
•
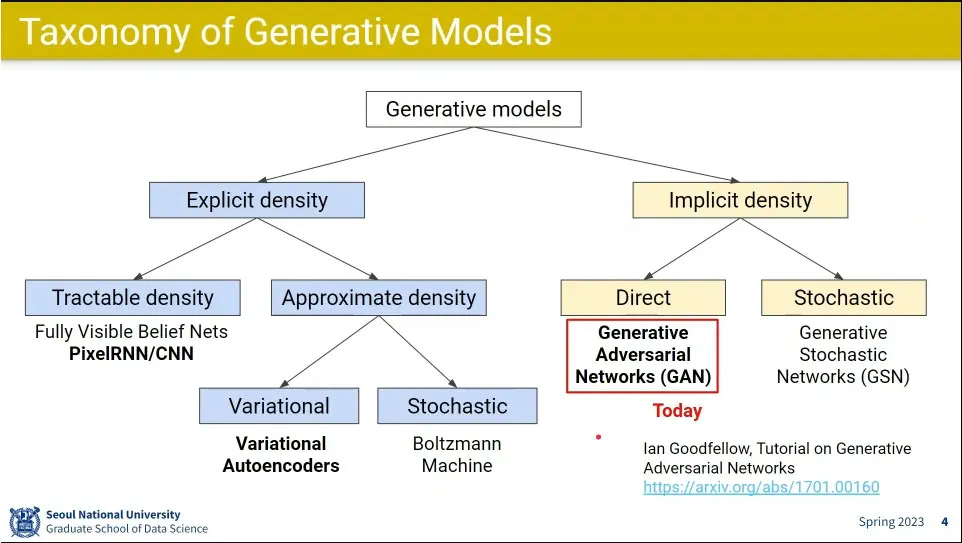
Implicit 생성 모델의 대표가 GAN

•
GAN의 발전 모습

•
GAN으로 만든 그림을 43만 달러에 팜
•
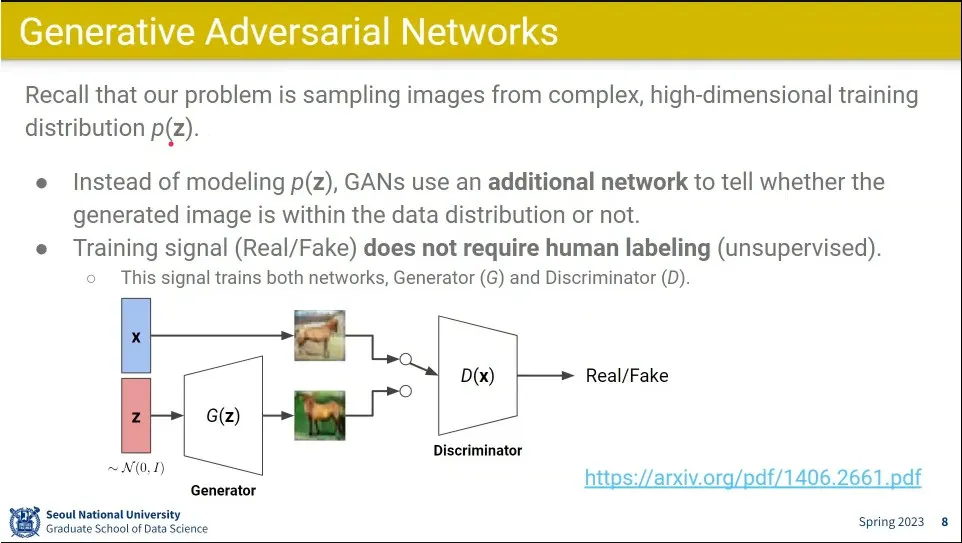
GAN은 explicit 모델과 달리 를 직접 생성하지 않음.
◦
Generator와 Discriminator를 나누고, Discriminator가 Generator가 만든 이미지와 진짜 이미지를 구별해 내는 구조

•
Discriminator의 loss
◦
앞 텀은 진짜 이미지에 대한 것이고, 뒤쪽 텀은 가짜 이미지에 대한 것.
◦
앞 텀은 진짜 이미지를 맞췄을 때 1이 나오고, 뒤쪽 텀은 가짜 이미지를 맞췄을 때 1이 나오게 해서 전체 합을 maximize 함.
◦
실제 loss로 사용할 때는 앞에 마이너스를 붙여서 minimize 함
•
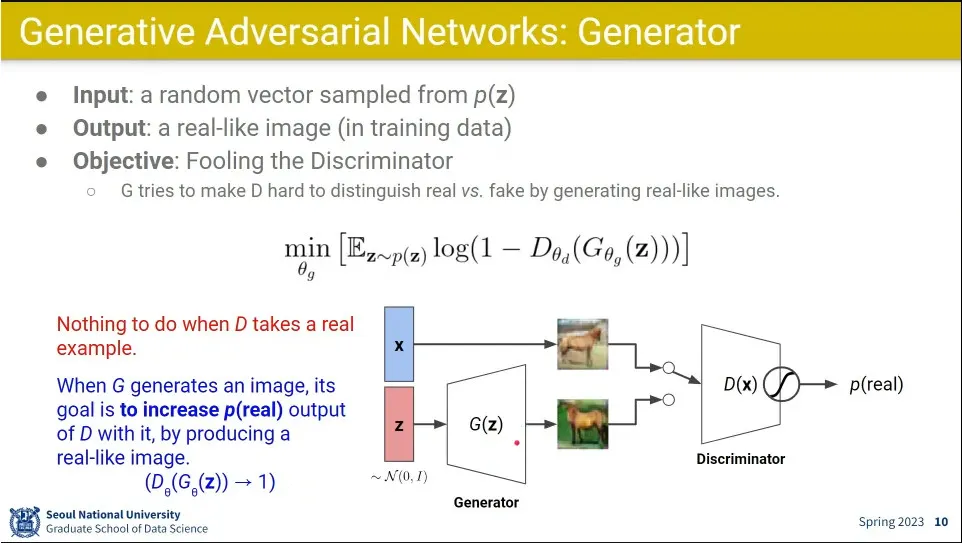
Generator는 loss를 Discriminator를 통해서만 받음.
◦
discriminator의 뒤쪽 텀을 쓰는데, 그 값을 maximize 해야 하는 discrimination 와 달리 그 값을 minimize 하게 만들어서 generator와 discriminator가 경쟁하게 만듦.

•
Discriminator 입장에서는 loss를 maximize 해야 하기 때문에 Gradient Ascent 하고, Generator 입장에서는 loss를 minimize 해야 하기 때 문에 Gradient Descent 함.
•
그 둘의 수식을 하나로 합친게 가장 위의 식. min, max 해야하는 파라미터가 다름
◦
이런걸 min-max 게임이라고 함
◦
다만 이렇게 되면 학습이 매우 까다롭다고 함.

•
generator은 매번 하고, discriminator는 k번에 1번만 한다.
◦
generator이 더 어렵기 때문
•
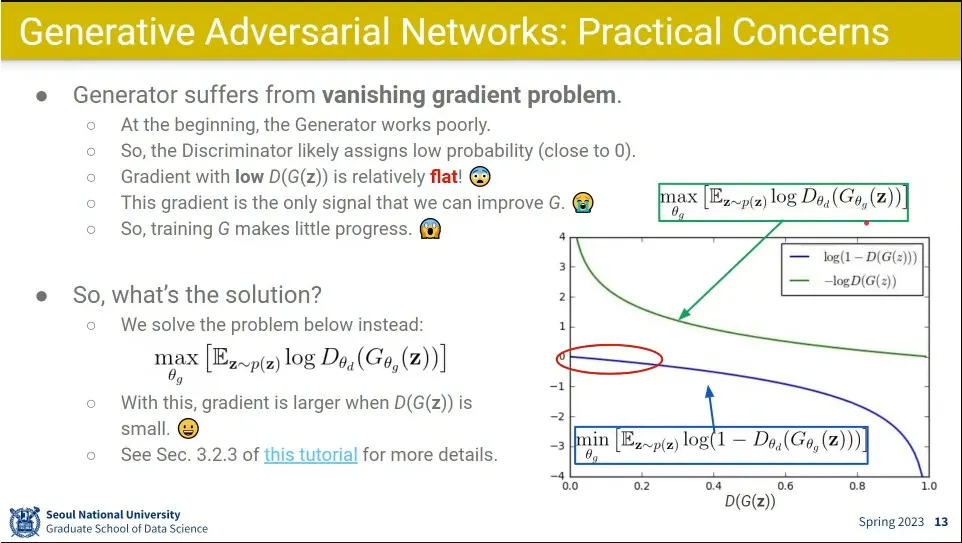
GAN은 vanishing gradient 문제가 심함.
◦
처음에는 그림을 잘 못 그리니까 generator의 loss가 작게 나옴. 그래서 초반에 학습이 잘 안 됨.
◦
이 문제를 해결하기 위해 처음에는 loss를 바꿔서 maximize 하는 식을 사용 함. 이러면 초반에 기울기가 급격해서 학습이 잘 됨.

•
처음 GAN에서는 Generator와 Discriminator를 Fully-connected로 만들었음. 그 다음에 conv, deconv 사용함.
◦
그래도 이미지처럼 생긴게 나오긴 함.

•
GAN 학습의 가장 문제점은 학습 시키기가 더러움.
◦
설명 가능성도 떨어짐.
•
그런 이슈들을 개선한게 DCGAN
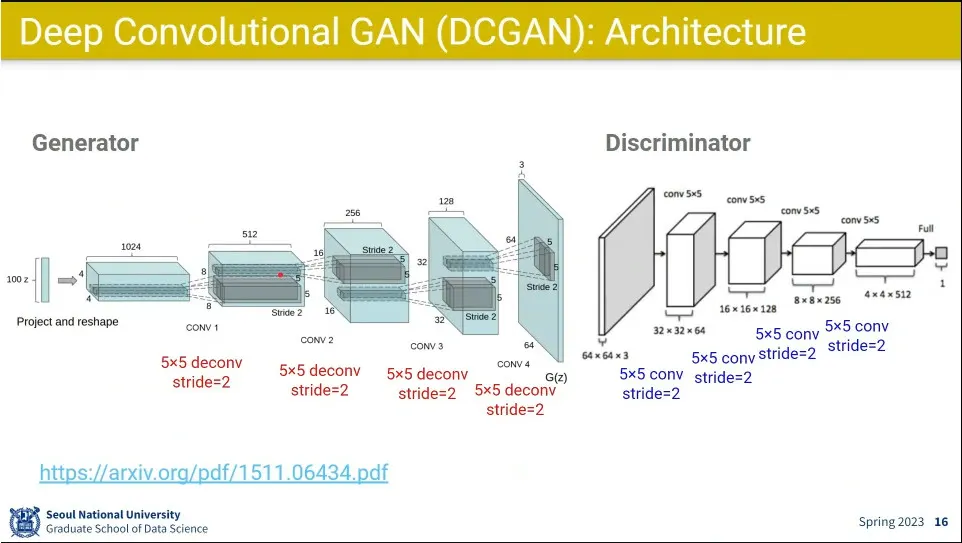
•
Generator는 Deconv 하면서 사이즈를 키움.
•
Discriminator는 일반적인 conv처럼 사이즈를 줄여가며 진짜인지 아닌지 판별하게 함.

•
신기하게도 안경 쓴 남자에서 남자를 빼고, 여자를 더해주면 안경 쓴 여자들이 나오더라

•
이미지가 서서히 변하는 모습도 보임.

•
loss가 Generator와 Discriminator가 싸우는거라서 점점 줄어드는 경향이 안 나옴.
◦
실제 이미지 퀄리티는 계속 좋아짐.
•
어디까지 학습을 해야 하는지 판별이 어려움.
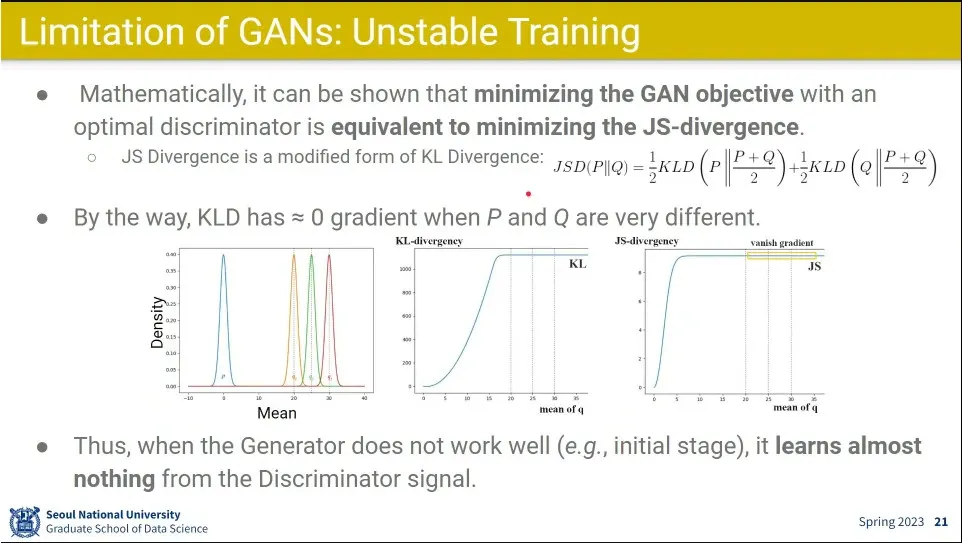
•
GAN의 loss를 줄이는 것은 JS Divergence를 minimize 하는 것과 동일한 문제임.
◦
JSD는 KL Divergence를 두 개의 분포에 대해 각각 divergence를 구한 뒤 평균을 내는 것.
◦
그래서 사실 둘은 같은거로 봐도 됨
•
확률 분포 P, Q가 매우 다르면 그 두 분포의 KL Divergence의 Gradient는 0에 가깝게 나오게 됨.
◦
위 중간의 2, 3번째 그래프를 보면 분포가 멀면 기울기가 0이 나옴.
•
그래서 KLD, JSD를 minimize하는게 학습에 별 도움이 안 됨. 초반에는 두 분포의 거리가 매우 크므로.

•
Mode Collapse는 GAN의 가장 큰 한계이고 현재까지도 해결이 안 된 문제.
◦
generator가 쉬운 mode에 대해서만 답을 내고, discriminator는 어쨌건 답이니까 ok 함. 이래서 학습이 안 됨.
◦
숫자 생성 예제에서 generator는 숫자 1만 생성하게 됨.
◦
분포를 좀 넓게 하게 해줘도 4개 정도까지만 됐음.

•
Wasserstein GAN은 KL Divergence를 안 쓰고 Earth Mover(EM) distance를 쓰게 함.
◦
cross entropy를 쓰지 않고 log를 없애서 output에 bound가 없어짐. 0-1 사이의 값이 아니라.
◦
대신 무한대가 나오진 않게 output에 c 값으로 clipping 해 줌.
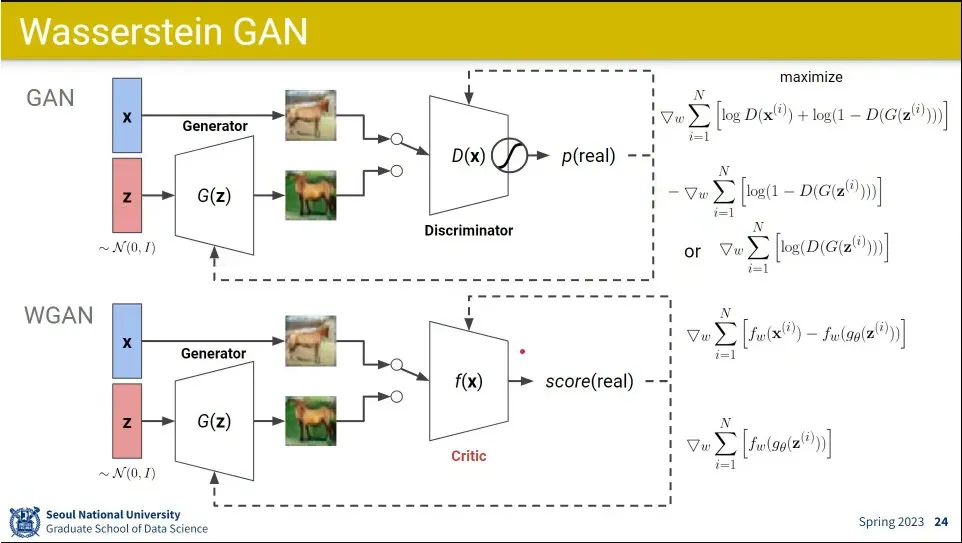
•
WGAN은 기존 GAN에 대해 Discriminator을 Critic으로 바꿈. 확률이 아니기 때문에.
◦
loss에 log를 없앰
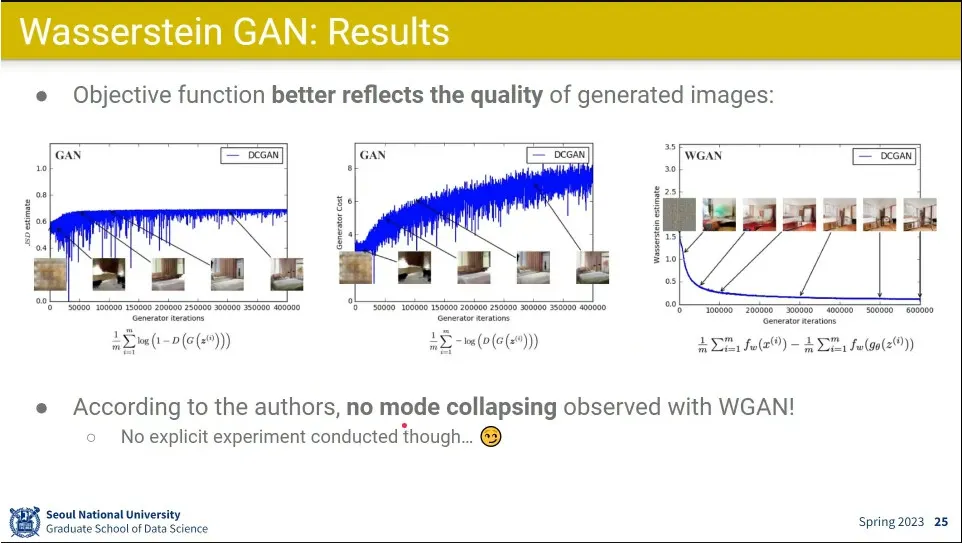
•
0-1 사이 값으로 싸우지 않기 때문에 학습이 좀 완화 됨.
•
그러나 여전히 mode collapsing 문제는 해결 안 됨.
•
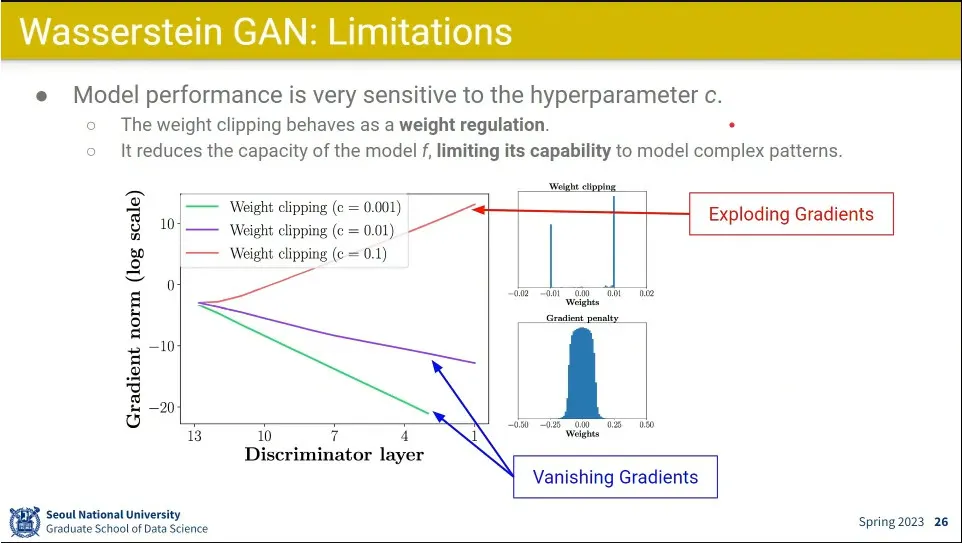
WGAN은 c를 얼마로 잡아주느냐가 문제가 됨
◦
적절한 c를 찾는게 어려움. 조금만 작으면 vanishing gradient가 발생하고, 조금만 크면 exploding gradient가 발생함.
•
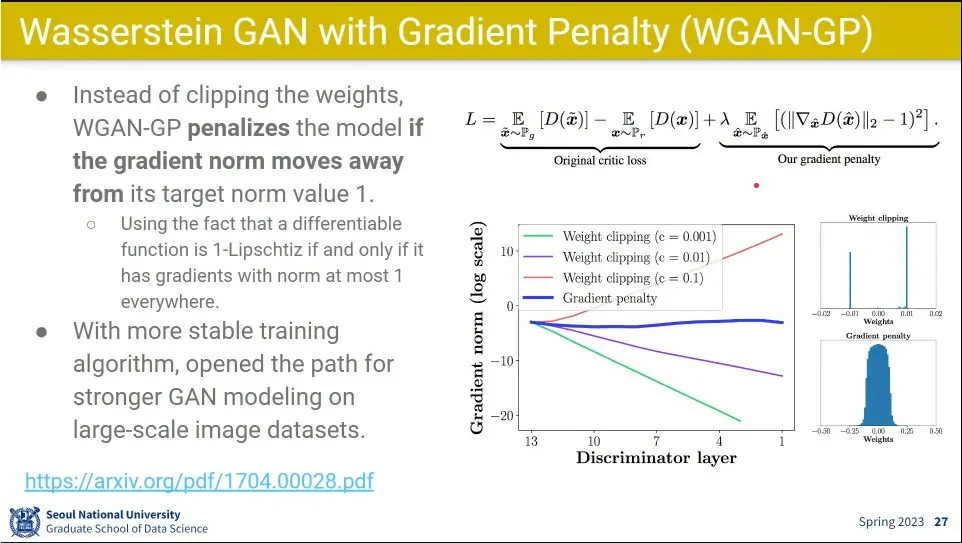
WGAN-GP는 WGAN을 개선해서 넘어야 하지 않을 값 사람이 c로 정해주지 않고, loss 함수에 regularization으로 동작하는 penalty 텀을 줘서, 대신 그걸 조절해 주는 하이퍼파라미터 를 줌.
◦
그랬더니 잘 되더라.

•
결과

•
Image Translation은 이미지의 semantic를 유지하면서 style을 바꾸는 문제

•
크기를 유지하고 style만 바꾸는게 Pix2pix
•
input을 2장을 pair로 넣어줌.
◦
discriminator는 domain이 제대로 되었는지를 판단.
◦
generator는 짝에 맞는 이미지를 생성
•
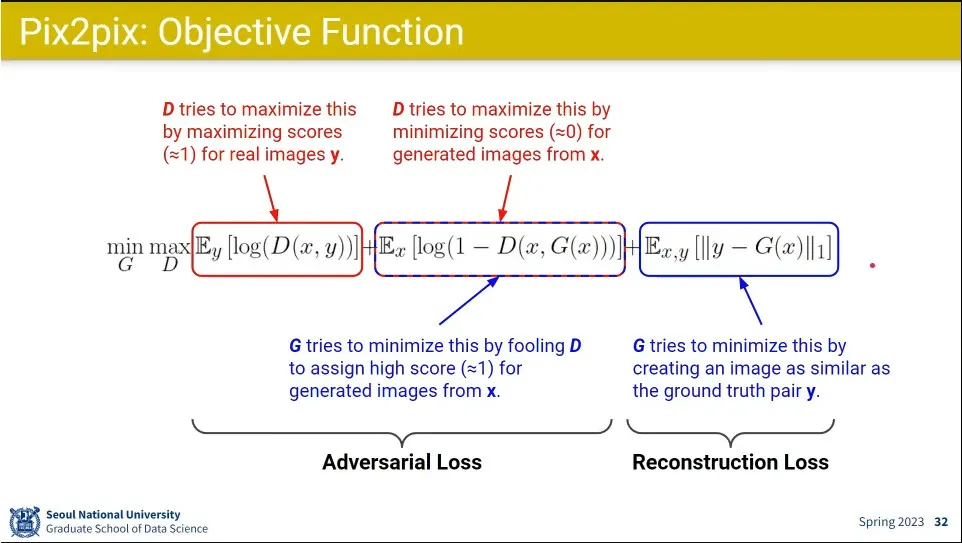
loss의 앞 2개 텀은 기존의 GAN과 동일.
◦
discriminator는 진짜를 진짜로 맞추는 것, 가짜를 가짜로 맞추는 것을 loss로 받고
◦
generator는 가짜를 진짜로 맞추는 것에 대해 loss를 받고
◦
추가로 마지막 텀으로 생성한 이미지가 실제 domain pair가 맞도록 하는 loss를 받아서 style에 맞는 이미지를 생성하도록 함. ← 이 텀이 없으면 아무 신발이나 그려내게 됨.

•
Pix2pix 상세
◦
Generator로 UNet을 쓰고, Discriminator을 PathGAN을 씀.
◦
patch 단위로 쪼개서 판별 함.
•
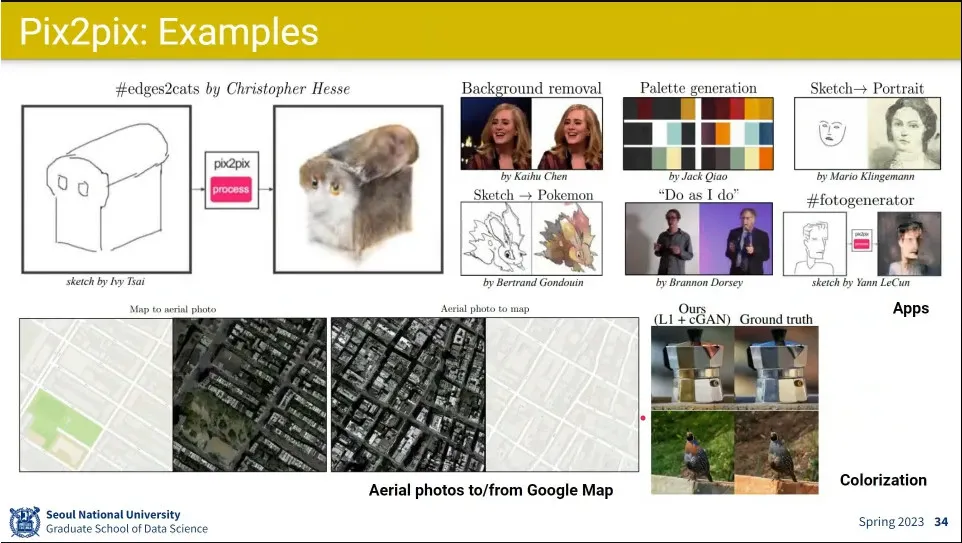
사례
•
pix2pix 요약
◦
결과가 잘 나왔음.
•
데이터셋으로 pair 된 이미지가 필요하다는게 한계
◦
pair 된 데이터셋을 아예 가지지 못하는 경우가 많음.
•
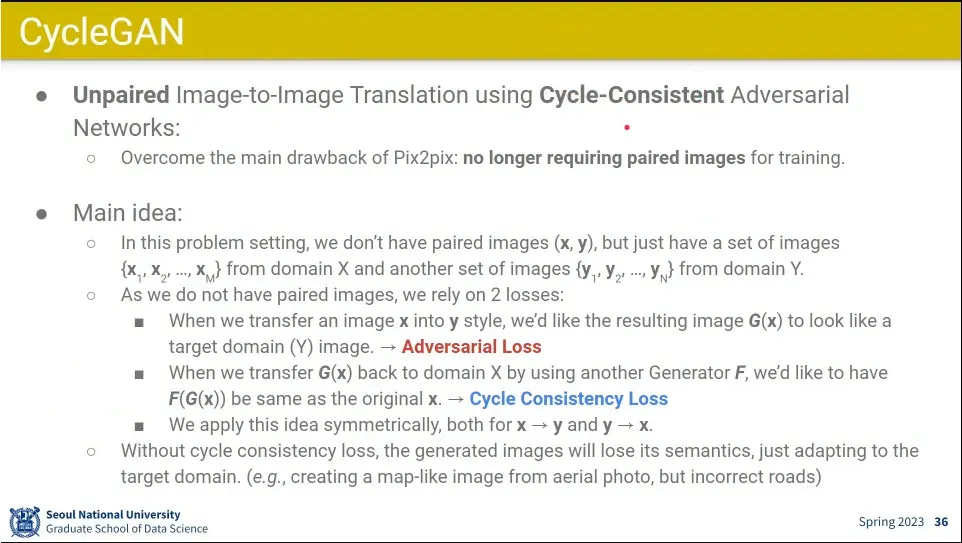
Pix2pix의 한계를 개선한 것이 CycleGAN
•
pair 이미지 없이, 특정 domain으로 style을 바꿨다가, 다시 원래 이미지로 돌아오게 해서 원래와 같은 이미지를 만드는게 아이디어.
◦
그래서 cycle임
◦
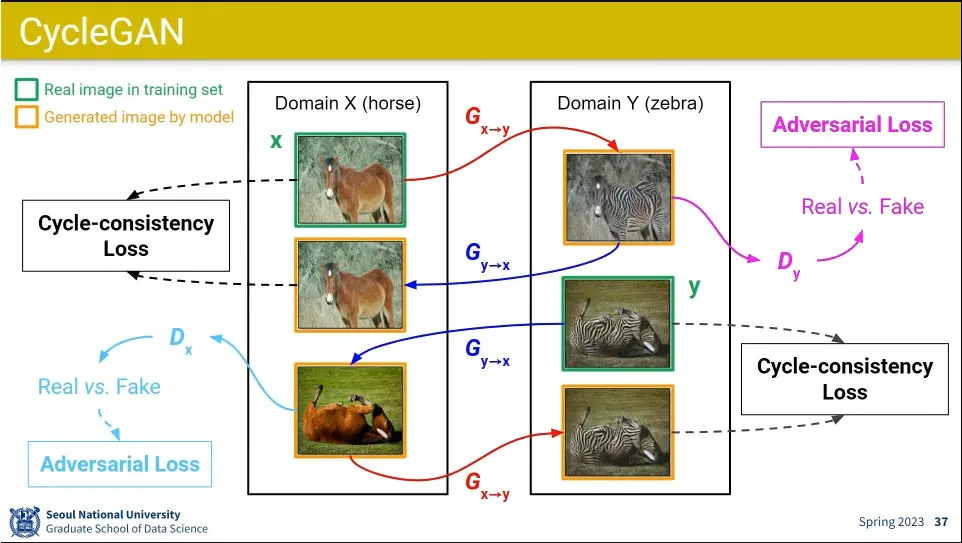
변환 시켰다가 되돌리기 때문에 Generator와 Discriminator가 2개씩 있음.
•
이걸 위해 전통적인 adversarial loss와 cycle consistency loss를 추가해 줌.
◦
cycle consistency loss는 원복 시켰을 때 원본과의 loss가
•
말에서 얼룩말로 갔다가 다시 말로 되돌리는 것과 얼룩말에서 시작해서 말로 바꿨다가 다시 얼룩말로 가는 것을 모두 시킴
•
이러면 pair 된 도메인이 없어도 학습이 가능함.
•
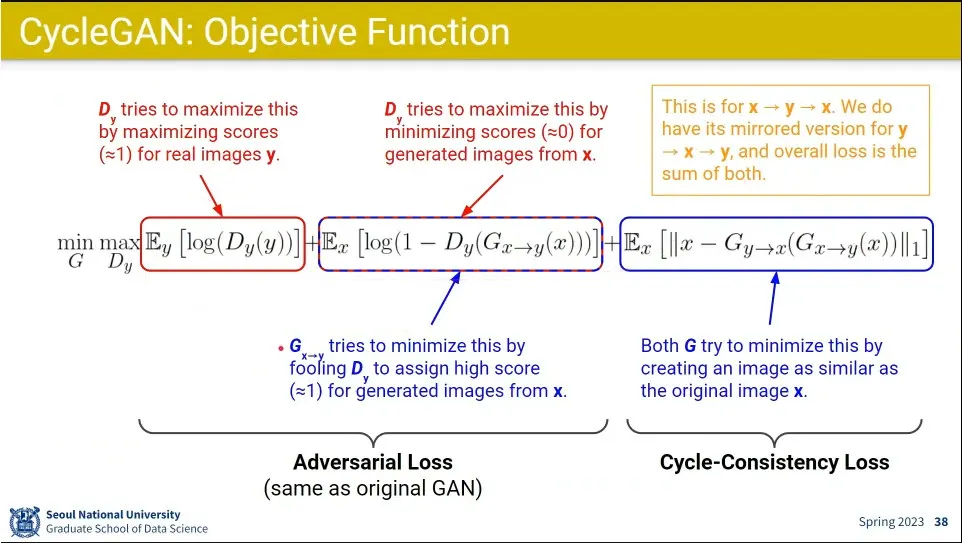
loss에서 앞의 2개 텀은 전통적인 adversarial loss와 비슷하고
•
뒤의 텀이 x에서 y로 갔다가 x로 되돌아 오는 것에 대한 cycle-consistency loss 텀
◦
y에서 x로 갔다가 다시 y로 되돌아오는 것도 필요해서 식이 2개가 있고 학습도 2개를 하게 됨.

•
CycleGAN 상세
◦
Generator는 ResNet을 쓰고 Discriminator는 PatchGAN을 씀.
◦
Loss는 LSGAN을 씀


•
사례

•
이미지 pair 없이 style 변환 가능.
•
높은 해상도 이미지 생성이 가능
•
학습이 느리고 모양이 바꿔야 하는 task가 잘 안된다는게 단점.
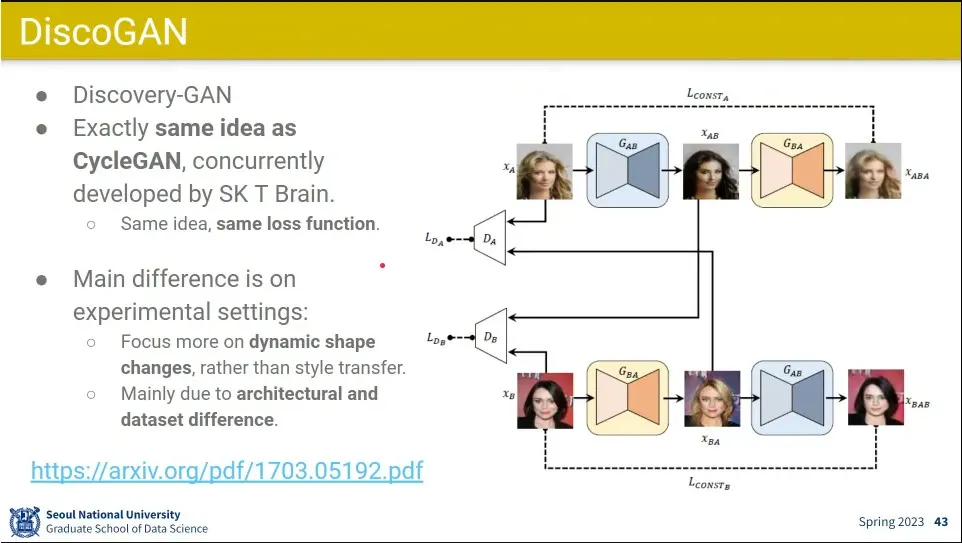
•
CycleGAN과 동시대에 똑같은 아이디어로 나온게 DiscoGAN
◦
한국에서 만든 모델

•
상세한 부분에서 차이가 있음.
◦
모델이 좀 더 경량화 되서 빠르고 대신 해상도는 낮음
•
모양이 바뀌는 것에 강점이 있음.

•
사례
