

이 논문은 video에서 unsupervised learning을 위한 stand-alone 목적으로 feature prediction을 탐구하고, feature prediction 목적을 단독으로 사용하여 학습된 vision 모델의 컬렉션인 V-JEPA를 소개한다. 이것은 image encoder, text, negative examples, reconstruction 또는 다른 supervision 소스를 사용하지 않고 학습된다. 모델은 공개된 데이터셋에서 수집된 2M 비디오에서 학습되었고 downstream 이미지와 비디오 task에서 평가되었다. 우리의 결과는 비디오 feature를 예측하여 학습하는 것이 움직임과 외형 기반 task 모두에서 잘 동작하는 다재다능한 visual representation을 이끈다는 것을 보인다. 이는 모델 파라미터를 조정하지 않고도 예컨대: frozen backbone으로 사용할 때도 해당된다. 가장 큰 모델인 ViT-H/16은 비디오로만 학습되고, Kinetics-400에서 81.9%, Something-Something-v2에서 72.2%, ImageNet1K에서 77.9%의 성능을 달성한다.
1 Introduction
인간은 망막에서 발생하는 low-level 신호를 시공간적으로 의미 있는 이해로 매핑하는 놀라운 능력을 소유하고 이를 통해 object나 global 움직임 같은 개념을 통합할 수 있다. 머신 러닝 커뮤니티의 오래 목표 중 하나는 이러한 인간의 unsupervised learning을 이끄는 원리나 목적을 식별하는 것이다. 이와 관련된 한 가지 가설은 predictive feature principle에 기반한다. 이것은 시간적으로 인접한 센서 자극의 representation이 서로 예측 가능해야 한다는 것을 제시한다.
이 연구에서 비디오에서 visual representation을 unsupervised learning하는 stand-alone object로써 feature prediction을 재검토한다. 이 분야의 여러 발전들 —예컨대 vision에서 transformer 아키텍쳐의 표준 사용, masked autoencoding 프레임워크의 성숙, query 기반 feature pooling, joint-embedding predictive architectures(JEPA)와 더 큰 데이터셋— 을 기반으로 우리는 video joint-embedding predictive architecture(V-JEPA)라는 현대적이고 개념적으로 간단한 방법을 통합한다. 이는 pre-trained image encoder, text, negative examples, human annotation 또는 pixel level reconstruction을 사용하지 않고 feature prediction에만 의존한다.
우리는 간단한 질문에 답하고자 한다.
“현대적인 도구를 사용하여 feature prediction이 video에서 unsupervised learning을 위한 stand-alone 목적으로 얼마나 효과적인가?”
이를 위해 우리는 공개적으로 접근 가능한 데 2M 비디오의 데이터셋에서 masked modeling prediction task과 joint-embedding predictive architecture와 결합하여 V-JEPA 모델 계열을 pre-train한다(그림 2). 우리는 frozen 평가와 end-to-end fine-tuning을 모두 사용하여 여러 image와 video의 downstream task에서 성능을 측정한다. 우리의 결과는 feature prediction이 pixel prediction 방법 보다 훨씬 짧은 학습 스케쥴로도 video에서 unsupervised learning을 위한 효과적인 stand-alone 목적으로 활용될 수 있음을 시사한다. 구체적으로
•
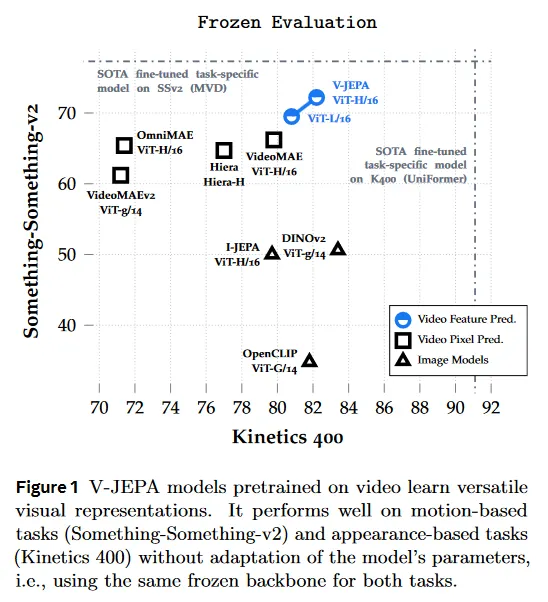
feature prediction은 모델 가중치의 변경 없이 downstream 이미지와 비디오에 걸쳐 잘 수행되는 다재다능한 visual representation을 이끈다. 예컨대 frozen backbone을 사용하여 V-JEPA는 시간적 이해를 fine-tuning해야하는 Something-Something-v2 task에서 우리가 고려한 방법들 중에서 최고의 성능(6% 정확도 상승)을 달성한다. 또한 V-JEPA는 Kinetics400 같은 task에서도 경쟁력 있으며, 이러한 작업에서 appearance-based feature가 충분하여 DINOv2 같은 최첨단 이미지 모델이 탁월한 성과를 낸다(그림 1과 Table 6).
•
feature prediction으로 학습된 model은 frozen 평가 프로토콜(attentive probing) 하에 pixel prediction 접근을 능가하고, full fine-tuning 하에 pixel prediction과 경쟁력 있으면서도 훨씬 짧은 학습 스케쥴을 사용한다(Table 5, 6)
•
feature prediction을 사용하여 학습된 모델은 pixel prediction 접근 보다 더 label 효율적이다. 사용 가능한 라벨링된 예제의 수를 줄이면 V-JEPA와 pixel-reconstruction 모델 사이의 성능 격차가 증가한다(Table 7).
2 Related Works
Slow Features.
시간적으로 인접한 표현들이 서로의 예측 가능하도록 하는 한 가지 방법은 그것들이 시간에 따라 천천히 변하도록 하는 것이다. 예측 feature를 목표로 한 초기 연구는 개별 비디오 프레임의 representation이 locally 시간적 불변성을 갖도록 장려하면서 SFA, SSA, Simulated Fixations에서처럼 spectral 방법을 사용하여 representation 붕괴를 방지한다. 더 최근에 Horoshin et al(2015), Wang et al(2010)은 siamese(쌍둥이) convolutional network를 학습하여 두 연속 프레임의 representation을 동일한 점에 매핑하고 pair-wise margin loss와 triplet loss를 통해 멀리 떨어진 프레임의 representation이 다양하도록 장려한다. 또 다른 연구들은 noise contrastive estimation을 사용하여 시간적 불변성을 구현한다. 이 논문에서는 시간적 불변성을 넘어서 masked modeling을 사용한 feature prediction을 탐구한다.
Predictive Features.
local invariance를 넘어, 한 time-step에서 frame이나 clip의 representation에 다른 time-step의 고유한 representation으로 매핑하는 predictor network를 학습시키는 연구들이 존재한다. Srivastava et al(2015), Vondrick et al(2016), Wang et al(2023b)는 frozen pre-trained image 나 video encoder 위에 이러한 video feature predictor network를 학습시킨다. target feature extractor를 unfreezing하면 여러 방법이 video encoder와 predictor network를 동시에 학습시키면서 supervised action forecasting loss를 사용하거나 contrastive loss에서 먼 클립의 representation을 negative sample로 사용하는 방법으로 붕괴를 방지한다. 이들은 종종 작은 convolutional encoder에 초점을 맞춘다. feature 공간에서 누락된 정보를 예측하여 representation을 학습하는 아이디어는 joint-embedding predictive architecture(JEAP)에서도 핵심이다. 이것은 siamese encoder와 predictor network를 결합한다. JEPA는 audio data, image data와 같은 여러 모달리티에서 성공적으로 구현되었다. 이 연구에서 우리는 self-supervised learning의 최근 진보를 활용하여 이 패러다임을 비디오 데이터로 확장한다.
Advances in Self-Supervised Learning.
vision transformer의 사용은 joint-embedding architecture을 사용하는 self-supervised learning에서 표준 관행이 되었으며 학습 가능한 mask token을 가진 transformer로 pixel decoder를 파라미터화하여 픽셀 공간에서 masked image 모델링을 가능하게 한다. 이는 autoencoding 방법의 representation 품질에서 큰 변화를 보였다. 이러한 생성 방법은 이후 spatio-temporal masking을 사용하여 비디오 데이터로 확장되었다. 최근에는 cross-attention에 기반한 학습 가능한 pooling 메커니즘을 사용하여 masked image autoencoder의 representation이 상당히 개선할 수 있음을 보였다. 마지막으로 조심스러운 설계 선택을 통해 BYOL의 non-contrastive collapse prevention 전략이 최근 image feature prediction 방법과 함께 작동하도록 만들어졌으며, 이는 수작업으로 만든 이미지 변환에 대한 불변성에 의존하지 않고도 다양한 downstream task에 활용될 수 있는 representation을 학습하는 능력을 시연한다.
Feature Prediction versus Pixel Reconstruction.
픽셀 공간에서 예측하는 접근은 visual input의 모든 low-level detail을 포착하기 위해 상당한 모델 수용량과 계산 자원을 할당해야 한다. 반면에 latent space에서 predict 접근은 target representation에서 관련 없거나 예측 불가능한 pixel-level의 detail을 제거할 수 있는 유연성을 갖는다. representation 공간에서 예측은 linear probing 또는 low-shot adaptation을 통해 많은 downstream task에 걸쳐 잘 수행되는 다재다능한 representation을 이끄는 것을 보였으며, 픽셀 레벨 reconstruction과 비교하여 pre-training 동안 효율성을 보인다. Baevski et al(2022a,b)의 작업은 추가적으로 representation 공간에서 예측이 이미지, 오디오, 텍스트 도메인에서 경쟁력있는 end-to-end fine-tuning 성능을 가져온다는 것을 보인다. 이 연구에서 우리는 이러한 발견을 비디오 모달로 확장한다.
3 Methodology: Video-JEPA
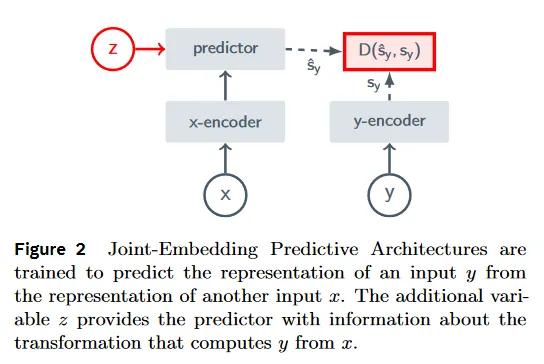
우리의 목표는 비디오에서 visual representation을 학습하기 위한 단독 목적으로써 feature prediction의 효과를 탐구하는 것이다. 이를 위해 우리는 joint-embedding predictive architecture(JEPA)를 사용한다. 그림 2에서 JEPA의 주요 아이디어는 입력 의 representation을 또 다른 입력 의 representation에서 예측하여 학습하는 것이다. 기본 아키텍쳐는 입력의 representation을 계산하는 encoder 와 의 representation에서 의 representation을 예측하는 predictor 을 구성되며, 이는 와 사이의 변환(또는 오염)을 나타내는 변수 를 조건으로 한다. 에 대한 조건화를 통해 의 다양한 변환에 대한 고유한 예측을 생성할 수 있다.
3.1 Training Objective
우리는 비디오의 한 부분에서 계산된 representation인 가 비디오의 또 다른 파트에서 계산된 representation 에서 예측가능해야 한다는 제약을 만족하도록 visual encoder 을 학습한다. 의 representation을 의 representation에 매핑하는 predictor network 는 encoder와 동시에 학습되며 조건화 변수 를 통해 의 시공간 position에 대한 명세를 제공받는다.
회귀를 이용하여 목적을 순진하게 구현하면
이것은 encoder가 입력에 관계 없이 상수 representation을 출력하는 자명한 해를 허용한다. 실제로 우리는 representation 붕괴를 막기 위해 다음의 수정된 목적을 사용한다.
여기서 은 인수에 역전파를 하지 않는 stop-gradient 연산을 나타내고 은 네트워크 의 exponential moving average이다. stop-gradient와 predictor를 함께 사용하는 EMA feature extractor의 사용은 이미지 pre-training을 위한 붕괴 방지하는 전략으로 사용되었으며, 실험적으로(Xie et al (2021) 연구되고 이론적(Tian et al, 2021)으로 연구되었다. 실제로 방정식 1에서 목적은 image pre-training을 위해 사용된 Assran et al(2023)의 loss와 유사하지만 우리는 더 안정적임을 발견된 regression으로 수정한다.
Theoretical motivation.
이 붕괴 방지 전략의 효과에 대한 이론적 동기는 BYOL 방법을 위한 Grill et al(2020)에서 제안되었다. 우리는 우리의 loss에 대한 그들의 분석의 간단히 적용 한다. 설명을 쉽게 하기 위해, 우리는 조건화 변수 의 효과를 무시하고 1차원 표현을 고려한다. 의 representation을 확률 변수 로 표기한다. 방정식 1 하에 최적 predictor는 다음의 함수 표현을 따른다.
이 최적 predictor 표현을 loss 함수에 대입하고 encoder의 기대 gradient를 평가하면 다음과 같다.
여기서 는 에 조건화된 확률 변수의 median 절대값 편차이다. 따라서 predictor가 최적인 경우, encoder는 타겟의 편차를 최소화하기 위해 비디오에 대한 가능한 많은 정보를 포착하도록 학습해야 한다. 가설은 의 representation을 계산하기 위해 exponential moving average를 통합하면 predictor가 encoder보다 빠르게 진화하고 최적에 가깝게 유지되어 붕괴를 방지한다는 것이다.
3.2 Prediction Task: Predicting from
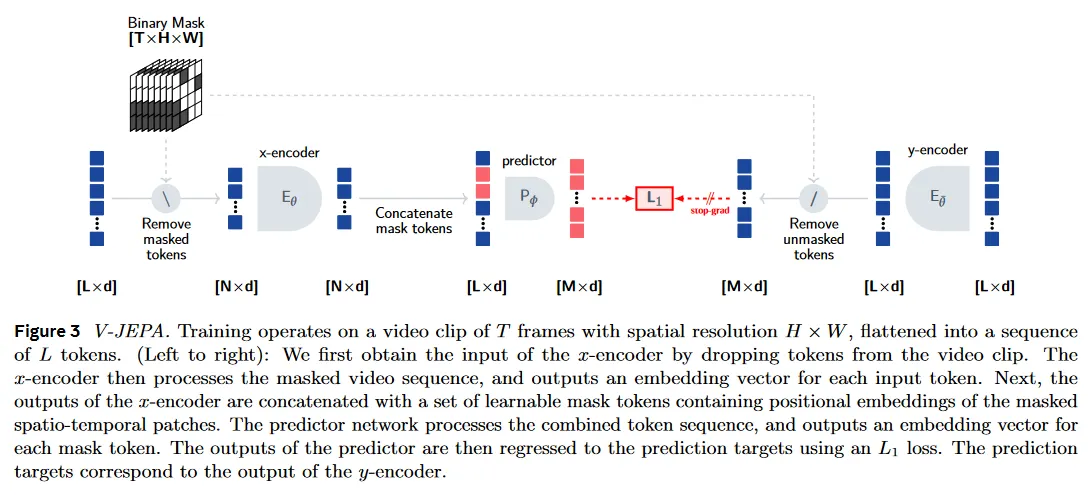
feature prediction task는 masked modeling 공식에 기반한다. 즉 비디오에서 영역 와 는 masking을 사용하여 샘플링된다. 비디오에서 를 샘플링하기 위해, 여러 개의(중복일 수 있는) 공간적으로 연속된 블록을 다양한 종횡비로 샘플링하고, 이러한 공간적 블록을 비디오의 전체 시간적 차원에 걸쳐 반복한다. 는 보완으로 취해진다. 전체 시간 차원을 커버하는 큰 연속 블록을 마스킹하여 비디오의 공간적과 시간적 중복성으로 인한 정보 유출을 제한하고, prediction task를 더 어렵게 만든다.
우리는 두 유형의 mask를 활용한다. short-range mask는 각 프레임의 15%를 커버하는 8개의 무작위로 샘플링된 타겟 블록의 합집합이고, long-range mask는 각 프레임의 70%를 커버하는 2개의 무작위로 샘플링된 타겟 블록의 합집합이다. 두 경우에 모두 샘플링된 블록의 종횡비는 범위에서 무작위로 선택된다. short-range와 long-range mask 모두 여러 블록을 샘플링하고 그 합집합을 취해 생성되므로, 평균 masking ratio는 약 90%에 이른다. 우리는 우리의 masking 전략을 multi-block이라 부르며, 섹션 4에서 다른 가능한 masking 전략과 비교한다.
3.3 Network Parameterization
우리는 video backbone으로 Vision Transformer(ViT)를 사용한다. transformer network로 비디오를 처리하기 위해, 비디오 클립을 3d grid의 개의 시공간 patch로 분할한다. 여기서 패치는 2개 연속 프레임에 걸친 16x16 픽셀 블록으로 구성된다. 우리는 이러한 시공간적 패치를 토큰이라 부른다. 그다음 이 토큰의 시퀀스는 transformer 블록의 stack에 의해 직접 처리된다. 입력 와 는 비디오의 masked 영역에 해당하며, 우리는 간단히 token의 부분집합을 dropping하여 비디오 mask를 적용한다. -encoder의 입력에서 masking을 적용하고 -encoder의 출력에서 contextualized target을 구성하기 위해 masking을 적용한다. encoder는 표준 ViT 네트워크를 이용하여 파라미터화 되는 반면 predictor는 384의 embedding 차원을 갖는 12개의 block을 가진 narrow transformer이다. masked autoencoder에서 영감을 받아 우리의 predictor는 -encoder에 의해 생성된 embedding의 시퀀스와 token의 시공간 position을 나타내는 positional embedding이 포함된 학습 가능한 mask 토큰의 시퀀스를 입력으로 취한다. predictor의 출력은 각 mask token에 대한 embedding 벡터이다. 더 자세한 내용은 그림 3과 부록 B 참조.
3.4 Pretraining Data and Evaluation Setup
Pretraining.
우리는 여러 공개된 데이터셋을 결합하여 unsupervised 비디오 pre-training 데이터셋을 구성하고 VideoMix2M이라 부른다. 구체적으로 우리는 HowTo100M(HT)와 Kinetics-400/600/700(K710)과 Something-Something-v2(SSv2)를 결합하고, Kinetics-400/600/700과 Something-Something-v2의 검증 집합과 겹치는 부분을 제거하여 약 2M 비디오를 얻었다. 우리는 VideoMix2M에서 ViT-L/16, ViT-H/16과 ViT-H/16_384 transformer 모델을 학습한다. ViT-L/16과 ViT-H/16 모델을 위해 3072의 배치 사이즈를 사용하고 ViT-H/16_384 모델을 위해 2400의 배치 사이즈를 사용한다. 각 모델은 4 frame씩 건너 뛴 16 프레임의 비디오 클립을 입력으로 취하며, 이는 평균적으로 약 3초 클립에 해당한다. ViT-L/16과 ViT-H/16은 공간 해상도 224에서 비디오를 처리하고 ViT-H/16_384는 384의 입력 해상도를 사용한다. 부록 C 참조.
Evaluations.
pre-trained 모델은 downstream 비디오와 이미지 task에서 평가된다. video task에 대해 VideoGLUE 벤치마크의 부분집합을 사용하여 다양한 능력을 테스트한다. 구체적으로 Kinetics 400(K400)에서 action recognition, Something-Something-v2(SSv2)에서 motion 분류, AVA에서 action localization을 조사한다. Kinetics에서 action classification은 특정 object의 존재를 통해 비디오에서 다양한 action 클래스가 추론될 수 있기 때문에, 모델의 appearance-based 이해를 평가한다. something-something-v2에서 motion 분류는 비디오에서 특정한 객체의 appearance/presence와 독립적으로 action 클래스가 분리되기 때문에 모델의 시간적 이해를 평가한다. 마지막으로 AVA에서 action localization은 비디오에서 motion의 이해하고 localize하는 모델의 능력을 평가한다. 우리는 표준 관례를 따르고 여러 공간적, 시간적 view를 샘플링하여 K400과 SSv2에서 정확도를 리포트한다. 정적 이미지 task에 대해 우리는 ImageNet에서 object recognition, Places205에서 장면 분류, iNaturalize 2021에서 fine-grained recognition을 탐구한다.
4 What Matters for Learning Representations from Video?
이 섹션에서 우리는 몇 가지 설계 선택의 기여도를 분리하여 살핀다. a) feature prediction vs pixel prediction 목적의 사용 b) pre-training 데이터 분포 c) downstream task에서 모델의 representation을 활용하기 위한 feature pooling 전략 d) masking 전략, 무엇에서 무엇을 예측하는가?
4.1 Predicting Representations versus Pixels
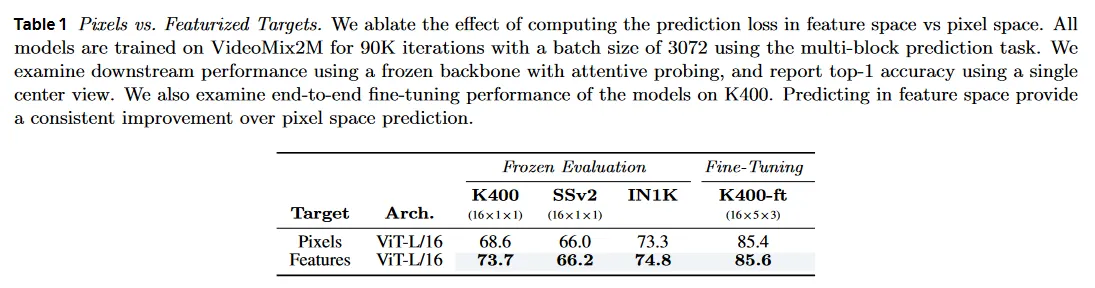
우선 representation 공간에서 prediction loss를 계산하는 효과를 ablate한다. 우리는 ViT-L/16 모델의 쌍을 각각 V-JEPA feature prediction loss 또는 masked autoencoder에서와 같이 normalized pixel 값을 사용하는 mean-squared error loss로 학습하고, 두 접근 모두에서 learning rate와 weight decay 스케쥴을 조정했다. 모든 모델은 VideoMix2M에서 90K iteration으로 3072 batch 크기의 multi-block masking으로 pre-train된다. 우리는 Kinetics-400(K400), Something-Something-v2(SSv2), ImageNet-1K(In1K)에서 성능을 평가하며, frozen backbone과 attentive probe를 사용하여, single center view의 top-1 정확도를 리포트한다. 또한 Kinetics-400에서 모델의 end-to-end fine-tuning 성능도 조사한다.
이 비교 결과는 Table 1 참조. feature 공간에서 예측하는 것이 pixel 공간의 예측보다 video backbone의 frozen 평가와 end-to-end fine-tuning 모두에서 일관되게 개선된 성능을 제공한다.
4.2 Pretraining Data Distribution
다음으로 Table 2에서 pre-training 데이터 분포의 영향을 연구한다. 대규모 스케일 데이터셋을 활용하는 것은 텍스트와 이미지 같은 다른 모달리티에서 발전을 가능하게 하는데 핵심이다. 우리는 비디오 데이터에서도 유사한 경향이 유지되는지 여부를 조사한다. 계산 예산의 가능한 confounding 변수를 통제하기 위해, Table 2에서 모든 모델은 3072 배치크기를 사용하여 90K 반복동안 pre-train한다. 우리는 frozen backbone과 attentive probe을 사용하여 K400, SSv2, IN1K에서 downstream 결과를 리포트하고 single center view를 사용하여 top-1 정확도를 리포트한다.
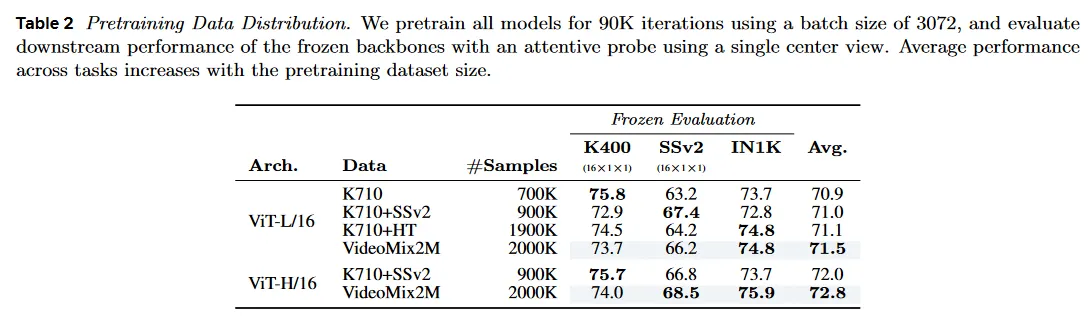
Table 2에서 pre-training 데이터셋의 크기가 증가함에 따라 전체 task에서 평균 성능이 점진적으로 증가하는 것을 볼 수 있다. 그러나 각 특정한 downstream task에서 최고의 성능은 특정 task에 맞춰 pre-training 데이터를 독립적으로 선택할 때 얻어진다. 예컨대 L/16 모델은 K710+SSv2에서 pre-trained일 때 SSv2에서 최고의 성능을 기록하고, K710에서만 pre-trained일 때 K400에서 최고의 성능을 기록하고, K710+HT에서만 pre-trained일 때 IN1K에서 최고의 성능을 기록한다. 모든 task에서 최고의 평균 성능은 모든 데이터 소스를 결합한 VideoMix2M을 pre-training 할 때 달성된다. 유사하게 H/16 은 K710+SSv2에서 pre-trained일 때 VideoMix2M에서 pre-trained인 H/16보다 K400 점수가 더 높지만, 평균적으로 H/16에서 최상위 성능은 VideoMix2M에서 pre-trained인 것이다.
4.3 Evaluation: Attentive Probing
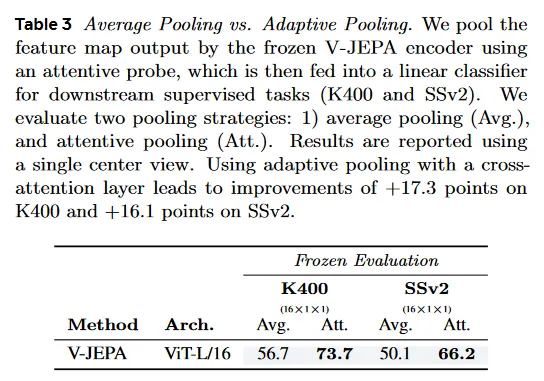
다음으로 모델의 representation을 downstream task에 적용하기 위한 feature pooling 전략을 탐구한다. 방정식 (1)에서 prediction 목적이 unnormalized이므로 encoder가 선형적으로 분리 가능한 부분 공간을 생성할 이유가 사전에 존재하지 않는다. 따라서 frozen backbone의 출력 features를 pool 하기 위해 단순한 linear operation (평균)을 사용하는 대신, 우리는 학습 가능한 non-linear pooling 전략을 탐구한다. 구체적으로 downstream task에서 frozen pre-trained backbone을 평가할 때, 학습 가능한 query token을 사용한 cross-attention layer를 학습한다. 그 다음 cross-attention layer의 출력은 query token에 다시 더해지고(residual connection), 그 다음 단일 GeLU activation과 LayerNorm이 따르는 2-layer MLP로 공급되고 마지막에 linear classifier에 연결된다.
Table 3에서 학습 가능한 cross-attention layer를 사용한 adaptive pooling을 사용하는 것이 K400에서 17점, SSv2에서 16.1점의 상당한 개선을 이끄는 것을 볼 수 있다. attentive-probe를 사용하는 것은 부록 E에서 리포트 된 것과 같이 다른 baseline 모델에 대해서도 이점을 줄 수 있다.
4.4 Prediction Task: Predicting y from x
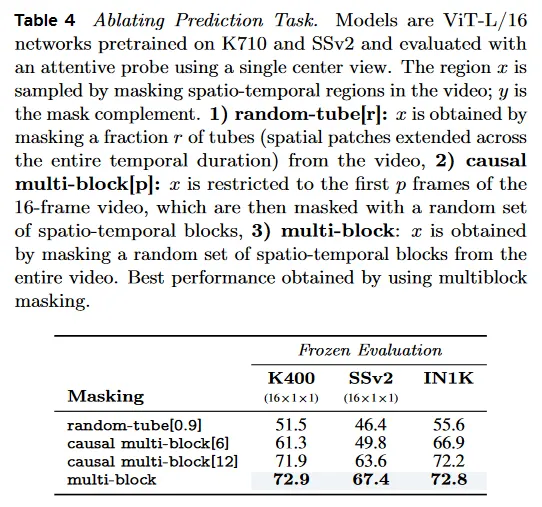
V-JEPA pre-training에서 사용된 masking 전략에서 ablation을 수행한다. 우리는 다음의 masking 전략을 조사한다. random-tube[r]는 이 전략에서는 비디오에서 무작위로 비율 의 tube(전체 시간 duration에 걸쳐 확장된 공간 patch)를 제거하여 가 얻어진다. causal multi-block[p]는 를 16-프레임 비디오의 첫 프레임에 제한한 다음 이를 무작위 spatio-temporal block 집합으로 마스킹한다. multi-block은 전체 비디오에서 무작위 spatio-temporal 블록 집합을 masking하여 를 얻는다. Spatio-temporal 블록은 섹션 3.2에서 설명된 파라미터를 사용하여 샘플링된다. masked spatio-temporal block의 크기와 수량에 대한 ablation은 부록 E.4에서 제공된다.
Table 4는 비디오에서 큰 연속 블록을 제거한 후에 예측을 하도록 네트워크를 강제하는 multi-block 전략을 사용하여 를 샘플링할 때 최고 결과를 얻는다는 것을 보인다. causal multi-block 전략에서와 같이 가 비디오의 첫 몇 프레임에서만 샘플링될 때, 우리는 downstream 성능이 감소를 관찰한다. 마지막으로 비디오에서 90%의 tube가 무작위로 masking 되는 random-tube 전략은, 우리의 feature prediction 목적과 결합될 때 low-semantic 품질의 feature로 이어진다.
5 Comparison with Prior Work
섹션 5.1에서는 모든 baseline에 대해 유사한 아키텍쳐를 사용하면서 V-JEPA를 pixel prediction에 의존하는 비디오 접근과 비교하여 feature prediction의 영향을 조사한다. 이어서, 섹션 5.2에서 아키텍쳐 제약을 제거하고 self-supervised 비디오와 이미지 pre-training 접근 방식에 대해 아키텍쳐에 걸쳐 최고의 성능을 보고한다. 마지막으로 섹션 5.3에서 다른 self-supervised 비디오 pre-training 접근과 비교하여 V-JEPA의 라벨링 효율성을 탐구한다. 평가 설정에 대한 자세한 내용은 부록 D 참조.
5.1 Comparison with Pixel Prediction
feature prediction pre-training의 효과성을 조사하기 위해 우리는 우선 V-JEPA를 pixel prediction loss에 의존하는 video masked modeling model과 비교한다. 우리는 ViT-L/16 encoder 또는 유사한 파라미터 수를 갖는 Hiera-L encoder를 사용하여 모든 모델을 평가하여, 모델 아키텍쳐의 가능한 confounding factor를 통제 한다. pixel prediction baseline에 대해 우리는 비디오에서만 vision transformer autoencoder를 학습하는 VideMAE와 비디오에 대해 hierarchical transformer autoencoder를 학습시키는 Hiera, 정적 이미지와 비디오에 대해 동시에 vision transformer autoencoder를 학습시키는 OmniMAE를 고려한다.
Table 5는 downstream video와 image task에 대한 attentive probe를 사용한 frozen 평가와 end-to-end fine-tuning를 모두 조사한다. frozen 평가에서 V-JEPA는 ImageNet을 제외한 모든 downstream task에서 baseline을 능가한다. ImageNet에서는 74.8%를 달성하며 이는 ImageNet에 직접 학습된 OmmniMAE 모델의 75.1%와 비교할만 하다. 따라서 V-JEPA는 비디오에서만 pre-training 했음에도 ImageNet과 비교 가능한 성능을 달성한다.
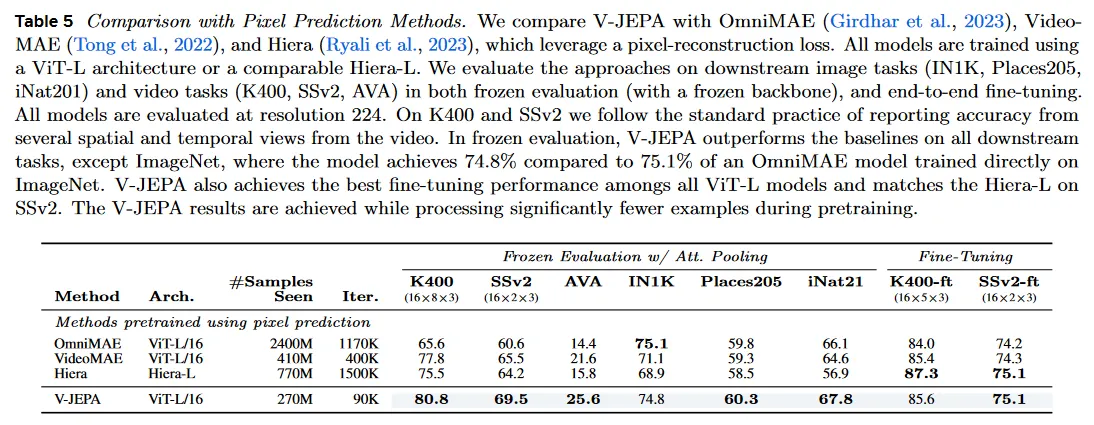
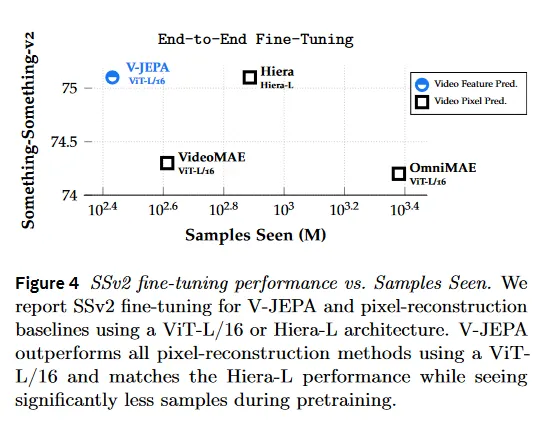
fine-tuning 프로토콜에서 V-JEPA는 또한 ViT-L/16으로 학습된 임의의 모델에서 최고 성능을 달성하며 hierarchical prior에서 이점을 얻는 SSv2에서 Hiera-L의 성능과 일치한다. V-JEPA 모델은 pre-training 동안 상당히 적은 샘플을 처리하면서도 이러한 결과를 달성하여(그림 4), 학습 원리로서의 feature prediction의 효율성을 시연한다.
5.2 Comparison with State-of-the-Art
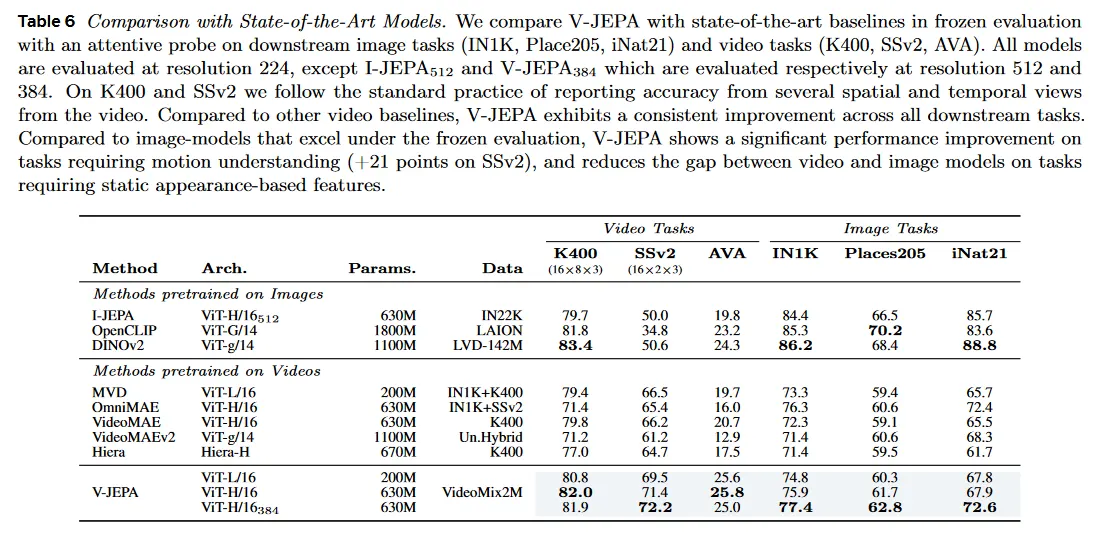
다음으로 Table 6에서 우리는 비디오에서 pra-trained인 V-JEPA 모델이 backbone encoder를 freezing하고 그 위에 attentive prob를 학습시킬 때, 최첨단 self-supervised 이미지와 비디오 모델들과 비교하여 어떤 성능을 보이는지 살펴본다. 우리의 이미지 pre-trained baseline에는 OpenCLIP, DINOv2, I-JEAP가 포함된다. Open-CLIP 모델은 contrastive image-text 정렬 목적으로 학습되며, DINOv2와 I-JEPA는 self-supervision으로 학습된다. 이러한 모델은 frozen-evaluation 성능에서 뛰어난 것으로 알려져 있다. 즉 end-to-end fine-tuning 없이 동시에 다양한 downstream task에 적용될 수 있는 visual feature를 생성하는 능력이 뛰어나 매우 경쟁력 있는 baseline을 제공한다. 우리의 비디오 pre-trained baseline에는 VideoMAE, Ommni-MAE, Hiera, VideoMAEv2, MVD가 포함된다. OpenCLIP, DINOv2와 Video-MAEv2 모델은 1B 파라미터를 포함하는 Giant/Gigantic vision transformer 아키텍쳐로 파라미터화 되어 대규모 이미지 또는 비디오 데이터셋에서 학습된다.
Comparison with video models.
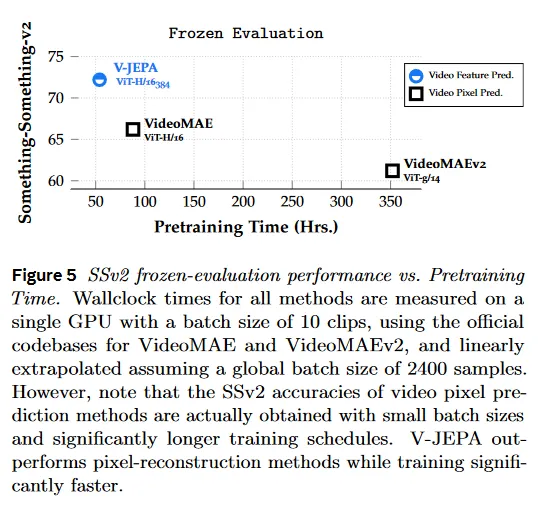
대규모 비디오 baseline과 비교할 때 V-JEPA 모델은 모든 downstream 비디오와 이미지 작업에서 이전 모델을 상당한 격차로 능가한다(Table 6). 우리의 H/16 모델은 가장 공개적으로 접근 가능한 큰 VideoMAE, VideoMAEv2, OmniMAE, MVD와 Hiera 모델을 motion 이해에서(Something-Something-v2) 최소 +5점, action recognition(Kinetics-400)에서 +2점, action detection(AVA)에서 +5점, object recognition(ImageNet-1K)에서 +1점, scene recognition(Places205)에서 +2점, fine-grained recognition(iNaturalize)에서 +0.2점 능가한다. 게다가 그림 5의 pre-training 시간과 비교할 때, 우리는 V-JEPA가 대규모 pixel prediction 모델과 비교하여 약 2배 빠른 속도를 달성함을 볼 수 있다.
Comparison with image models.
motion의 fine-grained understanding(Something-Something-v2)이 필요한 작업에서 V-JEPA 모델은 DINOv2, OpenCLIP, I-JEPA와 같은 대규모 이미지 baseline과 비교하여 상당한 개선(약 21점 상승)을 제공한다. video에서 self-supervised pre-training은 정적 이미지 데이터셋에서 쉽게 학습되지 않는 동적 컨셉을 모델링할 수 있게 한다. 유사하게 우리는 V-JEPA 모델이 action localization에서 이미지 기반 pre-training을 능가하는 것을 관찰할 수 있다.
Kinetic-400에서 이미지 모델이 잘 동작하는 것을 볼 수 있다. 예컨대 DINOv2가 이전에 linear probe로 K400에서 78.4%를 보고 했지만, 우리는 attentive probe를 사용하여 g/14 모델의 frozen 평가를 83.4%까지 높였다. 이 경우에 우리의 H/16 모델은 82.0% top-1 정확도를 달성한다. 많은 Kinetics 비디오 라벨링이 motion에 대한 이해 없이 appearance-based 단서를 사용하여 추론될 수 있다는 점은 주목할만한 가치가 있다.
V-JEPA 모델은 이미지 분류 작업에서 이미지 모델과 격차를 좁힌다. 특히 V-JEPA는 one-layer attentive probe를 사용하여 ImageNet에서 77.4%의 점수를 달성하며, 이것은 two-layer attentive probe를 사용하여 77.9%로 추가 개선될 수 있다. 더 일반적으로 우리는 V-JEPA를 다른 비디오 모델을 학습하는데 사용된 데이터셋이 너무 제한적이고 이미지 모델을 사용하는 인터넷 규모의 pre-training 데이터의 시각적 다양성이 부족하다고 가정한다. 따라서 다양한 공개 비디오 데이터셋을 구축하는데 초점을 맞춘 향후 연구에 가치가 있다.
5.3 Label-efficiency
우리는 pre-trained backbone이 적은 수의 라벨로 downstream task에 적응하는 능력을 측정하여 다른 self-supervised video 모델과 비교하여 V-JEPA의 라벨링 효율성을 조사한다. 구체적으로 우리는 각 데이터셋에서 attentive probe를 학습에 사용 가능한 라벨이 있는 예제의 비율을 변경하면서 Kinetics-400과 Something-Something-v2에 대한 frozen model의 성능을 조사한다. 우리는 여러 low-shot 설정에서 probe를 학습한다. 학습 셋의 5%, 10%, 또는 50%를 사용하고, 각 설정에서 3개의 무작위 분할을 취하여 더 견고한 메트릭을 얻고 각 모델에 대해 9개 다양한 평가 실험을 수행한다. Table 7은 K400과 SSv2 validation 집합을 사용한 mean performance와 표준 편차를 리포트한다.
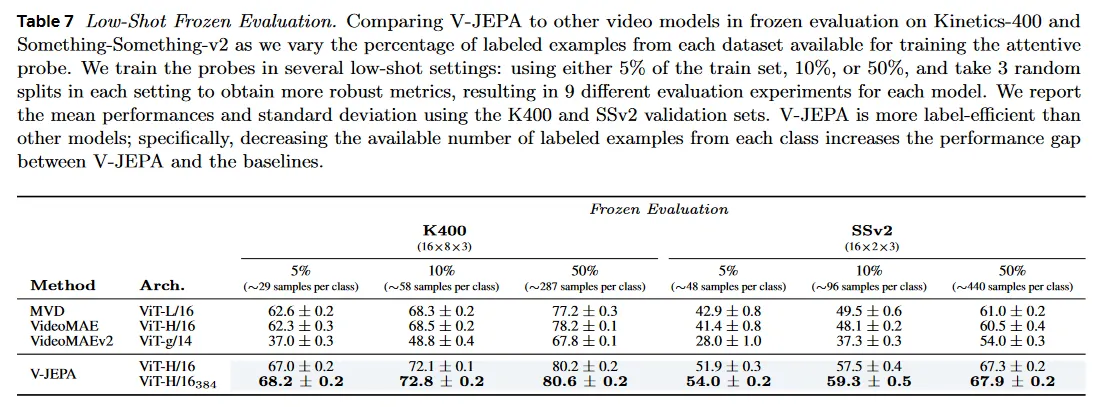
우리는 V-JEPA가 다른 self-supervised 비디오 모델보다 더 라벨링 효율적이라는 것을 발견한다. attentive probe에 사용가능한 예제의 수를 줄이면 V-JEPA와 다른 모델 들 사이의 성능 격차를 증가시킨다. 특히 K400에서 가장 큰 V-JEPA 모델의 성능은 라벨링된 예제의 수를 약 10배 감소시킬 때(클래스당 287개 예제를 클래스당 29개 예제로) 12% 감소하여 68.2% top-1 정확도를 기록한다. 반면에 VideoMAEv2는 30% 감소하여 37% top-1 정확도, VideoMAE는 15.9% 감소하여 62.3% top-1 정확도이고 MVD는 14.6% 감소하여 62.6% top-1 정확도를 기록한다.
SSv2에서 유사한 관찰이 유지된다. SSv2에서 가장 큰 V-JEPA 모델의 성능은 라벨링 예제의 수를 약 10배씩 감소시킬 때(클래스 당 440 예제에서 클래스당 48 예제) 13.9% 감소하여 54.0%의 top-1 정확도인 반면에 VideoMAEv2는 26% 감소하여 28% top-1 정확도이고, VideoMAE는 19.1% 감소하여 41.4% top-1 정확도이고 MVD는 18.1% 감소하여 42.9% top-1 정확도를 기록한다.
6 Evaluating the Predictor
다음으로 우리는 V-JEPA 모델을 정성적으로 조사한다. V-JEPA의 predictor 네트워크가 masked region의 positional 정보가 주어질 때, visible region 에서 masked spatio-temporal region 의 representation을 예측한다는 것을 떠올려라(섹션 3). feature-space prediction의 grounding을 정성적으로 조사하기 위해, 우리는 pre-trained encoder와 predictor network를 freeze하고 V-JEPA 예측을 해석 가능한 픽셀에 매핑하는 conditional diffusion decoder를 학습시킨다. 특히 decoder는 비디오에서 누락된 region에 대해 예측된 representation만 입력 받으며 비디오의 unmasked region에 접근할 수 없다(그림 6a).
masked video가 주어지면 우리는 V-JEPA pre-trained 모델을 사용하여 누락된 region의 representation을 예측한 다음 decoder를 사용하여 representation을 픽셀 공간에 투영한다. 그림 6b는 다양한 랜덤 시드에 대한 decoder 출력을 보인다. 샘플 사이의 공통적인 품질은 predictor representation에 포함된 정보를 나타낸다.
그림 6b는 V-JEPA feature 예측이 실제로 ground임을 보이고 video의 unmasked region과 spatio-temporal 일관성을 보인다. 구체적으로 그림 6b에서 샘플은 V-JEPA predictor가 positional 불확실성을 올바르게 포착하고, 일관된 모션을 갖는 다양한 location에서 다양한 visual object를 생성함을 보인다. 샘플들의 일부는 또한 visual object가 부분적으로 occlusion 후에도 일관성을 유지하는 것을 보임으로써 object-permanence에 대한 이해를 보인다.

7 Conclusion
이 연구에서 우리는 비디오에서 unsupervised learning을 위한 독립 목적으로 feature prediction의 효과를 탐구하고, self-supervised feature prediction 목적만 사용하여 학습된 vision 모델의 컬렉션인 V-JEPA를 도입한다. V-JEPA 모델은 모델 파라미터의 적용 없이 다양한 downstream 이미지와 비디오 task를 해결할 수 있는 능력을 보이고, action recognition, spatio-temporal action detection, image classification task에 대해 frozen 평가에서 이전의 비디오 representation learning 접근을 능가한다. 게다가 우리는 비디오에서 V-JEPA를 pre-training 하는 것이 fine-grained motion 이해를 요구하는 downstream task를 해결하는데 특히 효과적임을 보인다. 반면 인터넷 규모 데이터셋에서 학습된 대규모 이미지 모델은 이런 작업에서 부족함을 보인다. 마지막으로 우리는 실험적으로 V-JEPA 모델들이 라벨 효율적인 학습자이고 적은 라벨링 예제만 사용할 때도 downstream 작업에서 좋은 성능을 보이는 것을 관찰했다.
