
Transformer
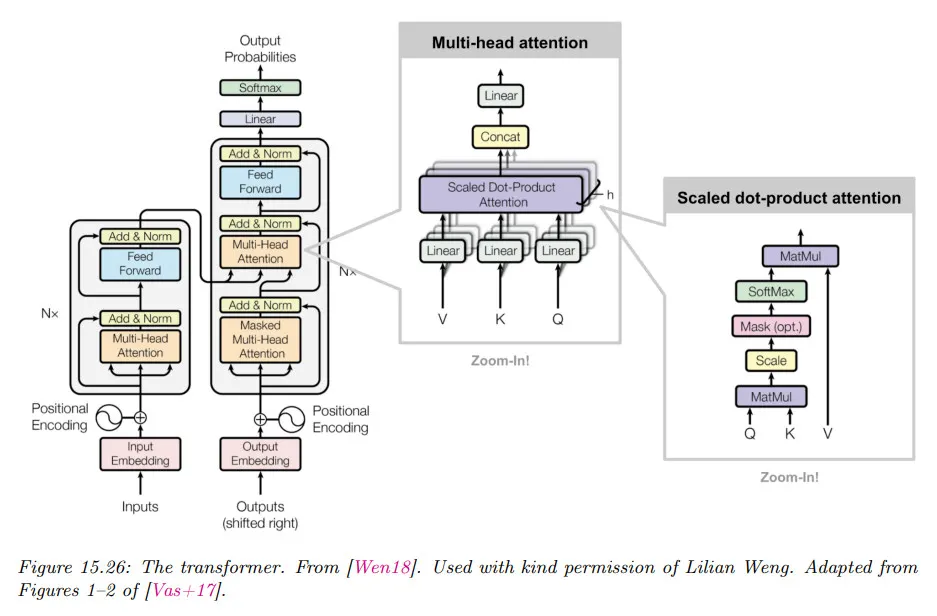
Multi-headed Self-Attention
Transformer의 가장 핵심적인 부분은 multi-headed self-attention이다. 우선 self-attention이라는 것은 attention의 를 모두 입력 를 이용해서 만든다는 뜻이다. (모델에 따라 를 decoder의 출력을 사용하고 를 encoder의 출력을 사용할 수도 있다.)
self-attention은 입력이 자신 뿐만 아니라 배치 내에 자신과 함께 입력된 다른 입력의 정보도 함께 반영한다는 의미를 갖는다. 다시 말해 입력에 context가 반영된다.
Multi-headed는 하나의 단어가 여러 의미를 가질 수 있음을 고려하여 attention을 여러 개를 사용한다는 의미이다. 이를 위해 head 수 만큼의 attention을 수행하고, 이를 최종적으로 다시 하나의 출력으로 만든다.
더 자세히 말해서 query , key , value 가 주어질 때 -번째 attention head를 다음과 같이 정의할 수 있다. 여기서 는 투영(projection) 행렬이다
그 다음 head를 개 함께 쌓고(stack), 다음을 사용하여 를 투영(project)할 수 있다.
여기서 는 를 쌓은 것과 곱해서 최초 입력의 크기로 되돌리는 역할을 한다. 따라서 Multi-headed attention은 의 4개의 가중치를 학습하게 된다.
(이해의 편의를 위해 head 수 만큼 쌓았다가 입력 크기로 줄이는 식으로 설명했으나, 실제로는 성능과 효율성을 위해 head 수로 나눈 후에 다시 원래 출력으로 확장하는 식으로 표현된다. 아래 sample 코드 참조)
Position-wise Feed Forward
Transformer에서 가장 중요한 부분이 Multi-headed Self-Attention이지만, attention은 입력에 대해 맥락 정보를 부여할 뿐, 맥락이 부여된 정보를 이용하여 데이터에 대한 실제 이해를 저장하는 곳은 Attention Block 다음에 수행되는 Fully Connected Layer에서 일어난다고 알려져있다.
Transformer에서는 Attention Block 후에 크기를 키웠다가 줄이는 형태로 2개의 Linear를 사용하여 Feed Forward Layer를 구성하고 이를 Position-wise Feed Forward라고 한다. 아래 sample 코드 참조.
Auto-Regressive Model
Transformer의 Encoder는 입력을 Encoding하는 역할만 수행하므로 입력 문장을 전체로 받아 학습한다. 입력의 학습은 Decoder의 출력에 대한 loss의 역전파를 통해 이루어진다.
Transformer의 Decoder는 입력이 주어지면 Encoder를 출력을 참조하여 출력을 생성하고, 그 출력을 다시 다음 단계 입력에 추가하여 새로운 출력을 생성하는 auto-regressive한 방식으로 실행된다. Decoder의 학습은 각 출력에 대해 target에 대한 loss을 구해 역전파를 수행한다.
예컨대 ‘hello, my name is suyeong park’ 이라는 문장을 입력으로 받아 ‘안녕하세요 제 이름은 박 수영 입니다’이라는 문장을 출력하는 것을 학습한다고 하자. (이것은 번역 task이다.)
이 경우 encoder에는 전체 문장이 하나의 입력으로 주어진다. 이것이 올바르게 encoding 되었는지 판별할 수 있는 방법은 decoder의 출력에 대해 역전파를 수행하는 것 밖에 없다.
[‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
Plain Text
복사
decoder에서는 입력이 주어지면 그에 맞는 출력을 생성하고 현재 생성된 출력은 다음 단계의 입력에 추가되어 새로운 출력을 생성한다. 출력을 생성할 때는 단순히 입력 token만 보지 않고 encoder의 encoding 결과도 함께 참조한다.
step 1.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>]
출력: ['안녕하세요']
step 2.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요']
출력: ['제']
step 3.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제']
출력: ['이름은']
step 4.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은']
출력: ['박']
step 5.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박']
출력: ['수영']
step 6.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박', '수영']
출력: ['입니다']
step 7.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박', '수영', '입니다']
출력: [<eos>]
Plain Text
복사
이것은 inference가 동작하는 방식과 동일하다.
parallel training
Transformer의 강점 중 하나는 병렬로 학습이 가능하다는 것이다. 덕분에 학습 시간을 줄여서 대규모 학습 데이터를 사용하여 모델의 성능을 높일 수 있었고, 현세대를 주도하는 모델이 되었다
위의 예시에 대해 1-7단계를 순차적으로 진행하지 않고 병렬로 처리하는 것이 가능하다. 다만 병렬로 학습하려면 입력의 크기가 동일해야 하는데, 전체 입력을 그대로 사용하면 decoder가 정답을 보고 출력을 생성할 수 있기 때문에, 현재 출력을 생성하기 이전의 입력만 제공하고 나머지는 masking을 통해 입력을 가려야 한다. 아래 예시 참조
1.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, 0, 0, 0, 0, 0, 0]
출력: ['안녕하세요']
2.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', 0, 0, 0, 0, 0]
출력: ['제']
3.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', 0, 0, 0, 0]
출력: ['이름은']
4.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', 0, 0, 0]
출력: ['박']
5.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박', 0, 0]
출력: ['수영']
6.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박', '수영', 0]
출력: ['입니다']
7.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박', '수영', '입니다']
출력: [<eos>]
Plain Text
복사
위의 예시 데이터를 행렬 형태로 표현하면 대각성분 아래에만 데이터가 있고 그 위에는 0으로 채워지는 하삼각행렬이 만들어진다. 구현 예는 Sample의 subsequent_mask() 함수 참조
Teacher forcing
auto-regressive한 방식으로 모델의 출력을 decoder의 다음 입력으로 활용하는 기본이지만 실제 Transformer 모델을 학습할 때는 성능을 높이기 위해 모델의 출력이 아니라 실제 정답을 다음 입력으로 사용하는데 이것을 teacher forcing이라고 부른다. 아래 예시 참조. (앞의 parallel 학습을 수행하면 Teacher Forcing이 자연스럽게 수행된다.)
1.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, 0, 0, 0, 0, 0, 0]
모델 출력: ['안녕']
2.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', 0, 0, 0, 0, 0]
모델 출력: ['오늘은']
3.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', 0, 0, 0, 0]
모델 출력: ['얼굴이']
4.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', 0, 0, 0]
모델 출력: ['박수영']
5.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박', 0, 0]
모델 출력: ['입니다']
6.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박', '수영', 0]
모델 출력: ['에요']
7.
encoder: [‘hello’, ‘my’, ‘name’, ‘is’, ‘suyeong’, ‘park’]
입력: [<start>, '안녕하세요', '제', '이름은', '박', '수영', '입니다']
모델 출력: [<eos>]
Plain Text
복사
Sample Code
Model
Sinusoidal Positional Encoding
sinusoidal 을 이용하여 길이에 대해 unique한 embedding을 생성한다. sinusoidal에 대한 자세한 내용은 아래 참조
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# positional encoding의 수식대로 값을 구한다.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
# positional encoding은 학습되는 파라미터가 아니므로 requires_grad_(False)
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
Python
복사
Rotary Positional Embedding(RoPE)
원래의 Transformer는 sin, cos을 이용하여 절대적 위치 정보를 반영하는 sinusoidal position encoding을 사용했으나, 이후 이런 방식이 long-context에서 성능이 떨어진다는 것이 발견되고 이를 개선하기 위해 Rotary Positional Embedding을 이용한 상대적 위치 인코딩 방식이 등장했다. RoPE에 대한 자세한 내용은 아래 참조
import torch
def apply_rope(x, dim):
"""
x: (batch_size, seq_len, d_model)
dim: 임베딩 차원의 절반 크기
"""
batch_size, seq_len, d_model = x.shape
theta = 10000 ** (-2 * (torch.arange(0, dim, 2).float()) / d_model) # RoPE 각도 값
theta = theta.to(x.device) # GPU에 맞게 이동
t = torch.arange(seq_len, device=x.device).float().unsqueeze(1) # 위치 인덱스
# 회전 변환을 위한 사인 및 코사인 값 계산
sin_t = torch.sin(t * theta)
cos_t = torch.cos(t * theta)
# x를 (batch, seq_len, dim//2, 2) 형태로 변환하여 적용
x_reshaped = x.view(batch_size, seq_len, -1, 2) # [batch, seq_len, dim//2, 2]
x_rotated = torch.cat([
x_reshaped[..., 0] * cos_t - x_reshaped[..., 1] * sin_t,
x_reshaped[..., 0] * sin_t + x_reshaped[..., 1] * cos_t
], dim=-1) # 다시 원래 차원으로 변환
return x_rotated.view(batch_size, seq_len, d_model) # 원래 차원으로 변환
Python
복사
forward에서는 아래처럼 적용하면 된다.
class MultiheadAttention(torch.nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.q_proj = torch.nn.Linear(d_model, d_model)
self.k_proj = torch.nn.Linear(d_model, d_model)
self.v_proj = torch.nn.Linear(d_model, d_model)
# ... 이하 생략
def forward(self, query, key, value):
q = self.q_proj(query)
k = self.k_proj(key)
v = self.v_proj(value)
# RoPE 적용 (Q와 K에만 적용)
q = apply_rope(q, q.shape[-1] // 2)
k = apply_rope(k, k.shape[-1] // 2)
# ... 이하 생략
Python
복사
Embeddings
nn.Embedding 결과는 일반적으로 작은 값의 범위로 설정되는데, 이러면 attention 내적 값이 너무 작아져서 효율성이 떨어질 수 있다. 이를 방지하기 위해 다음과 같이 embedding의 scale을 조정하는 용도로 d_model의 제곱근을 곱해서 사용함.
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
Python
복사
LayerNorm
layer normalization은 입력의 평균과 표준편차를 이용해서 계산한다.
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
# normalization에서 학습되는 파라미터
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
Python
복사
Multi-headed Attention Block
Multi-headed Attention Block은 입력을 projection 한 후에 head 수로 나누어서 계산한다. 원래 개념상 projection 결과를 head 수 만큼 곱하고 그것들을 stack하고 최종적으로 입력 크기로 축소 하는데, 실제로는 projection 결과를 그냥 head 수로 나누고 차원만 늘려서 —이러면 projection 결과를 head 수 만큼 분할하게 됨— 계산한 후에 최종적으로 입력 크기로 되돌리도록 구성됨.
class MultiheadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout, bias=True):
super(MultiheadAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = d_model // num_heads # embedding 차원을 head 수로 나눈다.
self.attention_weight = None
assert self.head_dim * num_heads == d_model, "embed_dim must be divisible by num_heads"
# q, k, v, out의 input, output 차원이 모두 동일함.
self.q_proj = nn.Linear(d_model, d_model, bias=bias)
self.k_proj = nn.Linear(d_model, d_model, bias=bias)
self.v_proj = nn.Linear(d_model, d_model, bias=bias)
self.out_proj = nn.Linear(d_model, d_model, bias=bias)
self.dropout = nn.Dropout(dropout)
# self-attention이기 때문에 query, key, value는 입력 x가 된다.
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 우선 query, key, value를 projection 한다.
q = self.q_proj(query)
k = self.k_proj(key)
v = self.v_proj(value)
# [bath_size, seq_length, embed_dim] 차원을 [batch_size, seq_length, num_heads, head_dim] 차원으로 변환한다.
q = q.contiguous().view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
k = k.contiguous().view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
v = v.contiguous().view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
# qk의 곱이 너무 커지지 않도록 d_k로 나누는 부분
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
# mask가 있었으면 씌운다. mask는 decoder에서 사용된다.
if mask is not None:
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
# scores의 결과를 softmax()에 통과시켜서 attention_weight를 얻는다
# attention_weight를 self에 저장하는 것은 heatmap 때문
self.attention_weight = scores.softmax(dim=-1)
# dropout
self.attention_weight = self.dropout(self.attention_weight)
# attention_weight를 value와 곱해 output을 구한다.
output = torch.matmul(self.attention_weight, v)
# 입력 크기로 되돌리기 위해 [batch_size, seq_length, num_heads, head_dim] 차원 다시 [bath_size, seq_length, embed_dim] 차원으로 되돌린다.
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.head_dim)
# 최종 output projection
output = self.out_proj(output)
return output
Python
복사
Multi-headed Attention Block with KV Cache
위의 Attention 코드는 순수하게 Query, Key, Value만 이용한 multi-head attention을 보여주는데, 이것은 Training 단계에서는 유효하지만, Inference 단계에서는 이전 step에서 생성한 Key-Value를 이용해서 다음 token을 예측하는데, 이 경우 매번 Key, Value를 새로 계산하면 낭비가 심하므로, Key, Value를 저장해서 다음 step에 재사용하면 계산 비용을 아끼는 편이 낫다. 이를 위해 아래 코드 처럼 Key, Value를 저장하는 KV Cache를 활용하는 형태로 코드를 변경할 수 있다.
결국 query는 최초에는 사용자의 입력이 query로 사용되고, 이후 step에서는 이전 step의 출력이 query로 사용되고, key, value는 최초에는 사용자의 입력이 각각 key, value로 사용되고, 이후에는 이전 step의 출력을 기존 key, value에 concatenate 하여 사용된다. 결국 query는 항상 이전 모든 step의 출력(과 최초 입력)에 대해 attention하여 새로운 출력을 생성하는 것을 반복하게 된다.
실제로는 Transformer의 MHA block이 여러 개 쌓여서 수행되므로 가장 하단의 layer가 아닌 이상 입력은 이전 step의 출력이 아니라 이전 layer의 출력이 된다.
class MultiheadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout, bias=True, use_kv_cache=False):
super(MultiheadAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.attention_weight = None
self.use_kv_cache = use_kv_cache # KV Cache 사용 여부
assert self.head_dim * num_heads == d_model, "embed_dim must be divisible by num_heads"
self.q_proj = nn.Linear(d_model, d_model, bias=bias)
self.k_proj = nn.Linear(d_model, d_model, bias=bias)
self.v_proj = nn.Linear(d_model, d_model, bias=bias)
self.out_proj = nn.Linear(d_model, d_model, bias=bias)
self.dropout = nn.Dropout(dropout)
# KV Cache를 저장하는 변수
self.k_cache = None
self.v_cache = None
def forward(self, query, key, value, mask=None, use_cache=False):
batch_size = query.size(0)
# Query, Key, Value 생성
q = self.q_proj(query)
# KV 캐시 사용 여부에 따라 기존 Key-Value를 유지
if self.use_kv_cache and self.k_cache is not None and self.v_cache is not None:
k = torch.cat([self.k_cache, self.k_proj(key)], dim=1) # 기존 Key와 새로운 Key 결합
v = torch.cat([self.v_cache, self.v_proj(value)], dim=1) # 기존 Value와 새로운 Value 결합
else:
k = self.k_proj(key)
v = self.v_proj(value)
# KV 캐시 업데이트 (현재 Key, Value 저장)
if self.use_kv_cache:
self.k_cache = k
self.v_cache = v
# Multi-Head Attention 연산 수행
q = q.contiguous().view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
k = k.contiguous().view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
v = v.contiguous().view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
if mask is not None:
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
self.attention_weight = scores.softmax(dim=-1)
self.attention_weight = self.dropout(self.attention_weight)
output = torch.matmul(self.attention_weight, v)
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.head_dim)
output = self.out_proj(output)
return output
Python
복사
Position-wise Feed Forward
MultiheadAttention을 수행한 후 FeedForward를 수행하는데, 이때 Linear를 2번 수행한다. 처음 linear는 크기를 d_ff 만큼 확장한 후에 두 번째 linear에서 다시 d_model 크기로 축소하는 형식으로 수행된다.
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))
Python
복사
Encoder Block
Encoder Block은 MultiHeadAttention과 Position-wise Feed Forward로 구성되고 이들을 연결할 때 residual connection과 layer norm을 사용한다.
class EncoderBlock(nn.Module):
def __init__(self, d_model, d_ff, n_heads, dropout):
super(EncoderBlock, self).__init__()
self.attn = MultiheadAttention(d_model, n_heads, dropout)
self.ff = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = LayerNorm(d_model)
self.norm2 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
x_norm1 = self.norm1(x)
x = x + self.dropout1(self.attn(x_norm1, x_norm1, x_norm1, mask))
x_norm2 = self.norm2(x)
x = x + self.dropout2(self.ff(x_norm2))
return x
Python
복사
Encoder
Encoder는 입력을 embedding 한 후에 PositionalEncoding을 추가하고 Encoder Block을 n번 수행하는 식으로 구성된다. Encoder Block을 통과한 후에 Layer Normalization을 수행하고 반환
class Encoder(nn.Module):
def __init__(self, N, vocab, d_model, d_ff, n_heads, dropout):
super(Encoder, self).__init__()
self.embedding = Embeddings(d_model, vocab)
self.positionalEncoding = PositionalEncoding(d_model, dropout)
self.encoderBlock = EncoderBlock(d_model, d_ff, n_heads, dropout)
self.layerNorm = LayerNorm(d_model)
self.N = N
def forward(self, x, mask=None):
x = self.positionalEncoding(self.embedding(x))
for _ in range(self.N):
x = self.encoderBlock(x, mask)
return self.layerNorm(x)
Python
복사
Decoder Block
Decoder Block은 Encoder Block과 유사하지만 encoder의 output을 받아서 MultiHeadAttention을 한 번 더 수행한다는 점이 차이가 있다.
class DecoderBlock(nn.Module):
def __init__(self, d_model, d_ff, n_heads, dropout):
super(DecoderBlock, self).__init__()
self.self_attn = MultiheadAttention(d_model, n_heads, dropout)
self.src_attn = MultiheadAttention(d_model, n_heads, dropout)
self.ff = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = LayerNorm(d_model)
self.norm2 = LayerNorm(d_model)
self.norm3 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
# memory에는 encoder의 output이 들어온다.
def forward(self, x, memory, src_mask, tgt_mask):
x_norm1 = self.norm1(x)
x = x + self.dropout1(self.self_attn(x_norm1, x_norm1, x_norm1, tgt_mask))
# encoder에서 들어오는 memory는 normalize 하지 않는다.
x_norm2 = self.norm2(x)
x = x + self.dropout2(self.src_attn(x_norm2, memory, memory, src_mask))
x_norm3 = self.norm3(x)
x = x + self.dropout3(self.ff(x_norm3))
return x
Python
복사
Decoder
Decoder는 Encoder와 매우 유사하지만 encoder의 output을 받는다는 점이 다르다.
class Decoder(nn.Module):
def __init__(self, N, vocab, d_model, d_ff, n_heads, dropout):
super(Decoder, self).__init__()
self.embedding = Embeddings(d_model, vocab)
self.positionalEncoding = PositionalEncoding(d_model, dropout)
self.decoderBlock = DecoderBlock(d_model, d_ff, n_heads, dropout)
self.layerNorm = LayerNorm(d_model)
self.N = N
def forward(self, x, memory, src_mask, target_mask):
x = self.positionalEncoding(self.embedding(x))
for _ in range(self.N):
x = self.decoderBlock(x, memory, src_mask, target_mask)
return self.layerNorm(x)
Python
복사
Generator
Generator는 Decoder의 output을 받아 실제 사용자가 제시할 결과를 생성한다. 이를 위해 Decoder의 output을 Linear를 통과시킨 후 softmax 함수를 이용해서 최종 단어를 뽑는다.
class Generator(nn.Module):
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1)
Python
복사
Transformer
앞서 정의한 Encoder, Decoder, Generator를 모아 Transformer 모델을 만든다.
class Transformer(nn.Module):
def __init__(self, N, src_vocab, tgt_vocab, d_model, d_ff, n_heads, dropout):
super(Transformer, self).__init__()
self.encoder = Encoder(N, src_vocab, d_model, d_ff, n_heads, dropout)
self.decoder = Decoder(N, tgt_vocab, d_model, d_ff, n_heads, dropout)
self.generator = Generator(d_model, tgt_vocab)
def forward(self, source, target, src_mask, tgt_mask):
x = self.encode(source, src_mask)
x = self.decode(target, x, src_mask, tgt_mask)
return x
def encode(self, source, src_mask):
return self.encoder(source, src_mask)
def decode(self, target, memory, src_mask, tgt_mask):
return self.decoder(target, memory, src_mask, tgt_mask)
def generate(self, x):
return self.generator(x)
Python
복사
subsquent_mask
decoder 학습 시 병렬처리를 위해 미래 입력을 가리는 subsequent_mask 함수를 만든다.
# i 번째 token을 생성할 때 1 ~ i-1의 token은 안 보이도록 masking 한다.
def subsequent_mask(size):
# 마스크를 씌우기 위한 size
attn_shape = (1, size, size)
# triu는 상삼각행렬을 구성한다.
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(torch.uint8)
# 행렬에서 0인 부분은 true로 만들고 그 외는 false가 만든다
# 결과적으로 대각 이하 부분의 데이터만 남고 대각 이상 부분은 mask를 씌우게 됨
return subsequent_mask == 0
Python
복사
Objective
Annotated Transformer에서 loss는 KL divergence(KLDivLoss)를 사용하며, 다음처럼 정답(target)을 smoothing하여 예측에 대한 loss를 계산한다. 정답을 smoothing하는 이유는 모델이 과도하게 확신하는 것을 방지하여 일반화 성능을 높이기 위한 것이다.
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction="sum")
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx) # target에서 padding 인덱스 부분을 0으로 채움
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, true_dist.clone().detach())
Python
복사
Train
학습은 아래처럼 할 수 있다. 데이터를 load 하는 것을 포함하여 기타 처리는 생략하였으므로 원본 코드 참조.
def run_epoch(
data_iter,
model,
loss_compute,
optimizer,
scheduler,
mode="train",
accum_iter=1,
train_state=TrainState(),
):
"""Train a single epoch"""
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
n_accum = 0
for i, batch in enumerate(data_iter):
out = model.forward(
batch.src, batch.tgt, batch.src_mask, batch.tgt_mask
)
loss, loss_node = loss_compute(out, batch.tgt_y, batch.ntokens)
# loss_node = loss_node / accum_iter
if mode == "train" or mode == "train+log":
loss_node.backward()
train_state.step += 1
train_state.samples += batch.src.shape[0]
train_state.tokens += batch.ntokens
if i % accum_iter == 0:
optimizer.step()
optimizer.zero_grad(set_to_none=True)
n_accum += 1
train_state.accum_step += 1
scheduler.step()
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 40 == 1 and (mode == "train" or mode == "train+log"):
lr = optimizer.param_groups[0]["lr"]
elapsed = time.time() - start
print(
(
"Epoch Step: %6d | Accumulation Step: %3d | Loss: %6.2f "
+ "| Tokens / Sec: %7.1f | Learning Rate: %6.1e"
)
% (i, n_accum, loss / batch.ntokens, tokens / elapsed, lr)
)
start = time.time()
tokens = 0
del loss
del loss_node
return total_loss / total_tokens, train_state
Python
복사
