
Bootstrap your own latent(BYOL)
Bootstrap your own Latent(BYOL)은 self-supervised 모델로 동일한 아키텍쳐를 갖는 2개의 네트워크(online, target)을 이용하여 이미지의 representation을 학습하는 모델이다. 이 모델은 일반적인 self-supervised 모델과 같이 특정한 task를 직접 해결하는 것을 목표로 하기 보다는 downstream task로 연결될 수 있는 일반화된 representation을 학습하는 것을 목표로 한다.
BYOL 이전에 SimCLR와 같은 positive pair와 negative pair를 활용해서 positive pair는 가까이하고, negative pair는 멀리 떨어뜨리도록 학습하는 contrastive learning 방법이 각광 받고 있었으나, 이러한 방법들이 negative sample을 이용한 방법들은 학습에 유용한 hard negative를 찾아야 한다는 것과 모든 negative sample과 비교해야 해서 계산 시간이 많이 든다는 점과 무엇보다도 image augmentation에 영향을 많이 받는다는 점이 문제였고, BYOL은 positive 샘플만 사용하는 negative-free 방법을 통해 이것을 개선한다.
Architecture
보다 정확히 BYOL은 하나의 이미지를 서로 다르게 augmentation 한 후에 2개의 네트워크를 통과시킨 후에 그 결과를 예측하는 형식으로 representation을 학습한다.
이를 위해 BYOL은 아래와 같이 마지막 단계만 제외하고 동일한 아키텍쳐를 갖는 2개의 네트워크 online network와 target network를 구축한다(online은 마지막에 추가로 predictor를 갖는다). 여기서 두 네트워크는 서로 다른 파라미터를 사용하는데, 여기서 online network의 파라미터는 로 target network의 파라미터는 로 표기된다.
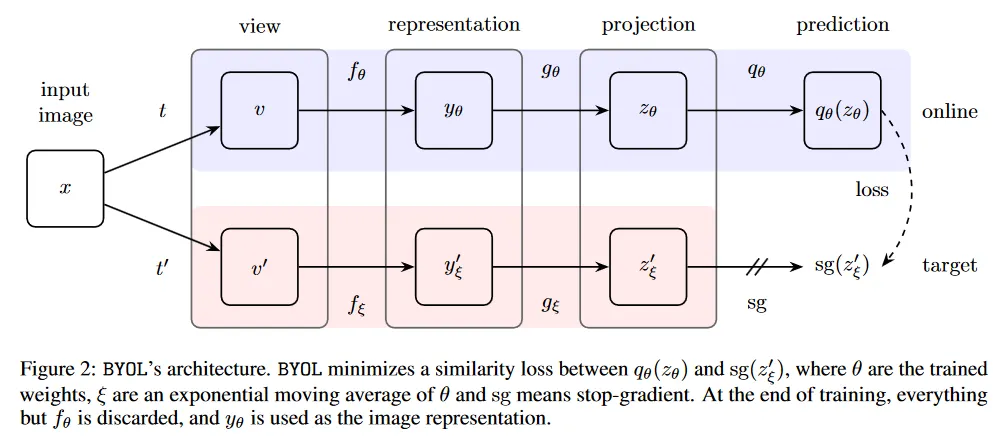
Bootstrapping
BYOL은 다음과 같은 절차로 모델 학습을 수행한다.
1.
우선 두 네트워크는 동일한 이미지에 대해 각기 다른 random 값을 이용하여 augmentation한 이미지를 입력으로 받는다.
2.
그 다음 두 네트워크는 별도의 파라미터를 갖는 encoder 를 이용해서 입력을 인코딩한다. 여기서 encoder는 일반적으로 ResNet 같은 아키텍쳐를 사용한다.
3.
encoder를 통과해 얻은 데이터를 projector 를 통해 저차원 공간으로 투영한다. 여기서 projector는 일반적으로 MLP 구조를 사용한다.
4.
다음으로 online network에만 존재하는 predictor 는 online network의 projector의 결과 를 입력으로 받아 target network의 projector의 결과 를 예측하는 값 을 출력한다. 여기서 predictor는 projector와 동일한 아키텍쳐를 사용한다.
5.
predictor의 예측값 과 실제 target network의 projection 결과 을 각각 normalization한 후에 L2 distance를 이용해 loss를 계산한 다음 역전파하여 online network를 학습한다.
6.
target network의 파라미터는 online network와 달리 역전파로 업데이트 하지 않고, 매 학습 단계 후에 online network의 파라미터를 이용해 업데이트 한다. 이때 target decay rate 를 이용해서 다음과 같이 slowly moving exponential average 형태로 파라미터를 업데이트 한다.
이것은 강화학습에서 Target Network를 별도로 두고 파라미터를 업데이트하는 방식에서 착안 되었다. 이것은 학습은 안정성을 높이고(진동을 줄이고) 수렴 속도를 높이는데 효과가 있다고 한다.
이러한 방법을 통해 모델은 점진적으로 표현을 개선해 나가기 때문에 이 모델에 Bootstrap이라는 이름이 붙었다. BYOL의 학습에 대한 더 자세한 수식과 파라미터 설정 등은 참고 자료의 논문 페이지 참조.
Sample Code
모델 샘플 코드
import torch
import torch.nn as nn
import torch.optim as optim
import copy
class BYOL(nn.Module):
def __init__(self, encoder_name='resnet50', projection_dim=256, hidden_dim=4096):
super(BYOL, self).__init__()
# Encoder: Using a pre-defined ResNet model from torchvision
self.encoder = self.get_encoder(encoder_name)
# Projector: A simple MLP with two linear layers
self.projector = nn.Sequential(
nn.Linear(self.encoder.fc.in_features, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, projection_dim)
)
# Predictor: Another MLP with two linear layers
self.predictor = nn.Sequential(
nn.Linear(projection_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, projection_dim)
)
def get_encoder(self, encoder_name):
if encoder_name == 'resnet50':
encoder = models.resnet50(pretrained=False) # Initialize without pre-trained weights
elif encoder_name == 'resnet18':
encoder = models.resnet18(pretrained=False)
# Remove the classification head
encoder = nn.Sequential(*list(encoder.children())[:-1])
return encoder
def forward(self, x):
# Forward through the encoder to get the representation
representation = self.encoder(x)
representation = representation.view(representation.size(0), -1) # Flatten
# Forward through the projector to get the projection
projection = self.projector(representation)
# Forward through the predictor to get the prediction
prediction = self.predictor(projection)
return representation, projection, prediction
Python
복사
학습 샘플 코드.
원래 논문 코드는 동일한 이미지의 서로 다른 증강 버전 x1, x2를 online과 target에 각각 넣고 그 결과를 비교하는 것이지만, 여기서는 그 접근 방법을 확장하여 x1, x2를 online과 target에 모두 넣고, 그 두 결과를 교차로 비교해서 loss를 계산한다.
# Helper function to update target network
def update_moving_average(online_net, target_net, beta):
for online_params, target_params in zip(online_net.parameters(), target_net.parameters()):
target_params.data = beta * target_params.data + (1.0 - beta) * online_params.data
# Loss function: BYOL uses a simple mean squared error loss
def byol_loss(p_online, z_target):
p_online = nn.functional.normalize(p_online, dim=-1, p=2)
z_target = nn.functional.normalize(z_target, dim=-1, p=2)
return 2 - 2 * (p_online * z_target).sum(dim=-1).mean()
# Training function
def train_byol(online_net, target_net, dataloader, optimizer, epochs=100, beta=0.99):
online_net.train()
target_net.eval() # target network is not trained directly
for epoch in range(epochs):
for (x1, x2) in dataloader: # Assuming x1 and x2 are two augmented versions of the same batch
optimizer.zero_grad()
# Forward pass through the online network
_, p1_online, q1_online = online_net(x1)
_, p2_online, q2_online = online_net(x2)
# Forward pass through the target network
with torch.no_grad():
_, p1_target, _ = target_net(x1)
_, p2_target, _ = target_net(x2)
# Compute the BYOL loss
loss1 = byol_loss(q1_online, p2_target)
loss2 = byol_loss(q2_online, p1_target)
loss = loss1 + loss2
# Backpropagation and optimization
loss.backward()
optimizer.step()
# Update the target network
update_moving_average(online_net, target_net, beta)
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")
# Initialize online and target networks
online_net = BYOL()
target_net = copy.deepcopy(online_net) # Target network is a copy of the online network
# Initialize optimizer
optimizer = optim.Adam(online_net.parameters(), lr=0.001)
# Example dataloader
# You need to provide your own dataloader where each item is a tuple (x1, x2) of two augmented views of the same image
# dataloader = ...
# Train BYOL
train_byol(online_net, target_net, dataloader, epochs=100, beta=0.99)
Python
복사
