

•
Image Translation은 style이 다른 이미지를 생성해 내는 것.
•
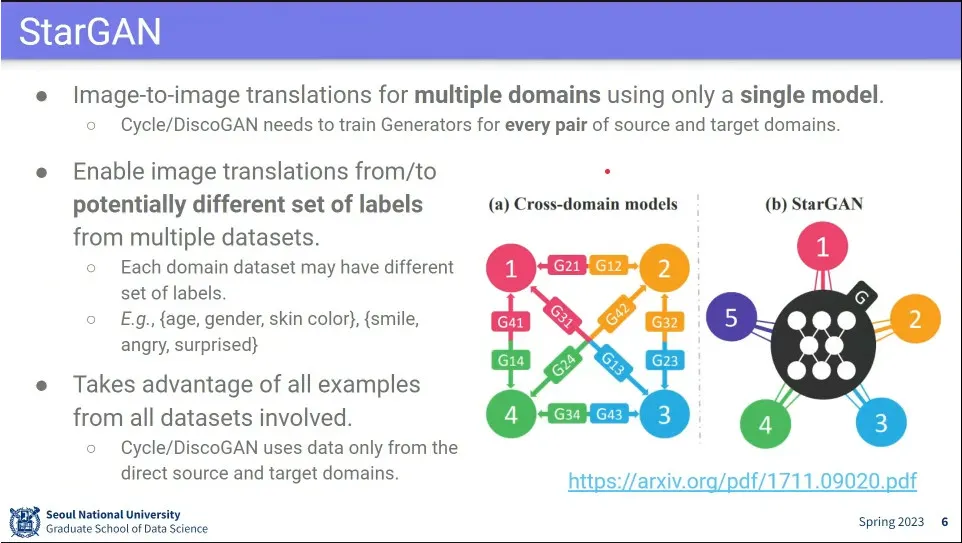
StyleGAN은 여러 style 변환을 만들려면 그 변환 마다 학습을 따로 해줘야 하는 문제가 있음. 그걸 하나로 합친게 StarGAN
◦
하나의 모델에 Style을 다 학습 시켜 놓고, 그걸로 다양한 Style 변환이 가능하도록 함.
•
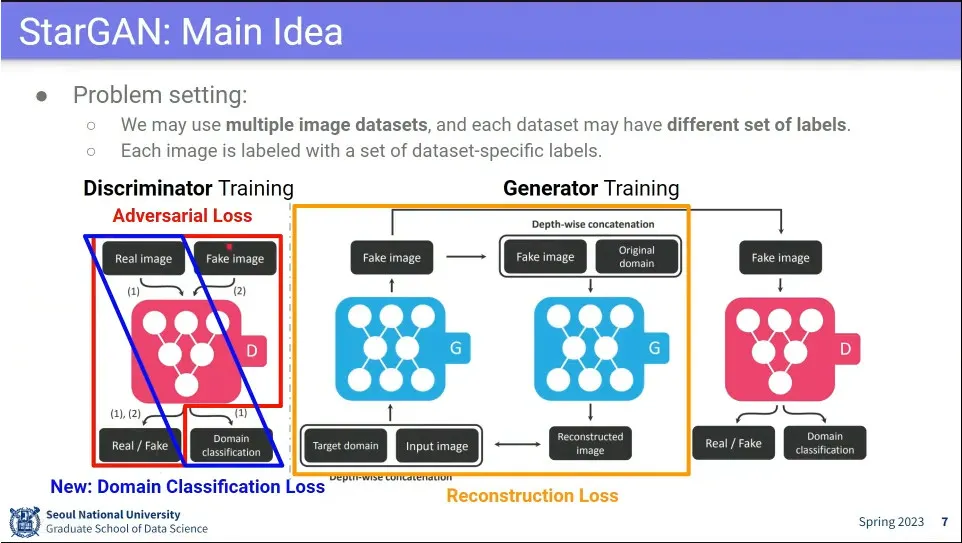
Adversarial Loss와 Reconstruction Loss는 CycleGAN과 유사한데, 진짜 이미지가 들어왔을때 domain도 분류해주는 loss가 추가됨

•
Adversarial Loss, Reconstruction Loss는 CycleGAN과 같음.
•
추가로 진짜 이미지일 때는 domain class를 맞추는 loss가 추가되고, 가짜 이미지일 때는 가짜 이미지라는 것을 맞춰야 함.
◦
이미지가 제대로 나왔는지만 보는 것에 class까지 맞추도록 함.
•
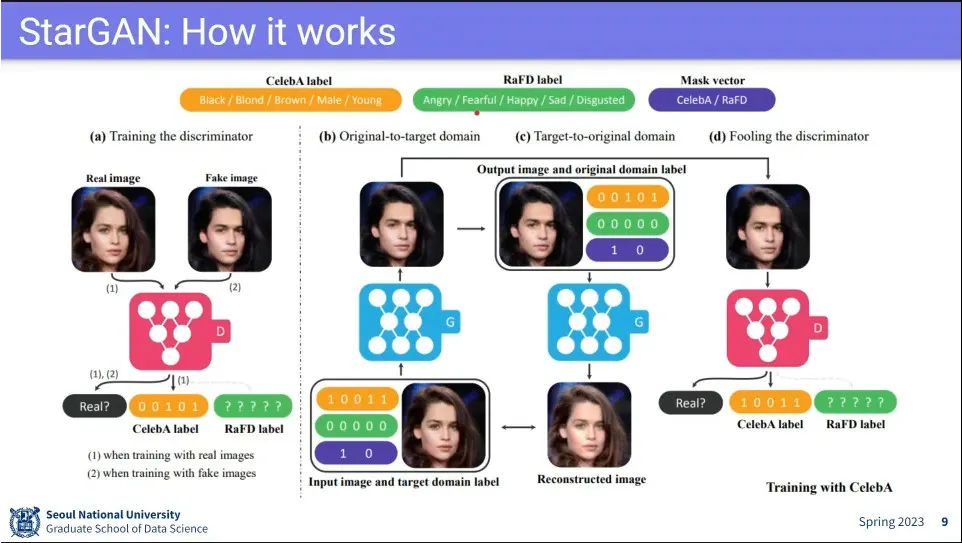
Dataset에 따라 설정하는 속성이 다름. 다만 다른 데이터셋이라도 속성의 길이는 동일하게 맞춤.
◦
Mask vector에서 어떤 데이터셋을 사용하는지를 지정해 줌.
•
그 외는 CycleGAN과 비슷하게 동작함. Generator가 style 변환 했다가 원복. 그리고 Discriminator가 가짜인지 진짜인지 맞추게 함.
•
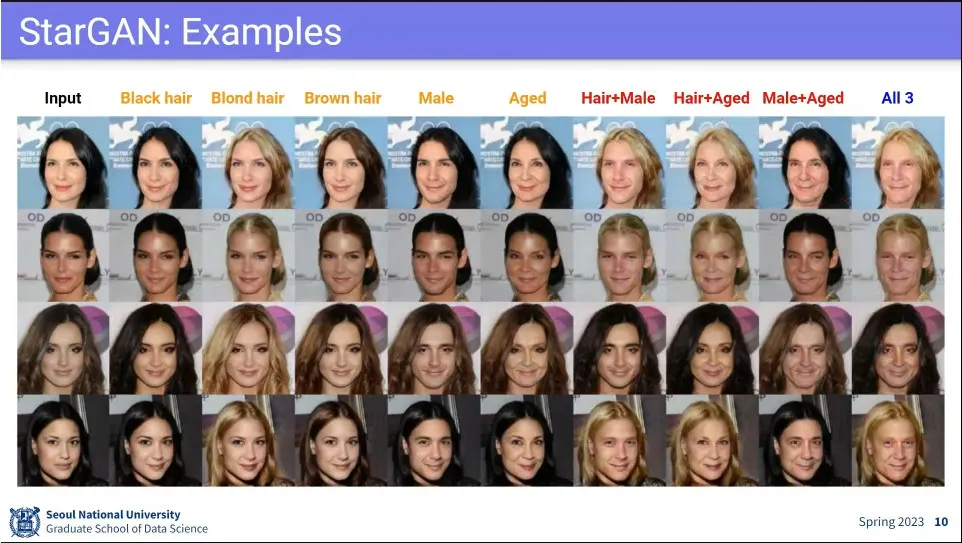
사례

•
GAN은 해석 가능성이 없음. black box
•
GAN의 결과에 대해 control 가능하게 하는게 목표
◦
포즈를 지정한다거나, 헤어 스타일을 지정한다거나 등
•
Discriminator는 그대로 쓰고 Generator만 바꿈.
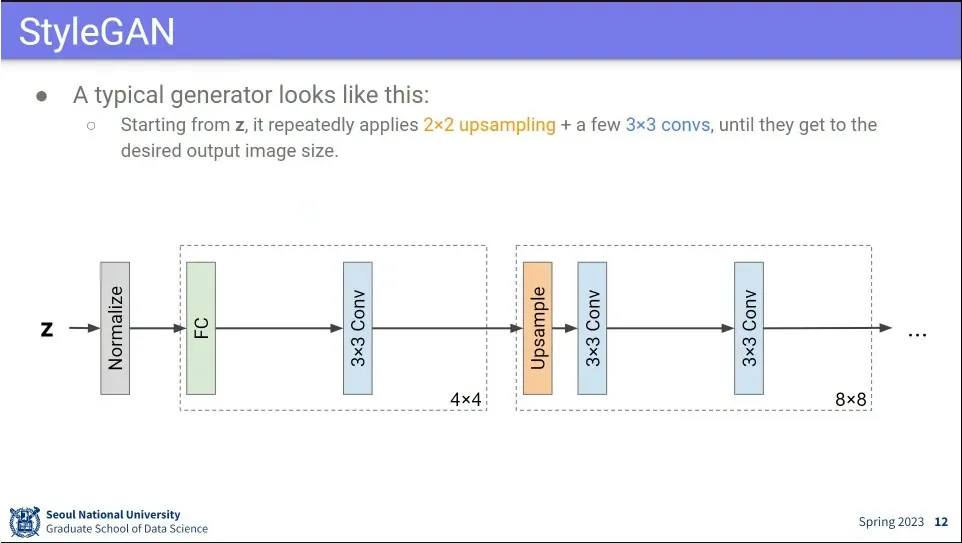
•
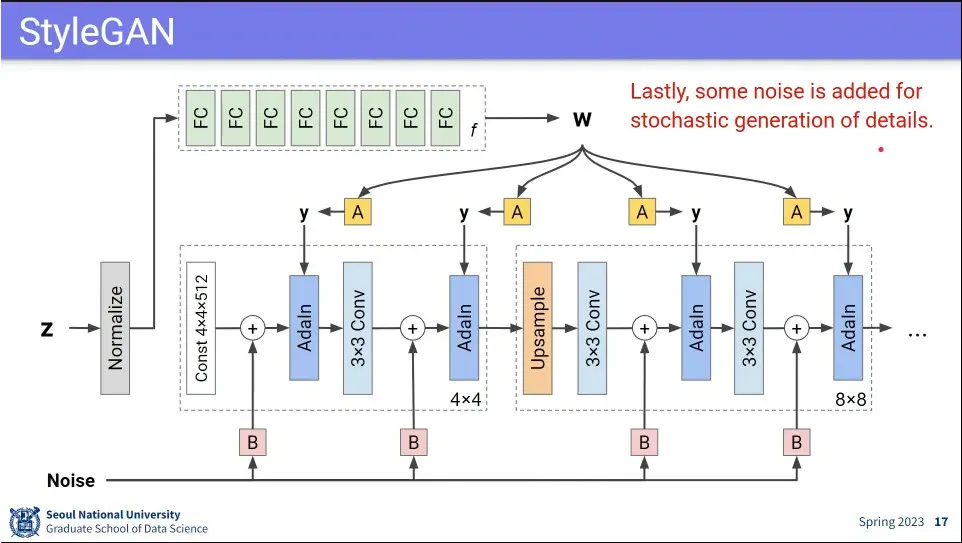
generator는 대체로 위와 같이 생김.
◦
z 값에 대해 normalize 한 후에 fully-connected, conv를 거쳐서 upsample해서 사이즈를 키워나감.
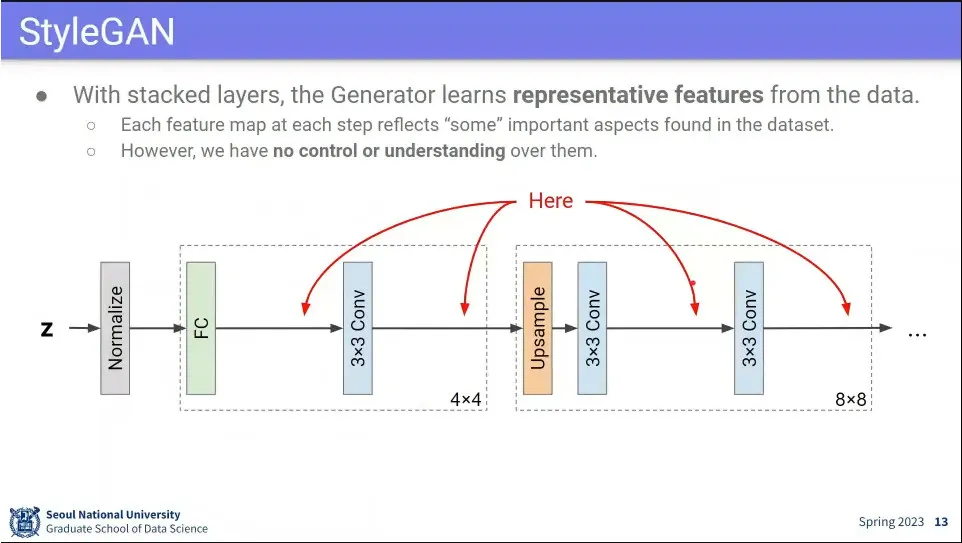
•
z 값을 처음 설정한 이후에는 control이 안되기 때문에 중간에 어떤 설정을 할 수 있게 하는게 아이디어.
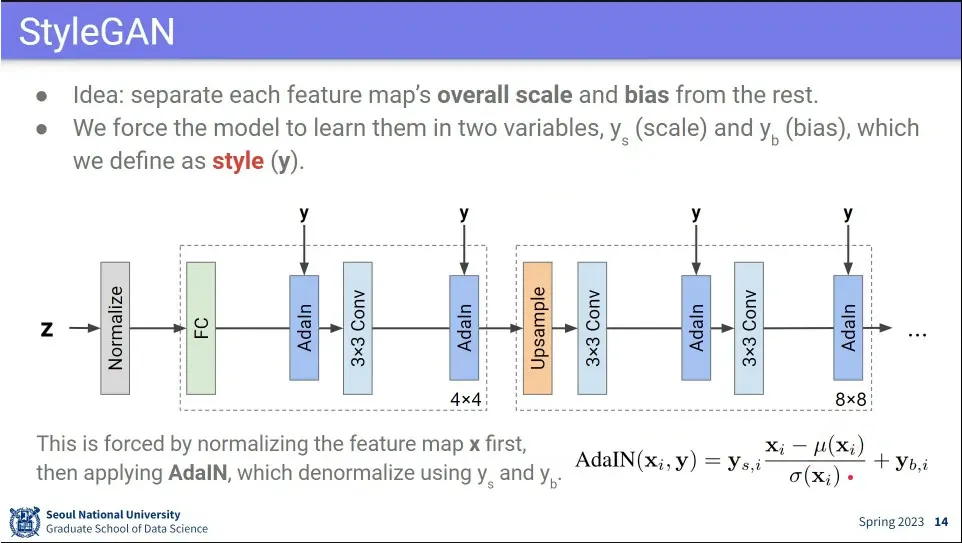
•
style을 주입하기 위해 각 단계 사이에 AdlN이라는 것을 넣어 줌.
◦
AdalN은 입력에 대해 normalize(평균을 빼고 분산을 나눔) 한 후에 원하는 scale과 bias을 추가해 줌.
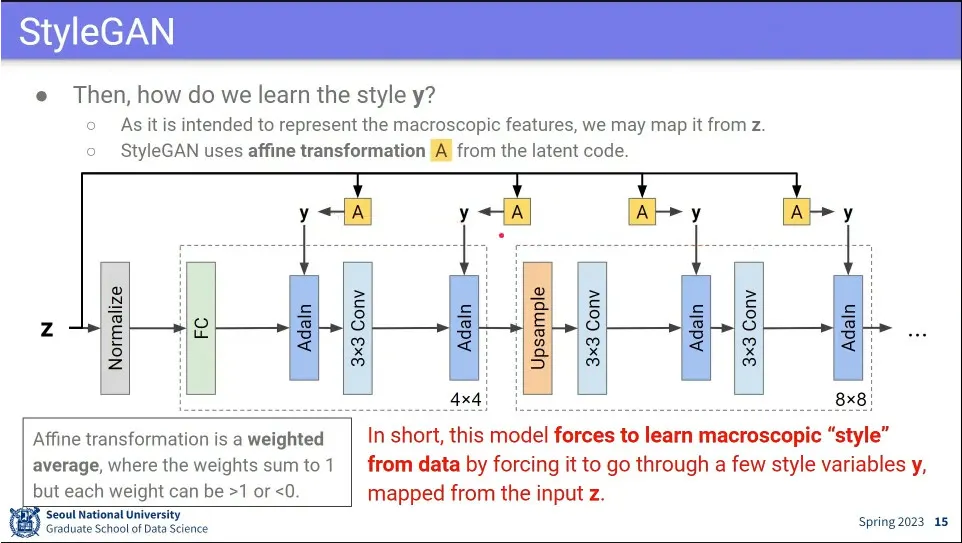
•
y를 학습 가능하게 하기 위해 affine transformation을 사용 함.
◦
y가 학습 가능하지 않으면 그냥 하이퍼 파라미터가 됨. 사람이 그걸 정해줄 수는 없으니 데이터로부터 배울 수 있게 해줘야 함.
•
2개의 벡터가 있다고 할 때
◦
Linear Combination은 그냥 선형 결합 → 공간 상의 모든 점을 표현할 수 있음
◦
Affine Combination은 결합 할 때 weight의 합이 1이어야 한다는 조건 → 두 벡터를 지나는 직선 위에 존재하게 됨.
◦
Convex Combination은 Affine Combination에 대해 weight가 모두 0이상 이어야 한다는 조건 → 두 벡터 사이에 존재하게 됨
•
Adalh에 넣는 style y에 z를 Affine Transformation한 값을 사용 함.
◦
최종적으로 style y를 z가 통제하도록 함.
•
z는 결국 데이터로부터 배우는 값인데, 데이터로부터 특성을 분리하는게 쉽지 않음.
◦
예컨대 데이터에 머리가 긴 남자가 많지 않기 때문에, 마치 머리 길이가 성별을 결정하는 요인으로 학습해 버릴 수 있음.
•
disentangle을 위해 z를 그대로 사용하지 않고, fully-connected를 통과 시켜서 —8개 사용함— w를 만들고 그 w로 style을 통제하게 함.
•
그렇게 함으로써 z가 이미지를 만들지 않고, 초기에 상수를 줘서 만들고, w로 스타일을 제어하게 함.
•
마지막으로 noise를 중간에 추가해서 매번 같은 이미지가 나오지 않게 함.

•
현실에서 수집한 데이터 (a) 자체가 불균일하기 때문에 그걸 그냥 학습 하면 (b) 실제 데이터를 제대로 반영하지 못함.
◦
그래서 fully-connected를 쭉 쌓아서, w를 만들어내면 (c) 처럼 데이터를 제대로 반영할 수 있게 됨.

•
사례. 어느 단계에서 style을 적용하느냐에 따라 style이 바뀌는 정도가 달라짐.
◦
앞단에서 바꾸면 전체적으로 style이 달라지는 반면, 뒷단에서 바꾸면 조금만 바뀜.

•
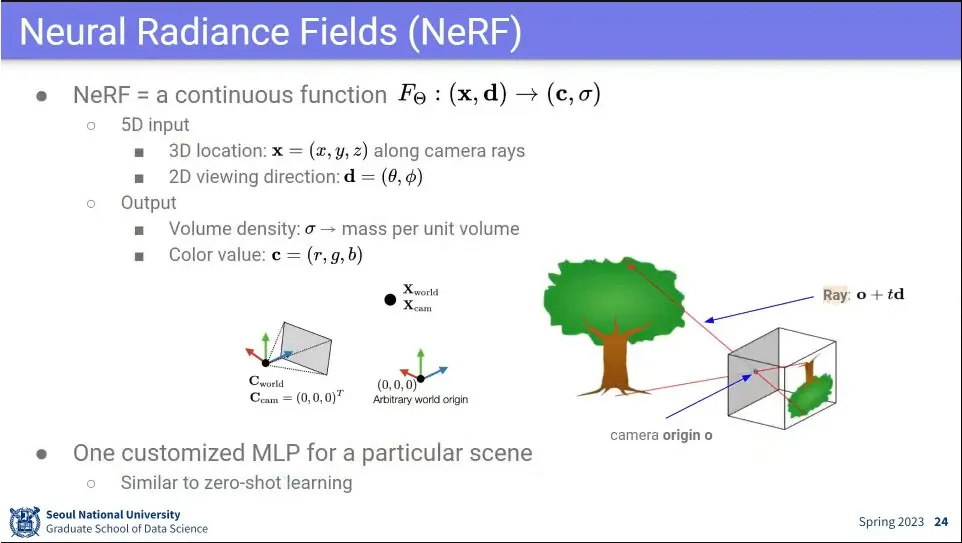
NeRF는 3D를 만드는 모델
◦
같은 씬은 여러 곳에서 본 이미지가 들어오는데, 그걸 이용해서 3D를 만들어 냄.
◦
시간 정보와 공간 정보를 분리 시켜서 같은 시간에 여러 방향에서 본 이미지를 만들어 줌.

•
3D를 voxel로 표현할 수 있음. (x, y, z)에 color가 추가 됨.
◦
이러면 데이터가 너무 많음.
◦
MRI 같은 것에서는 사용 함.
•
컴퓨터 animation에서는 빠른 처리가 중요해서 모든 점을 표현하지 않고 triangle로 표현 함.
•
또는 level set으로 등고선 형태로 표현할 수도 있음.

•
NeRF는 voxel 값을 예측하는 모델.
◦
3차원 공간에서 여러 방향에서 이미지를 찍고, 그걸 모아서 MLP 돌려 주는게 NeRF
◦
이미지와 어느 방향에서 찍은 것인지도 같이 input으로 넣어 줌.
•
NeRF는 x, d를 input으로 받음
◦
x는 값
◦
d는 값
•
그렇게 받아서 output은 color 와 volume density 값을 출력 함
◦
는 물체가 있는지 빈공간인지를 나타 냄.
•
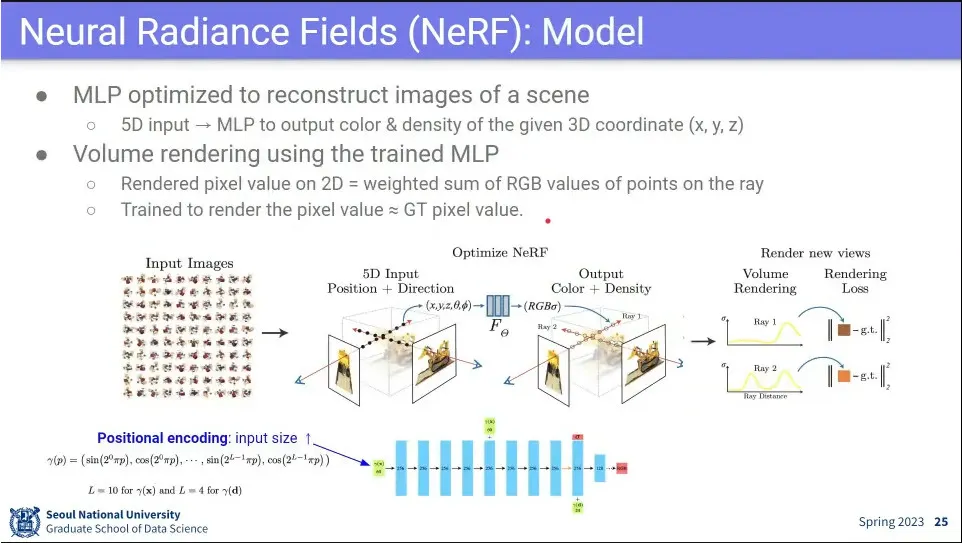
여러 장의 이미지로부터 3d를 reconstruct 함.
•
각 카메라에서 ray를 쏘고, 그 방향으로 적분하는데, 순서대로 적분하고, 불투명한 것이 나오면 그 색을 사용 함.

•
카메라 좌표 에서 방향으로 ray를 쏨. 는 벡터를 만들기 위한 상수
◦
부터 까지 모든 에 대해 물체가 존재하는 영역에 대해 위 수식대로 적분함.
◦
카메라 앞에 있는 것을 써야하기 때문에 앞에 있는 점에 대해 더 가중을 두는 방식으로 함. 그걸 위해 weight 2를 사용.
•
그렇게 최종적으로 구해진 값을 실제 값과 비교해서 loss를 줌.

•
사례. 실제 잘 되더라
•
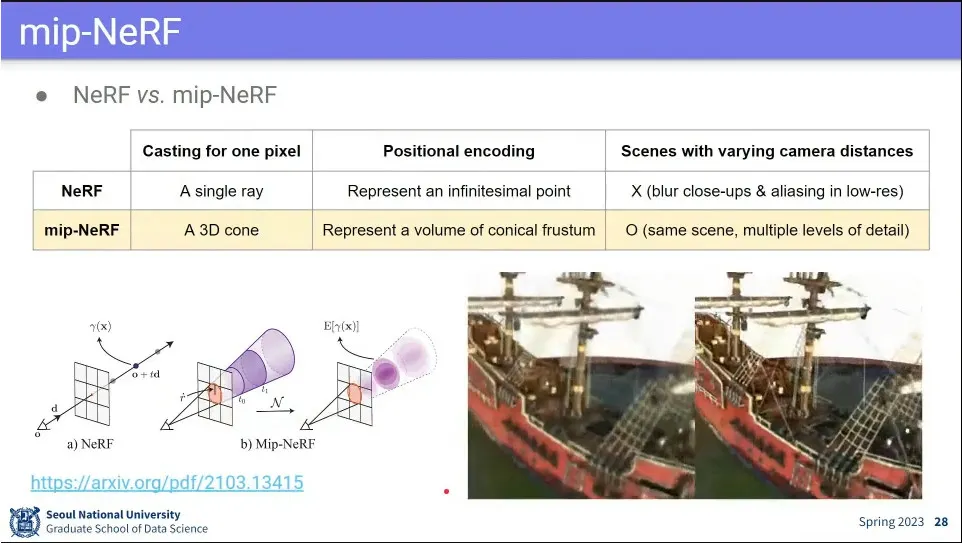
3D인데다 연산도 비싸기 때문에 너무 느림. 그걸 개선한 모델이 mip-NeRF
•
NeRF와 달리 3D Cone을 쏴서 학습 함

•
제대로 된 3D를 구성하려면 이미지가 많이 필요함. 사진이 적으면 가려지는 부분이 많음.
•
3장 가지고 돌렸더니 다 깨지더라.
•
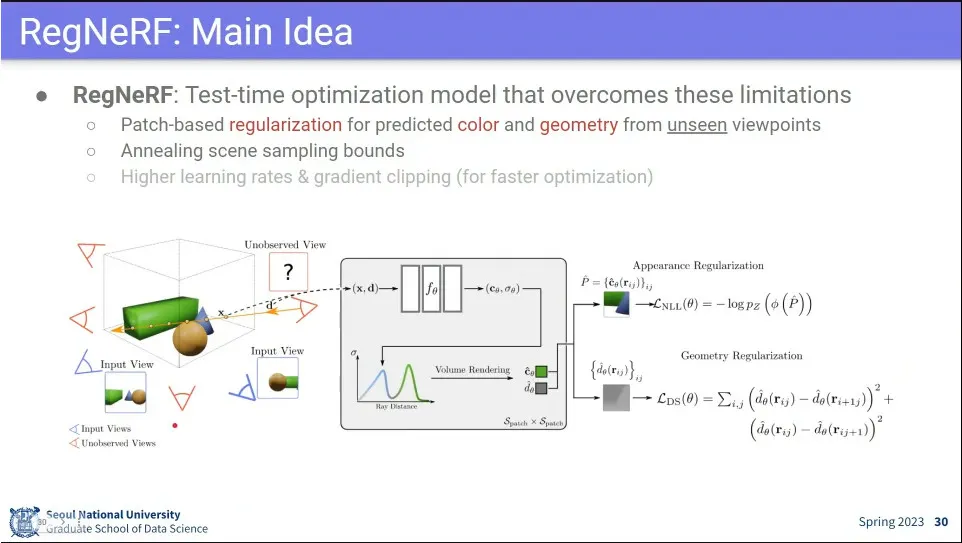
이미지가 몇 장 없을 때도 쓸 수 있게 한게 RegNeRF
•
color와 geometry가 인접한 것들은 같은 물체라는 가정으로 함.

•
이미지가 몇 장 없을 때 geometry를 regularization 하자는 아이디어

•
표면이 flat 하다는 가정으로 patch 기준으로 잘라서 regularization을 수행함.
•
color도 비슷하다는 가정으로 loss 줌.

•
기존의 Reconstruction loss에 Geometry와 color loss를 추가함.

•
NeRF에서 빈 공간에 대해 적분하면 학습이 잘 안되서 문제가 됨.
•
사람들이 사진 찍을 때는 보통 물체를 중심에 두고 찍는다는 가정으로 중심을 주로 sampling 함.

•
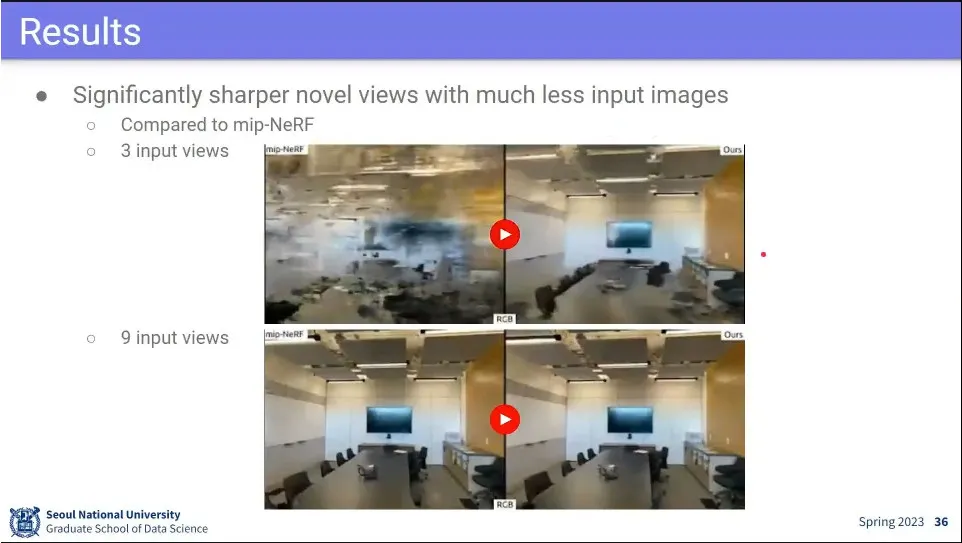
사례
◦
이미지가 적더라도 기존 것들보다 잘 된다.

•
기존 모델들보다 정량적인 성능도 좋았다.

•
표면이 flat 하지 않은 것들은 한계가 있음.
