
Abstract
지난 몇 년간 Transformer를 더 긴 시퀀스 길이로 확장하는 것이 주요한 문제였다. 이를 통해 언어 모델링과 고해상도 이미지 이해 성능 향상 뿐만 아니라 코드, 오디오, 비디오 생성 등의 새로운 응용을 열 수 있었다. attention 레이어는 실행 시간과 메모리 사용량이 시퀀스 길이에 따라 2차적으로 증가하기 때문에 더 긴 시퀀스로 확장하는 것에 주요 병목이다. FlashAttention은 비대칭 GPU 메모리 계층구조를 활용하여 근사 없이 상당한 메모리 절약(2차 대신 선형), 실행 속도(최적화된 baseline과 비교하여 2-4배) 개선을 가져왔다. 그러나 FlashAttention은 여전히 최적화된 행렬 곱(GEMM) 연산에 근접하지 못해서 이론적 최대 FLOPs/s의 25-40% 에 불과하다. 우리는 이러한 비효율성이 GPU의 다른 thread 블록과 warps 사이의 분할 작업이 suboptimal이기 때문이라고 관찰했다. 이로 인해 점유율이 낮거나 불필요한 공유 메모리 읽기/쓰기가 발생한다. 우리는 작업 분할을 개선한 FlashAttention-2를 제안한다. 특히 (1) 알고리즘을 비틀어서 non-matmul FLOPs의 수를 줄이고, (2) 점유율을 높이기 위해 단일 head에 대해서도 attention 계산을 다른 thread 블록에 병렬화하고, (3) 각 thread 블록 내에서 wraps 사이의 작업을 분배하여 공유된 메모리를 통한 커뮤니케이션을 줄인다. 이를 통해 FlashAttention과 비교하여 2배 이상 빠르고, A100에서 이론적 최대 FLOPs/s의 50-73%에 도달하며 GEMM 연산의 효율성에 근접한다. 우리는 GPT-style 모델 학습에 FlashAttention-2를 end-to-end로 사용할 때 A100 GPU 당 최대 225 TFLOPs/s의 학습 속도(72% 모델 FLOP 활용도)에 도달함을 경험적으로 검증했다.
1 Introduction
Transformer의 컨텍스트 길이를 확장하는 것은 그것의 핵심인 attention 레이어의 실행 시간과 메모리 요구량이 시퀀스 길이에 따라 2차적이기 때문에 도전적이다. 이상적으로는 표준 2k 시퀀스 길이 한계를 넘어서 책, 고해상도 이미지와 장편 비디오를 이해할 수 있는 모델을 학습시키기를 원한다. 지난 1년간 기존 보다 훨씬 더 긴 컨텍스트를 사용하는 여러 언어 모델이 등장했다. GPT-4는 32k 컨텍스트 길이를 사용하며, MosaicML은 컨텍스트 길이 65k를 사용하고, Anthropic의 Claude는 컨텍스트 길이 100k를 사용한다. 긴 문서 쿼리와 이야기 작성 같은 새로운 사례는 이러한 긴 컨텍스트를 사용하는 모델에 대한 요구를 나타낸다.
이런 긴 컨텍스트에 대한 attention의 계산적 요구량을 줄이기 위해 attention을 근사하는 많은 방법들이 제안되었다. 이런 방법들이 일부 사례에서 활용되고 있지만, 우리가 아는 한 대부분의 대규모 학습에서는 여전히 표준 attention을 사용한다. 이것에 동기 부여를 받아 Dao et al은 attention 계산을 reorder하고 전통적인 기법(tiling, recomputation)을 활용하여 속도를 크게 높이고 메모리 사용량을 시퀀스 길이에 따라 2차에서 선형으로 줄였다. 이것은 근사를 사용하지 않고도 최적화된 baseline에 비해 2-4배 실제 시간 속도 개선을 산출했고, 10-20배까지 메모리를 절약했다. 결과적으로 FlashAttention은 Transformer의 대규모 학습과 추론에 널리 채택되었다.
그러나 컨텍스트 길이가 더 증가하면 FlashAttention은 여전히 matrix-multiply(GEMM) 같은 다른 primitives 만큼 효율적이지 않다. 특히 FlashAttention은 이미 표준 attention 구현 보다 2-4배 빠르지만 forward pass는 디바이스의 이론적 최대 FLOPs/s의 30-50%에 불과하다(그림 5). backward pass는 더 도전적이어서 A100 GPU의 최대 처리량의 25-35%에 불과하다(그림 6). 반면 최적화된 GEMM은 이론적 디바이스 최대 처리량의 80-90%에 도달한다. 조심스럽게 프로파일링하여 우리는 FlashAttention에서 GPU의 다른 thread 블록과 warps 사이의 작업 분할이 suboptimal 임을 관찰했다. 이것은 낮은 점유율 또는 불필요한 공유 메모리 읽기/쓰기의 원인이다.
FlashAttention을 기반으로 이러한 문제를 해결하기 위해 더 나은 병렬화와 작업 분할을 사용하는 FlashAttention2를 제안한다.
1.
섹션 3.1에서 우리는 출력을 변경하지 않고 알고리즘을 비틀어서 non-matmul FLOPs의 수를 줄인다. non-matmul FLOPs가 총 FLOPs의 작은 부분이지만, GPU에는 행렬 곱에 특화된 유닛이 있어서 matmul 처리량이 non-matmul 처리량보다 16배 높을 수 있기 때문에 수행하는데 더 오래 걸린다. 따라서 non-matmul FLOPs을 줄이고 가능한한 많은 시간을 matmul FLOPs에 사용하는 것이 중요하다.
2.
우리는 배치와 head 차원의 수 외에도 시퀀스 길이 차원을 따라 forward pass와 backward pass 모두 병렬화할 것을 제안한다. 이를 통해 시퀀스 길이가 길 때(그리고 따라서 배치 크기가 종종 작음) 점유율(GPU 자원의 활용)을 증가시킨다.
3.
하나의 attention 계산 블록 내에서도 thread block의 다른 warp 사이의 작업을 분할하여 통신과 공유된 메모리 읽기/쓰기를 줄인다.
섹션 4에서 FLashAttention-2가 FlashAttention과 비교하여 큰 속도 개선을 산출한다는 것을 경험적으로 평가한다. 다양한 설정(causal mask를 사용하거나 사용하지 않거나, 다양한 head 차원)에 대한 벤치마크에서 FlashAttention-2가 FlashAttention에 대해 2배 이상 빠르다는 것과 forward pass에서 이론적 최대 처리량의 73%, backward pass에서 이론적 최대 처리량의 63%에 도달하는 것을 보인다. GPT-style 모델을 학습하기 위해 end-to-end를 사용할 때 A100 GPU당 최대 225 TFLOPs/s의 학습 속도에 도달한다.
2 Background
우리는 성능 특징과 GPU의 실행 모델에 대한 일부 배경 지식을 제공한다. 또한 attention의 표준 구현과 FlashAttention도 설명한다.
2.1 Hardware characteristics
GPU performance characteristics.
GPU는 계산 요소(예: floating point 산술 유닛)와 메모리 계층구조로 구성된다. 대부분 최신 GPU는 low-precision 행렬곱 가속화에 특화된 유닛(예: FP16/BF16 행렬 곱에 대한 Nvidia GPU의 Tensor Core)을 포함한다. 메모리 계층구조는 high bandwidth(HBM)과 on-chip SRAM(shared memory라 불림)으로 이루어져 있다. 예컨대 A100 GPU는 bandwidth 1.5-2.0TB/s의 40-80GB HBM과 108개 streaming multiprocessor 각각에 대해 bandwidth가 대략 19TB/s의 192KB on-chip SRAM을 가진다. L2 캐시는 프로그래머가 직접 제어할 수 없기 때문에 이 논의에서 HBM과 SRAM에 초점을 맞춘다.
Execution Model.
GPUs는 연산(kernel이라 불리는)을 수행하기 위해 대규모의 thread를 갖는다. threads는 thread block으로 구성되고, 이것은 streaming multiprocessors(SMs)에서 실행되도록 스케쥴링된다. 각 thread 블록 내부에서 thread는 warps으로 그룹화된다(32개 thread가 1개 group). warp 내의 thread는 빠른 shuffle 명령어를 통해 통신하거나 행렬 곱을 수행하기 위해 협력한다. thread 블록 내 warps는 shared 메모리에서 읽기/쓰기로 통신할 수 있다. 각 커널은 HBM에서 입력을 로드하고 SRAM에 저장하고, 계산하고, 그 다음 출력을 HBM으로 쓴다.
2.2 Standard Attention Implementation
입력 시퀀스 이 (여기서 은 시퀀스 길이이고 는 head 차원) 주어지면 우리는 attention 출력 를 계산하기를 원한다.
여기서 softmax는 행별로 적용된다. multi-head attention(MHA)를 위해 동일한 계산이 여러 head에 걸쳐 병렬로 수행되고, batch 차원에 걸쳐 병렬화된다(배치의 입력 시퀀스 수).
attention의 backward pass는 다음처럼 진행된다. 를 어떤 loss 함수에 대한 의 gradient라고 하자. 그러면 chain rule(backpropagation이라고도 불림)을 따라
여기서 dsoftmax는 행별로 적용된 softmax의 (backward pass) gradient이다. 어떤 벡터 와 에 대해 이면 출력 gradient 를 사용하여 입력 gradient 를 계산할 수 있다.
표준 attention 구현은 행렬 와 를 HBM으로 구체화하며 이는 메모리를 취한다. 종종 (일반적으로 은 1k-8k의 차수이고 는 64-128이다)이다. 표준 attention 구현은 (1) 행렬 곱(GEMM) 서브루틴을 호출하여 를 곱하고 결과를 HBM에 쓴다. 그 다음 (2) HBM에서 를 로드하여 softmax를 계산하고 결과 를 HBM에 쓴다. 마지막으로 (3) GEMM을 호출하여 를 얻는다. 연산의 대부분은 메모리 대역폭에 의해 제한 되므로 메모리 접근 수가 많으면 실행 시간이 느려진다. 게다가 와 를 구체화하기 위해 요구되는 메모리가 이다. 게다가 gradient를 계산하기 위한 backward pass에 대해 을 저장해야 한다.
2.3 FlashAttention
GPU 같은 하드웨어 가속기에서 attention의 속도를 높이기 위해 동일한 출력을 유지하면서 (근사 없이) 메모리 읽기/쓰기를 줄이는 알고리즘을 제안한다.
2.3.1 Forward pass
FlashAttention은 tiling의 전통적인 기법을 적용하여 메모리 IO를 줄인다. (1) 입력의 블록을 HBM에서 SRAM으로 로딩하고, (2) 그 블록에 대해 attention을 계산하고, (3) 큰 중간 행렬 와 를 HBM에 쓰지 않고 출력을 업데이트한다. softmax가 전체 행 또는 행의 블록을 커플링하므로, online softmax는 attention 계산을 블록으로 분할할 수 있고 각 블록의 출력을 rescale하여 최종적으로 (근사 없이) 올바른 결과를 얻을 수 있다. 메모리 읽기/쓰기의 양을 크게 감소시켜서 FlashAttention은 최적화된 baseline attention 구현에 대해 2-4배 빠른 실제 속도를 얻는다.
online softmax 기법과 attention에서 이를 사용하는 방법을 설명한다. 단순성을 위해 attention 행렬 의() 하나의 행 블록만 만 고려한다. 여기서 이고 과 는 행과 열 블록 크기. 이 행 블록의 softmax를 계산하고 값 와 곱하고자 한다. 여기서 . 표준 softmax는 다음을 계산한다.
마지막 식은 원래 논문에는 로 나오는데 오타 같아 보여서 괄호 추가함
FlashAttention1의 논문에서는 알고리즘이 를 먼저 구하고 그것을 합해서 을 구하는 순서로 나오는데 여기는 정규화 상수 을 먼저 구하고 그걸 이용해서 를 구하는 식으로 나온다. 마지막에 를 구하는 방법도 차이가 있음. 그런데 여기서 설명은 을 먼저 구하고 를 구하는 식으로 나오는데, 정작 FlashAttention-2 알고리즘에서는 FlashAttention-1과 마찬가지로 를 먼저 구하고 그걸 이용해서 을 구하는 식으로 나온다.
를 로 빼는 것은 수치적 안정성을 위한 방법으로 FlashAttention1과 동일함. 의 각 항을 로 뺀 후 를 씌운 것을 정규화 상수로 나누면 가 된다. 정규화 상수도 물론 의 각 항을 로 뺀 후 값을 합산함. 최종 이므로 마지막과 같이 계산
대신 online softmax는 각 블록에 대해 ‘local’ softmax를 계산하고 마지막에서 올바른 결과를 얻기 위해 rescale 한다.
원래 논문에서 마지막 줄은 로 되어 있는데, 오타 같아 보여서 를 으로 수정 함.
이것은 online 방식으로 업데이트 하기 때문에 위와 달리 (1)을 먼저 구한 다음 그것을 이용해서 (2)를 업데이트 하는 방식으로 구현된다. online 버전은 batch 버전에 비해 수행 속도가 느리지만, 메모리를 더 아낄 수 있고, 데이터가 순차적으로 존재하는 경우게 사용할 수 있다.
online으로 점진적으로 업데이트 하므로 마지막 항인 가 전체 에 해당한다. 이를 위해 에 해당하는 에다 기존의 의 값을 의 비율로 더한다. 만일 3번째 데이터인 이 추가된다면 같은 식으로 을 구할 수 있다. 이 방법은 online 방식으로 업데이트하는 것으로 각 값을 독립적으로 구한와 같다.
마지막 를 구하는 부분도 유사하게 에 해당하는 값에 기존 의 값을 비율로 곱하여 더하는 식으로 구한다. 그 값은 최종적으로 가 된다. 만일 3번째 데이터인 가 주어진다면 으로 구할 수 있다.
우리는 FlashAttention이 online softmax를 사용하여 tiling을 활성화하여(그림 1) 메모리 읽기/쓰기를 줄이는 방법을 보인다.
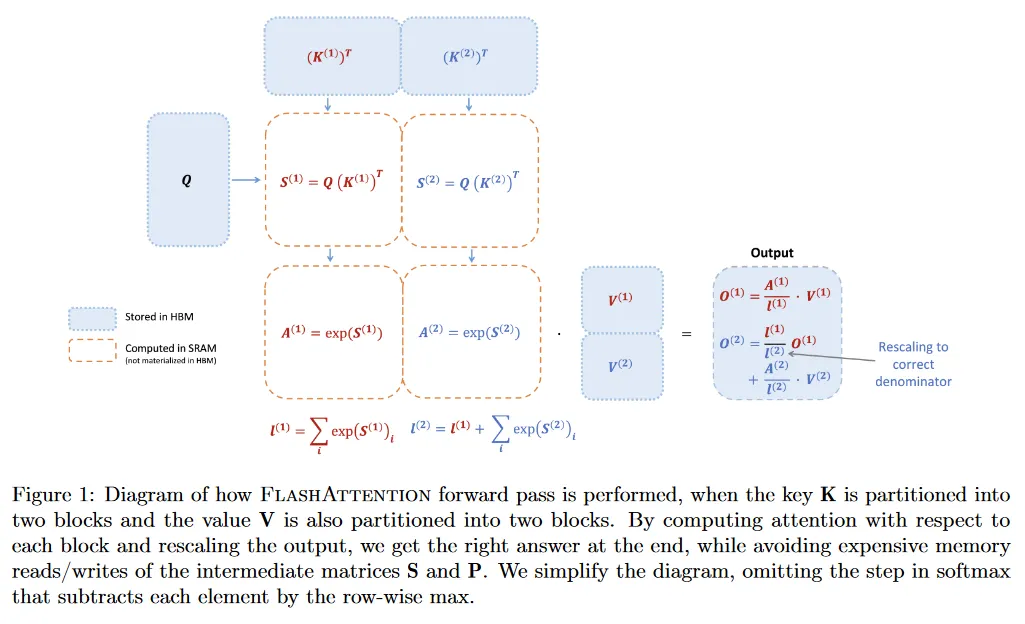
2.3.2 Backward pass
backward pass에서 FlashAttention은 입력 의 블록이 이미 SRAM에 로드되었을 때 attention 행렬 와 의 값을 re-computing하여, 큰 중간 값을 저장하는 것을 피한다. 크기 의 큰 행렬 와 를 저장하지 않고, FlashAttention은 시퀀스 길이에 따라 10-20배 메모리 절약을 얻는다(메모리 요구량이 시퀀스 길이 에 대해 2차가 아니라 선형이다) backward pass를 또한 메모리 읽기/쓰기를 줄였기 때문에 2-4배 실제 속도 향상을 달성한다.
backward pass는 섹션 2.2의 방정식에 tiling을 적용한다. backward pass가 forward pass 보다 개념적으로 더 간단하지만(여기에는 softmax rescaling이 없다) 구현은 더 복잡하다. 이것은 forward pass에서 2개 행렬 곱과 비교하여 backward pas에서 5개 행렬 곱을 수행하기 위해 SRAM에 더 많은 값을 유지해야하기 때문이다.
3 FlashAttention-2: Algorithm, Parallelism, and Work Partitioning
FlashAttention-2 알고리즘을 설명한다. 이것은 FlashAttention에 대해 몇가지 비틀기를 포함하여 non-matmul FLOPs의 수를 줄인다. 그 다음 GPU 리소스를 full로 사용하기 위해 다른 thread 블록에 대한 계산을 병렬화하는 방법을 설명한다. 마지막으로 하나의 thread 블록 내에 다른 warps 사이의 작업을 분할하여 shared 메모리 접근의 양을 줄인다. 이 구현은 2-3배 속도 향상을 이끌며 섹션 4에서 평가된다.
3.1 Algorithm
우리는 FlashAttention에서 알고리즘을 비틀어서 non-matmul FLOPs의 수를 줄인다. 이것은 최신 GPUs가 matmul을 훨씬 더 빠르게 만드는 특화된 계산 유닛(예: Nvidia GPUs의 Tensor Core)를 갖고 있기 때문이다. 예컨대 A100 GPU는 FP16/BF16 matmul의 312 TFLOPs/s의 최대 이론적 처리량을 갖지만 non-matmul은 FP32의 19.5 TFLOPs만 갖는다. 이것을 생각하는 또 다른 방법은 각 non-matmul FLOP이 matmul FLOP 보다 16배 더 비싸다는 것이다. 높은 처리량(예: 최대 이론적 TFLOPs/s의 50% 이상)을 유지하려면 가능한 많은 시간을 matmul FLOPs에 할애해야한다.
3.1.1 Forward pass
섹션 2.3에서 보여진 online softmax 트릭을 다시 보고 non-matmul FLOPs를 줄이기 위해 2가지 마이너 조정을 한다.
1.
출력 업데이트의 두 항을 로 rescale 하지 않는다.
대신 의 ‘un-scaled’ 버전을 유지하고 의 통계량을 유지할 수 있다.
각 반복문의 끝에서만 최종 를 로 scale하여 올바른 결과를 얻는다.
2.
backward pass에 대해 최대 와 지수합 를 저장하지 않는다. 오직 log-sum-exp 만 저장한다.
위의 에 대해 이므로 를 씌운 가 되고, 따라서 은 그 자체로 log-sum-exp 형식이 된다.
여기서
원래 FlashAttention-1의 backward pass의 recompute 단계에서 는 다음과 같이 계산된다.
아래 backward pass의 알고리즘에서는 다음과 같이 계산한다.
따라서 요소 별로 고려할 때 과 의 효과가 동일하므로 결과는 동일하다. 고로 를 로 대체할 수 있다.
섹션 2.3의 2개 블록의 단순화 경우에서 online softmax 트릭은 이제 다음이 된다.
위 식에 부분이 생략되어 있음.
unscaled 버전이기 때문에 기존의 에서 부분을 없애고 근사치 로 만든다.
위의 설명에서는 라 했는데, 위 식에서는 로 사용된다. 이 경우 가 되는데, 이고 이기 때문에 실제 계산해 보면 이 식은 직접적으로 변환되지 않는다. unscaled 버전 를 로 scale 한다는 개념으로 이해해야 할 듯.
여하튼 해당 unscaled 버전은 와 를 각각 구하여 합한 것과 같다.
에 의 값이 반영되어 있기 때문에 맨 마지막에 unscaled 를 로 scale하여 를 구한다. 만일 이 존재한다면 마지막 부분은 으로 구할 수 있음.
FlashAttention-2의 전체 forward pass 알고리즘을 Algorithm 1에 설명한다.
Algorithm 1. FlashAttention-2 forward pass
Require: HBM에서 행렬 , 블록 크기
1.
를 각각 크기의 개 블록 으로 분할하고 를 각각 크기의 개 블록 와 으로 분할
2.
를 각각 크기의 개 블록 으로 분할, log-sum-exp 을 각각 크기 의 개 블록 로 분할
3.
for do
a.
를 HBM에서 on-chip SRAM으로 로드
•
FlashAttention-1에서는 바깥 반복문에서 를 반복하고 그 내부 반복문에서 를 반복했는데, FlashAttention-2는 병렬화를 위해 외부에서 를 반복하고 내부에서 를 반복한다.
b.
on chip에서 초기화
c.
for do
i.
를 HBM에서 on-chip SRAM으로 로드
ii.
on chip에서 계산
iii.
on chip에서 다음을 계산
•
•
(point-wise)
•
◦
순서로 구하던 이 글의 설명과 달리 FlashAttention-1의 알고리즘 순서대로 을 구한다.
iv.
on chip에서 계산
•
unscaled 버전 계산
d.
end for
e.
on chip에서 계산
•
반복문 종료 후에 한번에 scale을 적용한다.
f.
on chip에서 계산
•
backward pass를 위한 log-sum-exp 저장
g.
를 를 -번째 블록으로 HBM에 쓰기
h.
를 를 -번째 블록으로 HBM에 쓰기
4.
end for
5.
출력 와 log-sum-exp 반환
Causal masking.
attention의 일반적인 사용은 auto-regressive 언어 모델링이다. 여기서 attention 행렬 에 causal mask를 적용해야 한다. (즉, 인 모든 항목 를 로 설정)
1.
FlashAttention과 FlashAttention-2은 이미 블록별로 계산되므로 열 인덱스가 행 인덱스보다 모두 큰 블록(긴 시퀀스 길이에서 대략 절반의 블록)에 대해, 해당 블록의 계산을 건너뛸 수 있다. 이것은 대략 causal mask를 사용하지 않는 attention과 비교하여 1.7-1.8배 속도 향상을 이끈다.
2.
행 인덱스가 열 인덱스보다 엄격하게 작은 것이 보장되는 블록에 대해 causal mask를 적용할 필요가 없다. 이것은 각 행에 대해 1개 블록(square 블록을 가정하여)에만 causal mask를 적용하면 된다는 것을 의미한다.
Correctness, runtim, and memory requirement.
FlashAttention과 마찬가지로 Algorithm 1은 (근사 없이) 올바른 출력 을 반환하고 입력과 출력 외에 FLOPs와 추가 메모리(log-sum-exp 을 저장하기 위해)를 사용한다. 증명은 Dao et al.의 증명과 거의 같다. 따라서 여기서는 생략한다.
3.1.2 Backward pass
FlashAttention-2의 backward pass는 FlashAttention과 거의 유사하다. softmax에서 행별 max와 행별 지수합을 모두 사용하는 대신 행별 log-sum-exp 을 사용하는 작은 변형만 한다. 완전성을 위해 Algorithm 2의 backward pass 설명을 포함한다.
Algorithm 2. FlashAttention-2 Backward pass
Require: HBM에서 행렬 , HBM에서 벡터 , 블록 크기
1.
를 각각 크기의 개 블록 으로 분할하고 를 각각 크기의 개 블록 와 으로 분할
2.
를 각각 크기의 개 블록 으로 분할, 를 각각 크기의 개 블록 로 분할, 을 각각 크기의 개 블록 로 분할
3.
HBM에서 를 초기화하고 각각 크기의 개 블록 로 분할. 를 각각 크기의 개 블록 와 로 분할.
4.
를 계산하고(pointwise 곱), 를 HBM에 쓰고 각각 크기의 개 블록 로 분할
•
FlashAttention-1에서는 를 반복문 안에서 계산했는데, FlashAttention-2에서는 반복문을 시작하기 전에 한 번에 계산하고 분할해서 사용
5.
for do
a.
를 HBM에서 on-chip SRAM으로 로드
b.
SRAM에서 초기화
c.
for do
i.
를 HBM에서 on-chip SRAM으로 로드
ii.
on chip에서 계산
iii.
on chip에서 계산
•
FlashAttention-1에서는 를 사용했지만 FlashAttention-2에서는 위의 형식으로 대체
•
여기까지가 forward의 recomputation
iv.
on chip에서 계산
v.
on chip에서 계산
vi.
on chip에서 계산
vii.
를 HBM에서 SRAM으로 로드하고 on chip에서 업데이트하고 HBM으로 다시 쓰기
viii.
on chip에서 계산
•
backward 계산은 FlashAttention-1과 동일하다.
d.
end for
e.
를 HBM으로 쓰기
6.
end for
7.
반환
Multi-query atetntion and grouped-query attention.
Multi-query attention(MQA)와 grouped-query attention(GQA)는 attention의 변종으로 추론하는 동안 KV 캐시의 크기를 줄이기 위해 여러 개의 query head가 key와 value의 동일한 head에 attend 한다. 계산을 위해 key와 value head를 복제할 필요 없이, head의 인덱스를 암시적으로 조작하여 동일한 계산을 수행한다. backward pass에서 암시적으로 복제된 다른 head에 걸쳐 gradient 와 를 합해야 한다.
3.2 Parallelism
FlashAttention의 첫 번째 버전은 batch 크기와 head 수에 따라 병렬화한다. 우리는 1개 thread 블록을 사용하여 하나의 attention head를 진행하고 전체적으로 batch 크기 x head 수만큼의 thread 블록이 존재한다. 각 thread 블록은 streaming multiprocessor(SM)에서 실행되도록 스케쥴링되며, 예컨대 A100 GPU에는 이러한 SM이 108개 존재한다. 이 수가 클 때 () 스케쥴링이 효율적이어서 GPU의 거의 대부분 컴퓨팅 리소스를 효과적으로 사용할 수 있다.
긴 시퀀스의 경우(일반적으로 작은 batch 크기나 작은 head 수), GPU의 multiprocessor를 더 잘 사용하기 위해, 추가적으로 시퀀스 길이 차원에 따라 병렬화를 한다. 이를 통해 이 체제에서 상당한 속도 개선을 이룬다.
Forward pass.
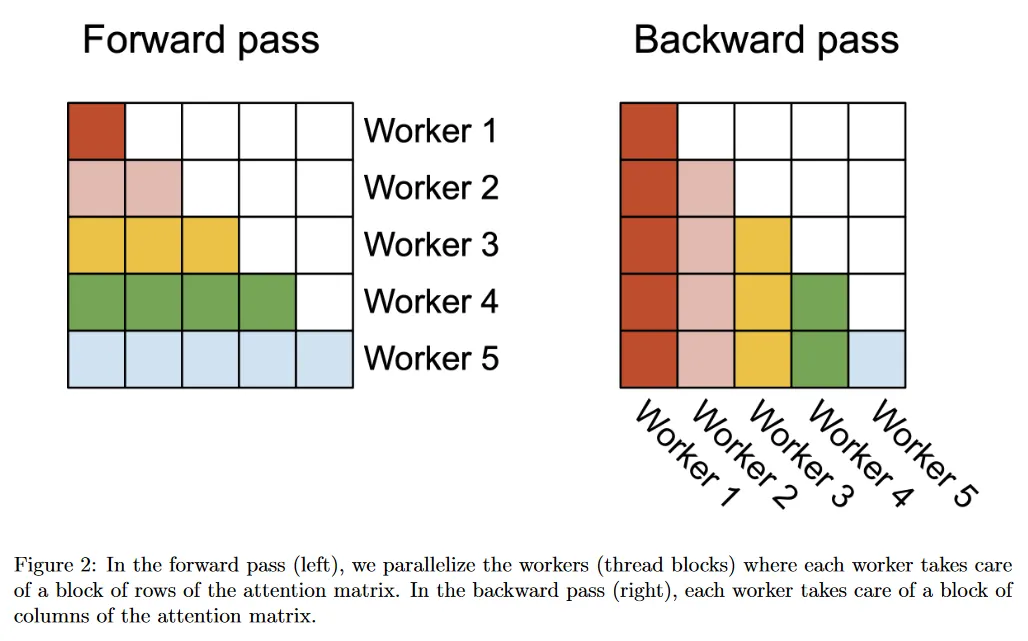
우리는 외부 반복문(시퀀스 길이에 대한)이 매우 병렬화 가능하며, 서로 커뮤니케이션 할 필요 없는 다른 thread 블록에서 이것을 스케쥴링한다는 것을 알 수 있다. 또한 FlashAttention에서와 같이 batch 차원과 head 수 차원에 대해서도 병렬화한다. 시퀀스 길이에 대해 증가된 병렬화는 batch 크기와 head 수가 작을 때 점유율(GPU 리소스가 사용 중인 비율)을 높이는데 도움이 된다. 이 경우에서 속도 개선을 이끈다.
반복의 순서를 swap 하는 이 아이디어(FlashAttention 논문과 반대로 행 블록에 대한 외부 반복과 열 블록에 대한 내부 반복) 뿐만 아니라 시퀀스 길이 차원에 대한 병렬화는 Phil Tillet에 의해 Triton에서 제안되고 구현되었다.
Backward pass.
Algorithm 2의 를 업데이트할 때만 다른 열 블록 사이에서 공유된 계산이 있다는 것에 주목하라. 여기서 를 HBM에서 SRAM으로 로드해야 하고 그 다음 on chip에서 를 업데이트한 다음 다시 HBM으로 쓴다. 따라서 시퀀스 길이 차원에 대해서도 병렬화하고, backward pass의 각 열 블록에 대해 1개 thread 블록을 스케쥴링한다. 를 업데이트하기 위해 다른 thread 블록 사이의 커뮤케이션에 atomic 덧셈을 사용한다.
그림 2에서 병렬화 체제를 설명한다.
3.3 Work Partitioning Between Warps
섹션 3.2에서 thread 블록을 어떻게 스케쥴하는지 설명한 것처럼 각 thread 블록 내에서도 다른 warps 사이에 작업을 어떻게 분할하지 결정해야 한다. 일반적으로 thread 블록 당 4, 8개의 warps을 사용하고, 분할 방식은 그림 3에 나와 있다.
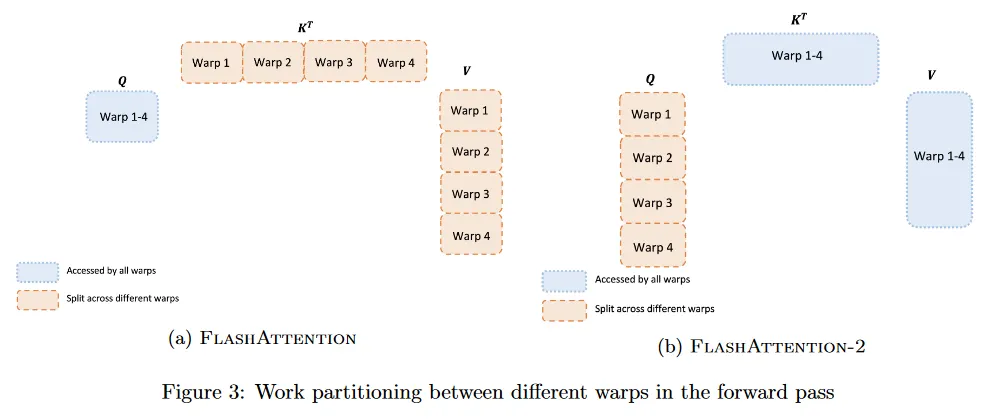
Forward pass.
각 블록에 대해, FlashAttention은 와 를 4개 warps 분할하는 반면 는 모든 warps에 의해 접근 가능도록 유지한다. 각 warp는 곱하여 의 조각을 얻은 다음 의 조각과 곱하고 결과를 합산하기 위해 통신해야 한다. 이것을 ‘split-K’ 체제라고 한다. 그러나 이것은 모든 warps가 중간 결과를 shared 메모리에 기록하고, 동기화한 다음, 중간 결과를 합산해하기 때문에 비효율적이다. 이 shared 메모리 읽기/쓰기로 인해 FlashAttention의 forward pass를 느리게 한다.
FlashAttention-2에서 대신 를 4개 warps으로 분할하면서 와 를 모든 warps에서 접근가능하게 한다. 각 wrap가 행렬 곱을 수행하여 의 조각을 얻은 후, 공유된 의 조각과 곱하면 해당 출력 조각을 얻을 수 있고, wraps 사이의 통신이 필요하지 않다. shared 메모리에서의 읽기/쓰기가 축소되면 속도 개선을 얻는다(섹션 4).
Backward pass.
backward pass에서도 유사하게, ‘split-K’ 체제를 피하기 위해 warp을 분할한다. 그러나 모든 다른 입력과 gradient 사이의 더 복잡한 의존성 때문에 여전히 일부 동기화가 남아 있다. 그럼에도 불구하고 ‘split-K’를 피하는 것은 shared 메모리 읽기/쓰기를 줄이고 다시 속도 개선을 얻는다(섹션 4).
Tuning block sizes.
블록 크기가 증가하면 일반적으로 shared 메모리 로드/저장이 줄어들지만 필요한 레지스터의 수와 총 shared 메모리 양은 증가한다. 특정 블록 크기를 초과하면, 레지스터 spilling으로 인해 상당한 속도 저하가 발생하거나 필요한 shared 메모리 양이 GPU에서 사용 가능한 양을 초과하여 커널을 전혀 실행할 수 없게 된다. 일반적으로 head 차원 와 장치 shared 메모리 크기에 의존하여 크기의 블록을 선택한다.
근본적으로 블록 크기에 대한 선택이 4가지만 존재하기 때문에 각 head 차원에 대해 수작업으로 조정했지만, 수작업을 피하는 auto-tuning이 이익일 수 있다. 우리는 이것을 미래 작업으로 남긴다.
4 Empirical Validation
Transformer 모델을 학습하기 위해 FlashAttention-2를 사용하는 효과를 검증한다.
•
Benchmarking attention. 다양한 시퀀스 길이에 걸쳐 FlashAttention-2의 실행을 측정하고 Python에서 표준 구현, FlashAttention과 Triton의 FlashAttention과 비교한다. 우리는 FlashAttention-2가 FlashAttention 보다 1.7-3.0배 빠르고 Triton에서 FlashAttention 보다 1.3-2.5배 더 빠르고 표준 attention 구현보다 3-10배 더 빠르다는 것을 확인했다. FlashAttention-2는 A100 GPU에서 이론적 최대 TFLOPs/s의 73%인 230 TFLOPs/s에 도달한다.
•
End-to-end training speed. 시퀀스 길이 2k나 2k에서 1.3B와 2.7B 크기의 GPT style 모델을 학습하기 위해 end-to-end를 사용할 때, FlashAttention-2는 FlashAttention과 비교하여 1.3배 빠르고, FlashAttention 없는 baseline과 비교하여 2.8배 더 빠르다. FlashAttention-2는 A100 GPU당 225 TFLOPs/s (72% 모델 FLOPs 활용률)를 달성한다.
4.1 Benchmarking Attention
A100 80GB SXM4 GPU에서 다양한 설정에 대해(causal mask 있음/없음, head 차원 64 또는 128) 다양한 attention 방법의 실행을 측정한다. 우리는 결과를 그림 4, 그림 5, 그림 6에 리포트한다. FlashAttention-2가 FlashAttention과 xformers(’cutlass’ 구현) 보다 약 2배 빠르다는 것을 볼 수 있다. FlashAttention-2는 Triton의 FlashAttention 보다도 forward pass에서 약 1.3-1.5배 빠르고, backward pass에서 2배 더 빠르다. Pytorch의 표준 attention 구현과 비교하여 FlashAttention-2는 10배 더 빠르다.
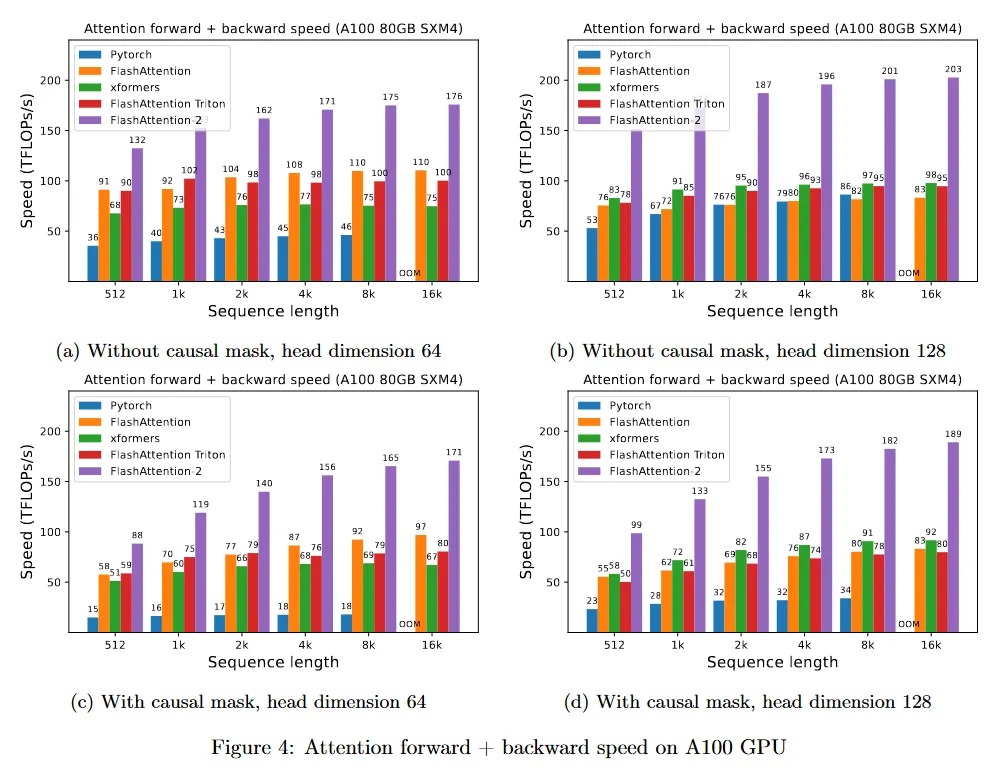
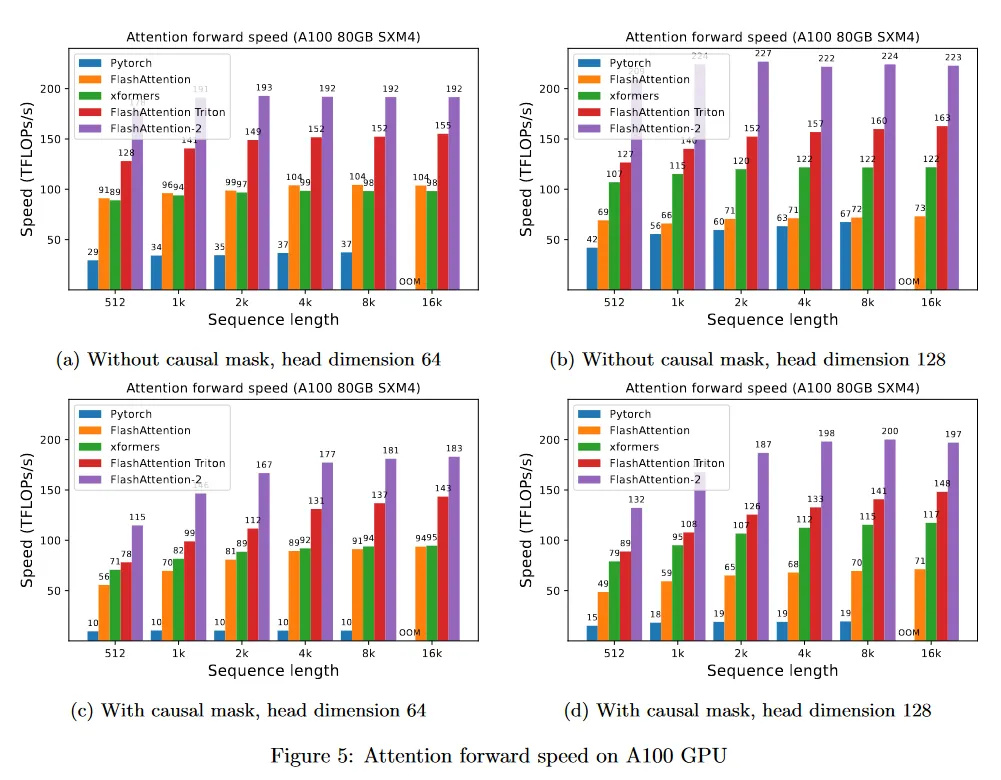
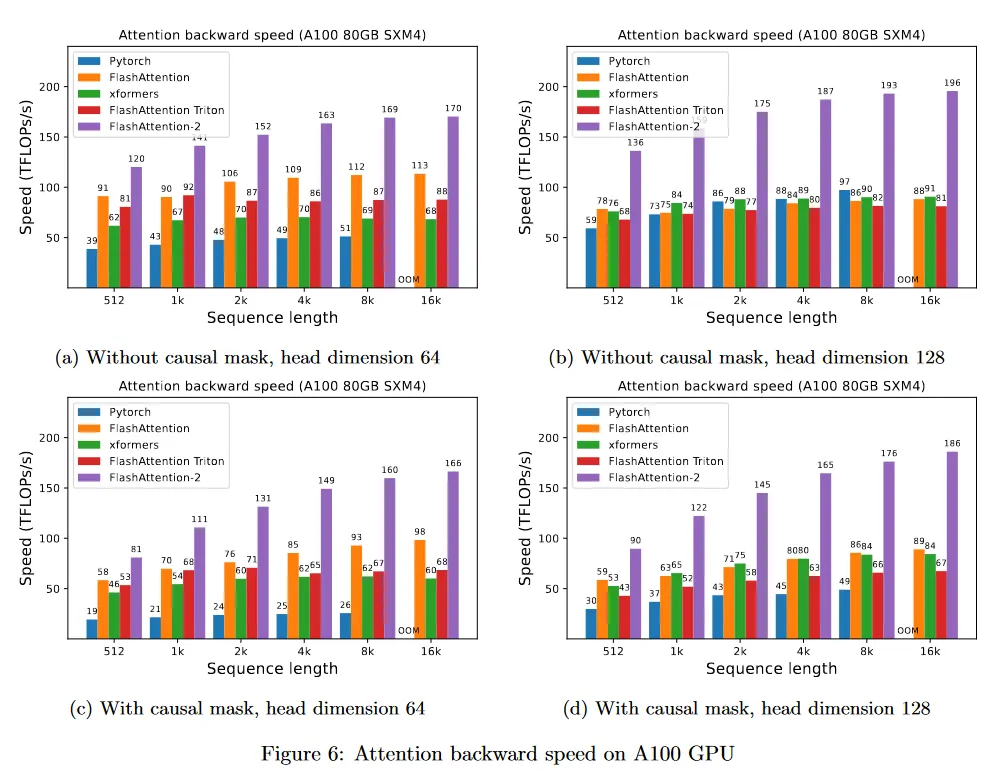
Benchmark 설정: 우리는 시퀀스 길이를 512, 1k, …, 16k까지 다양화하고, 총 토큰 수가 16k가 되도록 batch 크기를 설정한다. 은닉 차원을 2048로 설정하고, head 차원은 64 또는 128(즉 32 heads 또는 16 heads)를 설정한다. forward pass의 FLOP 계산을 위해 다음을 사용한다.
causal mask가 있는 경우 항목의 절반만 계산된다는 사실을 고려하여 이 수를 2로 나눈다. backward pass의 FLOP를 얻기 위해 forward pass FLOP에 2.5를 곱한다(forward pass에서 2개 matmul이 존재하고 recomputation 때문에 backward pass에서 5개 matmul이 존재하기 때문)
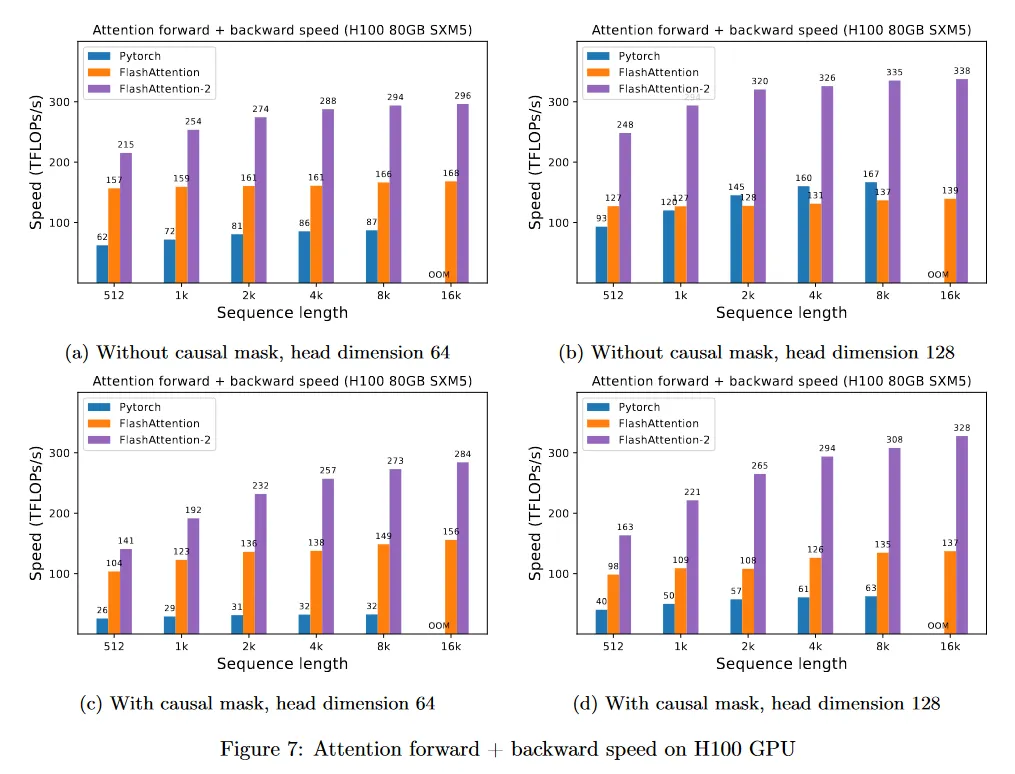
H100 GPU에서 동일한 구현을 실행하면(TMA와 4세대 Tensor Core 같은 새로운 feature의 사용하기 위한 특별한 명령어를 사용하지 않고) 최대 335 TFLOPs/s을 얻었다(그림 7). 우리는 새로운 명령어를 사용하면 H100 GPU에서 1.5-2배 더 빠를 수 있을 것으로 기대한다. 이 작업은 미래를 위해 둔다.
4.2 End-to-end Performance
8xA100 80GB SXM4에서 1.3B나 2.7B 파라미터를 사용하는 GPT 스타일 모델의 학습 처리량을 측정한다. 결과는 표 1 참조. FlashAttention-2는 FlashAttention이 없는 baseline과 비교하여 2.8배 더 빠르고, FlashAttention과 비교하여 1.3배 더 빠르고, A100 GPU 당 225 TFLOPs/s를 달성한다.

Megatron-LM(과 다른 많은 논문과 라이브러리)을 따라 공식으로 FLOPs를 계산한다.
첫 번째 항은 가중치-입력 곱에의한 FLOPs이고, 두 번째 항은 attention에 의한 FLOPs이다. 그러나 causal 마스크가 있을 때는 attention에서 계산해야 하는 요소 수가 절반이므로 두 번째 항을 2로 나눠야 한다고 주장할 수 있다. 그러나 우리는 문헌(attention FLOP을 2로 나누지 않는)과의 일관성을 위해 공식을 따른다.
5 Discussion and Future Directions
FlashAttention-2는 FlashAttention 보다 2배 더 빠르므로 동일한 수의 토큰으로 8k 컨텍스트 모델을 학습하는데 들었던 비용으로 16k 더 긴 컨텍스트 모델을 학습할 수 있다. 이를 통해 긴 책과 리포트, 고해상도 이미지, 오디오, 비디오를 이해하는데 활용될 수 있어 기대가 된다. FlashAttention-2는 또한 기존 모델의 학습과 finetuning, 추론 속도도 높일 수 있다.
가까운 미래에 우리는 연구자와 공학자들과 협업하여 FlashAttention을 다양한 종류의 기기(예: H100 GPUs, AMD GPUs)와 FP8 같은 새로운 데이터 유형에도 널리 적용할 수 있도록 할 계획이다. 즉시 다음 단계로 새로운 하드웨어 feature(TMA, 4세대 Tensor Cores, fp8)을 사용하기 위해 H100 GPU에 대해 FlashAttention-2를 최적화할 계획이다. FlashAttention-2의 low-level 최적화를 high-level 알고리즘 변경(예: local, dilated, block-sparse attention)과 결합하면 더 긴 컨텍스트의 AI 모델을 학습할 수 있다. 또한 이러한 최적화 기법은 쉽게 프로그래밍할 수 있도록 컴파일러 연구자들과의 작업을 기대한다.
