
•
비디오 예측

•
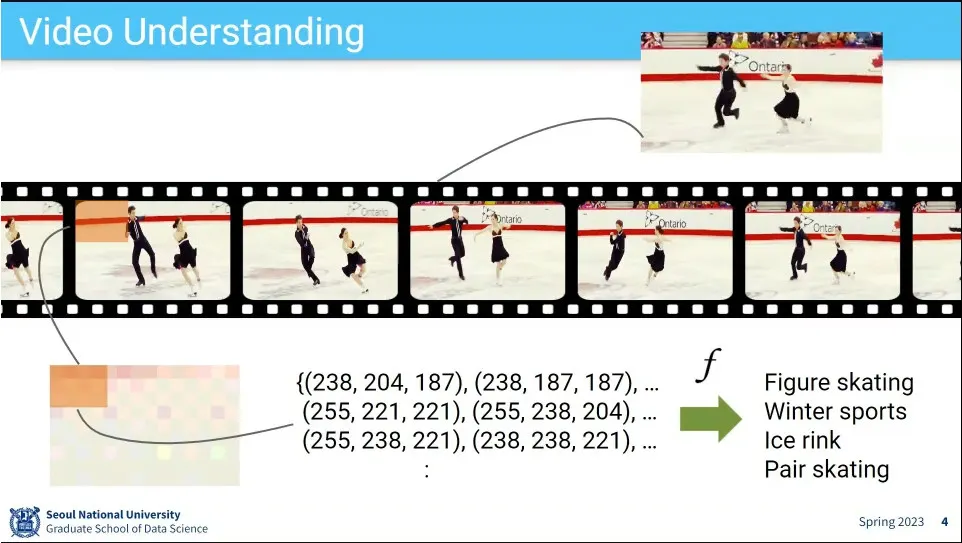
비디오는 주로 action에 초점을 맞춤. 그걸 하려면 당연히 object 인식도 해야 함.
•
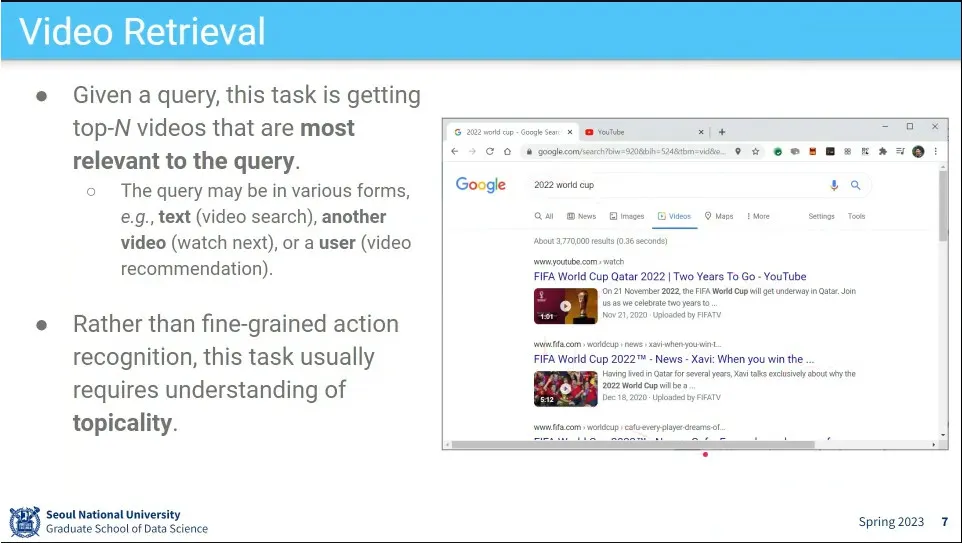
응용 예는 비디오 검색
•
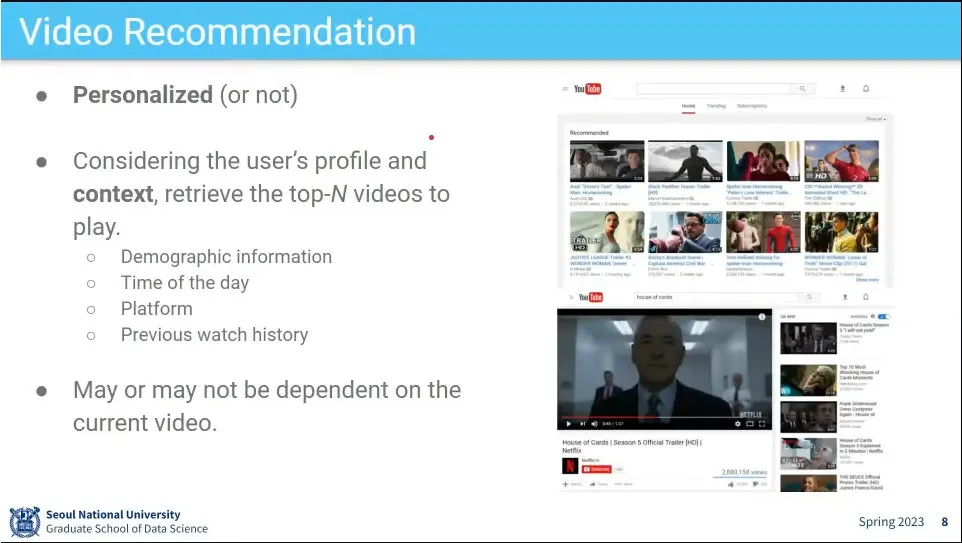
또 다른 예는 비디오 추천
•
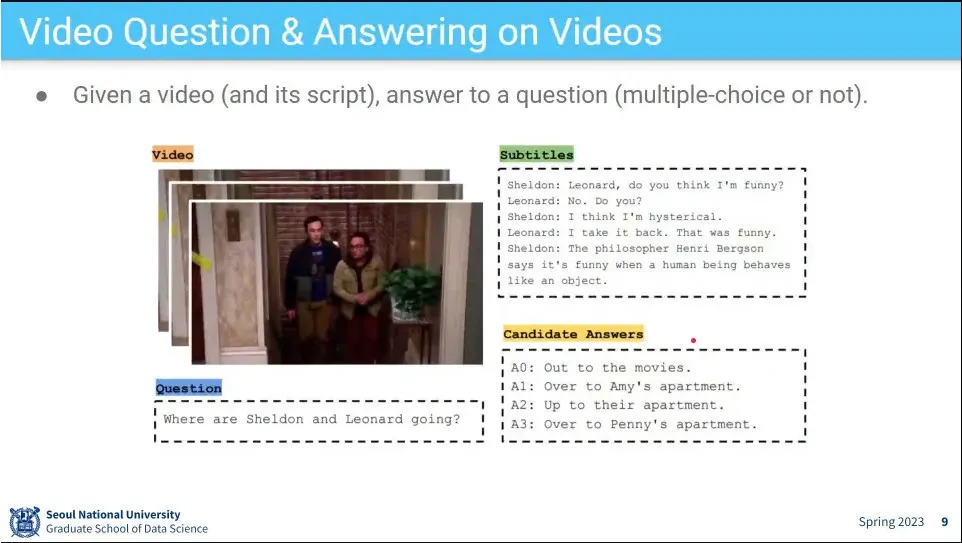
Video와 option으로 script가 주어지고 (아니면 음성 인식으로 script를 구성) 영상에 대해 질문을 하면 답을 줌
◦
질문에 따라 내용을 봐야 할 수도 있고, 장면을 봐야 할 수도 있음.
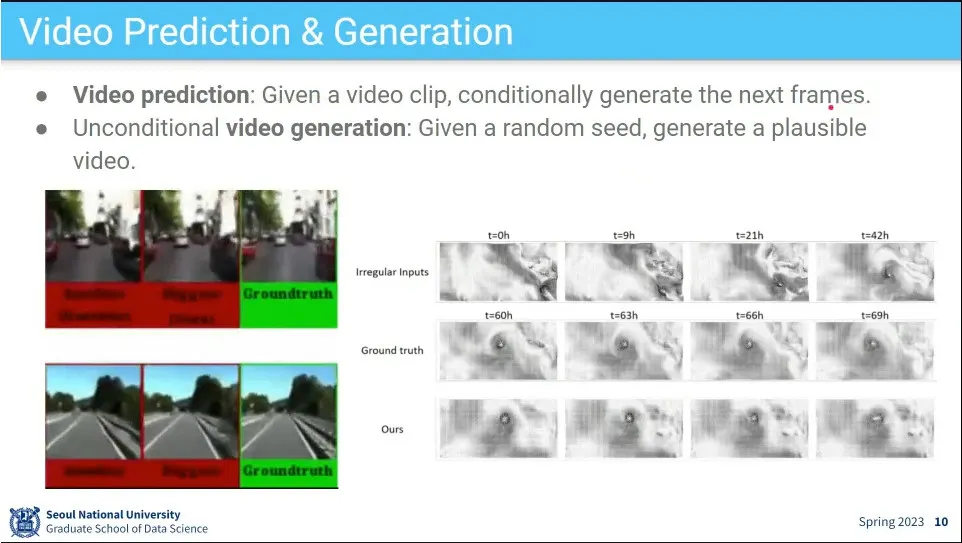
•
Video 생성하는 task

•
Video 압축 task
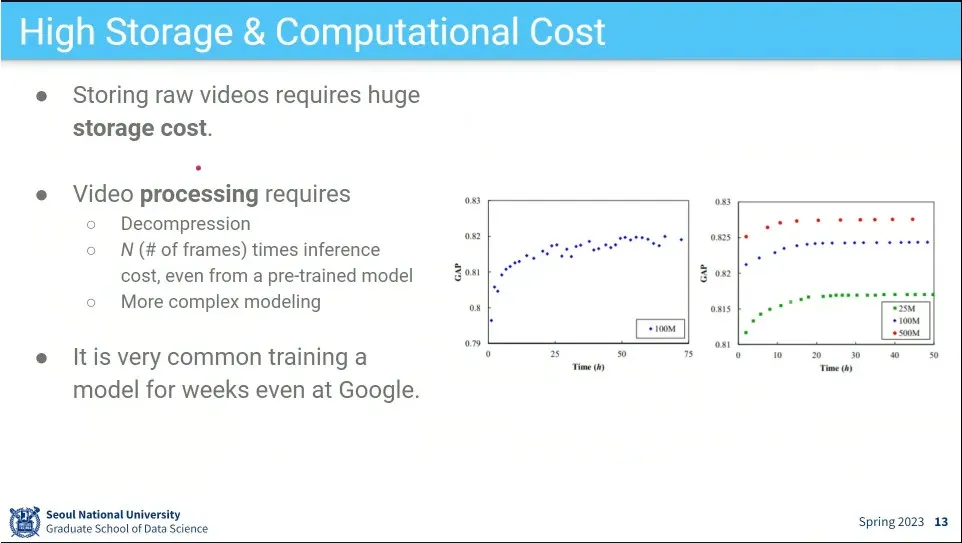
•
Video 문제의 어려운 점. 데이터가 크고 계산량이 많음.
◦
(video를 할 수 있다는 것은 사실상 인간이 세상을 이해하는 것을 할 수 있다는 것이라고 볼 수 있음. 연속된 이미지 + 음성 + 객체 인식 + 상황 인식이 다 포함되어 있기 때문. 결국 자율주행은 결국 video 인식 문제가 기본)

•
Video는 라벨링 코스트가 큼. 그래서 scale을 키우기가 어려움.

•
시간 dimesion이 추가된 것, 영상의 앞과 뒤에 context가 달라지는 것 등 복잡한 요인들이 많음.
◦
fps가 다른 것도 video 마다 차이가 있음.
•
video 연구는 근본적으로 인간의 시청각 능력을 모사하는 것.
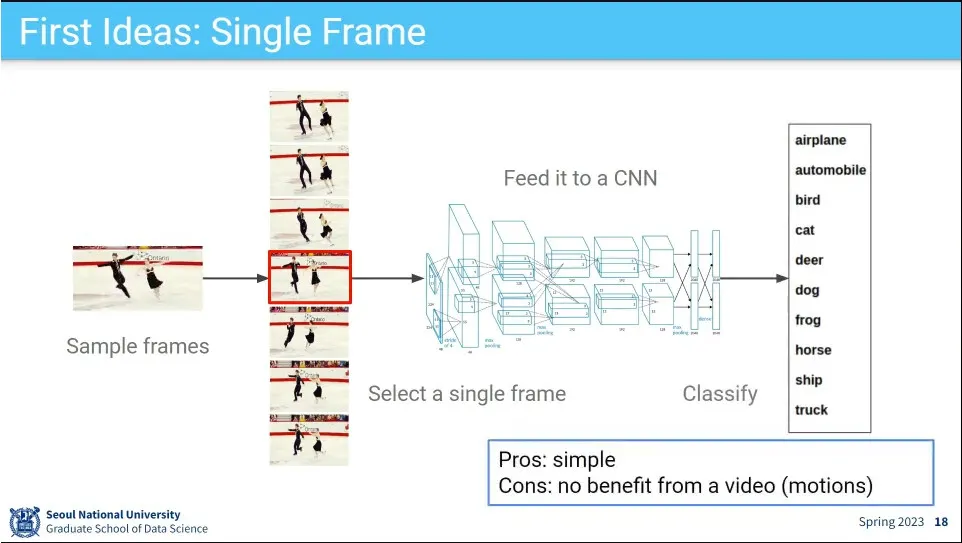
•
처음에는 video 중에서 한 장 가져와서 분류를 했음.
◦
이러면 motion에 대한 정보가 없음

•
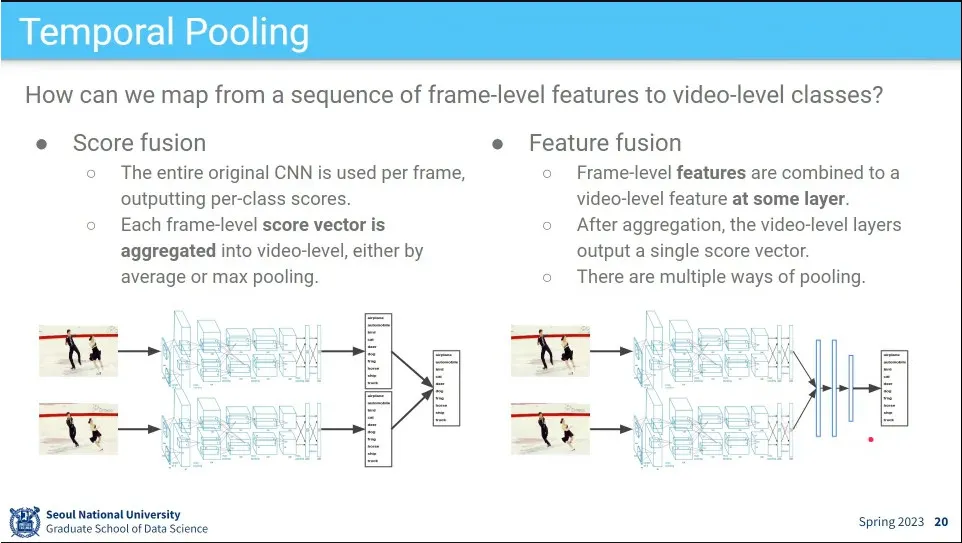
그래서 아예 여러 장을 뽑아서 분류를 시도
•
최종 score를 합쳐서 처리하는 방법이 있고, feature 수준에서 합쳐서 처리하는 방법이 있음.

•
합치는 몇 가지 방법들 - max, average, concatenate. concatenate를 세로로 쌓는 방법 등.

•
feature를 어디 합칠 것인가?
◦
late fusion은 개별 프레임의 결과를 가장 마지막에 합침. 이러면 frame 고유의 정보가 남아 있음.
◦
early fusion은 처음에 여러 프레임을 아에 하나로 합치고 그 이후에 한 장의 이미지처럼 처리 함.

•
그 외에 여러 방법들이 가능함. 중간에 하든가 slow fusion도 있음.
•
video 인식의 흐름

•
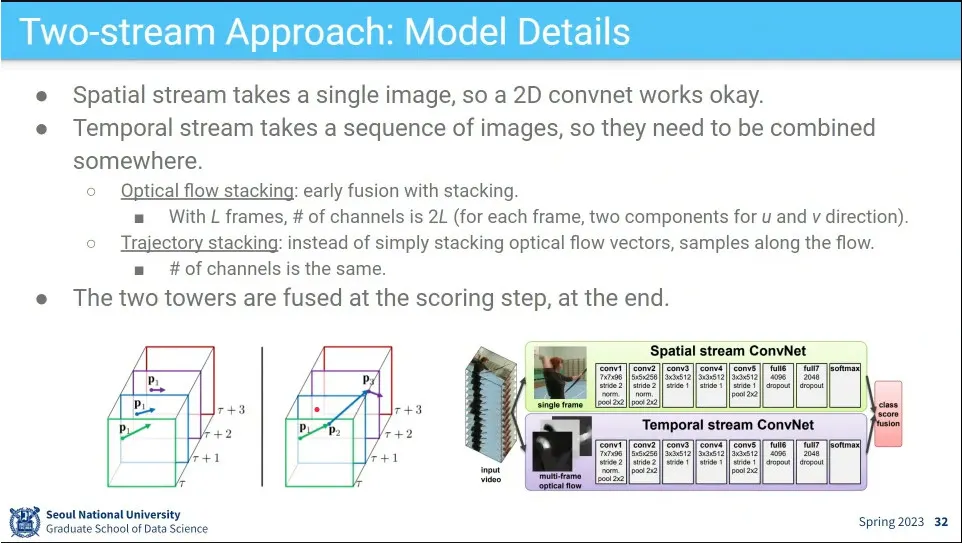
Two-stream 접근 방식은 공간에 대한 conv net과 시간에 대한 conv net을 따로 돌려서 합치는 방식
◦
공간 정보는 한 장의 이미지에서 배우고, 시간적인 정보는 optical flow를 통해 배움
•
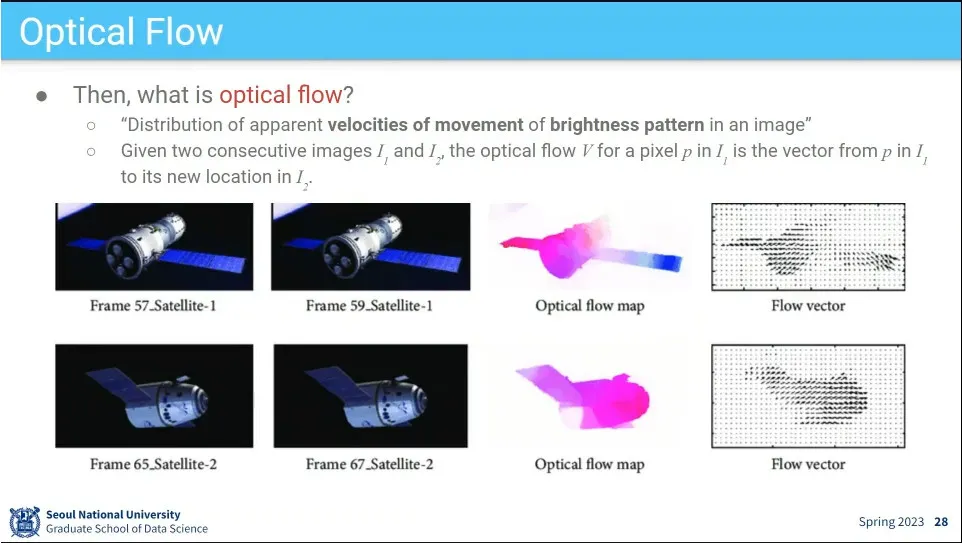
이미지 상의 픽셀들이 어디로 가는지를 나타내는 벡터장을 optical flow라고 함.

•
optical flow의 예
◦
horizontal 방향, vertical 방향으로 얼마나 움직이는지, 움직임이 얼마나 있는지를 표시

•
Optical flow를 위한 몇 가지 가정.
◦
픽셀이 다음 프레임에서도 비슷한 brightness를 가질 것이다.
◦
픽셀이 다음 프레임에서 근처 어디에 있을 것이다.
◦
가까이 이는 pixel은 같은 오브젝트일 것이다.
•
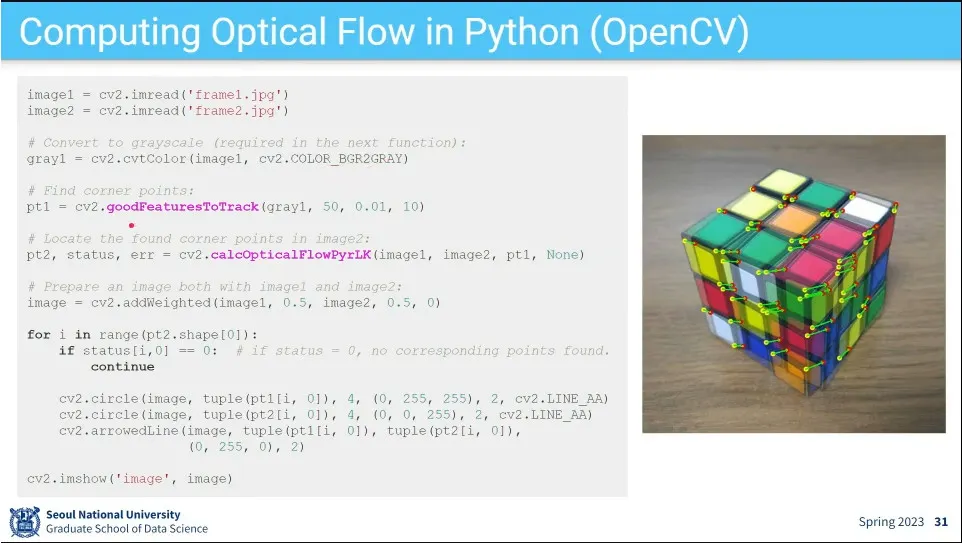
Lukas-Kanade 알고리즘
•
opencv에서 구현한 예
◦
모든 pixel에 대해 연산하기 어렵기 때문에 우선 특징점을 잡아서 그 점들이 어떻게 움직이는지를 본다.
•
이렇게 미리 계산한 optical flow를 Temporal stream에 input으로 넣어준다.
•
temporal stream에서는 전체 프레임의 정보를 stacking해서 한장의 이미지처럼 처리함.
•
그렇게 공간적, 시간적 2장의 이미지를 합쳐서 처리 함.

•
위 방식으로는 비디오가 길어지면 제대로 처리 못 함.
◦
멀리 뛰기인데, 달리는 부분 이미지만 가져오면 달리기라고 인식 함.
◦
영상이 길어지면 optical flow를 계산해서 저장하는데 큰 비용이 발생 함
•
optical flow를 쓰므로 end-to-end 학습이 안 됨
•
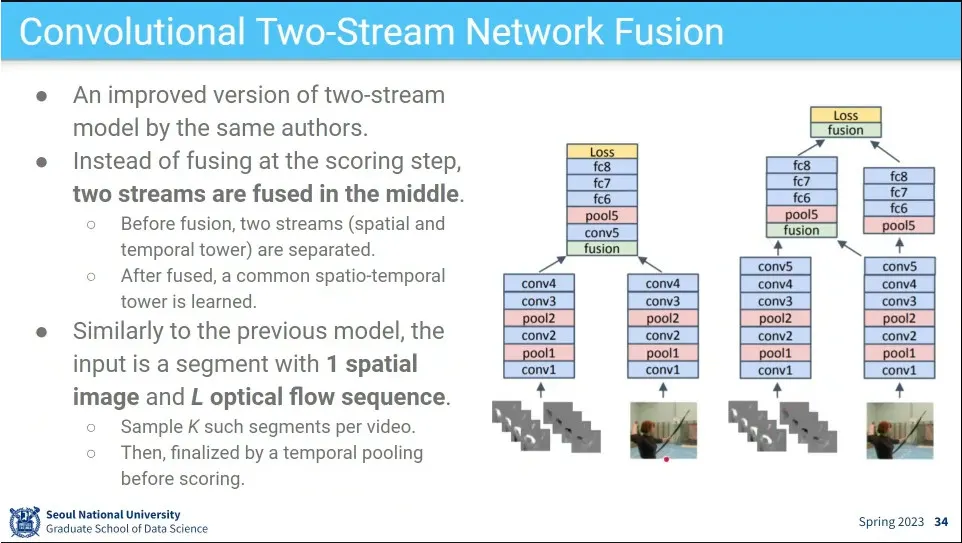
저자들이 후속 논문에서 이미지를 합치는 다른 방법들을 시도 해 봄.
◦
마지막에 합치지 않고, 중간에 합치거나, 중갑에 합치고 공간정보를 남겼다가 다시 합치거나 등

•
중간에 합치려면 이미지 크기가 같아야 하기 때문에 같은 크기를 유지해야 한다. 그래서 같은 위치의 pixel들이 같은 것을 보도록.
◦
pixel-wise corresponding을 유지하는게 중요하다.
◦
high-level layer들의 feature를 공유해서 파라미터 수를 줄여서 효율적으로 할 수 있었다.

•
2개의 타워를 합칠 때 언제 합치는거에 대한 실험.
◦
끝에서 합치나 앞에서 합치나 별 차이 없더라. 대신 앞에서 합치면 모델 파라미터를 아낄 수 있어서 더 효율적이다.
◦
conv layer는 나중에 합치는게 좋더라.

•
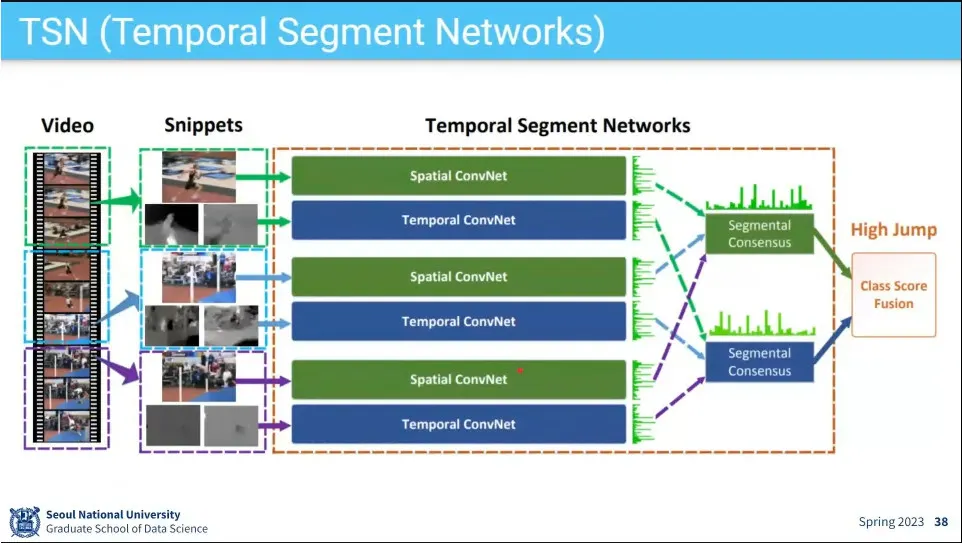
TSN은 Two-stream 모델에서 input을 k 장을 뽑는 등 여러 가지 개선을 함.
•
video를 여러 segment로 쪼갠 후에 그 안에서 1장을 뽑고, optical flow를 계산해서 two-stream 모델을 돌림

•
optical flow를 미리 계산해서 저장해 두었다가 쓰기 때문에 용량을 많이 잡아 먹기 때문에 그걸 개선한 버전.
◦
spatial은 two-stream을 그대로 쓰고, temporal 부분에 optical flow를 만들어주는 MotionNet을 이용함.
•
Motion Net은 optical flow 계산을 한 것을 이용해서 모델을 학습 시켜서 만듦.
