
Abstract
현대의 hierarchical vision transformer는 supervised 분류 성능을 추구하는 과정에서 여러 vision 특정화 컴포넌트를 추가했다. 이러한 컴포넌트는 효율적인 정확도와 매력적인 FLOP 수를 제공하지만, 추가된 복잡성으로 인해 vanilla ViT 버전 보다 속도가 실제로 더 느리다. 이 논문에서 이러한 추가인 bulk가 불필요하다고 주장한다. 강력한 visual pretext task로 pre-training 된 것(MAE)을 이용하여 최첨단 multi-stage vision transformer에서 복잡한 부가 요소를 제거해도 정확도 손실 없이 성능을 유지할 수 있다. 이 과정에서 우리는 Hiera를 개발했다. 이는 극단적으로 간단한 hierarchical vision transformer로서, 이전 모델 보다 더 정확하면서도 추론과 학습 시간 모두에서 매우 빠르다. 우리는 Hiera를 image와 video 인식을 위한 다양한 작업에서 평가한다. 우리의 코드와 모델은 git hub 참조.
1. Introduction
Dosovitskiy et al(2021)에 의해 몇 년 전 도입된 Vision Transformer(ViTs)는 여러 computer vision task를 주도했다. 아키텍쳐는 간단하지만 정확도와 확장 능력 덕분에 여전히 인기 있는 선택이다. 또한 그것의 단순함은 MAE 같은 강력한 pre-training 전략의 사용을 가능하게 하여, ViT를 학습하는데 계산과 데이터 효율성을 높인다.
그러나 이 단순성에는 비용이 발생한다. 네트워크 전반에서 동일한 공간 해상도와 채널 수를 사용함으로써 ViT는 파라미터를 비효율적으로 만든다. 이는 초기 단계에서 간단한 feature와 높은 해상도를 사용하고, 후반부에서는 복잡한 feature와 낮은 해상도를 갖는 이전의 ‘hierarchical’ 또는 ‘multi-scale’ 모델과 대비된다. Siwn 또는 MViT과 같은 hierarchical 설계를 활용하는 여러 도메인 특화 vision transformer가 도입되었지만, fully supervised training를 사용하여 ImageNet-1K에서 최첨단 결과를 달성하려는 과정에서 이러한 모델들은 점점 더 복잡해진다(예: CSWin에서 cross-shaped window, MViTv2에서 decomposed relative position embedding과 같은 특수 모듈). 이러한 변경은 매력적인 floating point operation(FLOP) 수를 가진 효과적인 모델을 만들지만, 추가된 복잡성으로 인해 모델이 실제로 더 느려진다.
우리는 이러한 것 중 많은 것이 실제로 불필요하다고 주장한다. ViT는 그들의 초기 patchify 연산 후에 inductive bias가 없기 때문에, 이후 vision 특화 transformer에 의해 제안된 많은 변경이 공간적 bias를 수동으로 추가하기 위한 것일 뿐이다. 그러나 왜 우리가 이러한 bias를 학습시킬 수 있다면, 왜 그러한 bias를 추가하면서 아키텍쳐를 느리게 해야 하는가? 특히 MAE pre-training은 ViT에게 공간적 추론을 가르치는 매우 효율적인 도구임을 보였고, 이를 통해 순수 vision transformer가 detection에서 좋은 결과를 얻을 수 있었다. 이것은 이전에 Swin이나 MViT 같은 모델이 주도했던 작업이다. 또한 MAE pre-training은 sparse이고 normal supervised training 보다 4-10배 만큼 빠를 수 있다. 정확도를 너머 더 많은 도메인에서 바람직한 대안이 되고 있다.
우리는 이 가설을 간단한 전략으로 테스트한다. 몇 가지 구현 트릭을 사용하여(그림 4), 기존 hierarchical ViT(예: MViTv2)에서 조심스럽게 필수적이지 않은 컴포넌트를 제거하고 MAE로 학습한다(Table 1). 새로운 아키텍쳐에 MAE를 조정 후에(Table 3), 우리는 실제로 단순화 하거나 non-transformer component를 모두 제거하면서도 정확도를 증가시킬 수 있음을 발견한다. 그 결과 복잡한 요소가 없는 극단적으로 효율적인 모델이 만들어진다. convolution도 없고 shift나 cross-shaped window도 없고 decomposed relative position embedding도 없다. 단순히 순수하고 간단한 hierarchical ViT이지만 여러 모델 크기와 도메인 task에 걸친 이전 작업 보다 더 빠르고 더 정확하다.
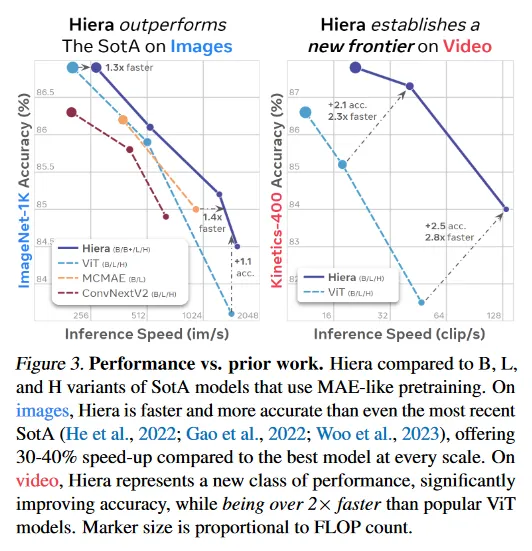
우리의 간단한 hierarchical vision transformer(Hiera)는 이미지에서 최첨단을 능가하고 video에서 여러 각 모델 스케일과 광범위한 데이터셋과 task에 걸쳐(섹션 5, 6) 이전 작업을 훨씬 초과하면서 더 빠르다(그림 1, 3).

2. Related Work
Vision Transformer(ViTs)
Vision Transformer(ViTs)는 image classification, video classification, semantic segmentation, object detection, video object segmentation, 3D object detection, 3D reconstruction과 같은 여러 vision task에서 그들의 큰 성공 덕분에 attention을 매력적으로 만들었다. vanilla ViT와 이전 convolutional neural network(CNN)사이의 핵심 차이는 ViT는 이미지를 16x16 픽셀의 겹침없는 path로 분할하고 공간적 grid를 1D sequence로 평탄화하는 반면 CNN은 여러 단계에 걸쳐 grid를 유지하고 각 단계에서 해상도를 줄이고, shift equivariance 같은 inductive bias를 도입한다는 것이다. 최근에는 transformer를 convolution-like 연산과 이전 CNN의 hierarchical stage 구조를 결합한 hybrid 방법에 대한 관심이 높아졌다. 이 방향은 다양한 vision task에서 성공을 보이고 최첨단을 달성했다. 그러나 실제로 이러한 모델은 vanilla ViT에 비해 느리고, conv는 masked image modeling 같은 인기 있는 self-supervised task와 쉽게 호환되지 않는다. 우리는 Hiera를 만들면서 이 두 가지 이슈를 모두 해결한다.
Maksed Pre-training
Maksed Pre-training은 visual representation을 학습하기 위한 강력한 self-supervised learning pretext task로 출현했다. 이전 작업 중에서 Masked AutoEncoder(MAE)는 vanilla ViT의 이점을 활영하여 입력 길이를 유연하게 조정할 수 있어 masked image의 희소성을 활용한 효율적인 학습 체계를 유도한다. 이것은 masked pre-training의 학습의 효율성을 매우 개선했지만 sparse training을 hierarchical model에 채택하는 것은 입력이 더는 rigid 2D grid에 배치되지 않기 때문에 간단하지 않다. hierarchical ViT에서 masked pre-training을 가능하게 하려는 여러 시도가 있었다.
MaskFeat과 SimMIM은 masked patch를 [mask] token으로 교체하여 대부분의 계산이 non-visible token에 낭비되며 학습이 매우 느렸다. Huang et al(2002a)는 네트워크의 각 컴포넌트에 희소성을 가능하게 하는 여러 기법을 도입했지만, 결과적으로 매우 복잡한 모델을 만들었고 정확도는 크게 개선되지 않았다. UM-MAE는 희소성을 허용하는 특별한 masking 전략을 사용하지만, 이 제한은 정확도를 크게 저하시킨다. MCMAE는 초기 몇 단계에서 masked convolution을 사용하여 높은 정확도를 얻었지만, 모델의 전체적인 효율성을 감소시켰다.우리는 이러한 복잡한 기법을 모두 우회하고 sparse MAE pre-training을 위한 특별한 아키텍쳐를 설계하여 강력하면서도 간단한 모델을 생성한다.
3. Approach
우리의 목표는 강력하고 효율적인 multiscale vision transformer를 만드는 것이며 무엇보다 단순함을 추구한다. 우리는 vision task에서 높은 정확도를 얻기 위해 convolution, shifted windows, attention bias 같은 특화된 모듈이 필요 하지 않다고 주장한다. 이러한 기법은 vanilla transformer가 부족한 공간적(그리고 시간적) bias를 추가하기 때문에 필요해 보일 수 있지만 우리는 다른 전략을 활용한다. 이전 작업은 복잡한 아키텍쳐 변경으로 spatial bias를 추가했다면, 우리는 모델을 간단하게 유지하면서 강력한 pretext task를 통해 이러한 bias를 학습시키는 방법을 고른다. 이 아이디어의 효율성을 보이기 위해 기존 hierarchical vision transformer를 사용하고, pretext task와 함께 bells-and-whistles를 albate하는 간단한 실험을 유도한다.
pretext task를 위해 우리는 Masked Autoencoder(MAE)를 사용하며, 이것은 네트워크가 masked 입력 패치를 재구성하도록 하여 ViT의 downstream task에 필요한 localization 능력을 가르치는데 효율적임을 보인다(그림 2). 여기서 MAE pre-train은 희소함에 유의하라. 즉 다른 masked image 모델링 접근과 달리 masked token이 덮어씌워지지 않고 삭제된다. 이로 인해 pre-training이 효율적으로 이루어지지만, 기존의 hierarchical 모델에서는 2D grid가 깨져서 문제를 제기한다(그림 4b). 또한 MAE는 개별 token을 mask out 하는데, ViT에서 이 토큰이 16x16 패치이지만, 대부분의 hierarchical model에서는 4x4의 작은 패치이다(그림 4a).
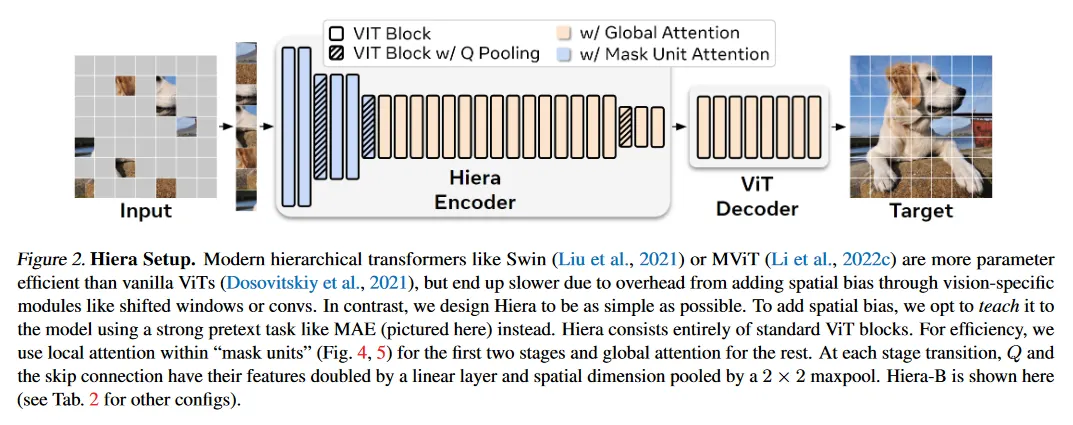

이러한 이슈를 모두 해결하기 위해 우리는 토큰과 ‘mask unit’을 구별한다. 그림 4a에서 설명된 것과 같이 mask unit은 MAE masking을 적용하는 해상도이고, token은 모델의 내부 해상도이다. 우리의 경우에 우리는 32x32 픽셀 영역을 mask 처리하며, 이는 네트워크 초기에 8x8 token을 한 mask unit으로 사용한다는 의미이다. 이 구별을 만들면, 우리는 영리한 트릭(그림 4d)를 사용하여 mask unit을 다른 token과 분리된 연속적인 요소로 처리하여 hierarchical 모델을 평가할 수 있다. 따라서 우리는 기존의 hierarchical vision transformer와 함께 MAE를 사용한 실험을 계속할 수 있게 된다.
3.1. Preparing MViTv2
우리는 MViTv2를 기본 아키텍쳐로 사용한다. 이것은 그림 4d에서 설명된 separate-and-pad trick에 의해 3x3 kernel이 가장 작게 영향을 받기 때문이다. 다른 transformer를 통해서도 유사한 결과를 얻었을 가능성이 크다. 여기에서 MViTv2를 간략히 소개한다.
MViTv2.
MViTv2(Li et al. 2022c)는 hierarchical model이로, 4단계를 통해 multi-scale representation을 학습한다. 처음에는 작은 channel 능력과 높은 공간적 해상도로 low level feature를 모델링한 다음 더 깊은 layer의 각 단계에서 더 복잡한 high-level feature를 모델링하기 위해 채널 용량과 공간 해상도를 교환한다.
MViTv2의 핵심 feature는 pooling attention(그림 5a)이다. 여기서 feature는 self-attention을 계산하기 전에 3x3 convolution을 사용하여 locally aggregated이다. pooling attention에서 계산을 감소시키기 위해 첫 두 단계에서 K와 V는 pooled하며, Q는 공간 해상도를 축소하며 다음 단계로 전이하기 위해 pooled 된다. MViTv2는 또한 절대적 position embeddings 대신 decomposed 상대적인 것을 사용하며, attention block 내에서 pooled Q token 간의 skip을 위한 residual pooling connection을 feature로 한다. 기본적으로 MViTv2의 pooling attention은 downsampling이 필요하지 않더라도 stride 1의 conv를 포함한다.

Applying MAE.
MViTv2는 총 3번 2x2로 downsampling하며(그림 2), 4x4 픽셀의 token 크기를 사용하므로 32x32 크기의 mask unit을 활용한다. 이것은 각 mask unit이 단계 1, 2, 3, 4에서 각각 토큰에 해당하며, 각 단계에서 최소 1개 고유 토큰을 커버하도록 보장한다. 그 다음 그림 4d에서 설명된 것과 같이, conv kernel이 삭제된 token으로 확장되지 않도록, mask unit을 배치 차원으로 shift하여 pooling을 위해 분리한다(각 mask unit을 ‘image’로 처리). 그 다음 shift를 원래대로 돌려서 self-attention이 여전히 global이 되도록 유지한다.
3.2. Simplifying MViTv2
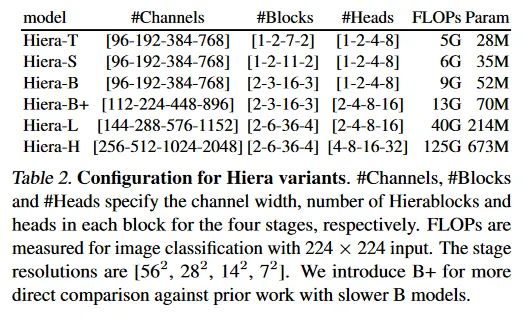
이 섹션에서 MAE와 함께 학습하면서 MViTv2의 필수적이지 않은 컴포넌트를 제거한다. Table 1에서 이러한 요소를 모두 제거하거나 단순화해도 ImageNet-1K에서 이미지 분류에 대한 높은 정확도를 유지할 수 있다. 우리는 대규모에서도 이러한 변경이 작동하는지 확인하기 위해 MViTv2-L을 사용한다.

Relative Position Embeddings.
MViTv2는 Dosovitskiy et al(2021)의 절대값 position embedding을 각 블록에 attention에 추가된 더 강력한 상대적 position embedding으로 교체한다. 기술적으로 이 작업을 sparse pre-training과 호환되도록 구현할 수 있지만, 상당한 복잡성을 추가해야 한다. 대신 이 연구를 시작하면서 이 변경을 되돌리고 절대값 position embedding을 사용했다. Table 1a에서 보이는대로 MAE로 학습할 때는 이러한 상대적 position embedding은 필요하지 않다. 또한 절대값 position 임베딩이 훨씬 빠르다.
Removing Convolutions.
다음으로 모델에서 conv를 제거하는 것을 목표로 한다. 이것은 vision 특화 모듈로 불필요한 overhead를 추가할 수 있다. 우리는 우선 모든 conv layer를 maxpool로 교체하려 했는데, 이는 Fan et al(2021)에 의해 가장 적합한 대안으로 제시되었다. 그러나 이 방법도 상당한 비용이 든다. 결과적으로 이미지의 정확도가 1% 이상 하락했는데 이것은 기대했던 결과이다. 우리는 또한 모든 stride=1의 추가 conv를 maxpool로 교체했기 때문에 feature에 상당한 영향을 미쳤다(padding과 작은 mask unit으로 인해 각 feature map에서 relu를 수행하는 것과 유사한 효과를 갖는다). 그 다음 이러한 추가적인 stride=1 maxpool을 삭제할 때(Table 1c), 우리는 이전의 정확도와 가까우면서 이미지에 대한 모델의 속도가 22%, video에 대해서는 27% 빨라졌다. 이 지점에서 남아 있는 pooling layer는 단계 전이에서 Q와 첫 두 단계에서 KV pooling 뿐이다.
Removing Overlap.
남아 있는 maxpool layer는 여전히 3x3 kernel 크기를 가지며, 이로 인해 학습과 추론 모두에서 그림 4d의 separate-and-pad trick을 사용해야 한다. 그러나 그림 4e에서 보이는 바와 같이 이러한 maxpool kernel이 겹치지 않게 하면, 이 문제를 완전히 피할 수 있다. 즉 각 maxpool에 대한 kernel 크기를 stride와 일치시키면 separate-and-pad trick 없이 sparse MAE pre-training을 사용할 수 있다. Table 1d에서 보이는대로 이것은 이미지에서 모델 속도를 20% 높이고, 비디오에서 12% 높인다. 반면 pad를 가지지 않기 때문에 정확도가 증가한다.
Removing the Attention Residual.
MViTv2는 pooling attention을 학습하는 것을 돕기 위해 attention layer에 Q와 출력 사이에 residual connection을 추가한다. 그러나 지금까지 레이어의 수를 최소화하여 attention이 학습을 더 쉽게 만들었으므로 이를 안전하게 제거할 수 있다(Table 1e).
Mask Unit Attention.
이 지점에서 남은 특수 모듈은 pooling attention 뿐이다. Pooling Q는 hierarchical model을 유지하기 위해 필요하지만 KV pooling은 첫 두 단계에서 attention matrix의 크기를 줄이는데만 필요하다. 우리는 이 완전히 제거할 수 있지만, 그렇게 하면 네트워크의 계산 비용이 크게 증가한다. 대신 Table 1f에서 구현이 간단한 대안으로 mask unit 내부에서 local attention을 사용한다.
MAE pre-training 동안, 네트워크의 시작에서 mask unit을 분리하므로(그림 2) token은 attention에서 도착할 때 이미 mask unit 별로 잘 정렬되어 있다. 그 다음 오버헤드 없이 이러한 unit 내에서 local attention을 수행할 수 있다. 이 ‘Mask Unit attention’이 pooling attention 같이 global이 아니라 local 이고(그림 5), K와 V는 첫 두 단계에서만 pooled하므로, 여기서 global attention은 유용하지 않다. 따라서 Table 1에서 보이듯이, 이 변경은 정확도에 영향을 주지 않으면서 처리량을 비디오의 경우 32%까지 증가시킨다.
mask unit attention이 window attention와 구별되는 것에 유의하라. 이것은 현재 해상도에서 mask unit의 크기에 맞춰 window size를 조정하지만, window attention은 네트워크 전반에서 고정된 크기를 가지며 downsampling 이후에 삭제된 토큰으로 누출 될 수 있다(그림 6)

Hiera.
이러한 변경의 결과로 매우 간단하고 효율적인 모델이 만들어졌으며 우리는 이것을 ‘Hiera’라고 부른다. Hiera는 MViTv2보다 이미지에서 2.4배 더 빠르고, video에서 5.1배 더 빠르다. 그리고 MAE 덕분에 실제로 더 정확하다. 또한 Hiera가 sparse pre-training을 지원하기 때문에 Table 1에서 결과는 매우 빠르게 얻을 수 있다. 실제로 Hiera-L은 이미지를 위한 더 높은 정확도를 얻기 위해 supervised MViTv2-L에 비해 학습이 3배 빠르다(그림 7). 비디오에 대해 Wei et al(2022)이 MViTv2의 첫 3개 단계에서 KV stride를 2배로 설정한 cut down 버전을 사용에서 80.5%를 보고 했다. 이에 비해 우리의 Hiera-L은 800회 pre-train epoch에서 85.5%를 얻으면서도 학습 속도가 2.1배 더 빠르다(그림 7). 이 논문의 모든 벤치마크는 달리 명시하지 않는 한, 실용적으로 가장 유용한 설정인 A100에서 fp16으로 학습되었다.

이 섹션에서 Hiera-L을 사용했지만, 이를 다른 크기로도 구현 할 수 있다. 예: Table 2
4. MAE Ablations
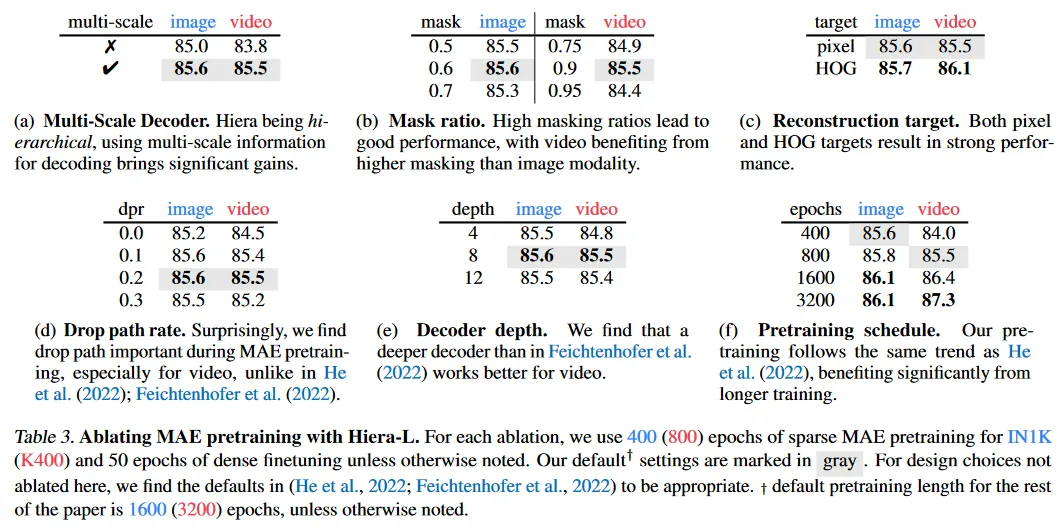
이 섹션에서 ImageNet-1K(IN1K)와 Kinetics-400(K400)을 사용하여 image와 video에 대한 Hiera에서 MAE pre-training 설정을 ablate한다. He et al(2002)와 Feichtenhofer et al(2002)와 유사하게 우리는 대규모에서 잘 작동한다는 것을 확인하기 위해 대형 모델인 Hiera-L을 사용하여 ablate한다. 우리는 fine-tuning으로 성능을 평가한다. 모든 메트릭은 표준 평가 프로토콜을 사용하여 top-1 정확도로 측정한다. IN1K에서는 단일 (resized) center crop을 사용하고 K400에서는 3 spatial x 5 temporal view를 사용한다.
Multi-Scale decoder.
He et al(2022)와 Feichtenhofer et al(2022)는 encoder의 마지막 블록의 token을 decoder의 입력으로 사용하지만, Hiera는 계층구조를 통해 더 유연하게 작동할 수 있다. Gao et al(2022)와 같이 모든 단계에서 representation을 융합하여 multi-scale 정보를 사용할 수 있으며, 이는 두 가지 모달리티 모두에서 큰 이점을 얻는다(Table 3a).
Masking ratio.
Feichtenhofer et al(2022)는 비디오에서 이미지보다 훨씬 높은 masking 비율을 필요로 한다는 것을 발견했다. 이는 더 높은 정보 중복을 시사한다. Table 3b에서 우리도 유사한 경향을 관찰했다. 이미지에 대해 최적 masking 비율은 0.6이고 video에서는 0.9이다. 우리의 이미지에 대한 최적 비율 0.6은 He et al(2022)에서 사용된 0.75보다 약간 낮다. 우리는 이것이 16x16 대신 32x32 mask unit을 사용함으로써 pretext task가 더 어려워졌기 때문이라고 예상한다. 흥미롭게도 우리는 비디오에 대해 Feichtenhofer et al(2022)에서와 동일한 0.9 masking 비율이 적절하다는 것을 발견한다. 이는 더 긴 학습을 하면 최적의 비율이 0.95로 작동할 수 있기 때문일 수 있다. 우리의 설정에서 높아진 task 어려움으로 인해 0.9에서 최고로 작동했다.
Reconstruction target.
Table 3c에서 보듯이, 픽셀(w/norm)과 HOG target 모두에서 강력한 성능을 발견했다. 기본 pre-training epoch 수에서는 HOG target이 약간 더 나은 성능을 보이지만, 더 긴 training에서 비디오에 대해 픽셀 target과 동일한 성능을 달성함을 발견했다. 그러나 이미지에서는 약간 나빴다.
Droppath rate.
원래의 MAE pre-training 레시피는 pre-training 동안 명시적으로 drop path를 사용하지 않고 fine-tuning 동안에만 사용한다. 그러나 Hiera-L은 ViT-L 모델 보다 2배 더 깊고(Hiera-L의 경우 48 vs ViT-L에서 24), 각 레이어의 파라미터 수가 더 적지만, Hiera의 깊이 때문에 drop path에서 상당한 이익을 얻을 수 있다.
Table 3d에서 우리는 pre-training 동안 drop-path를 적용하는 것을 ablate하고(fine-tuning에서는 기본으로 drop path 활용) 상당한 이득을 관찰했다. 이것은 놀라운 결과로 drop path 없이 Hiera가 MAE task에 대해 과적합 될 수 있음을 의미한다.
Decoder depth.
우리는 비디오에서 이전 연구보다 더 깊은 decoder를 사용할 때 상당한 이점을 발견한다(Table 3e. 이것은 비디오 decoder를 이미지와 동일하게 맞춘다.
Pretraining schedule.
여러 masked 이미지 모델링 접근은 더 긴 pre-training 스케쥴에서 이점을 발견했으며, 종종 1600 epoch까지 사용한다. Table 3f에서 우리는 Hiera에 대해 동일한 경향을 관찰한다. IN1K에서 400 epoch에 대해 0.5% 향상한다. 사실 Hiera의 400 eopch에서 정확도는 ViT-L MAE(84.9%) 보다 0.7% 더 높고, 1600 epoch에서는 0.2% 더 높다. 이것은 Hiera가 더 효율적인 학습자임을 시사한다. K400에서 Hiera는 800 epoch의 pre-training으로도 1600 epoch을 사용하는 이전의 최첨단 결과(85.2%)를 능가한다. 비디오에서는 더 긴 학습이 포화에 도달하는 시간이 더 느리며, 800 epoch에서 1600 epoch로 연장했을 때 0.9%의 이득이 있었다.
5. Video Results
우리는 video recognition에서 결과를 리포트한다. 별도로 명시되지 않는 한, 모든 모델은 픽셀의 16 프레임을 입력으로 사용한다. 비디오의 경우 mask unit은 픽셀(즉 이전과 같이 토큰)이다. 모델의 나머지는 이미지에서와 동일하다.
Kinetics-400,-600,-700.
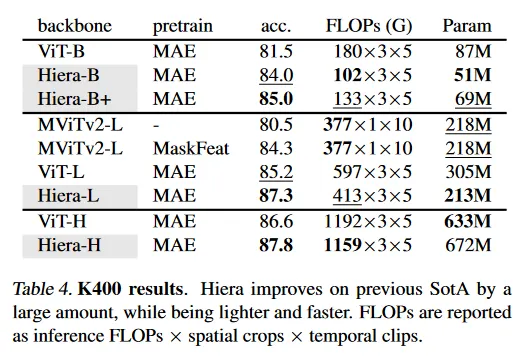
Table 4에서 우리는 Kinetics-400에서 MAE로 학습된 Hiera를 최첨단 모델과 시스템 레벨에서 비교한다. 우리는 MaskFeat으로 pre-trained인 MViTv2-L와 비디오에 대해 MAE로 pre-trained인 ViT을 비교한다. Hiera-L은 이전 최첨단에 대해 큰 성능 향상(2.1%)를 얻는 반면 45% 더 적은 flop를 사용하고 43% 더 작고, 2.3배 더 빠르다(그림 3). 사실 Hiera-L은 한 단계 상위 모델을 능가하면서도(0.7%), 3배 더 작고 3.5배 더 빠르다. Hiera-L은 MViTv2-L supervised baseline에 대해 6.8% 성능 향상 달성한다. 한 단계 더 큰 Hiera-H 모델은 이전 최첨단 모델에 대해 1.2% 성능 향상되고, 외부 데이터 없이 에서 새로운 최첨단 성능을 달성한다. Table 5에서 유사하게 K600에 대해 1.9%, K700에 대해 2.8% 개선된 결과를 보인다. 우리의 H 모델은 더 큰 향상을 얻는다.
Something-Something-v2 (SSv2).
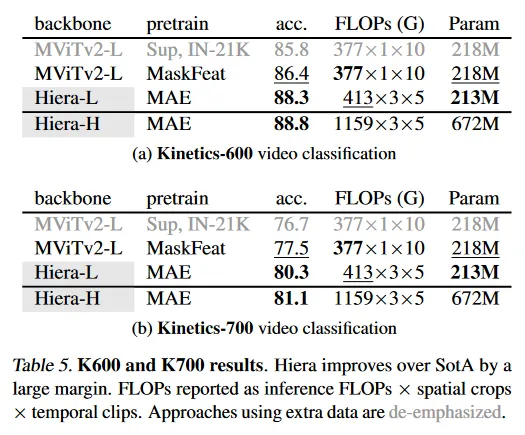
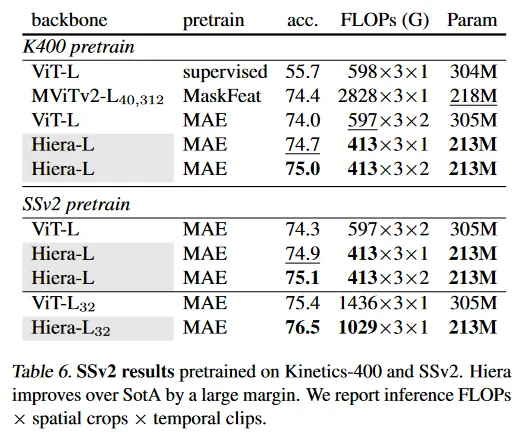
Table 6에서 우리는 SSv2에서 Hiera를 현재 최첨단 방법과 시스템 레벨에서 비교한다. MaskFeat으로 pre-trained MViTv2-L과 비디오에 대해 MAE로 pre-trained ViT을 비교한다. K400에서 pre-trained Hiera-L은 차점자인 MaskFeat 보다 0.6% 향상되지만 Hiera는 훨씬 효율적이다. MaskFeat은 에서 40 프레임을 사용하지만 Hiera는 에서 16 프레임을 사용해 FLOP를 3.4배 더 적게 사용한다. SSv2에서 pre-trained일 때, Hiera-L은 75.1%를 기록하며, MAE pre-trained ViT-L을 0.8% 능가하면서도 flops가 45% 더 적고, 크기는 43% 더 작다. Hiera-L32 모델은 76.5% 를 달성하며 SSv2에서만 학습된 모델 중 최첨단을 달성한다.
Transferring to action detection (AVA).
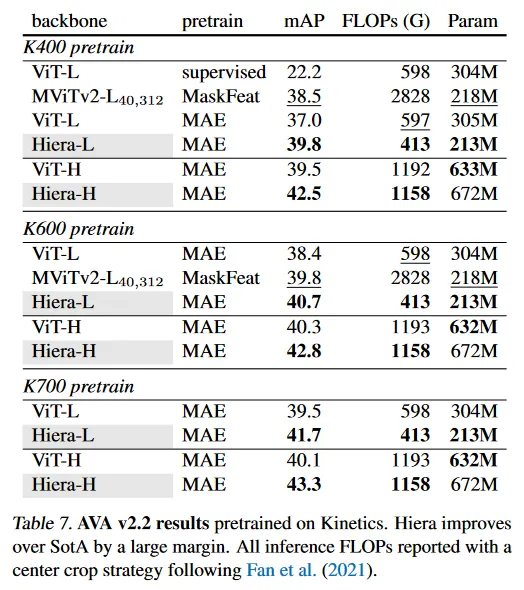
우리는 AVA v2.2 데이터셋을 사용하여 K400/K600/K700 pretrained Hiera의 action detection에 대한 transfer learning을 평가한다. Table 7에서 우리는 pre-trained Hiera를 최첨단 방법과 시스템 레벨에서 비교하고(MaskFeat을 사용한 MViTv2와 비디오에 대해 MAE를 사용한 ViT) mean average precision(mAP)을 리포트한다. K400 pre-trained Hiera-L은 MAE pre-trained ViT-L을 2.8% 능가하고 MViTv2-L MaskFeat 보다 mAP가 1.3% 높으면서, 더 적은 FLOPs와 파라미터를 갖는다. Hiera-H는 MAE pre-trained ViT-H 보다 3.0% mAP 높다. K600/K700 pretrained Hiera에서도 유사한 성능 향상을 관찰한다. 특히 K700 pre-trained Hiera-H는 MAE pre-trained ViT-H를 3.2% 능가하고 새로운 최첨단을 설립한다.
6. Image Results
우리는 우선 IN1K에서 성능을 평가하고 다른 이미지 recognition, detection, segmentation task로 transfer 한다.
6.1. Performance on ImageNet-1K
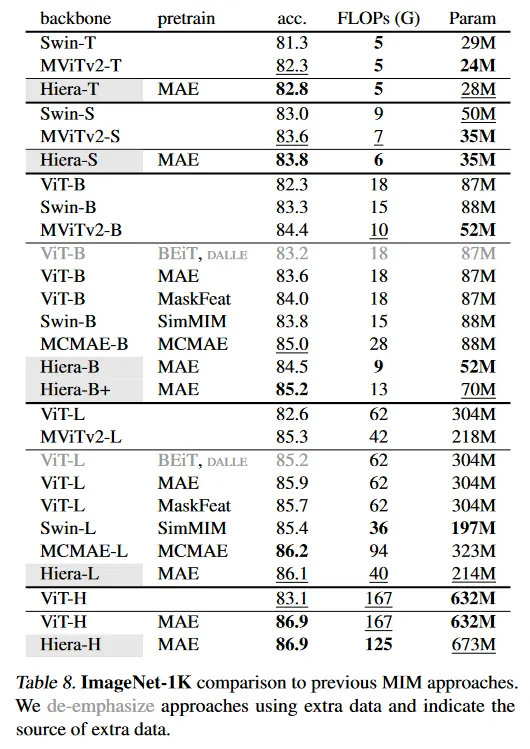
Table 8에서 우리는 MAE로 trained Hiera를 이전 작업과 시스템-레벨 비교를 수행한다. 우선 supervised MViTv2 baseline이 매우 강력함을 관찰한다. MViTv2-B(L)은 84.4(85.3)의 top 1 정확도를 달성하여 pre-training을 사용하는 여러 접근들(예: ViT-B MAE) 보다 나은 성능을 보인다. 이것은 supervised setting에서 convolution이 제공하는 상당한 이점, 특히, base 모델 크기 이하에서으 ㅣ이점을 보인다. 놀랍게도 동일한 크기에서 Hiera-B은 bells-and-whistles를 사용하지 않고도 84.5%에 도달하여 MViTv2-B를 (약간) 능가한다. MCMAE-B는 더 높은 정확도를 달성하지만 모델은 매우 무겁다. 우리의 Hiera-B+ 모델은 속도와 정확도 모두에서 이를 능가한다. 더 작은 모델로 가면, Hiera-S, -T는 놀랍도록 강력한 성능을 보이며, 이는 convolution이 역사적으로 지배했던 scale 영역에서, 좋은 공간적 bias가 학습될 수 있다는 핵심 전제와 일관된다.
기본 scale에서 Hiera-L MAE는 86.1% 정확도에 도달하고 MViTv2-L에 대해 0.8% 능가한다. 또한 42% 더 크고 1.6배 FLOPs를 갖는 ViT-L MAE를 0.2% 능가한다. 이 연구에서 MAE pre-training을 효율적인 sparse pre-training으로 채택했지만, Hiera-L은 EMA teacher를 사용하는 보완적이고 직교인 방식과 쉽게 호환될 수 있다.
6.2. Transfer learning experiments
여기서 우리는 downstream classification, detection, segmentation task에 transfer learning 실험을 수행한다.
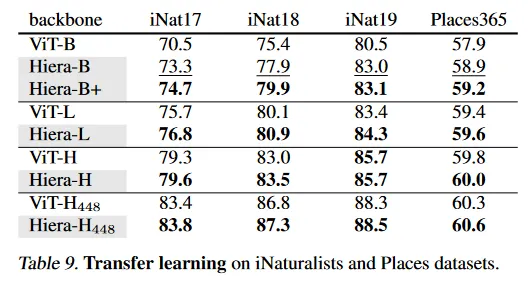
Classification on iNaturalists and Places.
Table 9에서 iNaturalist와 Places 데이터셋을 사용한 downstream transfer learning 성능을 평가한다. 우리는 ImageNet-1k pre-trained Hiera를 INaturalist 2017, 2018, 2019와 Places 365에 fine-tune 한다. Hiera는 MAE로 pre-trained인 ViT를 일관되게 능가하며, 우리의 Hiera-L과 Hiera-H 아키텍쳐가 ImageNet의 외에서도 효율적임을 시사한다.
Object detection and segmentation on COCO.
우리는 Mask R-CNN을 COCO 데이터셋에서 다양한 pre-trained backbone으로 fine-tune 한다. 우리는 object detection과 instance segmentation을 위해 와 를 리포트한다. 우리는 ViT-Det를 따라 학습 레시피를 활용하고, 원본 논문에서 설명된 대로 Hiera에서 multi-scale feature를 Feature Pyramid Network(FPN)와 통합한다.
Table 10에서 MAE pre-training을 사용하는 Hiera가 MViTv2와 같은 supervised pre-training을 사용하는 모델과 비교할 때 일관되게 더 빠르면서 강력한 scaling을 시연함을 볼 수 있다. 예컨대 Hiera-L은 MViTv2-L보다 1.8 더 높고(55.0 vs 53.2) 추론 시간을 24% 축소시킨다. ImageNet-21K pre-training을 사용하는 MViTv2와 비교할 때도 Hiera-L은 여전히 MViTv2-L 보다 1.4 낫다.
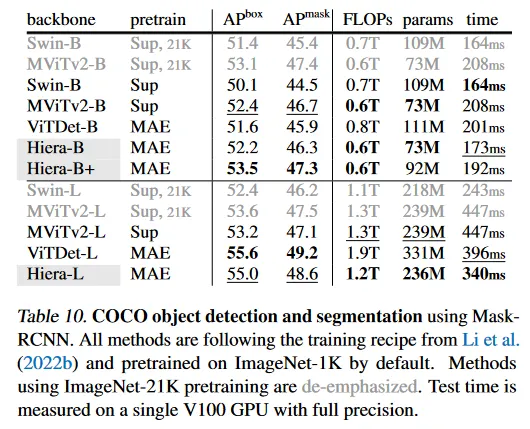
최첨단 방법 ViTDet과 비교할 때, 우리의 Hiera 모델은 더 빠른 추론과 더 적은 연산 수로 비교할만한 결과를 달성한다. 예컨대 Hiera-B는 ViTDet-B보다 0.6 더 높고 34% 더 적은 파라미터와 15% 더 적은 추론 시간을 갖는다. 추가로 Hiera-B+은 더 낮은 추론 시간과 모델 복잡성을 가지면서 ViTDet-B와 비교하여 1.9 개선을 달성한다. 더 큰 모델의 경우 Hiera-L은 일관되게 ViTDet-L 보다 빠르고 약간 낮은 정확도를 보인다.
7. Conclusion
이 연구에서 우리는 기존의 것에서 모든 bells-and-whistles를 제거하고, MAE pre-training을 통해 모델에 공간적 bias와 제공하여 간단한 hierarchical vision transformer를 만들었다. 그 결과 아키텍쳐 Hiera는 이미지 recognition 작업에서 현재 작업보다 더 효율적이고 video 작업에서 최첨단 성능을 능가한다. 우리는 Hiera가 미래 작업에서 더 많은 일을 더 빠르게 수행할 수 있기를 희망한다.
A. Implementation Details
video의 mask unit은 ‘2 프레임 x 32 픽셀 x 32 픽셀’의 블록에 해당한다(이미지가 1 x 32 x 32인 것과 대비된다). Feichtenhofer et al(2022)을 따라 Hiera에서 video의 각 토큰은 입력의 2 프레임에 해당한다. mask unit이 또한 2 프레임에 걸쳐 있으므로 Mask Unit Attention에 대한 window 크기는 video에 대해서도 변하지 않는다(즉 첫 번째 단계에서 1x8x8 token, 두 번째 단계에서 1x4x4 token). 이것은 이미지와 비디오에 대해 정확히 동일한 구현을 사용한다는 것을 의미한다(단지 mask unit 크기만 바뀐다.) 우리는 이미지에 대해 학습된 공간적 position embedding을 사용하고 video에 대해서는 학습된 분리된 spatio-temporal position embedding을 사용한다. 이것이 이미지와 비디오 용 Hiera의 차이이다. encoder의 나머지는 spatio-temporal 구조에 완전히 agnostic(무관하다)이다.
Wei et al(2022)처럼 우리는 MAE pretraining 중에 마지막 단계 이전에서만 Q-pooling을 제거한다. 이것은 ViT를 사용하는 이전 작업의 MAE 설정이 최소 수정으로 Hiera에서 작동하기 위한 것이다. 4 단계는 작기 때문에 추가 계산은 작다. 원하면 설계에 의해 Hiera는 pre-training 동안 query pooling을 제거하지 않을 수 있다. 1x8x8 token의 mask unit이 마지막 단계에서 1개의 고유한 token에 해당하기 때문이다.
