
Progressive Distillation
DDPM과 DDIM을 함께 사용하여 Distaillation 할 수 있다. 이것은 작은 단계로 높은 품질의 샘플을 생성할 수 있고 progressive distillation 이라 한다. 기본 아이디어는 다음과 같다.
우선 일반적인 방법으로 DDPM 모델을 학습하고 DDIM 방법을 사용하여 샘플한다. 이것을 ‘teacher’ 모델로 취급한다. 이것을 사용하여 중간 잠재 장태를 생성하고 아래 그림에 나오는대로 ‘student’ 모델을 매 두 번째 단계에서 교사의 출력을 예측하도록 학습한다.
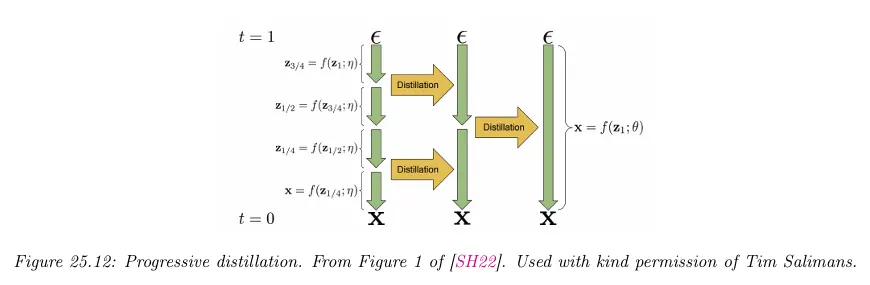
학생이 학습된 후에 교사만큼 좋은 결과를 생성할 수 있지만 단계는 절반으로 줄어든다. 이 학생은 다시 교사가 되어 더 빠른 세대의 학생을 생성할 수 있다. pseudocode에 대해 아래 알고리즘 참조.
교사가 더 작아짐에 따라 teaching의 각 단계는 더 빨라짐에 유의하라. 따라서 distillation을 수행하는 전체 시간은 상대적으로 작아진다. 결과 모델은 4단계만으로 높은 품질의 샘플을 생성할 수 있다.
Algorithm: Progressive distillation
1.
입력: 학습된 teacher 모델
2.
입력: 데이터셋
3.
입력: 손실 가중치 함수
4.
입력: student 샘플링 단계
5.
foreach 반복 do
a.
(student 할당)
b.
while 수렴하지 않으면 do
i.
ii.
iii.
iv.
v.
vi.
vii.
viii.
(teacher가 타겟)
ix.
x.
xi.
c.
(student는 새로운 teacher가 된다.)
d.
(샘플링 단계를 절반으로 줄인다.)
