
Abstract
이 논문은 수작업 데이터 augmentation에 의존하지 않고 매우 의미론적 이미지 representation을 학습하기 위한 접근을 시연한다. 우리는 Image-based Joint-Embedding Predictive Architecture(I-JEPA)를 소개한다. 이것은 이미지에서 self-supervised learning을 위한 non-generative 접근이다. I-JEPA의 뒤에 있는 아이디어는 간단하다. 단일 context block에서 동일한 이미지 내의 다양한 target block의 representation을 예측하는 것이다. I-JEPA를 의미론적 representation을 생성하도록 이끄는 핵심 설계 선택은 masking 전략에 있다. 구체적으로 (a) target block을 충분히 큰 스케일(의미론적)로 샘플링하고 (b) 충분히 정보가 풍부한 (공간적으로 분리된) context block을 사용한다. 실험적으로 Vision Transformer와 결합할 때 I-JEPA가 매우 확장 가능함을 발견했다. 예컨대 우리는 ImageNet에서 ViT-Huge/14를 16 A100 GPU를 사용하여 72시간 동안 학습하고 linear classification부터 object counting, depth prediction에 이르기까지 광범위한 작업에 걸쳐 강력한 downstream 성능을 달성했다.
1. Introduction
computer vision에서 이미지에서 self-supervised learning을 위한 2가지 친숙한 접근은 invariance-based 방법과 generative 방법이다.
Invariance-based pre-training 방법은 동일한 이미지의 2개 이상의 view에 대해 encoder가 유사한 embedding을 생성하도록 최적화한다. 이미지 view는 일반적으로 random scaling, cropping, color jittering 등과 같은 수작업 데이터 augmentation을 사용하여 구축된다. 이러한 pre-training 방법은 높은 의미론적 레벨의 representation을 생성할 수 있지만, 특정 downstream 작업 또는 심지어 다양한 데이터 분포를 사용하는 pre-training 작업에도 해로울 수 있는 강력한 bias를 도입한다. 이러한 bias를 다양한 추상화 레벨을 요구하는 작업에 어떻게 일반화해야 할지 명확하지 않다. 예컨대 image classification과 instance segmentation은 동일한 invariance을 요구하지 않는다. 추가적으로 이러한 image 특유의 augmentation을 audio와 같은 다른 모달로 일반화하는 것이 간단하지 않다.
Cognitive learning 이론은 생명공학 시스템에서 representation learning의 뒤에 있는 메커니즘이 감각 입력 반응을 예측하기 위해 내부 모델의 적응시키는 것이라고 제안한다. 이 아이디어는 self-supervised generative 방법의 핵심으로 입력의 일부를 제거하거나 오염시킨 후 오염된 컨텐츠를 예측하도록 학습한다. 특히 mask-denoising 접근은 입력에서 무작위로 마스킹된 패치를 픽셀이나 토큰 레벨로 복원하여 representation을 학습한다. Maksed pre-training 작업은 view-invariance 접근 보다 prior 지식을 덜 요구하고 이미지 모달 너머로 쉽게 일반화 가능하다. 그러나 결과 representation은 일반적으로 의미론적 레벨이 낮고 off-the-shelf 평가(예: linear probing)과 semantic classification task에서 limited supervision을 사용하는 transfer 설정에서 invariance-based pre-training의 성능에 미치지 못한다. 결론적으로 이러한 방법의 이점을 최대한 활용하기 위해서는 더 복잡한 적응 메커니즘(예: end-to-end fine-tuning)이 필요하다.
이 연구에서 이미지 변환을 통해 인코딩된 추가 prior 지식 없이 self-supervised representation의 의미론적 레벨을 개선하는 방법을 탐구한다. 이를 위해, 우리는 이미지에 대한 Joint-Embedding Predictive Architecture(I-JEPA)를 소개한다. 방법의 설명은 그림 3 참조. I-JEPA 뒤의 아이디어는 추상 representation 공간에서 누락된 정보를 예측하는 것이다. 예: 단일 context block이 주어지면, 동일한 이미지 내에서 다양한 target block의 representation을 예측한다. 여기서 target representation은 학습된 target-encoder network에 의해 계산된다.
pixel/token 공간에서 예측하는 generative 방법과 비교할 때, I-JEPA는 불필요한 픽셀-레벨 디테일이 제거될 수 있는 abstract prediction target을 사용하므로, 모델이 더 많은 의미론적 feature를 학습하게 된다. I-JEPA가 의미론적 representation을 생성하도록 이끄는 또 다른 핵심 설계 선택은 multi-block masking 전략이다. 구체적으로 우리는 이미지에서 충분히 큰 target block을 예측하고, 정보가 풍부한(공간적으로 분리된) context block을 사용하는 것의 중요성을 시연한다.
광범위한 실험 평가를 통해 우리는 다음을 시연한다.
•
I-JEPA는 수작업으로 설계된 view augmentation의 사용 없이 강력한 off-the-shelf representation을 학습한다(그림 1). I-JEPA는 ImageNet-1K linear probing, ImageNet-1K semi-supervised 1%, 그리고 semantic transfer task에서 MAE와 같은 픽셀 복원 방법을 능가한다.
•
I-JEPA는 semantic task에서 view-invariant pre-training 접근과 비교하여 경쟁력 있고, object counting과 depth prediction 같은 low-level vision task에서 더 나은 성능을 달성한다(섹션 5, 6). 더 단순한 모델과 덜 강건한 inductive bias를 사용하여 I-JEPA는 광범위한 작업에 적용 가능하다.
•
I-JEPA는 확장 가능하고 효율적이다(섹션 7). ImageNet에서 ViT-H/14를 pre-training하는데 1200 GPU 시간 미만이 걸리며, 이것은 iBOT를 사용한 ViT-S/16 보다 2.5배 이상 빠르고, MAE를 사용하여 pre-trained인 ViT-H/14보다 10배 이상 효율적이다. representation 공간에서 예측하는 것은 self-supervised pre-training을 위한 총 계산량을 크게 줄일 수 있다.
2. Background
self-supervised learning은 시스템이 입력 사이의 관계를 포착하도록 학습하는 representation learning이다. 이 목적은 Energy-Based Models(EBMs)의 프레임워크a를 사용하여 쉽게 설명할 수 있다. 여기서 self-supervised 목적은 incompatible 입력에 높은 에너지를 할당하고 compatible 입력에 낮은 에너지를 할당한다. 실제로 기존의 많은 self-supervised learning에 대한 생성, 비생성 접근이 이 프레임워크에서 설명될 수 있다. 그림 2 참조.
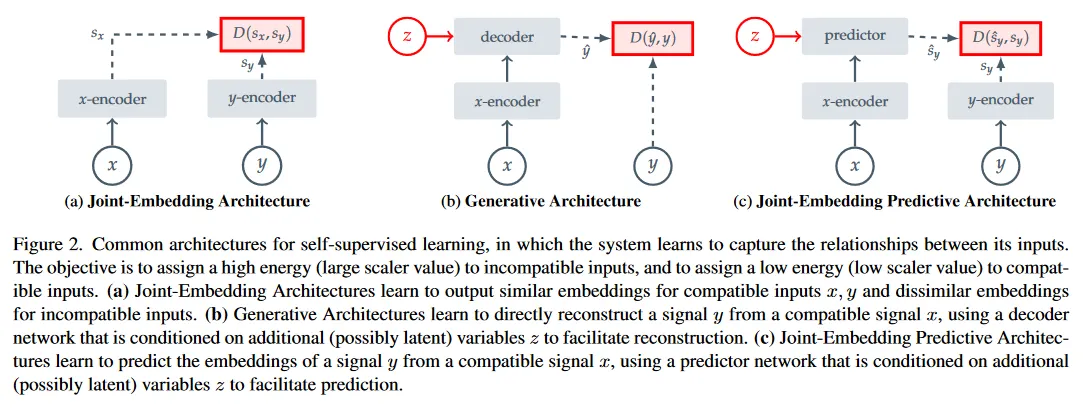
Joint-Embedding Architectures.
Invariance-based pre-training은 EBMs의 프레임워크에서 Joint-Embedding Architecture(JEA)로 설명될 수 있다. 이것은 compatible 입력 에 대해 유사한 임베딩을 출력하고, incompatible 입력에 대해서는 비유사한 임베딩을 출력하도록 학습된다. 그림 2a 참조. image-based pre-training의 맥락에서 compatible pair는 일반적으로 동일한 입력 이미지에서 수작업으로 설계된 데이터 증강을 무작위로 적용하여 구성된다.
JEA의 주요 도전은 에너지 환경이 flat(즉 encoder는 입력에 상관없이 상수 출력을 생성한다)해지는 representation 붕괴이다. 지난 몇 년간 representation 붕괴를 방지하기 위해 여러 접근이 조사되었다. 예컨대 negative 예제의 embedding을 명시적으로 분리하는 constrastive loss, embedding 간의 중복 정보를 최소화하는 non-contrastive loss와 평균 embedding의 entropy를 최소화하는 clustering-based 접근이 그것이다. 또한 붕괴를 피하기 위해 -encoder와 -encoder 사이의 비대칭 아키텍쳐 설계를 활용하는 휴리스틱 접근도 있다.
Generative Architectures.
self-supervised learning의 reconstruction-based 방법도 EBMs의 프레임워크에서 Generative 아키텍쳐를 사용하여 설명될 수 있다. 그림 2b 참조. Generative 아키텍쳐는 추가적인 (latent일 수 있는) 변수 에 조건화된 decoder 네트워크를 사용하여 compatible 신호 에서 신호 를 직접 복구하도록 학습한다. computer vision에서 image-based pre-training의 맥락에서 일반적인 접근은 masking을 사용하여 compatible pair를 생성하는 것이다. 여기서 는 이미지 의 copy이지만 일부 패치가 마스킹 된다. 그 다음 조건 변수 는 decoder가 어느 이미지 패치를 복원할지를 지정하는 (학습 가능한) 마스크와 position 토큰의 집합에 해당한다. 의 정보 용량이 신호 에 비교하여 낮은 한, 이러한 아키텍쳐에서 Representation 붕괴는 문제가 되지 않는다.
Joint-Embedding Predictive Architectures.
그림 2c에서 보이는 대로, Joint-Embedding Predictive Architecture는 개념적으로 Generative 아키텍쳐와 유사하다. 그러나 핵심 차이는 loss 함수가 입력이 아닌 embedding 공간에 적용된다는 것이다. JEPA는 추가적인 (latent일 수 있는) 변수 에 조건화된 predictor network를 사용하여 compatible 신호 에서 신호 의 embedding을 예측하는 방식으로 학습한다. 우리가 제안하는 I-JEPA는 이미지를 마스킹하여 이 아키텍쳐를 구현한 예시이다. 그림 3 참조.
Joint-Embedding Architecture와 달리, JEPA는 수작업 데이터 증강에 invariant인 representation를 탐색하는 것이 아니라 추가적 정보 에 조건화된 경우 서로 예측할 수 있는 representation을 탐색한다. 그러나 Joint-Embedding Architecture와 마찬가지로 JEPA에서도 representation 붕괴가 문제가 될 수 있다. 우리는 -encoder와 -encoder 사이의 비대칭 아키텍쳐를 활용하여 repersentation 붕괴를 피한다.
3. Method
이제 Image-based Joint-Embedding Predictive Architecture(I-JEPA)를 설명한다. 그림 3 참조. 전체 목적은 하나의 context block이 주어지면, 동일한 이미지 내에서 다양한 target block의 representation을 예측하는 것이다. 우리는 context-encoder, target-encoder, predictor에 대해 Vision Transformer(ViT) 아키텍쳐를 사용한다. ViT는 self-attention과 fully-connected MLP로 구성된다. 우리의 encoder/predictor 아키텍쳐는 generative masked autoencoder(MAE)를 연상시키지만 한 가치 핵심 차이는 I-JEPA 방법이 non-generative이고 예측이 representation 공간에서 일어난다는 것이다.
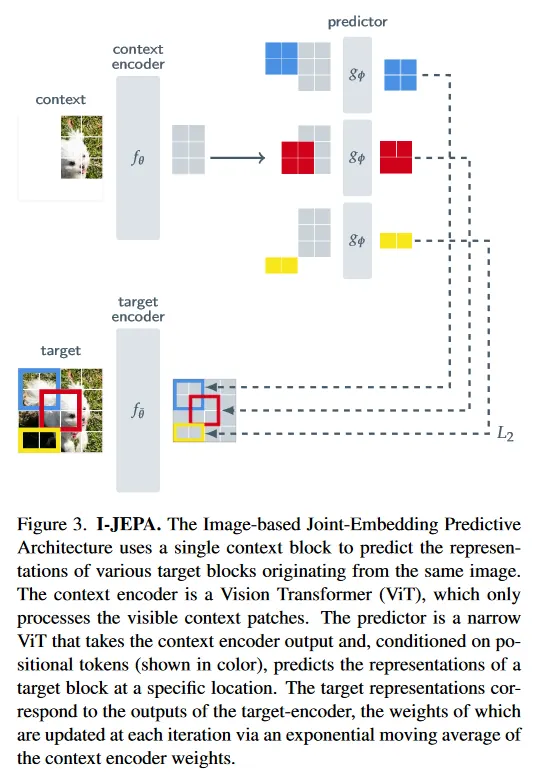
Targets.
우선 I-JEPA 프레임워크에서 어떻게 target을 생성하는지 설명한다. I-JEPA에서 target은 이미지 block의 representation에 해당한다. 입력 이미지 가 주어질 때, 그것을 겹침 없는 개의 패치로 변환하고, 이것을 target-encoder 에 공급하여 해당하는 패치-레벨 representation 를 얻는다. 여기서 는 패치와 연관된 representation이다. loss를 위한 target을 얻기 위해 우리는 target representation 에서 개 (겹칠 수 있는) block을 무작위로 샘플링한다. 우리는 를 번째 블록에 해당하는 마스크로, 를 그 패치-레벨의 representation으로 표기한다. 일반적으로 을 로 설정하고, 의 범위에서 무작위로 종횡비를 샘플링하고 의 범위에서 무작위로 스케일링한다. target block은 입력이 아니라 target-encoder의 출력을 masking하여 얻어진다는 것에 주의하라. 이 차이는 target representation이 높은 의미론적 레벨을 갖도록 보장하는데 핵심이다.
Context.
I-JEPA의 목표는 단일 context block에서 target block의 representation을 예측하는 것임을 떠올려라. I-JEPA에서 context를 얻기 위해, 우선 이미지에서 스케일 범위 와 unit 종횡비로 단일 블록 를 샘플링한다. 우리는 를 context block 와 연관된 mask로 표기한다. target block이 context block과 독립적으로 샘플링되기 때문에 상당한 겹침이 발생한다. non-trivial prediction task를 보장하기 위해 우리는 context block에서 겹치는 영역을 제거한다. 그림 4는 실제로 사용된 다양한 context와 target block의 예를 보인다. 다음으로 마스킹된 context block 를 context encoder 에 공급하여 해당하는 패치-레벨 representation 를 얻는다.

Prediction.
context encoder의 출력 이 주어지면, 우리는 개 target block representation 을 예측하기를 원한다. 이를 위해 target mask 에 해당하는 target block 에 대해 predictor 은 context encoder의 출력 와 예측하기를 원하는 각 패치에 대한 mask token 를 입력으로 취하여, 패치 레벨 예측 을 출력 한다. mask token은 공유된 학습 가능한 벡터에 positional embedding을 추가하여 파라미터화 된다. 우리는 개 target block에 대해 예측 수행해야 하므로 각 target-block location에 해당하는 마스크 토큰을 조건으로 predictor를 번 적용하여 예측 을 얻는다.
Loss.
loss는 간단히 예측된 패치-레벨 representation 와 target 패치 레벨 representation 사이의 평균 거리이다. 즉
predictor 와 context encoder 의 파라미터는 gradient-based 최적화를 통해 학습된다. 반면 target encoder 의 파라미터는 context-encoder 파라미터의 exponential moving average를 통해 업데이트 된다. exponential moving average target-encoder의 사용이 Visio Transformer와 함께 JEA를 학습하는데 핵심이다. I-JPEA에서도 동일한 사실을 발견했다.
4. Related Work
누락 또는 오염된 sensory 입력의 값을 예측하여 visual representation learning을 탐구한 오랜 작업이 있었다. denoising autoencoder는 입력 오염을 위해 무작위 노이즈를 사용한다. context encoder는 surrounding을 기반으로 전체 이미지 영역을 회귀한다. 다른 작업은 이미지 colorization을 denoising 작업으로 변환한다.
최근에는 masked image modeling의 맥락에서 image denoising의 아이디어가 다시 등장했으며, Vision Transformer를 사용해 누락된 입력 패치를 재구성한다. Masked Autoencoder(MAE)에 기반한 연구는 encoder가 visible 이미지 패치만 처리하도록하는 효율적인 아키텍쳐를 제안했다. MAE는 픽셀 공간에서 누락된 패치를 복원하여 강력한 성능을 달성했다. 대규모 라벨링된 데이터셋에서 end-to-end로 fine-tune 될 때 강력한 성능을 달성하고, 좋은 확장성을 시연했다. BEiT는 토큰화 공간에서 누락된 패치의 값을 예측한다. 구체적으로 250 million 이미지를 포함하는 데이터셋에서 학습된 frozen discreteVAE를 사용하여 이미지 패치를 토큰화한다. 그러나 pixel-level pre-training이 fine-tuning에서 BEiT를 능가했다. 또 다른 작업인 SimMIM은 고전적인 Histogram of Gradients feature 공간을 기반으로 하여 target을 탐구하고 픽셀 공간 복원에 비해 일부 이점을 시연한다. 이런 작업과 달리, 우리의 representation 공간은 Joint-Embedding Predictive Architecture를 통해 training하는 동안 학습된다. 우리의 목표는 downstream task에서 광범위한 fine-tuning을 필요로 하지 않은 의미론적 representation을 학습하는 것이다.
우리의 연구와 가장 가까운 것은 data2vec과 Context Autoencoder이다. data2vec 방법은 online target encoder를 통해 계산된 누락된 패치의 representation을 예측하도록 학습한다. 수작업 증강을 피하여 이 방법은 vision, text와 speech 같은 다양한 모달리티에 적용되어 유망한 결과를 얻었다. Context Autoencoder는 reconstruction와 alignment constraint의 합한 loss을 통해 최적화된 encoder/decoder 아키텍쳐를 사용하며, representation 공간에서 누락된 패치의 예측 가능성을 보장한다. 이러한 방법과 비교할 때, I-JEPA는 계산적 효율성의 상당한 개선을 보이며, 더 의미론적인 off-the-shelf representation을 학습한다. 우리 연구와 동시에 진행된 data2vec-v2는 다양한 모달리티를 사용한 학습을 위한 효율적인 아키텍쳐를 탐구한다.
우리는 또한 I-JEPA를 DINO, MSN, iBOT과 같은 joint-embedding 아키텍쳐를 기반으로 하는 다른 방법과 비교한다. 이러한 방법은 pre-training 동안 의미론적 이미지 representation을 학습하기 위해 수작업 데이터 증강에 의존한다. MSN에서 작업은 pre-training 동안 마스킹을 추가적인 data-augmentation으로 사용했으며, iBOT은 data2vec-style patch-level reconstruction loss를 DINO의 view-invariance loss와 결합한다. 이러한 접근들의 공통점은 각 입력 이미지의 여러 사용자 생성 view를 처리해야 한다는 것으로 이것은 확장성을 저해한다. 반면, I-JEPA는 각 이미지의 단일 view만 처리한다. 우리는 I-JEPA를 사용하여 학습된 ViT-Huge/14가 iBOT를 사용하여 학습된 ViT-Small/16 보다 적은 계산비용을 필요로 한다는 것을 발견했다.
5. Image Classification
I-JEPA가 수작업 데이터 증강에 의존하지 않고 high-level representation을 학습한다는 것을 입증하기 위해 우리는 linear probing과 partial fine-tuning 프로토콜을 사용한 다양한 image classification task의 결과를 리포트한다. 이 섹션에서 우리는 ImageNet-1K 데이터셋에서 pre-trained인 self-supervised 모델을 고려한다. pre-training과 평가 구현 상세는 부록 A에 설명된다. 모든 I-JEPA 모델은 다른 언급이 없는 한 224x224 해상도로 학습된다.
ImageNet-1K.
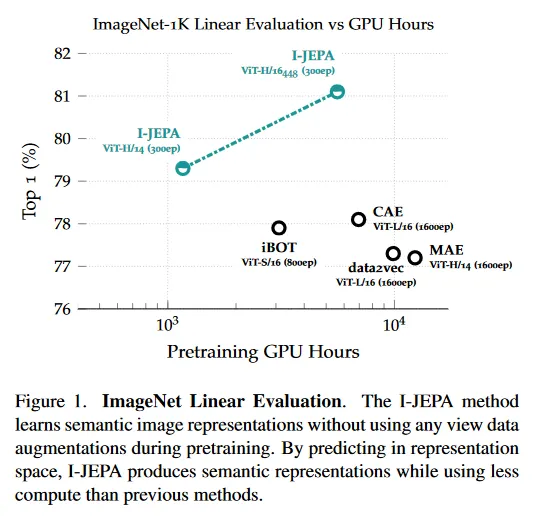
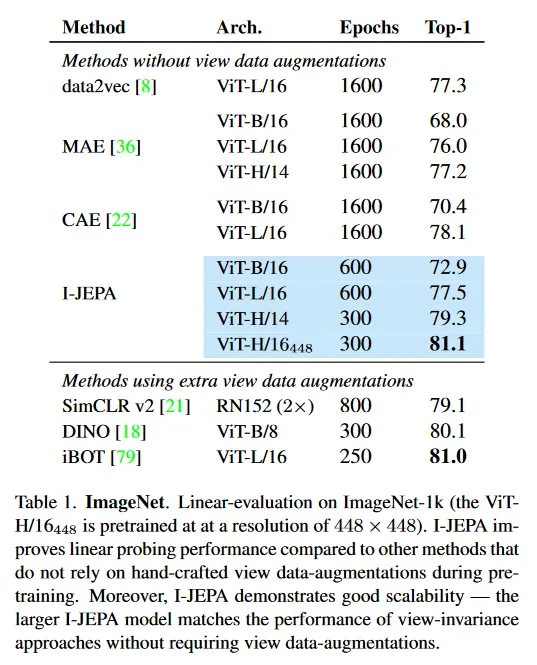
Table 1은 일반적인 ImageNet-1K linear evaluation 벤치마크에서 성능을 보인다. self-supervised pre-training 후에 모델 가중치는 frozen되고, full ImageNet-1K training set을 사용하여 linear classifier를 학습시킨다. pre-training 동안 값비싼 수작업 데이터 증강을 사용하지 않는 Masked Autoencoder(MAE), Context Autoencoder(CAE), data2vec과 같은 인기 있는 방법과 비교하여, 우리는 I-JEPA가 더 적은 계산 노력으로 linear probing 성능을 크게 개선하는 것을 볼 수 있다(섹션 7). I-JEPA의 개선된 효율성을 활용하여 더 큰 모델을 학습시킬 수 있으며, 이는 더 적은 계산량으로도 최고의 CAE 모델을 능가한다. I-JEPA는 확장성의 이점을 얻으며, 특히 해상도 448x448 픽셀에서 학습된 ViT-H/16는 수작업 데이터 증강의 사용을 하지 않고도 iBOT 같은 view-invariant 접근의 성능과 일치한다.
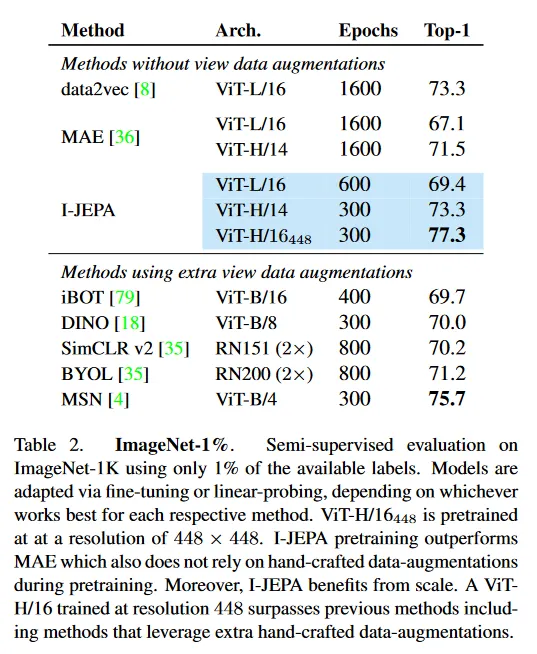
Low-Shot ImageNet-1K.
Table 2는 1% ImageNet 벤치마크에서 성능을 보인다. 여기서 가용한 ImageNet 라벨 중 1%만 사용하여 pre-trained 모델을 ImageNet classification에 대한 적용하는 것이 목표이다. 이것은 클래스당 약 12~13개 이미지에 해당한다. 각 방법에 맞게 fine-tuning이나 linear probing을 통해 모델을 적응시키며, 유사한 encoder 아키텍쳐를 사용할 때 I-JEPA는 더 적은 pre-training epoch로 MAE를 능가한다. ViT-H/14 아키텍쳐를 사용하는 I-JEPA는 더 적은 계산량으로 data2vec로 pre-trained인 ViT-L/16의 성능과 일치한다(섹션 7). 이미지 입력 해상도를 증가시키면, I-JEPA는 pre-training 동안 추가 수작업 데이터 증강을 활용해야 하는 MSN, DINO, iBOT을 포함한 이전의 joint-embedding 방법을 능가한다.
Transfer learning.
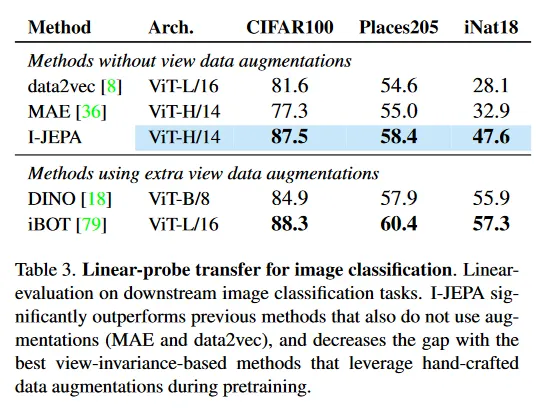
Table 3은 다양한 downstream image classification task에서 linear probing을 사용한 성능을 보인다. I-JEPA는 증강을 사용하지 않는 이전 방법(MAE와 data2vec)을 크게 능가하고, pre-training 동안 수작업 데이터 증강을 활용하는 최고의 view-invariance-based 방법과 격차를 줄이고, CIFAR100과 Place205에서 linear probing으로 DINO를 능가한다.
6. Local Prediction Tasks
섹션 5에서 보이는대로, I-JEPA는 MAE와 data2vec과 같은 이전 방법들의 downstream image classification 성능을 크게 개선하는 의미론적 이미지 representation을 학습한다. 게다가 I-JEPA는 확장성에서 이점을 얻으며, 추가 수작업 데이터 증강을 활용하는 view-invariance 기반 방법들과 격차를 줄이거나 능가할 수 있다. 이 섹션에서 우리는 I-JEPA가 local image feature도 학습하고 object counting과 depth prediction 같은 low-level과 dense prediction task에서 view-invariance 기반 방법을 능가함을 보인다.
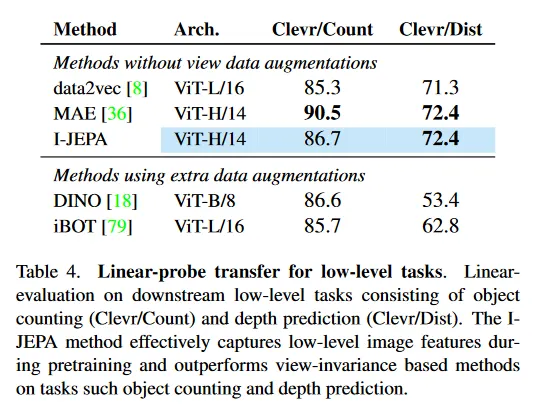
Table 4는 다양한 low-level task에서 linear probing을 사용하는 성능을 보인다. pre-training 후에 encoder 가중치를 frozen하고, object-counting과 depth prediction을 수행하기 위해 Clevr dataset에서 linear model을 학습한다. DINO와 iBOT 같은 view-invariance 방법과 비교하여, I-JEPA 방법은 pre-training 동안 low-level 이미지 feature를 효율적으로 포착하고 object counting(Clevr/Count)와 (큰 차이로) depth prediction(Clevr/Dist)에서 그들을 능가한다.
7. Scalability
Model Efficiency.
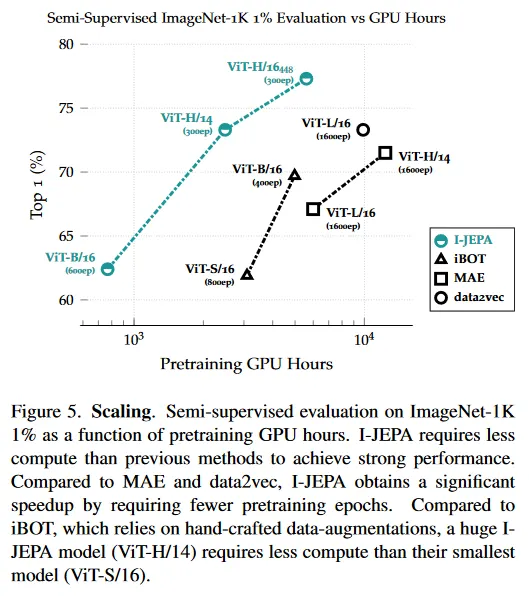
I-JEPA는 이전 접근과 비교하여 매우 확장 가능하다. 그림 5는 1% ImageNet-1K에서 GPU 시간의 함수로 평가된 semi-supervised를 보인다. I-JEPA는 이전 방법들 보다 계산량이 적으면서 수작업 데이터 증강 없이 강력한 성능을 달성한다. 픽셀을 직접 target으로 사용하는 MAE와 같은 reconstruction 기반 방법과 비교하여, I-JEPA는 representation 공간에서 타겟을 계산하므로 추가 오버헤드가 발생한다(iteration 마다 약 7% 느려진다). 그러나 I-JEPA가 약 5배 적은 iteration으로 수렴하기 때문에, 실제로는 상당히 큰 계산 절약을 볼 수 있다. 생성과 각 이미지의 multiple view를 처리하기 위해 수작업 데이터 증강에 의존하는 iBOT과 같은 view-invariance 기반 방법과 비교할 때 I-JEPA는 훨씬 빠르다. 특히 거대한 I-JEPA 모델(ViT-H/14)는 작은 iBOT 모델(ViT-S/16) 보다도 계산량이 적다.
Scaling data size.
우리는 또한 I-JEPA가 더 큰 데이터셋에서 pre-training 할 때 이점을 얻는 것을 발견한다. Table 5는 pre-training 데이터셋의 크기를 증가시킬 때(IN1k vs IN22K) 의미론과 low level 작업에서 transfer learning 성능을 보인다. 더 크고 더 다양한 데이터셋에서 pre-training 할 때, 개념적으로 다양한 작업에서 Transfer learning 성능이 개선된다.
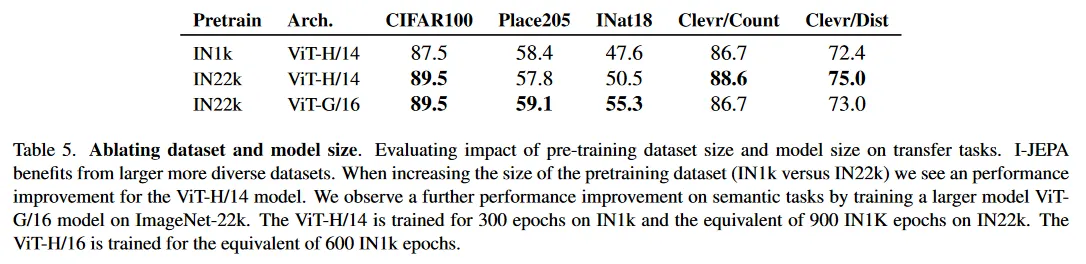
Scaling model size.
Table 5는 또한 I-JEPA가 IN22K에서 pre-training 할 때 더 큰 모델 크기에서 이점을 얻는 것을 보인다.
ViT-G/16을 pre-training할 때 Place205와 INat18과 같은 image classification task에서 ViT-H/14 모델과 비교하여 downstream 성능을 매우 개선하지만, low-level downstream task에서는 성능이 개선되지 않는다. ViT-G/16은 local prediction task에 대해 해로울 수 있는 더 큰 입력 패치를 사용한다.
8. Predictor Visualizations
I-JEPA에서 predictor의 역할은 context encoder의 출력을 취하고 positional mask 토큰을 조건으로 mask 토큰이 지정한 location의 target block의 representation을 예측하는 것이다. 자연스러운 질문은 positional mask 토큰에 조건화된 predictor가 target에서 positional 불확실성을 올바르게 포착할 수 있을까이다. 이 질문을 정성적으로 조사하기 위해, 우리는 predictor의 출력을 시각화한다. 리서치 커뮤니티가 우리의 결과를 독립적으로 재현할 수 있도록, 우리는 다음의 시각적 접근을 사용한다. pre-training 후에 우리는 context-encoder와 predictor 가중치를 freeze하고 RCDM 프레임워크를 따라 predictor 출력의 average-pool을 픽셀 공간에 다시 매핑하는 decoder를 학습시킨다. 그림 6은 다양한 무작위 시드에 대한 decoder 출력을 보인다. 샘플 전체에 걸쳐 공통으로 나타나는 특성들은 average-pooled predictor representation에서 포함된 정보를 나타낸다. I-JEPA predictor는 positional 불확실성을 올바르게 포착하고 올바른 pose를 가진 high-level object part(예: 새의 뒷모습과 자동차의 윗모습)를 생성한다.

9. Ablations
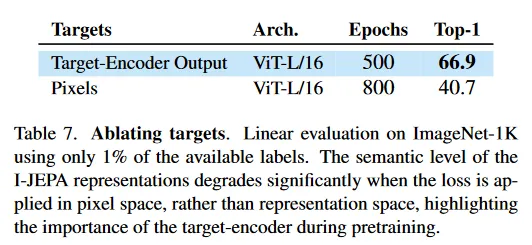
Predicting in representation space.
Table 7은 1% ImageNet-1K에서 linear probing을 사용할 때, loss가 pixel 공간과 representation 공간에서 계산되는 경우의 low-shot 성능을 비교한다. 우리는 I-JEPA의 핵심 성분이 loss가 전적으로 representation 공간에서 계산되는 것이라고 추측한다. 이로 인해 target encoder는 추상적인 예측 target을 생성할 수 있으며, 이 과정에서 관련 없는 픽셀-레벨 디테일은 제거된다. Table 7에서 보듯이, 픽셀 공간에서 예측하면 linear probing 성능이 크게 저하된다.
Masking strategy.
Table 6은 multi-block masking을 이미지를 4개의 큰 사분면으로 분할하고, 하나의 사분면을 context로 사용하여 다른 3가지 사분면을 예측하는 rasterized masking과 reconstruction-based 방법에서 일반적으로 사용되는 전통적인 block masking과 random masking을 비교한 것이다. block masking에서 target은 단일 이미지 블록이고 context는 그 이미지의 나머지이다. random masking에서 target이 무작위 패치의 집합이고 context는 그 이미지 나머지이다. 모든 전략에서 context와 target block 사이에 겹침이 없다는 것에 유의하라. 우리는 multi-block masking이 I-JEPA가 의미론적 representation을 학습하는데 유용하다는 것을 발견했다. multi-block masking에 대한 추가 ablation은 부록 C에서 찾을 수 있다.

10. Conclusion
우리는 수작업 데이터 augmentation에 의존하지 않고 의미론적 이미지 representation을 학습하는 간단하고 효율적인 방법인 I-JEPA를 제안한다. 우리는 I-JEPA가 representation 공간에서 예측함으로써 픽셀 reconstruction 방법 보다 빠르게 수렴하며, high semantic level의 representation을 학습할 수 있음을 보인다. view-invariance based 방법과 달리 I-JEPA는 수작업 view augmentation에 의존하지 않고 joint-embedding 아키텍쳐를 사용하여 일반적인 representation을 학습하는 경로를 밝힌다.
