
1 Overview
1.1 States and Representations
동적 시스템의 상태는 기본적으로 압축된 설명이며, 이 시스템의 주요 측면을 포착한다. 이러한 측면은 time-varying 또는 fixed 파라미터일 수 있다. 그림 1의 시스템을 가정하자. 수직 평면을 따라 걷는 로봇이다. 이 예에서 시간에 따라 변하는 양은 로봇의 현재 포즈(위치와 방향), 관절 구성 및 속도에 대한 정보로 구성될 수 있다. fixed 파라미터는 로봇의 limb(팔, 다리)의 길이, 각 limb의 무게 또는 관절의 마찰일 수 있다. 이 시스템의 상태에 대해 많은 representation이 가능하다. 예컨대 관절 각도, 속도, 위치 또는 로봇의 포즈 중 어떤 선택을 사용할 수 있다. 또한 이런 수량은 다양한 방법으로 표현될 수 있다. 예컨대 로봇 본체의 방향은 각 축 표현에 대해 Euler 각도나 quaternion으로 주어질 수 있다. 위치는 sptial 또는 극 좌표로 주어질 수 있다. 어떤 representation을 선택할지는 종종 수행할 작업에 따라 다르다. 마지막으로 상태 표현은 학습될 수도 있으며, 이에 대해서는 나중에 다시 다룬다.

동적 시스템의 상태는 정적이지 않고 시간에 따라 진화한다. 보행 로봇의 예에서 로봇의 포즈와 관절 구성은 time-varying이다. 우리는 시간 에서 상태를 로 표기한다. 이런 동적 상태에 대한 일반적인 가정은 Markov property를 따른다는 것이다. 미래 상태는 과거 상태가 아니라 오직 현재 상태에만 의존한다. 다시 말해 상태 은 현재 상태 가 주어지면 과거 상태 에 조건적으로 독립이다.
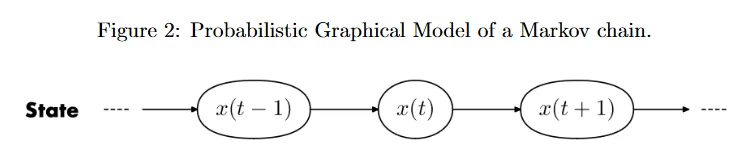
Markov 속성은 미래 상태를 예측할 때 중요한 의미를 갖는다. 이 속성이 성립하면, 미래 상태는 과거가 아니라 현재에만 의존한다. 그러므로 우리는 현재 상태가 주어지면 시스템의 특정한 동적 시스템을 따라 next timestamp에서 상태를 예측할 수 있다. 즉, . 예컨대 상태에 관절의 현재 각속도가 포함되면, 다음 시간 단계에서 관절 각도를 예측할 수 있다. 은 비선형 함수일 수 있고 종종 단순성을 위해 동역학이 시간에 따라 상수라고 가정한다. 이런 시스템을 Markov chain으로 모델링한다. 그림 2는 Markov chain의 조건부 종속 구조를 probailistic graphical model(PGM)으로 시각화한다. 여기서 노드는 확률 변수이고 엣지는 조건부 종속을 나타낸다.
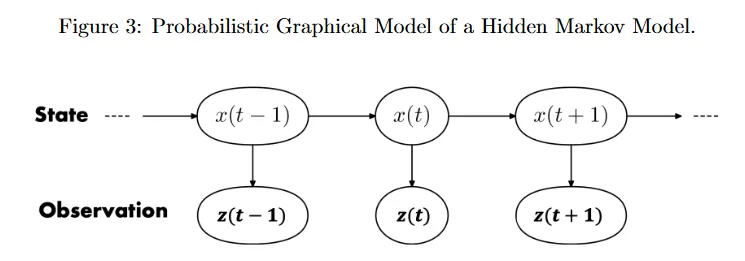
Markov chain은 동적 시스템을 완전히 관찰 가능한 것으로 모델링한다. 즉 상태가 알려져 있다고 가정한다. 실제로는 시간 에서 시스템의 상태를 직접 관찰할 수 없기 때문에 종종 알 수 없다. 우리의 임무는 noisy 센서 관측에서 실제 상태를 추정하는 것이다. 이 절차를 state estimation이라 부른다. 이런 시스템은 부분적으로만 관측되고 상태가 hidden이므로 Hidden Markov Model(HMM)으로 모델링될 수 있다. 우리는 상태 가 Markov 프로세스를 따른다고 가정한다. 또한 시간 에서 관측 가 그 시간의 상태 에만 의존한다고 가정한다. 즉 관측 는 관측 가 주어질 때 모든 이전 상태와 관측에 대해 조건부 독립이다.
이것은 현재 관측 를 예측하는 관찰 모델 이 에만 의존한다는 것을 의미한다. . 이것을 구체적인 vision 예제로 만들자. 우리가 그림 4에서 보여지는 point-of-view를 갖는 자율 주행차라고 하자. 우리는 충돌을 피하기 위해 모든 교통 참가자들의 상태를 알려고 한다. 3d 위치, bounding box(크기), 각각의 속도. 그러나 이 정보는 직접적으로 주어지지 않고 예를 들어 stereo 이미지의 쌍, RGB frame 또는 LIDAR 데이터 같은 센서 관측을 통해 캡쳐된 데이터로부터 추정되어야 한다.

미래의 최적 추정에 대한 강의에서 상태가 어떻게 진화하는지에 영향을 미치는 robot action이나 control input을 이러한 Markov 프로세스에 포함시킬 것이다. 구체적으로 대신 을 갖는다. 여기서 는 시간 에서 로봇이 취한 control input 또는 action이다. 이것은 그림 1에서 보행 로봇의 다리를 움직이는 관절 모터에 보내는 torque command일 수 있고 자동차의 경우에 steering과 throttle일 수 있다. 흥미로운 문제는 다음 best action 를 어떻게 결정할 것인가이다. 이것을 decision making이라 부른다. Markov chain은 Markov Decicison Process(MDPs)로 일반화 되고 Hidden Markov Model은 Partially Observable Markov Decision Process(POMDPs)로 일반화될 수 있다. 이것은 decision making을 형식화하는데 사용된다. 이 주제에 더 관심 있다면 Decision-Making under Uncertainty(https://web.stanford.edu/class/aa228/cgi-bin/wp/) 참조.
1.2 Generative and Discriminative Approaches
관찰에서 상태를 어떻게 추정할 수 있을까? 입력 RGB 이미지(관찰 )에서 객체의 포즈 (상태 )를 추정하는 작업을 고려하자. 6d 포즈는 객체의 3d translation과 3d rotation 모두(6개 파라미터 전체)를 의미한다.
우선 2가지 접근을 high-level에서 설명하고 이 코스의 후반부에 구체적으로 설명한다. 우선 generative model은 관측 와 상태 가 주어지면 결합 확률 분포 를 설명한다. 우리는 베이즈 룰을 사용하여 likelihood 와 prior 로 이 결합 분포를 계산한다(방정식 2 참조). 객체 포즈 추정의 예에서 우리는 에서 객체 포즈 를 샘플링할 수 있다. 이 prior는 공간에서 균등 분포일 수도 있고 또는 이 객체의 가능성 있는 위치(예: 빌딩의 옆이 아닌 도로 위의 자동차)를 포착하는 더 복잡한 분포일 수 있다. 이 포즈 샘플이 주어지면, 우리는 관측 모델을 사용하여 가장 가능한 관찰을 생성할 수 있다. . 즉, 샘플링된 포즈에서 이미지 평면에 대한 객체의 2d projection. 그 다음 는 가설된 포즈 가 주어질 때, 실제 관측 의 likelihood를 와 사이의 거리를 비교하여 제공한다.
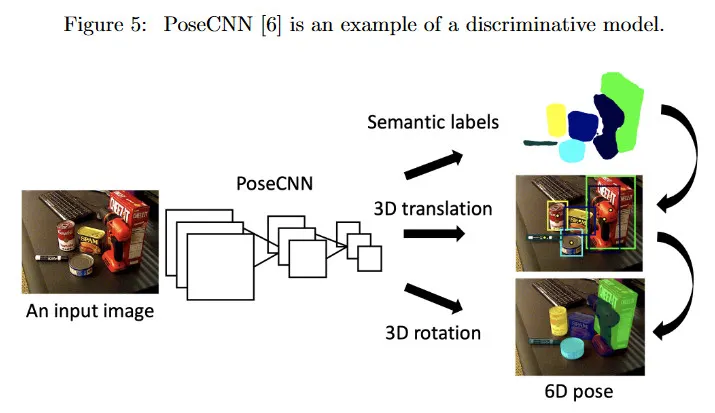
두 번째 discriminative model은 관측 가 주어질 때 상태 의 조건부 확률 를 설명한다. 예를들어 그림 5의 PosCNN과 같은 신경망을 학습하여 입력 이미지 를 가장 가능한 출력 포즈 에 직접 매핑할 수 있다. discriminative와 generative model 사이의 차이에 대한 더 많은 것은 CS229 note(https://cs229.stanford.edu/notes-spring2019/cs229-notes2.pdf) 참조.
2 Representation Learning
2.1 Representations in Computer Vision
Computer Vision에서 representation이라는 용어가 어떻게 사용되는지로 살펴보자. high-level에서 그림 6의 segmentation pipeline을 고려하자. 이것은 해당 pipeline 내의 어느 stage에서든 데이터가 특정한 representation으로 제공된다는 것을 보여준다. 따라서 우리는 representatuion이라는 용어를 보다 명확하게 정의하기 위해 context를 도입한다.
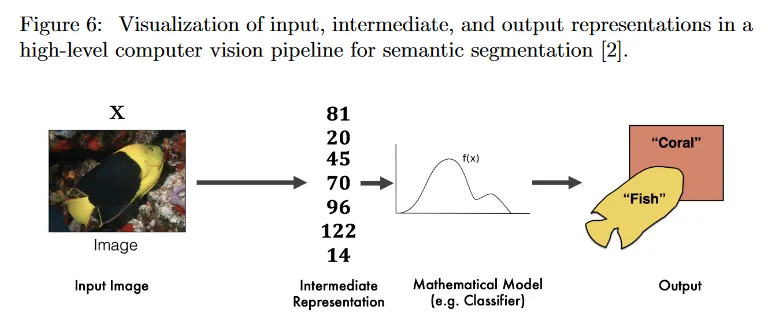
pipeline의 한쪽 끝에는 어떤 센서에 의해 포착된 raw 센서 데이터가 있다. input representation은 raw 센서 데이터 포맷을 설명한다. 그림 6에서 입력은 물고기가 포함된 바다의 3d 장면에 대한 관찰이다. 센서 선택에 따라 raw 센서 데이터는 2d 이미지, depth image, point cloud로 표현될 수 있다. 특정한 형식 내에서도 input representation내에 미묘한 차이가 존재한다. 예를 들어 color vs grayscale, stereo vs monocular, RGB vs HSV 이미지 색상 공간 등. pipeline의 다른 쪽 끝에서 raw 센서 데이터에서 추론된 정보가 고려된 decision-making 작업에 필요한 장면의 high-level 주요 측면을 succinctly(간결하게) 설명하는 output representation으로 제공된다. 우리가 생물학자이고 목표가 만나는 물고기의 수를 세는 것이었다면, 관련 output representation은 출력 측면의 ‘Fish’ 라벨일 수 있거나 또는 물고기의 더 구체적인 종을 지시하는 라벨 일 수 있다. 그러나 우리가 coral reef(산호초)를 탐험하는 드론이었다면, 경로 계획을 통합하는데 유용한 물고기의 6d 포즈와 3d bounding box를 추정하는 것에 더 관심을 가졌을 수 있다. input과 output representation 사이에서 intermediate representation으로 된 입력 데이터가 있다. 이 representation은 일반적으로 고차원 입력 센서 데이터를 요약하는 압축된 저차원 벡터이다. Intermediate representation은 input representation에서 제공된 입력 데이터를 압축한다. 그 다음 intermediate representation으로 제공된 데이터는 output representation에서 관련된 양을 유도하는데 사용된다.
이 지점에서 자연스러운 질문은 다음과 같다.
1.
representation이 decision-making에 핵심이므로, 좋은 representation에 대한 것은 무엇인가? Bengio 등은 좋은 representation을 위한 다음의 요구사항을 제안했다.
•
representation은 compact 해야 한다. 즉, 최소한이면서도
•
explanatory(설명력)해야 한다, 즉, 다양한 입력 구성을 표현하고 포착하기 위해 충분히 표현력이 있어야 한다.
•
representation은 disentangled(분리)이어야 한다. 즉, 입력 데이터 변화의 다양한 explanatory factor(설명 요인)들이 독립적으로 표현되어 이러한 factor들이 서로 독립적으로 변할 수 있음을 반영해야 한다.
•
representation은 hierarchical 해야 한다. 이는 더 추상적인 개념을 덜 추상적인 개념으로 설명할 수 있게 하여 특징 재사용을 가능하게 하고 계산적 효율성을 높인다.
•
궁극적으로, 이 representation은 downstream 추론, 예측 또는 decision-making 문제를 더 쉽게 만들어야 한다. 따라서 representation의 품질은 downstream performance로도 정량화 될 수 있다.
2.
실제로 intermediate와 output representation을 어떻게 얻을 수 있을까? 이것은 다음 섹션에서 논의된다.
2.2 Traditional CV and Interpretable Representations
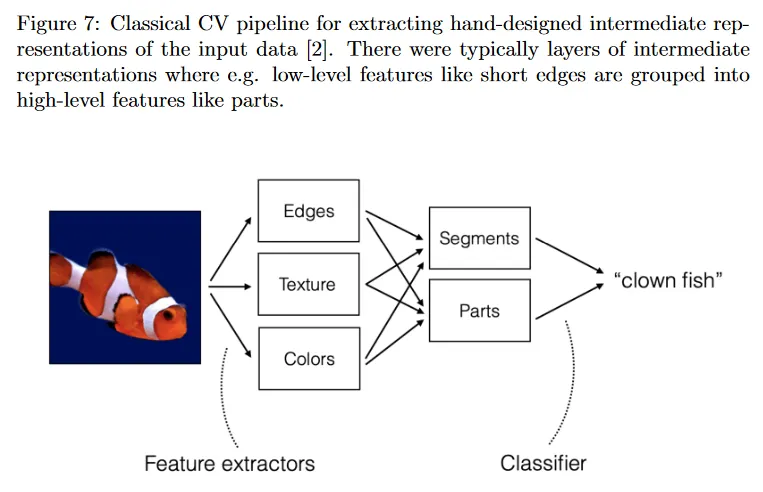
전통적인(2012년 이전) computer vision pipeline의 high-level 시각화가 그림 7에 보여진다. 입력 데이터는 특정한 input representation으로 제공된 입력 데이터에서 추출된 hand-crafted feature의 결합으로 intermediate representation으로 압축된다. 이러한 feature(descriptor)의 특정한 선택은 유연하고 작업별로 다를 수 있다. 예컨대 물고기 몸에 있는 특정한 스트라이프 또는 디자인이 다른 물고기나 해양 생물과 구별될 수 있다고 믿으면 이러한 특정한 패턴을 활용하여 raw 입력 데이터의 intermediate representation을 형성하기 위해 엣지와 색상을 추출할 수 있다. 그림 7에서 예로 output의 representation은 클래스 라벨이다. 이 클래스 라벨을 추론하기 위해 intermediate representation은 학습되거나 더 manually-defined 휴리스틱에 기반한 classifier에 공급된다. 간단한 예로 이미지에서 색상의 histogram에 오렌지색과 흰색이 많은 양을 포함한다면, 그 이미지는 아마도 clownfish일 가능성이 더 높다고 말할 수 있다. 많은 전통적인 문헌은 종종 이미지 프로세싱과 필터링 방법에 기반하여 새로운 feature extractor를 개발하는데 초점을 맞추었다. 특정 방법은 이 수업의 범위를 벗어나지만, 이 문서의 끝에 추가 읽을 거리를 제공한다. 전통적인 특징 추출 방법의 주요 이점은 interpretable representation이다. 이러한 방법은 손으로 설계되었기 때문에 특정한 output representation이 선택된 이유를 쉽게 설명할 수 있다. 이는 법률이나 의료와 같은 높은 위험이 따르는 downstream 작업에 특히 중요할 수 있다. 그러나 단점은 이러한 feature extractor를 고안하는 과정이 tedious(지루한)이고 엄청난 양의 시간과 도메인 전문적인 지식을 필요로 한다는 것이다.
2.3 Modern CV and Learned Representations
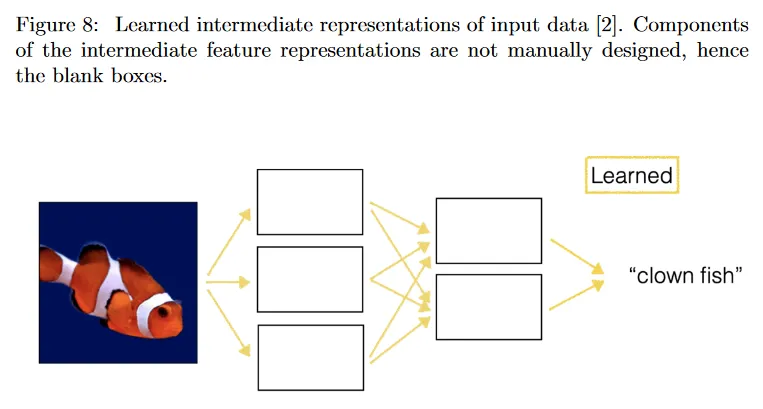
현대 Computer Vision 방법(2012-현재)는 그림 8에 표현된 것처럼 manually 추출된 feature를 learned intermediate representation으로 교체한다. 이 목적을 위한 가장 일반적인 모델 아키텍쳐 중 하나는 이미지에 적용되는 convolutional filter 레이어로 구성되는 Convolutional Neural Network(CNN)이다. 이러한 필터는 일반적으로 입력 데이터의 학습된 intermediate representation을 제공하는 라벨링된 학습 데이터를 사용하여 학습된다. 학습된 representation은 후속 분류기에 대해 필수적인 정보를 제공하는데 있어 이전의 hand-designed feature 보다 훨씬 더 강력한 것으로 드러났다.
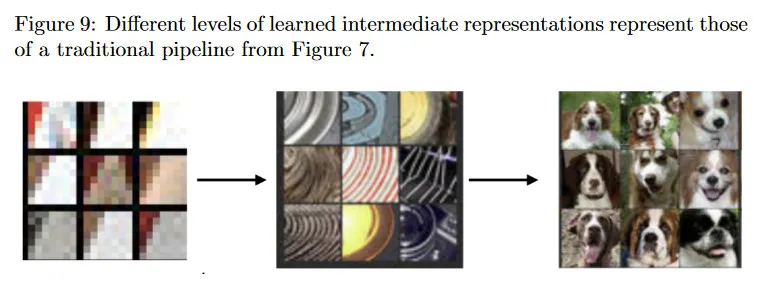
학습된 representation이 이미지 분류기와 같은 downstream 작업에서 더 높은 정확도를 보이지만 단점은 전통적인 representation의 해석 가능성이 부족하다는 것이다. 몇 가지 방법들이 학습된 representation을 해석하여 왜 그렇게 잘 수행되는지, 그리고 어떻게 개선하는지를 이해하려고 한다. Zeiler와 Fergus는 ImageNet에서 학습된 CNN에서 각 레이어에 대해 filter를 가장 강하게 활성화 시키는 특정 이미지 패치를 분석했다. 그들이 발견한 것은 그림 9에서 보여지는 학습된 representation이 그림 7에 보이는 전통적인 추출된 feature(edge, texture, body part 등)과 유사하다는 것이었다.
입력 데이터의 학습된 intermediate representation을 이해하기 위한 또 다른 접근은 이를 저차원 공간에 투영하고 plot하여 해석하는 것이다. 이것을 달성하기 위한 한 가지 인기 있는 기법은 tSNE이다. 이것은 저차원 임베딩과 원래의 고차원 representation 사이의 결합 확률의 KL-divergence(데이터 유사도에 기반하여)를 최소화하여 고차원 intermediate representation을 차원을 축소한다. 우리는 동일한 클래스에서 데이터 포인트가 그림 10에서 보이는 것처럼 지리적으로 서로 가까운 곳에 위치하기를 기대한다. tSNE를 사용하여 신경망이 동일한 라벨을 갖는 이미지들이 시각적으로 유사하다는 것을 실제로 학습했는지 확인할 수 있다.

2.4 Unsupervised and Self-Supervised Learning
전통적인 supervised learning 방식에서 학습 데이터셋 의 개 데이터 포인트에 대한 loss 함수(이미지 분류 정확도 또는 포즈 추정)를 최소화하도록 특정한 추론 작업에 대한 모델을 학습할 수 있다. 여기서 는 주어진 input representation(예: 이미지 또는 3d point cloud)에서 번째 데이터 포인트이고 는 output representation(예: 객체 카테고리 또는 6d 포즈)에서 라벨이다. 실제로 데이터는 풍부하지만 라벨은 획득하는 것은 비싸고 전문적인 지식이 필요하다. 라벨 없이 데이터에서 의미 있는 representation을 학습할 수 있을까?
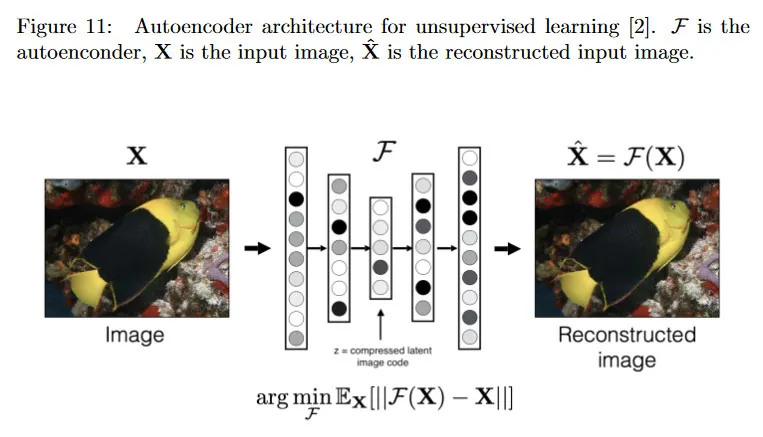
그림 11의 autoencoder 아케텍쳐를 고려하자. autoencoder의 목표는 입력 이미지를 완벽하게 재구성하는 것을 학습한다. 이러한 encoder는 이것을 얼마나 잘 달성하는지는 reconstruction loss로 측정되며, 이것은 입력 데이터 와 출력 사이의 거리로 정의된다. 둘 다 동일한 representation. 여기서 입력 데이터의 intermediate representation 는 저차원 벡터이고 그림 11에서 네트워크의 중간에 위치한다. 직관적으로 네트워크 2번째 절반인 가 에서 입력을 재구성할 수 있으면 가 입력 데이터의 유용하고 정보가 풍부한 압축 버전이라고 기대할 수 있다. 이러한 이유로 를 bottleneck이라고 부른다.
우리는 autoencoder가 입력 이미지(이것을 라벨 자체로 볼 수 있다) 외에 외부 라벨을 요구하지 않기 때문에 unsupervised learning을 수행한다고 말한다. 비슷한 맥락에서 self-supervised learning은 입력의 일부를 masking한 후에 출력 라벨로 사용한다. 예컨대 그림 12에서 보이는대로 이미지의 대각선 아래 모든 픽셀을 입력으로써 유지하고 대각 위의 모든 픽셀을 출력으로 유지한다.
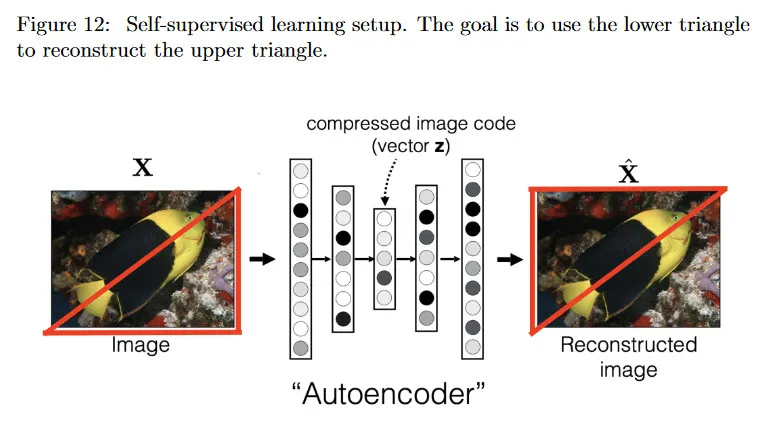
아래 부분이 주어지면 작업은 이미지의 위 부분을 재구성하는 것이다. 이 작업을 달성하기 위해 네트워크가 여전히 입력 이미지에 관한 의미 있는 representation을 학습할 것이라고 희망한다. 이것은 다음의 방식으로 어느 정도 경험적으로 입증되었다.
라벨링 되지 않은 많은 양의 데이터로 학습된 autoencoder가 주어지면, 네트워크의 첫 번째 절반(이를 encoder라 부른다)을 사용하여 압축된 intermediate representation 를 얻을 수 있다. 그 다음 적은 양의 라벨링된 데이터만으로 intermediate representation 의 위에 분류기를 학습시켜 출력 출력 representation을 정확하게 예측할 수 있다. 왜냐하면 autoencoder가 이미 입력에 대한 의미 있는 representation을 학습하는 중요한 작업을 수행했기 때문이다.
