
Multivariate Student distribution
•
Student 분포를 차원으로 쉽게 확장할 수 있다. 특히 다변량 student 분포의 pdf는 다음과 같이 주어진다.
•
여기서 는 scale 행렬이라 부른다.
•
student는 가우시안 보다 두꺼운 꼬리를 갖는다. 가 작을수록 꼬리가 더 두꺼워진다. 이면 분포는 가우시안에 가까워지는 경향이 있다. 이 분포는 다음의 속성을 갖는다.
•
평균은 (유한) 일 때만 잘 정의된다. 유사하게 공분산은 일 때만 잘 정의된다.
Circular normal (von Mises Fisher) distribution
•
때때로 데이터가 유클리드 공간의 임의의 점이 아니라 단위 원에 존재할 수 있다. 예컨대 -normalized -차원 벡터는 의 단위 구에 임베딩 되어 있다.
•
von Mises-Fisher 분포 또는 circular normal 분포라고 부르는 가우시안 분포의 확장은 이런 angular 데이터에 대해 적합하다. 다음의 pdf를 갖는다.
•
여기서 는 평균 (인)이고,
◦
은 농도(concentration) 또는 정밀도(precision) 파라미터(표준 가우시안의 와 유사)이고
◦
는 정규화 상수이다.
◦
는 첫 번째 종류의 수정된 Bessel 함수이고 차수 이다.
◦
vMF는 유클리드 거리 대신 cosine 거리로 파라미터화된 구형 다변량 가우시안과 같다.
•
가우시안 혼합 모델을 사용하는 대신 혼합 모델 내부에서 -normalized 벡터를 클러스터링 하기 위해 vMF 분포를 사용할 수 있다. 이면 구형 K-mean 알고리즘으로 축소된다.
◦
이 알고리즘은 혼합(admixture) 모델의 내부에서도 사용될 수 있다. 이것을 spherical topic model이라 부른다.
•
인 경우 대안은 다음 형식을 갖는 단위 원에서 von Mises 분포를 사용하는 것이다.
Matrix normal distribution (MN)
•
matrix normal 분포는 다음과 같이 행렬 에 대한 확률 밀도 함수로 정의된다.
•
여기서 는 의 평균값이고 는 행 사이의 공분산이고, 는 열 사이의 정밀도 이다. 이것은 다음처럼 볼 수 있다.
•
대신에 column-covariance 행렬 을 사용하여 다음의 밀도를 이끄는 행렬 normal 분포의 정의를 하는 다른 버전이 있다.
•
이 두 가지 버전의 정의는 분명히 동등하다. 그러나 위의 방정식 가 posterior의 정돈된 업데이트를 이끈다.
◦
켤례 prior의 다변량 정규 분포의 posterior를 해석에서 공분산 행렬 보다 정밀도 행렬을 사용하는 것이 더 편리한 것처럼.
Wishart distribution
•
Wishart 분포는 감마 분포를 양의 정부호 행렬로 일반화한 것이다. ‘Wishart 분포는 다변량 통계에서 중요함과 유용함의 측면에서 정규 분포 다음 순위이다.’라는 주장도 있다. 대부분 이것을 공분산 행렬을 추정할 때 불확실성을 모델링하기 위해 사용한다.
•
Wishart의 pdf는 다음과 같이 정의된다.
•
여기서 는 자유도이고 는 scale 행렬이다. 정규화 상수는 일 때만 존재한다(따라서 pdf는 잘 정의된 경우에만 존재한다).
•
분포는 다음의 속성을 갖는다.
•
최빈값(mode)가 에만 존재함에 유의하라.
•
이면 위샤트는 감마 분포로 축소된다.
•
이면 chi-squared 분포로 축소된다.
•
위샤트 분포와 가우시안 사이에 흥미로운 연결이 존재한다. 특히 에서 scatter 행렬 이 위샤트 분포 을 갖는 것을 보일 수 있다.
Inverse Wishart distribution
•
이면 인 것과 유사하게 이면 이다. 여기서 IW는 inverse Wishart이다. inverse gamma의 다차원 일반화이다.
•
과 에 대해 다음과 같이 정의된다.
•
이 분포가 다음 속성을 갖는 것을 보일 수 있다.
•
이면 inverse gamma로 축소된다.
•
이면 inverse chi-squared 분포로 축소된다.
Dirichlet distribution
•
베타 분포의 다변량 일반화는 Dirichlet 분포이다. 이것은 다음과 같이 정의되는 확률 simplex에 대한 support를 제공한다.
•
pdf는 다음과 같이 정의된다.
•
여기서 는 다변량 베타 함수이다.
•
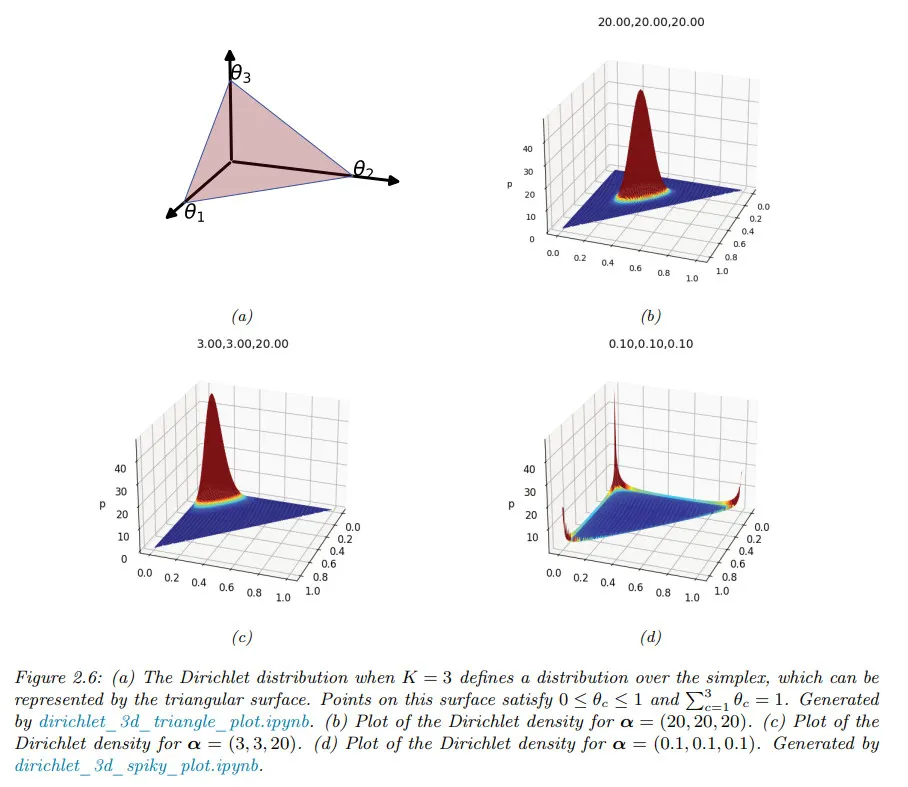
아래 그림은 일 때 디리클레를 plot한 것이다.
◦
는 분포의 강도(얼마나 peaked인지)를 제어하고, 는 어디서 peak가 나타나는지를 제어하는지를 볼 수 있다.
◦
예컨대 은 균등 분포이고 는 에 중심을 둔 넓은(broad) 분포이다.
◦
은 에 중심을 둔 좁은(narrow) 분포이다.
◦
는 1개의 코너에 더 많은 밀도가 부여된 비대칭 분포이다.
•
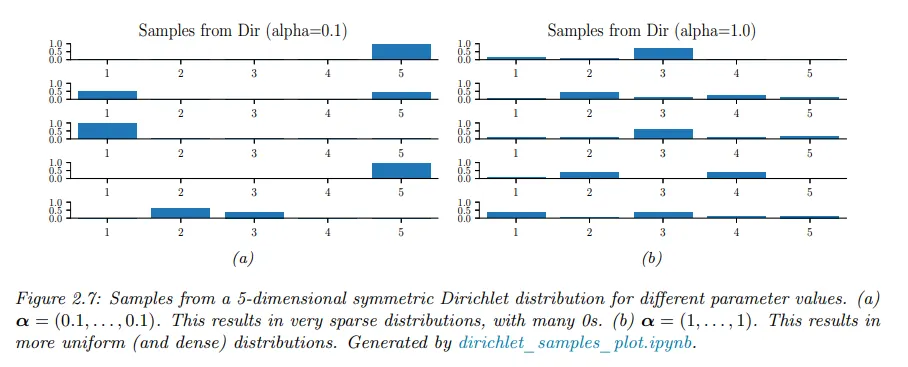
모든 에 대해 이면 simplex의 코너에 spike를 갖는다. 일 때 분포의 샘플은 희소하다. 아래 그림 참조.
•
디리클레 분포의 다음과 같은 유용한 속성이 있다. 여기서
•
종종 형식의 대칭 디리클레 prior를 사용한다. 이 경우에 와 을 갖는다.
◦
따라서 를 증가시킴에 따라 분포의 정밀도가 증가하는 것(분산은 감소)을 볼 수 있다.
•
디리클레 분포는 aleatoric (데이터) 불확실성과 인식적(epistemic) 불확실성을 구분하는데 유용하다.
◦
이를 알아보기 위해 3면 주사위를 생각해 보자. 각 결과가 똑같이 나올 확률이 높다는 것을 안다면 위 그림에 표시된 과 같은 ‘peak’ 대칭형 디리클레 분포를 사용할 수 있는데, 이는 결과를 예측할 수 없다는 사실을 반영한 것이다.
◦
반대로 결과가 어떻게 나올지 확실하지 않은 경우(예컨대 편향된 주사위일 수 있음), 과 같은 ‘편평한’ 대칭형 디리클레를 사용하면 다양한 결과 분포를 생성할 수 있다.
◦
디리클레 분포를 입력에 따라 조건부로 만들 수 있는데 이는 (출력은 라벨)가 아닌 (출력은 분포)를 인코딩 하기 때문에 prior network라고 부른다.
