B Extended Description of V-JEPA
이 섹션에서 우리는 그림 3에 그려진 V-JEPA의 in-depth 설명을 제공한다.
Input.
달리 명시되지 않는 한, pre-training 동안 우리는 항상 각 입력 비디오에서 16 프레임의 클립을 랜덤으로 샘플링하며 샘플링된 프레임 사이의 시간적 stride는 4이다. 그러므로 입력 비디오 클립은 총 64 프레임 또는 초당 30 프레임으로 실행 되는 주어진 비디오의 약 2초를 커버한다. 그 다음 비디오의 공간적 차원을 224x224로 resize하여 전체 클립에 대해 16x224x224x3의 전체 형태를 생성한다. ViT 네트워크가 토큰의 1차원 시퀀스를 처리하므로 우리는 입력 비디오 클립을 1차원 토큰 시퀀스로 변환해야 한다. 이를 위해 우리는 시간적 stride를 2로 공간적 stride를 16으로 가진 2x16x16 크기의 d 필터로 구성된 3D convolution을 적용하여 8x14x14xd 형태의 텐서를 얻는다. 다음으로 spatio-temporal feature map에 절대값 3d sin-cos positional embedding을 추가하고 평탄화하여 1568xd의 1차원 토큰 시퀀스를 만든다. 절차는 그림 7 참조.
V-JEPA.
우리는 각 iteration에서 비디오 클립과 비디오 mask 모두를 샘플링한다. 우리는 길이 의 1차원 토큰 시퀀스로 표현된 video clip을 로 나타낸다. 유사하게 패치의 마스크가 주어지고 패치가 unmask인 경우, masked patch의 index를 으로 표기하고 그 complement(unmasked patch의 index)를 으로 표기한다.
Computing the x-representations.
V-JEPA loss를 계산하기 위해 우리는 우선 비디오 클립을 masking 하고 -encoder에 공급하여 -representation을 생성한다. masked video를 으로 표기한다. -encoder 을 masked clip에 적용하면 패치 represntation의 시퀀스가 생성되며 이를 으로 표기한다.
Predicting the target.
다음으로 V-JEPA predictor network 은 -encoder가 생성한 토큰을 입력으로 취하고 비디오 클립에서 누락된 영역을 예측한다. 이것은 학습 가능한 mask 토큰의 집합으로 지정된다. 구체적으로 mask token은 공유된 학습 가능한 벡터와 절대값 3D sin-cos positional embedding의 합으로 파라미터화되고, 이를 로 표기한다. 따라서 predictor의 출력은 으로 주어지며, 이것은 개 masked 패치의 각각에 대한 -차원 출력에 해당한다.
Computing the y-representations.
마지막으로 prediction target을 계산하기 위해 전체 unmasked 비디오 클립이 -encoder에 의해 처리되어 target representation의 집합을 얻고 이를 로 표기한다. V-JEPA의 loss는 이제 다음과 같이 계산된다.
이것은 단순히 predictor의 출력과 -encoder 사이의 평균 거리이다. 그 다음 -encoder의 파라미터 와 predictor의 파라미터 에 대한 gradient 업데이트를 계산하고, 그 후에 -encoder의 파라미터를 context encoder weights의 exponential moving average(Polyak average)으로 업데이트한다.
Multi-Mask Prediction.
V-JEPA의 효율성을 증가시키기 위해, 우리는 target 계산의 비용을 amortize 할 수 있는 multi-masking 전략을 사용한다. 섹션 3에서 언급된 것처럼 주어진 비디오 클립에 대해 short-range와 long-range의 2가지 다른 mask를 샘플링한다. 각 mask에 대해 -encoder와 predictor를 별도로 forward 전파해야 하지만, -representation은 한 번만 계산하면 된다.
C Pretraining details
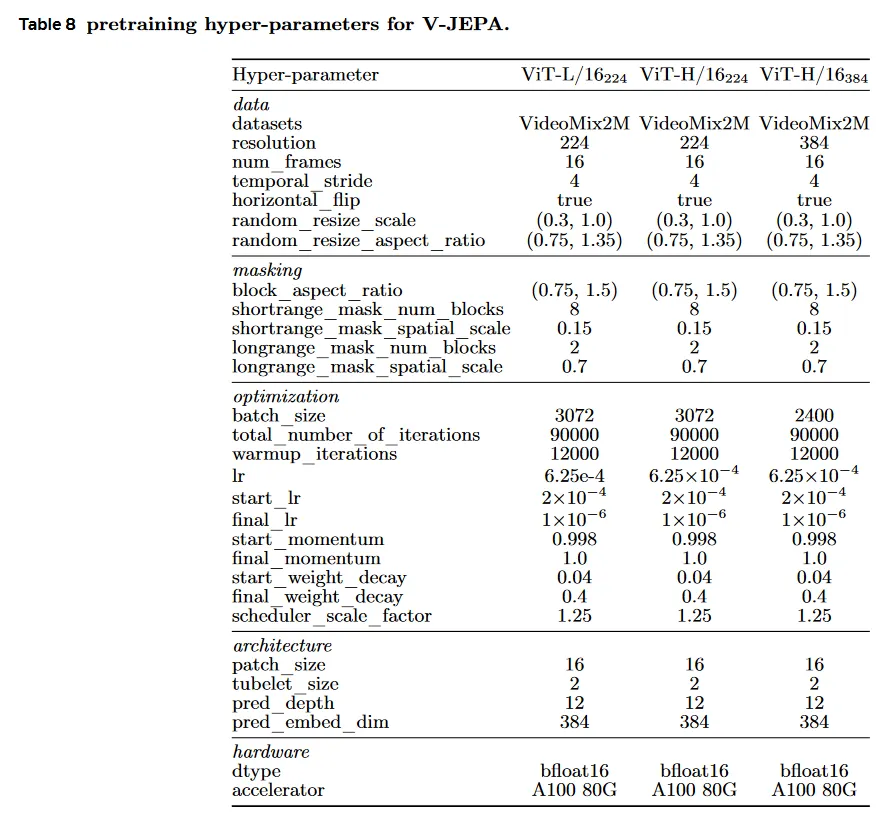
이 섹션에서 V-JEPA pre-training detail을 리포트한다. Table 8은 pre-training 동안 사용된 주요 하이퍼파라미터를 요약한다.
Architectures.
우리는 -encoder와 -encoder에 Vision Transformer(ViT) 아키텍쳐를 사용한다. 우리는 ViT-L/16_224, ViT-H/16_224, ViT-H/16_384의 3가지 V-JEPA encoder를 학습시킨다. 3가지 encoder 모두 연속 프레임 사이의 시간 stride가 4인 16 프레임의 짧은 비디오 클립을 입력으로 취한다. 아래첨자 224와 384는 비디오 클립의 공간적 해상도를 나타낸다. V-JEPA는 비디오 클립을 16x16x2 크기의 겹침없는 spatio-temporal 시퀀스로 평탄화한다(그림 7). 3가지 모델 모두 predictor는 각 384의 embedding 차원을 가진 12개 transformer block으로 구성된 narrow ViT 아키텍쳐로 설계된다. 단순화를 위해 predictor의 self-attention head의 수를 context-encoder/target-encoder에서 사용된 backbone과 일치하도록 유지한다. V-JEPA는 [cls] token을 사용하지 않고 pre-trained한다.
Optimization.
우리는 AdamW를 사용하여 -encoder과 predictor 가중치를 최적화 한다. ViT-L/16_224와 ViT-H/16_224 모델은 배치 크기 3072를 사용하는 반면 ViT-H/16_384는 배치 크기 2400을 사용한다. 모델은 총 90,000 iteration 동안 학습된다. learning rate는 pre-training의 처음 12,000 iteration 동안 에서 까지 선형적으로 증가하고, 이후 cosine 스케쥴을 따라 으로 감소된다. weight-decay는 또한 pre-training 전체에 걸쳐 0.04에서 0.4으로 선형적으로 증가한다. -encoder 가중치는 -encoder와 동일하게 초기화되고, 이후 -encoder 가중치의 EMA로 업데이트되며, momentum 값은 0.998에서 시작하고 학습하는 동안 1.0까지 선형적으로 증가한다. 모든 하이퍼-파라미터 스케쥴을 실제 학습 스케쥴 보다 25% 확장한다. 구체적으로 learning rate schedule, weight-decay schedule, EMA schedule은 112,500 iteration의 학습 길이를 가정하여 계산되지만, 실제로는 90,000 iterations만 학습한다. 기본 스케쥴러 주기의 마지막 25%가 하이퍼파라미터를 너무 적극적으로 업데이트한다는 것을 발견했고, 단순히 스케쥴러를 잘라내는 것이 성능을 개선한다.
Masking.
섹션 3에서 설명한 것처럼 우리는 3D Multi-Block masking 전략을 제안한다. 우리는 mask의 2가지 유형을 사용한다. short-range mask는 0.15의 공간적 스케일을 갖는 8개의 랜덤으로 샘플링된 target block의 합집합이고, long-range mask는 0.7의 공간적 스케일을 갖는 2개의 랜덤으로 샘플링된 target block의 합집합이다. 두 경우 모두 샘플링된 모든 블록에 대한 종횡비는 (0.75, 1.5)의 범위에서 무작위로 선택된다.
D Evaluation details
D.1 Frozen classification
Attentive Probing.
입력 비디오 이 주어지면 V-JEPA target encoder 은 token의 시퀀스를 출력한다. . 여기서 . 이 token의 시퀀스를 단일 feature 벡터로 pool 하기 위해, 우리는 transformer block의 self-attention operation을 cross attention과 교체하는 lightweight non-linear cross-attention 블록을 적용한다. 구체적으로 cross-attention은 다음 계산을 수행한다.
여기서 는 key와 value 행렬이고 는 학습 가능한 query token이다. 그 다음 cross-attention의 출력은 query token에 다시 추가되고(residual connection), 그 다음 단일 GeLU activation을 갖고 LayerNorm이 이어지는 2 layer MLP로 공급된다. 마지막에 linear classifier에 전달된다. cross-attention block의 파라미터는 downstream task를 위한 linear classifier와 jointly 학습되며 encoder 파라미터는 frozen으로 유지된다. 실제로는 12개의 head를 갖는 attentive probe를 사용하며 각 head의 차원은 12이다. 부록 E에서 baseline이 attentive probe 프로토콜에서 이점을 얻는다는 것을 보인다.
Optimization.
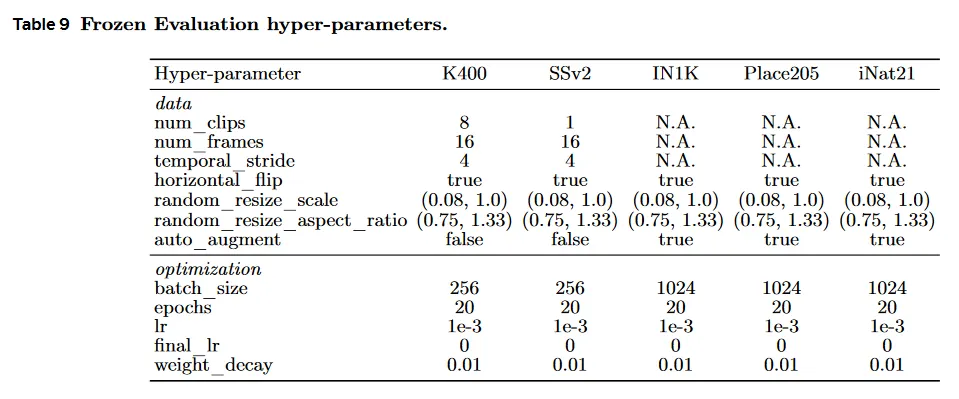
모든 task에 대해 우리는 AdamW optimizer와 (warmup 없이) 0.001에서 0까지 learning rate를 감소시키는 cosine 스케쥴러를 사용한다. 우리는 0.01의 고정된 weight-decay를 사용하고 attentive probe의 학습 중에 간단한 data augmentation을 적용한다(무작위 resized crop과 horizontal flip). 단, image task에서는 AutoAugment를 적용한다. Table 9는 각 downstream 평가에 대한 하이퍼파라미터를 리포트한다.
Extension to multiple clips.
달리 명시하지 않는 한, 우리의 attentive probe는 Kinetics에서 16 프레임의 8개 클립을, Something-Something-v2에서 16 프레임의 2개 클립을 입력으로 취하고 비디오의 시간적 커버리지를 증가시킨다. 구체적으로 먼저 비디오를 8(또는 2)개의 동일한 길이의 시간 segment로 나누고 segment 당 1개 클립을 랜덤으로 샘플링한다. 비디오 encoder 는 각 클립을 별도로 처리하여 clip-level feature map을 생성한다. 그 다음 각 클립의 feature map은 서로 concatenate 되어 attentive probe에 공급된다. test 시에 우리는 비디오 분류에서 표준 관계를 따라 3개의 공간 view의 예측을 평균화한다.
Application of video models to images.
이미지 task에서 video 모델을 평가하기 위해 우리는 간단히 입력 이미지를 복제하여 16 프레임의 정지 비디오 클립을 생성한다. 이 복제 작업은 비디오 모델의 평가에서 간편함을 위해 수행되지만, 우리는 일반적으로 이 단계가 불필요함을 발견했다. temporal stride 2인 3D-conv로 구현된 video tokenizer가 주어진 경우, 이미지를 2 프레임 비디오 클립으로 복제하는 것으로 충분하다. 이것은 2D-conv tokenizer를 rkwls 정적 이미지 모델dl 생성하는 것과 동일한 수의 입력 토큰을 생성한다.
Application of image models to videos.
DINOv2와 OpenCLIP 같은 이미지 모델을 video 작업에서 평가하기 위해, 우리는 간단히 각 프레임을 독립적으로 image encoder로 처리하여 frame-level feature map을 생성한다. 그 다음 각 프레임에 대한 feature map은 concatenated 되어 attentive probe에 공급된다. 이는 비디오 모델을 평가할 때 클립-레벨 feature map을 처리하는 방식과 동일하다.
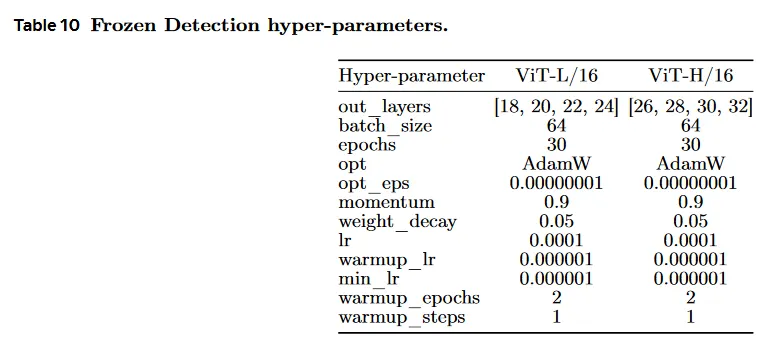
D.2 Frozen detection
우리는 211k training과 57k validation video segment를 포함하는 AVA spatio-temporal human action의 localization 데이터셋에서 우리의 모델을 평가한다. 우리는 Feichtenhofer et al(2021)의 실험 프로토콜을 따르고, 비디오에 맞게 조정된 pre-trained Faster-RCNN에서 미리 계산된 mask를 사용한다. 이것은 ResNeXt-101FPN backbone을 사용하고 ImageNet과 COCO에서 pre-trained이다. 우리는 frozen V-JEPA feature 위에 linear classifier를 학습하여 추출된 관심 영역을 분류하고 60개 일반 클래스에서 mean Average Precision(mAP)를 리포트한다. 하이퍼파라미터는 Table 10에서 제공된다. 우리의 frozen feature는 transformer의 마지막 레이어와 3개의 중간 layer를 concatenating하여 얻어진다. 우리는 64의 배치 크기와 AdamW으로 30 epoch pre-train하며, 0.0001 learning rate와 2 epoch의 warmup, 0.05의 weight decay를 사용한다.
D.3 Fine-tuning
Tong et al(2022)를 따라 우리는 layer decay schema와 mixup을 data augmentation pipeline으로 사용하여 우리 모델 위에 linear layer를 fine-tune 한다. K400과 SSv2 모두에 대한 하이퍼파라미터를 Table 11에 제공한다.