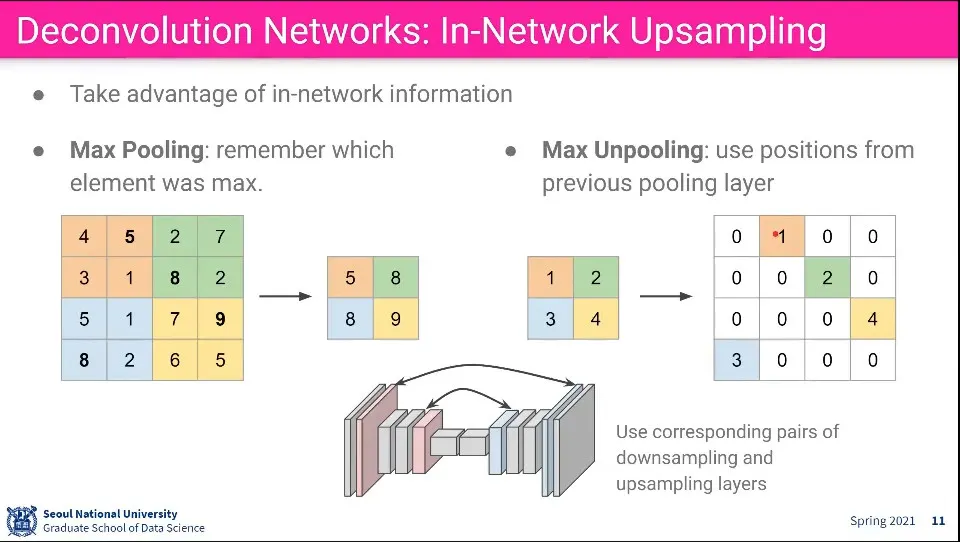
Max Pooling을 거꾸로 Max Unpooling을 할 수 있다. 이때 Pooling 할때의 위치를 기억해서 해당 위치에 값을 쓰고 나머지는 Bed of Nails처럼 0으로 채움
•
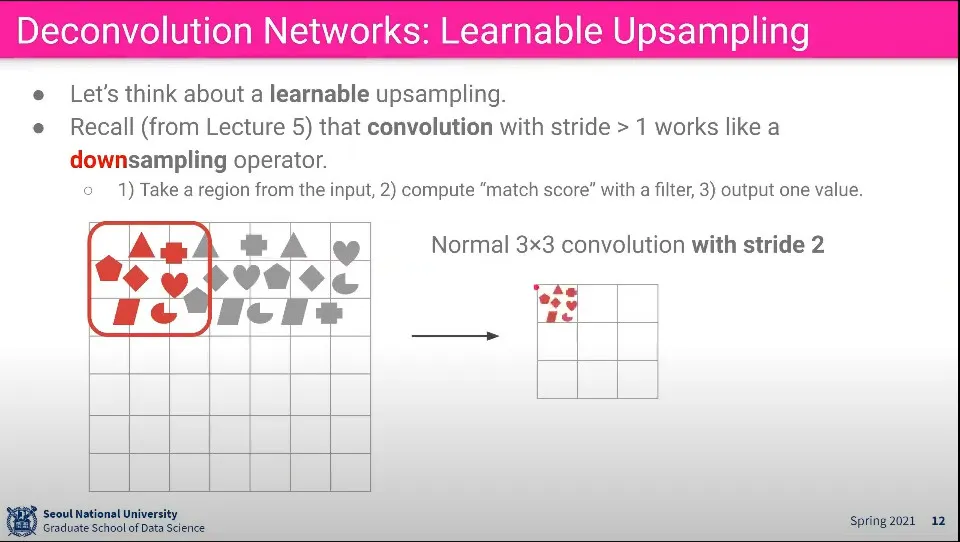
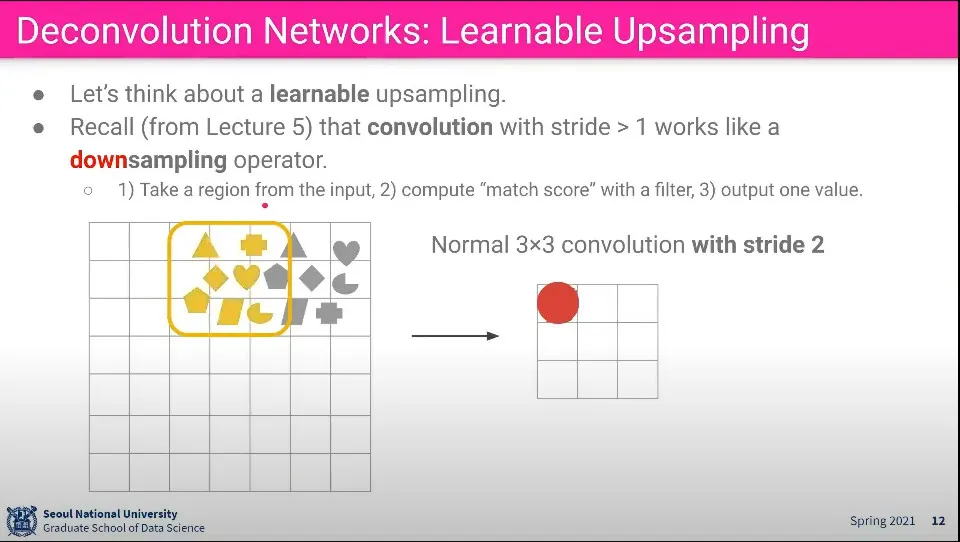
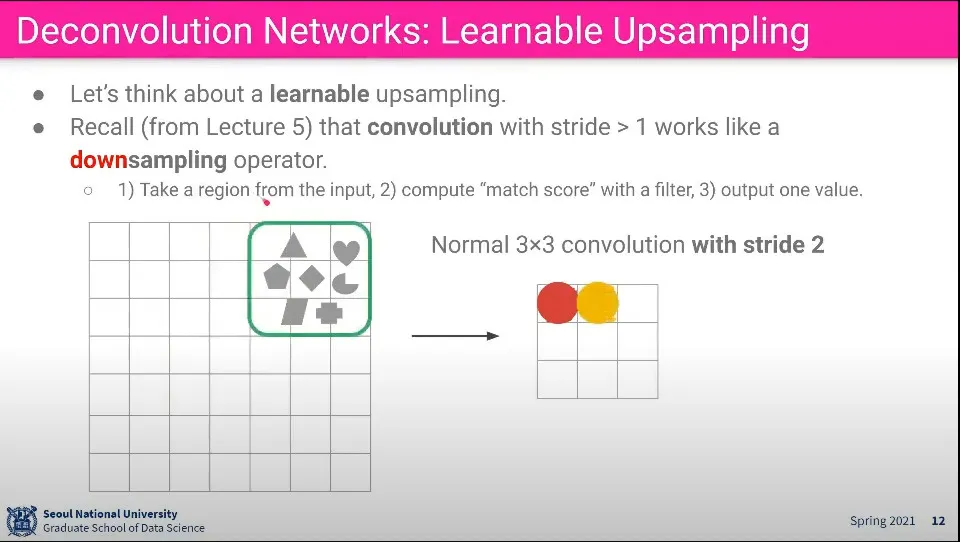
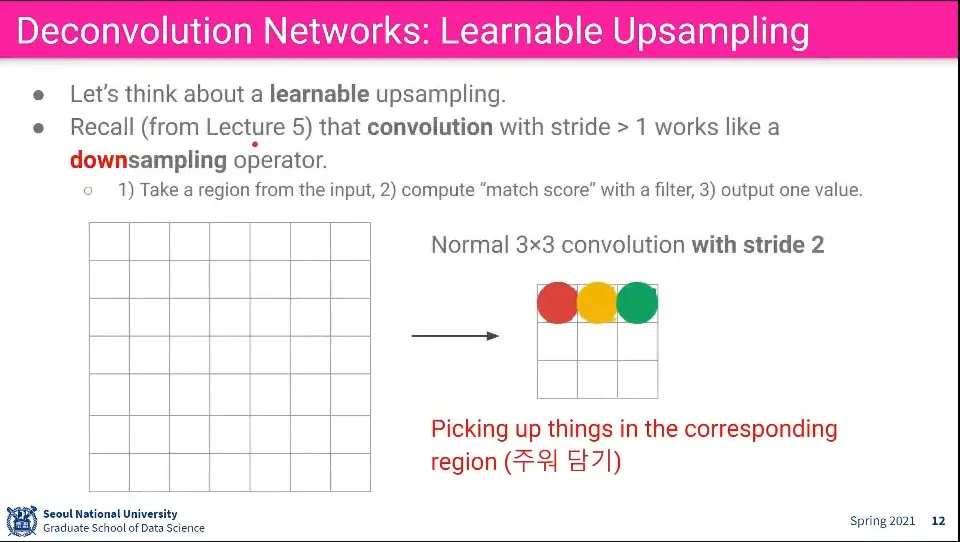
Convolution 단계는 위와 같이 이해할 수 있다. 영역내 pixel들에서 feature를 뽑아 더 작은 사이즈로 합침
•
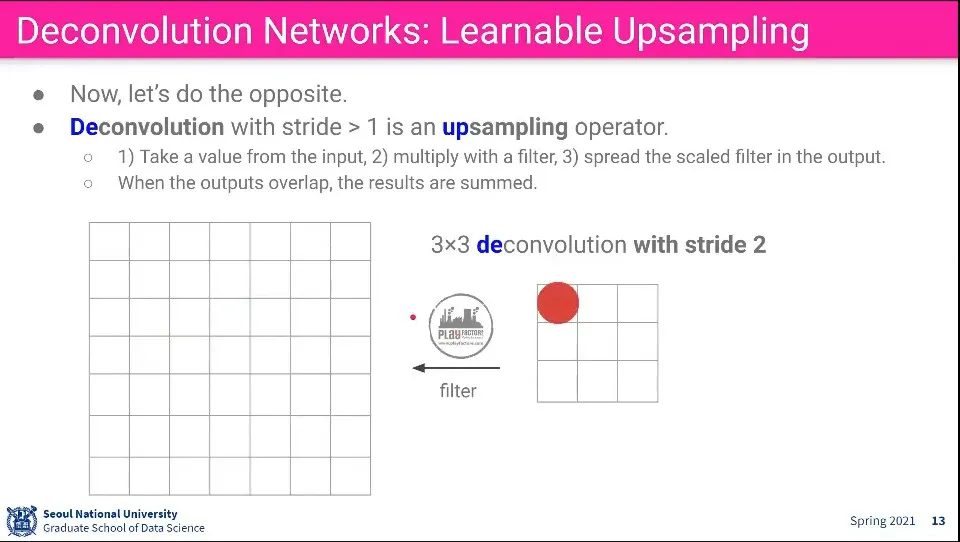
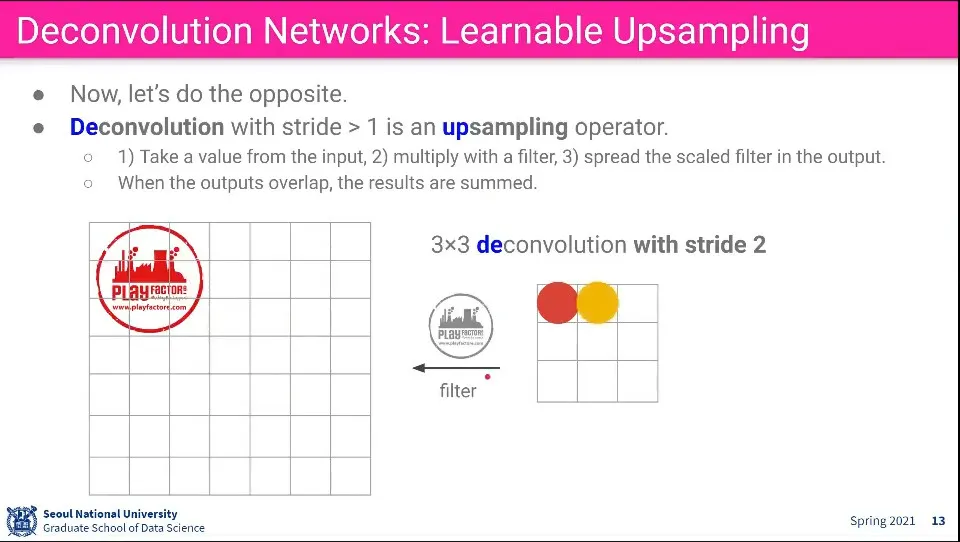
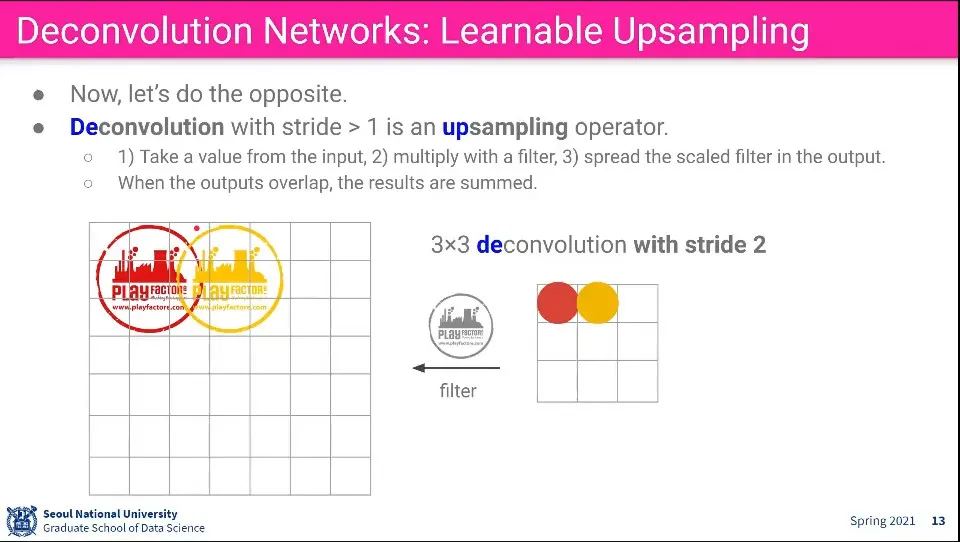
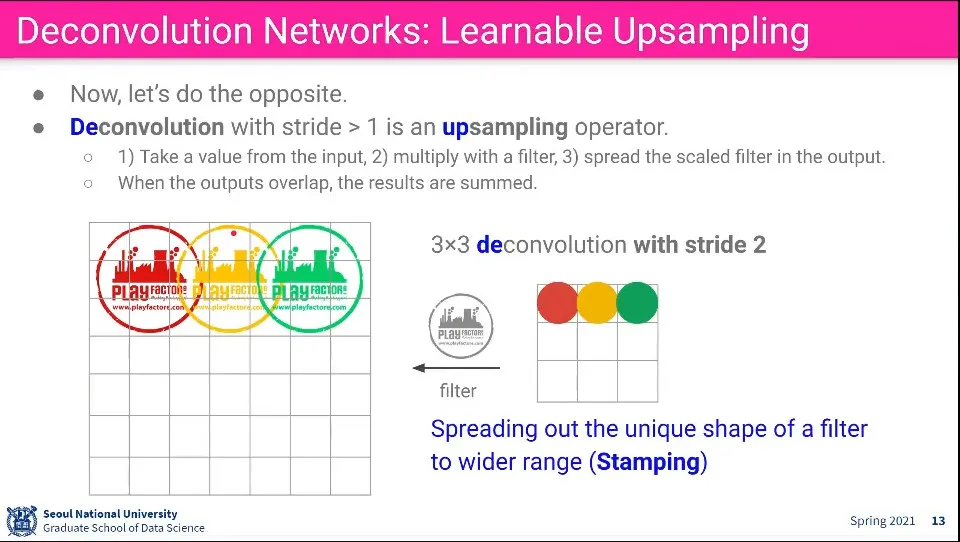
Deconvoultion은 Convolution의 반대 방향으로 생각할 수 있다. Input에 있는 값에 어떤 filter를 곱해서 더 큰 이미지를 만들어 냄.
◦
stride를 따라 가며 이미지를 계속 찍어내고, 찍어내는 부분이 겹치면 합친다.
•
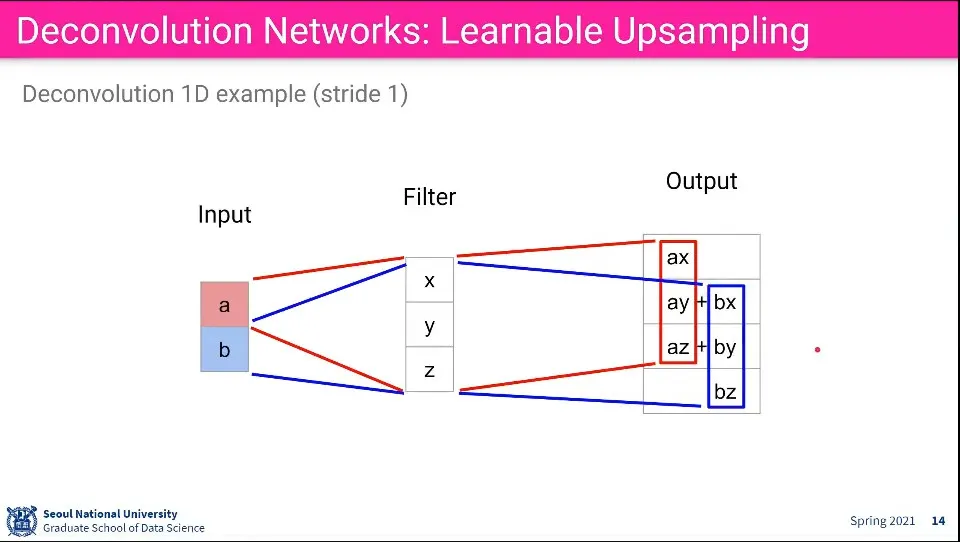
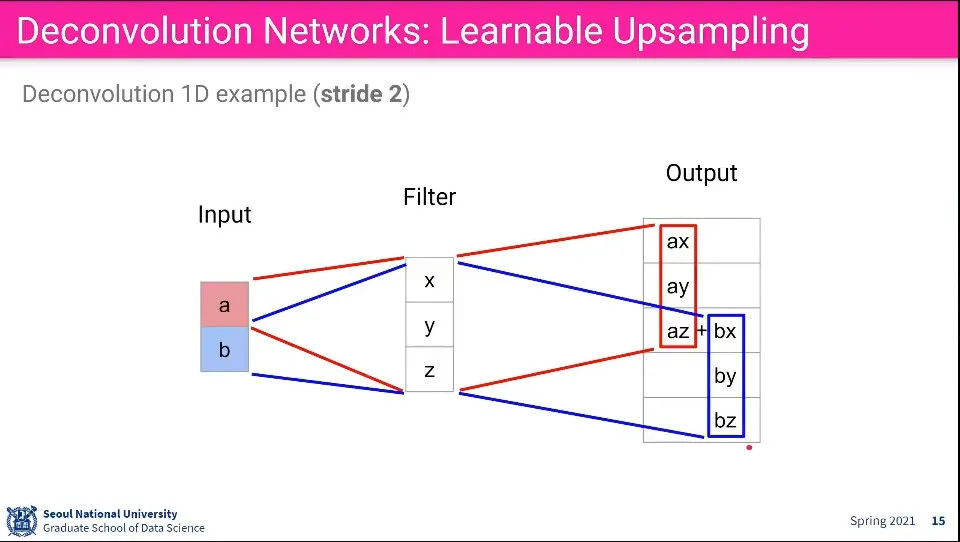
값이 들어가는 예는 위와 같다. Stride에 따라 겹치는 부분이 달라짐
•
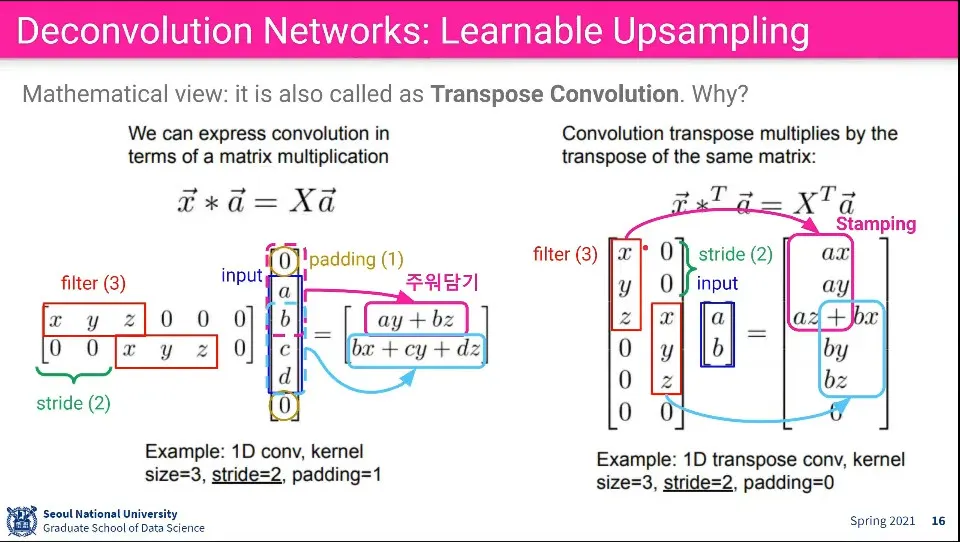
Deconvolution은 Convolution의 역 연산이기도 하지만 Transpose Convolution이 되기도 한다.
•
위의 왼쪽 그림은 Convolution이 일어나는 연산 흐름이다.
◦
Stride는 filter에 적용되므로, stride 만큼 이동하면서 구성되고,
◦
Padding은 이미지에 적용되므로 그 크기만큼 이미지 행렬에 추가됨
◦
그 결과로 만들어진 행렬은 그 다음 행렬이 된다.
•
위의 오른쪽 그림은 같은 식으로 표현한 Deconvolution의 연산 흐름인데, 이것은 filter를 Transpose 한 후 연산한 것과 동일한 결과가 나온다.
◦
때문에 Deconvolution의 연산은 어려운 연산이 아니다.
•
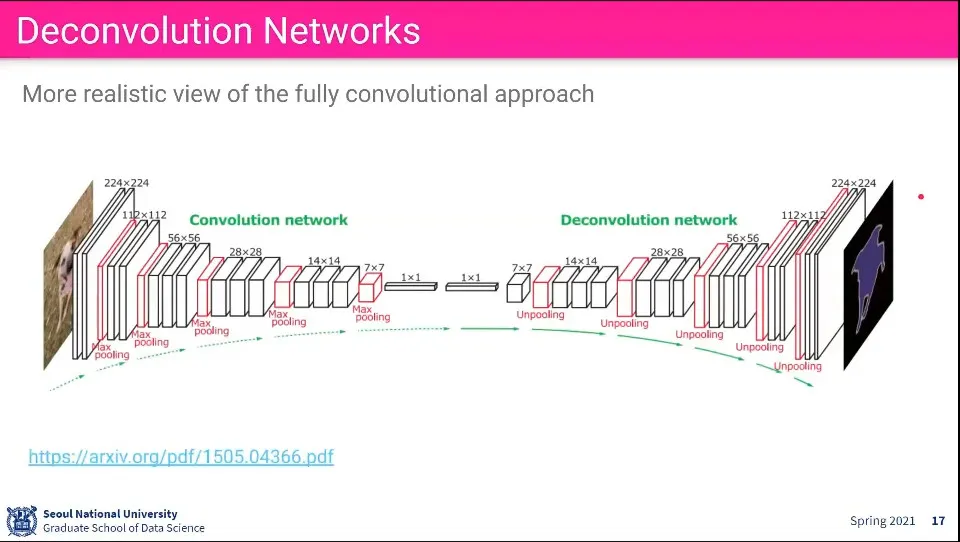
Deconvolution이 적용된 Network
◦
Convolution으로 이미지를 줄여서 1x1까지 만든 후에
◦
그걸 다시 Decovolution해서 원래 크기만큼 키운다.
•
Convolution 단계에서 Max Pooling을 Deconvolution 단계에서는 Unpooling을 한다.

•
Semantic Segmentation의 활용 예

•
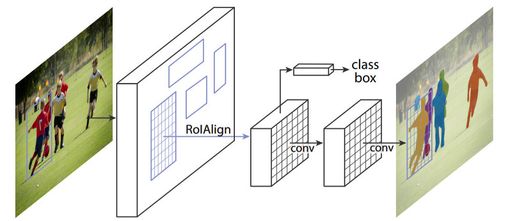
Instance Segmentation은 Object Detection과 Segmentation을 합친 것
•
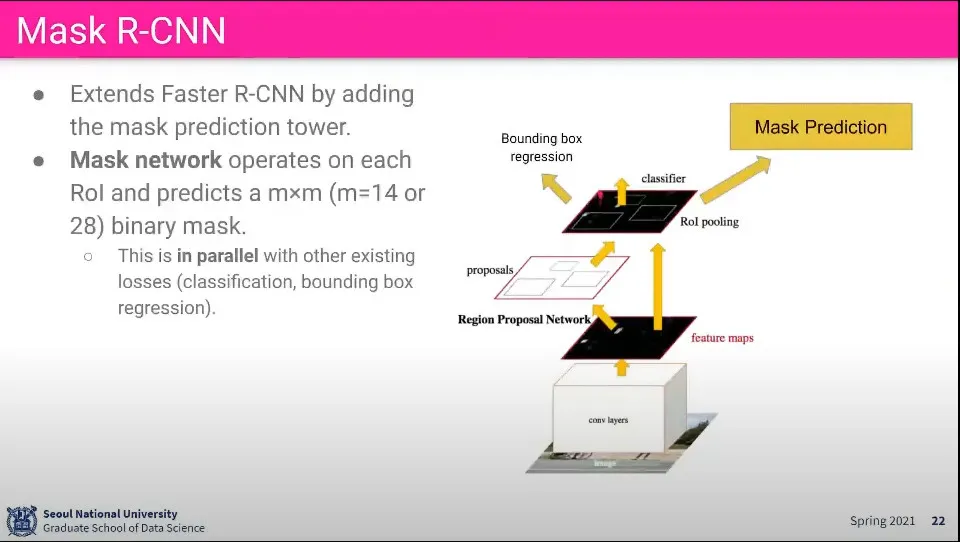
여기서 사용되는게 Mask R-CNN

•
Mask R-CNN에서는 ROI Align을 수행한다.
◦
ROI Pooling은 크기가 제각각인 이미지를 같은 크기로 Pooling하기 위해 우겨 넣는 일이 발생하게 되는데, ROI Align은 그것을 좀 더 완만하게 해주는 것. 보간을 이용해서 pooling 한다.
◦
ROI Pooling은 분류 문제였기 때문에 별 문제가 없었지만 Mask R-CNN에서는 Pixcel 단위로 이 Pixcel이 사람이냐 코끼리냐를 구분해야 하기 때문에 그냥 Pooling 하면 안 된다. 그러면 정보를 잃게 됨.
◦
추가로 Convolution으로 공간 정보를 하나도 잃지 않고 가져와야 함.
◦
Pooling할 때 Pixcel의 공간 정보를 이용해서 가장 스무스하게 보간하는 방법을 찾는다.
•
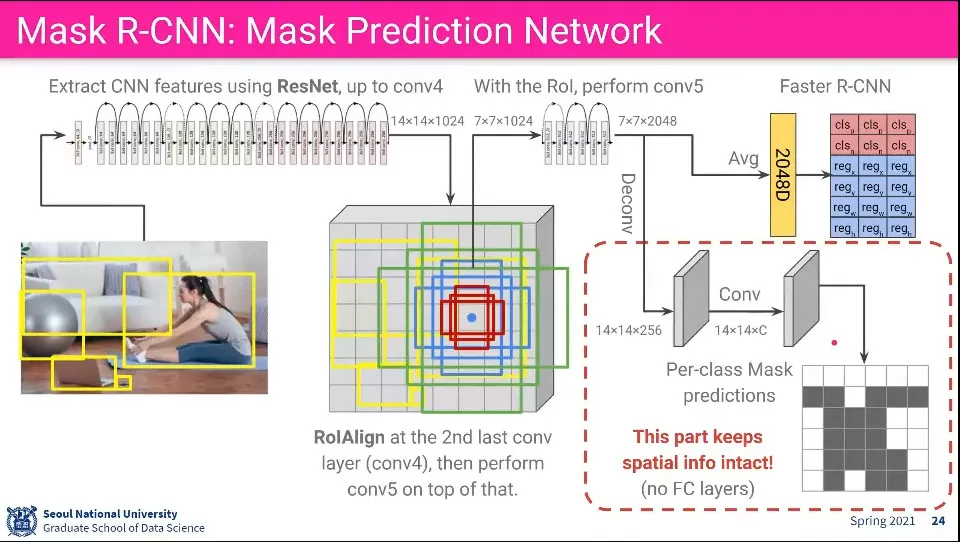
Faster R-CNN과 달리 ResNet을 사용함.
1.
ResNet에서 conv4까지 돌려서 14x14x1024를 얻음
2.
Pooling 하지 않고 ROI Align을 수행(보간)해서 7x7x1024를 뽑아냄
3.
그 후에 ResNet의 conv5를 돌려서 7x7x2048을 얻어냄
4.
그 결과를 평균내서 2048 1차원 벡터를 얻어서 이후는 Faster R-CNN의 과정을 수행함
5.
7x7x2048에 대해 Deconv를 시켜서 14x14x256을 얻어냄
6.
그 다음 다시 Conv 시켜 같은 사이즈를 얻고 마지막에 Per-class Mask Predictions을 얻어냄
•
5, 6 단계에서는 공간 정보를 잃어버리면 안되기 때문에 무조건 Deconv나 Conv만 써야 함

•
Loss 함수의 앞부분은 Faster R-CNN과 동일
•
그 뒤에 Pixcel 레벨 Mask에 대한 Loss 함수가 추가 됨
◦
결과적으로 Pixcel 단위로 classification을 수행하게 됨.
◦
근데 이걸 전체 이미지에 대해 수행하면 너무 오래 걸리므로 detection이 된 object에 대해서만 함

•
결과 예제
◦
전체 이미지에 대해서 하는 것은 아니고 Detection이 된 box에 대해서만 수행함

•
Segmentation에 대한 TensorFlow와 PyTorch 라이브러리