
Abstract
이 논문에서 self-supervised learning이 convolutional network(convnets)과 비교하여 Vision Transformer(ViT)에 새로운 속성을 제공하는지를 질문한다. 이 아키텍쳐에 self-supervised 방법을 채택하는 것이 특히 잘 동작한다는 사실을 넘어, 우리는 다음의 관찰을 한다. 첫째, self-supervised ViT feature는 이미지의 semantic segmentation에 관한 명시적인 정보를 포함하며, 이것은 supervised ViT에서는 분명히 드러나지 않는다. 둘째, 이러한 feature는 또한 훌륭한 k-NN classifier로, 작은 ViT로 ImageNet에서 78.3%의 정확도로 최상위 1위 달성한다. 우리의 연구는 또한 momentum encoder, multi-crop training과 ViT와 함께 작은 패치를 사용하는 것의 중요성을 강조한다. 우리는 우리의 발견을 DINO라 부르는 간단한 self-supervised 방법으로 구현하며, 이것은 라벨링 없이(no label) self-distillation의 한 형식으로 해석할 수 있다. 우리는 DINO와 ViT 사이의 시너지를 보이며, ViT-Base로 ImageNet 선형 평가에서 80.1%의 정확도로 최상위 1위를 달성한다. (distillation with no label에서 dino라는 이름이 나왔다)
1. Introduction
Transformer는 최근 visual 인식을 위한 convolution neural network(convnet)에 대한 대안으로 부상했다. 그들의 채택은 NLP에서 영감을 받은 학습 전략과 함께 결합되었다. 즉 대규모 데이터에서 pre-training 되고 target 데이터셋에서 fine-tuning 하는 것이다. 그 결과 Vision Transformer(ViT)는 convnet과 경쟁할 수 있었지만, 아직 그들에 비해 분명한 이점을 제공하지는 못했다. 그들은 계산적으로 더 요구하고, 더 많은 학습 데이터를 요구하고, 그들의 feature가 고유한 속성을 드러내지 않는다.
이 논문에서 우리는 vision에서 Transformer의 제한적인 성공이 그들의 pre-training에서 supervision의 사용으로 설명될 수 있는지 여부를 질문한다. 우리의 동기는 NLP에서 Transformer의 주요 성공 요인 중 하나가 BERT에서 완성 절차 또는 GPT에서 언어 모델링 형태의 self-supervised pre-training의 사용이었다는 것이다.
이러한 self-supervised pre-training 목적은 문장의 단어를 사용하여 pretext task를 생성하며, 이는 문장 당 단일 라벨을 예측하는 supervised 목적 보다 더 풍부한 학습 신호를 제공한다. 유사하게 이미지에서 이미지 레벨 supervision은 종종 이미지에 포함된 풍부한 시각적 정보를 몇 천 개의 pre-trained 카테고리 집합에서 선택된 단일 개념으로 축소시킨다.
NLP에서 사용된 self-supervised pretext 작업이 text 특화되어 있지만, 많은 기존의 self-supervised 방법들이 convnet을 사용하여 이미지에서 그 잠재력을 보여주었다. 그들은 일반적으로 유사한 구조를 공유하지만 자명한 해를 피하거나(붕괴) 성능을 개선하기 위해 설계된 서로 다른 컴포넌트를 갖는다. 이 작업에서 이러한 방법에서 영감을 받아 ViT feature에 대한 self-supervised pre-training의 영향을 연구한다. 특히 흥미로운 점은 supervised ViT나 convnet에서 나타나지 않는 여러 흥미로운 속성을 식별했다는 것이다.
•
Self-supervised ViT feature는 명시적으로 scene layout, 특히 object boundary를 포함한다. 그림 1 참조. 이 정보는 last 블록의 self-attention 모듈에서 직접 접근 가능하다.
•
Self-supervised ViT feature는 임의의 fine-tuning, linear classifier 또는 데이터 증강 없이 basic nearest neighbor classifier(k-NN)와 함께 특히 잘 동작하며 ImageNet에서 78.1%의 정확도로 최상위 1위를 달성했다.

segmentation mask의 출현은 self-supervised 방법 간에 공유되는 속성으로 보인다. 그러나 k-NN과의 좋은 성능은 momentum encoder와 multi-crop augmentation 과 같은 특정 컴포넌트와 결합할 때만 나타난다. 우리 연구의 또 다른 발견은 ViT에서 더 작은 패치를 사용하는 것이 결과 feature의 품질을 개선하는데 중요하다는 것이다.
전체적으로 이러한 컴포넌트의 중요성에 관한 우리의 발견은 라벨 없이 지식을 distillation 하는 형식의 하나로 해석될 수 있는 간단한 self-supervised 접근을 설계하도록 이끌었다.
그 결과 프레임워크 DINO는 momentum encoder로 구축된 teacher network의 출력을 표준 cross-entropy loss를 사용하여 직접 예측함으로써 self-supervised 학습을 단순화한다.
흥미롭게도 우리의 작업은 붕괴를 피하기 위해 teacher 출력의 centering과 sharpening만으로 작동할 수 있으며, predictor, advanced normalization 또는 contrastive loss과 같은 다른 대중적인 컴포넌트는 성능이나 안정성 측면에서 큰 이점이 없다. 특히 중요한 것은, 우리의 프레임워크가 유연하여 아키텍쳐를 수정하거나 내부 normalization을 조정할 필요 없이 convnet과 ViT에 모두 작동한다는 것이다.
추가로 우리는 작은 patch를 가진 ViT-Base로 ImageNet linear classification 벤치마크에서 80.1% 정확도로 최상위 1위를 달성하여 이전 self-supervised feature를 능가함으로써 DINO와 ViT 사이의 시너지를 평가한다. 또한 ResNet-50 아키텍쳐를 최신 기술 수준을 맞춤으로써 DINO가 convnet에서도 작동하는 것을 확인한다. 마지막으로 제한된 계산과 메모리 사용량의 경우에서 ViT와 함께 DINO를 사용하는 다양한 시나리오를 분석한다. 특히 ViT와 함께 DINO를 학습하는데, 단 2대의 8-GPU 서버만으로 3일간 학습하여 ImageNet linear 벤치마크에서 76.1% 정확도를 달성했다. 이것은 비슷한 크기의 convnet 기반 self-supervised 시스템들을 크게 줄어든 계산 요구량으로 능가한다.
2. Related work
Self-supervised learning
self-supervised learning에서 많은 연구는 instance classification이라 불리는 판별 접근에 초점을 둔다. 이는 각 이미지를 다른 클래스로 간주하고 데이터 증강을 통해 이들을 판별하도록 모델을 학습시킨다. 그러나 모든 이미지를 판별하기 위해 분류기를 명시적으로 학습하는 것은 이미지의 수가 증가함에 따라 잘 확장되지 않는다. Wu et al은 이미지를 분류하는 대신 인스턴스를 비교하기 위해 noise contrastive estimator(NCE)를 제안했다. 이 접근의 주의점은 동시에 대규모의 이미지에서 feature를 비교해야 한다는 것이다. 실제로 이것은 대규모 배치 또는 memory bank를 요구한다. 여러 변종은 클러스터링의 형식으로 인스턴스의 자동 그룹화를 허용한다.
최근 작업은 이미지 사이의 판별 없이도 unsupervised feature를 학습할 수 있음을 보였다. 특히 흥미로운 것은 Grill et al이 제안한 BYOL이라 부른 metric-learning 공식으로 여기서 feature를 momentum encoder를 사용하여 얻은 표현과 매칭하도록 학습시킨다. BYOL과 같은 방법은 momentum 인코더 없이도 작동하지만 성능 저하를 감수해야 한다. 여러 다른 작업은 이 방향을 반영하여 더 정교한 표현을 매칭하거나 균등 분포에 feature를 매칭하거나 whitening을 하여 학습시킬 수 있음을 보였다.
우리의 접근은 BYOL에서 영감을 받았지만 다른 유사도 매칭 loss를 연산하며, student와 teacher에 동일한 아키텍쳐를 사용한다. 그렇게 하여 우리의 작업은 BYOL에서 시작된 self-supervised learning을 라벨 없는 Mean Teacher self-distillation의 한 형식으로써 해석하는 것을 완성한다.
Self-training and knowledge distillation
self-training은 작은 초기 annotation 집합을 라벨링되지 않은 인스턴스의 대규모 집합에 전파하여, feature의 품질을 개선하는데 초점을 맞춘다. 이 전파는 라벨의 hard assignment 또는 soft assignment로 수행될 수 있다. soft 라벨을 사용할 때, 이 접근은 종종 knowledge distillation이라 부르고 주로 더 큰 네트워크의 출력을 흉내내도록 작은 네트워크를 학습시켜 모델을 압축하기 위해 설계된다. Xie et al은 distillation이 self-training 파이프라인에서 라벨링되지 않은 데이터에 soft pseudo-label을 전파하는데 사용될 수 있음을 보였다. 이는 self-training과 knowledge distillation 사이의 근본적인 연결을 그린다. 우리의 연구는 이러한 연결을 기반으로 하며 라벨이 없는 경우로 knowledge distillation을 확장한다. 이전 연구들도 self-supervised learning과 knowledge distillation을 결합하여 self-supervised model을 압축하고 성능 향상을 가능하게 했다. 그러나 이러한 작업은 pre-trained 고정된 teacher에 의존하는 반면 우리의 teacher는 학습하는 동안 동적으로 구축된다. 이렇게 하여 knowledge distillation은 self-supervised pre-training에 대한 후처리 단계로 사용되는 대신, 직접 self-supervised 목적으로 설정된다. 마지막으로 우리의 연구는 student와 teacher는 동일한 아키텍쳐를 갖고 학습하는 동안 distillation을 사용하는 codistillation과도 연관된다. 그러나 codistillation에서 teacher는 student로부터 distilling 되는 반면 우리의 연구에서는 student의 평균을 사용하여 업데이트된다.
3. Approach
3.1. SSL with Knowledge Distillation
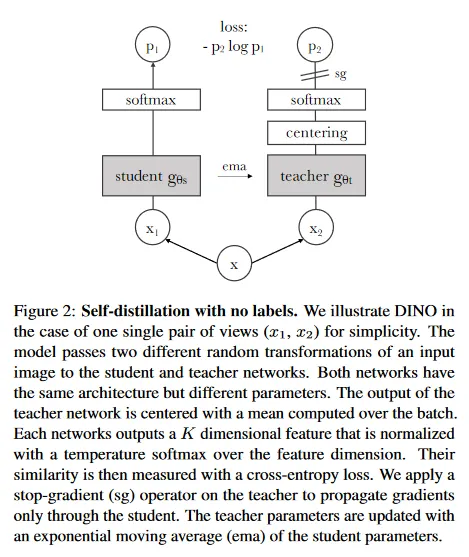
이 작업을 위해 사용된 프레임워크인 DINO는 최근 self-supervised 접근과 동일한 전반적인 구조를 공유한다. 그러나 우리의 접근은 knowledge distillation와도 유사성을 공유하고, 우리는 이 각도에서 제시한다. 우리는 그림 2에서 DINO를 소개하고 Algorithm 1에서 pseudo-code 구현을 제시한다.
Algorithm 1. DINO PyTorch pseudocode w/o multi-crop
# gs, gt: student and teacher networks
# C: center (K)
# tps, tpt: student and teacher temperatures
# l, m: network and center momentum rates
gt.params = gs.params
for x in loader: # load a minibatch x with n samples
x1, x2 = augment(x), augment(x) # random views
s1, s2 = gs(x1), gs(x2) # student output n-by-K
t1, t2 = gt(x1), gt(x2) # teacher output n-by-K
loss = H(t1, s2)/2 + H(t2, s1)/2
loss.backward() # back-propagate
# student, teacher and center updates
update(gs) # SGD
gt.params = l*gt.params + (1-l)*gs.params
C = m*C + (1-m)*cat([t1, t2]).mean(dim=0)
def H(t, s):
t = t.detach() # stop gradient
s = softmax(s / tps, dim=1)
t = softmax((t - C) / tpt, dim=1) # center + sharpen
return - (t * log(s)).sum(dim=1).mean()
Python
복사
Knowledge distillation은 student network 를 주어진 teacher network 의 출력에 맞추도록 학습하는 학습 패러다임이다. 여기서 각각 와 로 파라미터화 된다. 입력 이미지 가 주어지면 두 네트워크 모두 차원에 대한 확률 분포를 출력하며 이는 와 로 표기된다. 확률 는 네트워크 의 출력을 softmax 함수를 사용하여 normalizing 하여 얻어진다. 더 정확하게
여기서 는 출력 분포의 sharpness를 제어하는 온도 파라미터와이며, 유사한 공식이 온도 를 사용하는 에도 적용된다. 고정된 teacher 네트워크 가 주어지면 student 네트워크의 파라미터 에 관해 cross-entropy loss를 최소화하여 이러한 분포를 일치시키도록 학습한다.
여기서
이후 우리는 방정식 2에서 문제를 self-supervised learning에 어떻게 적용하는 지를 상세히 설명한다. 우선 multi-crop 전략[10]으로 이미지의 다양한 distorted view 또는 crop을 생성한다. 더 정확하게 주어진 이미지에서 서로 다른 view의 집합 를 생성한다. 이 집합에는 2가지 global view인 와 와 작은 해상도의 여러 local 뷰가 포함된다. 모든 crop은 student를 통과하지만 global view는 teacher만 통과하여 ‘local-to-global’ 대응을 유도한다. 우리는 다음 loss를 최소화한다.
이 loss는 일반적이고 2개의 view만으로도 사용될 수 있다. 그러나 우리는 multi-crop의 표준 설정을 따르며, 해상도 의 2가지 global view가 원본 이미지의 큰 영역(예컨대 50% 보다 큰)을 커버하고 해상도 의 여러 local view가 원본 이미지의 작은 영역(예컨대 50% 보다 작은)을 커버하게 한다. 다른 언급이 없으면 우리는 이러한 설정을 DINO의 기본 파라미터화라고 부른다. 두 네트워크는 서로 다른 파라미터 집합 와 로 동일한 아키텍쳐 를 공유한다. 우리는 stochastic gradient descent를 사용하여 방정식 3을 최소화하여 파라미터 을 학습한다.
Teacher network.
knowledge distillation과 다르게 우리는 prior가 주어지는 teacher 를 갖지 않는다. 따라서 우리는 그것을 student network의 과거 반복에서 구축한다. 우리는 섹션 5.2에서 teacher를 위한 다양한 업데이트 규칙을 연구하고, 한 epoch 동안 teacher 네트워크를 freezing 하는 것이 우리의 프레임워크에서 놀랍게도 잘 작동하는 반면, student 가중치를 teacher에 복사하는 것은 수렴에 실패하는 것을 보인다. 특히 student 가중치에 대해 exponential moving average(EMA)를 사용하는 것 즉, momentum encoder를 사용하는 것이 우리의 프레임워크에 대해 특히 잘 적합하다. 업데이트 규칙은 이고 여기서 는 학습하는 동안 0.996에서 1까지의 cosine 스케쥴을 따른다. 원래 momentum encoder는 contrastive learning에서 queue를 대체하기 위해 도입되었다. 그러나 우리의 프레임워크에서 queue나 contrastive loss를 사용하지 않기 때문에 그 역할은 다르며, self-training에서 사용된 mean teacher의 역할에 더 가깝다. 실제로 우리는 이 teacher가 exponential decay를 사용하는 Polyak-Ruppert averaging과 유사한 형태의 모델 앙상블을 수행하는 것을 관찰했다. 모델 앙상블을 위한 Polyak-Ruppert averaging 사용은 모델의 성능을 개선하기 위한 표준이다. 우리는 이 teacher가 학습하는 내내 student보다 더 나은 성능을 가지며, 따라서 더 높은 품질의 target feature를 제공하여 student의 학습을 가이드한다고 관찰했다. 이러한 다이나믹은 이전 연구에서는 관찰되지 않았다.
Network architecture.
신경망 는 backbone (ViT 또는 ResNet)와 projection head 로 구성된다. downstream task에서 사용되는 feature는 backbone 의 출력이다. projection head는 은닉 차원이 2048인 3개 layer의 MLP로 구성되며, normalization과 차원의 가중치 normalized인 fully connected layer가 이어진다. 이것은 SwAV의 설계와 유사하다. 우리는 다른 projection head를 테스트해 보았으며, 이 특정한 설계가 DINO에 가장 적합한 것으로 보인다(부록 C). 우리는 predictor를 사용하지 않으며, 그 결과 student와 teacher 네트워크의 아키텍쳐가 정확하게 동일해진다. 특히 흥미로운 것은 우리는 표준 convet과 달리 ViT 아키텍쳐가 기본으로 batch normalization(BN)을 사용하지 않는다는 것이다. 그러므로 DINO를 ViT에 적용할 때 우리는 projection head에서 BN을 사용하지 않고 시스템이 완전히 BN-free가 된다.
Avoiding collapse.
여러 self-supervised 방법들은 작업에 따라 붕괴를 피하기 위해 사용하는 것이 다르다. 예컨대 contrastive loss, clustering constraint, predictor, batch normalization 등이 있다. 우리의 프레임워크는 multiple normalization을 사용하여 안정화시킬 수 있지만, momentum teacher 출력의 centering과 sharpening 하는 것만으로도 모델 붕괴를 피할 수 있다. 섹션 5.3에서 실험적으로 보인대로, centering은 한 차원이 지배하는 것을 방지하지만 균등 분포로 붕괴하는 것을 장려한다. 반면 sharpening은 그 반대 효과를 갖는다. 두 작업을 모두 적용하면 이들의 효과가 균형을 이루며, momentum teacher가 존재하는 상황에서 붕괴를 피하는데 충분하다. 붕괴를 피하기 위해 이 방법을 선택하는 것은 안정성을 약간 희생하는 대신 배치에 대해 의존성을 줄인다. centering 작업은 1차 배치 통계량에만 의존하고, teacher에 bias 항 를 추가하는 것으로 해석될 수 있다. . center 는 exponential moving average로 업데이 되며, 섹션 5.5에서 보이는대로 이것은 다양한 배치 크기에 걸쳐 잘 작동한다.
여기서 은 rate 파라미터이고 는 배치 크기이다. 출력 sharpening은 teacher softmax normalization에서 낮은 값의 온도 를 사용하여 얻어진다.
3.2. Implementation and evaluation protocols
이 섹션에서 DINO를 사용하여 학습하는 것의 구현 상세를 제공하고 우리의 실험에서 사용된 평가 프토코골을 제시한다.
Vision Transformer.
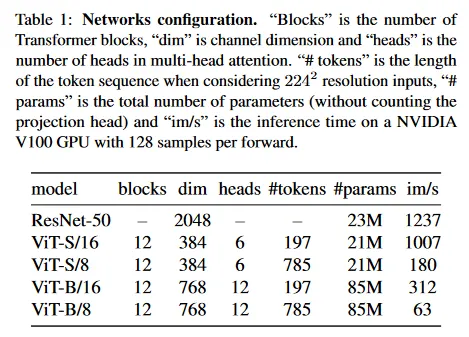
우리는 Vision Transformer(ViT)의 메커니즘을 간략히 설명한다. Transformer에 관한 상세한 내용은 Vaswani el al[70], 이미지에 대한 적용dms Dosovitskiy et al[19]를 참조하라. 우리는 DeiT[69]에서 사용된 구현을 따른다. 이 논문에서 사용된 다양한 네트워크의 설정은 Table 1에서 요약한다. ViT 아키텍쳐는 해상도 의 non-overlapping 연속 이미지 패치의 grid를 입력으로 취한다. 이 논문에서는 일반적으로 (”/16”) 또는 (”/8”)을 사용한다. 그 다음 패치는 embedding의 집합을 형성하기 위해 linear layer를 통과한다. 우리는 이 시퀀스에 추가 학습 가능한 토큰을 추가한다. 이 토큰의 역할은 전체 시퀀스의 정보를 취합하는 것이며, 우리는 이것의 출력에 projection head 를 붙인다. 이전 연구와의 일관성을 위해 이 토큰을 class token [CLS]라 부르지만, 어떤 라벨이나 supervision과 연결되지 않는다. 패치 토큰과 [CLS] 토큰 집합은 ‘pre-norm’ layer normalization을 사용하는 표준 Transformer 네트워크에 공급된다. Transformer는 self-attention과 feed-forward layer의 시퀀스로 구성되며 skip connection이 병렬로 배치된다. self-attention 레이어는 attention 메커니즘을 통해 다른 토큰 representation을 참조하여 토큰 representation을 업데이트한다.
Implementation details.
우리는 ImageNet 데이터셋에서 라벨링 없이 모델을 pretrain한다. ViT-S/16을 사용할 때 16개 GPU에 대해 분산하여 adam-w optimizer와 1024의 배치 크기로 학습한다. learning rate는 선형 스케쥴링 규칙을 따라 기본값에 도달할 때까지 처음 10 epoch 동안 선형적으로 증가한다. . 이 warm up 이후에 코사인 스케쥴을 사용하여 learning rate를 decay 한다. weight decay는 또한 에서 까지 코사인 스케쥴을 따른다. 온도 는 로 설정하고, 첫 30 epoch 동안 에서 까지 선형적으로 warm-up한다. 우리는 BYOL의 data augmentation(color jittering, Gaussian blur, solarization)과 multi-crop으로 따라 position embedding을 scale에 맞추기 위해 bicubic 보간을 사용한다. 우리의 결과를 재현할 수 있는 코드와 모델은 공개적으로 사용가능하다.
Evaluation protocols.
self-supervised learning을 위한 표준 프로토콜은 frozen feature 위에 선형 분류기를 학습시키거나 downstream task에 fine-tune 하는 것이다. linear evaluation의 경우, 학습하는 동안 무작위 resize crop과 horizontal filp 증강을 적용하고 central crop에서 정확도를 리포트한다. fine-tuning 평가의 경우 네트워크를 pre-trained 가중치로 초기화하고 학습하는 동안 이를 조정한다.
그러나 두 평가 모두 하이퍼파라미터에 민감하고 예컨대 learning rate을 변경할 때 실행 사이에 정확도에서 큰 분산을 관찰한다. 따라서 우리는 [73]에서와 같이 간단한 weighted nearest neighbor classifier(-NN)을 사용하여 feature의 품질을 평가한다. 우리는 pre-train 모델을 freeze하여 downstream 작업의 학습 데이터의 feature를 계산하고 저장한다. 그 다음 nearest neighbor classifier는 이미지의 feature을 라벨에 대해 투표하는 개의 저장된 nearest feature과 매칭한다. 우리는 다양한 수의 nearest neighbor의 대해 테스트하고, 대부분의 실행에서 20 NN이 일관되게 가장 잘 작동하는 것을 발견했다. 이 평가 프로토콜은 임의의 다른 하이퍼파라미터 조정이나 데이터 증강이 필요 하지 않고, downstream 데이터셋에 대해 단 한 번의 패스로 실행할 수 있어 feature 평가를 매우 단순화한다.
4. Main Results
우리는 우선 ImageNet에서 표준 self-supervised 벤치마크를 사용하여 이 연구에서 사용된 DINO 프레임워크를 검증한다. 그 다음 검색, object discovery, transfer-learning에 대한 결과 feature의 속성을 연구한다.
4.1. Comparing with SSL frameworks on ImageNet
우리는 동일한 아키텍쳐 간의 비교와 다른 아키텍쳐간의 비교라는 두 가지 설정을 고려한다.
Comparing with the same architecture.
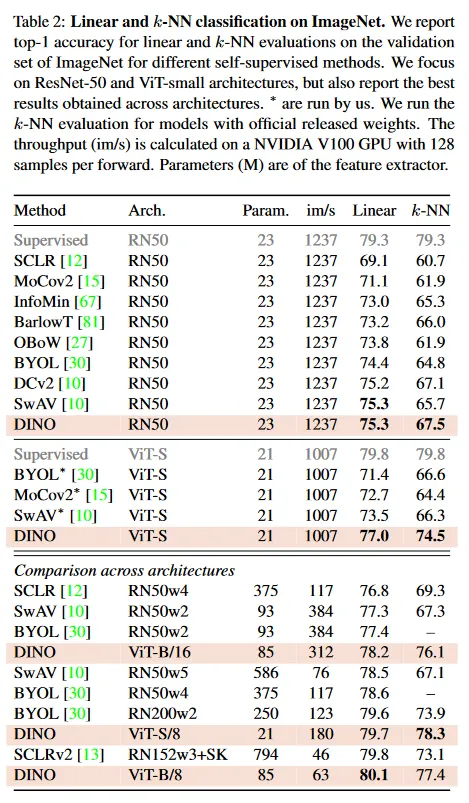
Table 2의 상단 패널에서 우리는 DINO를 동일한 아키텍쳐를 사용하는 다른 self-supervised 방법과 비교한다. 이것은 ResNet-50 또는 ViT-small(DeiiT-S의 설계를 따름)이다. ViT-S의 선택은 여러 측면에서 ResNet-50과의 유사성에 의해 동기부여 받았다. 파라미터의 수(21M vs 23M), 처리량(1237/sec vs 1007im/sec), [69]의 학습 절차를 사용한 ImageNet에서의 supervised 성능 (79.3% vs 79.8%). 우리는 부록 D에서 ViT-S의 변종을 탐구한다. 우선 DINO가 ResNet-50에서 최첨단과 동등한 성능을 보이는 것을 관찰한다. 이는 DINO가 표준 설정에서 잘 작동함을 보여준다. ViT로 교체할 때, DINO는 BYOL, MoCov2와 SwAV를 선형 분류에서 +3.5%, k-NN 평가에서 +7.9% 능가한다. 더 놀랍게도 간단한 k-NN 분류기를 사용한 성능이 선형 분류기와 거의 동등하다(74.5% vs 77.0%). 이 속성은 DINO을 ViT 아키텍쳐와 함께 사용할 때만 나타나고 다른 기존의 self-supervised 방법이나 ResNet-50에서는 드러나지 않는다.
Comparing across architectures.
Table 2의 하단 패널에서 우리는 아키텍쳐 별로 얻어진 최고 성능을 비교한다. 이 설정의 목적은 방법들을 직접 비교하는 것이 아니라, 더 큰 아키텍쳐로 이동할 때 DINO로 학습된 ViT의 한계를 평가하는 것이다. 더 큰 ViT를 DINO로 학습하면 성능이 향상되지만, patch의 크기를 줄이는 것(”/8” 변종)이 성능에 더 큰 영향을 미친다. 패치 크기를 줄이는 것은 파라미터 수를 증가시키지 않지만, 실행 시간을 상당히 감소하고 메모리 사용량을 증가시킨다. 그럼에도 불구하고 8x8 패치로 DINO 사용해서 학습된 base ViT는 선형 분류에서 top-1 80.1%를 달성하고, k-NN 분류기에서 77.4%를 달성한다. 이는 기존 최첨단 모델에 비해 10배 적은 파라미터와 1.4x배 빠른 실행시간을 갖는다.
4.2. Properties of ViT trained with SSL
우리는 DINO feature의 속성을 nearest neighbor search, object location 정보 유지 및 downstream 작업에 대한 transferability 측면에서 평가한다.
4.2.1 Nearest neighbor retrieval with DINO ViT
ImageNet 분류 결과는 nearest neighbor 탐색에 의존하는 작업에서 우리의 feature가 갖는 잠재력을 노출했다. 이 실험 집합에서는 landmark 검색과 copy detection 작업에서 이 발견을 더욱 확고히 한다.
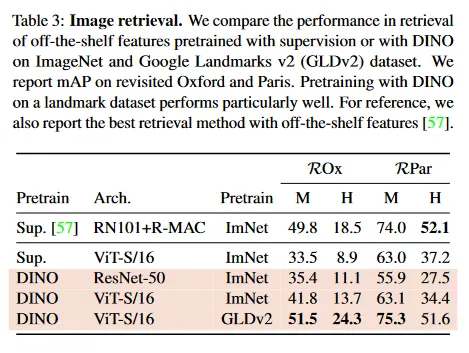
Image Retrieval.
우리는 Oxford와 Paris 이미지 검색 데이터셋을 다시 고려한다. 이것들은 점진적인 난이도를 가진 query/database pair의 3가지 다른 분할을 포함한다. 우리는 Medium(M)과 Hard(H) 분할에 대한 Mean Average Precision(mAP) 을 리포트한다. Table 3에서 supervised 또는 DINO 학습을 사용하여 얻은 다양한 off-the-shelf의 feature의 성능을 비교한다. 우리는 feature를 freeze하고 검색을 위해 k-NN을 직접 적용한다. DINO feature가 라벨링으로 ImageNet에서 학습된 것을 능가함을 관찰한다. SSL 접근의 이점은 어떠한 형태의 주석도 필요 없이 모든 데이터셋에서 학습될 수 있다는 것이다. 우리는 Google Landmark v2(GLDv2)에서 1.2M 깨끗한 집합에서 DINO를 학습한다. 이 데이터셋은 검색 목적으로 설계된 랜드마크이다. GLDv2에서 학습된 DINO ViT feature는 매우 뛰어나며, 이전에 공개된 off-the-shelf descriptor 기반 방법들을 능가한다.
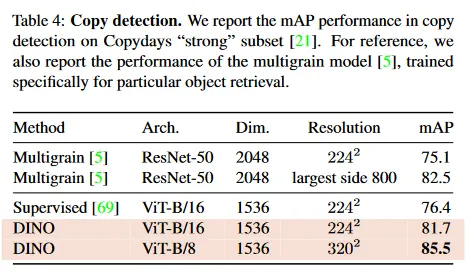
Copy detection.
우리는 DINO를 사용하여 학습된 ViT의 copy detection 작업에서의 성능을 평가한다. 우리는 INRIA Copydays 데이터셋의 ‘strong’ 부분 집합에서 mean average precision을 리포트한다. 이 작업은 blur, insertion, print, scan 등으로 오염된 이미지를 인식하는 것이다. 이전 작업을 따라 우리는 YFCC100M 데이터셋에서 무작위로 샘플링된 10k의 distractor(방해) 이미지를 추가한다. copy detection은 pre-trained 네트워크에서 얻어진 feature에 대해 코사인 유사도를 사용해 직접 수행한다. feature는 출력된 [CLS] 토큰과 GeM 풀링된 출력 패치 토큰을 연결하여 얻어진다. 이는 ViT-B에서 1535d descriptor를 발생시킨다. [5]를 따라 우리는 feature에 whitening을 적용한다. 이 변환은 distractor와 구별되는 YFCC100M에서 무작위로 선택된 추가 20k 이미지에서 학습한다. Table 4는 DINO로 학습된 ViT가 copy detection에서 매우 경쟁력 있음을 보인다.
4.2.2 Discovering the semantic layout of scenes
그림 1에서 질적 보여지듯이, 우리의 self-attention map은 이미지의 segmentation에 관한 정보를 포함한다. 이 연구에서 우리는 이러한 속성을 표준 벤치마크에서 측정할 뿐만 아니라 이러한 attention map에서 생성된 mask의 품질을 직접적으로 탐색한다.
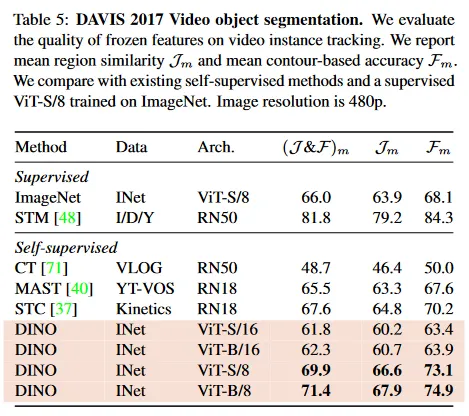
Video instance segmentation.
Table 5에서 우리는 DAVIS-2017 video instance segmentation 벤치마크에서 출력된 패치 토큰을 평가한다. 우리는 Jabri et al에서 실험 프로토콜을 따르고, 연속된 프레임 사이의 nearest neighbor를 사용하여 장면을 segment한다. 따라서 이 feature 위에 모델을 학습하거나 이 작업을 위한 가중치도 fine-tune 하지 않는다. Tab 5에서 우리의 학습 목적이나 아키텍쳐가 dense task를 위해 설계된 것이 아님에도 이 벤치마크에서 경쟁력 있는 성능을 보인다. 네트워크가 fine-tune 되지 않았기 때문에 모델의 출력은 어떤 공간적 정보를 유지하고 있어야 한다. 마지막으로 이 dense 인식 작업에서 작은 패치(”/8”)의 변종은 훨씬 성능이 좋다(ViT-B에 대해 +9.1%).
Probing the self-attention map.
그림 3에서 서로 다른 head가 이미지의 다른 semantic 영역에 attend 할 수 있음을 볼 수 있다. 이것은 심지어 차폐(세번 째 행에서의 bushes)이거나 작더라도(두 번째 행에서의 깃발) 마찬가지이다. 시각화는 480p 이미지로 얻어졌으며 ViT-S/8의 경우 3601개의 토큰 시퀀스를 생성한다.

그림 4에서 supervised ViT가 질적, 양적으로 무질서한 환경에서 객체를 잘 attend 하지 못하는 것을 볼 수 있다. 우리는 self-attention map을 ground truth와 질량의 60%까지 유지하도록 thresholding하여 얻은 segmentation mask와의 Jaccard 유사도를 리포트한다. self-attention map은 smooth하고 마스크를 생성하는데 최적화되지 않았음에 유의하라. 그럼에도 불구하고 supervised와 DINO 모델 사이에 Jaccard 유사도에서 분명한 차이를 볼 수 있다. self-supervised convnet 또한 segmentation에 관한 정보를 포함 하지만 이것을 가중치에서 추출하기 위해 전용 방법이 필요하다.

4.2.3 Transfer learning on downstream tasks
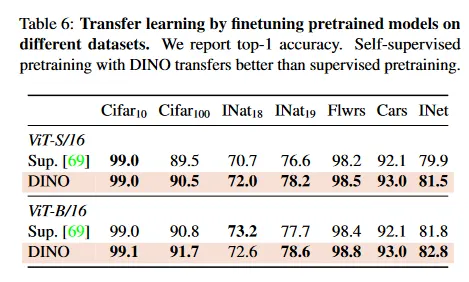
Tab 6에서 우리는 DINO로 pre-trained인 feature 품질을 다양한 downstream 작업에서 평가한다. 우리는 ImageNet에서 supervision으로 학습된 동일한 아키텍쳐의 feature와 비교한다. Touvron et al[69]에서 사용된 프로토콜을 따르며, 각 downstream task에서 feature를 fine-tune한다. ViT 아키텍쳐의 경우, self-supervised pre-training이 supervision으로 학습된 feature 보다 더 잘 전이 된다는 것을 관찰할 수 있으며, 이것은 convolutional 네트워크에서의 관찰과 일관성이 있다. 마지막으로 self-supervised pre-training은 ImageNet에서 결과를 매우 개선한다(+1-2%)
5. Ablation Study of DINO
이 섹션에서 우리는 ViT에 적용된 DINO를 실험적으로 연구한다. 이 전체 연구를 위해 고려된 모델은 ViT-S이다. 우리는 추가 내용은 부록 참조.
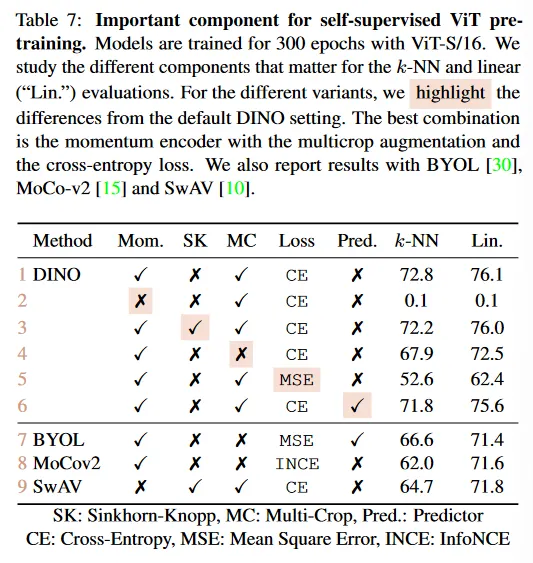
5.1. Importance of the Different Components
우리는 우리의 프레임워크에서 학습된 ViT에 self-supervised에 다양한 컴포넌트를 추가하는 효과를 보인다. Table 7에서 우리는 컴포넌트를 추가하거나 제거하는 모델의 다양한 변종을 리포트한다. 우선 우momentum이 없는 경우 우리의 프레임워크는 잘 동작하지 않고(2 행) 붕괴를 피하기 위해 SK와 같은 더 고급 작업이 필요하다. 그러나 모멘텀이 있는 경우 SK를 사용해도 큰 영향이 없다(3 행). 게다가 3행과 9행을 비교하면 성능에 대한 모멘텀 인코더의 중요성이 강조된다. 두 번째, 4행과 5행에서 DINO의 multi-crop training과 cross-entropy loss를 사용하는 것이 좋은 feature를 얻는데 중요한 컴포넌트임을 관찰한다. 또한 student 네트워크에 predictor를 추가하는 것이 작은 효과를 갖는데, 이는 BYOL에서 붕괴를 방지하는데 핵심이다. 완전성을 위해, 우리는 부록 B에서 이 ablation 연구의 확장된 버전을 제공한다.
Importance of the patch size.
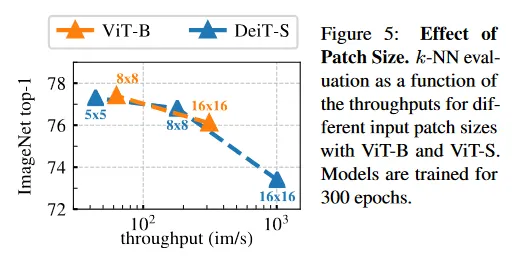
그림 5에서 우리는 16x16, 8x8, 5x5의 다양한 패치 크기로 학습된 ViT-S 모델의 k-NN 분류 성능을 비교한다. 또한 16x16과 8x8의 ViT-B와도 비교한다. 모든 모델은 300 epoch 동안 학습된다. 우리는 패치의 크기가 감소함에 따라 성능이 매우 개선되는 것을 관찰한다. 추가적인 파라미터 없이 성능이 매우 개선될 수 있다는 점이 흥미롭다. 그러나 더 작은 패치를 사용할 때 얻는 성능 이득은 처리량의 비용을 치른다. 5x5 패치를 사용할 때 처리량은 8x8 패치와 비교하여 44 im/s vs 180 im/s가 된다.
5.2. Impact of the choice of Teacher Network
이 ablation에서 우리는 DINO에서 teacher 네트워크의 역할을 이해하기 위해 다양한 teacher 네트워크를 실험한다. 우리는 k-NN 프로토콜을 사용하여 300 epoch 동안 학습된 모델을 비교한다.
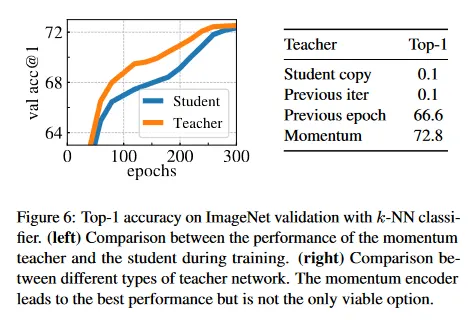
Building different teachers from the student.
그림 6(오른쪽)에서 우리는 momentum teacher 외에도 student 네트워크의 이전 인스턴스에서 teacher를 구축하는 다양한 전략을 비교한다. 우선 이전 epoch의 student 네트워크를 teacher로 사용하는 것을 고려한다. 이 전략은 memory bank[73]에서 사용되었거나 clustering hard-distillation의 형태로 사용되었다. 두 번째, 이전 iteration에서 student network를 사용하는 것과 아니라 student의 copy를 teacher로 사용하는 것을 고려한다. 이 설정에서 최근 버전의 student에 기반한 teacher를 사용하는 경우 수렴하지 않고, 이러한 설정은 작동하기 위해 더 많은 normalization이 필요하다. 흥미롭게도 이전 epoch의 teacher를 사용하는 것은, 붕괴하지 않고 k-NN 평가에서 MoCo-v2나 BYOL 같은 기존 프레임워크와 비교하여 경쟁력 있는 성능을 제공한다. 모멘텀 인코더를 사용하는 것이 이 순진한 teacher 보다 명확히 우수한 성능을 제공하지만, 이 발견은 teacher에 대한 대안을 조사할 여지가 있음을 시사한다.
Analyzing the training dynamic.
왜 momentum teacher가 우리의 프레임워크에서 잘 작동하는지 이유를 더 이해하기 위해 우리는 그림 6의 왼쪽 패널에서 ViT의 학습 하는 동안 다이나믹을 연구한다. 핵심 관찰은 이 teacher가 학습하는 동안 지속적으로 student를 능가한다는 것이며, ResNet-50을 사용하여 학습할 때도 동일한 동작을 관찰한다(부록 D). 이 동작은 momentum을 사용하는 다른 프레임워크나 teacher가 이전 epoch에서 구축될 때도 관찰되지 않았다. 우리는 DINO에서 momentum teacher를 exponential decay를 사용하는 Polyak-Ruppert averaging의 한 형식으로 이해하는 것을 제안한다.
Polyak-Ruppert averaging은 학습의 끝에서 네트워크의 성능을 개선하기 위해 모델 앙상블링을 시뮬레이션 할 때 종종 사용된다. 우리의 방법은 학습하는 동안 Polyak-Ruppert averaging을 적용하여 일관되게 성능이 우수한 모델 앙상블링을 구축하는 것으로 해석될 수 있다. 이 모델 앙상블링은 이후 student 네트워크의 학습을 가이드한다.
5.3. Avoiding collapse
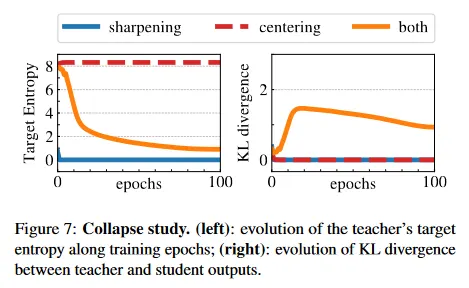
우리는 붕괴를 피하기 위한 centering과 target sharpening의 보완적인 역할을 연구한다. 붕괴에는 2가지 형식이 있다. 입력에 관계없이, 모델의 출력이 모든 차원을 따라 균등하거나 하나의 차원에 의해 압도된다. centering은 지배 차원에 의해 유도되는 붕괴를 피하는 반면 균등한 출력을 장려한다. Sharpening은 반대 효과를 도입한다. 우리는 cross-entropy 를 entropy 와 Kullback-Leibler divergence(KL) 로 분해 하여 이러한 보완을 보인다.
KL이 라는 것은 상수 출력을 나타내고, 따라서 붕괴를 의미한다. 그림 7에서 centering과 sharpening이 있고 경우와 없는 경우에 학습 중 entropy와 KL을 plot한다. 한 가지 작업이 누락되면, KL은 으로 수렴하고 붕괴를 나타낸다. 그러나 엔트로피 는 서로 다른 값으로 수렴한다. centering 없을 떄는 으로, sharpening 없을 때는 으로 수렴하며, 두 작업이 서로 다른 형식의 붕괴를 유도한다는 것을 나타낸다. 두 연산을 모두 적용하면 이러한 효과가 균형을 이룬다(sharpening 파라미터 의 연구는 부록 D 참조).
5.4. Compute requirements
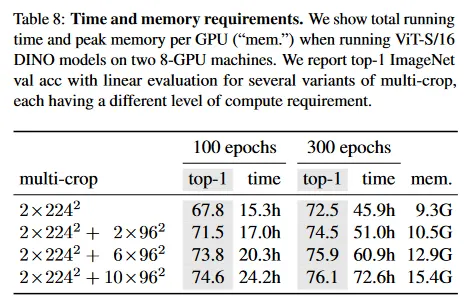
Table 8에서 우리는 2대의 8-GPU 머신에서 ViT-S/16 DINO 모델을 실행할 때의 소요되는 시간과 GPU 메모리 요구량의 세부사항을 보인다. 우리는 여러 multi-crop 학습의 변형을 리포트하며, 각 변형은 서로 다른 수준의 계산 요구량을 갖다. 우리는 table 8에서 볼 수 있듯이, multi-crop을 사용하면 DINO 실행 시 정확도/실생시간의 trade-off가 개선된다. 예컨대 multi-crop 없이() 48시간 동안 학습한 후에 성능은 72.5%이지만 의 crop 설정에서는 24시간만에 74.6%에 도달한다. 이것은 2배 적은 시간으로 2%의 개선이다. 다만 메모리 사용량은 더 높다(15.4G vs 9.3G). 우리는 multi-crop으로 인한 성능 부스트가 설정에서 더 많은 학습으로는 따라 잡을 수 없음을 관찰했으며, 이는 ‘local-to-global’ 증강의 가치를 보인다. 마지막으로 더 많은 뷰를 추가해도 학습이 길어지면 이득이 감소한다(6배에서 crop으로 +0.2%)
종합적으로 Vision Transformer로 DINO를 학습하면 3일간 2대의 8-GPU 서버를 사용하여 76.1 top-1 정확도를 달성한다. 이 결과는 비교 가능한 크기의 convolutional 네트워크에 기반한 self-supervised 최첨단을 능가하면서 계산 요구량을 매우 줄인다. 우리의 코드는 제한된 수의 GPU로 self-supervised ViT를 학습할 수 있도록 제공된다.
5.5. Training with small batches
Table 9에서 우리는 DINO를 사용하여 얻은 feature에 대해 배치 크기의 효과를 연구한다. 또한 부록 D에서 방정식 4의 centering update 규칙에서 사용된 smooth 파라미터 의 효과를 연구한다. 우리는 배치 크기에 따라 learning rate를 선형적으로 확장한다. . table 9에서 작은 배치 크기로도 높은 성능의 모델을 학습할 수 있음을 확인한다. 더 작은 배치 크기(bs = 128)를 사용하는 결과는 우리의 기본 학습 설정 bs=1024 보다 약간 낮고, momentum rate와 같은 하이퍼파라미터를 재조정해야 한다. 128의 배치크기를 사용하는 실험은 단지 1대의 GPU에서 실행했음에 주목하라. 우리는 8의 배치크기를 갖는 모델을 학습하는 것도 탐구했다. 50 epoch 이후에 35.2%에 도달했으며, GPU 당 이미지를 간신히 맞출 수 있는 큰 모델을 학습할 수 있는 가능성을 보인다.

6. Conclusion
이 연구에서 우리는 표준 ViT 모델을 self-supervised pre-training하는 것의 잠재력을 보인다. 이것은 이러한 설정을 위해 특별하게 설계된 최고의 convnet과 비교할만한 성능을 달성한다. 우리는 또한 미래 응용에 활용될 수 있는 두 가지 속성이 나타났다. k-NN 분류에서 feature의 품질이 이미지 검색에 대해 잠재력을 가지며, 이미 ViT가 유망한 결과를 보인다. 또한 feature 내에 장면 레이아웃에 관한 정보가 존재하는 것은 weakly supervised image segmentation에 이점이 있을 수 있다. 그러나 이 논문의 주요 결과는 self-supervised learning이 ViT에 기반한 BERT-like 모델 개발의 핵심이 될 수 있다는 증거를 제시한 것이다. 앞으로 우리는 DINO를 사용하여 무작위로 정제되지 않은 이미지에서 대규모 ViT 모델을 pre-train하는 것이 visual feature의 한계를 극복할 수 있을지를 탐구할 계획이다.
