
Abstract
우리는 unsupervised visual representation leanring을 위해 Momentum Contrast(MoCo)를 제안한다. contrastive learning를 dictionary look-up의 관점으로 보며, 우리는 queue와 moving-averaged encoder를 갖는 dynamic dictionary를 구축한다. 이를 통해 contrastive unsupervised learning을 용이하게 하는 크고 일관된 dictionary를 on-the-fly(즉석에서) 구축할 수 있다. MoCo는 ImageNet 분류에서 일반적인 선형 프로토콜 하에 경쟁력있는 결과를 제공한다. 더 중요한 것은 MoCo로 학습된 representation이 downstream task에 잘 전이 된다는 것이다. MoCo는 PASCAL VOC, COCO와 기 타 다른 데이터셋에서 7가지 detection/segmentation 작업에서 대응하는 supervised pre-training를 능가하며 때때로 매우 큰 격차로 앞선다. 이것은 많은 vision 작업에서 unsupervised와 supervised representation learning 사이의 간격이 매우 줄어들었음을 시사한다.
1. Introduction
unsupervised representation learning은 GPT와 BERT가 보여준 것과 같이 NLP에서 매우 성공적이었다. 그러나 computer vision에서는 여전히 supervised pre-training이 주도적이며 unsupervised 방법은 일반적으로 뒤쳐져 있다. 이유는 각 분야의 신호 공간의 차이에서 비롯될 수 있다. 언어 작업은 unsupervised learning이 기반이 될 수 있는 토큰화된 사전을 구축하기 위해 이산 신호 공간(word, sub-word units 등)을 갖는다. 대조적으로 computer vision에서 raw 신호가 연속적이고, 고차원 공간에 있으며 인간의 커뮤니케이션을 위해 구조화되어 있지 않기 때문에(예: 단어와 달리) dictionary 구축에 더 많은 관심을 기울인다.
몇몇 최근 연구는 contrastive loss에 연관된 접근을 사용하여, unsupervised visual representation learning에 대해 유망한 결과를 제시했다. 다양한 동기에 의해 추진되었지만, 이러한 방법들은 dynamic dictionaries를 구축하는 것으로 생각할 수 있다. dictionary에서 ‘keys’(토큰)은 데이터(이미지 또는 패치)에서 샘플링되고 인코더 네트워크에 의해 representation 된다. unsupervised learning은 인코더가 dictionary look-up을 수행한도록 학습한다. 인코딩된 ‘query’는 matching key와 유사해야 하고 다른 것과는 비유사해야 한다. 학습은 contrastive loss를 최소화하여 형식화된다.
이 관점에서 우리는 (i) 크고 (ii) 학습하는 동안 진화하면서 일관성을 유지하는 dictionary를 구축하는 것이 바람직하다고 가정한다. 직관적으로 더 큰 dictionary는 기저의 연속적이고 고차원적인 시각 공간을 더 잘 샘플링을 할 수 있으며, dictionary에서 key들은 쿼리와의 비교가 일관되도록 동일하거나 유사한 인코더에 의해 표현되어야 한다. 그러나 contrastive loss를 사용하는 기존의 방법은 이 2가지 측면 중 하나에서 제한될 수 있다.(이후에 논의됨)
우리는 contrastive loss을 사용한 unsupervised learning을 위해 크고 일관성 있는 dictionary를 구축하는 방법으로 Momentum Contrast(MoCo)를 제안한다(그림 1). 우리는 dictionary를 데이터 샘플의 queue로 유지한다. 현재 미니 배치의 인코딩된 representation이 enqueue되고, 가장 오래된 것은 dequeue된다. 이 queue는 dictionary 크기를 미니배치 크기에서 분리하여 dictionary가 크게 유지될 수 있게 한다. 게다가 dictionary key가 이전 몇 개의 미니 배치에서 오기 때문에, 쿼리 인코더의 momentum-based moving average을 구현된 천천히 진행되는 key 인코더가 일관성을 유지하기 위해 제안된다.
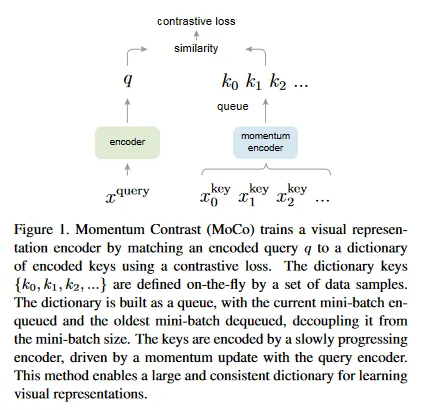
MoCo는 contrastive learning을 위한 dynamic dictionary를 구축하기 위한 메커니즘이고, 다양한 pretext 작업과 함께 사용될 수 있다. 이 논문에서 우리는 간단한 인스턴스 판별 작업을 따른다. 쿼리는 동일한 이미지의 인코딩된 뷰(예: 서로 다른 crop)일 경우 키와 일치한다. 이 pretext 작업을 사용하여 MoCo는 ImageNet 데이터셋에서 선형 분류의 일반적인 프로토콜 하에 경쟁력 있는 결과를 보인다.
unsupervised learning의 주요 목적은 fine-tuning을 통해 downstream 작업으로 전이될 수 있는 representation(즉 feature)을 pre-train하는 것이다. 우리는 detection이나 segmentation과 관련된 7가지 downstream 작업에서 MoCo unsupervised pre-training이 ImageNet supervised 대응을 능가할 수 있음을 보인다. 일부 경우에 상당한 차이로 앞선다.
이 실험에서 우리는 ImageNet 또는 one-billion Instragram 이미지 셋에서 pre-trained MoCo를 탐구하여, MoCo가 더 현실적이고, 수십 억 이미지 규모의, 상대적으로 덜 정제된 시나리오에서도 잘 작동할 수 있음을 시연한다. 이러한 결과는 MoCo가 많은 computer vision 작업에서 unsupervised와 supervised representation learning 사이의 간격을 크게 줄이고, 여러 응용에서 ImageNet supervised pre-training에 대한 대안을 제공할 수 있음을 시연한다.
2. Related Work
Unsupervised/self-supervised 학습 방법은 일반적으로 2가지 관점을 포함한다. pretext 작업과 loss 함수가 그것이다. ‘pretext’라는 용어는 작업을 해결하는 것이 진정한 관심이 아니라, 오직 좋은 데이터 표현을 학습하기 위한 진정한 목적으로만 해결된다는 것을 암시한다. loss 함수는 종종 pretext 작업의 독립적으로 연구될 수 있다. MoCo는 loss 함수 측면에 초점을 맞춘다. 다음으로 우리는 이 2가지 측면과 관련된 연구를 논의한다.
Loss functions
loss 함수를 정의하는 일반적인 방법은 모델의 예측과 고정된 타겟 사이의 차이를 측정하는 것이다. 예를 들어 또는 loss을 사용하여 입력 픽셀을 재구성하거나(예: auto-encoder) cross-entropy나 margin-based loss를 사용하여 입력을 pre-defined 카테고리(예: eight position, color bins)로 분류하는 것이다. 다음에 설명할 다른 대안 또한 가능하다.
Contrastive loss는 representation 공간에서 샘플 쌍의 유사성을 측정한다. 입력을 고정된 타겟에 매칭하는 것 대신, contrastive loss 공식에서는 타겟이 학습하는 동안 실시간으로 변할 수 있고 네트워크에 의해 계산된 데이터 representation의 측면에 의해 정의될 수 있다. contrastive learning은 최근 unsupervised learning에서 여러 연구의 핵심이며 이후에 자세히 설명한다(섹션 3.1)
Adversarial loss는 확률 분포 사이의 차이를 측정한다. 이것은 unsupervised 데이터 생성에 대해 광범위하게 성공적인 기법이다. representation learning을 위한 adversarial 방법은 [15, 16]에서 탐구되었다. generative adversarial network(GAN)과 noise-contrastive estimation(NCE) 사이의 관계가 존재한다.
Pretext tasks
광범위한 pretext 작업이 제안되었다. 예컨대, 어떤 오염된(corruption) 입력을 복구하는 작업들이 포함된다. 예: denoising auto-encoder, context auto-encoder, cross-channel auto-encoder(colorization). 일부 pretext 작업은 pseudo-label을 형성한다. 예: 단일 (exemplar) 이미지의 변환, patch ordering, 또는 비디오에서 tracking 또는 object segmenting, feature 클러스터링 등이 있다.
Contrastive learning vs. pretext tasks
다양한 pretext 작업이 어떤 형식의 contrastive loss 함수를 기반으로 할 수 있다. instance 판별 방법은 exemplar-based task와 NCE와 연관된다. contrastive predictive coding(CPC)의 pretext 작업은 context auto-encoding의 한 형태이며, contrastive multiview coding(CMC)은 색상화와 연관된다.
3. Method
3.1. Contrastive Learning as Dictionary Look-up
Contrastive learning과 이것의 최근 발전은 dictionary look-up task을 위한 인코더를 학습하는 것으로 생각할 수 있다. 이는 다음과 같이 설명된다.
인코딩된 query 와 dictionary의 key에 해당하는 인코딩된 샘플의 집합 을 고려하자. dictionary에 와 일치하는 단일 key(로 표기되는)가 있다고 가정하자. contrastive loss는 가 positive key 와 유사하고 다른 모든 key(에 대해 negative key로 고려한다)와 비유사할 때 값이 낮아지는 함수이다. 유사도를 dot product로 측정할 때, 이 논문에서는 InfoNCE라 부르는 형식의 contrastive loss 함수를 고려한다.
여기서 는 온도 하이퍼파라미터이다. 하나의 positive와 개 negative 샘플에 대해 합산한다. 직관적으로 이 loss는 를 로 분류하려는 -way softmax-based 분류기의 log loss이다. contrastive loss 함수는 margin-based loss와 NCE loss의 변종과 같은 다른 형식에 기반할 수도 있다.
contrastive loss는 쿼리와 키를 나타내는 인코더 네트워크를 학습하기 위한 unsupervised 목적 함수 역할을 한다. 일반적으로 쿼리는 로 표현되고, 여기서 는 인코더 네트워크이고, 는 쿼리 샘플이다(유사하게 ). 그들의 구체적 형태는 특정한 pretext 작업에 기반한다. 입력 와 는 이미지, 패치 또는 일련의 패치로 구성된 컨텍스트일 수도 있다. 네트워크 와 는 동등할 수 있고 부분적으로 공유되거나 서로 다를 수 있다.
3.2. Momentum Contrast
위의 관점에서 볼 때, contrastive learning은 이미지 같은 고차원 연속 입력에 대해 이산 dictionary를 구축하는 방법이다. 이 dictionary는 key가 랜덤으로 샘플되고 키 인코더가 학습하는 동안 진화한다는 맥락에서 dynamic 이다. 우리의 가설은 dictionary key가 진화함에도 불구하고, 가능한 일관성을 유지하면서, 풍부한 negative 샘플 집합을 포함하는 큰 dictionary을 통해 좋은 feature를 학습할 수 있다는 것이다. 이러한 동기에 기반하여 우리는 다음에 설명할 Momentum Contrast를 제시한다.
Dictionary as a queue
우리 접근의 핵심은 dictionary를 데이터 샘플의 queue로 유지하는 것이다. 이를 통해 직전 미니배치들의 인코딩된 key를 재사용하는 것이 가능하다. queue의 도입은 dictionary 크기를 미니배치 크기와 분리시킨다. 우리의 dictionary 크기는 일반적인 미니배치 크기보다 훨씬 커질 수 있고, 하이퍼파라미터로 유연하고 독립적으로 설정할 수 있다.
dictionary의 샘플은 점진적으로 교체된다. 현재 미니배치는 dictionary에 enqueue되고 queue에서 가장 오래된 미니배치는 제거된다. dictionary는 항상 모든 데이터의 샘플링된 부분집합을 나타내며, 이 dictionary를 유지하는데 필요한 추가 계산은 관리 가능하다. 또한 가장 오래된 미니배치를 제거하는 것은 이득일 수 있다. 왜냐하면 이것의 인코딩된 키들이 가장 오래되어 최신 것과 일관성이 떨어지기 때문이다.
Momentum update
queue를 사용하면 dictionary를 크게 만들 수 있지만 key 인코더를 back-propagation으로 업데이트하는데 까다로울 수 있다(gradient가 queue의 모든 샘플들에 전파되어야 한다). 순진한 솔루션은 gradient를 무시하고 key 인코더 를 쿼리 인코더 에서 복사하는 것이다. 그러나 이 솔루션은 실험에서 빈곤한 결과를 산출한다(섹션 4.1). 우리는 이런 실패가 key 표현의 일관성을 줄이는 빠르게 변화하는 인코더 때문이라고 가정한다. 우리는 이 이슈를 해결하기 위해 momentum 업데이트를 제아한다.
형식적으로 의 파라미터를 로 의 파라미터를 로 표기한다. 우리는 다음을 이용하여 를 업데이트한다.
여기서 은 momentum 계수이다. 오직 파라미터 만 역전파에 의해 업데이트된다. 방정식 2에서 momentum 업데이트는 를 보다 더 완만하게 진화하도록 만든다. 결과적으로 queue에서 key들이 서로 다른 인코더(서로 다른 미니배치에서)에 의해 인코딩됨에도, 이러한 인코더들 사이의 차이를 작게 만들 수 있다. 실험에서 상대적으로 큰 momentum(예: , 우리의 기본값)은 더 작은 값(예: ) 보다 훨씬 잘 작동했는데, 이는 느리게 진화하는 key 인코더가 queue를 활용하는데 핵심이라는 것을 시사한다.
Relations to previous mechanisms
MoCo는 contrastive loss를 사용하기 위한 일반적인 메커니즘이다. 우리는 이것을 그림 2에서 기존의 2가지 일반적인 메커니즘과 비교한다. 그들은 dictionary 크기와 일관성에 대해 서로 다른 속성을 보인다.
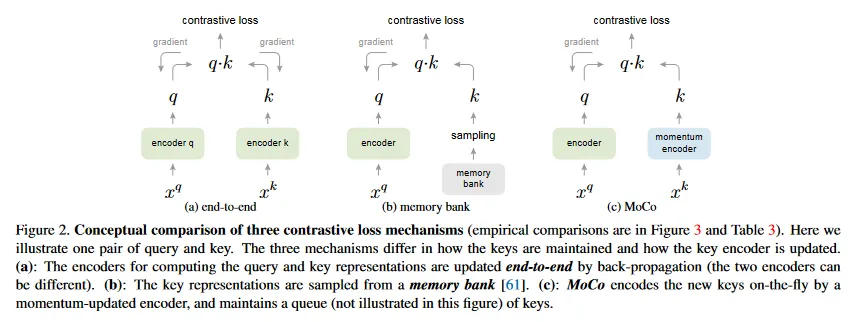
역전파에 의한 end-to-end 업데이트는 자연스러운 메커니즘이다(그림 2a). 이것은 현재 미니배치의 샘플들을 dictionary로 사용하므로 key가 일관되게 인코딩된다(동일한 인코더 파라미터 집합에 의해). 그러나 dictionary 크기가 미니배치 크기에 연결되고 GPU 메모리 크기에 의해 제한된다. 또한 대규모 미니배치 최적화에 도전적이다. 일부 최근 방법들은 local position에 의해 유도된 pretext 작업에 기반한다. 여기서 dictionary 크기는 multiple position에 의해 더 커질 수 있다. 그러나 이 pretext 작업들은 입력을 patch화 하거나 receptive field 크기를 커스터마이징하는 것과 같은 특정한 네트워크 설계를 요구하며 이것은 네트워크를 downstream 작업으로 전이하는 것을 복잡하게 만들 수 있다.
또 다른 메커니즘은 [61]에 의해 제안된 memory bank 접근이다(그림 2b). memory bank는 데이터셋의 모든 샘플의 representation으로 구성된다. 각 미니배치의 dictionary는 역전파 없이 memory bank에서 무작위로 샘플링되므로 큰 dictionary 크기를 지원할 수 있다. 그러나 memory bank의 샘플 representation은 마지막으로 본 시점에 업데이트되었으므로, 샘플링된 key는 본질적으로 과거 epoch 전체에 걸친 여러 서로 다른 단계의 인코더에 관한 것이며 따라서 덜 일관성 있다. [61]에서 memory bank에 momentum 업데이트를 채택했다. 이 momentum 업데이트는 동일한 샘플의 representation에 대한 것이고 인코더에 대한 것이 아니다. 이 momentum 업데이트는 우리의 방법과 무관하다. MoCo는 매 샘플을 추적하지 않기 때문이다. 게다가 우리의 방법은 더 메모리 효율적이고 수십 억 스케일 데이터에 대해 학습될 수 있다. 이것은 memory bank에서 까다로울 수 있다.
이 3가지 메커니즘을 비교하는 실험은 섹션 4 참조.
3.3. Pretext Task
contrastive learning은 다양한 pretext 작업을 추진할 수 있다. 이 논문의 초점은 새로운 pretext 작업을 설계하는 것이 아니므로 우리는 주로 [61]의 instance discrimination 작업을 따르는 간단한 작업을 사용한다. 이것은 일부 최근 작업과도 연관된다.
[61]을 따라 우리는 query와 key가 동일한 이미지에 기원하면 positive 쌍으로, 그렇지 않으면 negative 쌍으로 고려한다. [63, 2]을 따라 우리는 무작위 데이터 증강 하에 동일한 이미지의 2가지 무작위 ‘관점’을 취하여 positive 쌍을 형성한다. query와 key는 각각 그들의 인코더 와 에 의해 인코딩된다. 인코더는 임의의 convolutional neural network일 수 있다.
Algorithm 1은 이 pretext 작업에 대한 MoCo의 pseudo-code를 제공한다. 현재 미니배치에 대해 우리는 query와 그에 해당하는 key를 인코딩하고 이것은 positive 샘플 쌍을 형성한다. negative 샘플은 queue에서 가져온다.
Alogorithm 1. Pseudocode of MoCo in a PyTorch-like style
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
Python
복사
Technical details
우리는 인코더로 ResNet을 채택한다. 이것은 마지막 fully-connected layer(global average pooling 이후에)가 고정된 차원 출력(128-D)을 갖는다. 이 출력 벡터는 L2-norm에 의해 normalized 된다. 이것은 query 또는 key의 representation이다. 방정식 1에서 온도 는 로 설정된다. 데이터 증강 설정은 [61]을 따른다. 무작위로 resized 이미지에서 224x224 픽셀 crop이 취해지고, 무작위 color jitering, random horizontal filp과 무작위 grayscale conversion을 거친다. 모든 것은 PyTorch의 torchvision 패키지를 통해 가능하다.
Shuffling BN
우리의 인코더 와 모두 표준 ResNet에서와 같이 Batch Normalization(BN)을 갖는다. 실험에서 우리는 BN을 사용하는 것이 좋은 representation을 학습하는데 방해한다는 것을 발견했다. 유사한 리포트가 [35]에서도 있었다(이것은 BN을 사용을 피함). 모델이 pretext 작업을 ‘cheat’ 하고 쉽게 낮은 loss 해를 찾는 것으로 보인다. 이것은 아마도 샘플 사이의 intra-batch 커뮤니케이션(BN에 의해 발생)이 정보를 누출시키기 때문일 것이다.
우리는 shuffling BN을 사용하여 이 문제를 해결했다. 우리는 여러 GPU를 사용하여 학습하고 각 GPU에 대해 독립적으로 샘플에 BN을 수행한다(일반적인 관행처럼). key 인코더 에 대해 우리는 현재 미니배치에서 샘플 순서를 GPUs 사이에 분배하기 전에 shuffle 한다(그리고 인코딩 후에 다시 원래대로 shuffle 한다). 쿼리 인코더 에 대한 미니배치의 샘플 순서는 바꾸지 않는다. 이것은 query와 그것의 positive key를 계산하는데 사용되는 배치 통계량이 두 개의 서로 다른 부분집합에서 온다는 것을 보장한다. 이것은 효율적으로 cheating 이슈를 다루고 학습이 BN에서 이점을 얻게 한다.
우리의 방법과 end-to-end ablation 대응물 모두에서 shuffled BN을 사용한다. 이것은 memory bank 대응물과는 무관하다. 이것은 positive 키가 과거의 서로 다른 미니배치에서 오기 때문에 이러한 이슈에 시달리지 않는다.
4. Experiments
우리는 다음에서 수행되는 unsupervised 학습을 연구한다.
ImageNet-1M (IN-1M)
이것은 1000개 클래스에서 약 1.28million 이미지가 있는 ImageNet 학습셋이다(종종 ImageNet-1K라 불리지만 unsupervised learning에서는 클래스를 활용하지 않으므로 이미지수를 센다). 이 데이터셋은 잘 균형잡힙 클래스 분포이며, 이미지는 일반적으로 객체의 iconic view를 포함한다.
Instagram-1B (IG-1B)
[44]을 따라 이것은 인스타그램에서 공개된 약 1billion(940M) 이미지의 데이터셋이다. 이미지는 ImageNet 카테고리와 연관되는 약 1500 hashtags에서 온다. 이 데이터셋은 IN-1M과 비교하여 상대적으로 큐레이팅 되지 않고, 현실 세계의 long-tailed, unbalanced 분포를 갖는다. 이 데이터셋은 iconic object와 scene-level 이미지를 포함한다.
Training.
우리는 SGD를 optimizer로 사용한다. SGD weight decay는 0.0001이고 SGD momentum은 0.9이다. IN-1M에 대해 우리는 8대 GPU에서 256 크기의 미니배치(알고리즘 1의 N)를 사용하고 초기 learning rate 는 0.03이다. 우리는 200 epoch으로 학습하며 120과 160 epoch에서 learning rate을 0.1씩 곱한다. ResNet-50을 학습하는데 약 53시간이 걸린다. 1G-1B에 대해 64개 GPU에서 1024의 미니배치 크기를 사용하고 0.12의 learning rate를 사용하고, 62.5k iteration(64M 이미지)마다 0.9배씩 지수적으로 감소한다. 우리는 1.25M iteration(IG-1B의 약 1.4 eopch) 동안 학습하고 ResNet-50에 대해 약 6일 걸린다.
4.1. Linear Classification Protocol
우리는 일반적인 프로토콜을 따라 우선 frozen feature에 대한 linear classification을 통해 우리의 방법을 검증한다. 이 sub-section에서 우리는 IN-1M에서 unsupervised pre-training을 수행한 다음 feature를 freeze 하고 supervised linear classifier(fully-connected layer 뒤에 softmax가 뒤따름)를 학습한다. 우리는 이 classifier를 ResNet의 global pooling feature에 대해 100 epoch 동안 학습한다. 우리는 ImageNet validation set에 대한 1-crop, top-1 분류 정확도를 보고한다.
이 분류기에 대해 grid search를 수행하고 최적의 초기 learning rate가 30이고 weight decay가 0임을 발견한다([56]에서 보고된 것과 유사하게). 이러한 하이퍼파라미터는 이 subsection에서 제시된 모든 ablation 항목에 대해 일관성 있게 잘 수행된다. 이러한 하이퍼파라미터 값은 feature 분포(예: magnitudes)가 ImageNet supervised 학습과 상당히 다를 수 있음을 시사하며, 이 이슈를 섹션 4.2에서 다시 논의할 것이다.
Ablation: contrastive loss mechanisms.
우리는 그림 2에 그려진 3가지 메커니즘을 비교한다. contrastive loss 메커니즘의 효과에 초점을 맞추기 위해, 우리는 섹션 3.3에서 설명된 것과 동일한 pretext task에서 그것들을 모두 구현한다. 또한 contrastive loss function으로 방정식 (1)의 동일한 형식의 InfoNCE를 사용한다. 따라서 비교는 오로지 3가지 메커니즘에 대한 것이다.
결과는 그림 3에 나와있다. 전체적으로 3가지 메커니즘은 모두 가 커지면서 이득을 얻는다. memory bank 메커니즘 에서 유사한 경향이 관찰되었지만, 여기서 우리는 이러한 경향이 더 일반적이고 모든 메커니즘에서 볼 수 있음을 보인다. 이러한 결과는 우리의 큰 dictionary를 구축하려는 동기를 지지한다.
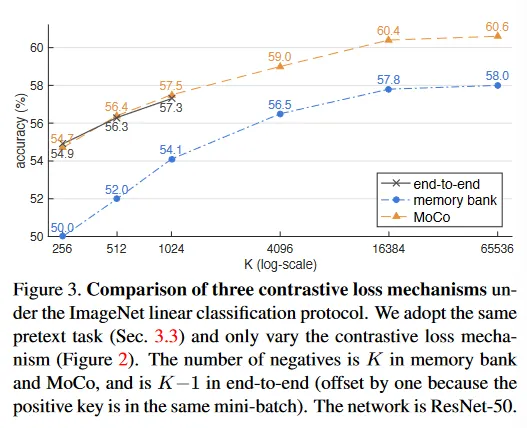
end-to-end 메커니즘은 가 작을 때 MoCo와 유사한 성능을 보인다. 그러나 end-to-end 요구사항에 따라 dictionary 크기는 미니배치 크기로 제한된다. 여기서 high-end 머신(8 Volta 32GB GPUs)이 감당할 수 있는 가장 큰 미니배치는 1024이다. 더 근본적으로 큰 미니배치 학습은 open problem이다. 우리는 여기서 선형 learning rate scaling 규칙을 사용해야 함을 발견했으며, 그렇지 않으면 정확도가 떨어진다(1024 미니배치에서 약 2%). 그러나 더 큰 미니배치로 최적화하는 것은 더 어렵고, 메모리가 충분하더라도 이 경향이 더 큰 로 외삽될 수 있는지 여부는 의문이다.
memory bank 메커니즘은 더 큰 dictionary 크기를 지원할 수 있다. 그러나 MoCo 보다 2.6% 더 나쁘다. 이것은 우리의 가설과 일치한다. memory bank의 key는 과거 epoch 전체에 걸쳐 서로 다른 인코더에서 온 것이며, 일관성이 없다. 58.0%의 memory bank의 결과는 우리가 개선한 구현을 반영한다.
Ablation: momentum.
아래 table은 pre-training에서 사용된 다양한 MoCo momentum 값(방정식 2에서 )에 따른 ResNet-50 정확도이다(여기서 ).
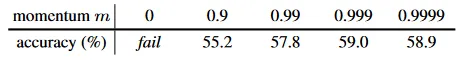
이 ~ 일 때 합리적으로 잘 수행되며, 이는 천천히 진행되는(즉 상대적으로 큰 momentum) key 인코더가 유익하다는 것을 보인다. 이 너무 작을 때(즉 ) 정확도는 상당히 낮아진다. 극단적으로 momentum이 없을 때(이 ) 학습 loss는 진동하고 수렴에 실패한다. 이러한 결과는 일관성있는 dictionary를 구축하려는 우리의 동기를 지지한다.
Comparison with previous results.
이전의 unsupervised learning 방법은 모델 크기에서 상당한 차이를 보인다. 공정하고 포괄적인 비교를 위해, 우리는 accuracy vs parameter trade-off를 리포트 한다. ResNet-50(R50) 외에도, [38]을 따라 2배와 4배 더 넓은(더 많은 채널)을 갖는 변종도 보고한다. 우리는 과 를 설정한다. Table 1은 그 결과이다.
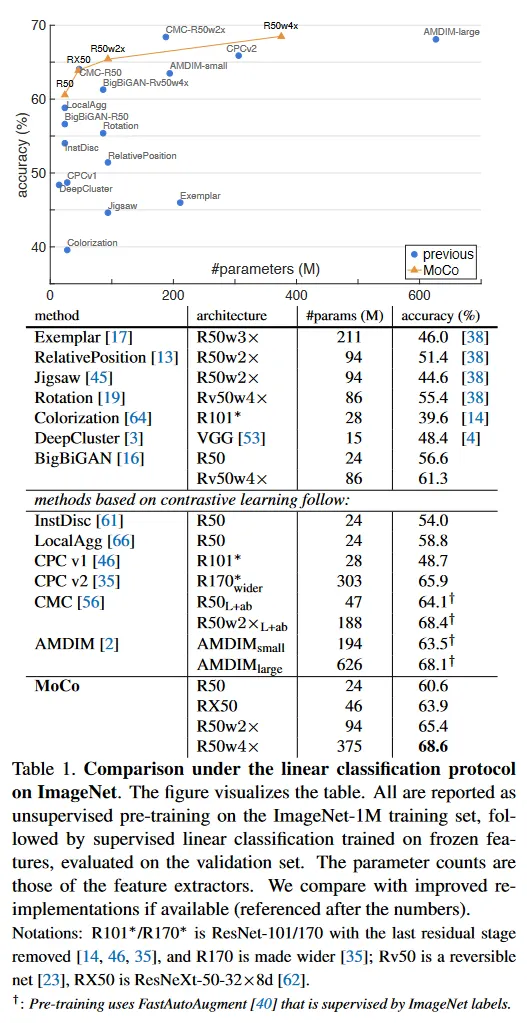
R50을 사용하는 MoCo는 경쟁력 있는 성능을 보이며 60.6% 정확도를 달성한다. 이것은 유사한 크기의 모델(약 24M)의 모든 경쟁자들보다 뛰어나다. MoCo는 더 큰 모델에서 이득을 얻어 R50w4x에서 68.6% 정확도를 달성한다.
주목할 것은, 우리는 표준 ResNet-50을 사용하여 경쟁력 있는 결과를 얻었으며, 특별한 아키텍쳐 설계를 요구하지 않는다는 것이다. (예: patchfied 입력, 조심스럽게 조정된 receptive fields, 또는 두 개의 네트워크 결합과 같은) pretext 작업에 대해 커스터마이징되지 않은 아키텍쳐를 사용함으로써, 다양한 시각 작업에 더 쉽게 전이하고 비교가 가능하다. 이는 다음 하위 섹션에서 연구된다.
이 논문의 초점은 일반적인 contrastive learning을 위한 메커니즘에 있다. 우리는 정확도를 추가로 개선할 수 있는 orthogonal factor(특정한 pretext 작업)를 탐색하지 않는다. 예컨대 이 원고의 preliminary 버전의 확장인 “MoCo v2”는 데이터 증강과 출력 projection head에 작은 변경을 하여 R50으로 71.1%의 정확도(60.6%에서)를 달성했다. 우리는 이러한 추가 결과가 MoCo 프레임워크의 일반성과 견고성을 보인다고 믿는다.
4.2. Transferring Features
unsupervised learning의 주요 목표는 전이할 수 있는 feature를 학습하는 것이다. ImageNet supervised pre-training은 downstream task에서 fine-tuning을 위한 초기화로 사용될 때 가장 영향력 있다. 다음으로 우리는 MoCo를 ImageNet supervised pre-training와 비교하고, PASCAL VOC, COCO 등을 포함하여 다양한 다양한 작업에 전이한다. 전제조건으로 우리는 관련된 두 가지 중요한 이슈를 논의한다. normalization과 schedule
Normalization.
섹션 4.1에서 언급한대로, unsupervisd pre-training에 의해 생성된 feature는 ImageNet supervised pre-training과 비교하여 서로 다른 분포를 갖는다. 그러나 downstream 작업을 위한 시스템은 종종 supervised pre-training을 위해 선택된 하이퍼파라미터(예: learning rate)를 갖는다. 이 문제를 완화하기 위해, 우리는 fine-tuning하는 동안 feature normalization을 채택한다. 우리는 affine 레이어로 freezing하는 대신 학습된(그리고 GPU간에 동기화된) BN을 사용하여 fine-tune한다. 또한 새롭게 초기화된 레이어(예: FPN)에서 BN을 사용한다. 이것은 magnitude를 보정하는 것을 돕는다.
우리는 supervised와 unsupervised pre-training 모델을 fine-tuning할 때 normalization을 수행한다. MoCo는 ImageNet supervised 대응 모델과 동일한 하이퍼파라미터를 사용한다.
Schedules.
fine-tuning 스케쥴이 충분이 길면, 무작위 초기화에서 detector를 학습하는 것이 강력한 baseline이 될 수 있고, COCO에서 ImageNet supervised 대응 모델의 성능과 일치할 수 있다. 우리의 목표는 feature의 전이가능성을 조사하는 것이므로 우리의 실험은 통제된 스케쥴에서 수행된다. 예컨데 COCO에 대한 1x(약 12 epoch) 또는 2x 스케쥴을 사용하며 이는 [31]에서 6x~9x와 대비된다. VOC와 같은 더 작은 데이터셋에서 더 길게 학습해도 [31]을 따라잡을 수 없다.
그럼에도 우리의 fine-tuning에서 MoCo는 ImageNet supervised 대응모델과 동일한 스케쥴을 사용하고 무작위 초기화 결과는 참조에서 제공된다.
종합하면, 우리의 fine-tuning은 supervised pre-training 대응 모델과 동일한 설정을 사용한다. 이것은 MoCo에 불리하지만 그럼에도 불구하고 MoCo는 경쟁력 있다. 이렇게 함으로써 추가적인 하이퍼파라미터 검색 없이 여러 데이터셋/작업에서 비교를 제시하는 것이 가능해진다.
4.2.1 PASCAL VOC Object Detection
Setup.
detector는 R50-dilated-C5 또는 R50-C4의 backbone을 사용하는 Faster R-CNN이다(자세한 것은 부록 참조). BN tune을 사용하며, [60]에서 구현되었다. 우리는 모든 레이어를 end-to-end로 fine-tune한다. 이미지 스케일은 학습하는 동안 [480, 800] 픽셀이고 추론할 때 800이다. 동일한 설정이 supervised pre-training baseline을 포함하여 전체 항목에서 사용된다. 우리는 default VOC 메트릭인 (즉 IoU threshold는 50%)과 더 엄격한 COCO-style의 AP와 메트릭을 평가한다. 평가는 VOC test2007 set에서 한다.
Ablation: backbones.
Table 2는 trainval07+12(약 16.5k 이미지)에서 fine-tune 결과를 보인다. R50-dilated-C5(Table 2a)의 경우, IN-1M에서 pre-trained MoCo는 supervised pre-training 대응 모델과 비교할만하고, 1G-1B에서 pretrained MoCo는 이를 능가한다. R50-C4(Table 2b)의 경우 IN-1M이나 IG-1B를 사용하는 MoCo는 supervised 대응 모델보다 더 낫다. 에서 최대 +0.9 , 에서 +3.7, 에서 +4.9까지 향상된다.
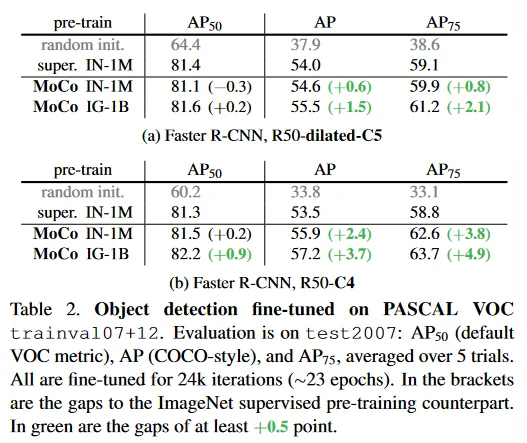
흥미롭게도 transferring 정확도는 detector 구조에 따라 달라진다. 기존 ResNet 기반 결과에서 default로써 사용된 C4 backbone의 경우 unsupervised pre-training의 이점이 더 크다. pre-training과 detector 구조 사이의 관계는 과거에 가려져 있고, 고려해야 할 요소가 되어야 한다.
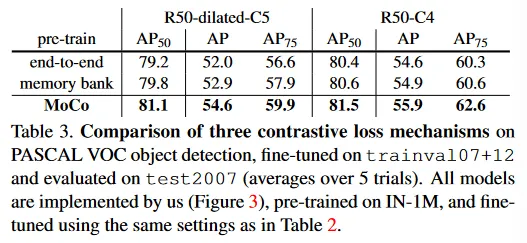
Ablation: contrastive loss mechanisms.
우리는 이러한 결과가 부분적으로 contrastive learning을 위한 solid detection baseline을 설립했기 때문이라고 주목한다. contrastive learning에서 MoCo 메커니즘을 사용하여 얻는 순수한 이득을 정확히 파악하기 위해, 우리는 end-to-end 또는 memory bank 메커니즘으로 pre-trained 모델을 fine-tune 한다. 이 두 메커니즘은 모두 우리가 구현한 것이며(즉 그림 3에서 최고 중 하나), MoCo와 동일한 fine-tuning 설정을 사용한다.
이러한 경쟁자들은 괜찮은 성는을 보인다(Table 3). C4 backbone을 사용하는 그들의 AP와 도 ImageNet supervised 대응 모델보다 더 높다(Table 2b). 그러나 다른 메트릭은 더 낮다. 그들은 모든 메트릭에서 MoCo 보다 더 나쁘다. 이것은 MoCo의 이점을 보여준다. 게다가 이러한 경쟁자들을 더 큰 스케일 데이터에서 어떻게 학습시키느냐는 open question이고, 그것들은 IG-1B에서 이점을 얻을 수 없다.
Comparison with previous results.
경쟁자들을 따라 우리는 C4 backbone을 사용하여 trainval2007(약 5k 이미지)에서 fine-tune 한다. 비교는 Table 4 참조.
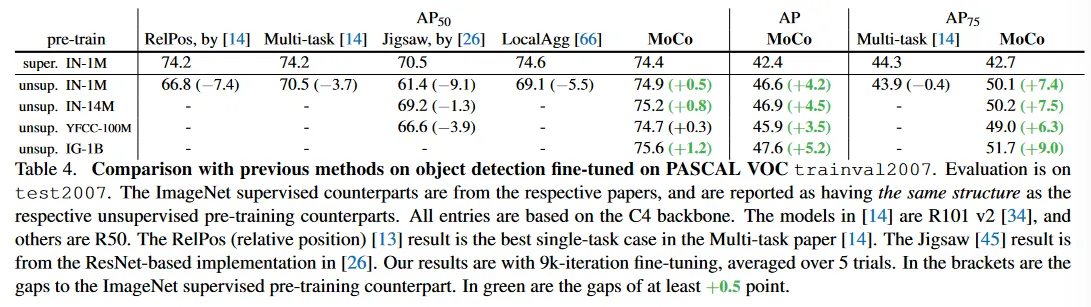
메트릭의 경우, 이전의 어떤 방법도 각각의 supervised pre-training 대응 모델을 따라잡지 못했다. IN-1M, IN-14M(전체 ImageNet), YFCC-100M과 IG-1B 중 어느 것에서 pre-trained MocO는 supervised baseline을 능가할 수 있다. 더 엄격한 메트릭에서 더 큰 이득을 볼 수 있다. AP에서 최대 +5.2, 에서 +9.0. 이러한 이득은 trainval07_12에서 보여진 이득보다 더 크다(Table 2b)
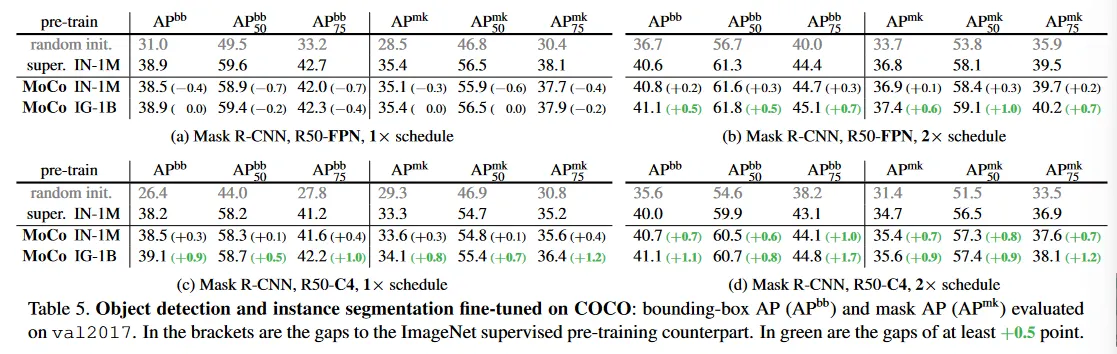
4.2.2 COCO Object Detection and Segmentation
Setup.
모델은 FPN이나 C4 backbone을 사용하는 Mask R-CNN이다. BN으로 조정되고, [60]에서 구현되었다. 이미지 크기는 학습하는 동안 [640, 800] 픽셀이고 추론에서 800 픽셀이다. 우리는 모든 레이어를 end-to-end로 fine-tune 한다. 우리는 train2017 set(약 118k 이미지)에서 fine-tune하고 val2017에서 평가한다. 스케쥴은 [22]에서의 default 1x 또는 2x이다.
Results.
Table 5는 FPN(Table 5a, b)와 C4(Table 5c, d) backbone을 사용하는 COCO에서 결과를 보여준다. 1x 스케쥴에서 모든 모델(ImageNet supervised 대응모델을 포함하여)은 매우 과소학습된다. 2x 스케쥴 경우와 비교하여 약 2점 격차를 나타낸다. 2x 스케쥴에서 MoCo는 두 backbone에서 모두 모든 메트릭에서 ImageNet supervised 대응모델 보다 낫다.
4.2.3 More Downstream Tasks
Table 6는 더 많은 downstream task을 보여준다(자세한 구현은 부록 참조). 전체적으로 MoCo는 ImageNet supervised pre-training과 경쟁력 있게 수행된다.
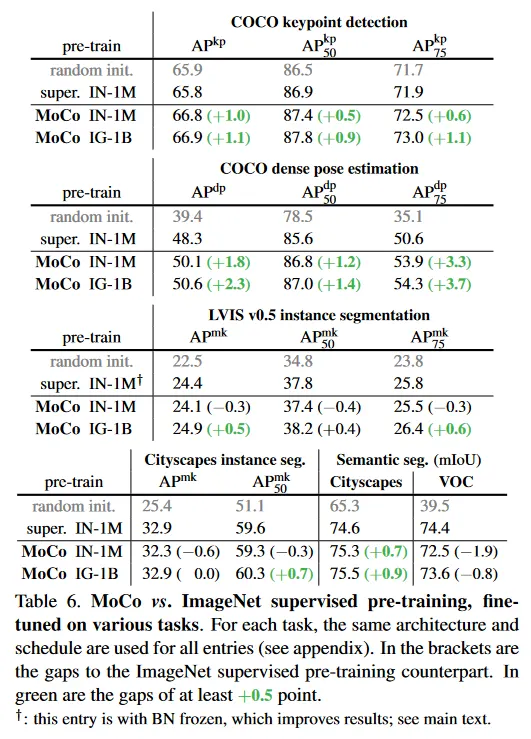
COCO keypoint detection: supervised pre-training은 무작위 초기화에 대해 분명한 이점을 갖지 않는 반면 MoCo는 모든 메트릭에서 능가한다.
COCO dense pose estimation: MoCo는 매우 localization-sensitive인 작업에서 supervised pre-training을 상당히 능가한다. 예컨대 에서 3.7 점 높다.
LVIS v0.5 instance segmentation: 이 작업은 약 1000 long-tailed 분포 카테고리를 갖는다. 특히 LVIS에서 ImageNet supervised baseline의 경우, frozen BN을 사용하여 fine-tuning하는 것(24.4 )이 조정가능한 BN 보다 낫다는 것을 발견했다(자세한 내용은 부록). 따라서 우리는 이 작업에서 MoCo를 더 나은 supervised pre-training 변종과 비교한다. 1G-1B의 MoCo는 모든 메트릭에서 이를 능가한다.
Cityscapes instance segementation: IG-1B를 사용하는 MoCo는 에서 supervised pre-training 대응 모델과 유사하고 에서는 더 높다.
Semantic segmentation: Cityscape에서 MoCo는 supervised pre-training 대응모델을 0.9점 능가한다. 그러나 VOC semantic segmentation에서 MoCo는 최소 0.8점 낮으며 이는 우리가 관찰한 negative case이다.
Summary.
요약하면, MoCo는 7가지 detection 또는 segmentation task에서 ImageNet supervised pre-training 대응 모델을 능가할 수 있다. 반면 MoCo는 Cityscape instance segmentation과 유사하고 VOC semantic segmentation에서 뒤쳐진다. 우리는 부록에서 iNaturalist에 대한 또 다른 비교가능한 경우를 보인다. 전체적으로 MoCo는 여러 vision task에서 unsupervised와 supervised representation learning 사이의 간격을 매우 좁혔다.
주목할 만한 점은, 이 모든 작업에서 IG-1B에서 pre-trained MoCo가 IN-1M에서 pre-trained MoCo 보다 낫다는 것이다. 이것은 MoCo가 대규모의, 상대적으로 uncurated 데이터셋에서 잘 동작할 수 있음을 보인다. 이것은 현실 세계의 unsupervised learning을 향한 시나리오를 나타낸다.
5. Discussion and Conclusion
우리의 방법은 다양한 computer vision 작업과 데이터셋에서 unsupervised 학습의 긍정적인 결과를 보인다. 논의할 가치가 있는 일부 open question이 있다. MoCo의 IN-1M에서 IG-1B로의 개선은 일관되게 눈에 띄지만 상대적으로 작다. 이는 더 큰 스케일 데이터가 완전히 활용되지 않을 수 있음을 시사한다. 우리는 발전된 pretext 작업이 이것을 해결할 것으로 기대한다. 단순한 instance discrimination 작업을 너머 MoCo을 예컨대 언어와 vision에서 masked auto-encoding 과 같은 pretext 작업에 대한 채택하는 것이 가능하다. 우리는 MoCo가 contrastive learning을 포함하는 다른 pretext 작업에 유용할 것이라고 희망한다.
