
•
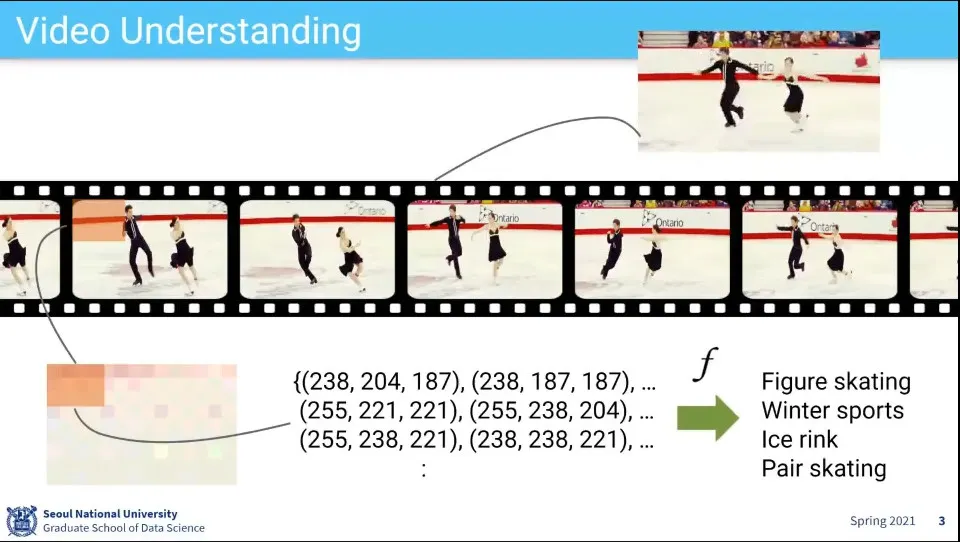
Video는 Image의 Sequence

•
Video Classfication 과제
◦
object와 action을 모두 인식해야 함
•
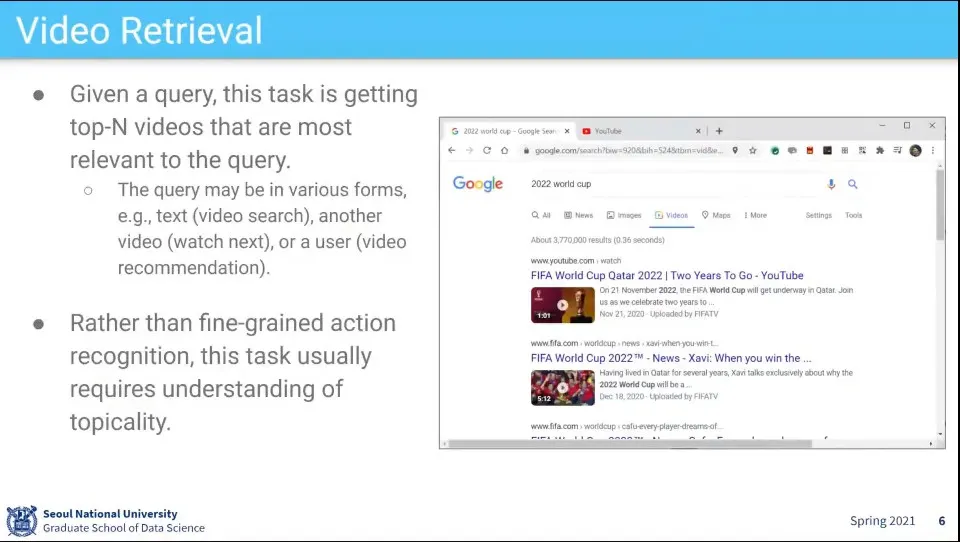
쿼리에 맞는 비디오 검색 과제
•
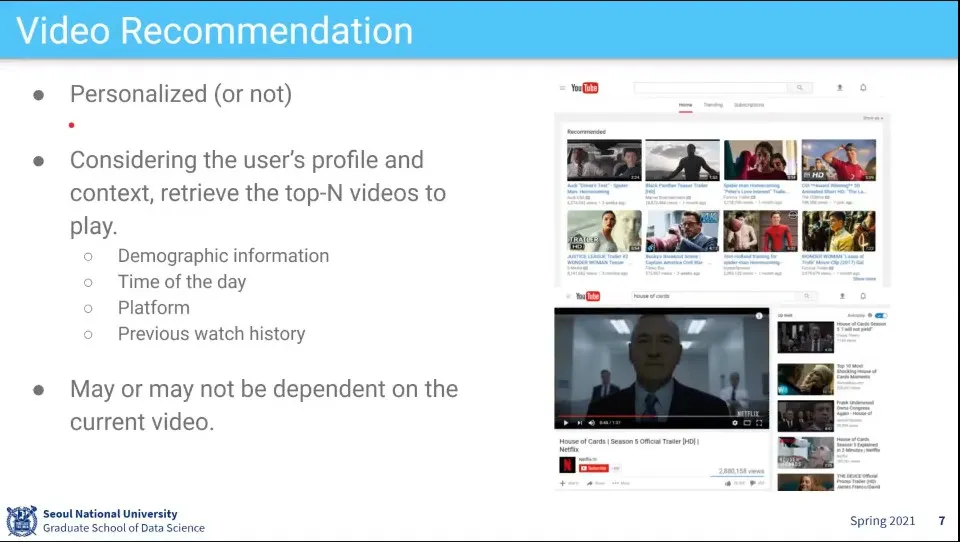
비디오 추천 과제
•
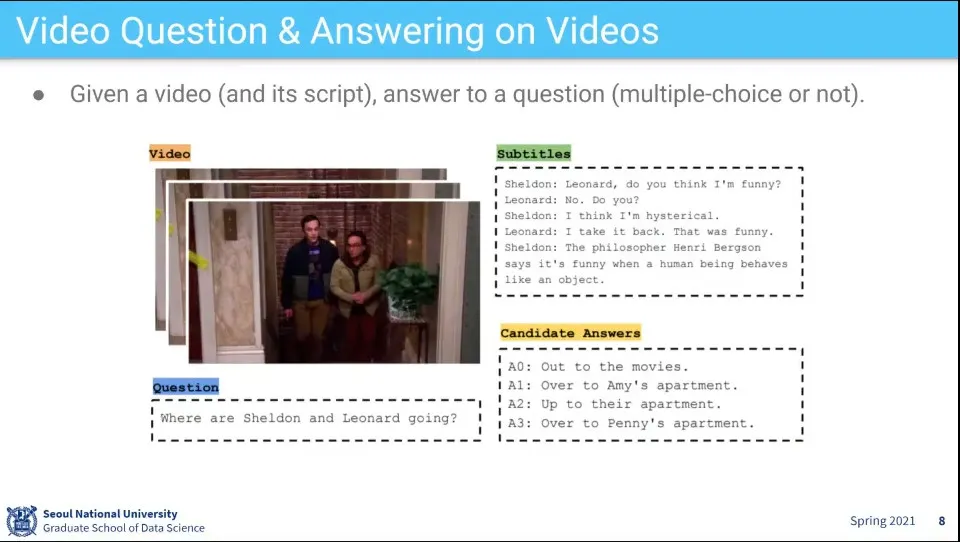
비디오와 자막을 넣어서 무엇을 하고 있는지를 맞추는 과제
•
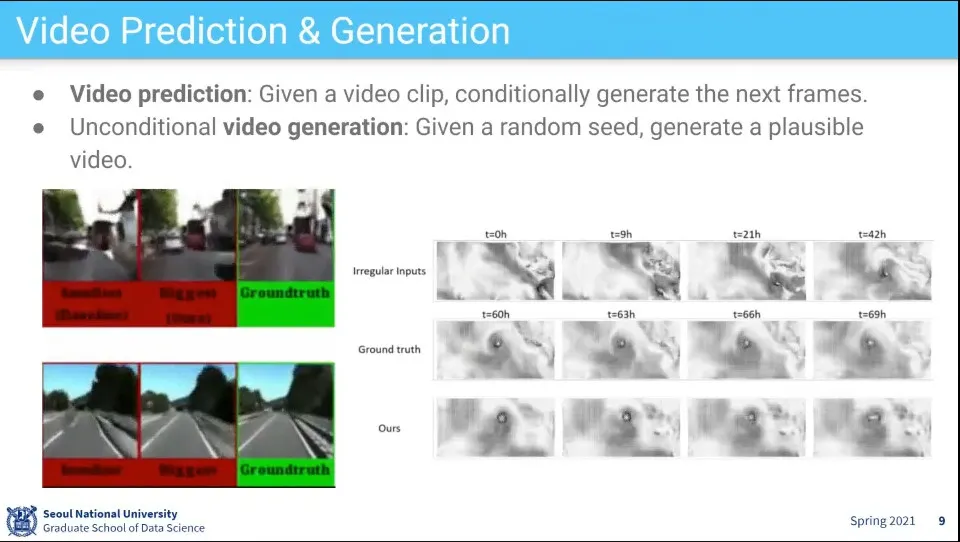
Video의 다음을 예측해서 생성하는 과제

•
Video 압축 과제
•
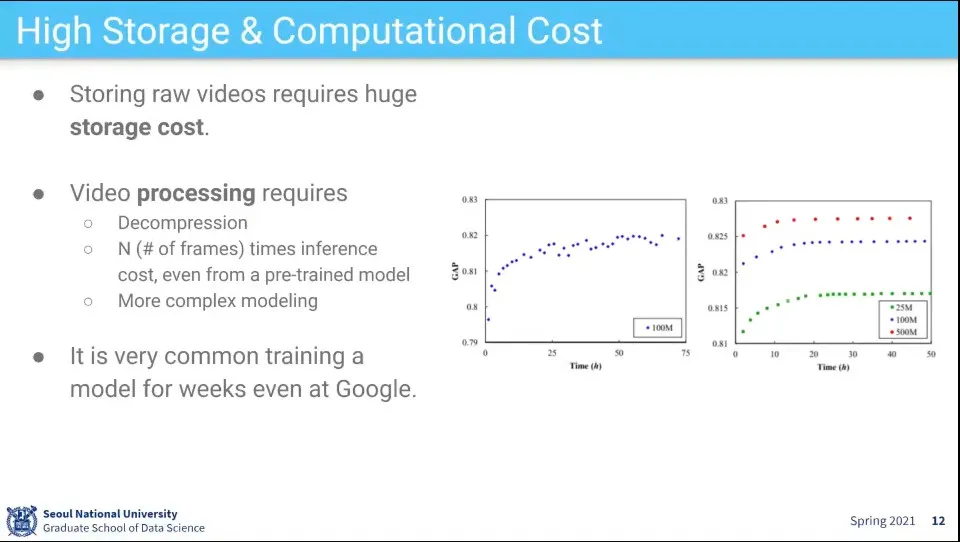
Video 학습의 어려운 점
◦
저장 용량이 큼
◦
때문에 inference 하는데 오래 걸림
•
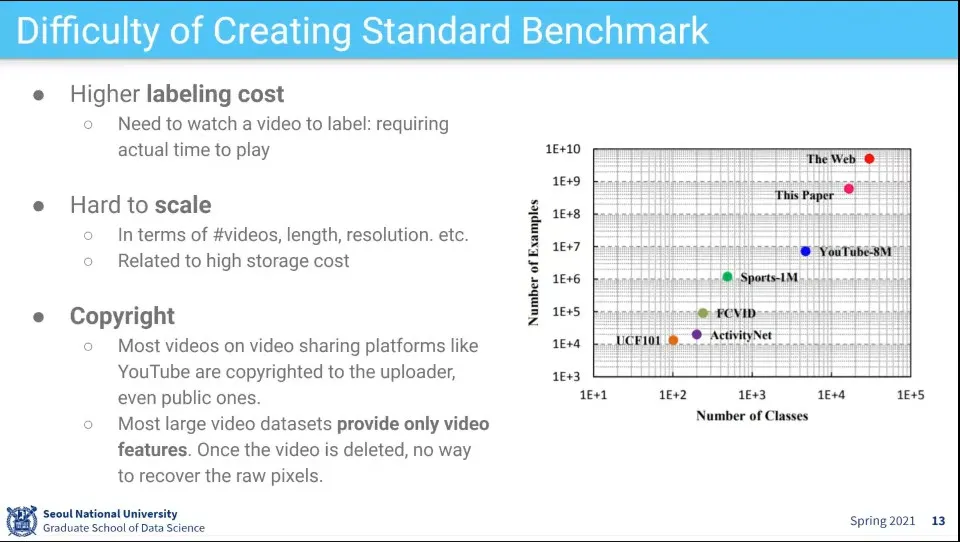
Dataset 만드는 비용이 큼
•
저작권 문제도 있음

•
정보 복잡도가 높음
◦
시간 정보도 포함 됨
•
우리가 세상을 보는 것은 비디오로 보기 때문에 결국 비디오 인식을 해야 함
•
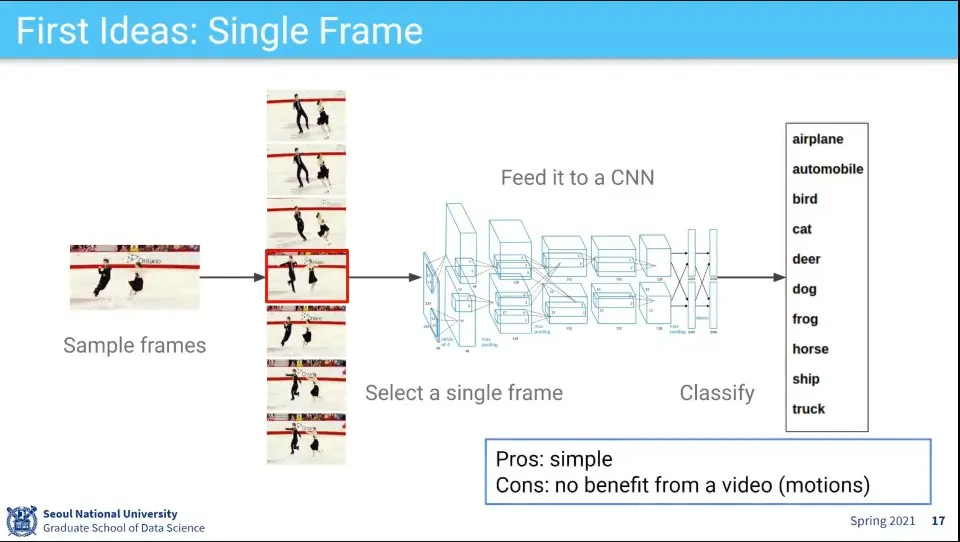
동영상을 분류하는 첫 번째 시도 이미지 한 장 뽑아서 CNN 돌려보자
•
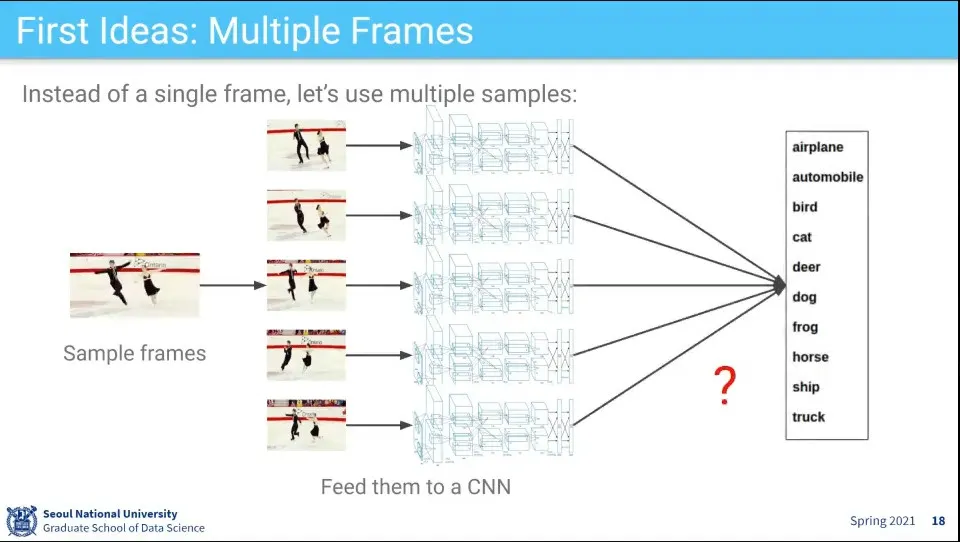
여러 장을 각각 CNN 돌려서 결과를 뽑자
•
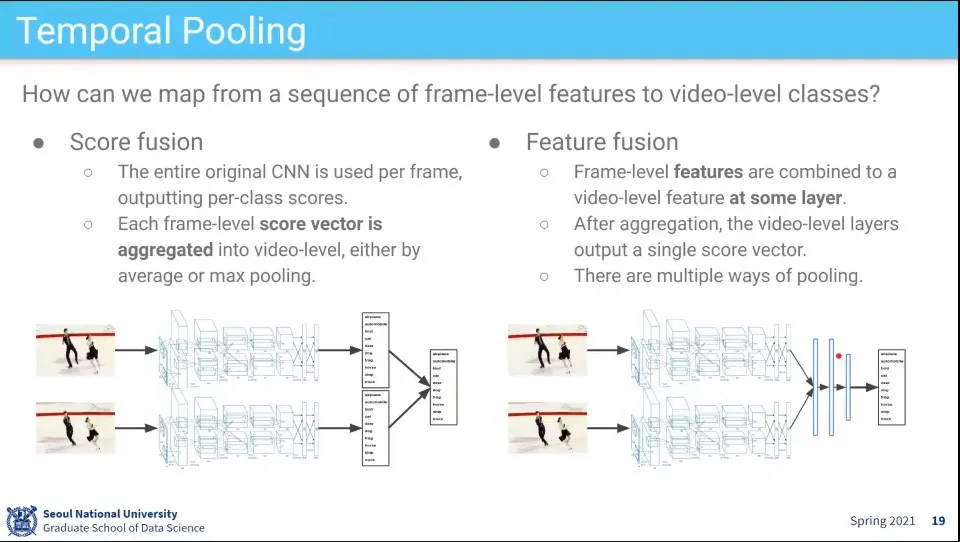
개별 이미지의 점수를 따로 뽑아서 합치거나, 개별 이미지의 feature를 합쳐서 하나의 결과를 뽑자
•
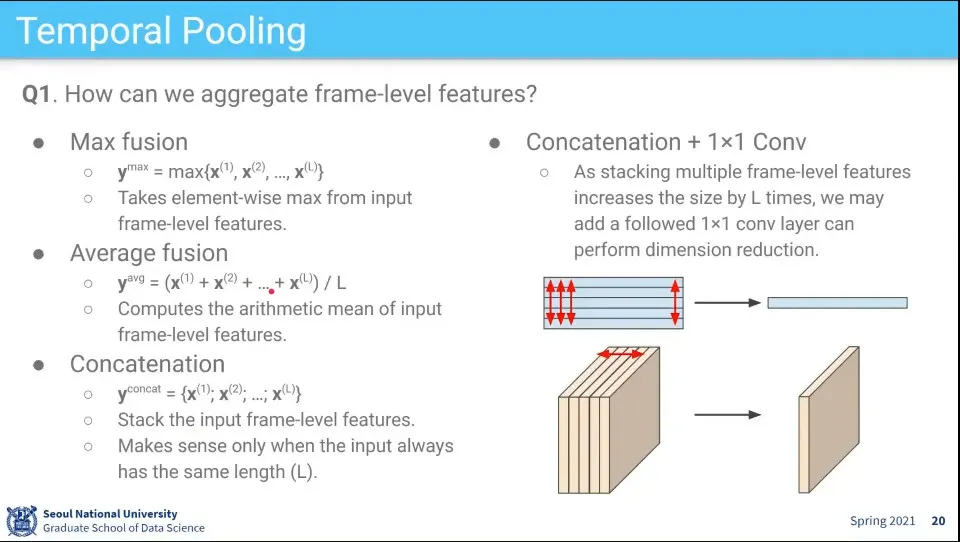
합치는 방법 예
◦
Max, Average, Concatenation 등
◦
유튜브는 Average를 쓴다. 다른 방법들 시도해 봤는데 계산량은 늘어나는데 딱히 개선이 안 되기 때문
◦
Concatenation + 1x1 Conv는 시간 차원을 하나로 합치는 역할을 함

•
Late Fusion은 마지막에 합치는 것
◦
이미지 인식을 먼저 하고 마지막에 그 결과만 합침
•
Early Fusion은 시작할 때 합치는 것
◦
Early Fusion 할 때는 픽셀을 아예 합치는 건데, 이때 그냥 픽셀의 평균이나 max를 쓰면 이상하므로, 차원을 1개 더 늘려서 사용함

•
합치는 단계를 여러개 두어서 사용하는 Slow Fusion 방식도 있음
•
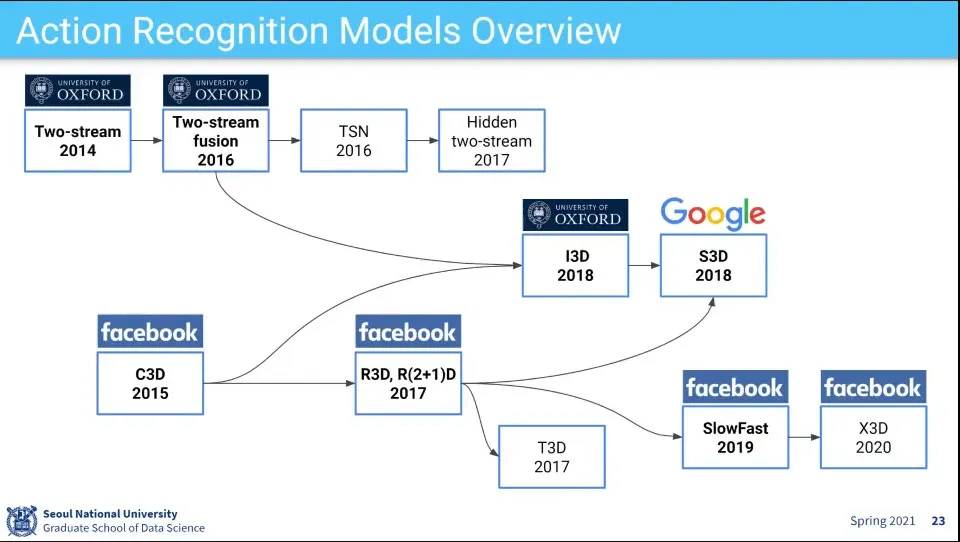
비디오 Action 인식 모델 발전 흐름
•
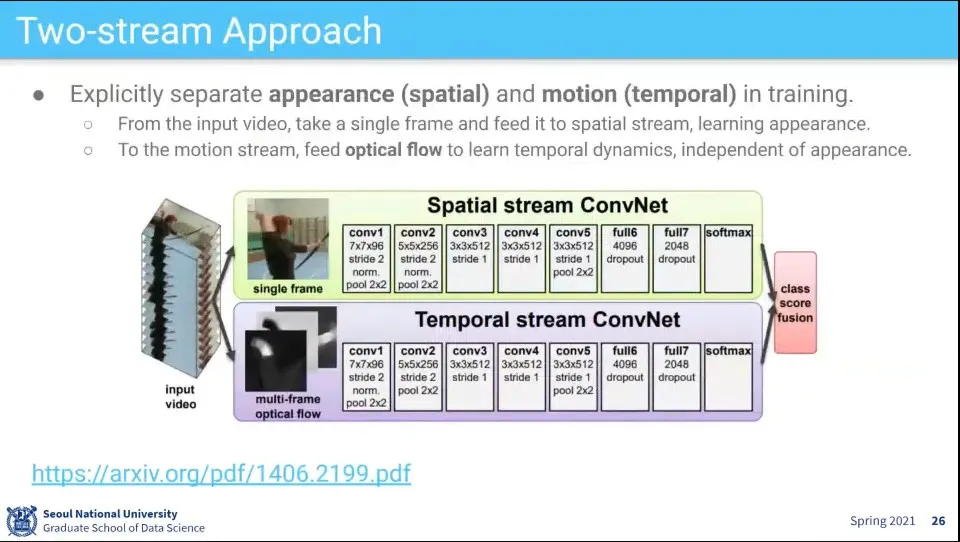
Two-stream 모델은 공간 정보와 시간 정보를 따로 학습해서 합치는 방식
◦
spatial 정보는 1장면만 뽑아서 학습
◦
temporal 정보는 시간에 따라 변화하는 정보를 따라 감. 이걸 optical flow라고 함
•
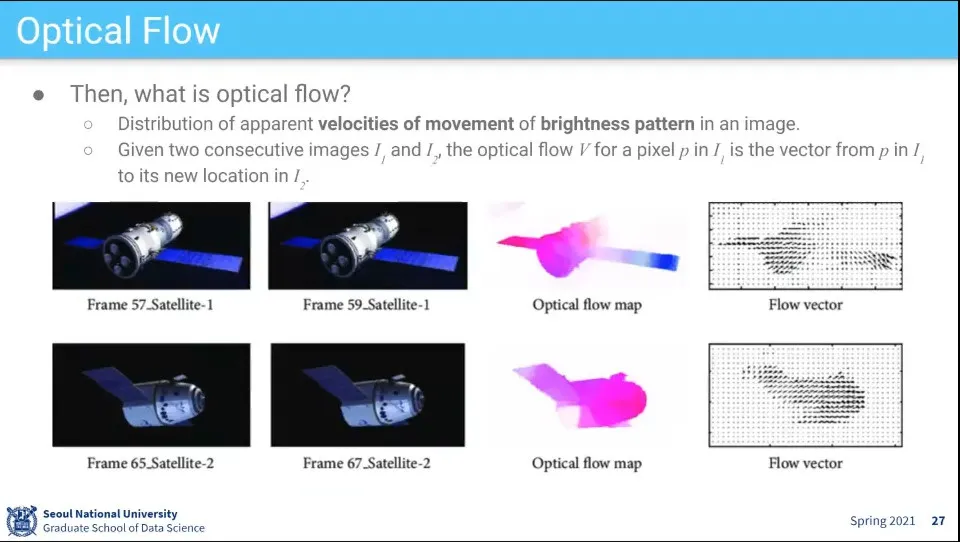
Optical Flow란 픽셀 단위로 움직임을 추적하는 것
◦
이전 프레임에서 다음 프레임으로 어떻게 움직이는지를 본다.

•
Optical Flow의 예

•
Optical Flow의 몇가지 가정
◦
모든 점은 색깔이 바뀌면 안 된다. —점 자체의 색이 바뀌면 추적이 안 됨
◦
물체가 너무 빨리 움직이면 안 됨.
◦
공간적으로 가까이 있는 점들은 같은 오브젝트라서 비슷하게 움직인다
•
이때 사용하는 알고리즘은 Lukas-Kanade 알고리즘을 사용함
•
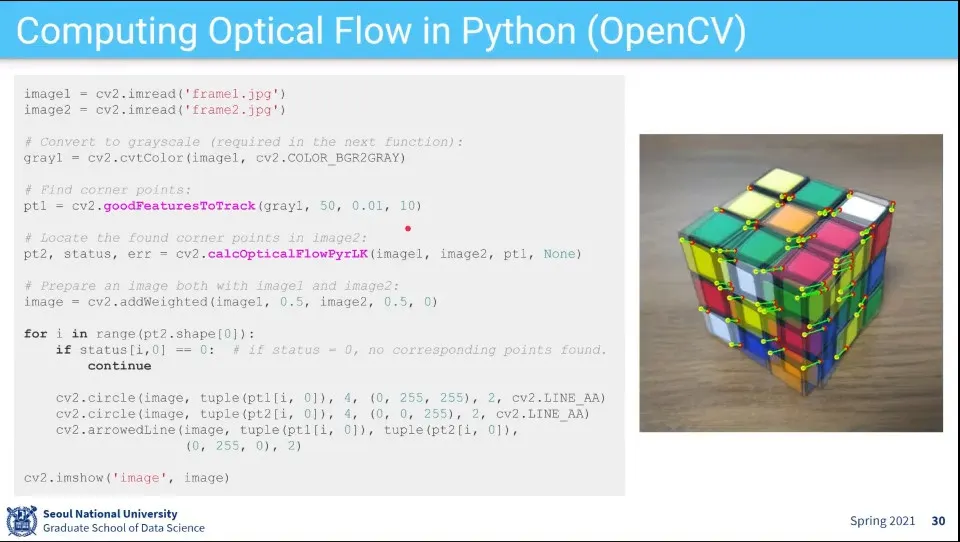
Optical Flow 코드 예
◦
gooFeaturesToTrack은 이미지에서 모서리점을 찾음
◦
그렇게 찾은 모서리점을 이용해서 어떻게 움직이는가를 찾음 —calcOpticalFlowPyrLK
•
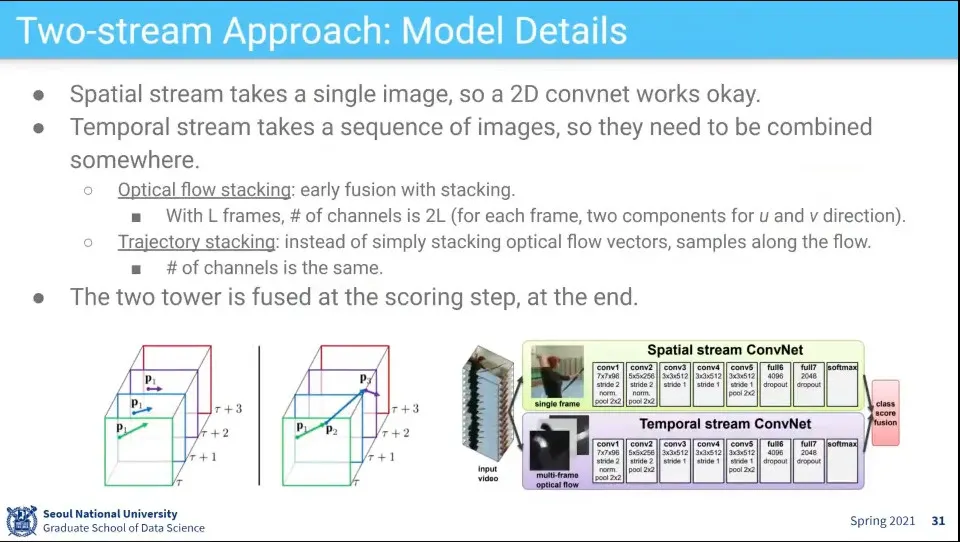
공간 정보는 이미지 1장 뽑아서 사용, 시간 정보는 Optical Flow Stacking, Trajectory Stacking을 이용해서 사용
•
그렇게 따로 돌린 결과를 하나로 합침

•
이 방식의 문제는
◦
Long range temporal 정보 처리가 안 됨.
◦
1장만 뽑다보니 Label을 제대로 적용하기 어려움. 멀리 뛰기에서 달리는 부분을 뽑으면 잘못된 label이 됨
◦
optical flow를 사용하는거 자체가 비용이 큼
◦
Two Stream을 따로 학습해야 해서 end-to-end 학습이 안 됨
•
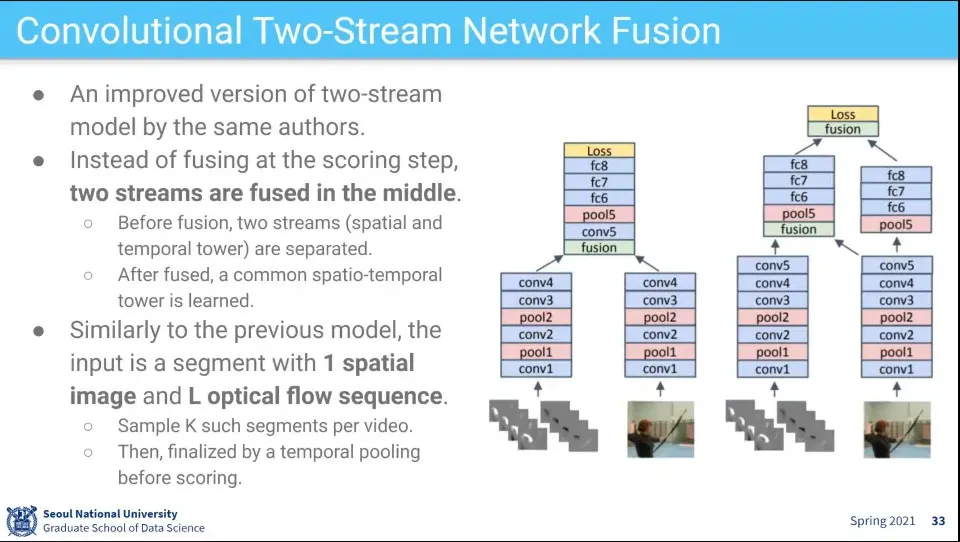
같은 저자가 이전 버전을 개선한 버전을 발표
◦
공간-시간 정보를 fusion 한 후에 레이어를 더 넣음


•
그냥 이것저것 해 봤다는 정도
◦
앞에서 fusion 했더니 학습 파라미터가 줄어서 학습이 빨라졌더라

•
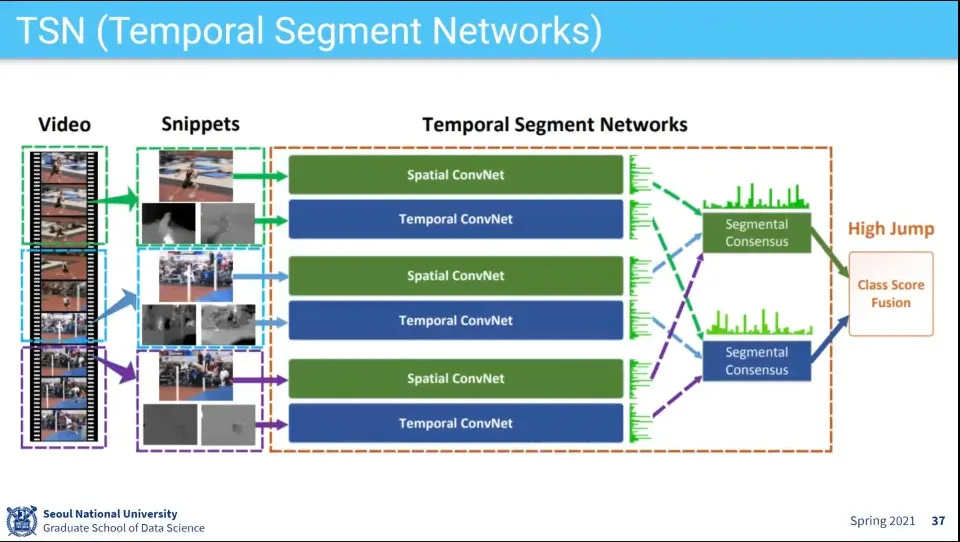
Two Stream 모델을 개선한 다른 버전
◦
Two Stream이 긴 영상에 취약해서, 영상을 10초 단위로 짜르고, 각 10초마다 Two Stream과 같이 하고, 마지막에 그것들을 다 합치는 방식
◦
Optical Flow를 Warped Optical Flow를 적용. 기존 Optical Flow는 카메라가 고정되어있어야 한다는 가정이 필요함.
◦
추가로 pre-training, drop-out, batch norm 등의 최신 딥러닝 기법을 적용해서 성능을 높임
•
방식은 기존 것과 유사 함

•
Hidden Two-Stream은 Optical Flow는 계산해 놓고 사용하지 않고 Neural Network 안에서 하자는 아이디어
