
U-Net
일반적으로 diffusion 모델에 대한 2가지 backbone 아키텍쳐 선택이 존재하는데 U-Net과 Transformer이 그것이다.
U-Net는 downsampling stack과 upsampling stack으로 구성된 아키텍쳐이다. downsampling과 upsampling 단계는 각각 conv, ReLU, pooling 등을 수행한 후에 마지막에 이미지의 크기를 (일반적으로 2배)로 줄이거나 늘린다. 이때 이미지 크기를 줄일 때는 channel의 크기를 키우고, 이미지 크기를 늘릴 때는 channel의 크기를 줄여서 전체 데이터포인트의 수를 일정하게 유지한다.
Transformer에서 Decoder가 Encoder를 참조하는 것과 유사하게 Upsampling 단계에서 동등한 depth의 Downsampling의 데이터를 concatenate 하여 데이터를 처리한다. 이것을 skip connection이라 한다.
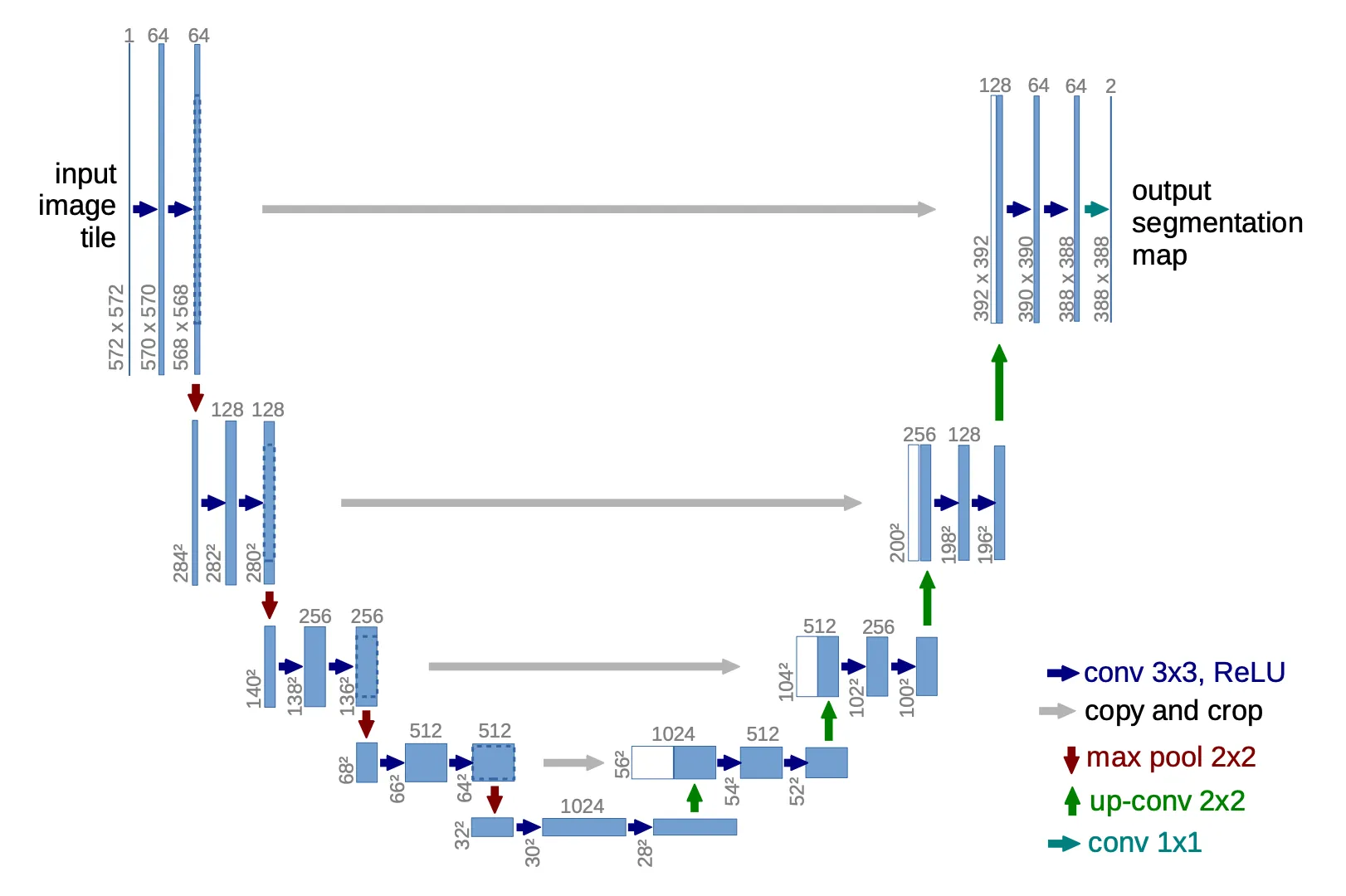
Diffusion Model에서 U-Net을 사용할 때는 reverse 단계에 U-Net을 적용하며 —forward 단계는 계산으로 구할 수 있으므로— 각 reverse step 마다 U-Net을 적용한다. 즉, diffusion model에서 reverse step을 1000번 수행하면 U-Net을 1000번 통과하게 된다.
Efficient U-Net
Imagen은 U-Net에서 다음과 같이 여러 설계를 수정하여 efficient U-Net을 만들었다.
•
낮은 해상도에 더 많은 residual lock을 추가하여 모델 파라미터를 고해상도 블록에서 저해상도로 이동
•
skip connection을 로 확장
•
forward pass의 속도를 개선하는 측면에서 downsampling(convolution 전에 이동)과 upsampling(convolution 후에 이동) 연산의 순서를 반전.
그들은 noise conditioning 증강, dynamic thresholding과 efficient U-Net이 이미지 품질에 더 중요하지만 텍스트 인코더 크기를 scaling하는 것이 U-Net 크기 보다 중요하다는 것을 발견했다.
