

•
image가 아니라 video-text 대응을 transformer에 적용.
◦
transformer는 sequential 데이터가 필요한데, 애초에 video가 frame들의 sequence이므로 문제 없음.
•
video-text pair는 어떻게 수집할까?
◦
비디오 검색과 클릭된 비디오 쌍을 보거나, video의 title, description을 보거나, video의 ASR(Auto Speech Recognition)을 쓰거나 등. 물론 이런 방법에는 noise가 많이 있음.

•
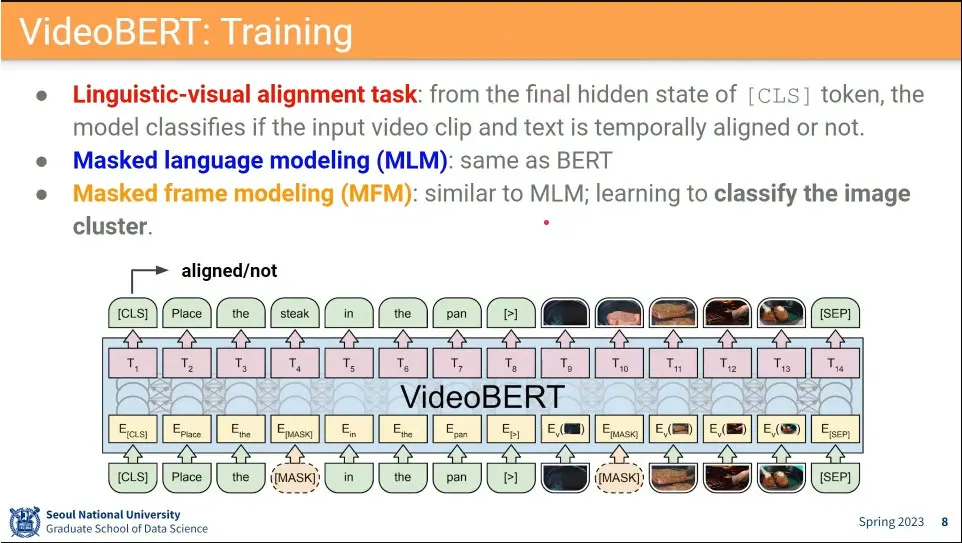
VideoBERT는 BERT처럼 token을 만들어서 함. text와 video에서 1.5초마다 뽑은 image를 함께 넣음.
◦
text에 mask를 씌우거나, image에 mask를 씌워서 맞추게 함.
◦
문제는 image mask를 채우는게 어려움.

•
모든 video의 frame들을 clustering 한 후에 frame들에 같은 cluster id를 줌.
◦
클러스터는 k-mean를 돌려서 사용.
•
그렇게 묶인 cluster에 대해 centroid에 가까운 frame을 찾아서 대표로 설정.
•
frame에 mask를 씌운 후에 어떤 cluster에 해당하는지를 맞추게 함.
•
text와 video가 같은 내용을 담고 있는지를 학습하는게 Linguistic-visual alignment. 이게 가장 중요함.
•
text에 mask 씌워서 맞추게 하는게 전통적인 MLM(masked language modeling)
•
frame에 mask 씌워서 이미지 cluster를 맞추게 하는게 MFM(masked frame modeling)

•
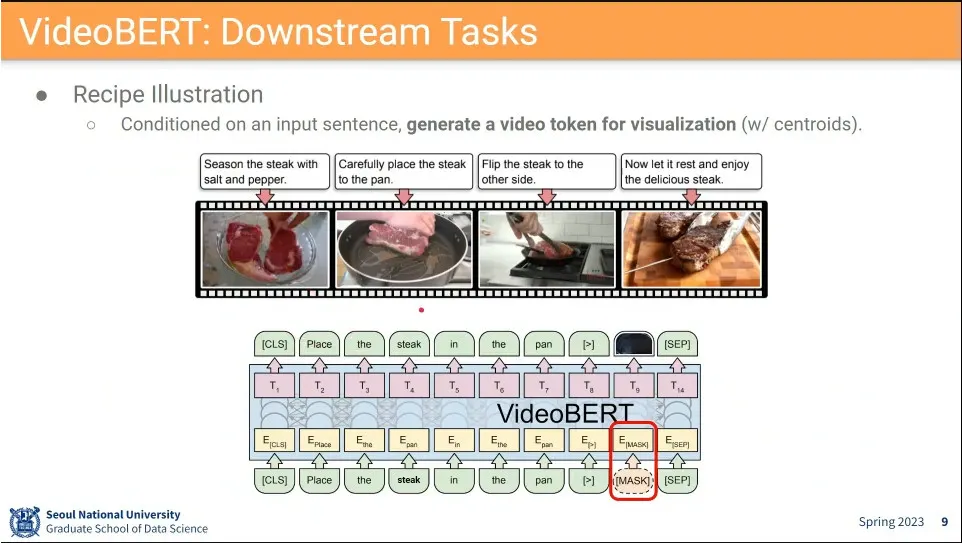
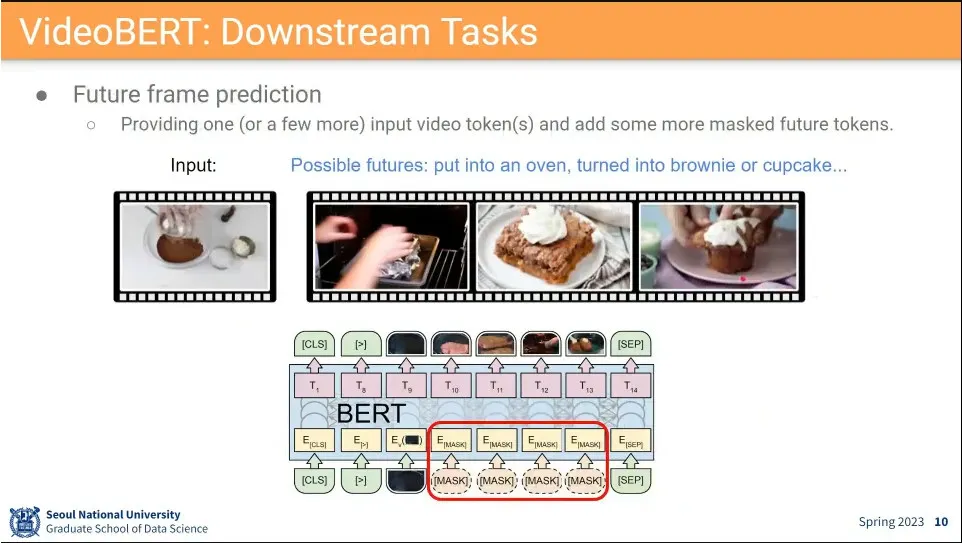
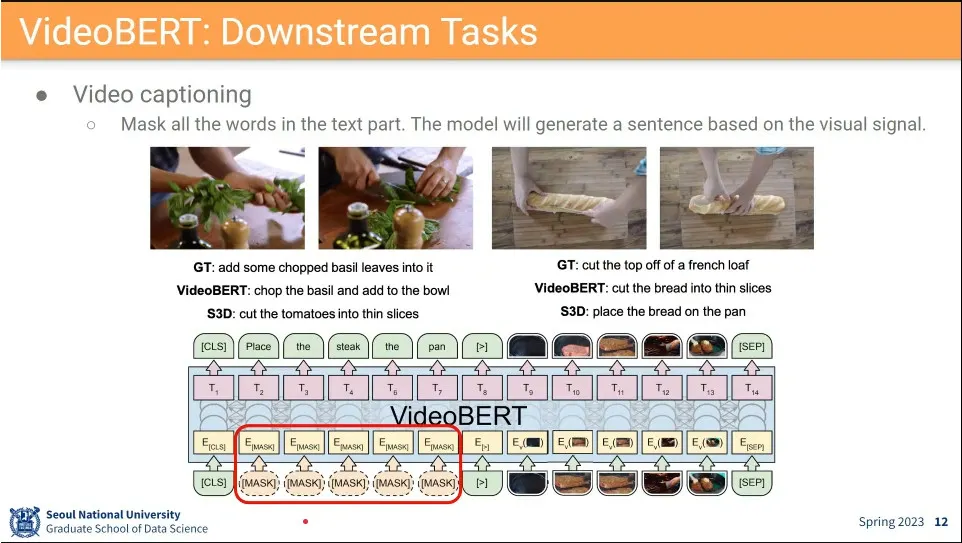
응용 사례 - 비어있는 프레임 채우기, 다음 프레임 예측하기, 비디오 captioning 등
•
Zero-shot은 좀 오해의 소지가 있는 용어
◦
labeling된 데이터셋을 안 쓴 경우에 zero-shot이라고 함.
◦
실제로 학습을 안한게 아님. 오히려 그런 경우에 훨씬 큰 데이터셋을 사용함.
•
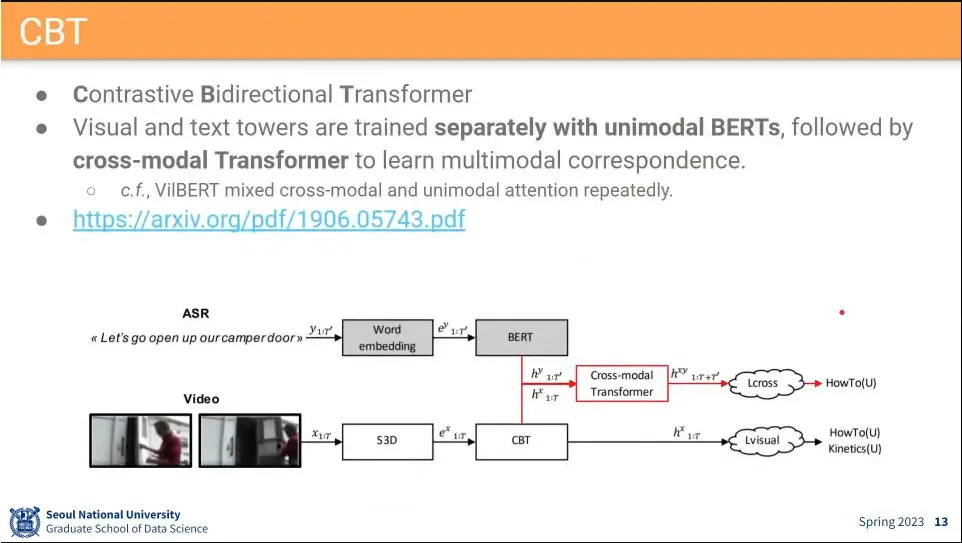
VideoBERT와 같은 저자들이 만든 모델.
◦
VideoBERT는 clustering 때문에 end-to-end 학습이 안되서 그걸 걷어낸 모델. 대신 contrastive learning을 씀.
•
text tower, video tower를 따로 돌림.
◦
text만 갖고 bert까지 돌리고
◦
video도 S3D를 돌리고, CBT까지 돌린 후에,
◦
그 두 결과를 합쳐서 Cross-modal transformer를 돌림
◦
최종적으로 그 둘을 합한 것과, video만 보는 것을 따로 사용 함.
•
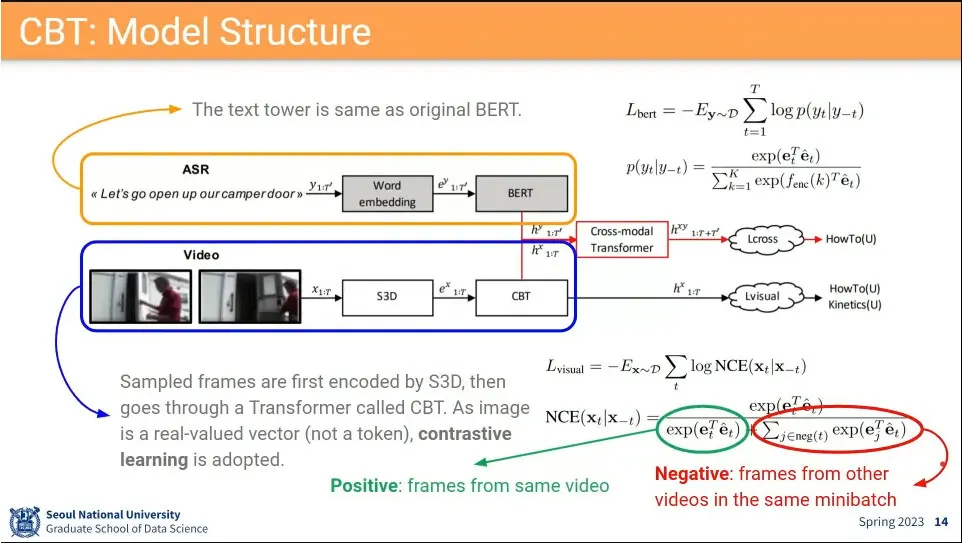
clustering을 안하는대신 contrastive learning을 하는게 CBT
◦
같은 video는 positive로 하고 다른 video는 negative로 하는 NCE loss를 사용함
◦
이때 모든 video를 negative를 쓰지 않고 샘플링해서 씀.
•
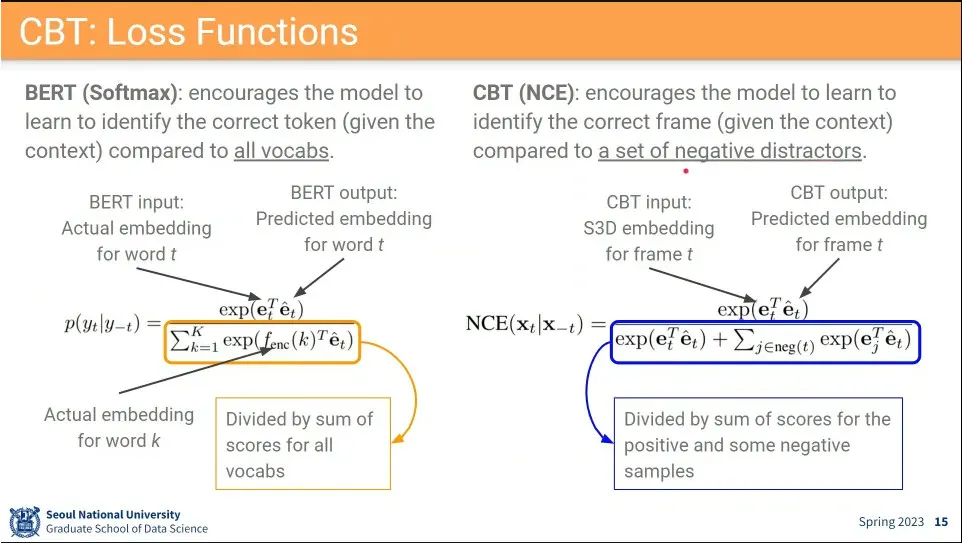
softmax는 기본적으로 정답인 것은 분자에 넣고, 분모에는 정답을 포함해서 모든 것을 넣고, 정답일 때는 값을 올리고, 그 외의 것은 낮아지게 함.
•
NCE도 정답을 분자에 넣고, 분모에는 정답을 포함해서 나머지 것들 중에서 sampling 해서 사용함. 정답인 것은 값이 올라가게 하고, 그 외의 것은 낮아지게 함.
•
softmax와 NCE는 개념적으로 달라 보이지만 실제 수식은 비슷함.
◦
분자는 동일하고, 분모가 negative를 모두 쓰지 않고 sampling해서 사용하는 부분만 차이가 있음.
•
NCE는 label이 필요 없음.

•
Cross-modal transformer에서도 NCE loss를 써서 같은 것끼리 가까워지게 하고, 다른 것은 멀어지게 함.
◦
다만 Cross-modal transformer에서는 exp를 쓰지 안고 정보이론에서 사용하는 mutual information을 사용함.
•
이렇게 하면 cluster하는 과정이 끊어지지 않고 end-to-end 학습이 됨
•
video에 text query를 줬을 때 그 location을 찾아주는게 Hammer
◦
하나의 video에 대해 하면 MLSV이고, 여러 비디오에 대해 하면 MLVC

•
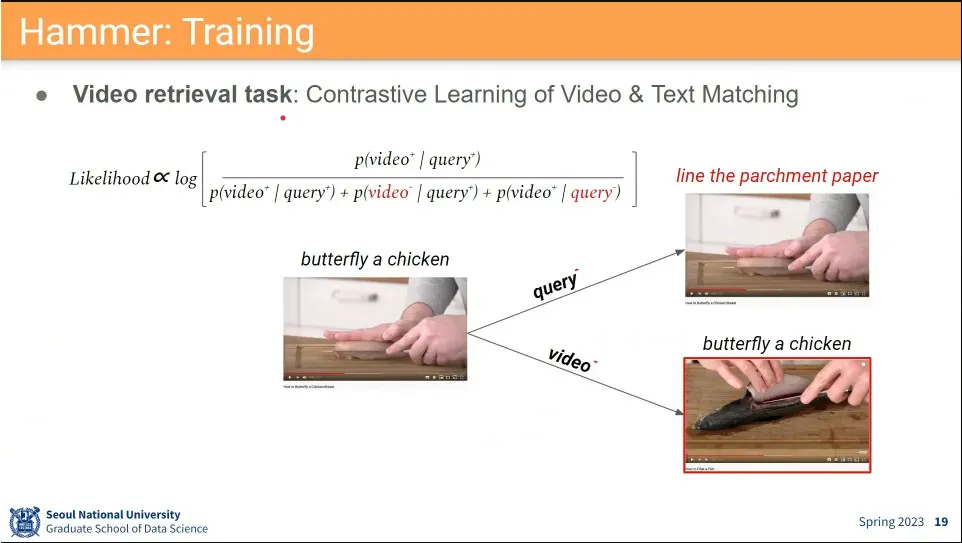
qeury가 주어졌을 때, 그 moment를 찾기 위해 베이지안 룰을 사용
◦
우선 query에 해당하는 video를 찾고
◦
그 찾아진 video와 query를 이용해서 video에서 moment를 찾는다.
•
video 검색에는 contrastive learning을 사용.
◦
negative pair를 text를 바꾸거나 image를 바꾸어서 만들어 줌.
◦
이렇게 충분히 큰 데이터셋에서 학습 시키면 잘 align 된다.

•
video 내 localization 분류를 위해 begin, end, other를 나눠서 함
•
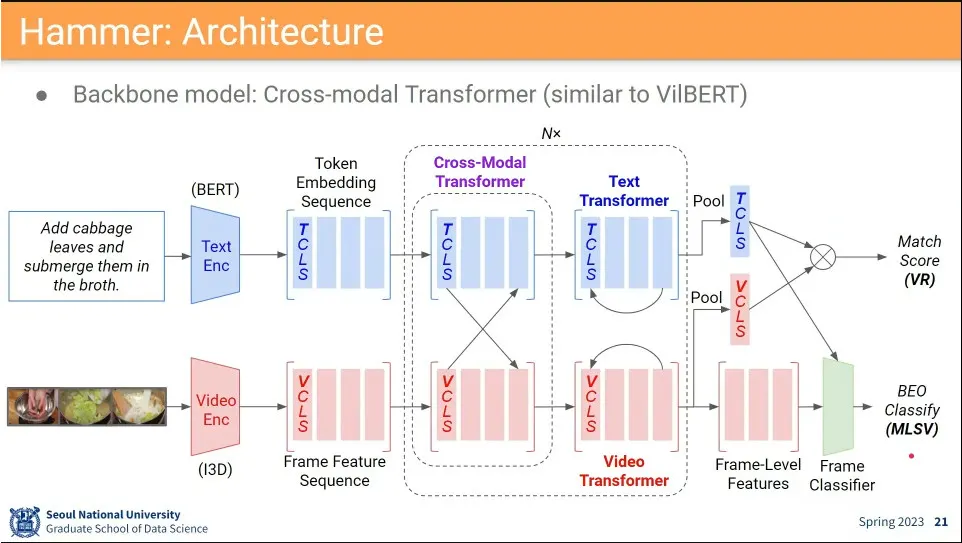
Hammer 아키텍쳐
◦
기본적으로 VilBERT와 동일한데, 마지막에 frame classifier 하는 부분만 차이가 있음.

•
그냥 하면 성능이 잘 안 나와서, 일정 간격의 clip들로 쪼개서 frame별로 돌리고 그 결과를 clip으로 묶어서 다시 한번 돌림.
◦
조금 성능 개선이 되긴 했지만, 크게 올라가진 않음.

•
결과 예시

•
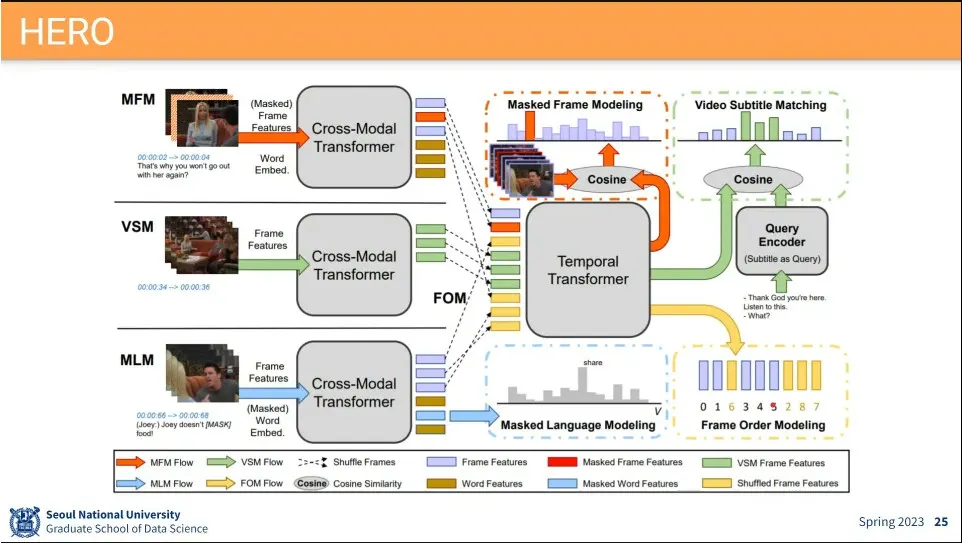
기존 아이디어를 다 합쳐서 사용한게 HERO
◦
별로 성능이 좋지 않았음
•
아키텍쳐

•
새로운 아이디어는 별로 도움이 안 됐다.

•
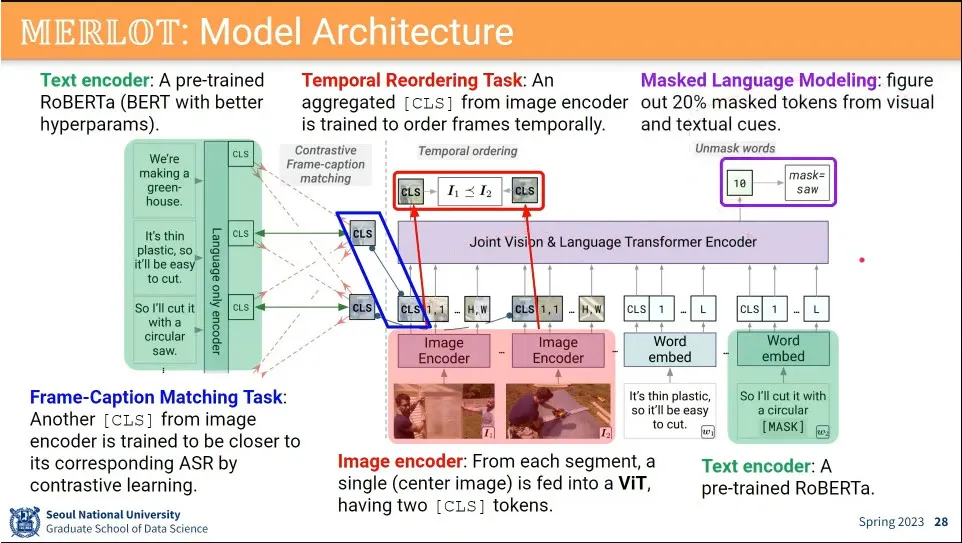
기존 아이디어들을 사용해서 했는데, 성능이 잘 나왔음.
◦
그 이유는 데이터셋 덕분이라고 추측 됨.
•
모델 아키텍쳐
◦
기존 아이디어들을 조합해서 사용 함.

•
데이터셋 수집을 잘 함.
◦
27M 유튜브 비디오를 수집해서 잘 정제해서 6M 정도로 만들어서 사용함.


•
성능이 잘 나왔다.
◦
기존 아이디어들이 데이터와 컴퓨팅 파워가 부족했는데, 그걸 잘 하니 잘 되더라.
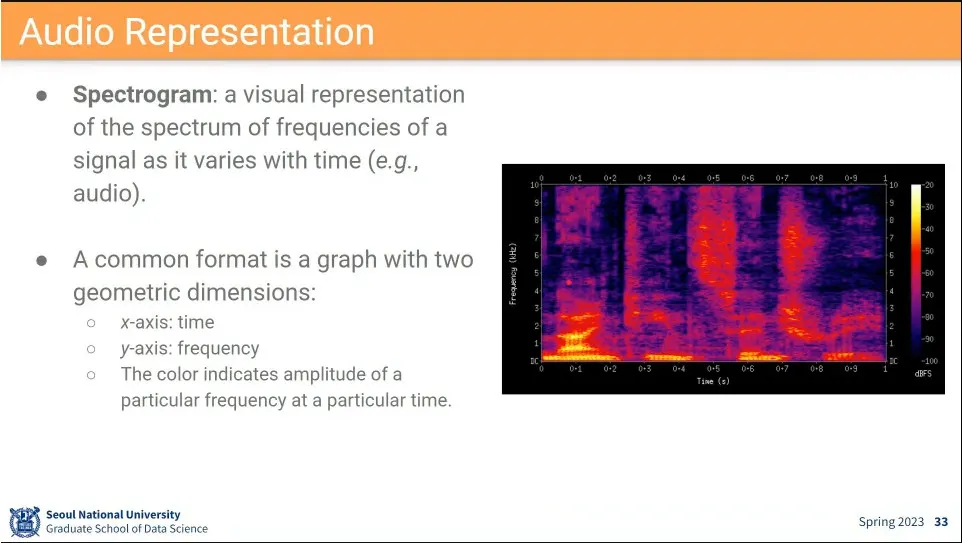
•
Audio는 visual이랑 비슷하게 함.
◦
2차원 공간에 소리를 시각화하는걸 spectrogram이라고 함.
◦
(근데 whisper 같은 경우는 이렇게 시각화하지 않고 그냥 conv1d를 사용함)
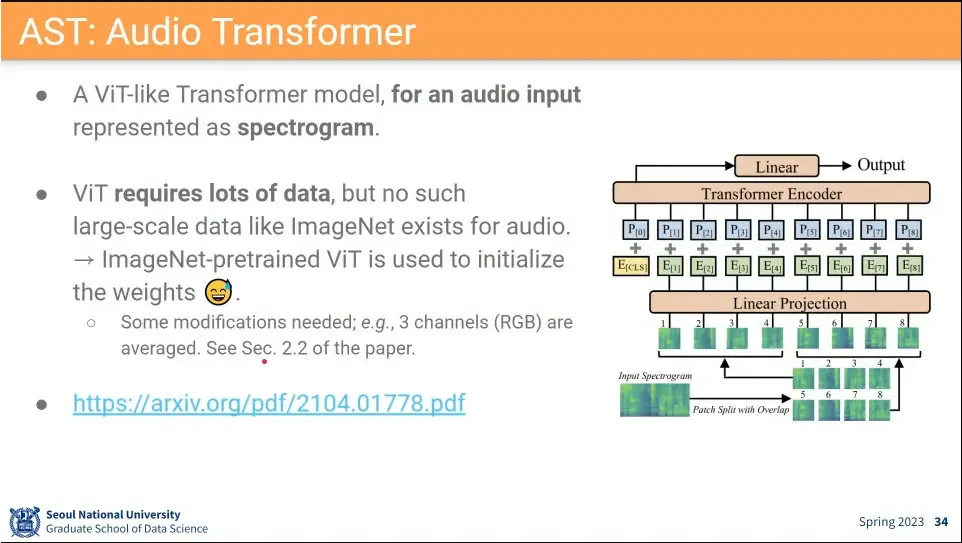
•
그렇게 visual로 바꾼 정보에 대해 transformer 돌림.
•
transformer가 cnn을 이긴 이유가 데이터셋이 커서인데, audio는 그런 데이터셋이 없음.
◦
그래서 ImageNet에서 pretrained된 모델을 가져와서 audio 용으로 학습함.
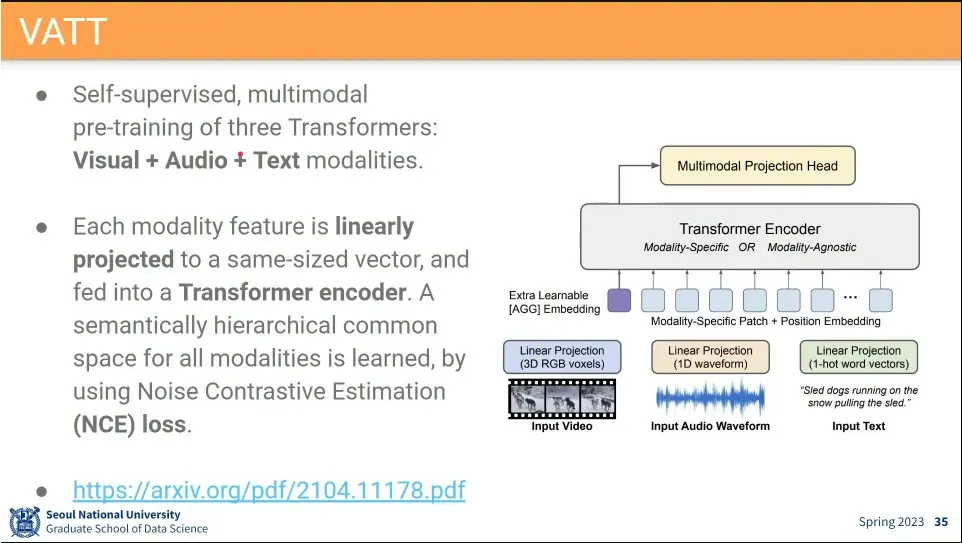
•
VAAT는 visual, audio, text를 모두 사용하는 모델.
◦
visual도 linear projection하고, audio도 바꿔주고, text도 embedding해서 한 번에 넣음
◦
loss는 NCE loss를 사용

•
학습은 3가지를 한 번에 안 함.
◦
visual과 audio는 1:1 매칭이 쉬워서 같은 시간이었으면 가까워지게 하고, 다른 시간이었으면 멀어지게 함.
◦
text는 그 자체가 sequence라서 하나로 통합해야 함. 그래서 sum해서 사용한 (이게 MIL_NCE)
◦
그렇게 sum한 것을 audio-visual embedding과 contrastive learning 함.
•
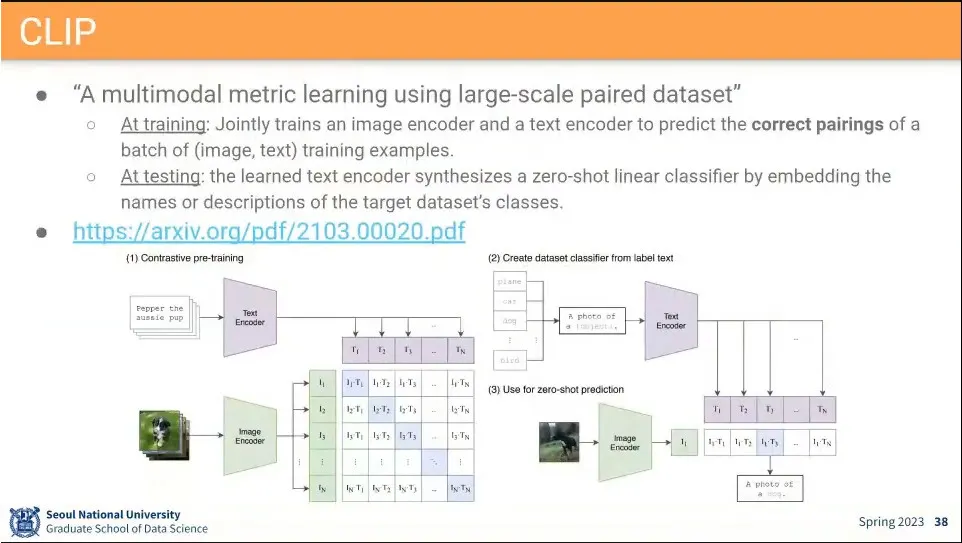
Multimodal은 metric learning이 대세이고, CLIP이 그냥 끝냄.
◦
모델이 단순한데, 데이터 파워로 끝냄.
•
Text feature와 image feature에 대해 가까운 것은 1이 나오게 하고, 그 외의 것은 0이 나오게 학습 시킴. contrastive learning
◦
이렇게 학습된 결과가 잘 나오면 흥미롭게도 Identity Matrix처럼 보이게 됨.
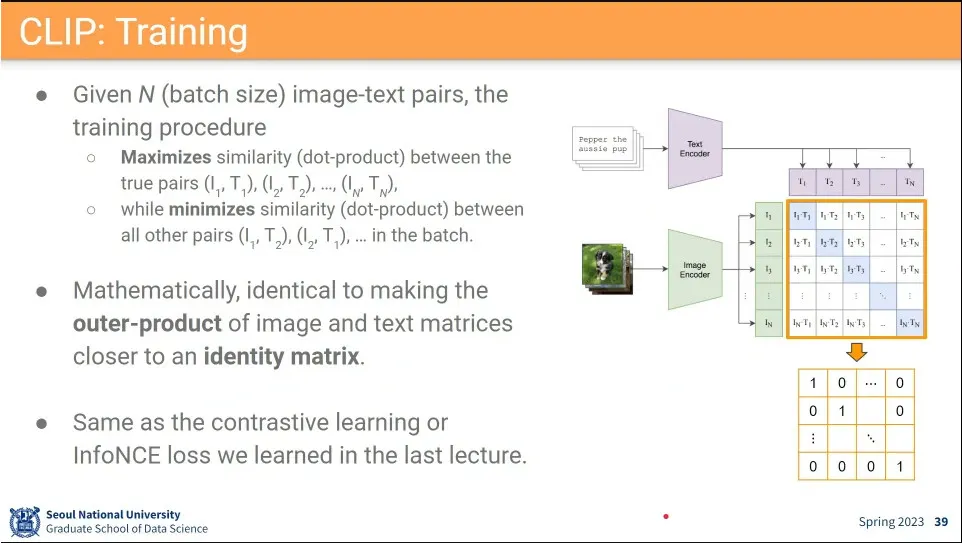
•
학습 결과는 Identity matrix가 됨.

•
이 embedding이 대단히 강력해서 BERT도 넘어서고, 이후 모델들은 그냥 CLIP을 가져다 씀
◦
실제로 stable diffusion도 그냥 clip을 가져다 씀.
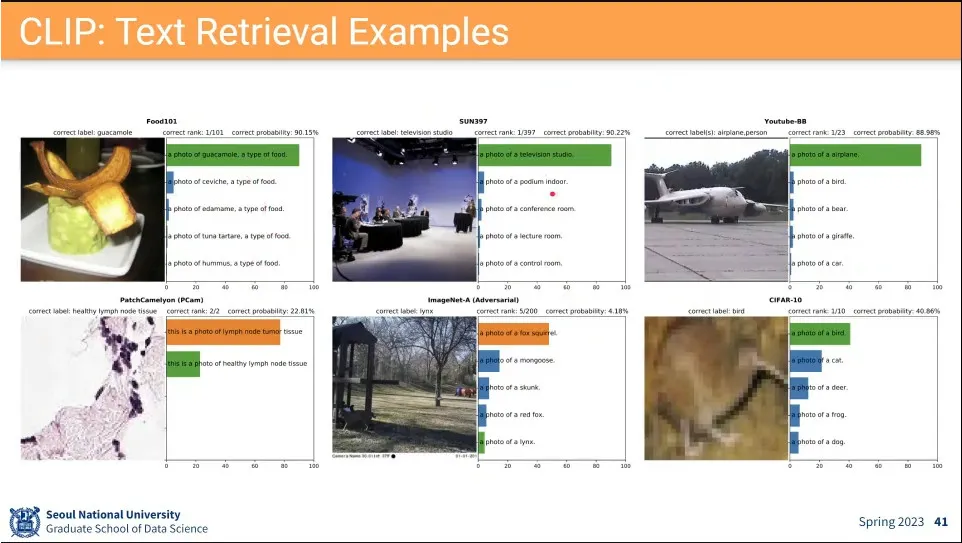
•
사례

•
MuLan은 Audio에 대한 CLIP
◦
visual 대신 audio와 text에 pair 대해 clip 처럼 돌림.
◦
music과 language라서 모델 이름이 mulan임
