
•
Transformer에 대해서 상세 내용은 다음 참조
•
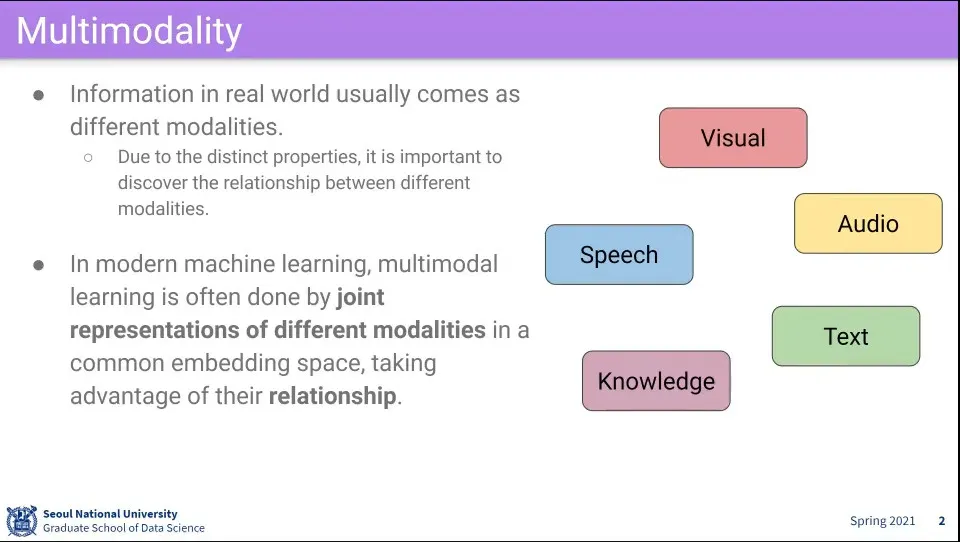
우리가 세상에서 받는 정보는 여러 modal로부터 들어옴
•
visual과 text를 합한 데이터를 학습
◦
speech 데이터도 text로 변환한 후에 할 수 있음
•
audio도 이미지로 변환한 후에 학습함

•
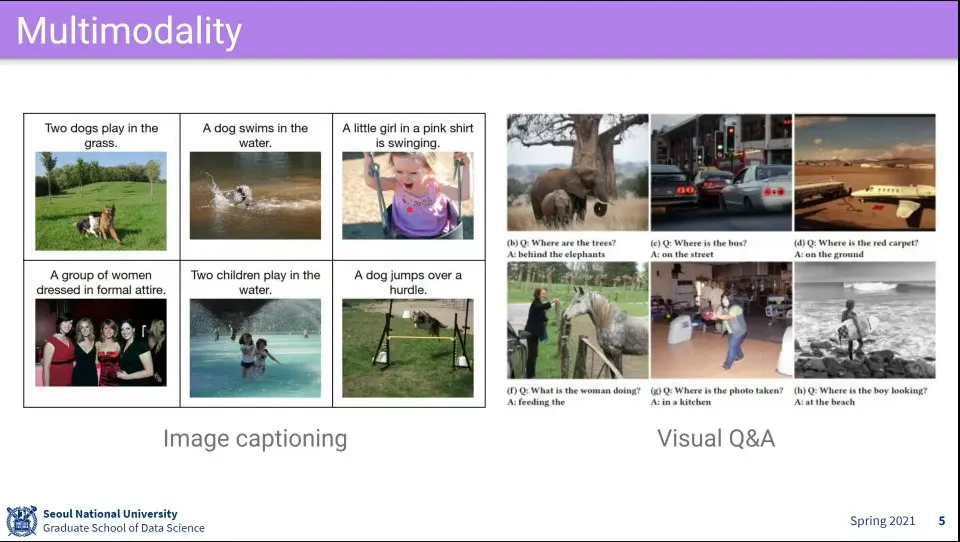
multimodal 활용 예

•
트랜스포머를 배우고, 트랜스포머 기반으로 여러가지 배워보겠다

•
word embedding은 단어를 벡터화 하는 것
•
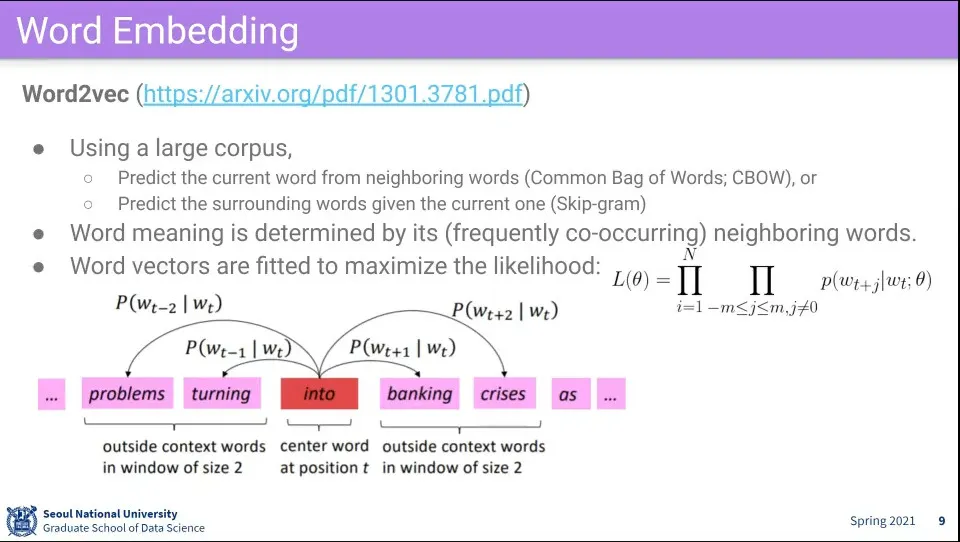
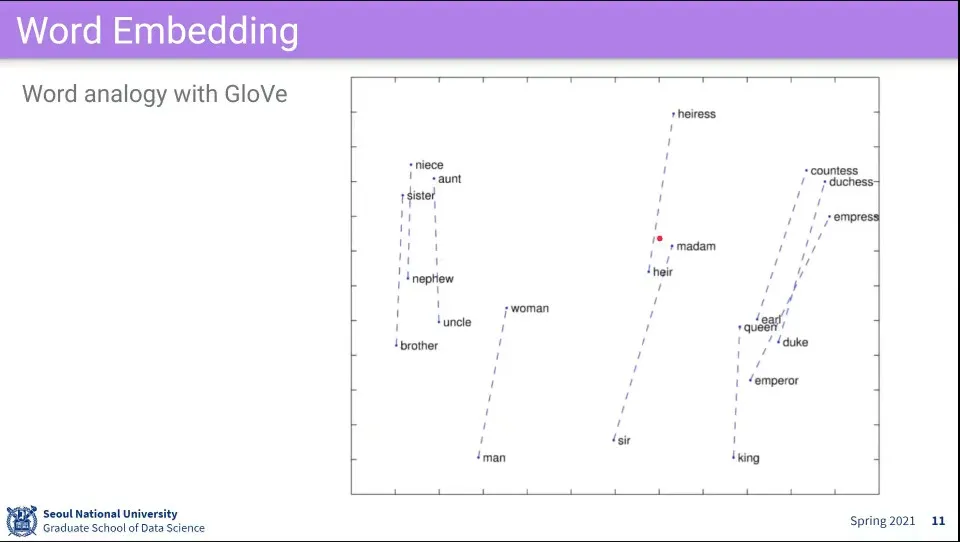
Word Embedding은 Word3Vec과 GloVe가 많이 쓰임
•
Word2Vec은 주위 단어들을 학습하게 하는 것

•
GloVe는 문맥 상의 관계를 이용한 방법
◦
Word2Vec과 달리 한 단어만 보지 않고, 두 단어가 같이 있을 때 어떤 단어가 나올 확률을 구한다.
◦
이걸 이용하면 단어들 간의 관계를 이해할 수 있다.
•
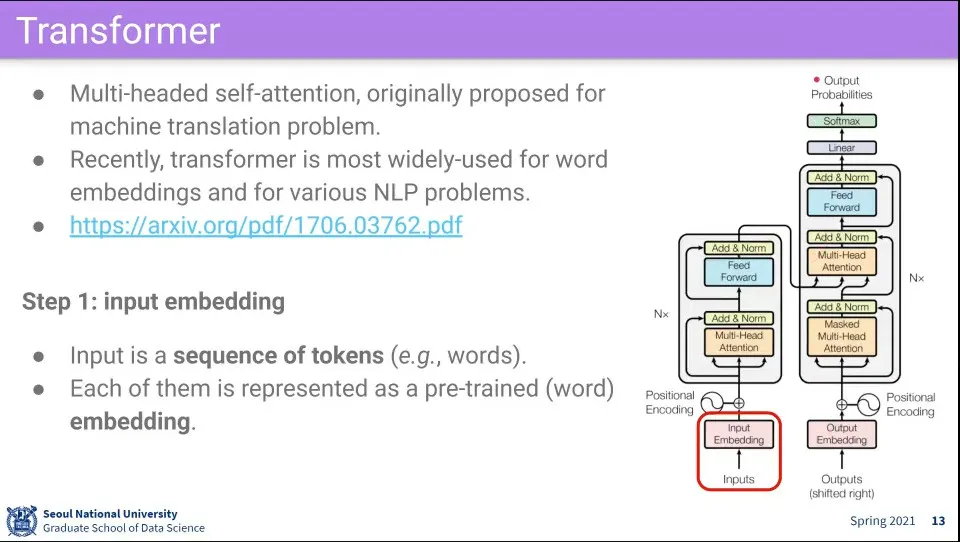
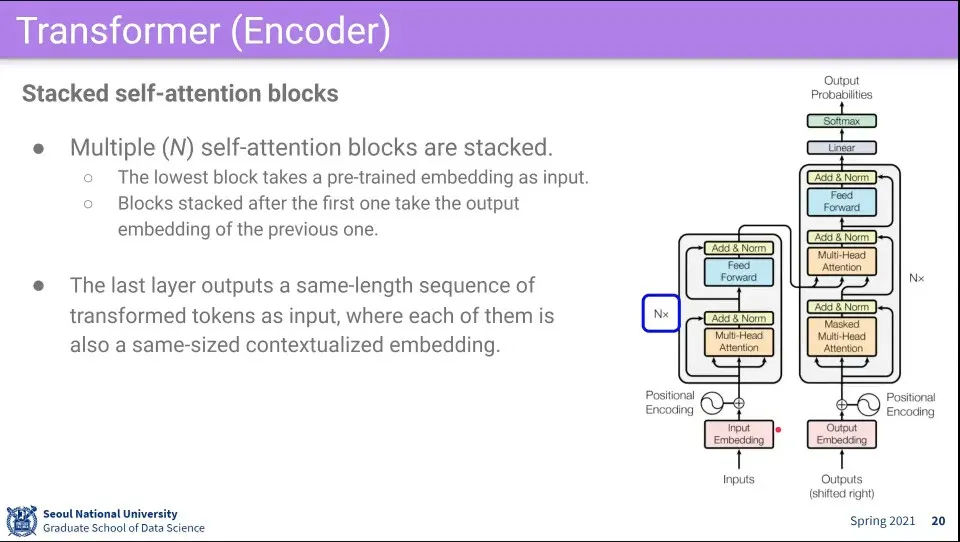
Transformer의 핵심은 Multi-headed self-attention
•
그림에서 왼쪽은 encoder, 오른쪽은 decoder가 됨
•
Transformer의 첫 단계는 embedding된 단어를 받는다. —Word2Vec이나 GloVe등으로 된 것
•
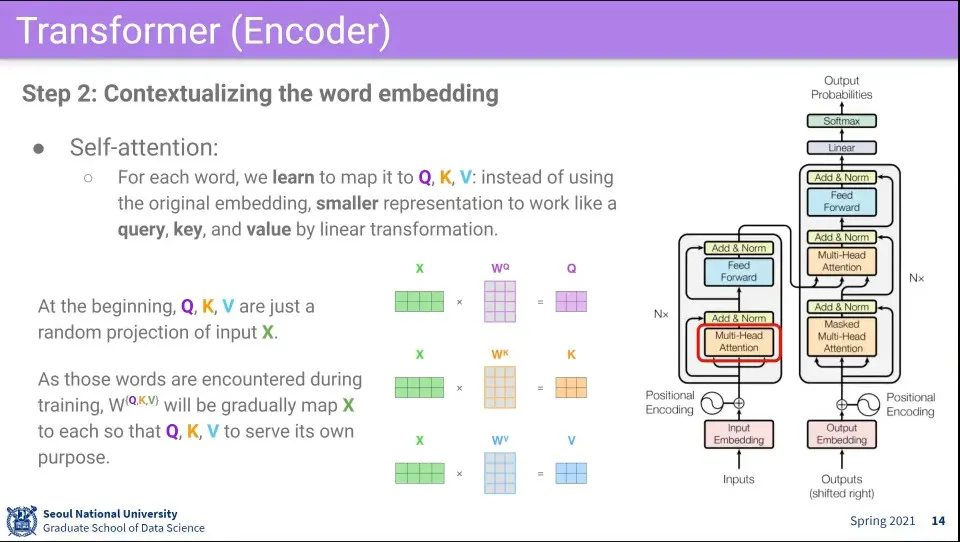
다음으로 Self-attention을 수행한다.
◦
입력으로 받은 문장을 이용해서 자기 자신에 대해 attention을 수행함. —self-attention
◦
이때 각 단어는 Q, K, V 역할을 모두 수행하기 때문에 그것을 맵핑해주는 3가지 벡터를 사용함. 결국에는 이것을 학습하는게 핵심
•
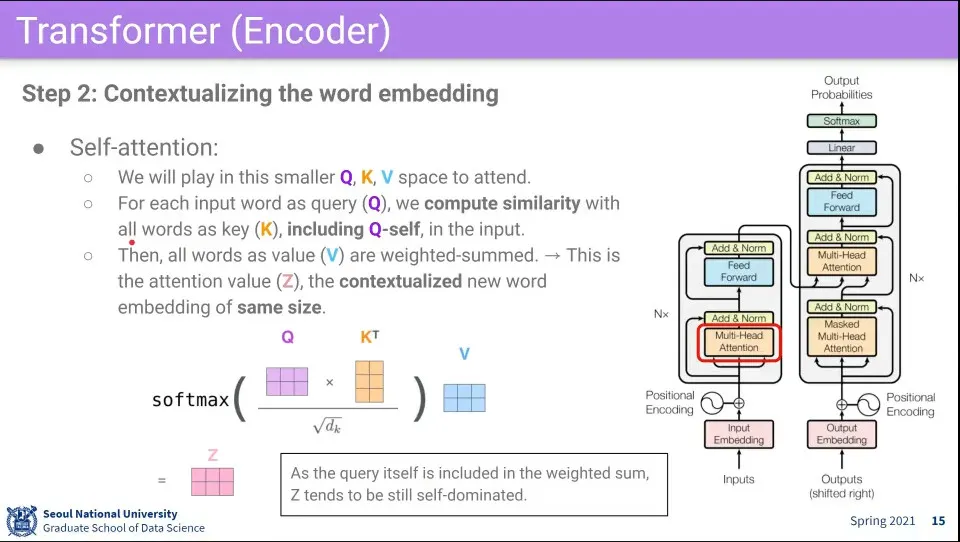
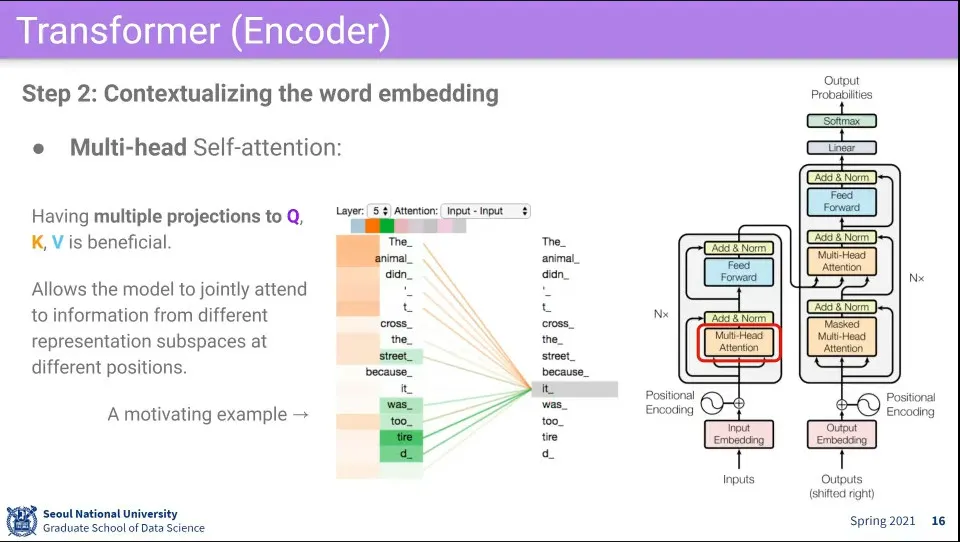
문장 내의 모든 단어들에 대해 Q로써 다른 모든 단어들과의 —심지어 자기 자신도 포함된— K, V를 계산함.
•
계산 과정은 다음과 같다.
1.
자기 자신을 Q로 변환한 것과 전체 단어들을 K로 변환한 것을 내적 해서 유사도를 구한다. 이때 K에는 자기 자신도 포함되게 된다.
•
Input이 N개 일 때 NxN 행렬이 나오게 됨. K에 자기 자신도 포함되기 때문에 NxN 행렬에서 자기 자신끼리 곱한 결과인 주대각선이 아무래도 값이 높게 나오게 됨.
2.
1의 결과에 대해 로 나누고 softmax를 씌운다.
3.
2의 결과에 대해 전체 단어들을 V로 변환한 것과 곱해서 Weighted Sum을 구한다. 그 결과를 Z라고 한다.
•
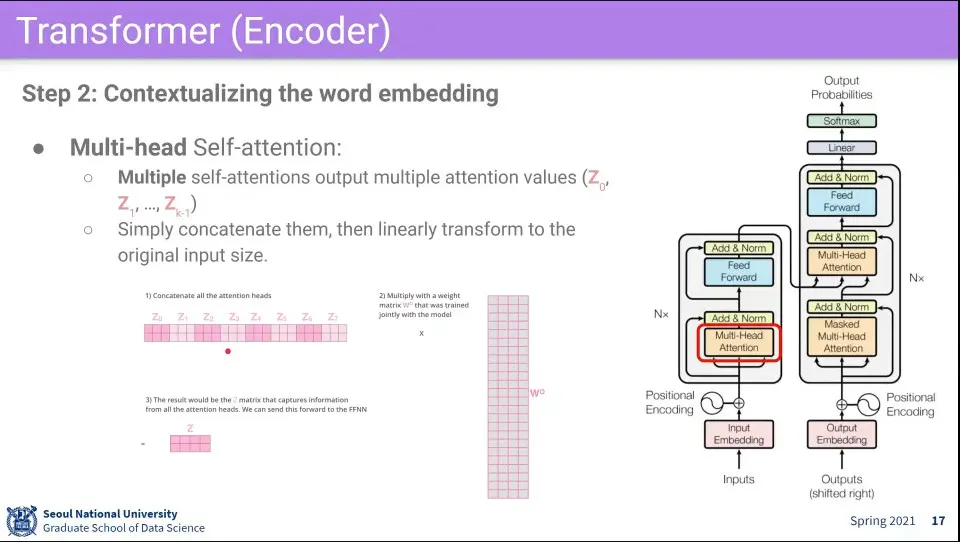
Multi-head는 위 self-attention을 여러 번 한다는 의미
◦
여러 번 하는 이유는 하나의 단어가 여러 의미를 갖고 있고 문맥에 따라 의미가 달라지기 때문
•
여러 번 수행하기 때문에 Z가 여러개 나온다.
◦
그런데 이러면 처음 input size와 다르기 때문에 이것을 input size로 되돌려주는 을 하나 더 사용한다. 이것도 학습 대상
◦
이렇게 변환된 Z는 최초 input X와 크기는 갖지만, attention이 반영된 것이 된다. 이렇게 X를 Z로 변환해 주기 때문에 transformer라고 한다.
•
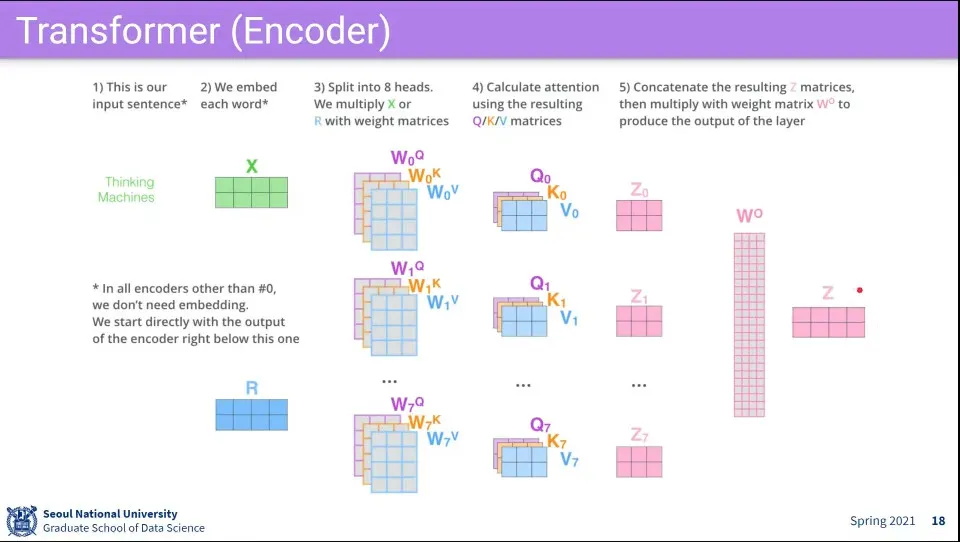
2단계 절차 요약
•
이것은 N번 돌면서 계속 transform 시킨다.
•
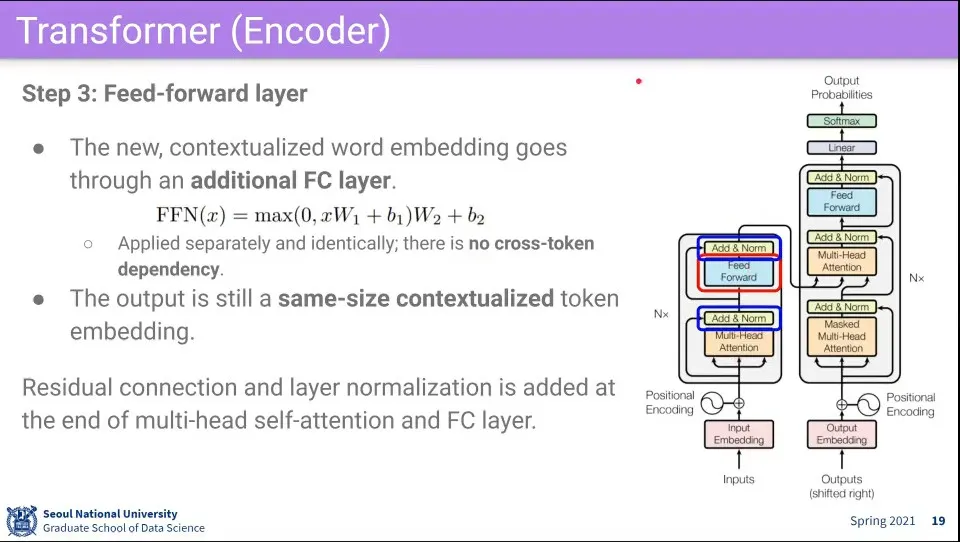
2단계를 통과한 것을 fully-connected를 수행한다.
◦
이때 fully-connected는 자기 자신에 대해서만 수행한다.
•
2단계를 통과한 것에 대해 Residual connection과 layer normalization을 수행하는데, 이것은 feed-forward를 통과한 것에 대해서도 수행해 준다.
•
위 2-3단계를 N번 반복해 줌
•
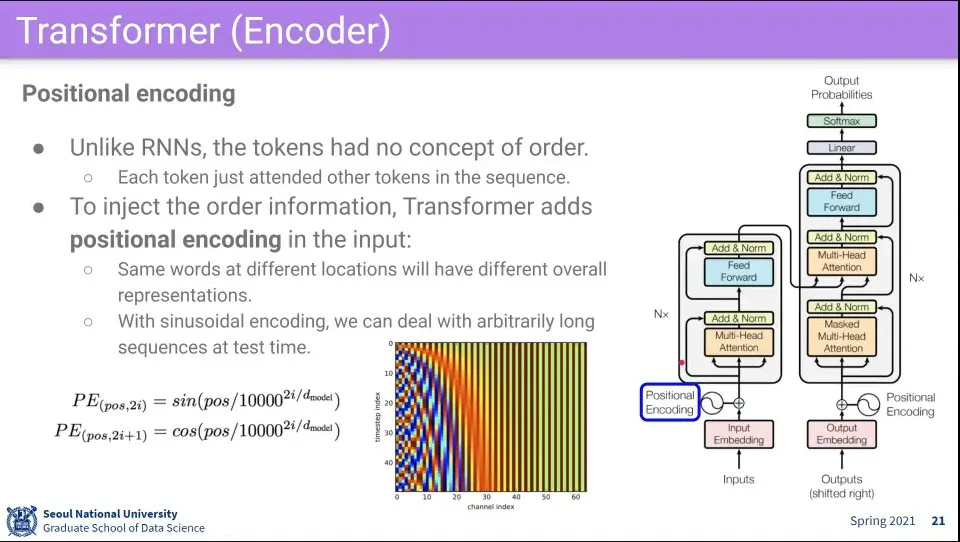
입력되는 단어가 모두 Q, K, V로 쓰이므로 단어의 순서의 의미가 없어지기 때문에, 순서 의미를 부여하기 위해 positional encoding을 해줌
◦
이때 더해주는게 sin, cos 함수를 이용한 값을 더해 줌
•
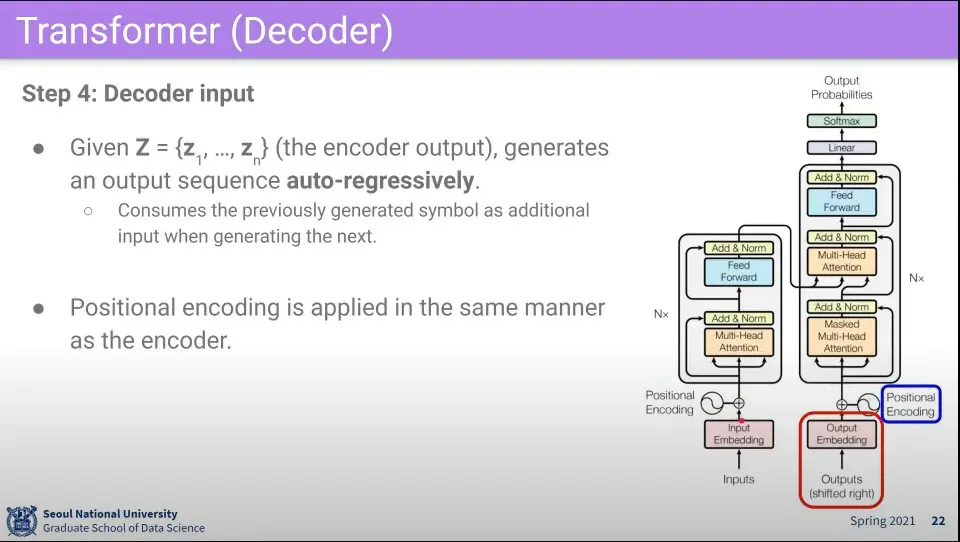
Decoder는 auto-regressively 동작함. -이전 output이 input이 된다는 의미
•
최초 decoder에 input이 들어오면 encoder와 마찬가지로 positionanl encoding을 추가해 줌
•
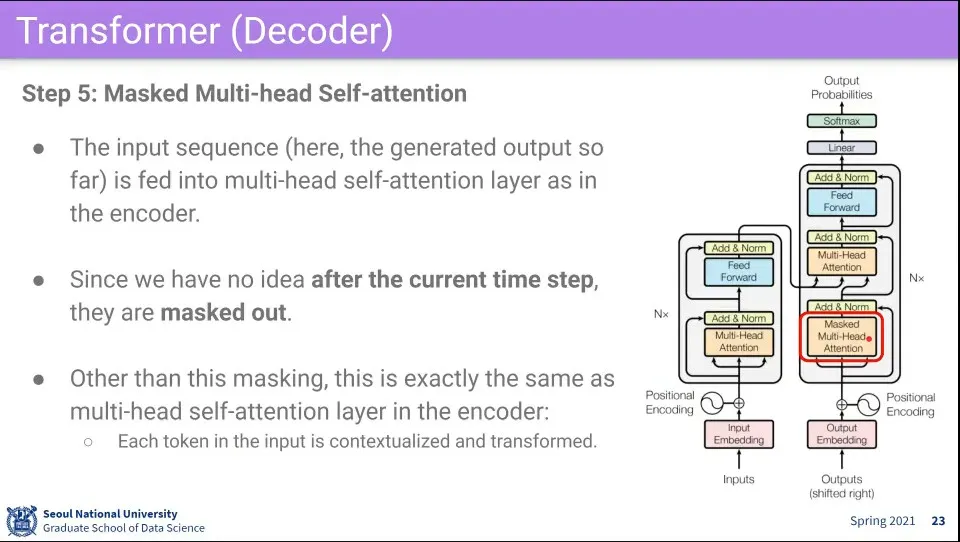
그 후에 Masked Multi-head Self-Attention을 수행함
◦
encoder의 self attention과 동일하게 수행하는데, 지금까지 만들어낸 값만 보고 미래를 보지 않게 하기 위해 mask를 씌워서 사용함
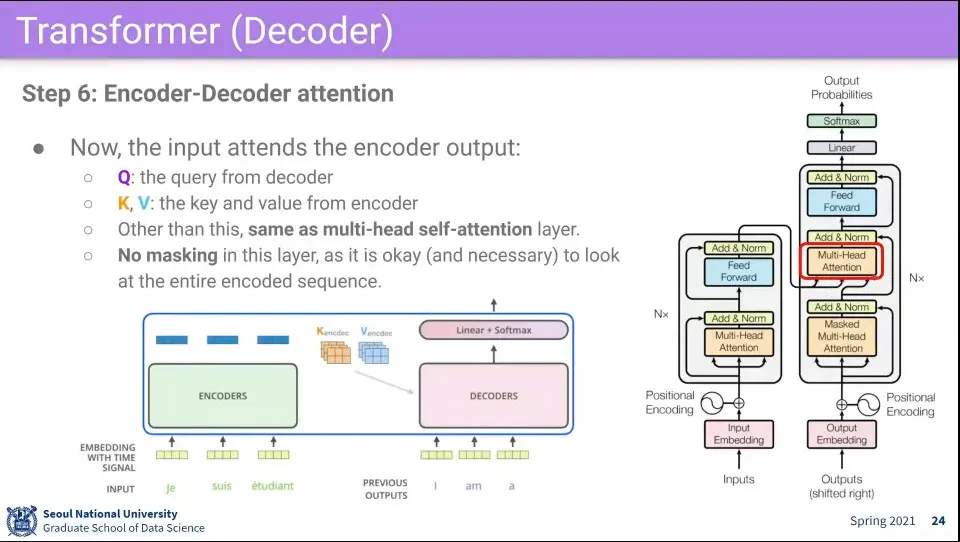
•
그 다음에 decoder의 Q를 쓰고, encoder의 K, V를 써서 다시 attention을 수행함. 이건 self-attention이 아님
•
encoder에 들어왔던 원래 문장이 뭐였는지를 봐야 하기 때문에 이 단계에서는 Mask 없이 수행한다.
•
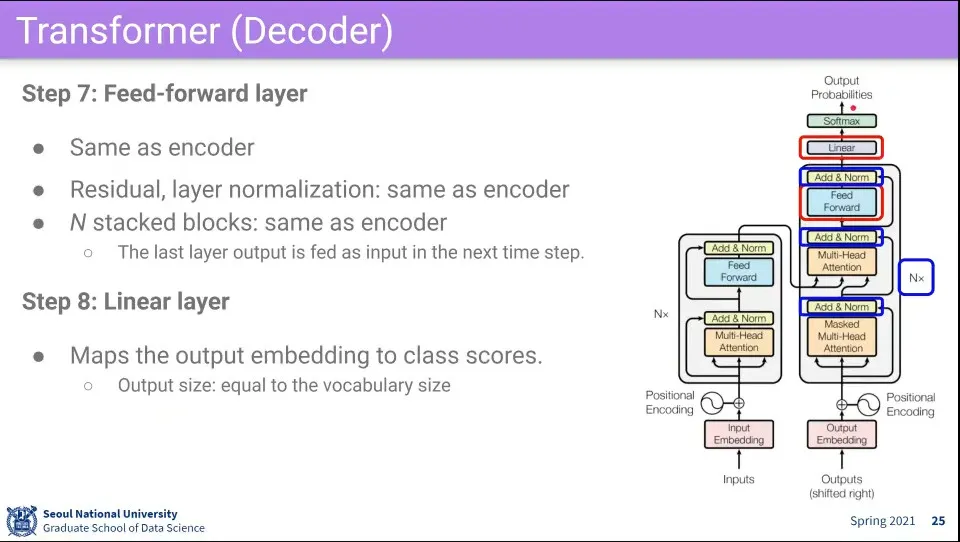
그 후에 Fully-connected는 encoder와 동일
•
각 단계별로 residual connection과 normalization 수행
•
encoder와 마찬가지로 이 과정을 N번 수행한다.
•
그렇게 나온 결과를 score를 내기 위해 최종적으로 linear layer를 통과시킨다.
•
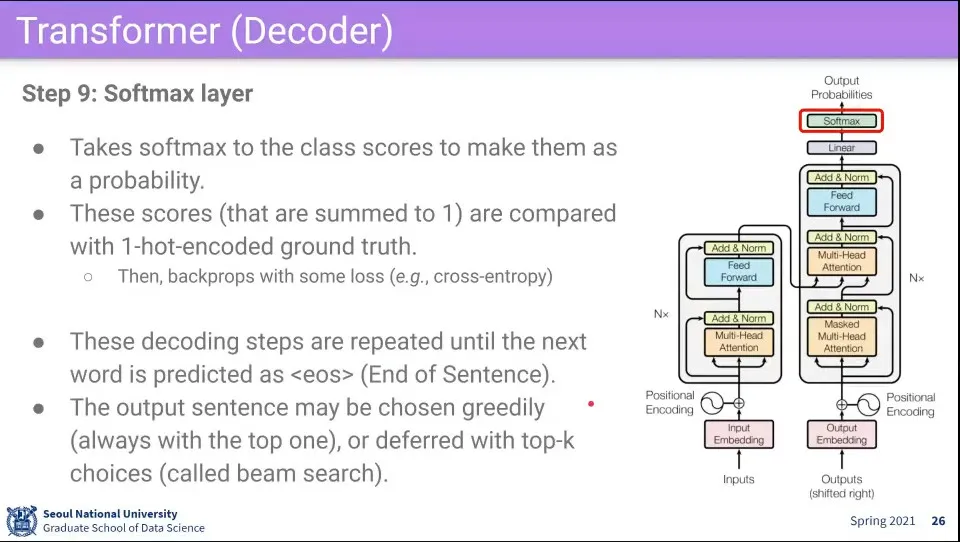
최종적으로 softmax를 통과시켜 output을 구한다.
•
문장을 끝내는 것은 <eos> 토큰이 나올 때까지 한다.
◦
<eos>가 나오는 것도 학습 시킴

•
BERT는 Transformer의 encoder를 이용해서 학습한 모델
◦
word embedding을 학습할건데 Transformer의 encoder 부분을 이용함
•
요즘 NLP는 BERT에서 나온 Word Embedding을 기본으로 사용함
•
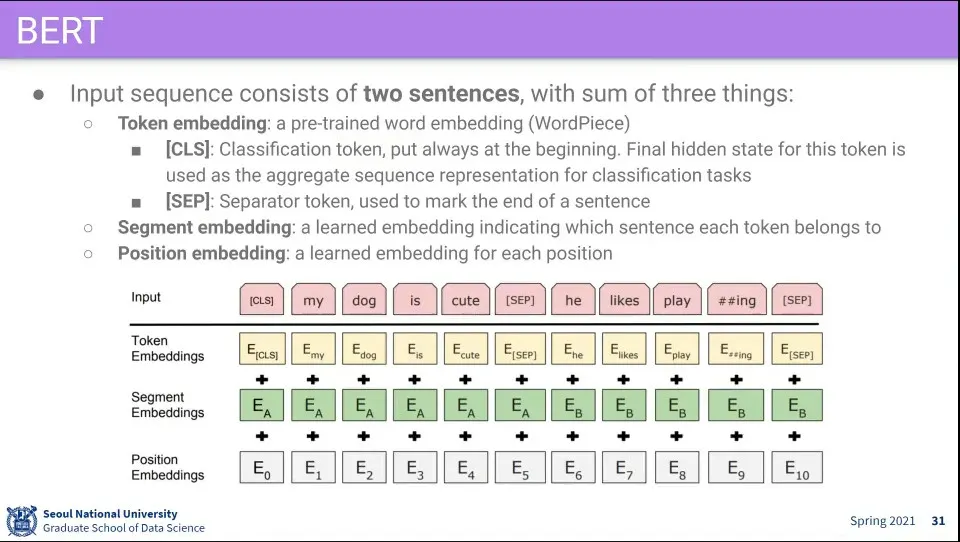
BERT의 데이터셋은 2개의 문장으로 구성 됨.
◦
Input 문장의 앞에 [CLS], 문장의 끝에 [SEP] 토큰을 추가함
•
Input으로 3개의 Embedding —Token Embedding, Segment Embedding, Position Embedding— 을 만들고 이것들을 합해서 넣음
◦
Token Embbeding은 Word Piece라는 pre-trained 모델을 사용함
◦
Segment Embedding은 현재 단어가 두 문장 중 어느 문장에 위치한 것인지를 표현
◦
Position Embedding은 현재 단어의 순서를 표현

•
문장의 빈칸을 채우는 학습을 시킴. 이렇게 하면 사람이 labeling 하지 않고도 학습을 시킬 수 있음
◦
문장 중 15%의 임의의 위치에 빈칸을 추가

•
문장이 연속된 것인지 classify함
•
사실 이거는 별로 안 중요하고 MLM이 훨씬 중요함

•
이미지와 텍스트가 연관있는 것을 이용해서 학습 함
•
text는 시퀀스가 있는데, 이미지에는 어떻게 sequence를 줄 수 있을까?
•
이런 데이터를 어떻게 수집할 수 있을까?
◦
검색 결과를 쓰기도 하고, 웹 페이지 내의 것을 쓰기도 함. 혹은 SNS에서 구하기도 함
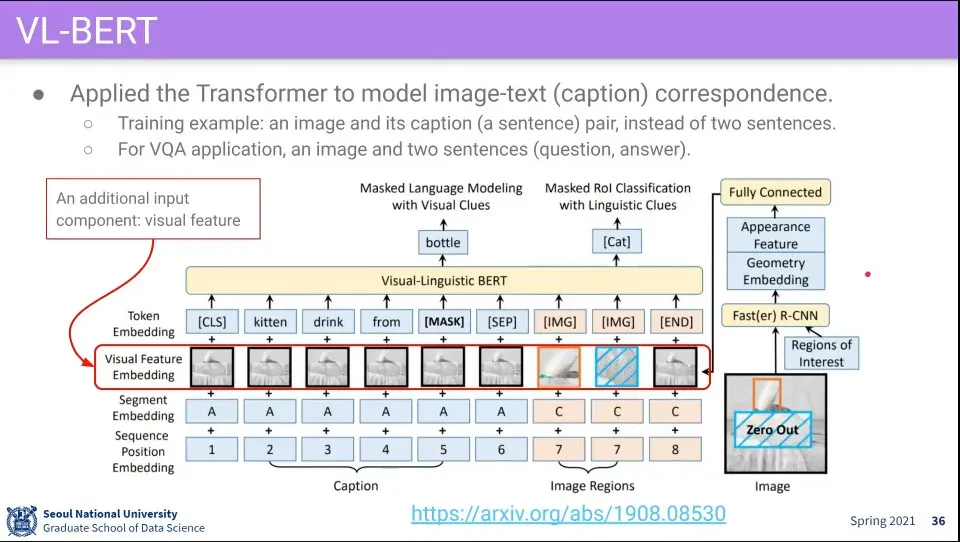
•
VL(Visual Language)-BERT 는 visual 정보와 language 정보를 BERT에 넣어서 사용함
•
원래 BERT에 Visual Feature Embedding을 추가함
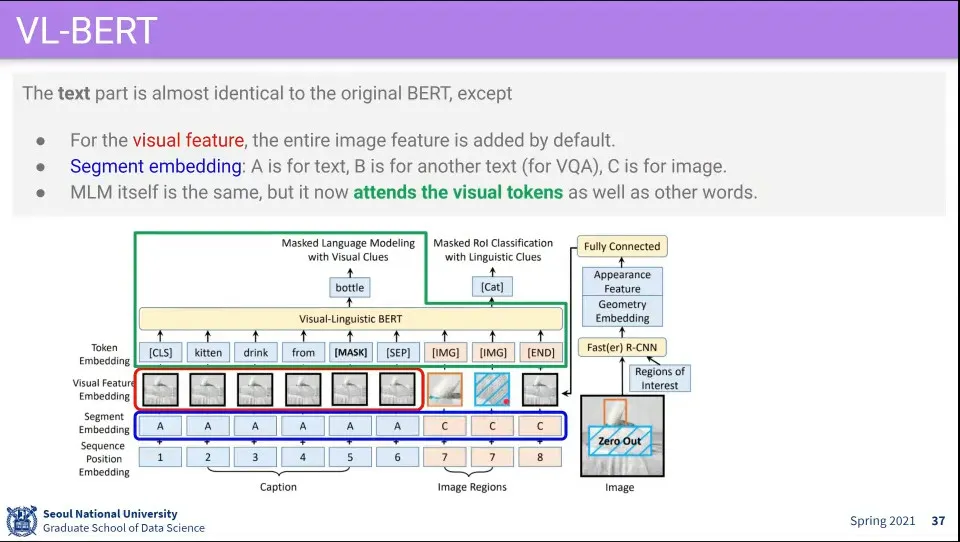
•
Visual 정보가 추가되었기 때문에 Text의 Visual 부분에는 [IMG] 태그를 추가하고
•
Text가 들어가는 부분의 Visual은 Input 이미지를 그대로 쓰고, [IMG] 태그 부분은 수정해서 사용
•
Segment Embedding 부분에서 Text 부분이면 A, Image 부분이면 C를 사용한다. —B가 다른 곳에서 쓰임
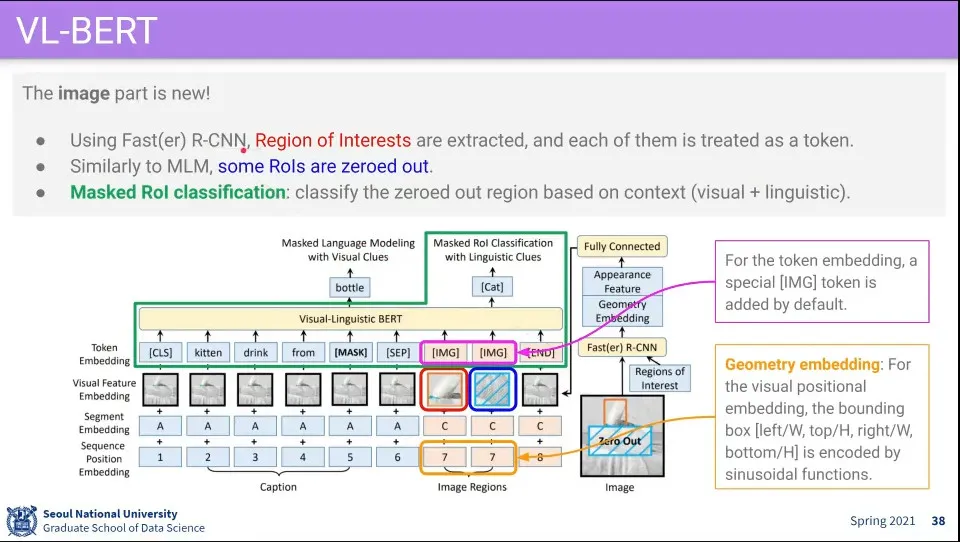
•
[IMG] 부분에는 이미지에 Fast(er) R-CNN을 돌려서 나온 ROI 부분을 하나의 Token으로 넣음
◦
이때 순서 개념이 없기 때문에 Sequence Position을 같은 값을 넣어줌
•
학습할 때 텍스트 부분을 MLM(Masked Language Modeling)으로 하는 것처럼 이미지 부분도 ROI 부분 중 하나를 Mask 해서 거기에 어떤 이미지가 나오는지 알아 맞추는 것을 학습 시킴.
◦
이때 함께 들어온 text를 보고 거기에 어떤 이미지가 있어야 하는지를 알아 맞추도록 함. 위 예시에서 kitten이라는 단어를 보고 고양이가 mask된 부분에 고양이가 그려져야 하는 것을 맞춰야 함 (classify로 맞춤)
◦
이것을 Masked ROI Classification이라고 함
•
BERT에서 2개의 문장을 쓰던 것을 문장 하나로 바꾸고 나머지는 이미지를 넣음
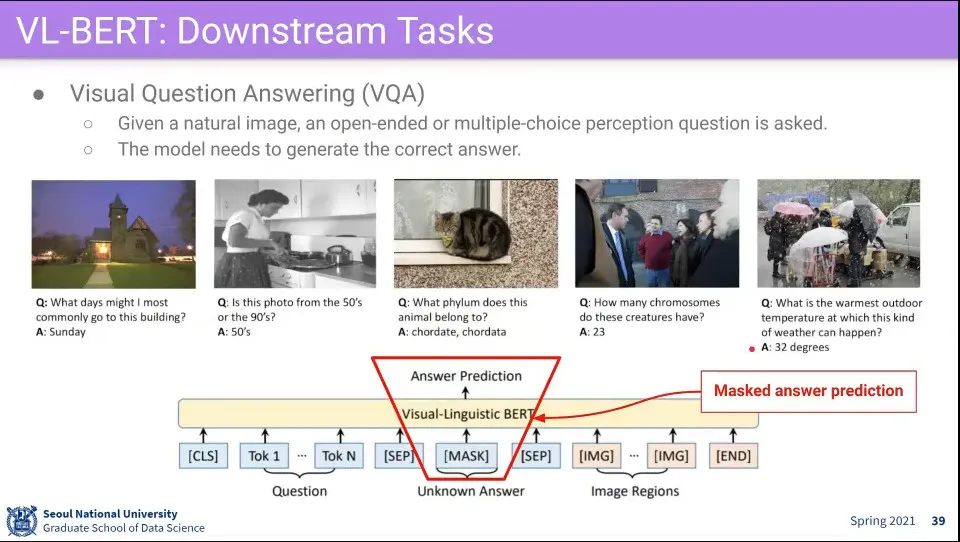
•
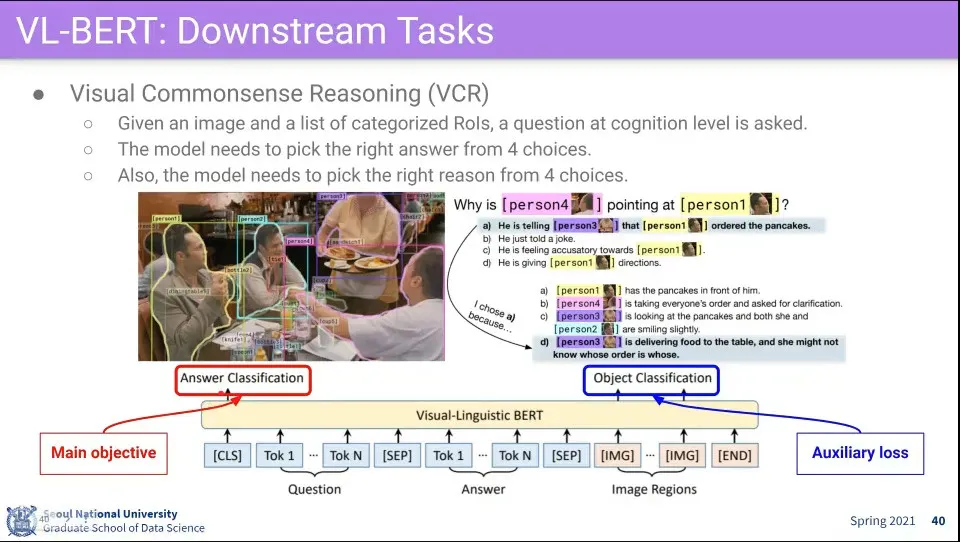
활용 예 - 이미지를 보고 QA를 함
◦
VOQ 할 때는 답을 Input으로 넣는데 답 부분에 Mask를 씌워서 답을 예측하도록 함
•
이미지를 보고 객관식 문제를 품
•
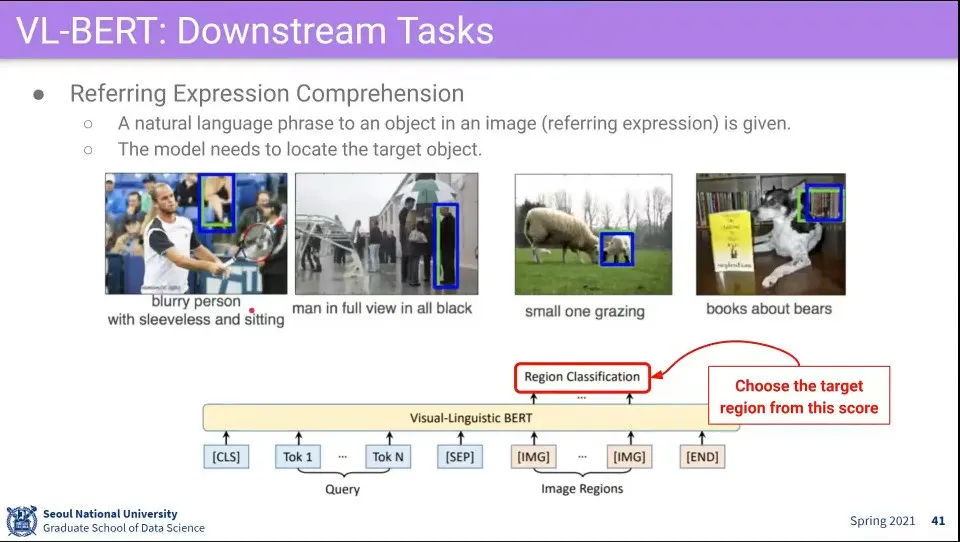
이미지에서 text가 가리키는 부분을 찾아 냄
•
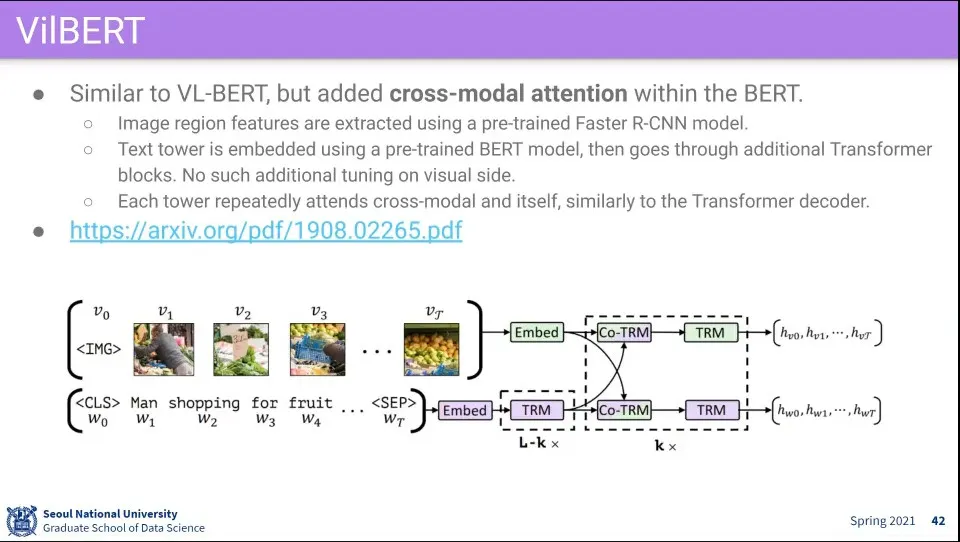
VilBERT는 VL-BERT와 비슷함
•
차이가 있는 것은 cross-modal attention을 사용한 것
◦
이미지와 텍스트가 각각 상대방에 대해서도 attention하고 다시 자기 자신에 대해서도 attention 함
•
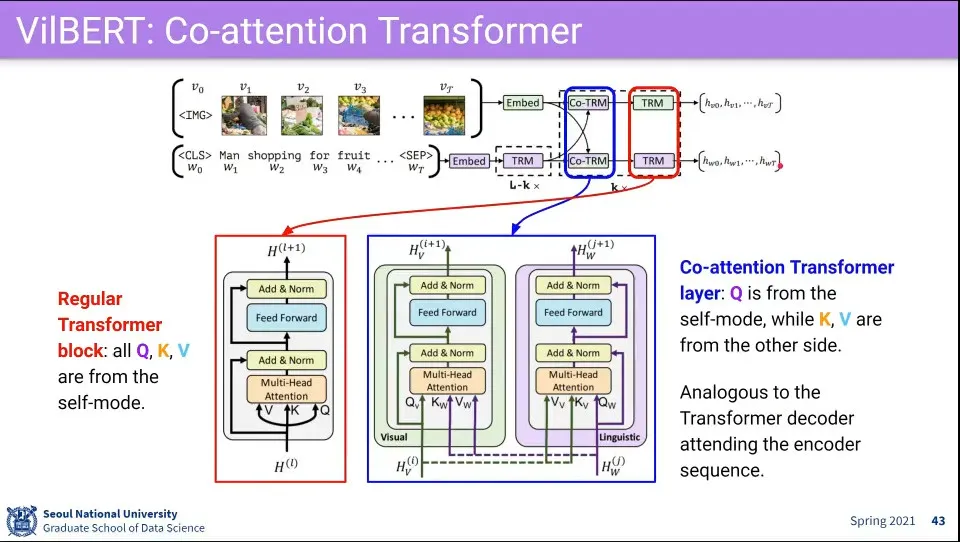
순서에서 TRM은 자기 자신에 대해 Transform을 하고, Co-TRM은 상대방에 대해 Transform 함. 이 과정을 반복해서 상대에 대한 관계를 학습 함
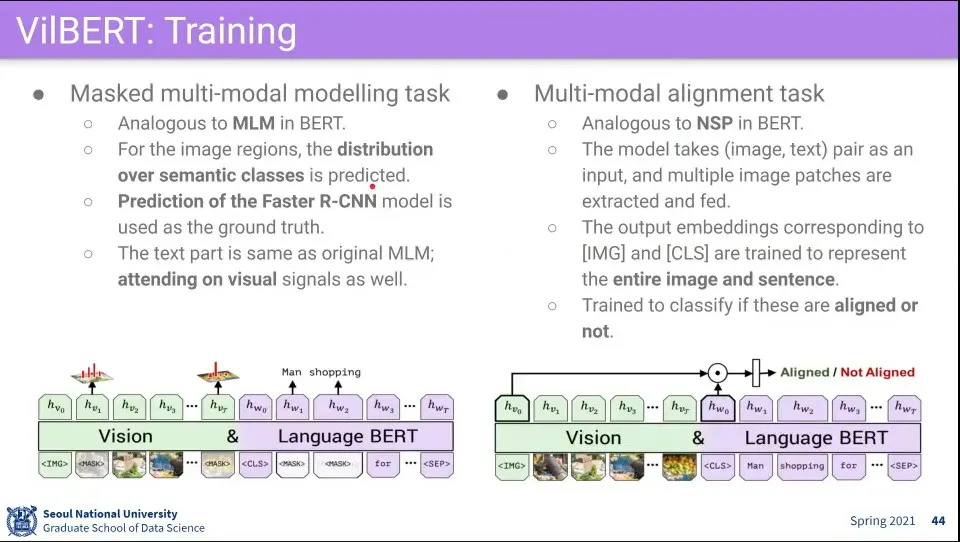
•
Vision과 Language에 대해 각각 Mask를 씌워서 예측 함
•
추가로 이미지와 텍스트가 서로 상관이 있는 것인지 예측 함
◦
이것은 굉장히 강력하다고 함

•
활용 예 - caption 기반 이미지 검색
