
•
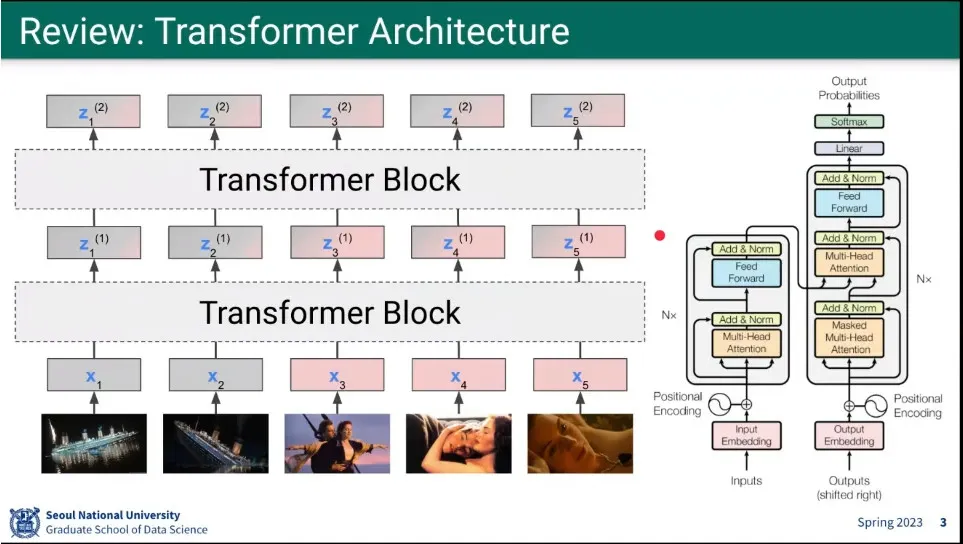
Transformer review
•
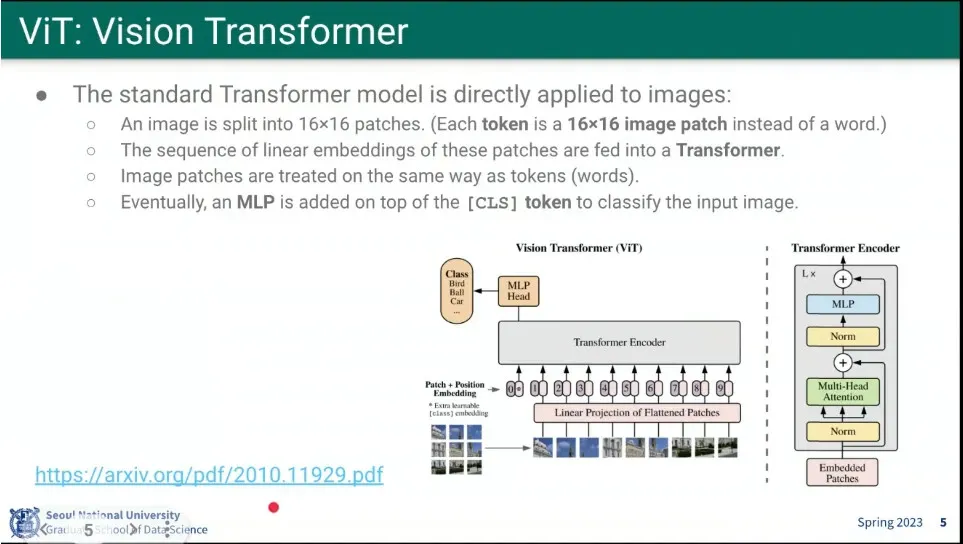
Transformer를 Vision에 적용한 모델이 ViT
◦
이미지를 16x16 patch로 분할한 후 Transformer를 적용함.
•
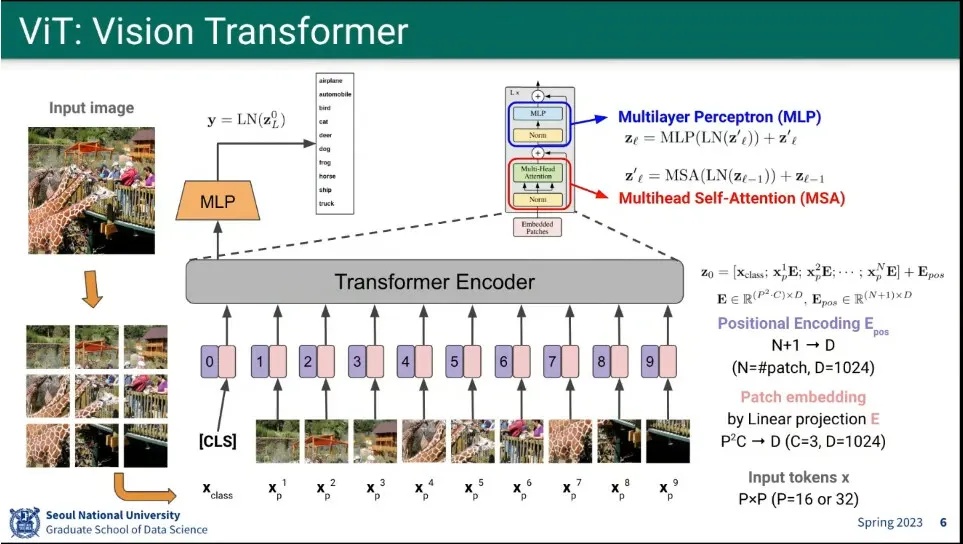
ViT는 이미지를 patch로 쪼갠 후에 그것을 linear로 변환 시킨 후에 positional encoding 더하고, 그렇게 만들어진 것을 transformer의 encoder에 input으로 넣는다.
•
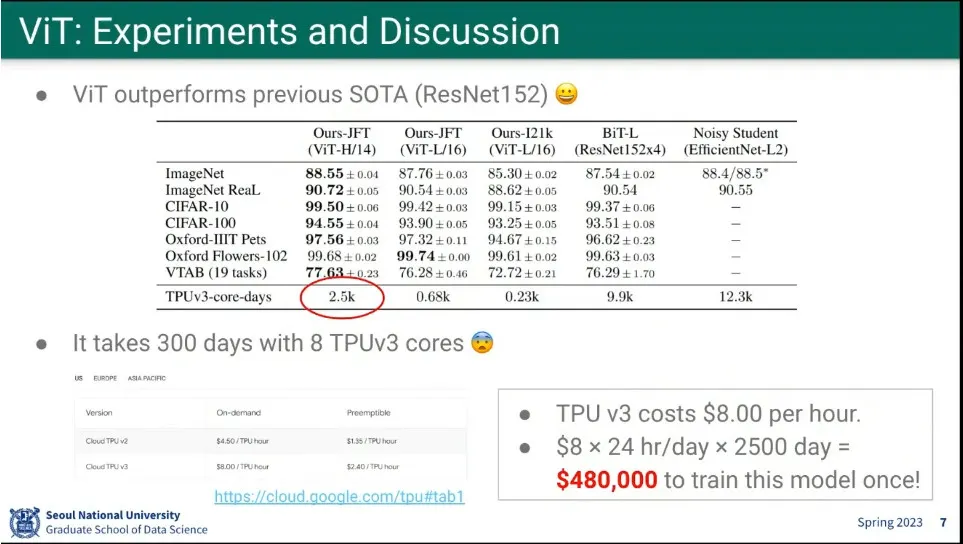
Resnet 보다 성능이 좋았다고 함.
•
하지만 모델 훈련하는데, 큰 비용이 듬.
•
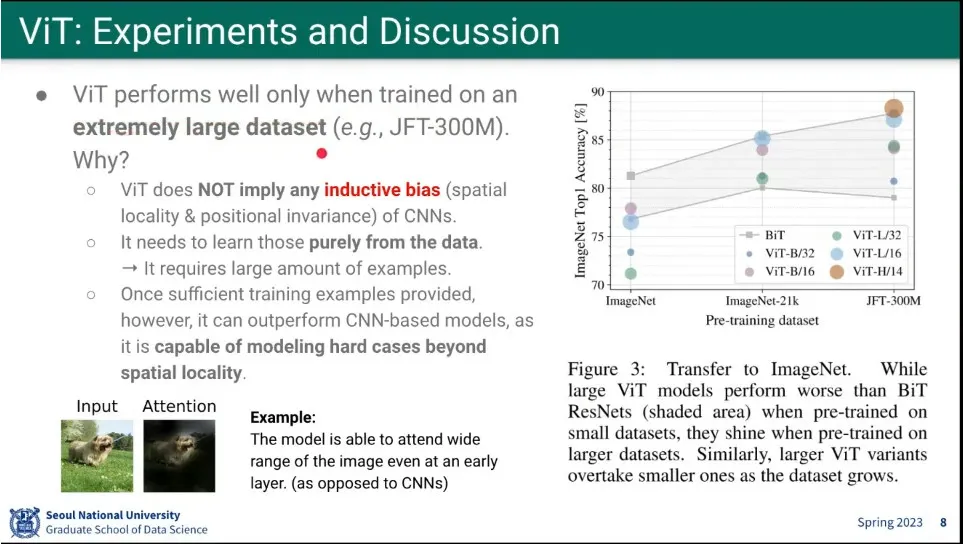
ViT는 아주 큰 데이터셋에서만 기존 모델들 보다 잘 동작 했음.
◦
ViT는 spatial locality를 활용하지 않음. spatial locality를 모델이 스스로 깨우쳤다고 하는데, 그게 가능하려면 아주 큰 데이터셋이 필요함.
•
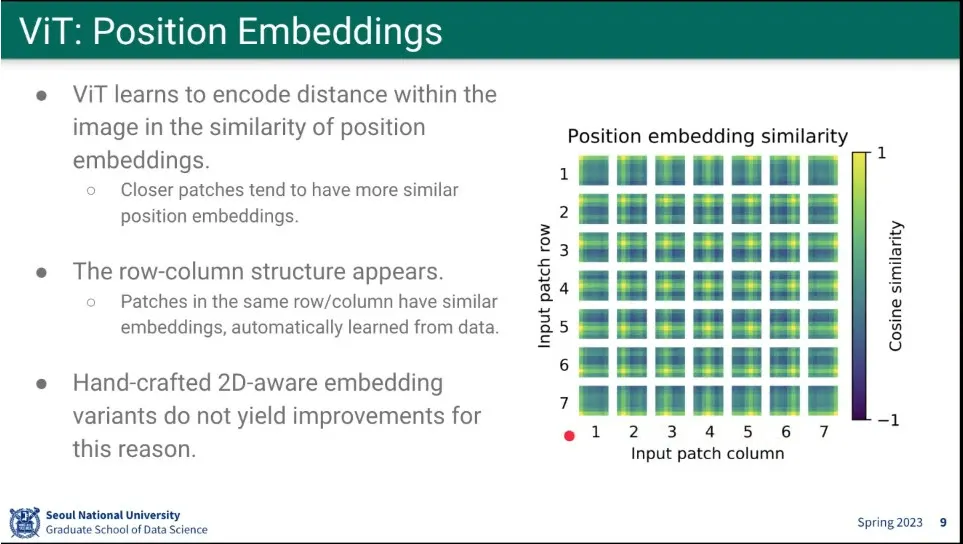
ViT의 position embedding 결과
◦
2D 구조를 주지 않아도 스스로 배우더라

•
DeiT는 데이터 효율적인 ViT 모델.
•
CNN 모델을 teacher로 쓰고, vit를 student로 만들어서 학습시킴
◦
teacher가 만든 분포를 vit가 모사하도록 함. 이게 distillation

•
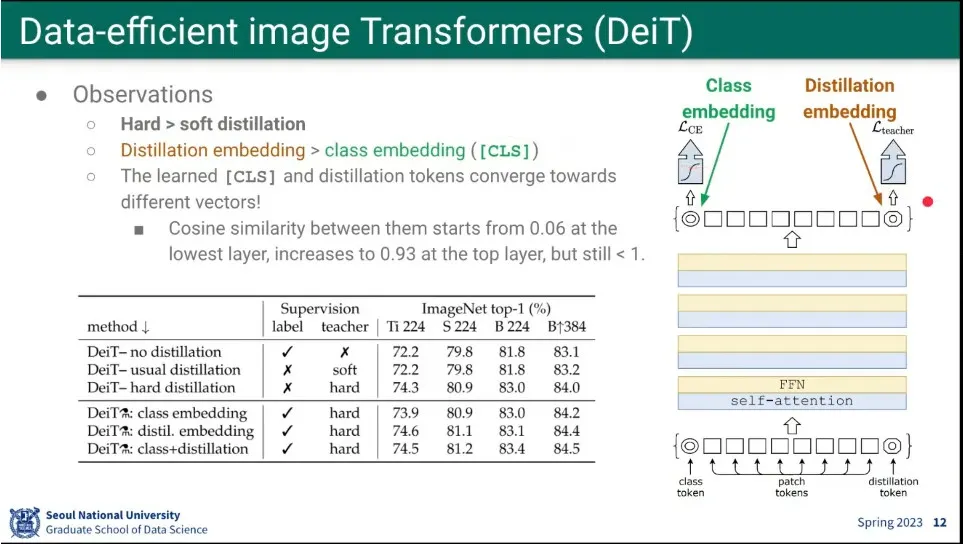
ViT가 이미지 앞에 class token을 추가한 것처럼, 마지막에 distillation token을 주고, transformer를 돌린 후에, distillation token의 결과를 teacher가 만든 분포와 비교해서 loss를 줌.
◦
loss에는 class token이 만든 cross entropy loss와 teacher와의 KL 다이버전스 loss를 더해서 구함.
◦
다른 방법으로는 분포가 아니라 student와 teacher의 정답을 비교한 hard distillation을 시도해 봄.
•
흥미롭게도 soft distillation보다 hard distillation의 결과가 더 좋았음.
•
또한 distillation embedding 결과가 class embedding 결과보다 중요했음.
•
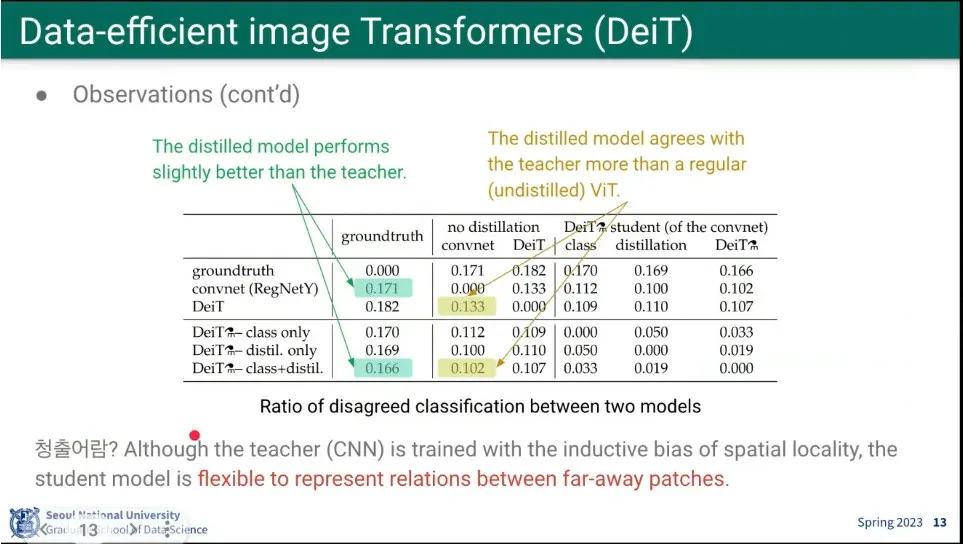
결과적으로 CNN이 ViT 보다 못했지만, ViT가 CNN을 넘어서더라. 안 하는 것보다 더 빨리 배우더라. 청출어람.

•
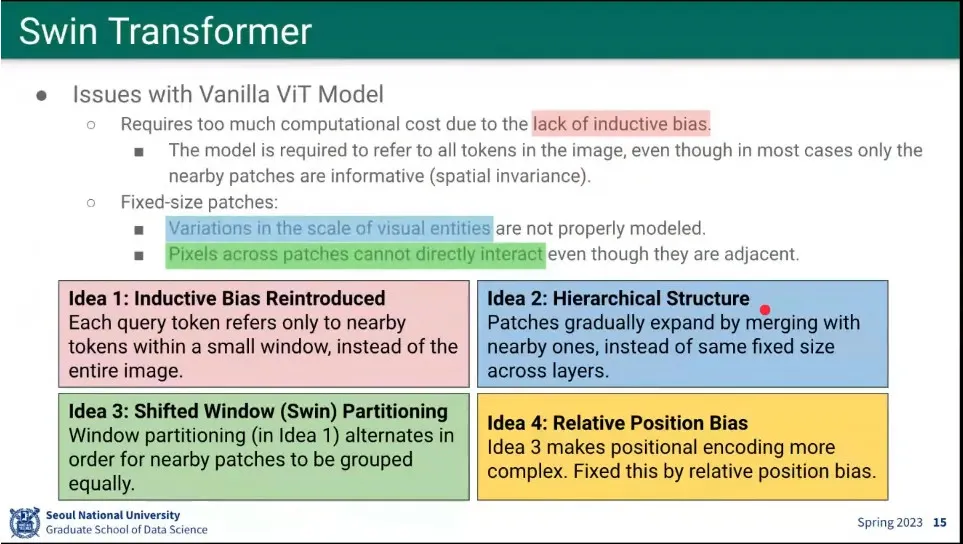
ViT의 이슈
◦
계산 비용이 큼
◦
고정된 크기로 patch를 만드는게 자연스럽지 않음.
•
Swin Transformer는 ViT를 다음과 같이 개선 함
◦
원래 ViT에는 inductive bias가 없었는데, 가까운 것만 보도록 추가해서 계산량을 줄임.
◦
fixed size patch가 애매하므로, fixed size를 hierarchy로 만들어서 합쳐지도록 함.
◦
patch를 shifted 시키면서 partitioning 함.
◦
Relative position bias를 추가 함

•
pixel를 4x4로 더 작게 쪼개고, 대신 MxM patch로 window를 만들고 같은 window 내의 것들 하고만 attention 하도록 함
•
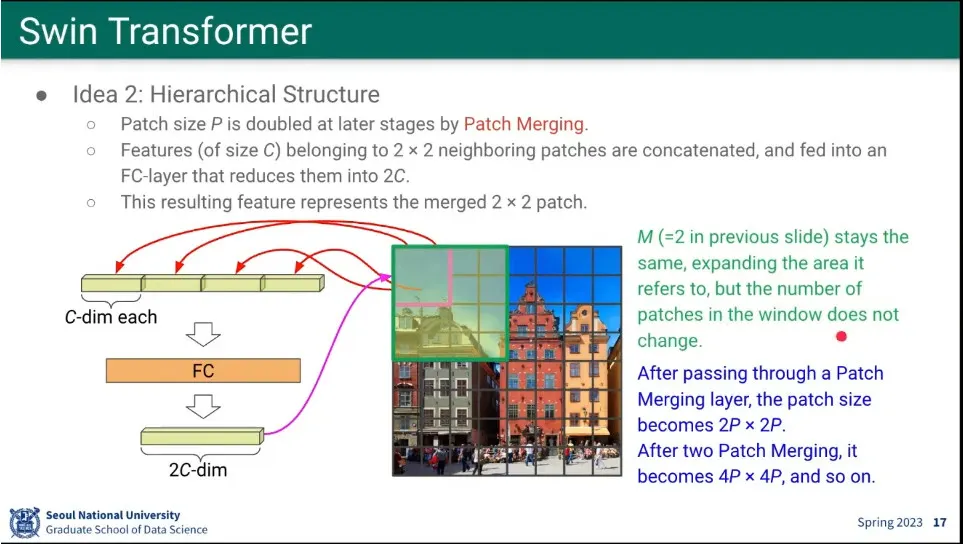
Hierarchical로 Patch merging을 함.
◦
patch를 merging 하면서 점점 크기를 키우면서 커진 것에 대해 다시 attention 수행
•
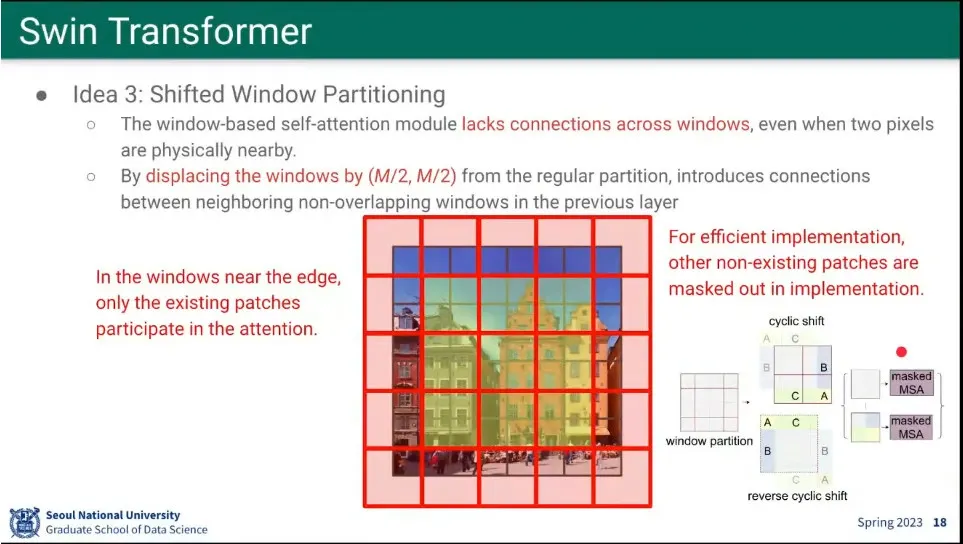
window를 patch 절반씩 움직이면서 attention 함.
•
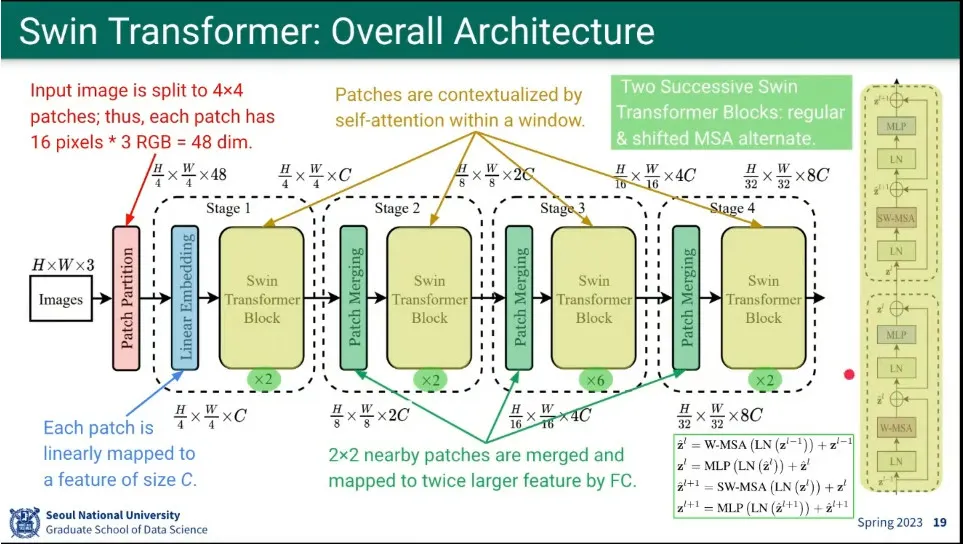
Swin Trasnformer 아키텍쳐
◦
patch를 merging 하면서 tansformer를 돌림.
◦
Swin Transformer Block은 Shifted Window Partitioning을 하기 때문에 짝수번 반복한다.

•
window를 잘라서 attention 하다보니 절대적인 position encoding을 하기 애매해서 상대적인 position을 추가 함.

•
Swin Transformer가 기존 ViT에 비해 계산량이 많이 적다.
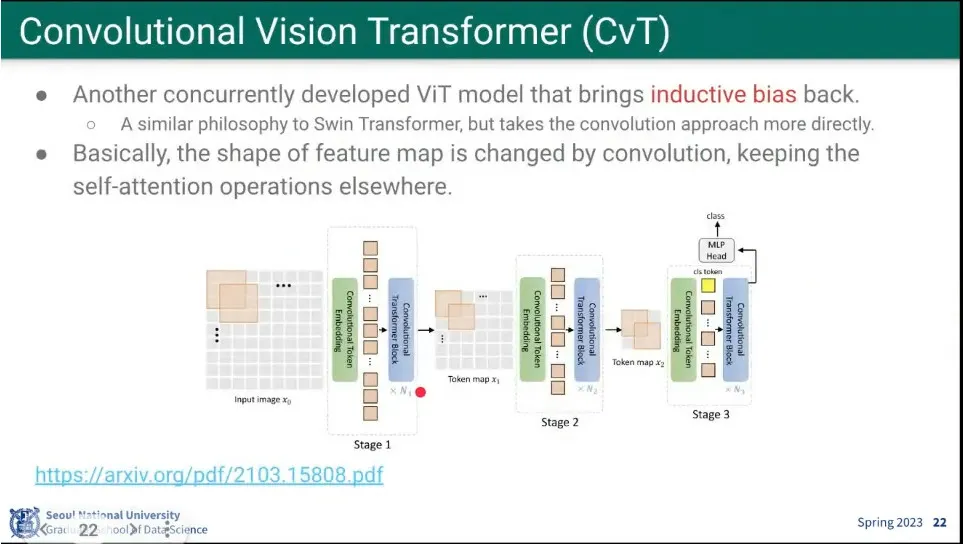
•
CvT는 Swin Transformer와 비슷한 철학으로 만들어짐.
◦
이미지 전체를 보지 말고 주위 것만 보자.
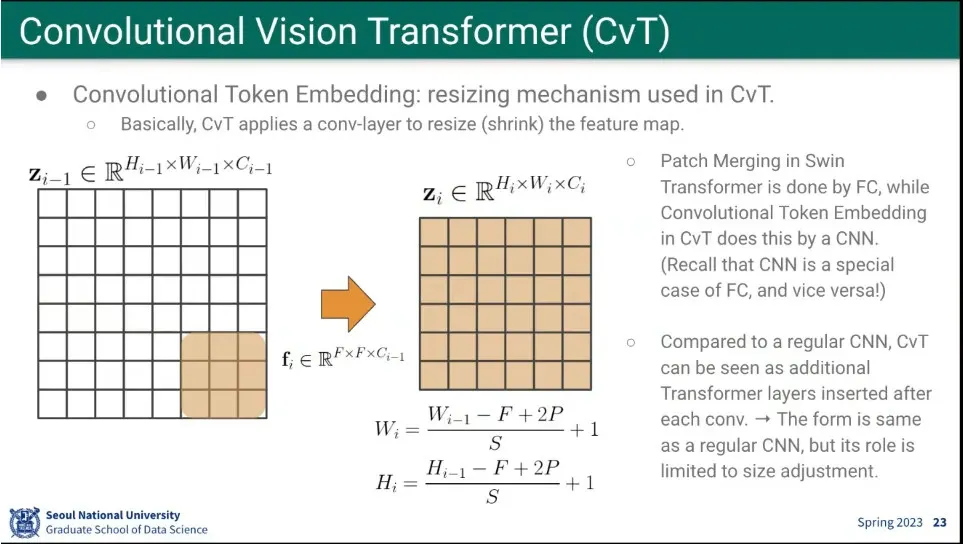
•
window를 나누지 않고, 그냥 conv 연산을 함.
◦
fully-connected는 convolution의 special case이다. (물론 그 반대도 성립)
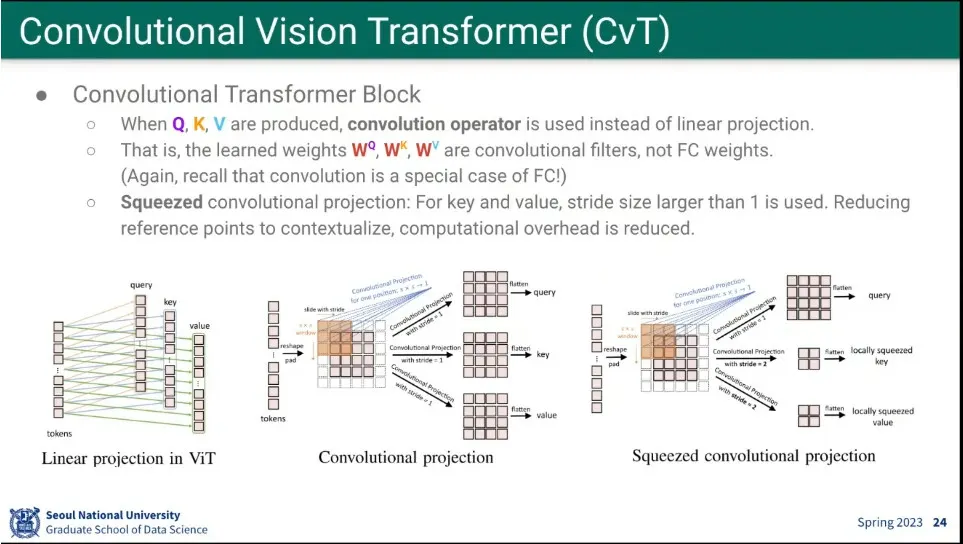
•
Q, K, V Attention 연산도 fully-connected가 아니라 그냥 conv 연산을 함. stride도 사용.
◦
(이게 stable diffusion에도 나옴)
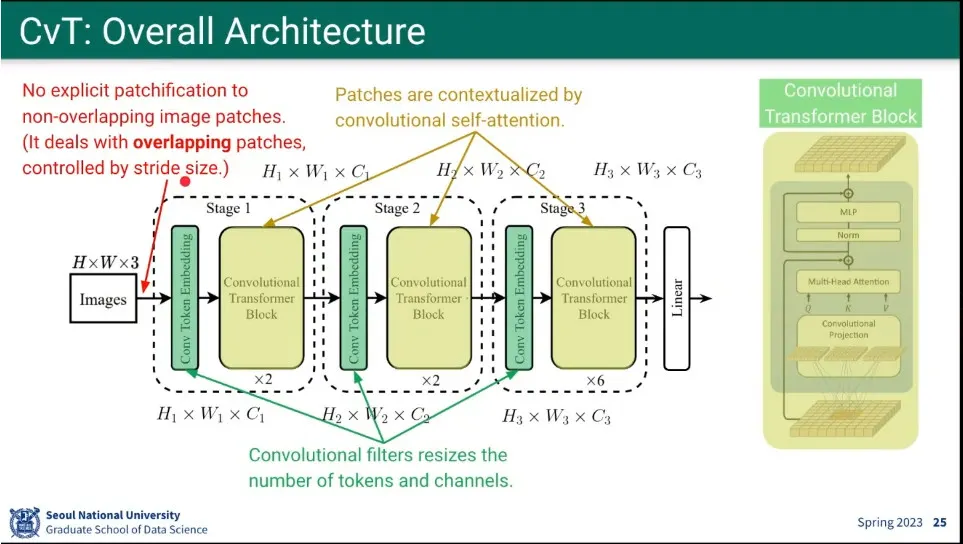
•
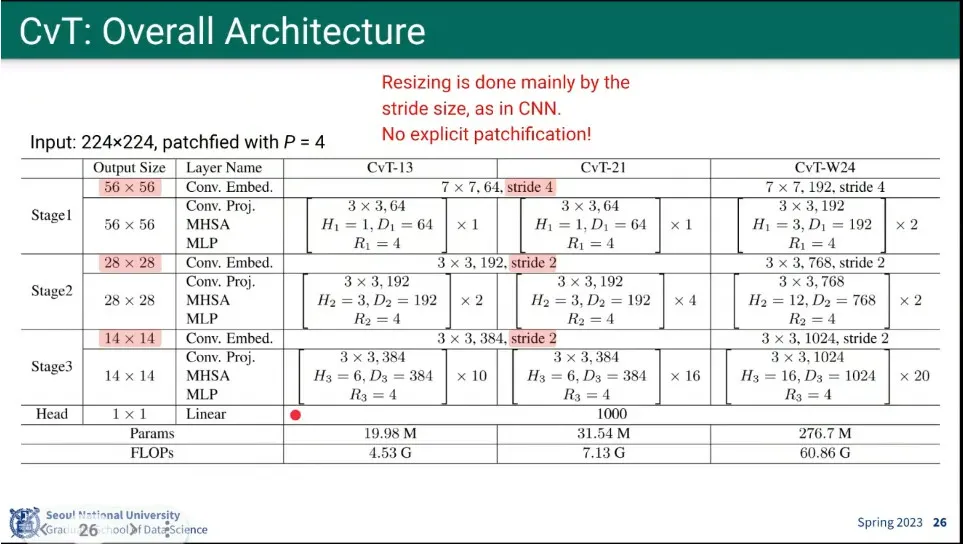
CvT의 아키텍쳐
◦
Transformer인데 연산을 그냥 convolution을 하는게 핵심
•
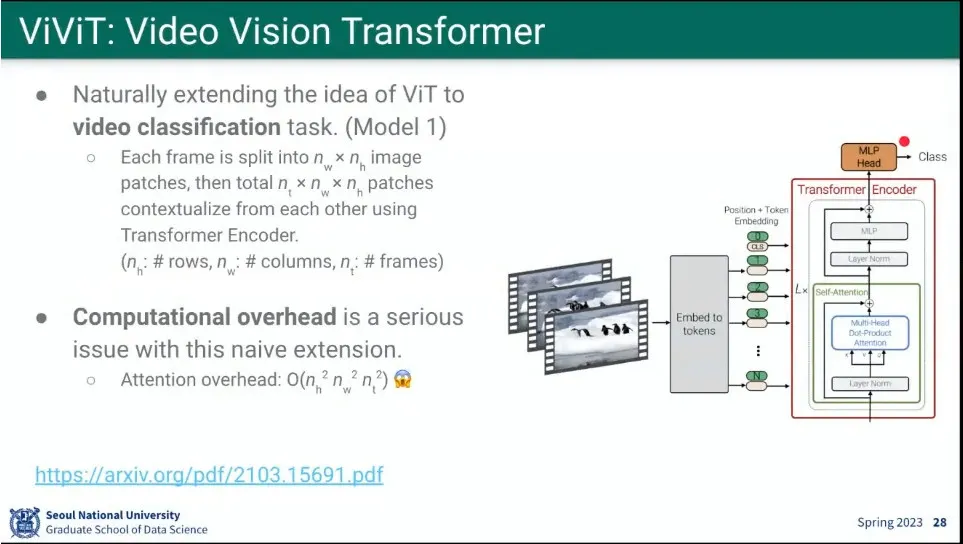
ViViT는 비디오용 ViT. 4개 모델을 만듦.
◦
첫 번째 모델은 ViT를 video 분류 문제에 그대로 사용 함.
•
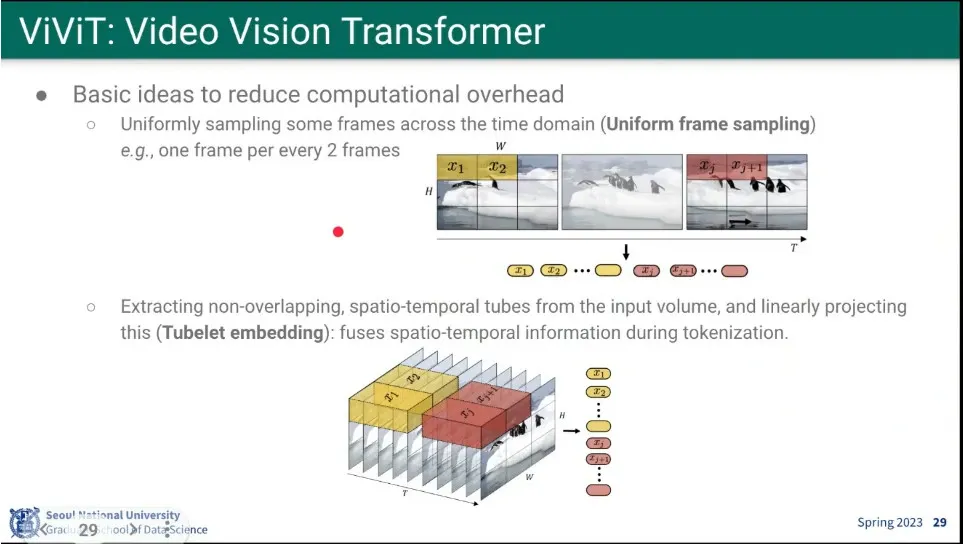
계산량이 너무 많아서 그걸 줄이기 위해 frame을 줄여서 쓰는 방법을 시도해 봄.
◦
인접한 frame끼리 합쳐서 처리해 봄
•
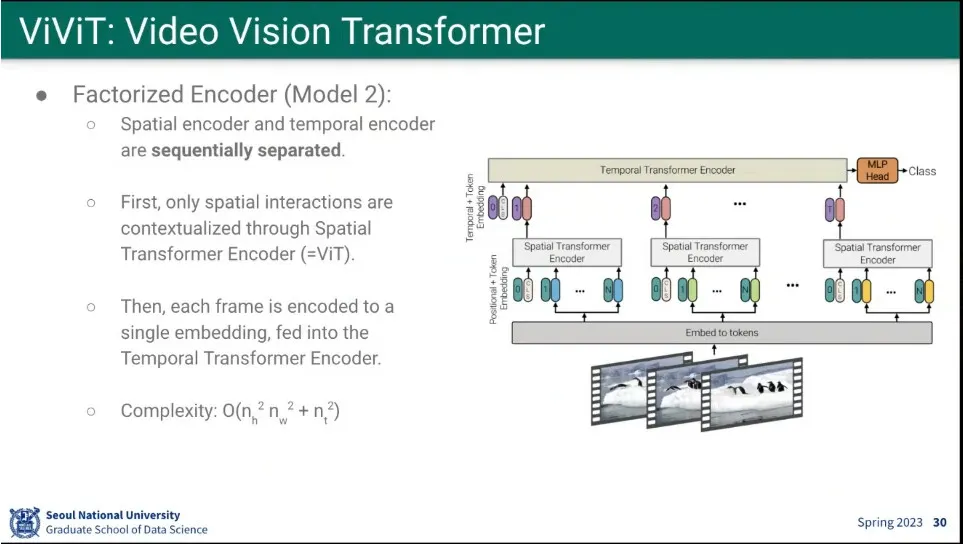
두 번째 모델이 Factorized 모델
◦
Spatial과 Temporal을 2단계로 나눠서 처리 함.
◦
Spatial은 ViT를 그대로 씀. 그 결과를 모아서 Temporal로 Transformer를 돌림.
◦
최초 모델보다 연산 시간을 줄임
•
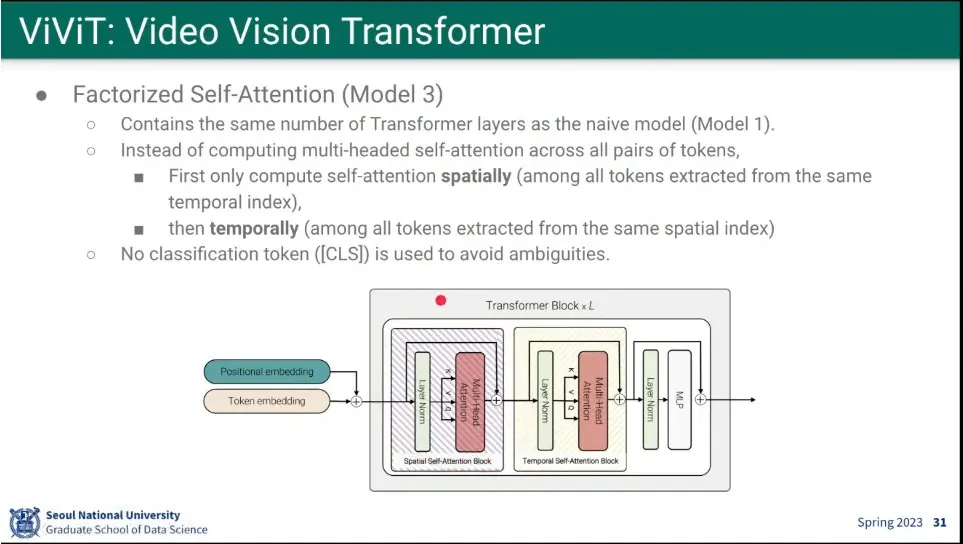
세 번째 모델은 Factorized Self-Attention 모델
◦
transformer block 안에서 spatial attention과 temporal attention을 나눠서 함.
•
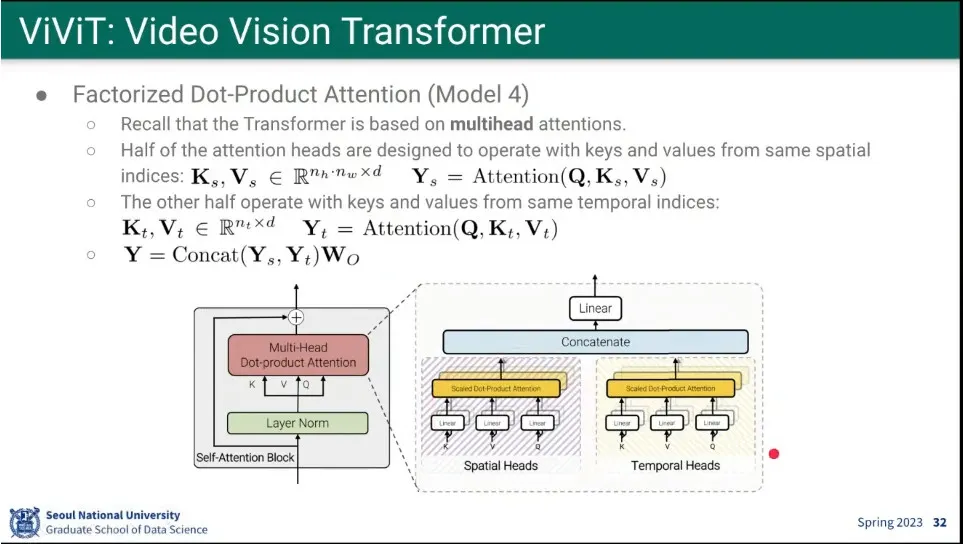
네 번째 모델은 Dot-Product Attention 모델
◦
Multi-Head를 Spatial과 Temporal로 나눠서 처리
•
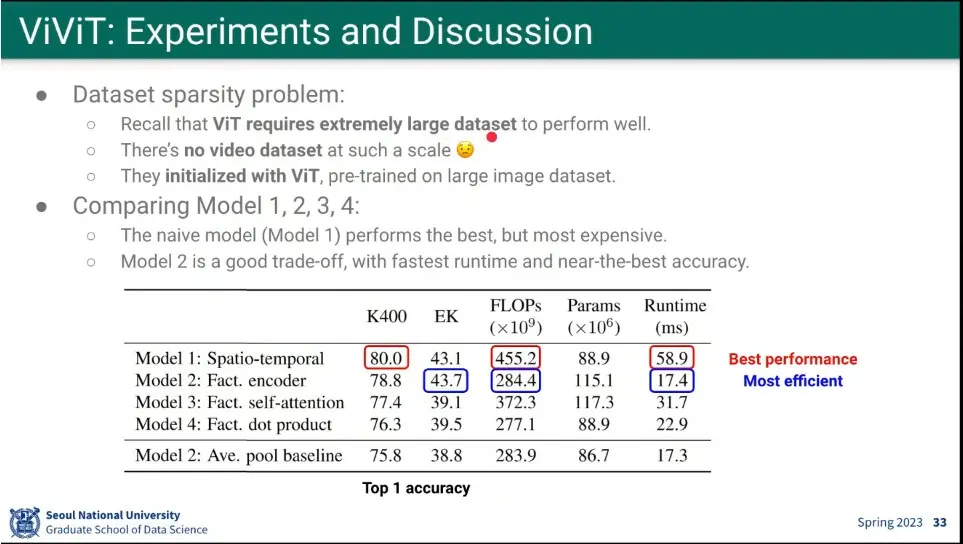
4가지 모델을 돌린 결과
◦
성능은 첫 번째 것이 좋았지만, 계산 효율성은 2번째 모델이 좋음
•
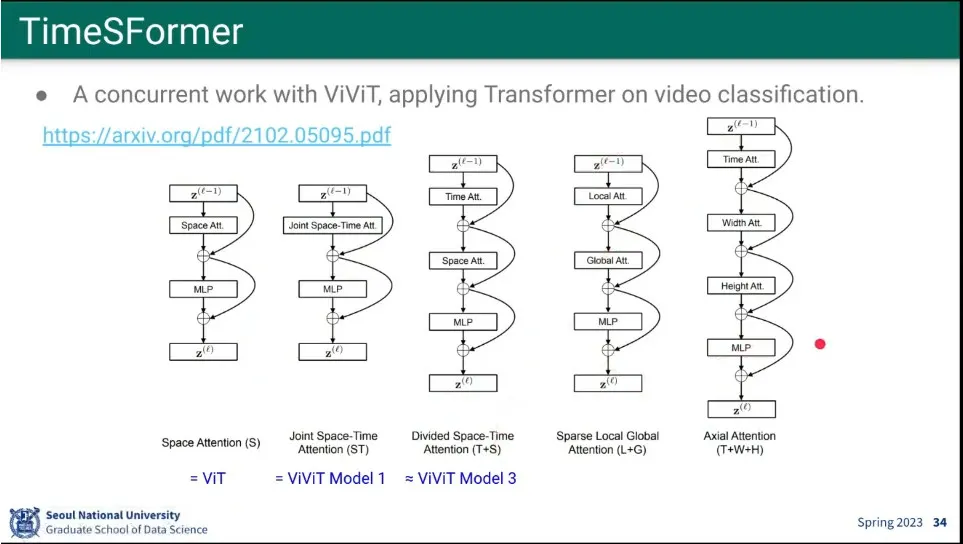
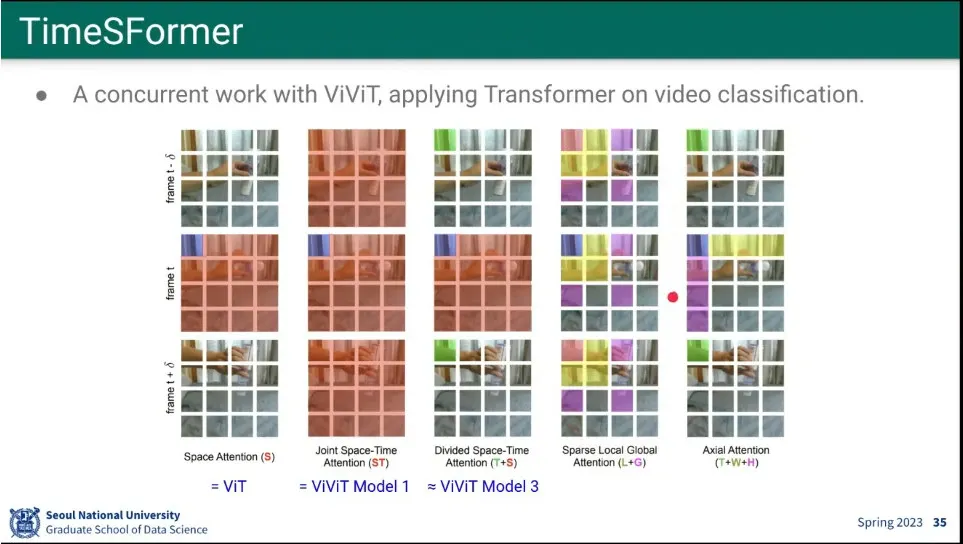
ViViT랑 비슷한 시기에 나온게 TimeSFormer
◦
5개 모델을 제시했는데, 가장 앞의 것은 ViT고, 그 뒤의 2개는 ViViT의 1, 3번째 모델과 비슷 함.
◦
다른 부분도 있는데, 성능은 별로 다르지 않음.
•
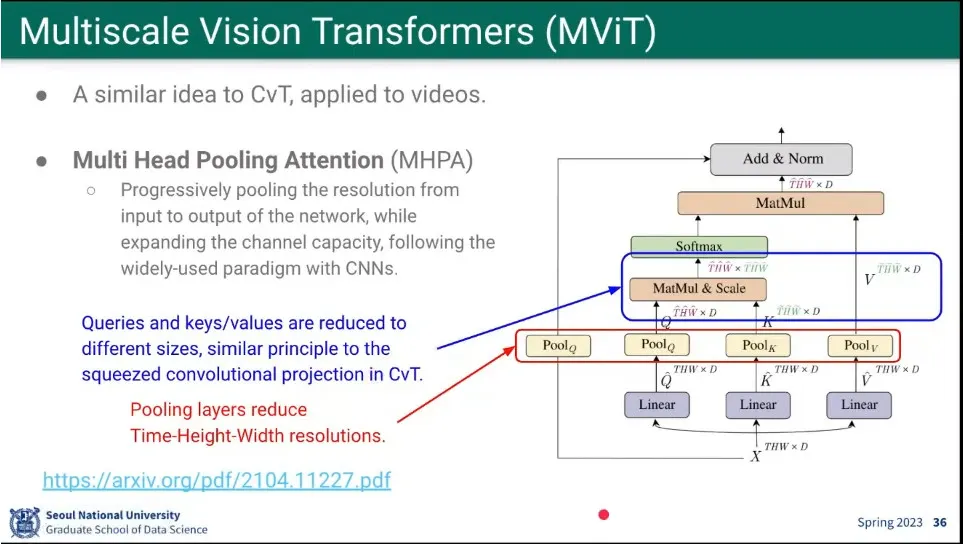
MViT는 CvT와 비슷한데, conv를 안 하고 계산량을 줄이기 위해 Multi-Head Pooling Attention을 함.
•
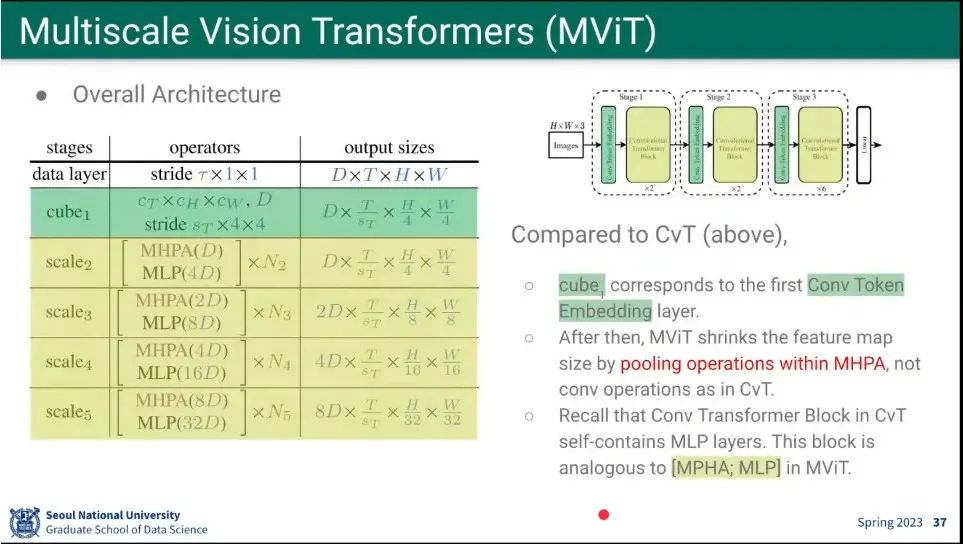
CvT와 비슷한데, 시간 축이 추가 됨.
•
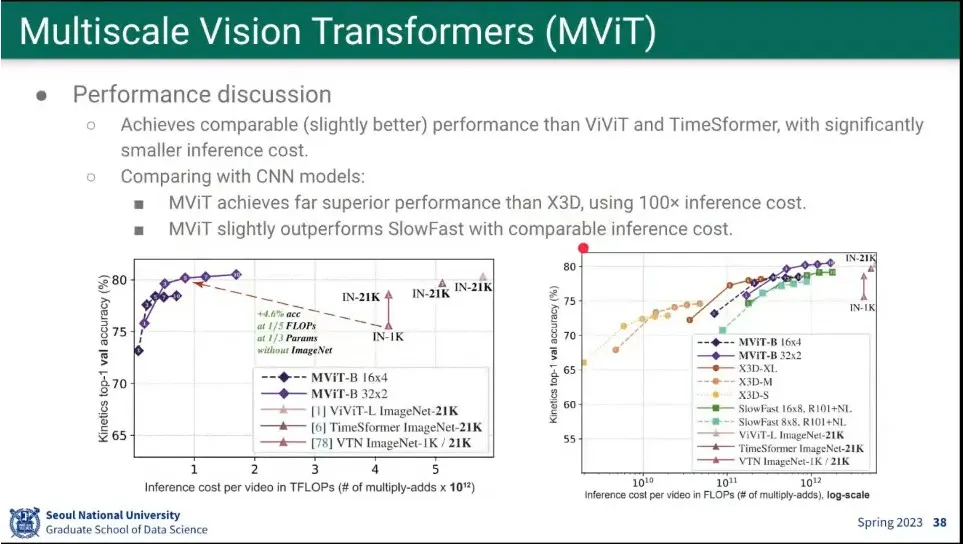
기존 모델들보다 성능이 더 뛰어남.
◦
가벼운 모델들보다는 성능이 뛰어나고, 무거운 모델들에 비해서는 성능은 비슷한데 더 가볍다.

•
논문들 참고
