
Abstract
대부분의 딥러닝 응용 프로그램을 구동하는 Foundation 모델은 거의 전적으로 Transformer 아키텍처와 그 핵심인 어텐션 모듈을 기반으로 한다. 긴 시퀀스에서 Transformer의 계산 비효율성을 해결하기 위해 linear attention, gated convolution, recurrent models 및 structured state space models(SSM) 등 여러 subquadratic 시간 아키텍처가 개발되었지만, 언어와 같은 중요한 모달리티에서는 attention 만큼 성능이 좋지 않았다. 우리는 이러한 모델의 주요 약점은 컨텐츠 기반 추론 능력 부족이라고 판단하고 몇 가지 개선 사항을 도입했다. 첫째, 이산 모달리티에 대한 약점을 해결하기 위해 SSM 매개변수를 입력의 함수로 만들어 모델이 현재 토큰에 따라 시퀀스 길이 차원을 따라 정보를 선택적으로 전파하거나 망각할 수 있게 했다. 둘째, 이런 변화로 인해 효율적인 컨볼루션을 사용할 수 없게 되었음에도 recurrent 모드에서 하드웨어 인식 병렬 알고리즘을 설계했다. 우리는 이러한 selective SSM을 attention이나 MLP 블록 없이 단순화된 end-to-end 신경망 아키텍처(Mamba)에 통합했다. Mamba는 빠른 추론(Transformer보다 5배 높은 처리량)과 시퀀스 길이에 대한 선형 확장성을 제공하며, 실제 데이터에서 최대 100만 길이의 시퀀스에 대해 성능이 향상된다. 일반 시퀀스 모델 backbone으로서 Mamba는 언어, 오디오, 유전체학 등 몇 가지 모달리티에서 최고 수준의 성능을 달성한다. 언어 모델링에서 Mamba-3B 모델은 사전 학습과 다운스트림 평가 모두에서 동일한 크기의 Transformer를 능가하고, 두 배 큰 Transformer와 동등한 성능을 보인다.
1 Introduction
Foundation Models(FMs), 즉 대규모 데이터로 사전 학습된 후 다운스트림 task에 적용되는 대형 모델은 현대 기계 학습에서 효과적인 패러다임으로 부상했다. 이러한 FMs의 backbone은 종종 시퀀스 모델링이며, 언어, 이미지, 음성, 오디오, 시계열, 유전체학 등 넓고 다양한 도메인에서 임의의 입력 시퀀스를 처리한다. 이러한 개념 자체는 특정 모델 아키텍처에 구애받지 않지만, 현대 FMs는 주로 한 가지 유형의 순차 모델, 즉 Transformer(Vaswani et al. 2017)와 그 핵심인 어텐션 레이어(Bahdanau, Cho, and Bengio 2015)를 기반으로 한다. self-attention의 효율성은 컨텍스트 윈도우 내에서 정보를 밀집되게 라우팅할 수 있는 능력 때문인데, 이것은 복잡한 데이터를 모델링할 수 있게 한다. 하지만 이러한 속성은 근본적인 단점이 있다. 유한한 윈도우 밖의 것은 모델링할 수 없고, 윈도우 길이에 대해 이차적인 확장성을 갖는다. 이러한 단점을 극복하기 위해 더 효율적인 어텐션 변종에 대한 엄청난 양의 연구가 있었지만(Tay, Dehghani, Bahri, et al. 2022), 종종 어텐션을 효과적으로 만드는 바로 그 속성을 희생해야 했다. 아직까지 이런 변종 중 어느 것도 다양한 도메인에 걸쳐 규모에 따라 경험적으로 효과 있음이 입증되지 않았다.
최근 structured state space models(SSMs) (Gu, Goel, and Ré 2022; Gu, Johnson, Goel, et al. 2021)이 시퀀스 모델링에 대한 유망한 아키텍처의 클래스로 등장했다. 이 모델은 classical state space models(Kalman 1960)에서 영감을 얻은 순환 신경망(RNNs)과 컨볼루션 신경망(CNNs)의 결합으로 해석될 수 있다. 이 모델의 클래스는 recurrence 또는 convolution으로 매우 효율적으로 계산할 수 있으며, 시퀀스 길이에 대해 linear 또는 near-linear 확장성을 가진다. 게다가 특정 데이터 모달리티에서 long-range 의존성을 모델링하기 위한 principled 메커니즘(Gu, Dao, et al. 2020)을 가지며, Long Range Arena 같은 벤치마크에서 우수한 성능을 보였다(Tay, Dehghani, Abnar, et al. 2021). SSM의 다양한 변종이 오디오 및 비전 같은 연속 신호 데이터를 포함하는 도메인에서 성공을 거두었다. 하지만 텍스트와 같은 이산적이고 정보 밀집적인 데이터를 모델링하는 데는 덜 효과적이었다.
우리는 selective state space models의 새로운 유형을 제안한다. 이것은 시퀀스 길이에서 선형적으로 확장되면서 Transformer의 모델링 능력을 달성하기 위해 몇 가지 축에 대한 이전 작업을 개선한다.
Selection Mechanism.
우선 우리는 기존 모델의 주요 한계점을 식별한다: 입력에 따라 효율적으로 데이터를 선택할 수 있는 능력(즉, 특정 입력에 집중하거나 무시). selective copy 및 induction heads와 같은 중요한 합성 태스크에 근거한 직관을 바탕으로, 입력에 기반하여 SSM 파라미터를 파라미터화함으로써 간단한 selection 메커니즘을 설계했다. 이를 통해 모델이 무관한 정보를 필터링하고 관련 정보를 무기한 기억할 수 있다.
Hardware-aware 알고리즘.
이 간단한 변화는 모델의 계산에 대한 기술적 도전을 제기한다. 사실 이전의 모든 SSM 모델은 계산 효율성을 위해 시간과 입력에 불변이어야 한다. 우리는 이것을 hardware-aware 알고리즘으로 극복했다. 이것은 convolution 대신 scan을 사용하여 모델을 recurrently 계산하지만, GPU 메모리 계층 구조의 서로 다른 레벨 간 IO 접근을 피하기 위해 확장된 상태를 구현하지 않는다. 구현 결과는 이전 방식보다 이론(모든 컨볼루션 기반 SSM에 대한 pseudo-linear와 비교하여 시퀀스 길이에 대해 선형 확장)과 최신 하드웨어(A100 GPU에서 최대 3배 빠름) 모두에서 빠르다.
아키텍처.
우리는 이전 SSM 아키텍처(Dao, Fu, Saab, et al. 2023)의 설계와 Transformer의 MLP 블록을 단일 블록으로 결합하여 이전 deep 시퀀스 모델 아키텍쳐를 단순화한다. 이것은 selective state spaces을 통합한 간단하고 homogenous인 아키텍처 설계(Mamba)로 이어진다.
selective SSM과 확장된 Mamba 아키텍처는 시퀀스를 처리하는 일반적인 foundation 모델의 백본으로 적합하게 하는 주요 특성을 가진 fully recurrent 모델이다. (i) 높은 품질: selectivity는 언어, 유전체학과 같은 밀집 모달리티에서 강력한 성능을 제공한다. (ii) 빠른 학습 및 추론: 학습 시 계산 및 메모리가 시퀀스 길이에 선형적으로 확장하며, 이전 항목의 캐시가 필요하지 않으므로 추론 시 모델을 autoregressively unrolling 하는 데 step별로 상수 시간만 필요하다. (iii) 긴 문맥: 품질과 효율성이 어우러져 실제 데이터에서 시퀀스 길이 100만까지 성능 향상을 가져온다.
우리는 몇 가지 유형의 모달리티와 설정에서 pre-training 품질과 도메인별 task 성능 모두에서 일반적인 시퀀스 FM 백본으로서의 Mamba의 잠재력을 경험적으로 검증했다.
•
합성. 대규모 언어 모델에 대해 핵심으로 제안된 copying와 induction head와 같은 중요한 합성 태스크에 대해 Mamba는 그것을 쉽게 해결할 뿐만 아니라 무한히 긴 해(>100만 토큰)를 extrapolate 할 수 있다.
•
오디오 및 유전체학. Mamba는 오디오 waveforms과 DNA 시퀀스를 모델링하는데 SaShiMi, Hyena, Transformer와 같은 이전 최고 성능 모델을 pre-trained 품질과 downstream metric(예: 음성 생성 데이터셋 도전에서 FID를 절반 이상 감소) 모두에서 능가한다. 두 설정 모두에서 100만 길이의 시퀀스까지 더 긴 컨텍스트로 성능이 향상된다.
•
언어 모델링. Mamba는 사전 학습 perpelexity와 다운스트림 평가 모두에서 진정으로 Transformer 수준의 성능을 달성한 최초의 선형 시간 시퀀스 모델이다. 10억 개 파라미터까지 확장 법칙을 사용하여, Mamba가 LLaMa(Touvron et al. 2023) 기반의 매우 강력한 최신 Transformer 학습 레시피를 포함하여 다양한 baseline의 성능을 능가한다는 것을 보였다. 우리의 Mamba 언어 모델은 유사한 크기의 Transformer에 비해 5배 높은 생성 처리량을 가지며, Mamba-3B의 품질은 두 배 큰 Transformer(예: 상식 추론에서 Pythia-3B에 비해 4점 높은 평균 점수, Pythia-7B를 능가)와 맞먹는다.
2 State Space Models
Structured State Space Sequence(S4) Models는 RNN과 CNN과 classical state space model과 광범위하게 연관된 딥러닝에 대한 최신 시퀀스 모델 클래스이다. 이것은 암시적 latent 상태 를 통해 1차원 함수 또는 시퀀스 를 매핑하는 특정 연속 시스템(1)에서 영감을 받았다.
구체적으로 S4 모델은 2 단계의 seq-to-seq 변환을 정의하는 4개 파라미터로 정의된다.
Discretization.
첫 스테이지에서 고정된 공식 와 를 사용하여 ‘연속 파라미터’ 를 ‘이산 파라미터’ 로 변환한다. 여기서 쌍은 이산화 규칙이라고 부른다. 방정식 4에서 정의된 zero-order hold(ZOH) 같은 다양한 규칙을 사용할 수 있다.
이산화는 resolution invariance(Nguyen, Goel, et al. 2022)와 모델이 적절히 normalized 되는 automatically ensuring(Gu, Johnson, Timalsina, et al. 2023; Orvieto et al. 2023) 같은 추가적인 속성을 부여할 수 있는 연속-시간 시스템과 깊게 연결되어 있다. 또한 섹션 3.5에서 다시 살펴볼 RNN의 gating 메커니즘(Gu, Gulcehre, et al. 2020; Tallec and Ollivier 2018)과도 연결되어 있다.
그러나 기계적 관점에서 이산화는 간단히 SSM의 forward pass에서 계산 그래프의 첫 번째 단계로 볼 수 있다. SSMs의 대체 버전은 이산화 단계를 우회하고 를 직접 파라미터화한다(Zhang et al. 2023). 이는 추론하기 더 쉬울 수 있다.
Computation.
파라미터가 로 변환된 후에, 모델은 linear recurrence(2) 또는 global convolution(3) 2가지 방법으로 계산된다. 일반적으로 모델은 효율적인 병렬화가능 학습(전체 입력 시퀀스가 사전에 보임)을 위해 컨볼루셔널 모드(3)을 사용하고, 효율적인 autoregressive 추론(입력이 한 번에 한 단계씩 보임)을 위해 recurrent 모드로 전환된다.
Linear Time Invariance (LTI).
방정식 (1) ~ (3)의 중요한 특성은 모델의 동역학이 시간에 따라 일정하다는 것이다. 다시 말해서 , 그리고 결과적으로 도 모든 시간 단계에서 고정되어 있다. 이 속성을 Linear Time Invariance(LTI)이라고 하며, 이것은 recurrence과 컨볼루션과 깊이 연관되어 있다. 비공식적으로 LTI SSM을 임의의 선형 recurrence(2a) 또는 컨볼루션(3b)과 동등한 것으로 간주하며, LTI를 이러한 모델 클래스를 포괄하는 용어로 사용한다.
지금까지 모든 structured SSM은 섹션 3.3에서 논의한 근본적인 효율성 제약 때문에 LTI (예: 컨볼루션으로 계산됨)였다. 그러나 이 작업의 핵심 통찰은 LTI 모델이 특정 유형의 데이터를 모델링하는데 근본적인 한계가 있고, 우리의 기술적 공헌은 LTI 제약을 제거하면서 효율성 병목을 극복하는 것을 포함한다.
구조 및 차원.
마지막으로, structured SSM이 그렇게 명명된 이유는 이를 효율적으로 계산하려면 행렬 에 구조를 부여해야 하기 때문이다. 가장 인기 있는 구조 형태는 대각 행렬로, 우리도 이를 사용한다.
이 경우 행렬은 모두 개의 숫자로 표현될 수 있다. 배치 크기 , 길이 , 채널의 입력 시퀀스 에 대한 연산을 위해 SSM은 각 채널에 독립적으로 적용된다. 이 경우 총 은닉 상태의 차원은 입력당 이며, 시퀀스 길이에 대해 이를 계산하는 데는 시간과 메모리가 필요하다. 이것은 3.3절에서 다루는 근본적인 효율성 병목 현상의 근원이다.
General State Space Models.
state space model라는 용어는 단순히 잠재 상태를 가진 임의의 recurrent 프로세스의 개념을 나타내며 매우 광범위한 의미를 가진다. 이것은 Markov Decision Processes(MDP), Dynamic Causal Modeling(DCM), Kalman Filter, Hidden Markov Models(HMMs), Linear Dynamical System(LDS), 대규모에서 recurrent (때로는 convolution) 모델을 포함하여 다양한 분야에서 다른 개념을 의미하는데 사용되었다.
이 전체 논문에서 우리는 ‘SSM’이라는 용어를 structured SSM 또는 S4 클래스의 model을 지칭하는데만 사용하고, 이 용어는 바꿔서 사용될 수 있다. 편의상 linear-recurrent 또는 global-convolution 관점에 초점을 맞춘 모델과 같은 모델의 도함수를 포함하고 필요한 경우 늬앙스를 명확히한다.
SSM 아키텍처.
SSM은 end-to-end 신경망 아키텍처에 통합될 수 있는 standalone 시퀀스 변환이다. (때때로 SSM 아키텍처를 SSNN이라고 부르는데, 이는 CNN이 선형 컨볼루션 레이어에 대한 것과 마찬가지로 SSM 레이어에 대한 것이다.) 우리는 가장 잘 알려진 SSM 아키텍처 중 일부를 논의하며 그중 다수는 primary baseline으로도 사용된다.
•
Linear attention(Katharopoulos et al. 2020)은 degenerate linear SSM으로 볼 수 있는 recurrence을 포함하는 셀프 어텐션의 근사이다.
•
H3(Dao, Fu, Saab, et al. 2023)는 S4를 사용하기 위해 이 recurrence을 일반화했다. 이것은 two gated connection(그림 3)에 의해 샌드위치된 SSM을 갖는 아키텍쳐로 볼 수 있다. H3는 또한 주요 SSM 레이어 앞에 Shift-SSM으로 구성되는 표준 local convolution을 삽입한다.
•
Hyena(Poli et al. 2023)는 H3와 동일한 아키텍처를 사용하지만, S4 레이어를 MLP로 파라미터화된 global convolution(Romero et al. 2021)으로 대체한다.
•
RetNet(Y. Sun et al. 2023)은 추가적인 게이트를 아키텍처에 추가하고 더 간단한 SSM을 사용한다. 이것은 convolution 대신 multi-head attention(MHA)의 변종을 사용하여 병렬화 가능한 계산 경로의 대안을 허용한다.
•
RWKV (B. Peng et al. 2023)는 또 다른 linear attention 근사(attention-free Transformer(S. Zhai et al. 2021))에 기반하여 언어 모델링을 위해 설계된 최신 RNN이다. 주요 ‘WKV’ 메커니즘은 LTI recurrences를 포함하고 두 SSM의 비율로 볼 수 있다.
기타 밀접하게 관련된 SSM 및 아키텍쳐는 확장된 관련 작업(부록 B)에서 자세히 논의한다. 우리는 특히 S5(Smith, Warrington, and Linderman 2023), QRNN (Bradbury et al. 2016), and SRU (Lei et al. 2017)를 강조한다. 이것들은 우리의 핵심 selective SSM과 가장 밀접하게 관련된 방법으로 볼 수 있다.
3 Selective State Space Models
synthetic task(섹션 3.1)의 직관을 사용하여 selection 메커니즘에 동기를 부여한 다음 이 메커니즘을 state space model(섹션 3.2)에 통합하는 방법을 설명한다. 결과 time-varying SSMs은 컨볼루션을 사용할 수 없으므로 이를 효율적으로 계산하는 방법에 대한 기술적인 문제가 발생한다. 이를 최신 하드웨어 메모리 계층 구조를 활용하는 hardware-aware 알고리즘으로 이 문제를 극복했다(섹션 3.3). 그 다음 attention이나 MLP 블록 없는 간단한 SSM 아키텍쳐를 설명한다(섹션 3.4). 마지막으로 selection 메커니즘의 몇 가지 추가 속성에 대해 논의한다(섹션 3.5).
3.1 Motivation: Selection as a Means of Compression
시퀀스 모델링의 근본적인 문제점은 컨텍스트를 더 작은 상태로 압축하는 것에 있다고 주장한다. 사실 인기 있는 시퀀스 모델의 tradeoff를 이 관점에서 볼 수 있다. 예컨대 attention은 컨텍스트를 전혀 압축하지 않기 때문에 효율적이면서 비효율적이다. 이것은 autoregressive 추론이 전체 컨텍스트를 명시적으로 저장(예: KV 캐시)해야 한다는 사실에서 알 수 있다. 이것은 Transformer에서 느린 선형 시간 추론과 2차적 시간 학습의 직접적 원인이다. 반면에 recurrent 모델은 상수-시간 추론과 선형시간 학습을 암시하는 유한 상태를 갖기 때문에 효율적이다. 그러나 이것의 효과는 상태가 컨텍스트를 압축하는 방법에 의해 제한된다.
이 원리를 이해하기 위해 synthetic task의 2가지 실행 예에 초점을 맞춘다. (그림 2)
•
Selective Copying task는 기억해야 할 토큰의 위치를 변경하는 인기 있는 Copying task(Arjovsky, Shah, and Bengio 2016)를 수정한 것이다. 이것은 관련 있는 토큰(색칠한)을 기억하고 관련 없는 것(흰색)을 filter out 할 수 있도록 content-aware 추론을 요구한다.
•
Induction Heads task는 LLM의 in-context 학습 능력의 대부분을 설명하기 위해 가정된 잘 알려진 메커니즘이다. 이것은 적절한 컨텍스트(검은색) 내에서 올바른 출력을 생성할 시기를 알기 위해 context-aware 추론을 요구한다.
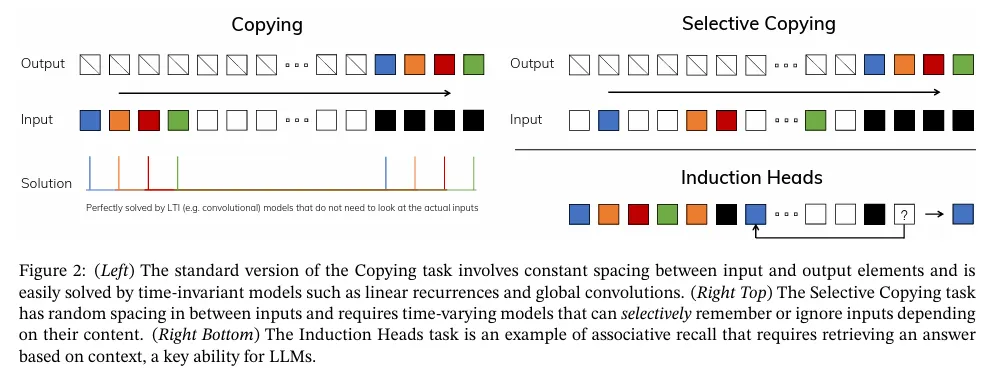
이러한 task는 LTI 모델의 실패 모드를 드러낸다. recurrent 관점에서 보면, constant dynamics(예: 방정식 (2)의 전이)로는 그들의 컨텍스트에서 올바른 정보를 선택하게 하거나 입력 의존적 방법에서 시퀀스를 따라 전달된 hidden state에 영향을 미칠 수 없다. convolution 관점에서 보면 global convolution은 time-awareness만 필요하므로 vanilla Copying task(Romero et al. 2021)를 풀 수 있지만, content-awareness 부족으로 인해 Selective Copying task를 사용하는 것에 어려움을 갖는다. 더 구체적으로 입력에서 출력 사이의 간격이 변화하여 정적 convolution 커널로 모델링될 수 없다.
요약하자면, 시퀀스 모델의 효율성 대 효과성 트레이드오프는 그들이 그들의 상태를 압축하는 방법에 의해 특징 지어진다. 효율적인 모델은 작은 상태를 가져야 하는 반면 효과적인 모델은 컨텍스트에서 필요한 모든 정보를 포함하는 상태를 가져야 한다. 차례로 시퀀스 모델에 대한 근본적 원리로 selectivity 또는 입력을 시퀀셜 상태로 focus on 하거나 filter out 하는 context-aware 능력을 제안한다. 특히 selection 메커니즘은 시퀀스 차원을 따라 정보를 전파하거나 상호작용하는 방법을 제어한다. (자세한 내용은 3.5절 참조).
3.2 Improving SSMs with Selection
selection 메커니즘을 모델에 통합하는 한 가지 방법은 시퀀스를 따라 상호 작용에 영향을 미치는 파라미터(예: RNN의 recurrent dynamics 또는 CNN의 컨볼루션 커널)를 입력에 의존하게 만드는 것이다.
알고리즘 1과 2는 우리가 사용하는 주요 selection 메커니즘을 보여준다. 주요 차이는 단순히 입력의 함수로 파라미터 를 만들고 전체 텐서 shape에 관련된 변경 사항을 적용하는 것이다. 특히 이러한 파라미터가 길이 차원 을 갖는다는 것을 강조한다. 이것은 모델이 time-invariant에서 time-varing으로 바뀌었다는 것을 의미한다. (shape annotation은 섹션 2에 설명되어 있음) 이것은 효율성에 대한 암시를 갖는 convolution (3)에 대한 동등성을 잃는다. 나중에 논의한다.
구체적으로 를 고른다. 여기서 는 차원 에 파라미터화된 projection이다. 와 의 선택은 섹션 3.5에 설명된 RNN gating 메커니즘에 대한 연결 때문이다.
Algorithm 1 SSM (S4)
Input:
Output:
1.
// 구조화된 행렬을 나타냄
2.
3.
4.
5.
6.
// time-invariant: recurrence 또는 convolution
7.
return
Algorithm 2 SSM + Selection (S6)
Input:
Output:
1.
// 구조화된 행렬을 나타냄
2.
3.
4.
5.
6.
// time-varying: recurrence (scan) only
7.
return
3.3 Efficient Implementation of Selective SSMs
컨볼루션(Krizhevsky, Sutskever, and Hinton 2012)과 트랜스포머(Vaswani et al. 2017) 같은 하드웨어 친화적인 아키텍쳐는 광범위하게 적용된다. 여기서 최신 하드웨어(GPU)에서도 selective SSM을 효율적으로 만드는 것을 목표로 한다. selective 메커니즘은 매우 자연스럽고 초기 연구에서는 recurrent SSMs(Gu, Dao, et al. 2020)에서 가 시간에 따라 달라지도록 하는 것과 같이 selection의 특별한 경우를 통합하려고 시도했다. 그러나 이전에 언급했듯이 SSM 사용의 핵심 제한은 계산 효율성이다. 이것이 바로 S4와 모든 파생이 LTI(non-selective) 모델을 사용하는 이유이다. 대부분 일반적으로 global convolution 형태이다.
3.3.1 Motivation of Prior Models
먼저 이러한 동기를 재검토 하고 이전 방법의 한계를 극복하기 위한 접근 방법을 검토한다.
•
high level에서 SSM과 같은 recurrent 모델은 항상 표현성과 속도 사이의 tradeoff를 균형을 유지한다. 섹션 3.1에서 설명한 것처럼 더 큰 은닉 상태 차원을 갖는 모델은 더 효과적이지만 느리다. 따라서 우리는 속도와 메모리 비용을 지불하지 않고 은닉 상태 차원을 최대화하기를 원한다.
•
recurrent 모드는 컨볼루션 모드보다 더 유연하다. 후자(3)가 전자(2)를 확장하여 유도될 수 있기 때문이다(Gu, Goel, and Ré 2022; Gu, Johnson, Goel, et al. 2021). 그러나 이것은 shape의 입력 와 출력 보다 훨씬 더 큰 ( 배, SSM 상태 차원) shape의 latent 상태 를 계산하고 구체화해야 한다. 따라서 상태 계산을 우회하고 의 컨볼루션 커널(3a)만 구체화할 수 있는 보다 효율적인 컨볼루션 모드가 도입되었다.
•
이전 LTI SSMs은 dual recurrent-convolutional 형식을 활용하여 효율성 저하 없이 유효 상태 차원을 전통적인 RNN보다 훨씬 더 크게 (약 10-100배)배 만큼 증가시킨다.
3.3.2 Overview of Selective Scan: Hardware-Aware State Expansion
selection 메커니즘은 LTI 모델의 한계를 극복하도록 설계되었다. 동시에 우리는 SSM의 계산 문제를 재검토할 필요가 있다. 우리는 이를 kernel fusion, parallel scan, recomputation이라는 세 가지 전통적인 기술로 다룬다. 우리는 두 가지 주요 관찰을 한다.
•
naive recurrent 계산은 FLOP를 사용하지만, convolution 계산은 FLOP를 사용하며, 전자의 상수 계수가 더 낮다. 따라서 긴 시퀀스와 너무 크지 않은 상태 차원 에 대해, recurrent 모드가 실제로 더 적은 FLOP를 사용할 수 있다.
•
두 가지 도전은 recurrence의 순차적 특성과 큰 메모리 사용량이다. 후자를 다루기 위해 컨볼루션 모드와 마찬가지로 전체 상태 를 실제로 구체화하지 않으려고 시도할 수 있다.
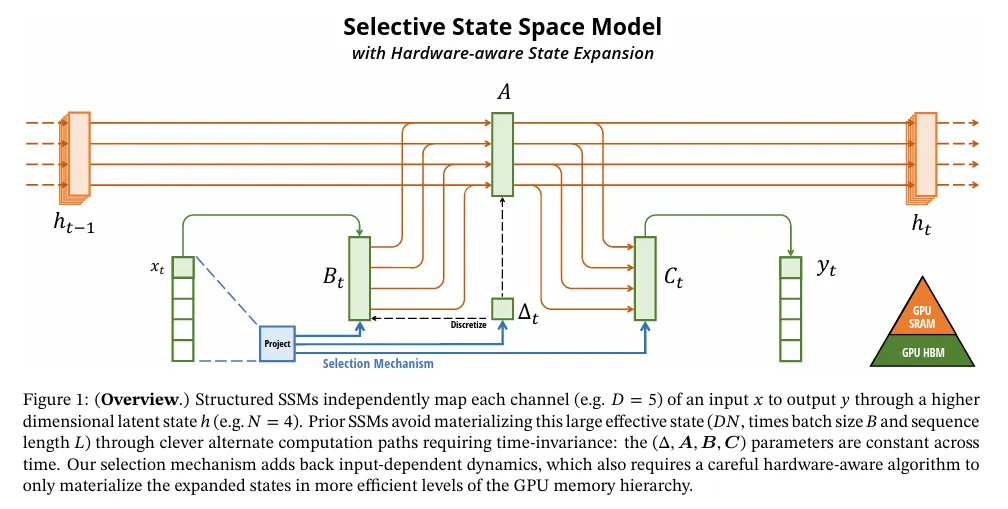
주요 아이디어는 현대 가속기(GPU)의 속성을 활용하여 상태 를 더 효율적인 메모리 계층 구조 level에서만 구체화하는 것이다. 특히 대부분의 연산(행렬 곱 제외)은 메모리 대역폭에 의해 제한된다(Dao, Fu, Ermon, et al. 2022; Ivanov et al. 2021; Williams, Waterman, and Patterson 2009). 이것은 우리의 scan 연산을 포함하고, kernel fusion을 사용하여 메모리 IO 양을 줄여서 표준 구현에 비해 상당한 속도 향상을 얻는다.
구체적으로, GPU HBM(고대역폭 메모리)에 크기의 scan 입력 를 준비하는 대신, SSM 매개변수 를 느린 HBM에서 빠른 SRAM으로 직접 로드하고, SRAM에서 이산화와 recurrence을 수행한 다음, HBM으로 크기의 최종 출력을 다시 쓴다.
순차적 recurrence을 피하기 위해, 비선형이지만 작업 효율적인 parallel scan 알고리즘을 사용하여 여전히 병렬화 할 수 있다는 것을 관찰했다(Blelloch 1990; Martin and Cundy 2018; Smith, Warrington, and Linderman 2023).
마지막으로 역전파에 필요한 중간 상태를 저장하는 것도 피해야 한다. 우리는 메모리 요구사항을 줄이기 위해 전통적인 recomputation 기술을 주의 깊게 적용한다. 중간 상태는 저장되지 않지만, 입력이 HBM에서 SRAM으로 로드될 때 역전파 패스에서 recomputation 된다. 그 결과 fused selective scan layer는 FlashAttention을 사용하는 최적화된 Transformer 구현과 동일한 메모리 요구사항을 갖는다.
fused kernel과 recomputation의 상세 내용은 부록 D 참조. 전체 selective SSM 레이어와 알고리즘은 그림 1 참조.
3.4 A Simplified SSM Architecture
structured SSM을 사용하는 것으로써 selective SSM은 신경망에 유연하게 통합될 수 있는 standalone 시퀀스 변환이다. H3 아키텍처(Section 2)는 가장 잘 알려진 SSM 아키텍처의 기저이며, 일반적으로 MLP block을 사용하여 교차된 linear attention에 의해 영감을 받은 블록의 구성이다. 우리는 이 두 컴포넌트를 하나로 결합하여 이 아키텍쳐를 단순화 한다. 이것은 stacked homogenously이다. (그림 3) 이것은 attention에 대해 유사한 것을 수행하는 gated attention unit(GAU)(Hua et al. 2022)에서 영감을 받았다.
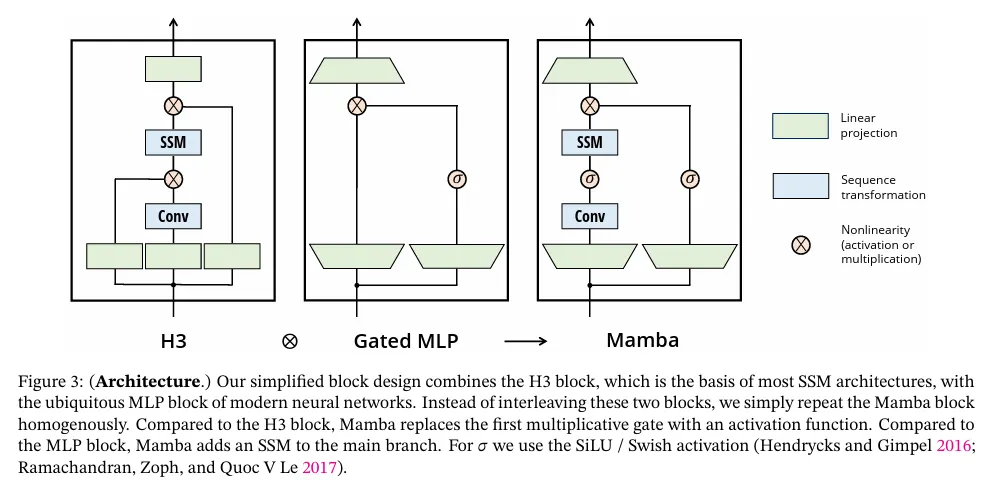
이 아키텍쳐는 제어 가능한 expansion factor 으로 모델 차원 를 expading하는 것을 포함한다. 각 블록에 대해 파라미터의 대부분 ()은 선형 투영(입력 projection에 , 출력 projection에 )에 있으며, SSM 내부의 기여는 적다. SSM 파라미터의 수(에 대한 projection과 행렬)는 이것과 비교하여 훨씬 더 적다. 우리는 표준 normalization과 residual connection을 교차하여 이 블록을 반복하여 Mamba 아키텍쳐를 형성한다. 우리의 실험에서 항상 로 고정하고 Transformer의 교차된 MHA(multi-head attention)와 MLP 블록의 매개변수와 일치하도록 블록의 2개 stack을 사용한다. 우리는 Gated MLP가 인기 있는 ‘SwiGLU’ 변종이 되도록 동기부여된 SiLU/Swish 활성화 함수를 사용한다. 마지막으로 RetNet의 유사한 위치에서 normalization 레이어를 사용한 것에 동기부여 받아 optional normalization 레이어(LayerNorm를 사용함)를 추가로 사용한다.
3.5 Properties of Selection Mechanisms
selection 메커니즘은 더 전통적인 RNNs 또는 CNNs 같은 다양한 방법에서 다양한 파라미터(예: 알고리즘 2의 ) 또는 다양한 변환 을 사용하도록 적용될 수 있는 더 넓은 컨셉이다.
3.5.1 Connection to Gating Mechanisms
가장 중요한 연결을 강조한다. RNN의 classical gating 메커니즘은 SSMs에 대한 우리의 selection 메커니즘의 한 예이다. RNN gating과 연속 시간 시스템의 이산화 사이의 연결이 잘 확립됨에 유의하라(Funahashi and Nakamura 1993; Tallec and Ollivier 2018). 실제로 Theorem 1은 ZOH 이산화와 입력 의존적 gate에 대한 Gu, Johnson, Goel, et al(2021, Lemma 3.1)의 일반화의 개선이다(부록 C에서 증명). 더 넓게 보면 SSM에서 는 RNN gating 메커니즘의 일반화된 역할을 수행하는 것으로 볼 수 있다. 이전 연구와 마찬가지로 우리는 SSM의 이산화가 휴리스틱 gating 메커니즘의 원칙적인 foundation이라는 관점을 채택한다.
Theorem 1.
이면 selective SSM recurrence(알고리즘 2)는 다음 형식을 취한다.
섹션 3.2에서 언급했듯이 의 구체적인 선택은 이와 관련되어 있다. 특히 주어진 입력 이 완전히 무시되어야 하는 경우(합성 작업에서 필요한 경우) 모든 채널은 이를 무시해야 하므로 를 사용하여 repeating/broadcasting 하기 전에 입력을 1차원으로 투영한다.
3.5.2 Interpretation of Selection Mechanisms
우리는 selection의 두 가지 특정 메커니즘 효과에 대해 자세히 설명한다.
Variable Spacing.
selectivity는 관심 있는 입력 사이에서 발생할 수 있는 관련 없는 노이즈 토큰을 필터링 할 수 있다. 이는 selective copying task에서 예시로 나타나지만, 특히 이산 데이터의 경우 일반적인 데이터 모달리티에서 널리 발생한다. 예컨대 ‘um’ 같은 언어 필러의 존재 때문이다. 이 속성은 gated RNN 경우(Theorem 1)에서 일 때와 같이 모델이 특정한 입력 을 기계적으로 필터링 할 수 있기 때문에 발생한다.
Filtering Context.
더 많은 컨텍스트가 엄격하게 더 나은 성능으로 이어져야 한다는 원리에도 불구하고, 많은 시퀀스 모델이 더 긴 컨텍스트에서 성능 향상을 보이지 않는다는 것이 경험적으로 관찰되었다(F. Shi et al. 2023). 한 가지 설명은 많은 시퀀스 모델이 관련 없는 컨텍스트를 효과적으로 무시할 수 없다는 것이다. 직관적인 예는 global convolution(과 일반적인 LTI 모델)이다. 반면에 selective model은 관련 없는 기록을 제거하기 위해 임의의 시간에 그들의 상태를 간단히 reset 할 수 있다. 따라서 원리적으로 그들의 성능은 컨텍스트 길이와 함께 단조적으로 증가한다. (예: 섹션 4.3.2)
Boundary Resetting.
여러 개의 독립적인 시퀀스가 서로 stitched인 설정에서, Transformer는 특정 어텐션 마스크를 인스턴스화하여 시퀀스를 분리할 수 있지만, LTI 모델은 시퀀스 간에 정보를 흘린다. selective SSM도 boundary에서 그들의 상태를 재설정할 수 있다(예: 또는 일 때 Theorem 1). 이러한 설정은 인위적(예: 하드웨어 활용도 개선을 위해 문서를 함께 패킹)이거나 자연스럽게(예: 강화 학습의 에피소드 bondary(Lu et al. 2023)) 발생할 수 있다.
추가적으로 각 selective 파라미터의 효과에 대해 설명한다.
의 해석.
일반적으로 는 현재 입력 에 얼마나 초점을 맞출지 또는 무시할지를 제어한다. 이는 RNN gate(예: Thorem 1의 )를 기계적으로 일반화한다. 큰 는 상태 를 재설정하고 현재 입력 에 초점을 맞추는 반면, 작은 는 상태를 유지하고 현재 입력을 무시한다. SSM (1)-(2)는 시간 간격 에 의해 이산화된 연속 시스템으로 해석될 수 있으며, 이 맥락에서 큰 는 시스템이 현재 입력에 더 오래 초점을 맞추는 것(따라서 그것을 "선택"하고 현재 상태를 잊음)을 나타내고, 작은 은 무시되는 일시적 입력을 나타낸다.
의 해석.
파라미터 역시 selective일 수 있지만, 궁극적으로는 (이산화 (4))를 통해 와의 상호작용을 통해서만 모델에 영향을 미친다는 점을 주목한다. 따라서 의 selectivity는 에서 seelctivity를 보장하는데 충분하고, 이것이 주요 개선이다. 우리는 외에 또는 대신 를 selective로 만드는 것도 유사한 성능을 보일 것이라고 가정하지만, 단순성을 위해 제외했다.
와 의 해석.
섹션 3.1에서 논의한 바와 같이, selectivity의 가장 중요한 속성은 시퀀스 모델의 컨텍스트가 효율적인 상태로 압축될 수 있도록 관련 없는 정보를 필터링 하는 것이다. SSM에서 와 를 selective로 수정하면 입력 를 상태 로 또는 상태를 출력 로 내보낼지 여부를 더 세밀하게 제어할 수 있다. 이는 모델이 컨텐츠(입력)과 컨텍스트(hidden state)에 각각 기반하여 recurrent dynamics를 조절할 수 있도록 하는 것으로 해석될 수 있다.
3.6 Additional Model Details
실수 vs 복소수. 대부분의 이전 SSM은 많은 작업에 대해 강력한 성능을 위해 상태 에 복소수를 사용한다(Gu, Goel, and Ré 2022). 하지만 일부 설정에서 완전히 실수 값의 SSM이 잘 작동하고 더 나은 성능을 보이는 것으로 경험적으로 관찰되었다(Ma et al. 2023). 우리는 기본값으로 실수를 사용하는데, 이것은 우리의 task 중 하나를 제외하고 모두 잘 작동한다. 복소수-실수 tradeoff는 데이터 모달리티의 연속-이산 스펙트럼과 관련이 있을 것이라고 가정한다. 여기서 복소수는 연속 모달리티(예: 오디오, 비디오)에는 도움이 되지만 이산 모달리티(예: 텍스트, DNA)에는 도움이 되지 않는다.
초기화.
대부분의 이전 SSM도 특수한 초기화, 특히 복소수 값 경우에 low-data regimes 같은 몇 가지 설정에 도움이 될 수 있는 특수한 초기화를 제안한다. 복소수 경우에 대한 우리의 기본 초기화는 S4D-Lin이고, 실수 경우에는 HIPPO 이론(Gu, Dao, et al. 2020)에 기반한 S4D-Real(Gu, Gupta, et al. 2022)이다. 이것은 의 번째 요소를 각각 와 로 정의한다. 그러나 우리는 많은 초기화, 특히 대규모 데이터와 실수값 SSM 체제에서 초기화가 잘 작동할 것으로 예상하며, 일부 ablation은 섹션 4.6에서 고려된다.
의 매개변수화.
우리는 에 대한 selective 조정을 로 정의했다. 이것은 의 메커니즘(섹션 3.5)에 의해 동기부여 되었다. 우리는 이것을 1차원에서 더 큰 차원 로 일반화할 수 있음을 관찰한다. 우리는 이것을 의 작은 비율로 설정한다. 이것은 블록에서 main linear projection과 비교하여 무시할 수 있을만한 파라미터 수를 사용한다. 추가로 broadcasting 연산을 과 의 특정한 패턴으로 초기화되는 또 다른 linear projection으로 볼 수 있다. 이 projection이 학습가능하면 이것은 대안 로 이어지며, 이것은 low-rank projection으로 볼 수 있다.
우리 실험에서 파라미터(bias 항으로 볼 수 있음)는 SSM에 대한 이전 작업(Gu, Johnson, Timalsina, et al. 2023)을 따라 로 초기화된다.
Remark 3.1.
실험 결과를 간략화하여, selective SSM을 때때로 S6 모델이라고 약칭한다. 왜냐하면 그것은 selection 메커니즘과 scan을 사용하여 계산된 S4 모델이기 때문이다.
4 Empirical Evaluation
섹션 4.1에서는 섹션 3.1에서 동기 부여된 두 가지 합성 작업을 해결하는 Mamba의 능력을 테스트한다. 그 다음 세 가지 도메인에 대해 평가하고, 각각 autoregressive pre-training과 downstream task에 대해 평가한다.
•
섹션 4.2: 언어 모델 pre-training(scaling 법칙) 및 zero-shot downstream 평가
•
섹션 4.3: DNA 서열 pre-training과 긴 서열 분류 작업에 대한 fine-tuning
•
섹션 4.4: 오디오 waveform pre-training과 autoregressively 생성된 음성 클립의 품질
마지막으로 섹션 4.5에서 학습과 추론 시간 모두에서 Mamba의 계산 효율성을 보여주고 섹션 4.6에서는 아키텍쳐와 selective SSM의 다양한 컴포넌트를 분석한다.
4.1 Synthetic Tasks
task 디테일과 학습 프로토콜을 포함하여 이 task에 대한 전체 실험 디테일은 부록 E.1 참조
4.1.1 Selective Copying
copying task는 sequence 모델링에 대해 가장 잘 연구된 합성 task 중 하나이다. 원래는 recurrent 모델의 기억 능력을 테스트하기 위해 설계되었다. 섹션 3.1에서 논의한대로 LTI SSMs(linear recurrences와 global convolution)은 데이터에 관한 추론 대신 시간을 추적만하여 이 task를 쉽게 해결할 수 있다. 예컨대 정확히 올바른 길이의 convolution 커널을 구성한다.(그림 2) 이것은 global convolution에 대한 이전 연구(Romero et al.2021)에서 명시적으로 평가된다. Selective Copying task는 토큰 사이의 spacing을 무작위화하여 이 shortcut을 방지한다. 이 작업은 이전에 Denoising task(Jing et al. 2019)로써 소개되었다.
이전의 많은 작업이 architecture gating(곱셈 상호작용)을 추가하는 것이 모델에 ‘데이터-종속성’을 부여하고 관련된 작업을 해결할 수 있다고 주장했다(Dao, Fu, Saab, et al. 2023; Poli et al. 2023). 그러나 이런 gating이 시퀀스 축을 따라 상호작용하지 않고 토큰 사이의 spacing에 영향을 줄 수 없기 때문에 우리는 이러한 설명이 직관적으로 불충분하다고 판단한다. 특히 architecture gating은 selection 메커니즘의 한 예가 아니다.(부록 A)
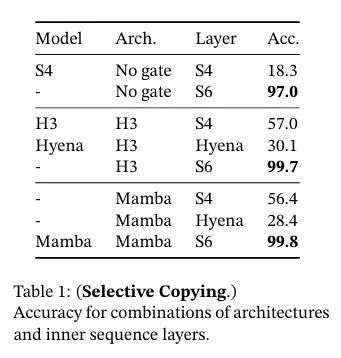
표 1에서 확인할 수 있듯이 H3나 Mamba 같은 gated architecture는 성능을 부분적으로 개선하는 반면, selection 메커니즘(S4를 S6로 수정)은 이 작업을 특히 더 강력한 아키텍쳐와 결합할 때 더욱 쉽게 해결한다.
4.1.2 Induction Heads
Induction head(Olsson et al. 2022)는 기계적 해석 가능성 렌즈(mechanistic interpretability lens, Elhage et al. 2021)에서 간단한 작업인데, 이것은 놀랍게도 LLM의 in-context learning 능력의 예측할 수 있다. 이것은 모델이 associative recall과 copy를 수행하도록 요구한다. 예컨대 모델이 ‘Harry Potter’와 같은 bigram을 시퀀스에서 보았다면, 같은 시퀀스에서 ‘Harry’가 나타날 때마다 모델은 history에서 copying하여 ‘Potter’를 예측할 수 있어야 한다.
데이터셋.
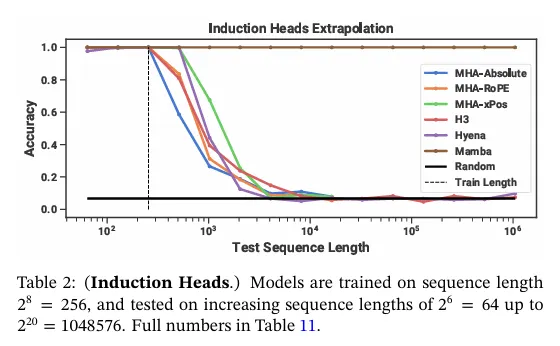
우리는 시퀀스 길이 에서 induction head task에 대해 2-layer 모델을 학습했다. 이것은 이 작업에 대한 이전 작업(Dao, Fu, Saab, et al. 2023)과 비교 가능하지만 더 긴 시퀀스를 사용한다. 우리는 추가적으로 테스트 시간에 부터 까지의 시퀀스 길이의 범위에대한 평가를 통해 일반화와 외삽(extrapolation) 능력을 조사했다.
모델.
induction head에 대한 기존 연구를 따라 2-layer 모델을 사용했는데, 이것은 induction head task를 기계적으로 풀기 위한 attention을 허용한다(Olsson et al. 2022). 우리는 multi-head attention(다양한 positional encoding을 사용하는 8개 heads)과 SSM 변종 모두에 대해 테스트 했다. 우리는 Mamba에 대해 차원 모델을 사용하고 다른 모델에 대해 을 사용했다.
결과.
표 2에 따르면 Mamba —더 정확히 selective SSM layer—가 task를 완벽히 해결하는 능력을 가졌음을 볼 수 있다. 왜냐하면 이것의 능력이 관련 있는 토큰을 selectively 기억하고 그 사이의 모든 것은 무시할 수 있기 때문이다. 이것은 million 길이 또는 학습 하는 동안 본 것보다 4000배 더 긴 시퀀스에 대해서 완벽하게 일반화 했지만 다른 방법은 2배 이상 일반화 되지 않는다.
attention 모델에 대한 positional encoding 변종의 중에서 xPos(length extrapolation을 위해 설계됨)는 다른 것들보다 약간 더 낫다. 또한 모든 attention 모델은 메모리 제한 때문에 시퀀스 길이 까지만 테스트되었다. 다른 SSM 중에서는 Poli et al. (2023)의 발견과 달리 H3와 Hyena가 유사하다.
4.2 Language Modeling
다른 아키텍쳐와 비교하여 표준 autoregressive 언어 모델링에 대해 pre-training 메트릭(perplexity)와 zero-shot 평가 모두에 대해 Mamba 아키텍쳐를 평가한다. 모델 크기(depth와 width)를 GPT3 사양과 동일하게 설정한다. 우리는 (L. Gao, Biderman 등, 2020)을 사용하고 Brown 등(2020)에 설명된 학습 레시피를 따른다. 모든 학습 세부사항은 부록 E.2에 있다.
4.2.1 Scaling Laws
baseline에 대해 표준 Transformer 아키텍쳐(GPT3 아키텍쳐) 뿐만 아니라 PaLM과 LLaMa 아키텍쳐(예: rotary embedding, SwiGLU MLP, LayerNorm 대신 RMSNorm, linear bias 없음, 더 높은 learning rate)를 기반으로 한 우리가 아는 한 가장 강력한 Transformer 레시피(여기서 Transformer++로 참조한)와 비교한다. 또한 다른 최근 subquadratic 아키텍쳐(그림 4)와도 비교한다. 모든 세부 사항은 부록 E.2 참조.
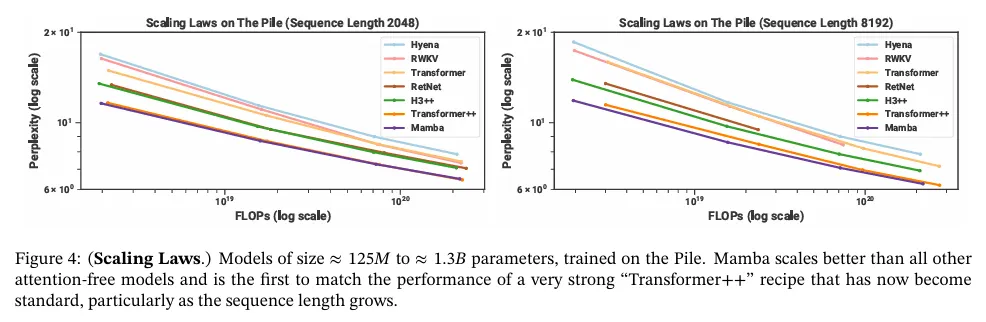
그림 4는 약 125M에서 약 1.3B 파라미터까지 모델에 대해 표준 Chinchilla(Hoffmann 등, 2022) 프로토콜 하에 scaling 법칙을 보인다. Mamba는 특히 시퀀스 길이가 길어질수록, 이제 표준이 된 매우 강력한 Transformer 레시피(Transformer++)의 성능을 따라잡은 최초의 attention-free 모델이다. SSM으로 해석될 수 있는 이전의 강력한 recurrent 모델인 RWKV와 RetNet baseline에 대해 효과적인 구현이 부족하여 out-of-memory 또는 비현실적인 계산 요구사항으로 인해 컨텍스트 길이 8k에 대한 전체 결과가 누락되었다.
4.2.2 Downstream Evaluations
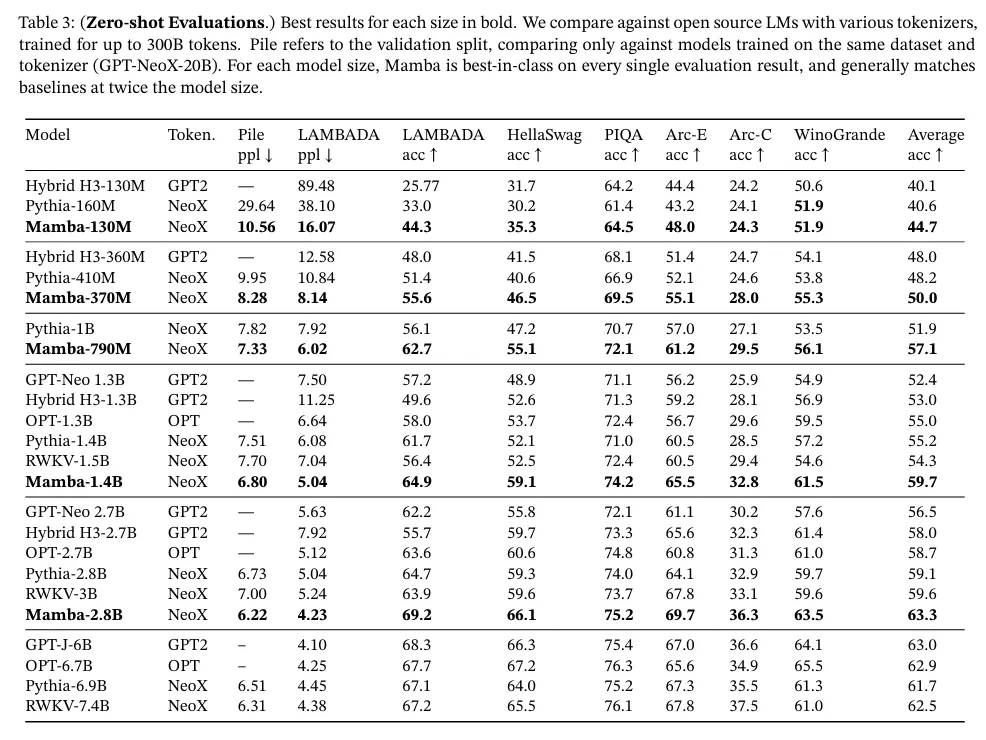
표 3은 인기 있는 downstream zero-shot 평가 task의 범위에 대한 Mamba의 성능을 보인다. 우리는 이 크기에서 가장 잘 알려진 오픈 소스 모델 특히 Pythia(Biderman 등, 2023)와 RWKV(B. Peng 등, 2023)와 비교한다. 이것들은 우리의 모델과 동일한 tokenizer, dataset, 학습 길이(300B 토큰)을 사용하여 학습되었다. (Mamba와 Pythia는 컨텍스트 길이 2048을 사용하여 학습되었지만 RWKV는 1024의 컨텍스트 길이로 학습되었음에 유의하라)
4.3 DNA Modeling
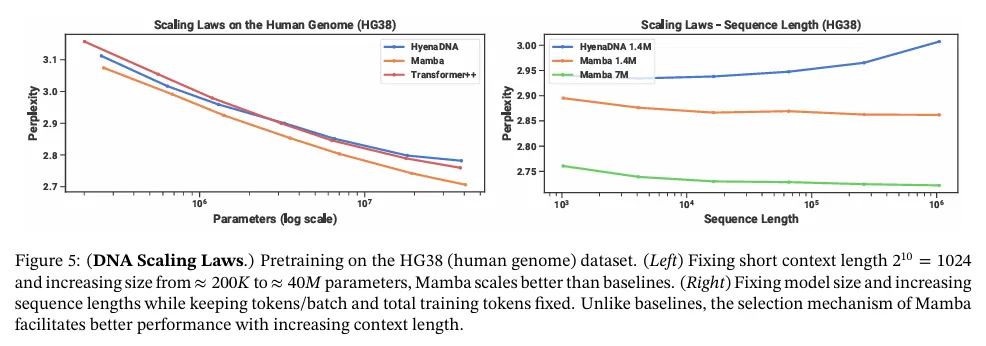
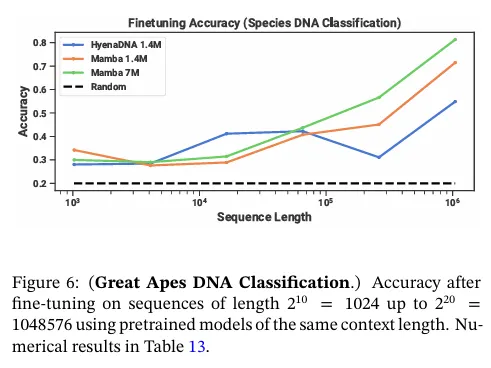
LLM의 성공에 동기부여 받아 유전체학에 대한 foundation 모델 패러다임을 사용하는 최근 연구가 존해했다. DNA는 유한한 어휘를 가진 이산 토큰의 시퀀스의 구성되어 있다는 점에서 언어에 비유되었다. 또한 모델에 대해 long-range 의존성을 요구하는 것으로 알려져 있다(Avsec et al. 2021). 우리는 DNA에 대한 long-sequence 모델에 대한 최근 연구(Nguyen, Poli, et al. 2023)와 동일한 설정에서 Mamba를 pre-training과 fine-tuning에 대한 FM 백본으로 조사한다. 특히 우리는 모델 크기와 시퀀스 길이에 대한 scaling 법칙(그림 5)과 long context를 요구하는 어려운 downstream 합성 분류 task(그림 6)의 두 가지 탐험에 초점을 맞춘다.
Pre-training에 대해 우리는 학습과 모델 디테일에 대해 표준 causal language 모델링(다음 토큰 예측) 설정을 대부분 따른다.(부록 E.2) 데이터셋에 대해 HyenaDNA의 설정을 대부분 따른다. 이것은 학습 분할에서 약 4.5B 토큰(DNA 기본 쌍)을 갖는 단일 인간 게놈으로 구성된 pre-training을 위한 HG38 데이터셋을 사용한다.
4.3.1 Scaling: Model Size
이 실험에서 우리는 다양한 모델 백본을 사용하여 genomics foundation 모델의 scaling 속성을 조서한다.(그림 5 왼쪽)
Training.
baseline을 활용하기 위해 1024의 짧은 시퀀스 길이에 대해 학습한다. 섹션 4.3.2에 보여진 것처럼 우리는 더 긴 시퀀스 길이에서 Mamba를 더욱 선호될 것으로 예상한다. batch 당 토큰에 대해 global batch 사이즈를 1024로 고정한다. 모델은 총 10B 토큰에 대해 10K gradient step으로 학습했다.
Results.
그림 5(왼쪽)은 Mamba의 pre-training perplexity가 모델 크기에 따라 smoothly 개선되며, Mamba가 HyenaDNA와 Transformer++보다 더 잘 scale 된다는 것을 보여준다. 예컨대 약 파라미터의 가장 큰 모델 크기에서 이 곡선은 Mamba가 약 3-4배 더 적은 파라미터로 Transformer++ 및 HyenaDNA 모델과 일치할 수 있음을 보인다.
4.3.2 Scaling: Context Length
다음 DNA 실험에서 우리는 시퀀스 길이 측면에서 모델의 scaling 속성을 조사한다. 2차적 attention이 더 긴 시퀀스 길이에 따라 엄두도 못 낼 만큼 비싸지기 때문에 오직 HyenaDNA와 Mamba 모델만 비교한다. 시퀀스 길이 에 대해 모델을 pre-train 한다. 모델은 총 약 330B 토큰에 대해 20k gradient 단계로 학습되었다. 더 긴 시퀀스 길이는 (Nguyen, Poli, et al. 2023)와 유사한 시퀀스 길이 warmup을 사용했다.
Result.
그림 5(오른쪽)은 Mamba가 길이 1M의 극단적으로 긴 시퀀스까지 더 긴 컨텍스트의 활용할 수 있으며, 컨텍스트가 증가함에 따라 pre-training perplexity가 개선되는 것을 보인다. 반면 HyenaDNA 모델은 시퀀스 길이가 길어질 수록 성능이 나빠진다. 이것은 섹션 3.5의 selection 메커니즘의 속성에 대한 논의를 통해 직관적으로 알 수 있다. 특히 LTI 모델은 convolutional 관점에서 selectively 정보를 무시할 수 없다. 매우 긴 convolution 커널은 매우 noisy 할 수 있는 긴 시퀀스의 모든 정보를 집계한다. HyenaDNA는 컨텍스트가 길어짐에 따라 성능이 향상된다고 주장하지만, 그들의 결과는 계산 시간을 제어하지 않음에 유의하라.
4.3.3 Synthetic Species Classification
우리는 5가지 서로 다른 종에 대해 그들의 DNA의 연속 segment를 무작위로 샘플링하여 분류하는 downstream task에 대해 모델을 평가한다. 이 task는 (인간, 여우원숭이, 쥐, 돼지, 하마)를 분류하는 HyenaDNA에서 채택되었다. 우리는 이 작업을 DNA의 99%를 공유하는 것으로 알려진 다섯 가지 유인원 종(인간, 침팬지, 고릴라, 오랑우탄, 보노보)를 분류하도록 훨씬 더 어렵게 수정한다.
4.4 Audio Modeling and Generation
오디오 waveform 모달리티에 대해 우리는 주로 SaShiMi 아키텍쳐와 학습 프로토콜(Goel et al. 2022)과 비교한다. 이 모델은 다음과 같이 구성된다.
1.
stage 당 모델 차원 을 두 배로 늘리는 factor 에 의해 두 stage 풀링을 갖춘 U-Net 백본
2.
각 stage에서 S4 및 MLP 블록을 교대로 사용한다.
우리는 S4+MLP 블록을 Mamba 블록으로 교체하는 것을 고려한다. 실험 세부사항은 부록 E.4 참조.
4.4.1 Long-Context Autoregressive Pretraining
우리는 YouTubeMix(DeepSound 2017)에 대해 pre-training 품질(autoregressive next-sample 예측)을 평가한다. 이것은 이전 작업에서 사용된 표준 피아노 음악 데이터셋으로, 16000Hz 비율로 샘플링된 4시간 분량의 솔로 피아노 음악으로 구성된다. pre-training 디테일은 표준 언어 모델링 설정(섹션 4.2)을 대부분 따른다.
그림 7은 계산량을 고정한 상태에서 학습 시퀀스 길이를 에서 까지 증가시키는 효과를 평가한다. (데이터 큐레이션 방식에 따라 scaling 커브에서 꺾임을 발생시키는 특이 사례가 존재한다. 예컨대 1분-길이 클립만 사용가능헀기 때문에 최대 시퀀스 길이는 실제로 60s*16000Hz=960000으로 제한된다.)
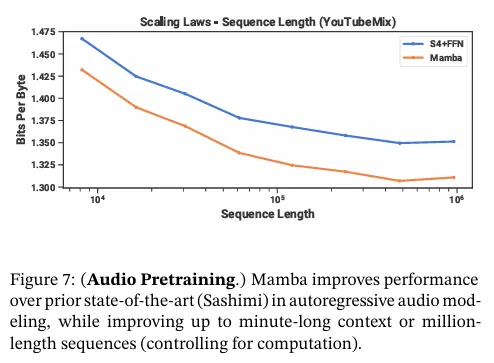
Mamba와 SaShiMi (S4+MLP) 모두 컨텍스트 길이가 길어질수록 베이스라인이 일관되게 개선되었다. Mamba가 전체적으로 더 나은 성능을 보였고, 길이가 길어질수록 격차가 벌어졌다. 주요 메트릭은 bits per byte(BPB)로, 다른 모달리티의 pre-training을 위한 표준 음의 로그 가능성(NLL) 손실의 상수 factor 이다.
한 가지 중요한 세부사항은 이것이 이 논문에서 유일하게 실수 파라미터를 복소수(섹션 3.6)로 전환한 실험이라는 점이다. 추가 ablation에 대해서는 부록 E.4를 참조.
4.4.2 Autoregressive Speech Generation
SC09는 "zero"부터 "nine"까지의 숫자를 다양한 특성을 사용하여 16000Hz로 샘플링한 1초 길이 클립으로 구성된 speech 생성 데이터셋이다(Donahue, McAuley, Puckette 2019; Warden 2018). 우리는 대부분 autoregressive 학습 설정과 Goel et al. (2022)의 생성 프로토콜을 따랐다.
표 4는 Mamba-UNet 모델의 자동화된 메트릭을 Goel et al.(2022), WaveNet(Oord 등, 2016), SampleRNN(Mehri 등, 2017), WaveGAN(Donahue, McAuley, Puckette 2019), DiffWave(Z. Kong 등, 2021), SaShiMi의 다양한 baseline과 비교한다. 작은 Mamba 모델이 최신 (그리고 더 큰) GAN과 diffusion 기반 모델을 능가했다. baseline과 동일한 파라미터 수의 더 큰 모델은 fidelity 메트릭을 드라마틱하게 개선한다.
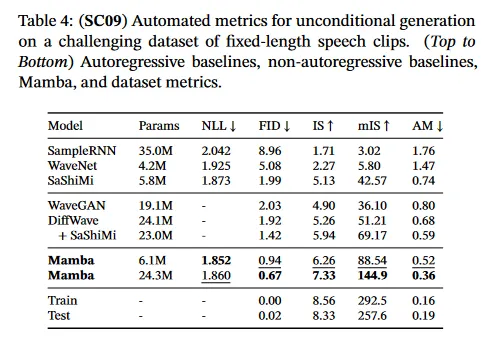
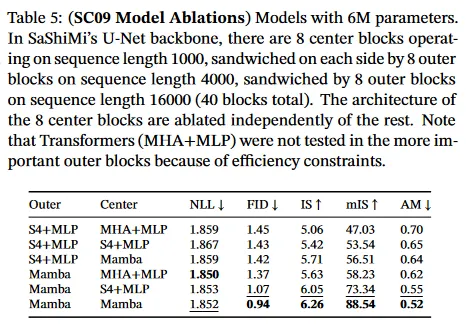
표 5는 작은 Mamba 모델을 사용하고 outer stage와 center stage에 대한 다양한 아키텍쳐의 조합을 조사한다. outer block에서 Mamba가 S4+MLP 보다 일관되게 낫고 center block에서는 Mamba > S4+MLP > MHA+MLP 임을 보인다.
4.5 Speed and Memory Benchmarks
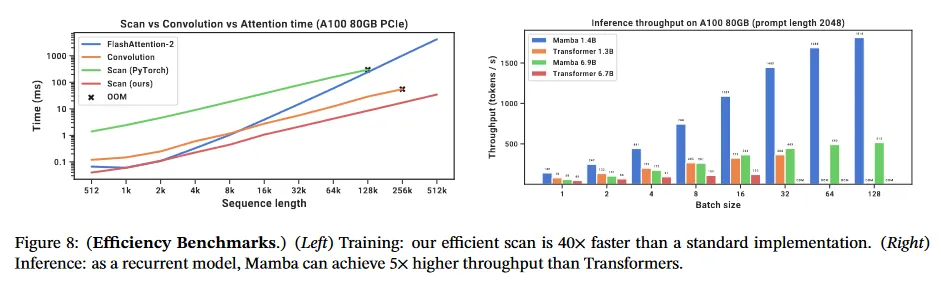
그림 8에서 우리는 SSM scan 연산(state expansion )과 Mamba의 end-to-end 추론 처리량을 벤치마크한다. 우리의 효율적인 SSM 스캔은 시퀀스 길이가 2K를 넘어서면 우리가 아는 한 최고의 attention 구현(FlashAttention-2(Dao 2023)) 보다 빠르며, PyTorch의 표준 스캔 구현보다 최대 20-40배 더 빠르다. Mamba는 KV 캐시가 없이 훨씬 더 큰 배치 크기를 사용할 수 있기 때문에 유사한 크기의 Transformer 보다 추론 처리량이 4-5배 더 높다. 예컨대 (untrained) Mamba-6.9B 는 5배 더 작은 Transformer-1.3B 보다 더 높은 추론 처리량을 갖는다. 디테일은 부록 E.5 참조. 여기에는 추가적으로 메모리 소비량의 벤치마크도 포함되어 있다.
4.6 Model Ablations
Chinchilla 토큰 수에서 크기 약 350M의 언어 모델링의 설정(그림 4와 동일한 설정)에 초점을 맞추어 모델의 컴포넌트에 대해 일련의 세부적인 ablations을 수행한다.
4.6.1 Architecture
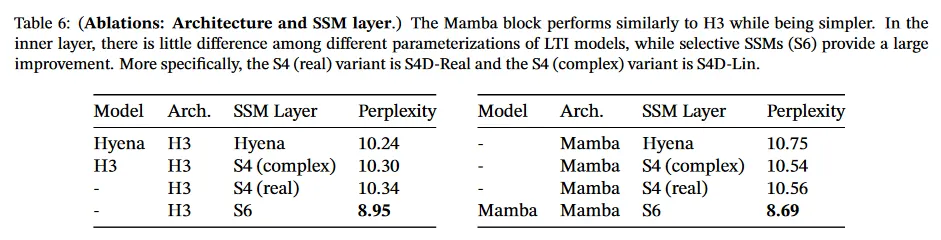
표 6은 아키텍쳐(블록)과 그것의 내부 SSM 레이어(그림 3)의 효과를 조사한 것이다. 우리는 다음을 발견했다.
•
global convolution과 동등한 이전의 non-selective (LTI) SSM 사이의 성능이 매우 유사하다.
•
이전 작업의 복소수값 S4 변종을 실수값으로 작업한 교체해도 성능에 별다른 영향이 없다. 하드웨어 효율성을 고려할 때 (적어도 언어 모델에 대해) 실수값 SSM은 더 나은 선택일 수 있다고 제안한다.
•
이들 중 어느 것이나 selective SSM(S6)로 교체하면 성능이 매우 향상된다. 이것은 섹션 3의 동기를 검증한다.
•
Mamba 아키텍쳐는 H3 아키텍쳐와 성능이 유사하다. (그리고 selective layer를 사용할 때 Mamba가 약간 더 낫다)
우리는 또한 Mamba 블록을 MLP(전통적인 아키텍쳐)나 MHA(hybrid attention 아키텍쳐) 같은 다른 블록과 교차하는 것을 조사했다. 부록 E.2.2 참조.
4.6.2 Selective SSM
표 7은 selective 의 다양한 결합을 고려하여(알고리즘 2) selective SSM 레이어를 ablate 한다. RNN gating에 대한 연결(Theorem 1) 때문에 가 가장 중요한 파라미터임을 보인다.
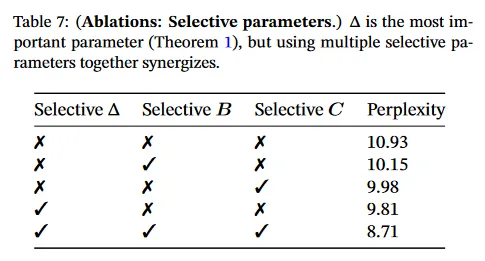
표 8은 일부 데이터 모달리티와 설정(Gu, Goel, Ré 2022; Gu, Gupta, et al. 2022)에서 매우 큰 차이를 보인 SSM의 다양한 초기화를 고려한다. 언어 모델링에 대해 더 단순한 실수값 대각 초기화(S4D-Real, 3행)가 더 표준적인 복소수값 파라미터화(S4D-Lin, 1행) 보다 성능이 낫다는 것을 발견했다. 랜덤 초기화 또한 잘 동작한다. 이것은 이전 연구에서 발견과 일치한다.(Mehta et al. 2023)
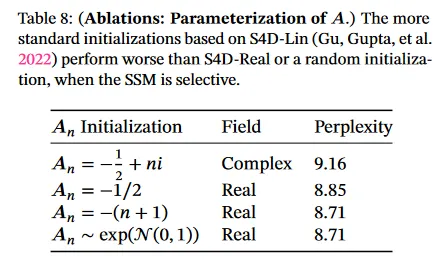
표 9와 10은 와 projection의 차원을 각각 변경하는 것을 고려한다. 정적에서 selective 변경할 때 가장 이점을 얻을 수 있으며, 차원을 더 늘리면 일반적으로 파라미터 수가 소폭 증가하여 성능이 어느 정도 향상된다.
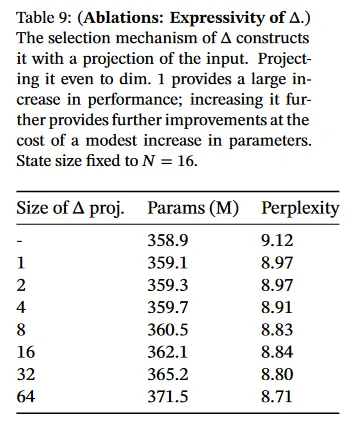
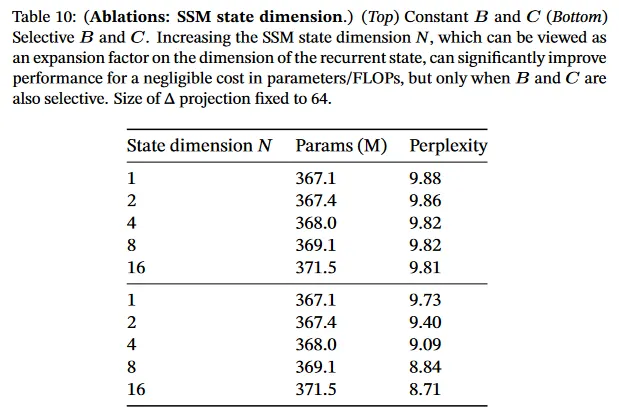
특히 주목할 점은 state 크기 이 증가할 때 selective SSM의 드마라틱한 개선된다는 것이다. 1%의 추가 파라미터의 비용에 대해 1.0 이상의 perplexity 개선을 갖는다. 이는 섹션 3.1과 3.3의 핵심 동기를 검증한다.
5 Discussion
관련 연구, 한계점 및 향후 방향에 대해 논의한다.
Related Work.
부록 A는 selection 메커니즘이 유사한 개념과 어떻게 관련되어 있는지를 설명한다. 부록 B에는 SSM의 확장된 관련된 작업과 다른 관련된 모델이 있다.
No Free Lunch: 연속-이산 스펙트럼.
structured SSM은 원래 연속 시스템의 이산화로 정의되었으며(1), 지각 신호(예: 오디오, 비디오)와 같은 연속 시간 데이터 모달리티에 대한 강력한 inductive bias를 가지고 있었다. 섹션 3.1과 3.5절에서 논의한 대로, selection 메커니즘은 text나 DNA 같은 이산 모달리티에 대한 약점을 극복한다. 그러나 이것은 반대로 LTI SSMs에 대해 탁월한 데이터의 성능을 저해할 수 있다. 오디오 waveform에 대한 ablation이 이 tradeoff을 더 자세히 검토한다.
다운스트림 용이성.
Transformer 기반 foundation 모델(특히 LLM)은 fine-tuning, adaptation, prompting, in-context learning, istruction tuning, RLHF, quantization과 기타 등등 pre-trained 모델과 상호작용하는 속성과 모드의 풍부한 에코시스템을 갖는다. 우리는 특히 SSM 같은 Transformer 대안이 유사한 속성과 용이성을 가지고 있는지 여부에 대해 관심 있다.
스케일링.
우리의 경험적 평가는 7B 파라미터 scale 이상에서 평가된 가장 강력한 오픈 소스 LLM(예: Llama(Touvron et al. 2023))) 뿐만 아니라 RWKV(B. Peng et al. 2023)와 RetNet(Y. Sun et al. 2023)와 같은 다른 recurrent 모델의 threshold 미만인 작은 모델 크기에 제한되어 있다. Mamba가 이러한 더 큰 크기에서 여전히 유리한지에 대한 평가가 남아 있다. 또한 SSM을 스케일링하는 것에는 이 논문에서 논의하지 않은 추가적인 엔지니어링 도전과 모델에 대한 조정이 포함될 수 있다.
6 Conclusion
우리는 structured space model에 대해 시퀀스 길이를 따라 선형으로 scaling 되면서 컨텍스트 의존 추론을 수행할 수 있는 selection 메커니즘을 도입했다. 간단한 attention-free 아키텍쳐로 통합될 때 Mamba는 다양한 도메인에서 최신 성능을 달성하며 강력한 Transformer 모델의 성능과 동등하거나 초과한다. 우리는 다양한 도메인 특히 genomics, audio와 video 같은 long 컨텍스트가 필요한 emerging 모달리티에 대한 foundation 모델을 구축하기 위한 selective state space model의 광범위한 응용을 기대한다. 우리의 결과는 Mamba가 일반적인 시퀀스 모델 백본으로 강력한 후보임을 시사한다.
