
Vision Transformer(ViT)
Vision Transformer는 말 그대로 Transformer를 Vision Task에 적용한 모델을 말한다. 본래 sequence 문제를 해결하기 위해 설계된 Transformer가 NLP에서 큰 성공을 거두자 이를 Vision 분야에도 적용하려던 시도가 많았는데, 다른 방법들이 Attention 레이어를 CNN과 섞어서 사용하는데 초점을 맞춘 반면 ViT는 CNN을 사용하지 않고 Transformer의 Encoder 아키텍쳐를 최대한 그대로 살리면서 Vision 분야에 적용한 모델이다.
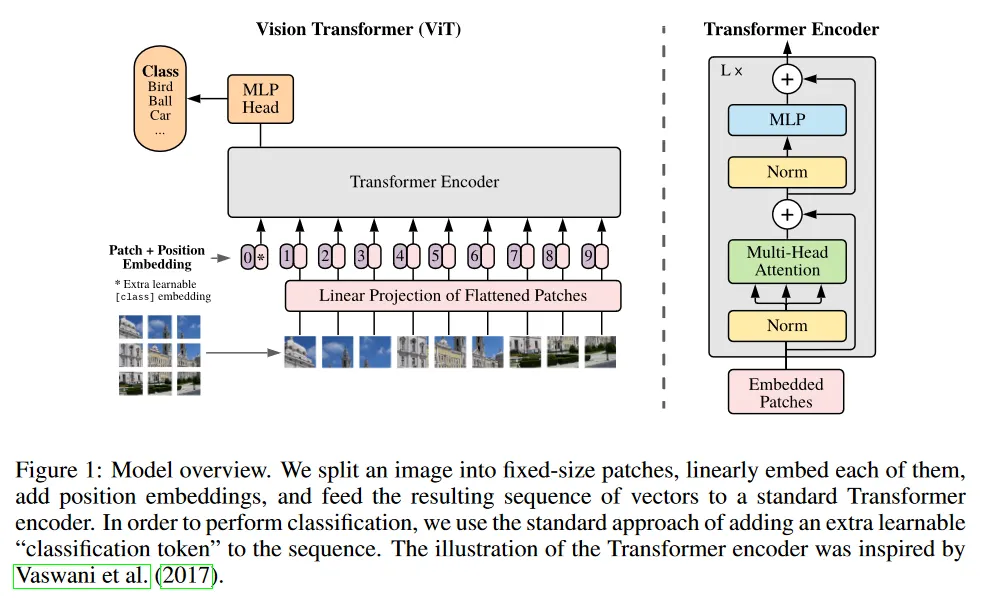
이미지의 모든 픽셀에 대해 나머지 모든 픽셀에 대해 attention 하는 것은 계산적으로 감당할 수 없었기 때문에 ViT는 이미지를 일정한 크기(16x16)의 patch로 분할한 후, 각 patch를 NLP 모델에서 token처럼 활용해서 transformer encoder에 입력으로(positional embedding을 추가해서) 사용하고, encoder 위에 classification을 위한 MLP head를 붙여서 분류 작업을 수행함.
이미지의 분할된 patch는 나머지 모든 patch를 이용해서 self-attention을 수행하기 때문에 patch 수에 따라 의 계산 복잡도를 갖는다. 또한 모든 patch에 대해 self-attention하기 때문에 patch를 굳이 2차원으로 구분하여 입력하지 않고 1차원으로 입력한다. 논문의 저자들은 2차원으로도 해봤는데, 별 차이 없었다고 함.
각 patch가 나머지 모든 patch를 이용하여 self-attention하기 때문에 local 정보만 활용하는 CNN에 비해 global 정보를 반영할 수 있다는게 이 모델의 장점. 다만 CNN의 내재된 inductive bias인 2차원 구조와 이동 불변의 속성이 덜 반영된다. 논문의 저자들은 아주 큰 데이터셋으로 학습하면 이것도 학습할 수 있다고 함.
기본적으로 적은 데이터셋에서는 CNN 기반 모델들의 성능이 더 좋았지만, 대규모 데이터셋을 사용하는 경우 CNN 기반 모델의 성능을 뛰어 넘을 수 있었다고 한다. 이것은 Transformer의 Scale 확장성에 기인한 것으로 보이며, 덕분에 대규모 데이터셋을 사용해 모델을 학습하는 곳에서 많이 차용하게 됨.
