
•
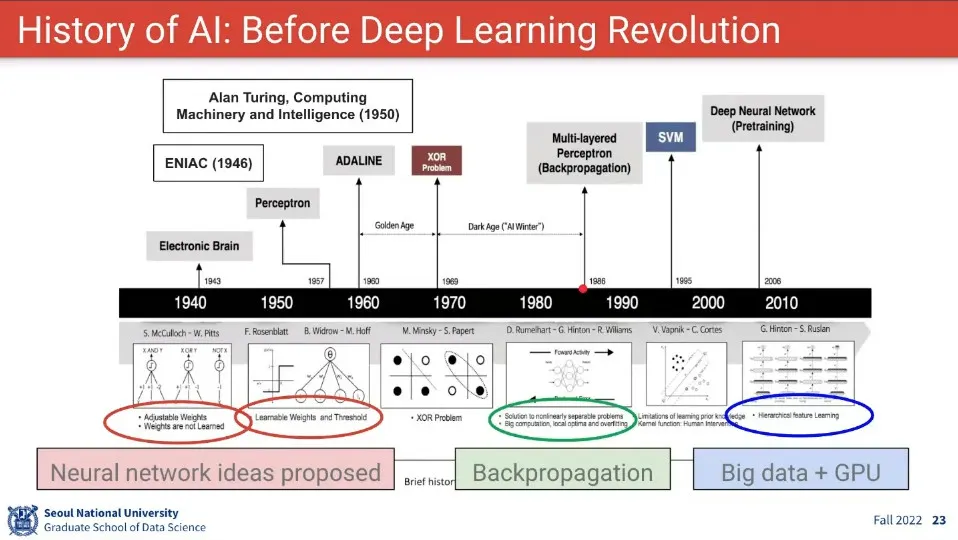
놀랍게도 인공지능이 ENIAC 보다 먼저 나왔음
•
퍼셉트론 등장 후에 AI가 큰 기대를 모았으나 XOR 문제 때문에 1차 AI 겨울이 시작 됨.
◦
XOR 문제를 해결한 사람이 제프리 힌튼 —딥러닝의 아버지이기도 함. 그래서 튜링상도 받음
•
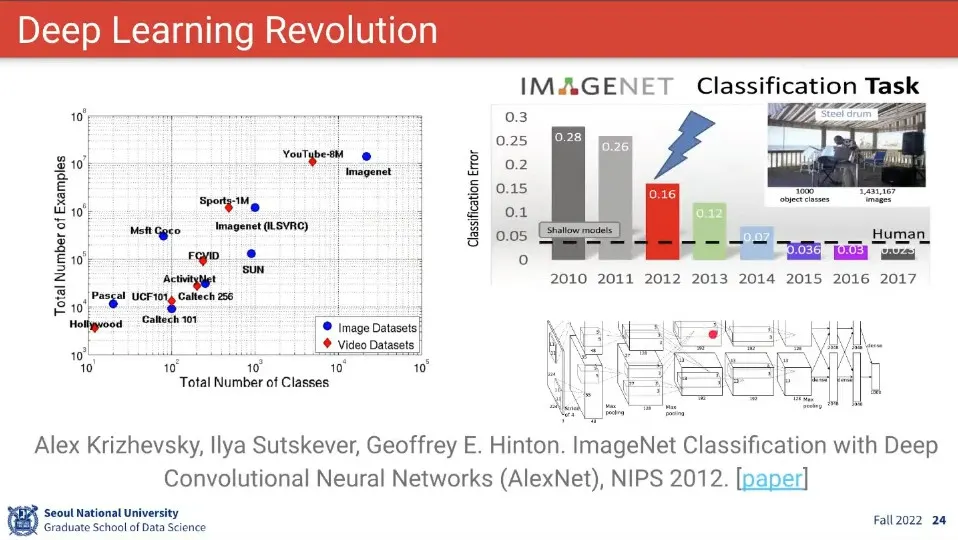
ImageNet 대회에서 AlexNet이 성과를 내면서 Deep Learning 혁명이 시작됨
•
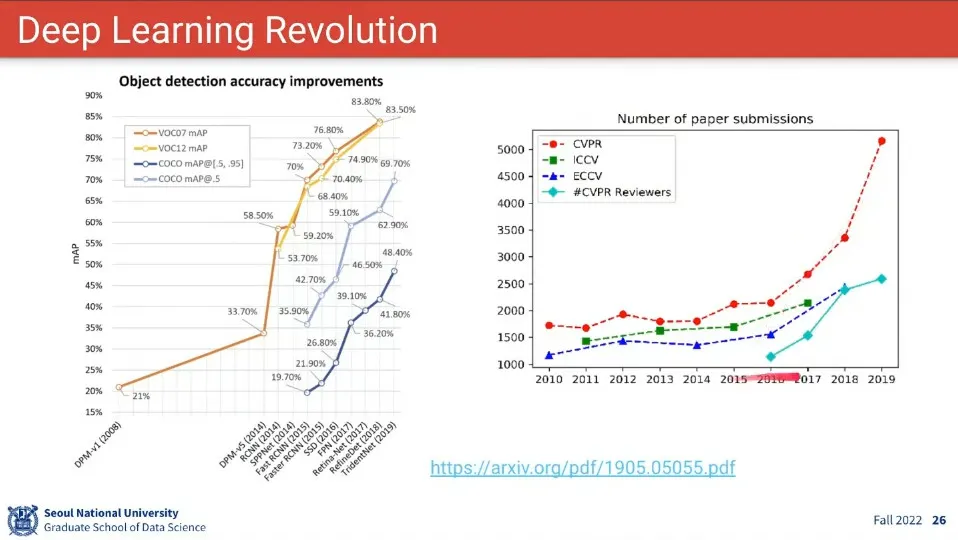
딥러닝 혁명이 시작 된 후에 빠르게 발전 하고 있음
•
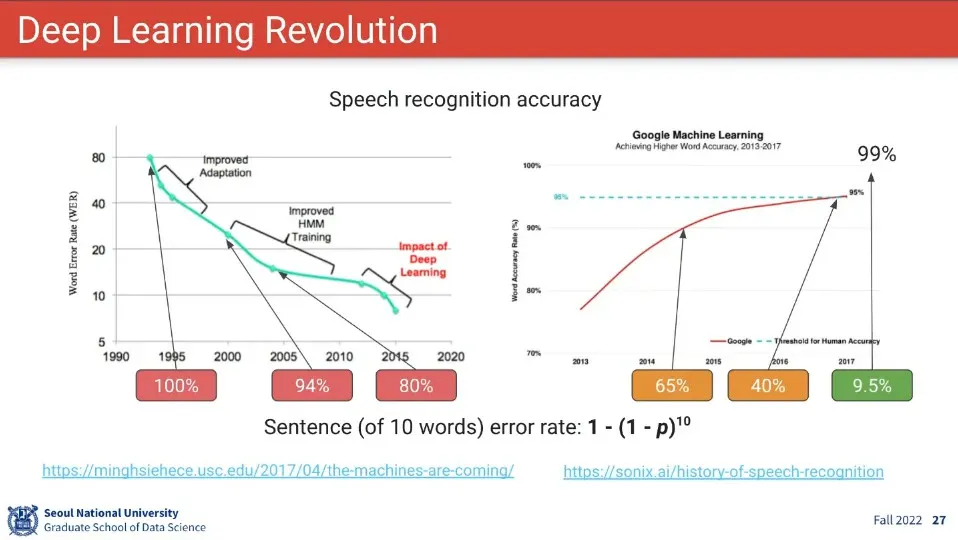
그러나 아직 음성 인식에 대해 단어 단위로는 정확도가 높은데, 그게 문장 단위로 가면 정확도가 많이 떨어짐.
•
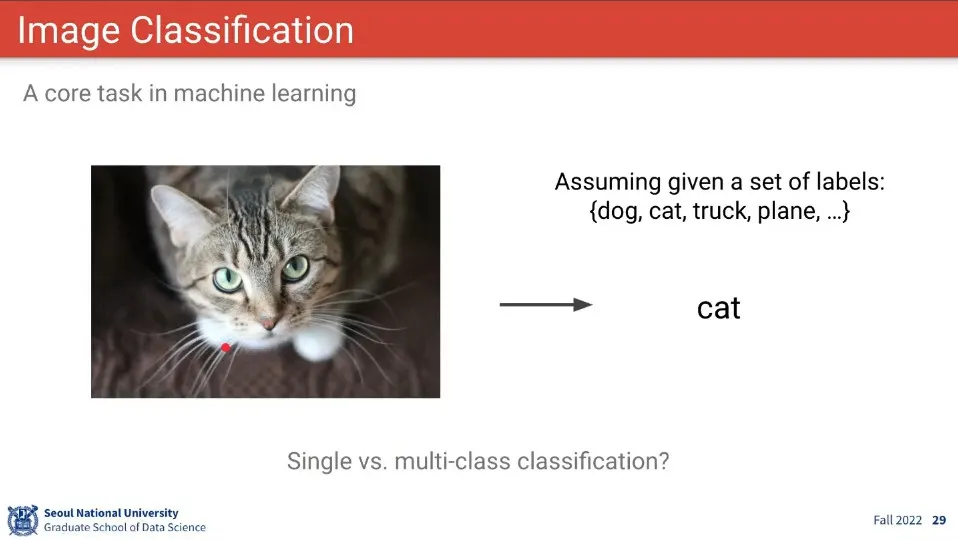
이미지 분류 문제는 주관식이 아니라 이미지와 라벨을 컴퓨터에게 주면 컴퓨터가 그 이미지에 해당 하는 라벨을 뽑아주는 것
•
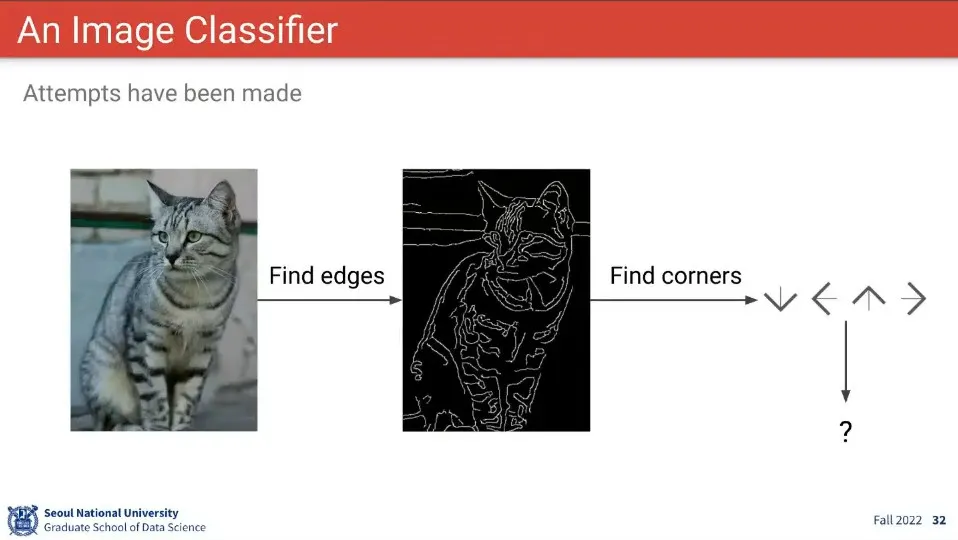
기존의 룰 기반 이미지 분류 방법은 모두 실패 함

•
머신러닝은 이미지 분류를 Data 기반으로 하는 것
•
머신러닝은 train/predict 단계가 분리되어서 수행 됨
•
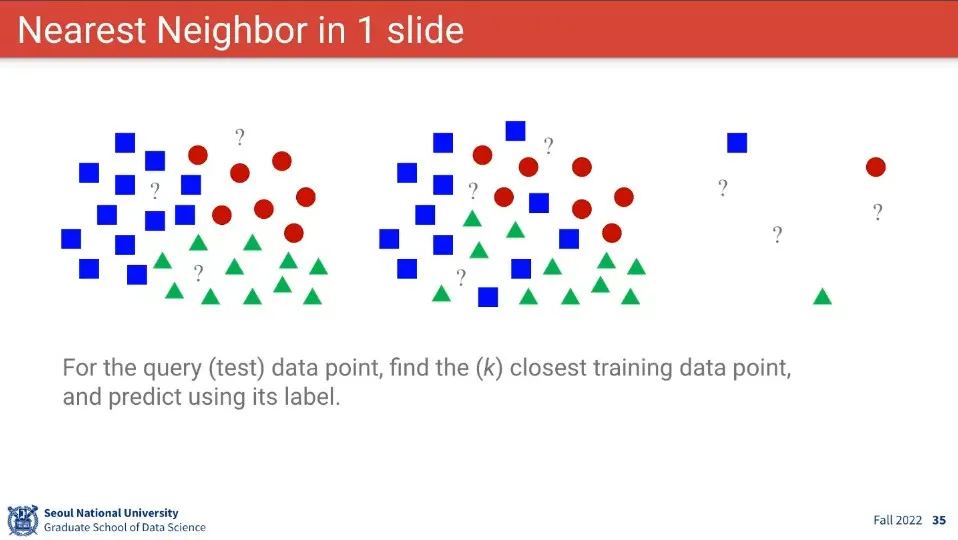
이미지 분류의 기초 컨셉은 Nearest Neighbor 방식.
•
대상의 주위에 있는 것을 기준으로 대상을 분류한다.

•
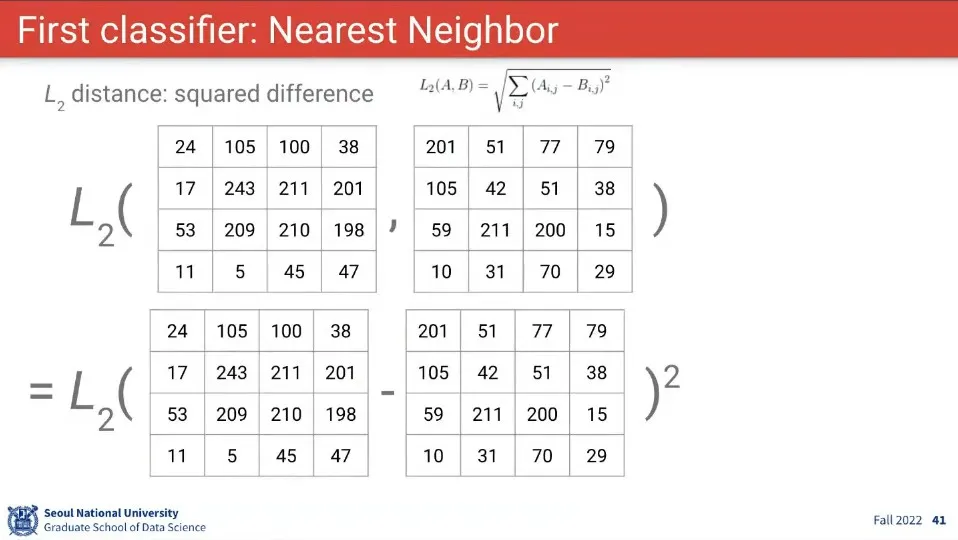
Nearest Neighbor의 아이디어를 차용하여 두 이미지의 픽셀 정보를 이용해서 유사도를 계산한다.
•
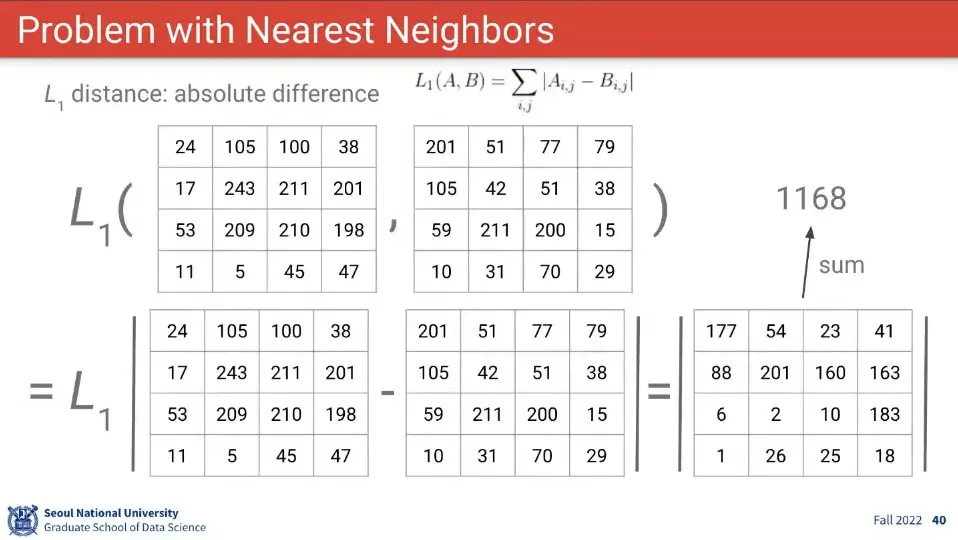
두 이미지의 차이(거리)를 계산하는 방법으로는 L1, L2 Distance가 있음
•
L1은 두 이미지의 차이에 절대값을 씌운 거고, L2는 두 이미지의 차이를 제곱한 후에 루트를 씌운 것

•
Nearest Neighbor를 기준으로 train, predict 하는 코드 예시

•
다만 이렇게 하면 학습할 때는 O(1)의 시간이 걸리지만, 예측할 때 O(N)의 시간이 걸려서 좋은 방법이 아님.
•
학습은 한 번만 하면 되기 때문에 오래 걸려도 문제 없지만, 예측은 오래 걸리면 사용하기 어려움
•
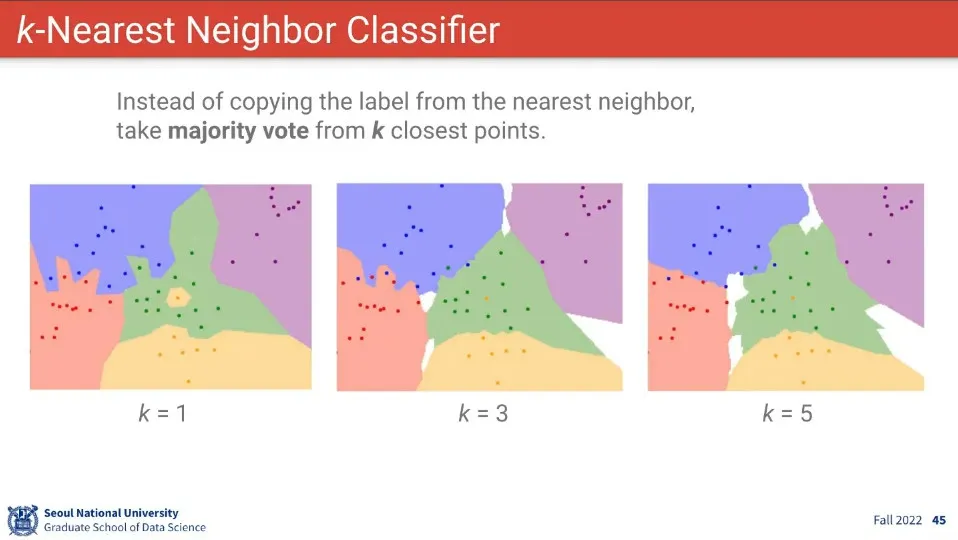
k-Nearest Neighbor는 가장 가까운 k개의 점을 이용해서 판단하는 방식. —다수결 방식
•
짝수일 경우 동률이 나올 수 있기 때문에 홀수를 사용한다.
•
단순히 거리만 쓰는 것 외에 L1 이나 L2 거리를 사용하기도 함

•
Nearest Neighbor는 이 예시와 같이 사람이 보기에 같은 이미지를 같다고 판별해 주지 못하기 때문에 이미지 분류 문제에서는 사용하지 않는다.
•
예측하는데 너무 오래 걸리는 것도 문제
•
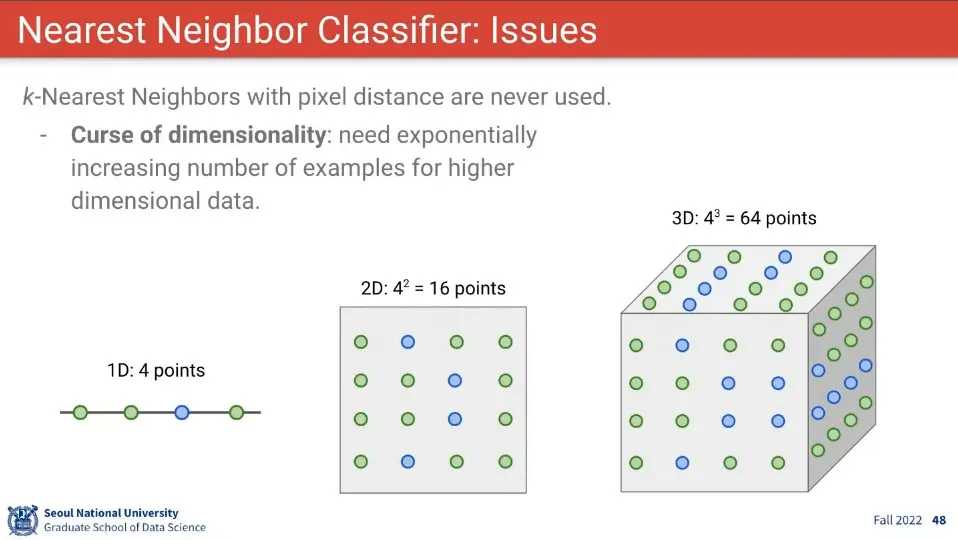
Nearest Neighbor는 차원의 저주 문제도 존재함.

•
Nearest Neighbor는 사용할 때는 다음과 같은 방법을 적용함
◦
데이터 정규화
◦
차원 축소
◦
train validation set 이용
◦
빠른 계산을 위해 모든 항목을 계산하지 않고 근사치를 구하는 라이브러리 사용
