
unCLIP
unCLIP은 text-guided 이미지를 생성하도록 CLIP 텍스트 encoder를 사용한 모델이다. pretrained CLIP 모델 와 diffusion 모델에 대한 쌍별 학습 데이터가 주어지면 CLIP text 와 이미지 embedding 을 각각 계산할 수 있다. unCLIP은 병렬로 2가지 모델을 학습한다.
•
prior model : 텍스트 가 주어질 때 출력 CLIP 이미지 embedding
•
decoder : CLIP 이미지 embedding 와 optional 로 원본 텍스트 가 주어질 때 이미지 를 생성.
이 두 모델은 조건부 생성을 가능하게 한다. 왜냐하면
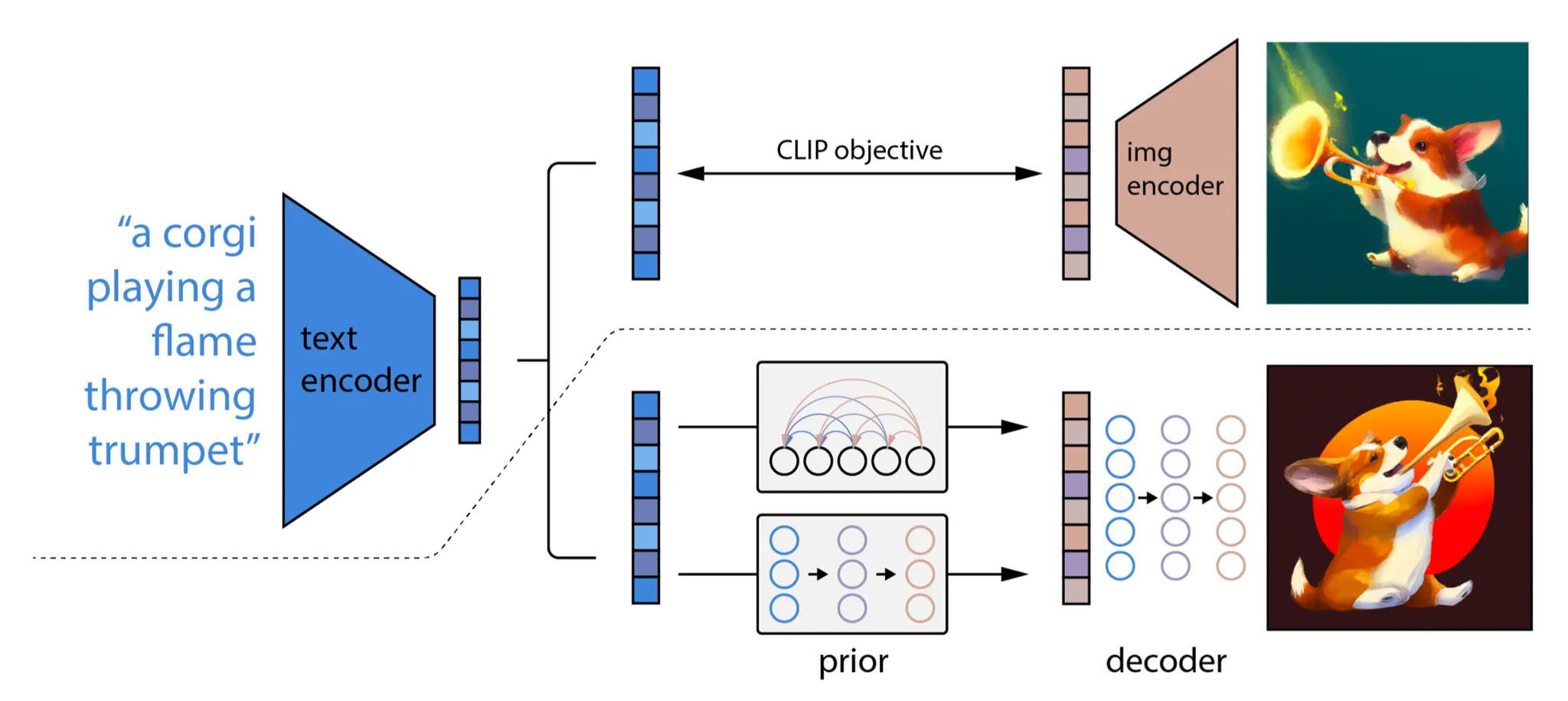
unCLIP은 2단계 이미지 생성 프로세스를 따른다:
1.
텍스트 가 주어지면 CLIP 모델은 우선 텍스트 임베딩 을 생성하도록 사용된다. CLIP latent 공간을 사용하여 텍스트를 통해 zero-shot image manipulation이 가능하다.
2.
diffusion 또는 autoregressive prior 가 이 CLIP 텍스트 임베딩을 처리하여 이미지 prior를 구성한 다음 diffusion decoder 가 prior에 조건화된 이미지를 생성한다. 이 디코더는 또한 스타일과 semantics를 보존하며 이미지 입력에 조건화된 이미지 변종을 생성할 수도 있다.
이 방법은 multimodal 입력, 출력을 갖는 생성 모델을 구성하는데도 동일하게 사용될 수 있다. 입력이 이미지든 텍스트든 음성이든 혹은 그들의 조합이든 embedding 공간으로 encoding 한 후에 해당 데이터를 바탕으로 prior를 생성하고 그것에서부터 이미지, 텍스트, 음성 혹은 그들의 조합을 생성하는 방식으로 구성할 수 있다.
Imagen는 CLIP 대신 pre-trained 대형 LM(예: frozen T5-XXL text encoder)을 사용하여 이미지 생성에 대한 텍스트를 인코드 했다. 더 큰 모델 크기는 더 나은 이미지 품질과 text-image alignment를 이끄는 일반적인 경향이 존재한다.
