
Diffusion Transformer(DiT)
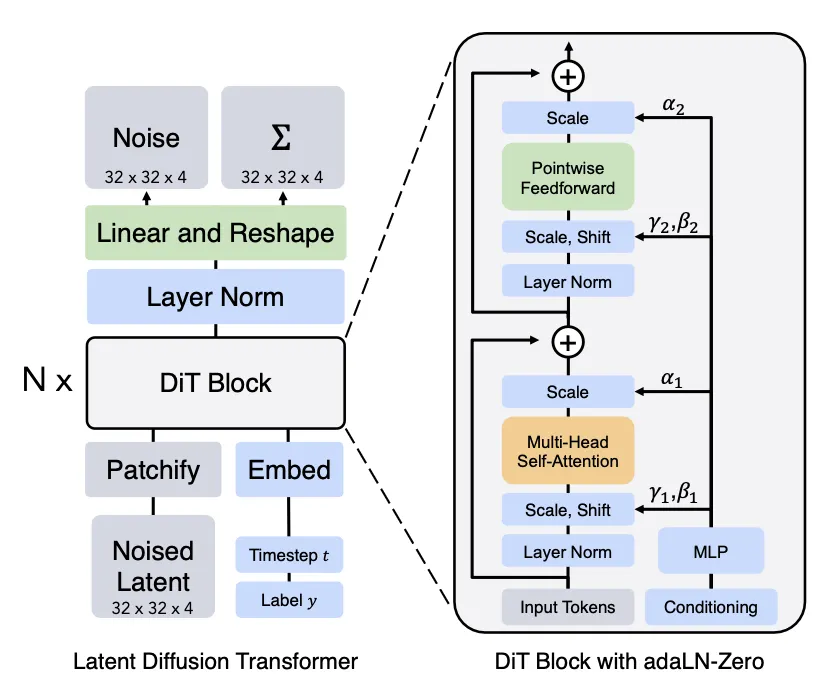
Diffusion Transformer (DiT)는 말 그대로 Diffusion model을 Transformer에 적용한 모델로 U-Net 대신 Vision Transformer(ViT)와 같은 Transformer 구조를 사용한다. DiT는 Latent Diffusion Model(LDM)과 같이 latent space을 사용하며 이미지의 patch를 사용한 ViT와 같이 latent patch를 사용하여 동작한다. DiT는 다음과 같이 동작한다.
1.
입력 의 latent 표현을 DiT의 입력으로 취한다.
2.
크기 의 noise latent를 크기 의 패치로 ‘patchify’ 하고 크기 의 패치의 시퀀스로 변환한다.
3.
그 다음 이 토큰의 시퀀스를 Transformer 블록에 통과시킨다.
•
저자들은 timestep 나 클래스 라벨 와 같은 contextual 정보에 조건화된 생성을 수행하는 3가지 다른 디자인을 탐험 했다. 3개의 디자인 사이에서 adaLN(Adaptive layer norm)-Zero가 가장 성능이 좋았고 in-context conditioning과 corss-attention block 보다 우수하다.
•
scale과 shift 파라미터 와 는 와 의 임베딩 벡터의 합에서 회귀된다. 차원별 스케일링 파라미터 또한 회귀되고 DiT 블록 내의 모든 residual connection에 즉시 prior로 적용된다.
4.
transformer 디코더는 노이즈 예측과 출력 대각 공분산 예측을 출력한다.
트랜스포머 아키텍쳐는 쉽게 확장할 수 있는 것으로 알려져 있다. 이것은 더 많은 컴퓨팅에 따라 성능이 확장되고 실험에 따르면 더 큰 DiT 모델이 더 컴퓨팅 효율적이기 때문에 DiT의 가장 큰 장점 이 된다.
